MumuSpec 实战指南:10个SKILL + 14篇Spec文档

MumuSpec 实战指南:10个SKILL + 14篇Spec文档

用户5602664
发布于 2026-05-20 13:35:15
发布于 2026-05-20 13:35:15
好的代码从好的规约开始。AI 写代码的能力越来越强,但 AI 写出的代码质量,取决于你给它的规格质量。
问题:AI Coding 时代的"垃圾进,垃圾出"
过去两年,AI 辅助编码从 Copilot 的逐行补全,进化到了 Agent 级别的端到端开发。但实践中有一个反复出现的问题:
你让 AI "做一个限时抢购功能",AI 生成的代码千奇百怪。因为"限时抢购"这个描述本身就不够精确。
人类工程师接到需求后,会做一系列隐性工作:
- 明确范围:抢购要支持库存预热吗?超时回滚走什么机制?
- 对齐契约:前端传什么字段?后端返回什么状态码?
- 想清楚异常:并发扣减怎么处理?库存为零时返回什么?
- 追溯测试:哪些场景需要覆盖?怎么判断完成?
这些思考过程,传统做法是写 PRD、画架构图、列 API 文档——但很少有人能坚持做完,也很少有人能保持多份文档之间的一致性。
MumuSpec 做的事情很简单:把工程师脑中"隐性思考"变成"显性文档",并且用 AI 帮你写这些文档,还能自动保持多份文档之间的一致性。
以"电商 618 促销系统"为例,完整走一遍
本文不只是理论——我们将用真实场景"电商平台 618 促销系统"(模块编号 M2-618),完整演示从原始需求到 14 篇 Spec 文档交付的全过程。你会看到每一步用了什么 Skill、输入了什么、产出了什么文档、中间遇到了什么问题以及如何修正。
14 篇文档,不是越多越好
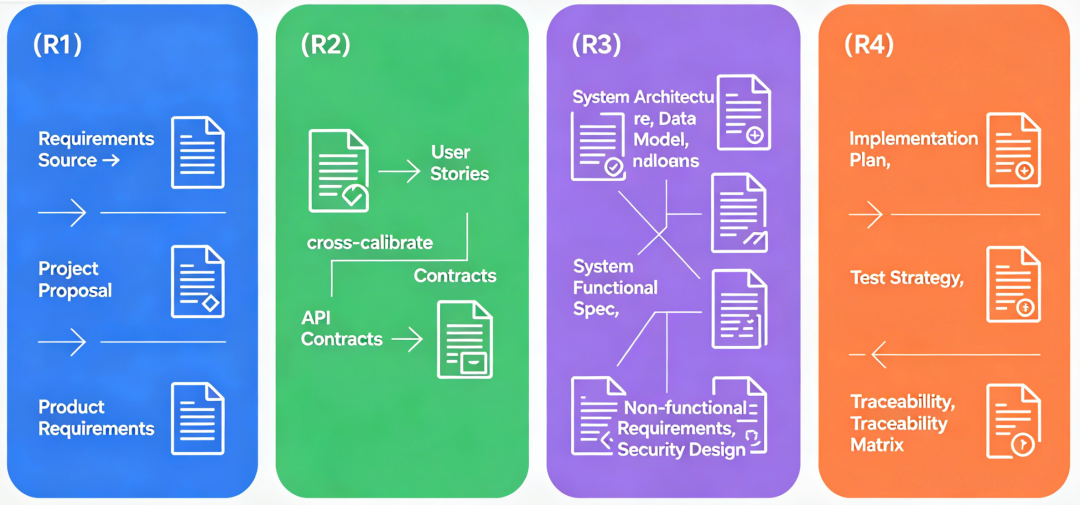
为什么是 14 篇?不是刻意凑数,而是从需求到交付,确实需要回答以下问题:
编号 | 文档 | 回答的问题 |
|---|---|---|
01 | 写作总则 | 我们怎么写文档?编号规则是什么? |
02 | 需求来源 | 需求从哪来?(纪要/邮件/访谈) |
03 | 立项提案 | 为什么做?做什么?不做什么?成功标准? |
04 | 产品需求 | 用户场景是什么?功能流程怎么走? |
05 | 用户故事 | 具体的需求描述?怎么算"做完了"? |
06 | 功能规格 | 每个交互细节怎么做?异常分支呢? |
07 | 非功能需求 | 性能指标?可用性要求? |
08 | 系统架构 | 组件怎么划分?技术选型?部署在哪? |
09 | API 接口 | 路径、参数、请求/响应格式? |
10 | 数据模型 | 表结构、字段、索引? |
11 | 安全设计 | 认证、授权、敏感数据怎么处理? |
12 | 实施计划 | 排期怎么排?里程碑在哪? |
13 | 测试策略 | 怎么分层测试?哪些门禁? |
14 | 追溯矩阵 | 需求→故事→API→测试用例,全链路覆盖了吗? |
其中 09(API 接口)是对外契约的真源——前端和第三方对接时,以这份文档的字段定义为准。10(数据模型)是存储侧的真源——DBA 和运维看这份文档。这两份文档的字段必须一致,其他文档引用它们但不能复制定义。
这就是 MumuSpec 的不混层原则:
- PRD 不写 SQL(那是 10 的事)
- API 不写像素级 UI(那是 06 的事)
- 用户故事不写完整 JSON Schema(引用 09 即可)
- 接口规格不写用户价值叙事(那是 05 的事)
10 个 AI Skills:怎么用
MumuSpec 不只是一套文档方法论——它直接提供 10 个 AI Skill,在 Qoder / Claude Code 等支持 Skill 的 AI 编辑器中可以立即使用。
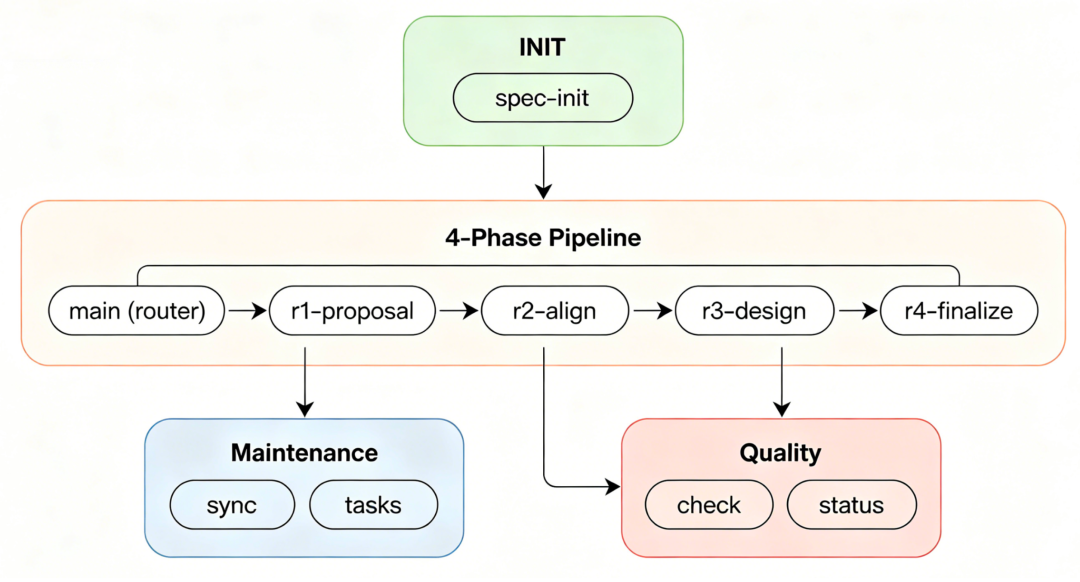
总览
┌─ 初始化 ──────────────────────────────────────────┐
│ mumu-spec-init 新项目骨架 │
└────────────────────────────────────────────────────┘
│
┌─ 内容生产(四轮递进) ─────────────────────────────┐
│ mumu-spec-main 总控入口,选轮次 │
│ mumu-spec-r1-proposal R1: 立项(02→03→04) │
│ mumu-spec-r2-align R2: 对齐(05↔09) │
│ mumu-spec-r3-design R3: 设计(08+10→06+07+11) │
│ mumu-spec-r4-finalize R4: 定稿(12+13→14) │
└────────────────────────────────────────────────────┘
│
┌─ 维护与工具 ──────────────────────────────────────┐
│ mumu-spec-sync 变更联动 │
│ mumu-spec-tasks 任务拆分 │
└────────────────────────────────────────────────────┘
│
┌─ 质量保障 ────────────────────────────────────────┐
│ mumu-spec-check 质量检查 │
│ mumu-spec-status 版本状态看板 │
└────────────────────────────────────────────────────┘所有 Skills 放在项目的 .qoder/skills/目录下,Spec 文档存放在 MumuSpec/目录。
实战:从 0 到 14,完整操作记录
以下以"电商 618 促销系统"为例,记录每一步操作了什么、产出了什么、遇到了什么问题、如何修正。
第一步:初始化项目骨架
Skill:mumu-spec-init
命令:
/mumu-spec-initAI 会提示你输入模块编号和名称:
- 模块编号:M2-618
- 模块名称:电商平台 618 促销系统
产出:在 MumuSpec-618/目录下创建 14 个骨架文件(01-总则.md~ 14-追溯矩阵.md),每篇包含:
- 元数据表(模块编号/名称/版本/状态)
- 章节标题结构
- 空的变更记录表
注意:这一步生成的文档大部分内容留空,只有框架结构。后续轮次逐步填充。
第二阶段 R1:需求采集 → 立项 → 产品需求
步骤 1:给 AI 原始需求材料
Skill:mumu-spec-r1-proposal
命令:
/mumu-spec-r1-proposal然后输入需求材料。我们的输入是两场会议的原始记录:
材料 1 — 618 大促启动会(2026-05-20):
参会人员:电商总监、运营经理、产品经理、技术负责人、营销负责人
痛点:
- 去年 618 秒杀活动库存超卖,引发大量客诉(P0)
- 优惠券系统在大促期间响应慢,领券页面超时(P0)
- 满减规则配置复杂,每次大促需要研发介入改代码(P0)
- 大促期间无法实时查看销售数据,决策滞后(P1)
- 活动结束后数据核对耗时 2-3 天(P1)
需求:限时秒杀、优惠券系统、满减规则引擎、实时数据大屏、活动排期管理
材料 2 — 运营人员访谈(2026-05-21):
- 大促期间最耗时的工作:配置和调整促销规则,每次需要和研发对齐 3-5 天
- 最希望系统解决的:规则配置可视化,活动进行中能实时调整
- 目前的做法:提需求给研发,研发改数据库+代码,测试后上线
- 核心诉求:"灵活 + 稳定"——规则配置灵活可调,底层系统稳定运行步骤 2:R1 自动产出 3 篇文档
产出文档 1:02-需求来源与采集记录.md
AI 将原始材料结构化为采集记录,包含 S-01(启动会)和 S-02(补充访谈)两个来源,每个来源记录时间、地点、参会人员、痛点列表(带优先级)、需求列表和下一步行动。
产出文档 2:03-立项提案与范围说明.md
基于 02 的结构化需求,AI 生成立项提案,包含:
- Why:618 大促是年度最重要营销活动
- Phase 1 交付范围(限时秒杀、优惠券系统、满减规则引擎、订单结算、实时数据大屏)
- Phase 2 Backlog(活动排期管理、数据核对自动化等占位)
- 成功标准(零超卖、领券 P99 < 200ms、运营 5 分钟配置规则)
- 不做清单(4 条:支付系统、物流、客服、商品管理)
- 风险与缓解措施
产出文档 3:04-产品需求说明.md
基于 03 的立项范围,AI 将每条需求展开为用户场景和功能流程,不涉及技术实现细节。
R1 阶段遇到的问题:
- 初始生成的 03 中"成功标准"写了"高性能"——被质量检查规则标记为模糊词,后改为具体指标"P99 < 200ms"
- 初始 02 缺少标准元数据表和变更记录——后续手动补充了标准头部格式
第三阶段 R2:用户故事 ↔ API 契约对齐(核心轮次)
R2 是 MumuSpec 最有特色的部分——同时生成用户故事和 API 契约,然后互相校准。
步骤 3:生成用户故事
Skill:mumu-spec-r2-align
命令:
/mumu-spec-r2-align产出文档 4:05-用户故事与验收标准.md
AI 基于 03 的 Phase 1 范围,为每个交付块生成一条用户故事:
US 编号 | 优先级 | 内容 | AC 数量 |
|---|---|---|---|
US-001 | P0 | 限时秒杀抢购 | 5 条 |
US-002 | P0 | 优惠券领取与使用 | 5 条 |
US-003 | P0 | 满减规则配置与生效 | 5 条 |
US-004 | P0 | 订单结算与优惠叠加 | 5 条 |
US-005 | P0 | 实时数据大屏 | 3 条 |
每条用户故事包含标准的"作为…我希望…以便…"格式和多个可测试的验收标准(AC)。
步骤 4:生成 API 接口规格
产出文档 5:09-API接口规格.md
AI 基于 05 的用户故事,为每个 P0 故事生成对应的 API 端点:
API 编号 | 方法 & 路径 | 对应 US |
|---|---|---|
API-001 | GET /api/v1/seckill/sessions | US-001 |
API-002 | GET /api/v1/seckill/products | US-001 |
API-003 | POST /api/v1/seckill/order | US-001 |
API-004 | POST /api/v1/coupons/claim | US-002 |
API-005 | POST /api/v1/orders/calculate | US-002, US-004 |
API-006 | POST /api/v1/promo-rules | US-003 |
API-007 | GET /api/v1/promo-rules | US-003 |
API-008 | POST /api/v1/orders | US-004 |
API-009 | GET /api/v1/dashboard/stats | US-005 |
每个 API 端点包含完整的路径、方法、请求体、成功响应、错误响应示例和字段定义表。
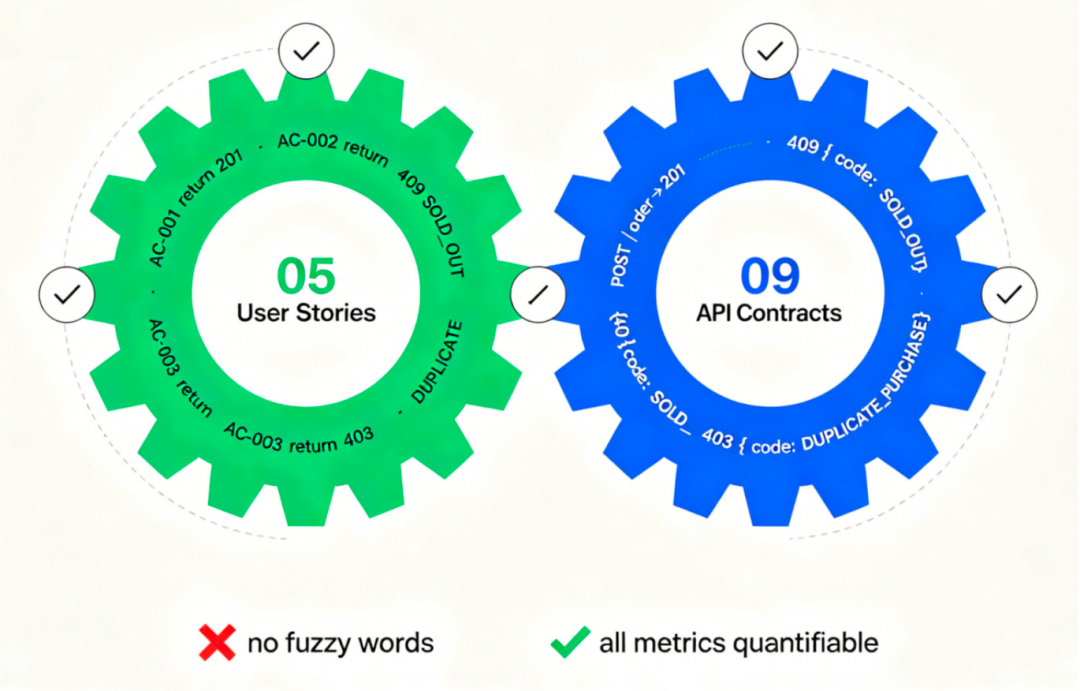
步骤 5:双向校准(05 ↔ 09)
这是 R2 的核心价值——AI 自动执行双向校验:
正向校验(05 → 09):
US-001 AC-002 "库存为零返回 409 SOLD_OUT"
→ API-003 错误响应中是否有 409 + SOLD_OUT? ✅ 有
US-001 AC-004 "重复购买返回 403"
→ API-003 错误响应中是否有 403 + DUPLICATE_PURCHASE? ✅ 有
US-002 AC-005 "领券 P99 < 200ms"
→ API-004 性能约束是否标注? ✅ 有
反向校验(09 → 05):
API-003 定义了 4 种错误响应
→ 05 中每个错误是否都有对应 AC? ✅ 是
API-005 被 US-002 和 US-004 共用
→ 两个故事的 AC 是否都覆盖了 API-005 的语义? ✅ 是
发现问题并修正:
US-001 AC-005 "超时取消库存回滚" — 初始描述中回滚时间
写的是"适当时间",违反质量规则(不能有模糊词)
→ 改为"15 分钟未支付自动取消,库存回滚 +1"关键约束:
- 05 不写 SQL、不写完整 JSON Schema(引用 09)
- 09 不写用户价值叙事(留在 05/04)
- 09 的字段名一旦确定就冻结,其他文档不允许出现别名
第四阶段 R3:技术设计
步骤 6:生成 5 篇技术文档
Skill:mumu-spec-r3-design
命令:
/mumu-spec-r3-designAI 按推荐顺序生成:
产出文档 6:08-系统架构.md
- 组件划分:API Gateway → 促销服务 → Redis Cluster → MySQL → Kafka
- 技术选型:Redis(库存缓存)、Aviator(规则引擎)、Kafka(事件流)
- 部署拓扑:主会场/分会场独立部署
产出文档 7:10-数据模型与存储规格.md
- 7 张表:seckill_session, seckill_product, seckill_order, coupon_template, user_coupon, promo_rule, order_event
- 每张表包含字段定义、类型、约束、索引
- 字段名与 09 API 完全一致(不混层原则)
产出文档 8:06-功能规格说明.md
- 按 US 展开行为细节:库存预热流程、规则引擎解析、优惠计算优先级
- 异常分支处理:Redis 降级到数据库、规则解析失败回退默认值
产出文档 9:07-非功能需求与约束.md
- 量化指标:秒杀 P99 < 50ms、领券 P99 < 200ms、大屏延迟 ≤ 10 秒
- 可用性:99.99% 大促期间
- 容量规划:10000 QPS
产出文档 10:11-安全设计规格.md
- 防刷限流:每用户每场次每秒 ≤ 1 次
- 原子库存:Redis Lua 脚本,不依赖数据库行锁
- 价格防篡改:最终价格由服务端计算
R3 阶段遇到的问题:
- 初始 10 数据模型中的字段名用了驼峰(orderId),与 09 API 的 snake_case(order_id)不一致——双向校验时发现,统一改为 snake_case
- 07 中初始写了"高性能"——被质量规则标记,改为具体 P99 指标
第五阶段 R4:定稿交付
步骤 7:生成实施计划、测试策略、追溯矩阵
Skill:mumu-spec-r4-finalize
命令:
/mumu-spec-r4-finalize产出文档 11:12-实施计划与里程碑.md
- 5 个里程碑(M1-M5),对应 5 个 Sprint
- 任务依赖关系图
- 每个任务标注对应 US、工期、前置依赖
产出文档 12:13-测试策略与质量门禁.md
- 4 层测试:L1 单元、L2 集成、L3 端到端、L4 性能
- 6 个质量门禁(G-LINT / G-UNIT / G-INT / G-E2E / G-PERF / G-NOSPOIL)
- 14 个测试用例(TC-M2-001 ~ TC-M2-014),每个包含步骤和预期结果
产出文档 13:14-需求追踪矩阵.md
- 18 行四向追溯矩阵(REQ → US → API → TC)
- 孤立项检查:6 项全部通过
- 终检清单:5 项全部通过
- 文档健康度:14/14 文档状态为 Draft v1.0
步骤 8:质量检查
Skill:mumu-spec-check
命令:
/mumu-spec-check检查结果:
完整性检查: 14/14 篇文档存在 ✅
一致性检查: 编号全局唯一,范围一致 ✅
追溯性检查: 18 行追溯矩阵,0 个孤立项 ✅
质量规则: 零模糊词,RESTful 路径,NFR 可量化 ✅所有检查通过,文档状态可标记为 Approved(待团队审查后确认)。
Skill 详解(完整参考)
以上是完整操作记录。下面是每个 Skill 的详细参考文档,方便日常使用。
mumu-spec-init — 初始化
什么时候用:新项目第一次使用 MumuSpec,还没有任何 Spec 文档。
做什么:
- 1. 创建 MumuSpec/目录
- 2. 生成 01-14 篇骨架文件
- 3. 01额外包含写作铁律和编号规则
怎么用:
/mumu-spec-initmumu-spec-main — 总控入口
什么时候用:不确定该用哪个 Skill,或者想走完整流程。
做什么:
- 根据你给的材料判断当前处于哪个轮次
- 路由到对应的子 Skill
- 内置全局铁律:不混层、写作顺序、契约真源
怎么用:
/mumu-spec-mainmumu-spec-r1-proposal — R1 立项
输入 → 输出:
输入 | 输出文档 |
|---|---|
会议纪要 / 邮件 / 口述 | 02 |
需求想法 / 老板要求 | 03 |
04 |
关键约束:
- 03的"不做清单"至少 3 条
- Phase 1 冻结范围,Phase 2 只做占位列表
mumu-spec-r2-align — R2 对齐(核心轮次)
输入 → 输出:
输入 | 输出文档 |
|---|---|
R1 的 03/04 文档 | 05 |
P0 需求列表 | 09 |
核心能力:双向校准
- 每条 AC 必须在 09 中找到可观测的断言
- 09 的字段名冻结,不允许别名
- 不允许出现没有对应 AC 的多余端点
mumu-spec-r3-design — R3 设计
输入 → 输出:
输入 | 输出文档 |
|---|---|
R2 对齐后的 05/09 | 08 |
推荐顺序:08 → 10 → 06 → 07 → 11
mumu-spec-r4-finalize — R4 定稿
输入 → 输出:
输入 | 输出文档 |
|---|---|
R1-R3 完整文档 | 12 |
终检清单:
每条 P0 US 在 14 有行
每条 REQ 在 13 有 ≥1 TC
09 示例请求/响应/错误齐全
10 索引与约束齐全
03 Phase 1 与 05 P0 范围一致
mumu-spec-sync — 变更联动
什么时候用:已有 14 篇文档,改了其中某一篇的某个章节,需要知道哪些其它文档要同步更新。
常见联动:
你改了 | 需要同步 |
|---|---|
05 用户故事 | 09 → 13 → 14 |
09 API 接口 | 10 → 05 AC → 13 TC → 14 |
10 数据模型 | 09 → 13 → 14 |
03 范围 | 04 → 05 → 下游全套 |
mumu-spec-tasks — 任务拆分
输入 → 输出:
输入 | 输出 |
|---|---|
05 | Sprint Backlog 任务清单 |
09 | 依赖关系图 |
10 | 排期建议 |
拆分原则:每条 P0 US 拆 3-5 个 Task,每个可独立测试。
mumu-spec-check — 质量检查
检查维度:完整性、一致性、追溯性、质量规则。
输出:P0(必须修复)/ P1(建议修复)/ 通过项 分级报告。
mumu-spec-status — 版本状态看板
展示内容:每篇文档版本和状态、变更追踪、健康度统计。
使用流程图
完整流程(新项目):
/mumu-spec-init ← 创建 14 篇骨架
↓
/mumu-spec-r1-proposal ← 给会议纪要 → 生成 02/03/04
↓
/mumu-spec-r2-align ← 给需求列表 → 生成 05 和 09 并互校准
↓
/mumu-spec-r3-design ← 基于对齐结果 → 生成 08/10/06/07/11
↓
/mumu-spec-r4-finalize ← 完整文档 → 生成 12/13/14 + 终检
↓
/mumu-spec-check ← 全面质量检查
↓
/mumu-spec-tasks ← 拆分开发任务日常维护:
改某篇文档 → /mumu-spec-sync ← 联动更新其它文档
日常检查 → /mumu-spec-check ← 输出健康度报告
看状态 → /mumu-spec-status ← 版本状态看板与 OpenSpec 的关系
你可能听说过 https://github.com/open-spec/open-spec。MumuSpec 和 OpenSpec 不是替代关系,而是互补关系:
能力 | OpenSpec | MumuSpec |
|---|---|---|
变更管理 | propose | 变更记录表 |
正文写作 | 不自动写 14 篇 | AI 生成 + 跨文档一致性 |
版本历史 | Git + manifest | 文档内版本号 + 变更追踪 |
追溯矩阵 | 需要手动 | R4 自动生成 14 |
质量检查 | 无内置检查 | mumu-spec-check |
如果项目启用了 OpenSpec,MumuSpec 的 Skills 会把它当作"变更壳"——变更流由 OpenSpec 管理,但合并后的结果仍以 MumuSpec/*.md为准。
适合谁?
- 独立开发者:不用写 14 篇,但至少跑 R1+R2 明确范围
- 小团队(3-5 人):R1→R4 完整走一遍,对齐前后端认知
- 大团队:用 mumu-spec-status做看板,mumu-spec-check做巡检
- AI Coding 重度用户:把写好的 Spec 喂给 coding agent,质量远高于口述需求
快速开始
- 1. 把 .qoder/skills/目录复制到你的项目根目录
- 2. 运行 /mumu-spec-init,输入模块编号和名称
- 3. 运行 /mumu-spec-r1-proposal,粘贴你的会议纪要或需求描述
- 4. 跟着 AI 的提示走 R2 → R3 → R4
《企业级AI Coding成熟度模型》PDF已开源至GitHub
https://github.com/lvzhaobo/mumu-coding/
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号