企业级 AI Coding,先算清「爆炸半径」:用 Spec + Skill 做检测、报告、评估与改单建议

企业级 AI Coding,先算清「爆炸半径」:用 Spec + Skill 做检测、报告、评估与改单建议

用户5602664
发布于 2026-05-20 13:34:10
发布于 2026-05-20 13:34:10
以 618 促销「每人限领优惠券由3张改为5张」为例,看影响面如何从「凭经验猜」变成「可出报告、可门禁、可复盘」。
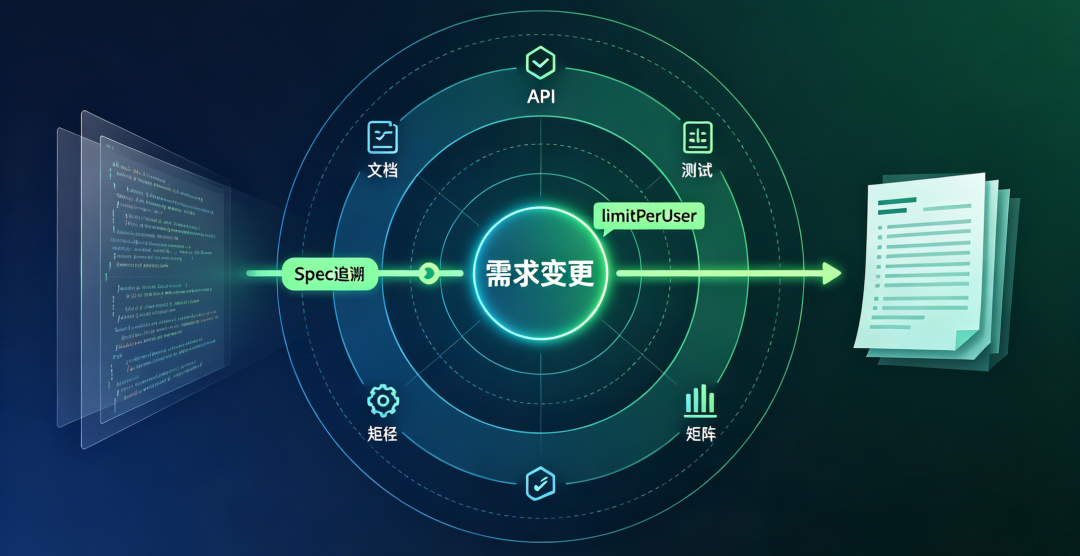
一、AI 写码越快,「改一行炸一片」越隐蔽
很多企业上了 Copilot、Cursor、内部大模型之后,研发反馈很分裂:一边是「出活快了」,一边是「不敢改老模块」。根因往往不在模型不够聪明,而在于 企业级交付仍然缺一张「影响面的地图」。
所谓 爆炸半径,不是炫技词汇,而是改一个锚点(字段、规则、接口、REQ)时,按规定必须联动哪些文档、测试、契约与交付物。在传统项目里,这张图存在于老员工的脑子里;在 AI Coding 场景里,模型会帮你改代码,但 不会自动知道产品口径、客服手册、边界 TC 是否一起变——结果变成:代码合并很快,联调与上线很慢。
我们在一套 618 促销活动的 Spec Coding 样例里,把这件事做成了可演示、可度量、可自动化的流程。下文用真实字段与编号举例,读者可直接对照自己项目里的 PRD / 用户故事 / 接口 / 用例表。
二、618 场景:一句「加码」背后到底要动哪里?
运营在群里说了一句:
「618 优惠券加码,每人限领从 3 张改成 5 张。」
若只把这句话丢给 AI「帮改一下领券逻辑」,常见结果是:模型改了后端校验或前端展示中的一处,漏掉 AC、漏改测试边界、漏同步 UI 文案,甚至 04 里的业务规则 R-02 仍写着 3。联调时前端显示「x/3」,接口已允许 5;上线后客服培训手册还是 3 张——这就是 爆炸半径失控,不是模型「笨」,是 缺少 Spec 真源与检测 Skill。
在我们固定的 十四文档体系(01~14)中,这条需求有清晰锚点:
层级 | 文档 | 618 样例中的关键条目 |
|---|---|---|
业务规则 | 04 PRD | R-02 |
用户故事 | 05 US | US-002 |
可测条款 | 05 AC | AC-002-02 |
契约真源 | 09 API | POST /coupons/receive |
界面 | 06 FSD | UI-COUNT |
测试 | 13 | TC-011 |
追溯 | 14 RTM | ROW-006 |
金标准答案(评审冻结用):一次合规变更至少联动 04 → 05 → 09 → 06 → 13 → 14六类文档;10领取记录表可视情况同步。改完后 TC-011的断言应从「第 4 次拒绝」改为「第 6 次拒绝」,06文案从 x/3 改为 x/5。
传统模式排期:开会打听 → 各端自查 → 联调对口径 → 补手册,约 2 天仍可能漏边缘交付物。
Spec + Skill 模式:先出 影响面报告→ 按清单 sync 联动→ gates 终检→ 再改代码,约 10~15 分钟确认范围(618 样例叙事)。
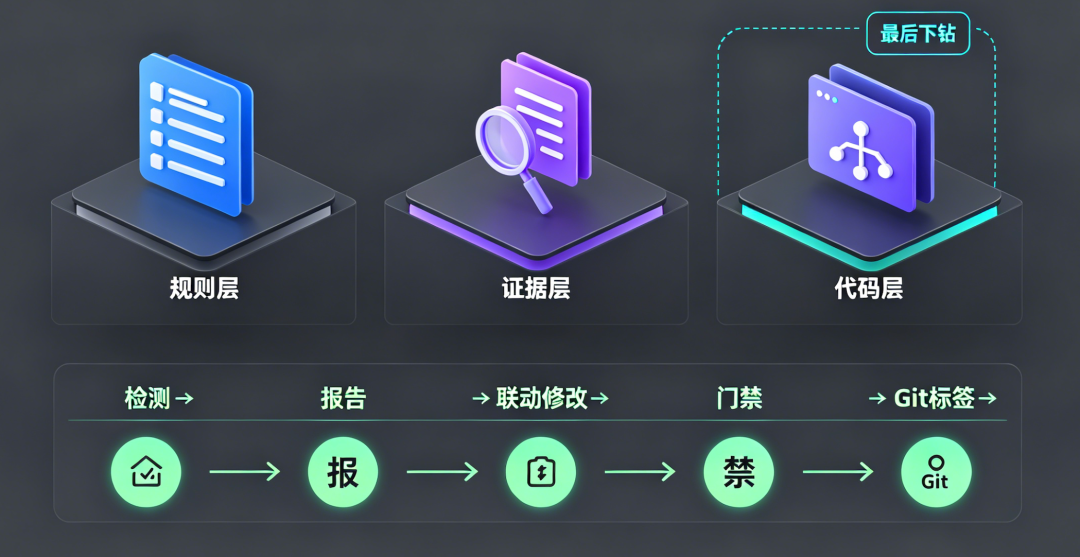
三、企业级 AI Coding 的爆炸面:三层,而不是全库 grep
我们主张 Spec-first:先文档、后代码。爆炸半径分三层,Skill 分工执行:
1)规则层——「应该影响谁」
来自 写作顺序 + 变更同步表(spec-sync-on-changeSkill)。例如:
- 改 API 字段 / 错误码→ 必走:09 → 10 → 05 AC → 13 TC → 14 行
- 改 业务规则→ 必先 04,再下游 05 / 09 / 06 / 13 / 14
规则层 不依赖代码结构,适合老项目:只要 01~14 真源在,就能给出 必改文档顺序,避免「只改 09 不改 AC」。
2)证据层——「文档里真的提到了谁」
在 Spec 目录(如 Spec模板-投研助手/*.md)对锚点做引用扫描:REQ 编号、字段名 limitPerUser、端点 POST /coupons/receive、TC-ID 等。可用脚本 impact-scan.py输出 JSON:命中文件、行号、片段——报告里可粘贴,评审可复核,不是黑盒 AI 幻觉。
618 金样例提示:若扫描类型仅按「字段→API 链」推断,可能 漏掉 04 业务真源与 06 UI(规则层 Recall 约 67%);合并规则 + 证据 + 人工对账后,才可达到金标准 100% 召回。这正是企业落地时要修的:规则表要覆盖业务真源,不能只会改接口。
3)代码层——「实现改哪里」
仅在报告标 P0、契约 breaking 或 TC 已绿之后再缩小范围下钻(receive 路由、校验、对应用例)。AI Coding 应用在这一层提速;爆炸半径估算不应第一步就全库 grep,否则噪音大、仍不知道「产品算不算改完」。
四、Skill 链:检测 → 报告 → 评估 → 修改建议
我们把能力拆成 可 @ 调用的 Skill(与 Cursor / 内部 Agent 集成),形成企业可复制的「改需求标准作业」:
Step 1:@spec-impact-blast-radius— 出影响面报告
输入:锚点(如 limitPerUser、REQ-SC618-006)或自然语言「3 张改 5 张」。
输出(对齐 report-template.md):
- 1. 结论摘要:爆炸半径标签(小/中/大)、影响面指数(非工时承诺)、必改文档数、最大风险一句
- 2. 锚点说明:对应 04 R-02、05 AC-002-02、09 字段等
- 3. 必改文档表:带顺序与原因(例:先 04,再 05,再 09…)
- 4. 引用命中表:文件名 | 行上下文 | 命中词
- 5. RTM / TC 影响:ROW-006 正向链;TC-011 需改断言次数
- 6. 爆炸半径分级:L0 直接 → L1 契约 → L2 行为 → L3 验证 → L4 范围 → L5 计划
- 7. 建议下一步:勾选框形式——是否调用 sync、gates、是否下钻代码
指数公式(用于对比,非科学绝对值):
影响面指数 = L0×1 + L1×3 + L2×2 + L3×2 + L4×4 + L5×1 + (无TC的REQ)×5 + …
618 样例 limitPerUser变更通常为 「中」改「大」之间,用于评审排序,不能当人力估算。
Step 2:@spec-sync-on-change— 按报告执行联动修改
报告只分析;改文档由 sync Skill 按表逐篇执行:同一 REQ 前缀、同一字段名 limitPerUser、AC 里写清「第 6 次拒绝」、09 JSON 示例与 1.1 路径约定一致。
禁止:只改后端、不碰 05/13;或只改 PRD、不碰 09。
Step 3:@spec-validate-gates— 文档侧评估 / 门禁
改完后终检(来自 01第七节),不过 不得标 Approved / 不得冻结基线:
门禁 | 618 样例 |
|---|---|
G1 | P0 US 在 14 有行 → ROW-006 ✅ |
G2 | 每条 REQ 在 13 有 TC → REQ-006 有 TC-009~014 ✅; |
G3 | 09 含请求/响应/错误示例 → |
G2 失败样例刻意保留:90% 追溯完整度仍可能带发布风险——门禁要把「矩阵上有行但无 TC」拦在 Approved 之前。
Step 4:@spec-doc-versioning— 冻结与 Git 基线
Phase1 评审通过后:05/09/14 升版 v0.2、状态 Approved → Frozen(基线),git tag spec/sc618-phase1。
此后修改必须回到 impact → sync → gates流程,不允许在主干上 silent 改 Frozen 正文。
贯穿轮次:R1~R4 与总控
- R1spec-round1-proposal:02 采集 → 03 Phase1 冻结 → 04 PRD(含 R-02)
- R2spec-round2-anchor:05 US/AC ↔ 09 API 双锚
- R3spec-round3-design:06 界面、10 库存与 decreaseStock乐观锁
- R4spec-round4-close:13 TC、14 RTM
- 总控spec-coding-14:接到「改限领张数」时 路由到 impact + sync,不代替轮次 Skill 写正文
OpenSpec 可选:propose → 写真源 → validate → apply 代码 → archive,与 01~14 双轨不打架。
为什么必须拆成多个 Skill,而不是一个「万能 Agent」?
企业落地里最容易踩的坑,是把「分析、修改、评审、打 tag」塞进一次对话。结果是:模型改了几份文档,却 没有报告留痕,评审无法签字,出事后也无法回答「当时认为影响面有多大」。
我们的做法是 职责分离:
- impact只读分析,默认不改真源(除非用户明确要求「分析并修复」);
- sync只改文档,且按顺序联动;
- gates只读检查,失败则阻断 Approved;
- versioning管版次与 Git 快照,与 OpenSpec 变更包解耦。
这样,AI Coding 的每一次需求变更,都能留下 「报告 → 修改 → 门禁 → 标签」四件套,满足金融、政企、大型互联网里常见的 审计与交接要求。
五、618 Gold 样例:一份影响面报告长什么样?
以下节选结构,便于企业直接套用:
## 结论摘要
- 爆炸半径:中偏大
- 锚点:limitPerUser(REQ-SC618-006)
- 必改:04, 05, 09, 06, 13, 14(顺序不可跳)
- 最大风险:只改 09 不改 AC-002-02 / TC-011 边界
## 必改文档(节选)
| 顺序 | 编号 | 动作 |
|------|------|------|
| 1 | 04 | R-02:3→5(张/人) |
| 2 | 05 | AC-002-02、RULE-002 |
| 3 | 09 | limitPerUser 示例与 ERR-LIMIT |
| 4 | 06 | UI-COUNT、ERR-MSG |
| 5 | 13 | TC-011:第 6 次拒绝 |
| 6 | 14 | ROW-006 状态与变更记录 |
## 建议下一步
- [ ] @spec-sync-on-change 按上表修改
- [ ] @spec-validate-gates 终检
- [ ] 代码:CouponReceive 校验 + 跑 TC-009~014修改建议由 Agent 按篇给出 diff 提纲(非盲目生成整库补丁):例如 05 的 Given/When/Then 如何改、13 的边界值如何随规则 +1。这与「让 AI 直接改代码」的区别是:改单建议绑定 REQ/TC 编号,可评审、可回滚、可进 Git。
六、如何衡量?才有底气使用 Spec
「好在哪里」必须能 对比、能复盘,我们拆三类度量:
1)文档健康度(冻结前)
- 追溯完整度= 五段链闭合的 REQ / 总 REQ → 618 90%(9/10,缺 US-008 无 TC)
- AC 覆盖率= 有 TC 的 AC / 总 AC → 618 87.5%(28/32)
- 影响面 Recall= 预测必改 ∩ 金标准 / 金标准 → 规则层约 67%,补全 04/06 后 100%
2)过程效率(改需求时)
- 变更影响评估耗时:传统约 2 天 vs Spec 约 10~15 分钟(同场景)
- 漏改文档次数:结合 RTM + sync 流程迭代统计(目标 ↓)
3)结果质量(上线后)
- 口径不一致类缺陷占比、P0/P1 缺陷密度、需求遗漏率(目标从约 20% → 5% 量级)
七、和「只让 AI 扫代码」的对比
维度 | 全库 grep / 静态分析 | Spec + Skill 爆炸半径 |
|---|---|---|
输入 | 代码符号 | REQ、字段、RTM 行 |
输出 | 调用链(可能含废弃代码) | 必改文档 + TC 清单 |
产品是否算改完 | 不知道 | AC + 14 矩阵可定义 Done |
客服/运营交付物 | 常漏 | 同步表 + 报告提醒边缘项 |
可否门禁 | 难 | G1/G2/G3 文档侧可拦 Approved |
AI 协作 | 易幻觉字段 | 只喂 05+09 片段,契约稳定 |
企业级 AI Coding 的正解不是「少写 Spec」,而是 Spec 做地图,Skill 做巡检员,AI 做实现手。
八、看不见的成本:为什么「没用 Spec 也没事」?
很多团队说「我们没用十四文档,项目也上线了」。往往不是没有损失,而是损失被 加班、英雄主义、联调周消化掉了,不会出现在「Spec 债」科目上。常见表象与 Spec 的解法如下:
表面现象 | 背后问题 | Spec + Skill 如何显性化 |
|---|---|---|
联调三天才对齐 | 05 与 09 各写各的 | 09 真源 + G3 示例;字段对照实验 |
改字段要改五处 | PRD、Wiki、类型定义分裂 | sync 表;09 冻结字段名 |
测试不知道测什么 | 无 REQ/TC 编号 | 13 与 14 对账;G2 门禁 |
AI 生成接口对不上 | 半截 PRD 进上下文 | 只投喂 05 一条 US + 09 一个端点 |
文档有但没人信 | 无 Approved / 冻结 / tag | versioning + Git 基线 |
618 样例里刻意保留 REQ-SC618-011(操作日志)在 14 有行、13 无 TC,就是用来演示:即使追溯完整度 90%,仍可能带缺口——门禁必须存在,爆炸半径报告里也要标 「缺口风险」,而不是粉饰太平。
九、落地建议:四个动作,一个 618 试点
- 1. 选一条真实变更做金样例(如限领张数、错误码、审批状态),写进 04/05/09/13/14,跑一遍 impact 报告。
- 2. 把「先报告、后改码」写进 PR 模板:无影响面摘要、无 gates 结果,Spec PR 不合并。
- 3. 冻结基线:Phase1 过了 gates 就打 spec/xxx-phase1tag,变更走 sync。
- 4. 用可视化实验台培训:覆盖矩阵、变更对比、影响面记分卡、遗漏实验——让新人 看见爆炸半径,而不是背概念。
读者自检清单(复制到评审会)
- 1. 我们是否能在 15 分钟内说出「改 limitPerUser」要动哪些文档与 TC?
- 2. 改接口字段时,是否 先改 09 再改 05 AC,而不是反过来?
- 3. 发布前是否跑过 G1/G2/G3,且 14 里无「有 REQ 无 TC」的 P0 行?
- 4. 影响面报告是否归档(如 变更影响面/日期-锚点.md),并与 Git PR 关联?
- 5. AI 生成代码的上下文,是否 默认带 05+09 片段,而非整本 PRD?
五条里若有 两条以上答否,就值得用 618 样例做一次 impact + sync试点——通常半天内就能看到「漏改清单」与「联调口径」的差异。
十、爆炸半径不是焦虑营销,是 AI 时代的交付准则
618 促销这类活动,规则一改,牵动领取、库存、试算、看板、权限多条链。AI 可以加速写码,但 不能替企业承担「改没改全」的责任。
通过 十四文档真源 + 影响面 Skill(检测、报告、评估、改单建议)+ 联动与门禁,我们把「爆炸半径」从老员工的直觉,变成 可生成、可复核、可冻结、可度量的工程能力。
若你正在推进企业级 AI Coding,不妨用下一次「改一张券、改一个字段」的需求做试点:先 @spec-impact-blast-radius 出报告,再让 AI 改代码——这一顺,往往比多训几个 PoPompt 更管用。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号