让 AI 自动记住你,再也不用每次从头解释,Claude Code 必备 claude-mem

让 AI 自动记住你,再也不用每次从头解释,Claude Code 必备 claude-mem

码哥字节
发布于 2026-05-20 13:20:46
发布于 2026-05-20 13:20:46
你好,我是码哥,今天我们来聊一聊 AI 自动记忆提高效率。
1. 彻底搞懂 AI 的"记忆"是怎么工作的——为什么每次打开都要重新介绍自己
2. 安装 claude-mem 插件,让记忆更强大——你的职业、写作风格、常用工具一次说完,永远记住
3. 学会查询、更新、删除记忆,不让 AI 记住你不想让它记的东西
一、你每次打开 Claude Code 都要"重新认识"它
我用 Claude Code 的第一个月,有件事让我特别烦。
每次打开一个新的对话窗口,我都得花三五分钟做同一件事——告诉 AI 我是谁:
“"我是一个内容运营,负责公众号和付费专栏。写作风格偏口语化,不用太多术语。我用 Mac,平时的工具是 Obsidian 记笔记、飞书写文档……"
不同的上下文还要加不同的背景:
“"我现在在写的这个系列是给职场人看的非技术教程,读者不会写代码……"
每次都要这样。每次。
更烦的是,我在上一个对话里刚告诉 AI"帮我改成短句,别用那么多长段落",它改了,改得很好。下次对话,它又全忘了。
AI 不是不聪明。它就是——没有记忆。
准确来说,它有记忆,但只在这一次对话里。你跟它说的每一句话,它都记得——直到你关掉窗口。下次打开,就像见到了一个完全陌生的人。
今天这一讲,我们来彻底解决这个问题。
解决方案有两条路,我会都讲到:一条是 Claude Code 自带的、不用装任何东西的「Auto Memory」;另一条是 claude-mem 插件,比自带功能更强,适合有更多个人偏好要记住的人。
搞明白这两条路的区别,你就知道自己需要用哪个了。
二、AI 的记忆是怎么工作的
要解决记忆问题,先得搞清楚 AI 为什么"没有记忆"。
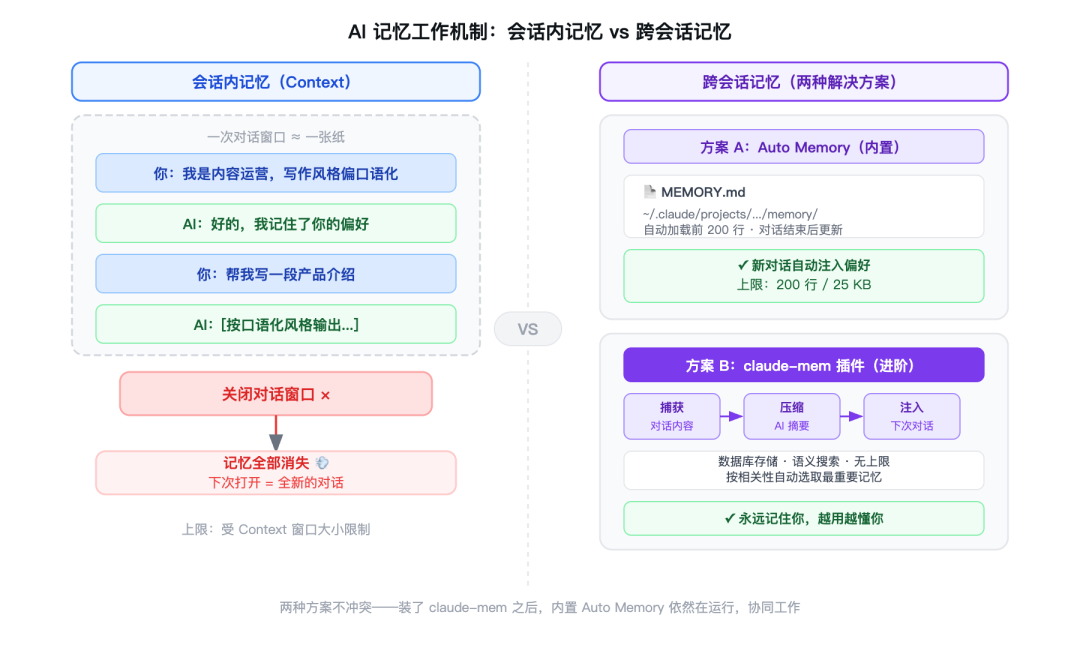
把每次对话想象成一张白纸
当你打开 Claude Code 开始新的对话,AI 拿到的是一张空白的纸。
它不知道你是谁,不知道你喜欢什么风格,不知道你上次说了什么。它唯一知道的,是你这次对话里写下来的东西。
随着对话进行,纸上的字越来越多——你的问题、它的回答、你的追问……这张纸就是它的"记忆",学名叫上下文(Context)。
但这张纸有两个问题:
第一,纸是有限的。 AI 每次能处理的文字量是有上限的。当对话太长,超过这个上限,最早的内容就会被"挤出去"。
第二,每次新对话,纸就换新的。 上一张纸的内容,不会带到下一张来。
所以 AI 不是傻,也不是懒——它就是每次都在从零开始。
AI 记忆工作机制:会话内记忆 vs 跨会话记忆
AI 记忆工作机制:会话内记忆 vs 跨会话记忆
两种解决思路
要让 AI 跨会话记住你,有两种做法:
做法一:在它"看"到的地方提前写好你的信息。
每次对话开始,自动把你的基本信息塞进去。AI 一开口就能读到"我今天要服务的是 XX 类型的用户"。
这就是 CLAUDE.md 和 Auto Memory 的做法——用文件来存储信息,每次对话自动加载。
做法二:让 AI 自己记,下次自己想起来。
AI 在对话过程中主动把值得记的东西记下来,放在某个地方。下次对话,它去查一下,捡回相关记忆。
这是 claude-mem 插件更进一步做的事。
好,概念讲完了。下面我们来实际操作。先从不用装任何东西的方案开始。
三、Claude Code 自带的记忆:Auto Memory
Claude Code v2.1.59 之后内置了 Auto Memory 功能,装好 Claude Code 就有,不需要额外操作。
它记什么、存在哪里
Auto Memory 会在你对话结束后,把值得记住的东西写进一个文件:
~/.claude/projects/<你的项目>/memory/MEMORY.md
里面大概长这样:
## 用户偏好
- 写作风格:口语化,避免长段落,短句为主
- 职业背景:内容运营,公众号 + 付费专栏
- 常用工具:Obsidian(笔记)、飞书(文档)
## 项目规范
- 文档用 Markdown 格式
- 标题层级:H2 用于主章节,H3 用于小节
- 图片命名:NN-类型-主题.png
每次你开始新对话,Claude Code 会自动把这个文件的前 200 行(或 25KB,取先到者)塞进 AI 的上下文。
所以 AI 不是"记住了你",更准确的说法是——每次它都先读了一份关于你的小抄。
怎么让它记住你想记的东西
方法一:直接告诉它。
在对话里说:
“"记住,我写东西习惯用第二人称,不用'我们应该'这种表达。" "帮我记一下,我的专栏读者是非技术职场人,不要写代码。"
Claude Code 会判断这句话值不值得记。如果值得,它会把这条信息写进 MEMORY.md。
方法二:纠正它,让它从错误中学。
你说:"这段话写得太正式了,改成说话的语气。"
它改了,同时悄悄记下:这位用户偏好口语化风格。下次不需要你再说。
方法三:用 /memory 命令直接查看和编辑。
打开 Claude Code,输入:
/memory
它会列出所有已加载的记忆文件,你可以点开查看,也可以直接编辑。
image-20260517183955742
image-20260517183955742
查看记忆文件
也可以直接在终端里看:
# 查看记忆索引文件
cat ~/.claude/projects/$(ls ~/.claude/projects/ | head -1)/memory/MEMORY.md
或者简单一点,找到你的项目目录:
ls ~/.claude/projects/
选对应的项目文件夹,进去找 memory/MEMORY.md 就行。
Auto Memory 存的是纯 Markdown 文件,你可以用任何文本编辑器打开它,增删改都行。AI 读它,你也读得懂它。
这就是最简单的记忆方案。零安装,装好 Claude Code 就有。
它的局限
内置 Auto Memory 很好用,但有两个地方够不着:
第一,它的检索能力有限。 存的内容太多了,只能加载前 200 行。超出的部分,AI 看不到。
第二,它不够"主动"。 AI 需要推断什么值得记,不一定每次都记对。有时候你说了一句很重要的偏好,它没意识到应该记下来。
对于大多数非技术用户,Auto Memory 已经够用了。但如果你有大量个人信息要让 AI 记住,或者你同时在跑多个项目需要切换记忆,claude-mem 插件会让体验好一个档次。
四、进阶方案:安装 claude-mem 插件
claude-mem 是 GitHub 上的一个开源插件,2026 年初发布后迅速走红,截至 2026 年 5 月 GitHub 上有 76,000+ stars。
它在 Auto Memory 的基础上再进一步:
- 记忆用数据库存储,不是普通文本文件,存多少都能搜到
- 支持语义搜索:你不记得之前具体说了什么,AI 可以根据意思找到相关记忆
- 自动把每次对话中的重要动作压缩成记忆条目——不只是你说的话,还有它做的事
- 提供 mem-search、knowledge-agent、smart-explore 三个 Skill,可以主动查询和管理记忆
安装前的准备
claude-mem 需要你的电脑上装有:
- Node.js 20.0.0 及以上(在终端输入
node --version检查) - 有效的 Claude Code 账号
检查 Node.js:
node --version
如果看到 v20.x.x 或更高版本,可以继续。如果看到 command not found 或版本低于 20,先回第 5 讲装好 Node.js。
“💡 版本提醒:claude-mem 截至 2026-05-17 的最新版本是 v13.2.0,安装命令和功能可能随版本迭代变化。如果你是几个月后看到这篇文章,建议先查一下 GitHub 页面确认最新安装方式。
安装步骤
打开 Claude Code,依次输入这两条命令:
/plugin marketplace add thedotmack/claude-mem
按回车,等它下载。完成后再输入:
/plugin install claude-mem
安装完成后,重启 Claude Code。
重启之后,claude-mem 开始在后台工作。它会在 ~/.claude-mem/ 目录下建立自己的数据库,你不需要关心这个目录——它是 claude-mem 自动维护的。
验证安装成功
重启后,在 Claude Code 里输入:
/mem-search
如果能看到 mem-search Skill 被加载,说明安装成功。
image-20260517184103270
image-20260517184103270
claude-mem 自动记住什么
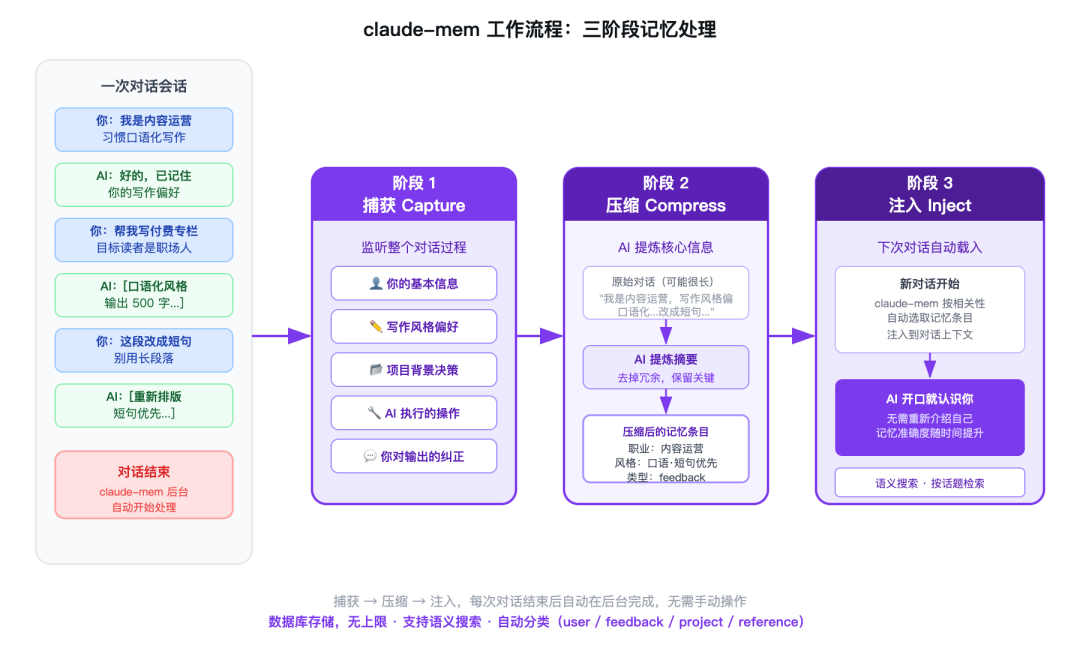
装好之后,你不需要手动操作任何东西。
claude-mem 在后台监听你的每次 Claude Code 会话。当会话结束,它会把这次对话里有价值的内容——你的请求、AI 的操作、文件的改动、你的偏好表达——用 AI 压缩成摘要,存进数据库。
这些摘要按类型分类:
类型 | 存什么 | 举例 |
|---|---|---|
user | 你的基本信息和偏好 | 职业、写作风格、常用工具 |
feedback | 你对 AI 输出的纠正 | "改成短句"、"不要用成语" |
project | 项目级别的决策 | 目录结构、命名规范、技术选型 |
reference | 文件位置和资源信息 | 哪个文件夹放哪类内容 |
下一次你开一个新对话,claude-mem 会把这些记忆里跟当前对话最相关的条目,自动塞进上下文。AI 读到了,就相当于"想起来了"。
claude-mem 工作流程:捕获 → 压缩 → 注入
claude-mem 工作流程:捕获 → 压缩 → 注入
五、实战:用 5 条信息让 AI 永远认识你
现在我们来做本讲的配套实战任务。
目标:让 AI 记住你的 5 条个人信息,下次新会话验证它是否记住了。
第一步:告诉 AI 你是谁
打开 Claude Code,开始一个新对话。直接输入:
请帮我记住以下关于我的信息:
1. 我的职业:[你的职业,比如"市场运营,负责公众号内容"]
2. 我的写作风格偏好:[比如"口语化,短句,不要堆砌术语"]
3. 我常用的工具:[比如"飞书、Notion、石墨文档"]
4. 我目前在做的主要项目:[比如"一个面向职场人的付费专栏,31 讲"]
5. 一个我特别不喜欢的表达方式:[比如"不要用'总而言之'这类套话"]
请把这些信息存入你的记忆,以后每次对话都能记住。
把方括号里的内容换成你自己的真实信息。然后发送。
AI 会把这些信息存进 Auto Memory(如果你只装了内置功能)或 claude-mem 数据库(如果你装了插件)。
第二步:关闭当前对话,开一个全新的
这一步很重要——你要确认是全新的会话,不是继续上次的对话。
如果你用的是 claude-mem,它还会在后台把刚才的对话压缩成记忆条目。
第三步:验证 AI 还记不记得
在新的对话窗口里,直接问:
你还记得我是谁吗?我的写作风格偏好是什么?
如果 Auto Memory 生效,AI 会说出你上次告诉它的那些信息。
如果装了 claude-mem,还可以主动调用记忆搜索:
/mem-search 我的职业和写作偏好
它会从记忆数据库里找到相关条目,显示出来。
第四步:更新和删除记忆
记忆不是一成不变的。换了工作、换了项目、改了写作风格——都得更新。
更新记忆:直接说。
帮我更新一下记忆:我的职业已经换成了产品经理,不再是市场运营了。
AI 会找到对应的条目更新它。
删除某条记忆:
用 Auto Memory 的话,打开 /memory 命令,找到对应文件,直接编辑删掉那一行。
用 claude-mem 的话,直接说:
/mem-search 删除关于我职业的那条记忆
或者去 ~/.claude-mem/ 目录下找到对应的数据库文件,用 claude-mem 提供的管理界面操作。
查看所有记忆:
# 内置 Auto Memory 方式
cat ~/.claude/projects/<项目目录>/memory/MEMORY.md
# 使用 /memory 命令(在 Claude Code 里)
/memory
六、进阶用法:让记忆工作得更精准
装好之后,还有几个小技巧能让记忆系统用起来更顺。
技巧一:主动标记重要偏好
不要等 AI 自己推断什么值得记。遇到重要的个人偏好,主动说:
“"请记住这一点:我的专栏读者都是非技术职场人,任何技术概念都必须用生活类比解释,不能直接上定义。"
在关键信息前加"请记住",会让 AI 更确定要把这条存进记忆,而不是只在这次对话里用一次。
技巧二:分类存储,让记忆更整洁
如果你有很多信息要记,建议一次只告诉 AI 一类,并说清楚类型:
关于我的个人偏好(写作风格):
- 短句优先,每段不超过 4 行
- 第二人称对话感,全程用"你"
- 比喻和类比放在专业解释前,不是后
关于我的项目背景:
- 正在写一个叫「AI 超能工具箱」的付费专栏
- 共 31 讲,每讲 4000-6500 字
- 目标读者是非技术职场人(产品、运营、内容)
分开存,以后查起来更容易找到。
技巧三:定期检查和清理
记忆积累多了,可能会有过时的条目——职业变了、项目做完了、偏好改变了。
建议每个月用 /memory 命令扫一眼,把不再准确的条目删掉或更新。
记忆不是越多越好。精准的少量记忆,比模糊的大量记忆更有用。
技巧四:用 private 标签保护敏感信息
如果你在对话里提到了不想让 claude-mem 存储的内容,可以用特殊标签包住:
<private>
我的信用卡号是 xxxx(这是测试用的,不要记住)
</private>
claude-mem 会跳过 <private> 标签里的内容,不会存进数据库。
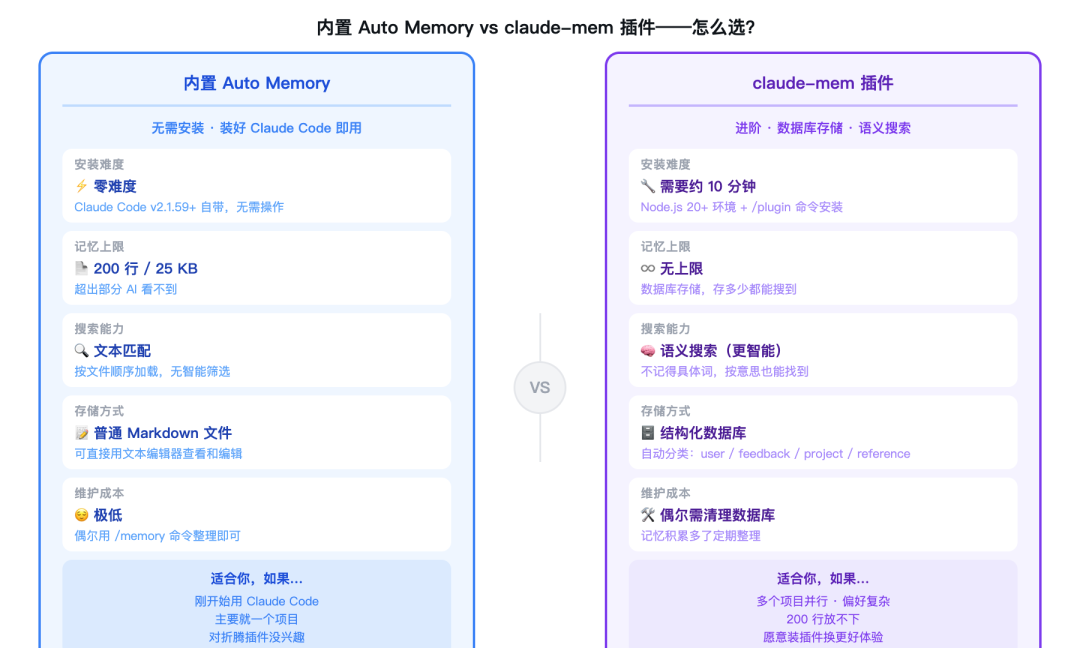
内置 Auto Memory vs claude-mem 插件对比
内置 Auto Memory vs claude-mem 插件对比
七、内置记忆 vs claude-mem:选哪个?
用了几个月之后,我的判断是这样的:
用内置 Auto Memory,如果你是这种情况:
- 刚开始用 Claude Code,不想一次装太多东西
- 主要就一个项目,记忆不会堆积太多
- 不太在意记忆精准不精准,有个大概就行
- 对折腾插件没兴趣
用 claude-mem 插件,如果你是这种情况:
- 同时在跑多个差别较大的项目,需要切换不同"背景"
- 对 AI 的记忆准确度有较高要求
- 积累了大量个人偏好、项目背景,内置的 200 行放不下
- 愿意花 10 分钟装插件、换更好的体验
内置 Auto Memory | claude-mem 插件 | |
|---|---|---|
安装难度 | 零 | 需要 10 分钟 |
记忆上限 | 200 行(约 25KB) | 无上限(数据库存储) |
搜索能力 | 文本匹配 | 语义搜索(更智能) |
适合场景 | 单项目、个人偏好少 | 多项目、偏好复杂 |
维护成本 | 极低 | 偶尔需要清理数据库 |
两个方案不冲突——装了 claude-mem 之后,内置 Auto Memory 还是在跑,它们协同工作。
一个叫做记忆助理的案例(这是本专栏的长寿案例之一)就是以这一讲的配置为起点。后续第 22 讲「打造你的专属 AI 工作流」会再次用到今天建立的记忆体系——到时候你会发现,今天存进去的那 5 条个人信息,能让 AI 在完全陌生的场景里依然准确理解你。
课后小结
今天这一讲,我们做了一件彻底改变 AI 使用体验的事:让 AI 不再每次都跟你重新认识。
如果你只能记住三件事,记住这三件:
- AI 的记忆是会话级别的——每次新对话它都从零开始,这是设计,不是 bug。解决方法是把信息写到它下次开始就能"读到"的地方。
- 内置 Auto Memory 已经够用了——不需要装任何插件,直接告诉 Claude Code"帮我记住这一点",它会写进 MEMORY.md,下次自动加载。
- claude-mem 是进阶版——如果你的个人偏好多、项目背景复杂,用 claude-mem 的数据库存储和语义搜索,体验会好很多。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号