本体+AI大模型驱动的电商数据分析报告生成详细设计和核心算法

本体+AI大模型驱动的电商数据分析报告生成详细设计和核心算法

人月聊IT
发布于 2026-05-20 21:10:44
发布于 2026-05-20 21:10:44
大家好,我是人月聊IT,今天继续分析本体驱动的电商数据分析报告生成项目详细设计文档。该详细设计基于已经完成的完整可运行的源代码项目逆向生成。
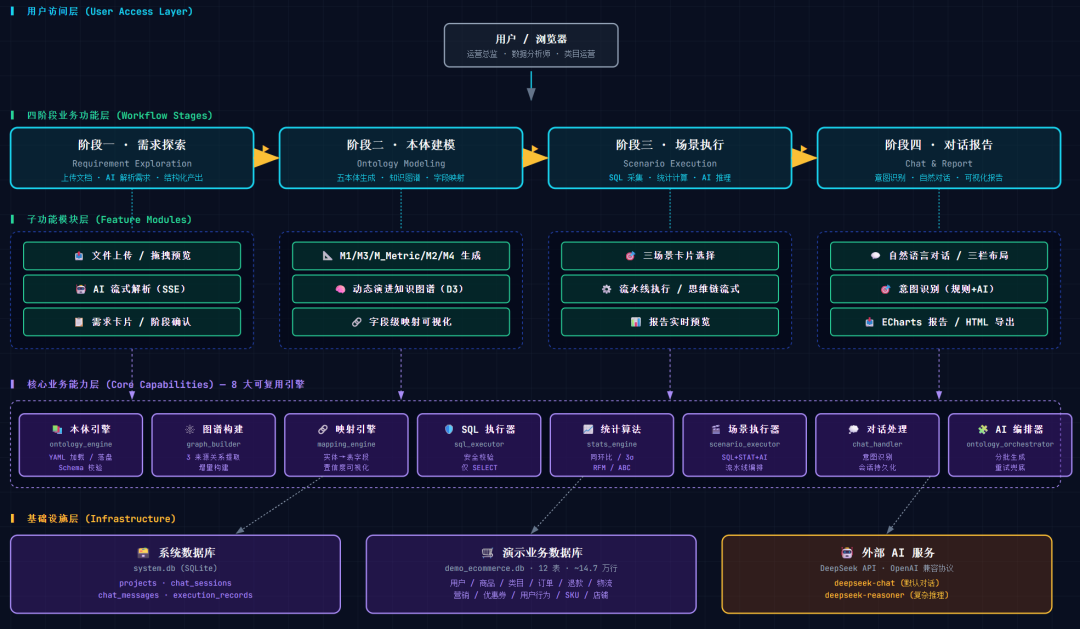
具体内容如下:
一、项目概述
1.1 项目背景
随着电商业务规模扩大,数据分析需求日趋复杂多变。传统 BI 工具依赖人工编写 SQL 和报表模板,开发周期长、维护成本高;而直接让大语言模型基于数据库生成 SQL,又常因模型对业务语义理解不足而产生错误推断或编造数字。
本项目借鉴 Palantir 的本体(Ontology)架构思路,提出**"以本体模型作为数据库与 AI 之间的业务语义中间层"**的解决方案。AI 不再直接面对裸数据库,而是先理解业务实体、规则、指标的语义定义,再去采集数据、推理结论、输出报告。整个过程零侵入既有系统,仅通过外部语义映射层完成数据接入。
1.2 业务场景
系统面向中型 B2C 电商平台的经营数据分析,覆盖五大业务域:交易(订单、支付、退款、物流)、商品(SPU、SKU、类目)、用户(注册用户、行为日志)、店铺(商家、库存)、营销(活动、优惠券、广告)。典型用户角色是平台运营总监、类目运营、数据分析师等,他们关心 GMV 趋势、用户流失风险、商品健康度、营销 ROI 等核心议题。
1.3 核心价值
系统以"演示系统"形态完整落地,作为本体驱动方法论的可运行参考实现:用户上传业务需求和数据库 Schema,系统自动产出本体模型并映射到真实数据库,最后通过自然语言对话即可获得带置信度的可视化分析报告。全程真实调用大模型 API,不提供任何 Mock 降级,所有数据、SQL、推理过程对用户透明可溯源。
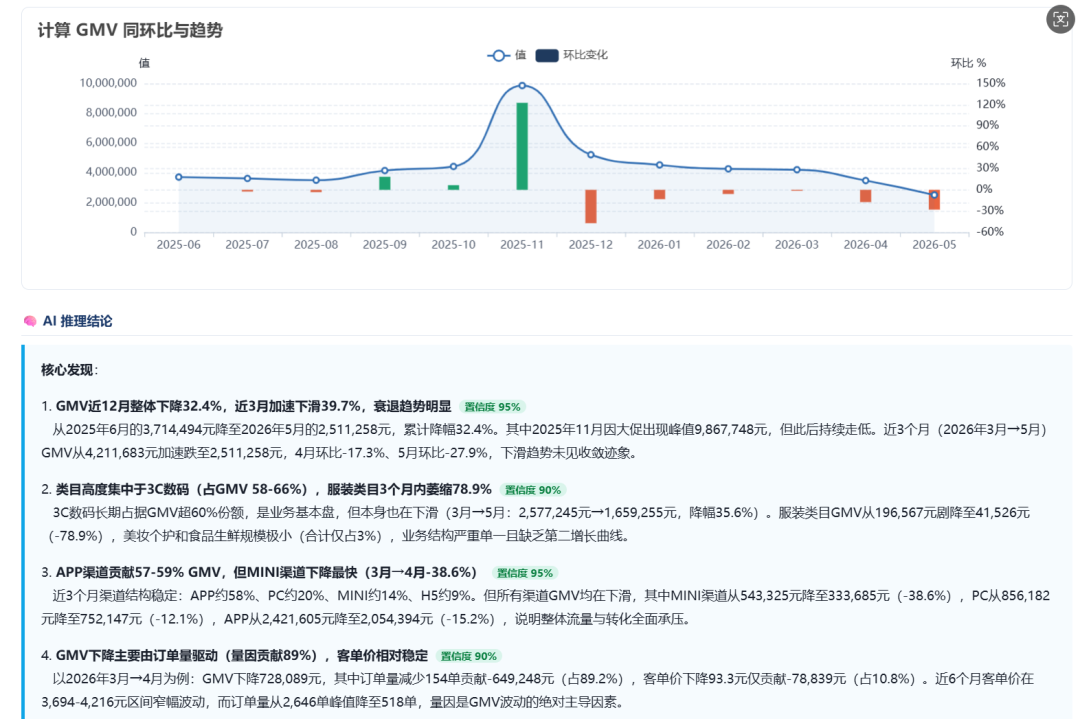
二、需求分析
2.1 核心业务需求
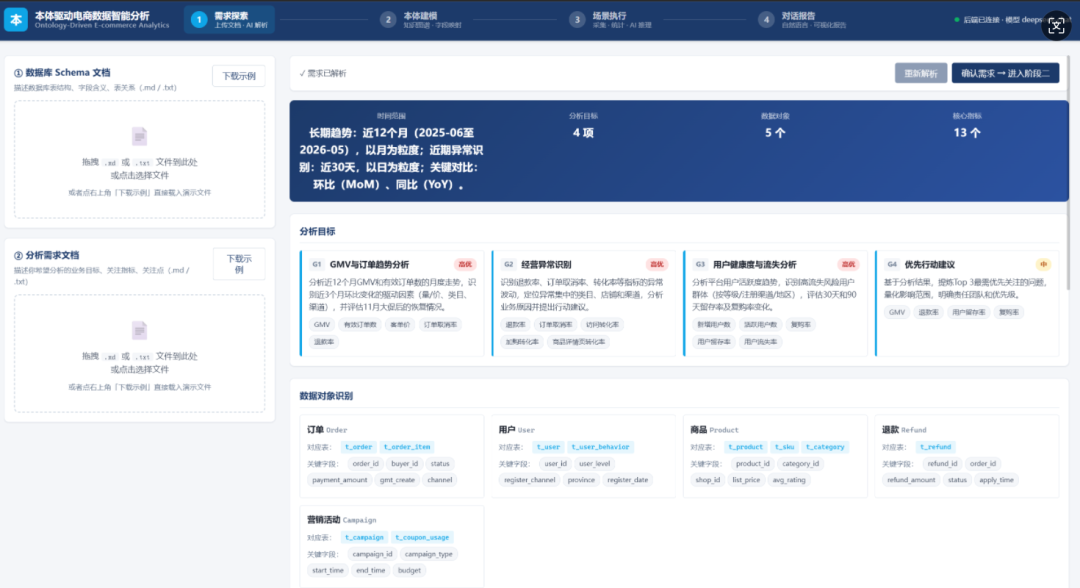
系统将完整的数据分析能力拆分为四个递进阶段,对应一个标准的"语义建模 - 数据接入 - 分析执行 - 自然语言交互"工作流:
阶段一:需求探索。用户上传两份 Markdown 文档——一份描述目标数据库的表结构,另一份描述需要分析的业务问题。AI 解析后输出结构化需求文档,包含分析目标列表(带优先级)、识别出的业务数据对象、核心指标清单、需要进一步澄清的问题等。
阶段二:本体模型构建。AI 基于阶段一的需求和上传的数据库 Schema,按预设的本体建模规范生成五个 YAML 文件:M1 对象模型、M2 行为模型、M3 规则模型、M4 场景模型、M_Metric 指标模型。模型生成过程中知识图谱在前端动态演进,节点随生成步骤逐步出现;同时生成"实体—数据库表"的字段级映射配置。
阶段三:预设场景执行。系统内置三个分析场景(经营异常分析、GMV 分析、客户流失分析)。用户选择场景后,系统按 SQL 采集→统计计算→AI 推理→报告组装的流水线逐步执行,所有步骤实时流式呈现。SQL 由 AI 基于本体映射动态生成,失败时切换到场景预配置的兜底 SQL。
阶段四:自然语言对话。用户用自然语言描述分析需求,系统通过关键词命中 + AI 兜底完成意图识别,路由到匹配的预设场景执行,最终输出咨询公司风格的完整可视化报告,包含执行摘要、核心指标卡片、ECharts 图表、AI 推理结论、行动建议、数据溯源等模块。
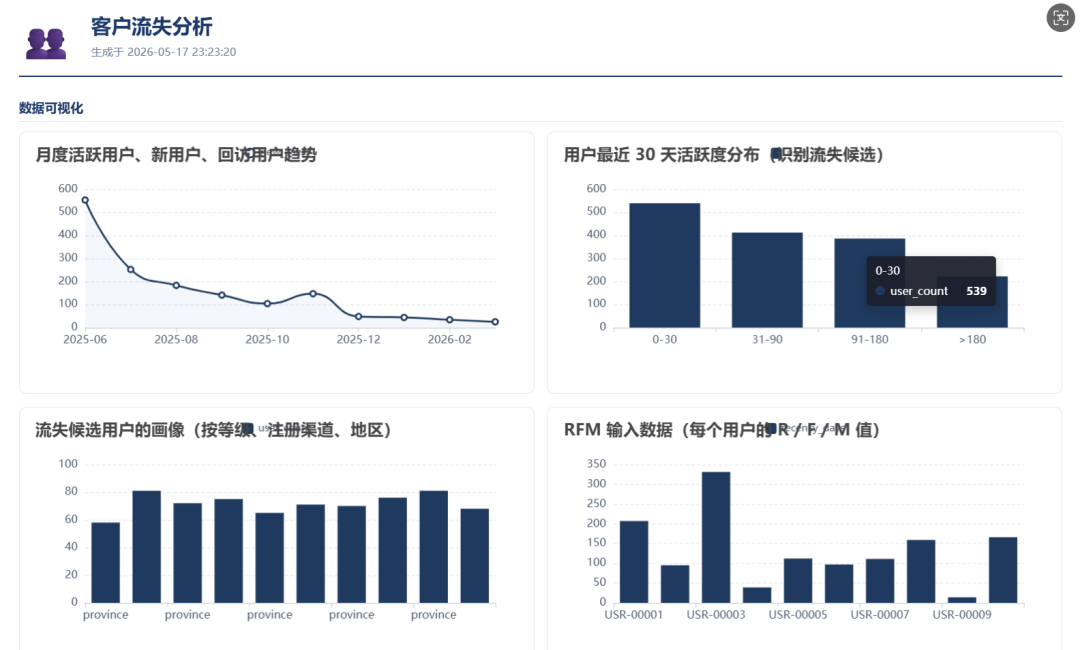
2.2 关键约束
系统作为演示项目有几项明确约束:无登录无权限控制,全平台单一默认项目;不提供 Mock 降级,API 不可用时显式报错,保证演示真实性;SQL 安全严格,仅允许 SELECT 语句、禁用所有 DDL/DML、强制 LIMIT;数据可重复,演示数据用固定随机种子生成,每次运行结果一致;报告风格定位,参考麦肯锡/BCG/德勤等国际咨询公司的视觉规范,深海军蓝主色调、麦肯锡蓝色系图表、留白克制。
2.3 数据特征预设
为让分析有意义,演示数据库预置了 5 个明显的业务特征:2025 年 11 月有大促峰值(GMV 是平均月份的 2.4 倍);最近 3 个月 GMV 加速下滑(4 月环比 -17.4%);服装类目在最近 2 个月发生结构性衰退(销量从月度第 1 跌至最后);约 73% 用户最近 30 天无购买行为(流失材料丰富);2025 年 12 月服装类目退款率从 3% 异常飙升至 14.6%。这些特征让 AI 推理有具体的洞察对象。
三、总体架构
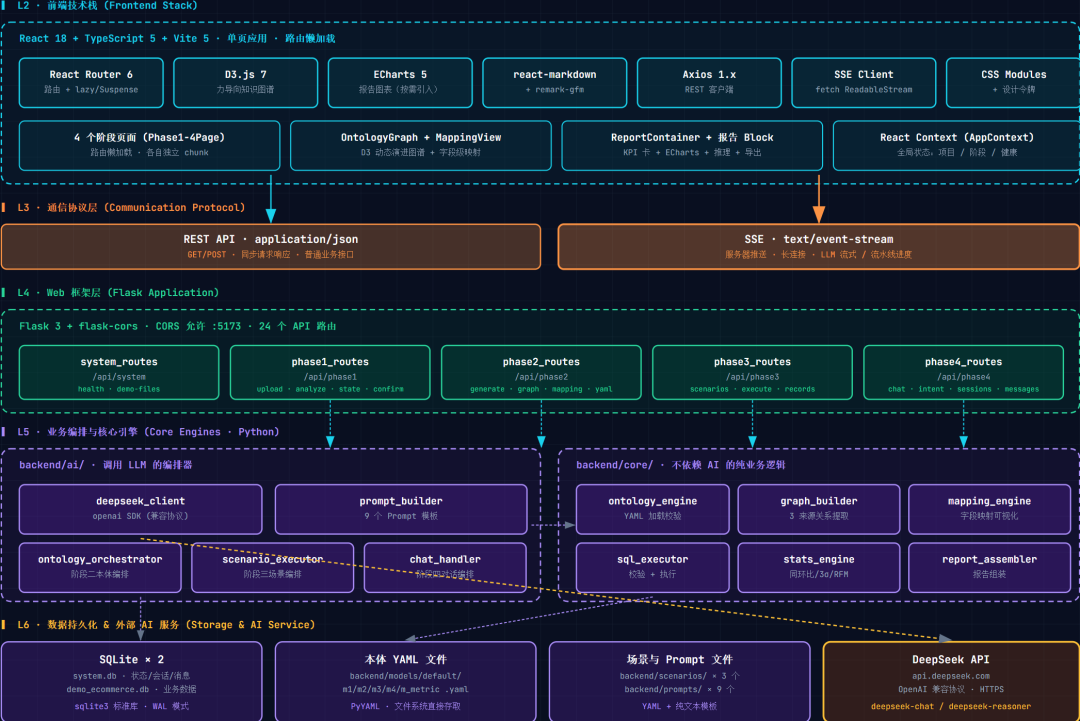
3.1 分层架构
系统采用经典的前后端分离架构,共分四层:
用户交互层(前端):React + TypeScript 单页应用,按四个阶段拆分页面,路由级懒加载。D3.js 渲染动态知识图谱,ECharts 渲染数据可视化报告,react-markdown 渲染富文本,全部使用 SSE 客户端消费流式接口。
应用接入层(后端 API):Flask 提供 24 个 RESTful 接口,按系统接口和四个阶段拆分为 5 个 Blueprint。流式接口统一用 Server-Sent Events(text/event-stream),CORS 配置允许前端开发服务器访问。
业务编排层(核心引擎):包含本体引擎、图谱构建器、映射引擎、SQL 执行器、统计算法引擎、场景执行器、对话处理器、AI 编排器等核心模块。这一层不直接面向 HTTP 请求,而是被 API 层调用,负责把 AI 调用、数据库访问、文件读写、状态机推进编排到一起。
数据持久化层:两个 SQLite 数据库——系统库存储项目状态、对话会话、消息、执行记录;演示电商业务库存储 12 张业务表共约 15 万行模拟数据。本体 YAML 文件直接落盘到文件系统的 backend/models/{project_id}/ 目录。
3.2 核心数据流

一次完整的分析流程数据流大致如下:用户上传文档→Flask 接口落库;前端触发 AI 解析→Flask 调用 DeepSeek 流式接口→SSE 转发到前端;阶段二生成本体→AI 编排器按 M1→M3→M_Metric→M2→M4 顺序逐个生成 YAML→每个 YAML 经 Schema 校验通过后落盘→图谱构建器实时增量构建节点和边→SSE 推送到前端 D3 force simulation;阶段三场景执行→场景执行器读 YAML 配置→对每个 SQL 步骤先让 AI 生成 SQL→安全校验→在演示库执行→统计算法处理结果→所有数据汇总后交给 LLM 做业务推理→XML 标签解析得到结论/建议/图表→报告组装;阶段四对话→意图识别→复用阶段三场景执行器→最终报告持久化到消息表。
3.3 模块划分
后端代码组织成八个 Python 包:api 是 Flask 蓝图入口;core 是不依赖 AI 的纯业务逻辑(本体、图谱、映射、SQL、统计、报告组装);ai 是所有调用 LLM 的编排器和 prompt 构建器;db 是数据库连接和演示数据生成脚本;config 加载环境变量和 YAML 配置;utils 是 SSE、SQL 安全校验、YAML 解析等工具函数;prompts 目录存放 9 个 AI prompt 模板;scenarios 目录存放 3 个场景 YAML 配置;models 目录是本体 YAML 落盘位置。
前端按"页面 + 组件 + API + 类型"四类组织:pages/ 是四个阶段页面;components/ 按用途分为 phase1/2/3/4(各阶段专属组件)、report/(报告渲染 Block)、shared/(跨阶段共享,如 MarkdownRenderer、YamlViewer、EChartsWrapper、ConfidenceBadge)、layout/(顶部进度条、主布局);api/ 封装 Axios 实例和 SSE 客户端;types/ 是 TypeScript 类型定义。
3.4 技术选型考量
后端选 Flask 是因为路由简单、SSE 支持简洁、依赖少;选 SQLite 是因为零配置、单文件易迁移、对演示场景足够;用 openai 官方 SDK 调用 DeepSeek 是因为 DeepSeek 提供 OpenAI 兼容接口,未来替换 GPT / Claude 只需改环境变量。前端用 Vite 而非 CRA 是因为冷启动快、HMR 性能好;用 D3.js 而非 ECharts 渲染知识图谱是因为 D3 的 force simulation 对动态增量节点支持更灵活;用 ECharts 渲染数据图表是因为图表种类丰富、咨询公司风格主题易配置。整个前端不引入大型 UI 框架(Antd / MUI),所有样式自写 CSS Modules,保持深度可定制。
四、数据库设计
4.1 系统数据库(system.db)
系统库存储应用状态,共四张表。projects 表记录项目元信息和各阶段产物:当前所处阶段、上传的 DB Schema 原文、需求原文、AI 解析后的结构化需求 JSON、本体模型摘要 JSON、映射配置 JSON。本系统永远只有一条记录 id='default'。chat_sessions 表管理对话会话,每个会话有标题和时间戳。chat_messages 表存储用户和助手的每条消息,助手消息可以是普通文本或完整报告(含 report_data 和 reasoning_data 两个 JSON 字段)。execution_records 表记录每次场景执行的详情,包括各步骤数据和最终报告。
4.2 演示电商业务数据库(demo_ecommerce.db)
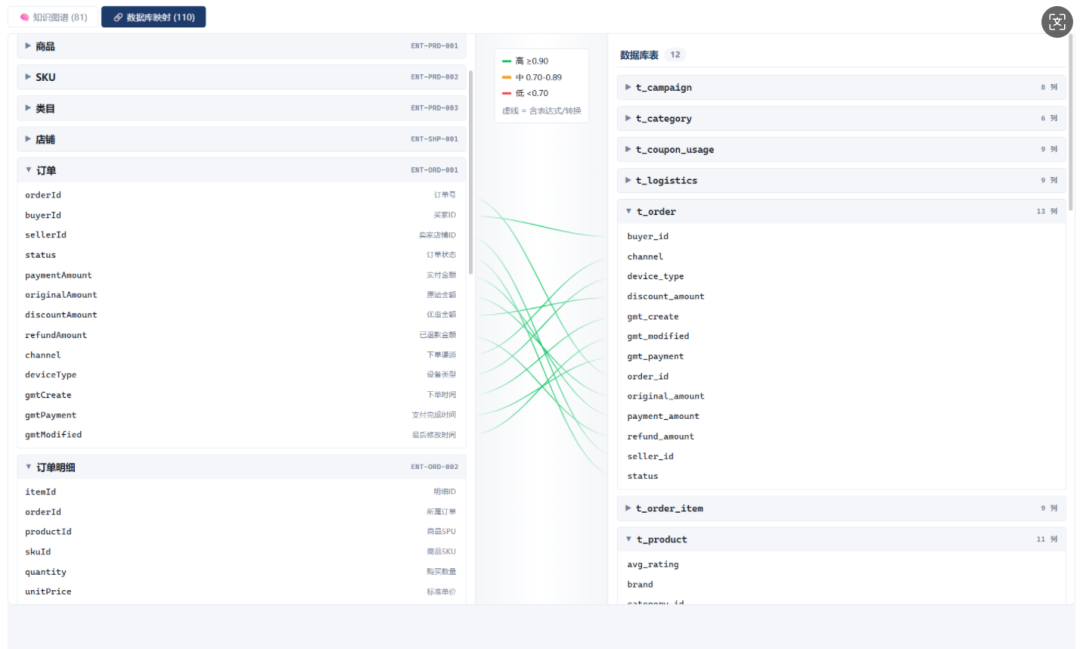
业务库共 12 张表,按业务域划分。用户域两张:t_user 主表(2000 行,含等级、注册渠道、地区等画像字段)、t_user_behavior 行为表(80000 行,含浏览/搜索/加购/收藏/分享五种行为)。商品域三张:t_product 商品 SPU(500 行)、t_sku 商品最小可售单元(1500 行)、t_category 三级类目树(30 行,5 个一级 + 15 个二级 + 10 个三级,ID 沿用层级前缀如 CAT-001-01-01 便于递归查询)。店铺域一张:t_shop(50 行,含店铺评级、主营类目、保证金)。交易域四张:t_order 订单主表(约 15000 行,含 6 种状态、4 个下单渠道、4 类设备)、t_order_item 订单明细(约 21000 行,含冗余 category_id 便于直接按类目聚合)、t_logistics 物流记录(约 13700 行)、t_refund 退款记录(约 480 行)。营销域两张:t_campaign 活动主表(30 行,含大促/折扣/秒杀/拼团/满减五种类型)、t_coupon_usage 优惠券领用使用记录(5000 行)。
所有时间字段统一为 Asia/Shanghai 本地时间的 ISO 8601 字符串格式,不带时区后缀,避免 SQLite strftime 函数因时区解释产生月份漂移。订单状态用整数枚举(1 待付款 / 2 已付款 / 3 已发货 / 4 已签收 / 5 已取消 / 6 退款完成),有效订单定义为 status NOT IN (5, 6)。退款率以"统计周期内的退款笔数 / 有效订单数"计算,与文档中的业务规则一致。
4.3 演示数据生成机制
数据生成脚本 generate_demo_data.py 用 random.seed(42) 固定随机种子保证可重复。生成顺序:类目 → 店铺 → 商品 → SKU → 用户 → 营销活动 → 订单(按月分布,每月订单数和类目权重按预设特征控制) → 订单明细 → 物流 → 退款(服装类目 12 月退款率 15%、其他 3%)→ 用户行为。Flask 启动时通过 bootstrap.ensure_demo_db() 检测演示库是否存在,不存在或文件过小则自动调用生成脚本,约 30-60 秒完成。
五、核心模块详细设计
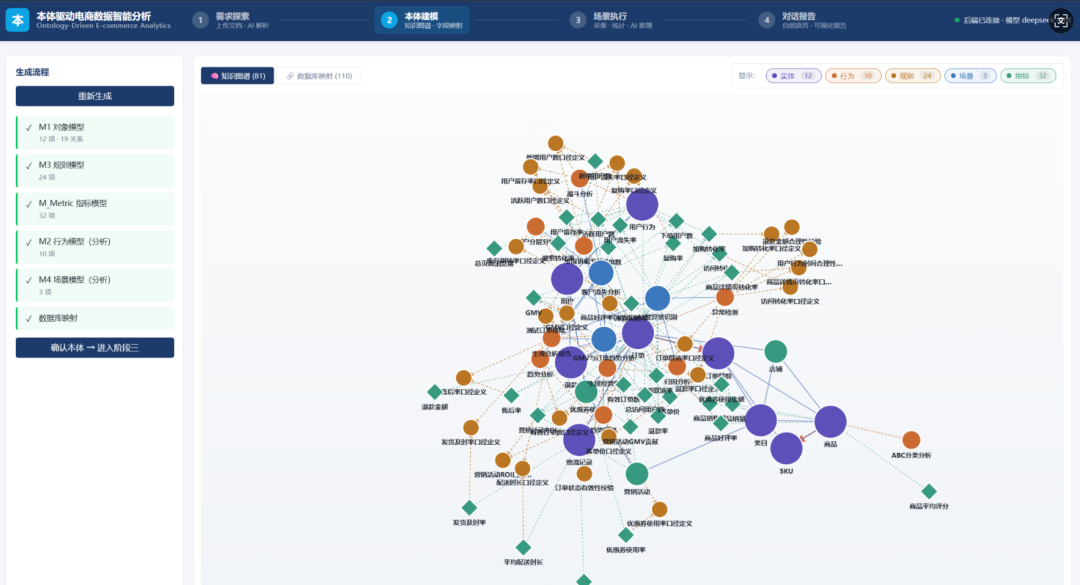
5.1 本体引擎(ontology_engine.py)
本体引擎负责五个 YAML 模型的加载、保存和 Schema 校验。每个模型对应文件名和根集合字段都通过常量映射定义,如 M1 对应 m1_object_model.yaml 和 entities 列表,M_Metric 对应 m_metric_model.yaml 和 metrics 列表。校验函数 validate_model_yaml(model_key, text) 做四件事:调用 PyYAML 解析、检查 model_type 字段值是否匹配预期(OBJECT/BEHAVIOR/RULE/SCENARIO/METRIC)、检查根集合非空、按模型类型做最小完整性校验(如 M1 要求每个实体有 id/name/attributes,M_Metric 要求每个指标有 id/name/computation_type)。校验失败抛出 ValidationError,AI 编排器据此触发重试。
5.2 知识图谱构建器(graph_builder.py)
图谱构建器有两个核心函数:build_graph(models) 全量构建,build_graph_delta(model_key, data, existing_ids) 增量构建(供 SSE 流式推送使用)。它从五个模型中提取节点(实体/行为/规则/场景/指标)和边(组合/聚合/关联/依赖/规则引用/指标依赖/场景调用/行为调用),自动去重,并为每种类型分配视觉属性(半径、颜色、形状)。关键算法是从 M1 提取关系的三重来源机制,详见第七章算法部分。
5.3 映射引擎(mapping_engine.py)
映射引擎管理"本体实体 → 数据库表/字段"的映射配置。save_mapping 同时把 JSON 写到磁盘的 YAML 文件和系统库的 mapping_data 字段;load_mapping 从系统库读回。validate_mapping 校验结构:必须有 entity_mappings 列表、每个实体至少有一个主表、每个字段映射有 ontology_field/db_column/confidence。最重要的是 build_mapping_visualization,把映射配置转换为前端可视化友好的三层结构(实体侧字段列表、表侧列列表、字段级连线列表),其中连线带置信度对应的颜色:≥0.90 绿色、0.70-0.89 橙色、<0.70 红色。
5.4 SQL 执行器(sql_executor.py)
SQL 执行器包装 SQLite 调用,封装 SqlExecutionResult 包含 SQL 文本、列名、行数据、耗时毫秒、错误信息。execute_sql 入口先调用 validate_and_prepare_sql 做安全校验:只允许 SELECT 或 WITH 开头、用正则边界匹配禁用 INSERT/UPDATE/DELETE/DROP/CREATE/ALTER 等关键字(避免误伤 created_at 这类字段名)、禁止分号多语句、未指定 LIMIT 则自动追加 LIMIT 10000。校验通过后执行查询,所有异常被捕获并以 error 字段返回,调用方不会因 SQL 错误而崩溃。
5.5 统计算法引擎(stats_engine.py)
实现四个常用统计算法:mom_yoy 计算时序的同环比(按 12 个时序点取同比,相邻取环比,并给出 up/down/flat 趋势判定);anomaly_3sigma 用 3σ 法则识别异常点,返回均值、标准差、上下阈值、异常列表;rfm_score 把用户按最近购买距离(R)、购买频次(F)、消费金额(M)三维做 5 分位评分,并按高低组合映射到 8 个用户分群(重要价值客户/重要发展客户等);abc_classification 按累计占比把项目分为 A(≤80%)、B(80-95%)、C(>95%)三类。统一通过 run_algorithm(name, rows, **kwargs) 调度入口供场景执行器调用。
5.6 场景执行器(scenario_executor.py)

场景执行器是阶段三的核心编排器,按 YAML 中定义的步骤顺序逐步执行。每个步骤的执行结果会保存到字典中,后续步骤可以通过 input_step 引用前面步骤的输出。SQL 步骤优先调用 LLM 动态生成 SQL(基于本体映射 + sql_intent 描述),失败重试 2 次仍失败则切换到 YAML 中预配置的 fallback_sql。STAT 步骤调用 stats_engine 的算法处理上一步 SQL 的结果。AI_REASONING 步骤把所有上游步骤的数据(精简到前 30 行)+ 本体语义上下文(涉及的实体/指标/规则定义)+ 任务描述塞进 prompt,让 LLM 流式输出 XML 标签格式的思维链/结论/建议/图表配置,最终解析合成完整报告。
5.7 AI 本体编排器(ontology_orchestrator.py)
阶段二的核心编排器。按 M1→M3→M_Metric→M2→M4 的依赖顺序逐个生成模型——这个顺序确保后续模型可以引用前序模型的 ID(如 M_Metric 引用 M1 实体、M2 引用 M_Metric 指标和 M3 规则)。每个模型生成流程:构造 prompt(包含本体规范 + DB Schema + 解析后的需求 + 前序模型摘要)→ 流式调用 DeepSeek → Schema 校验 → 失败带错误提示重试至多 2 次 → 校验通过则落盘 + 推送图谱增量。映射生成采用分批模式:把 M1 实体按 3 个一批切分,每批独立调用 LLM,输出量控制在 5-7K 字符以内,避开 DeepSeek 单次 8192 token 输出上限导致的截断。
5.8 对话处理器(chat_handler.py)
阶段四的入口编排器。意图识别采用"关键词命中优先 + AI 兜底"两级策略:先用场景 YAML 中的 triggers 列表对用户输入做关键词匹配,命中两个以上加分,置信度 ≥80 则直接判定;不达标时调用 LLM 做语义判断(输出严格 JSON 含 scenario_id/confidence/matched_keywords/reasoning/alternatives)。意图明确后直接复用 scenario_executor 执行场景,整个 SSE 流原样转发给前端,同时旁路解析关键事件(intent / report_ready / ai_complete)用于最后把消息和报告落库。
六、关键接口设计
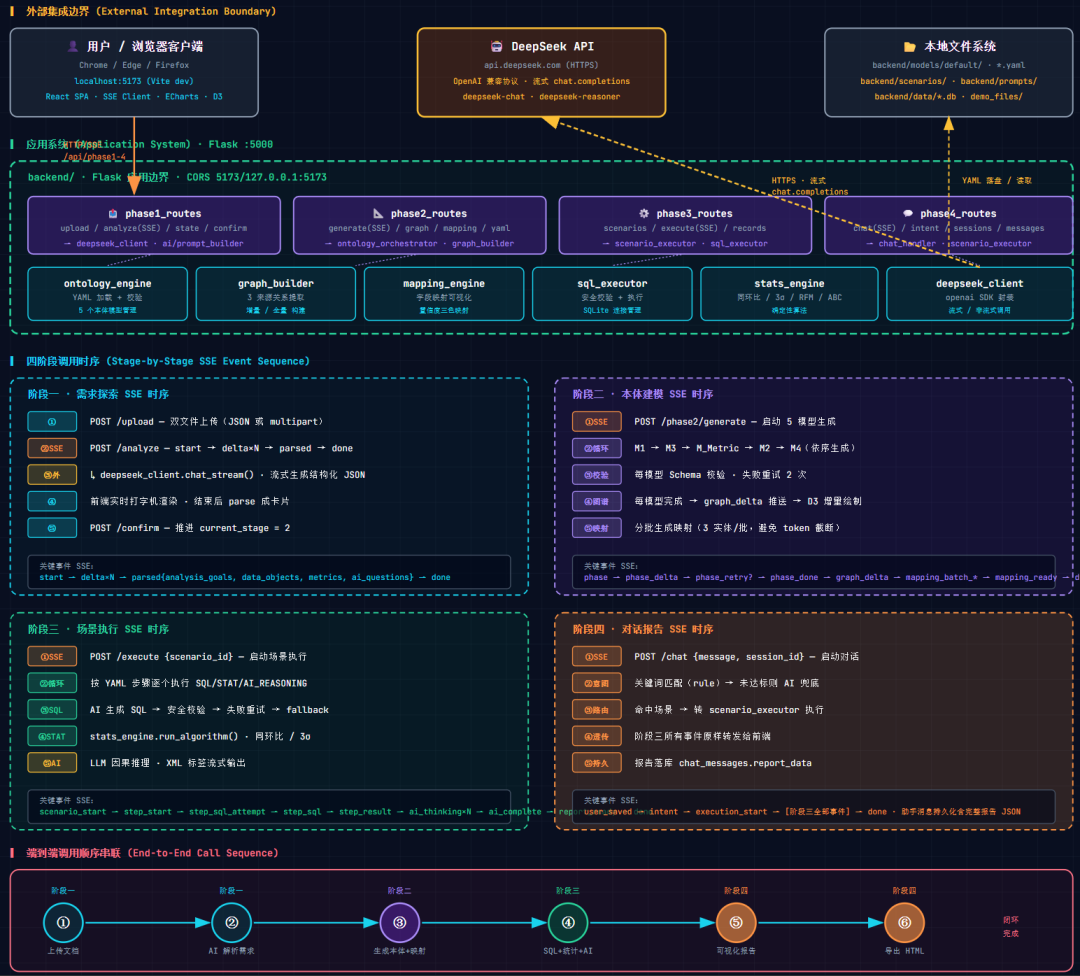
6.1 通用规范
所有 REST 接口走 /api/ 前缀,返回统一的 {success, data, message} JSON 结构。流式接口走 SSE 协议(text/event-stream),每条消息是一行 data: {...JSON...} 加双换行。前端用基于 fetch ReadableStream 的自定义 SSE 客户端消费,比 EventSource 更灵活(支持 POST 请求体)。CORS 配置允许 http://localhost:5173 和 127.0.0.1:5173 访问,便于本地开发。
6.2 四阶段接口列表
阶段一接口:POST /api/phase1/upload(multipart 或 JSON 双模式接受两份文档)、POST /api/phase1/analyze(SSE 流式 AI 解析)、GET /api/phase1/state(获取当前阶段状态用于恢复)、POST /api/phase1/confirm(推进阶段位)。
阶段二接口:POST /api/phase2/generate(SSE 流式生成 5 个 YAML + 映射)、GET /api/phase2/graph(一次性获取全部图谱节点和边)、GET /api/phase2/mapping(获取字段级映射可视化数据)、GET /api/phase2/yaml/<model_key>(获取指定模型的 YAML 原文)、GET /api/phase2/state、POST /api/phase2/confirm。
阶段三接口:GET /api/phase3/scenarios(场景列表)、GET /api/phase3/scenarios/<id>(场景详情)、POST /api/phase3/execute(SSE 流式执行场景)、GET /api/phase3/records(执行历史)、GET /api/phase3/records/<id>(单次执行详情)、POST /api/phase3/confirm。
阶段四接口:POST /api/phase4/chat(SSE 流式对话)、POST /api/phase4/intent(单纯做意图识别,前端实时回显用)、GET /api/phase4/sessions、GET /api/phase4/messages/<session_id>、GET /api/phase4/scenarios。
系统接口:GET /api/system/health(健康检查,含 DeepSeek 配置状态和模型名)、GET /api/system/demo-files(演示文件列表)、GET /api/system/demo-files/<filename>(下载演示文件)。
6.3 SSE 事件类型
阶段二 SSE 主要事件:phase(模型开始生成)、phase_delta(流式片段)、phase_retry(Schema 校验失败重试)、phase_done(单模型完成)、graph_delta(图谱节点和边增量)、mapping_plan/mapping_batch_start/mapping_batch_done/mapping_batch_failed(映射分批进度)、mapping_ready、error、done。阶段三 SSE 事件:scenario_start、step_start、step_sql_attempt、step_sql、step_result、ai_thinking、ai_complete、step_done、step_error、report_ready、done。
七、核心算法实现
7.1 知识图谱关系完整性算法
LLM 生成的本体 YAML 中,实体间关系可能不完整——AI 可能只在 relations 列表里写了部分关系,遗漏了实体属性中通过 type: Reference 隐式声明的关联。为了保证图谱不缺边,构建器从三个来源提取关系并去重合并:
def _add_relations(m1, edges, edge_keys, node_ids):
# 来源 1:显式 relations 列表
for rel in m1.get("relations", []):
src, tgt = rel.get("sourceEntity"), rel.get("targetEntity")
if src in node_ids and tgt in node_ids:
rtype = _REL_TYPE_NORMALIZE.get(str(rel.get("type", "")).upper(), "association")
_add_edge(edges, edge_keys, src, tgt, rtype, ...)
# 来源 2:属性中的 Reference 类型字段(兜底,避免遗漏)
for ent in m1.get("entities", []):
for attr in ent.get("attributes") or []:
if attr.get("type") == "Reference":
tgt = attr.get("refEntity")
if tgt in node_ids:
_add_edge(edges, edge_keys, ent["id"], tgt, "association", ...)
# 来源 3:constraints 中的 FOREIGN_KEY 类型
for ent in m1.get("entities", []):
for c in ent.get("constraints") or []:
if str(c.get("constraintType", "")).upper() == "FOREIGN_KEY":
# 表达式形如 "buyerId REFERENCES ENT-USR-001"
for token in c.get("expression", "").replace(",", " ").split():
if token in node_ids and token != ent["id"]:
_add_edge(edges, edge_keys, ent["id"], token, "dependency", "FK")
_add_edge 内部用 (source, target, type) 三元组作为去重键,重复添加自动忽略。这套机制实测有效——即使 LLM 在 relations 中只写了一两条核心关系,最终图谱仍能包含 15-25 条连线,保证可视化效果。
7.2 SQL 动态生成 + Fallback 兜底
阶段三每个 SQL 步骤的执行流程:先让 LLM 基于本体映射摘要 + 任务描述 + DB Schema 生成 SQL → 安全校验通过则试运行 → 试运行返回非空结果则采纳;任何环节失败带错误提示重试至多 2 次;全部失败时回退到场景 YAML 中预先验证过的 fallback_sql。整个过程的事件流推送到前端,让用户清楚看到"AI 生成成功"或"已切换到兜底 SQL"。
这个机制平衡了"AI 真实推理生成"和"演示稳定性"两个目标:常规情况下 AI 能正确生成 SQL(实测 12 个 SQL 步骤一次成功率约 95%),偶尔生成错误时也不会让整个演示流程中断。前端流水线明确标识 SQL 来源(橙色 AI 标签 / 紫色 Fallback 标签),透明可信。
7.3 本体映射分批生成(避免 LLM 截断)
最初设计时映射生成是一次性把 M1 全部 12 个实体喂给 LLM 让它输出完整映射 JSON,但实测发现单次输出长达约 31K 字符时被 DeepSeek 的 8192 token 上限截断,{} 括号不平衡导致 JSON 解析失败。
修复方案改为分批生成:
MAPPING_BATCH_SIZE = 3 # 每批 3 个实体,单次输出 ~5-7K 字符
def _generate_mapping(db_schema, prior_models):
entities = prior_models["M1"].get("entities", [])
batches = [entities[i:i+MAPPING_BATCH_SIZE]
for i in range(0, len(entities), MAPPING_BATCH_SIZE)]
all_mappings = []
for batch_idx, batch in enumerate(batches):
# 只把这一批的实体喂给 LLM
batch_yaml = dump_yaml({"entities": batch})
system = template.format(db_schema_doc=db_schema, entities_yaml=batch_yaml)
# 单批重试 2 次,含括号平衡快速检测
for attempt in range(MAX_RETRIES + 1):
full_text = run_llm_streaming(system)
ifnot _is_balanced_json_brackets(full_text):
continue # 输出被截断,重试
parsed = _try_parse_json(full_text)
if parsed and parsed.get("entity_mappings"):
all_mappings.extend(parsed["entity_mappings"])
break
# 单批失败则跳过该批,不阻塞其他批次
final_mapping = {"entity_mappings": all_mappings, ...}
mapping_engine.save_mapping(final_mapping)
辅助函数 _is_balanced_json_brackets 做快速预检:遍历字符串、忽略字符串内的内容(处理转义和引号状态机)、统计 {} 和 [] 是否平衡,若不平衡说明输出被截断,避免走漫长的 JSON 解析过程才发现问题。
分批后单批输出 ~5-7K 字符远低于 token 上限,且每批独立失败不阻塞其他批次,整体稳定性大幅提升。实测 12 实体 4 批生成 0 重试 0 跳过,共映射 110 个字段全部高置信度。
7.4 AI 推理输出的 XML 标签解析
阶段三阶段四的业务推理需要从 LLM 自然语言输出中提取结构化结果。直接让 LLM 输出 JSON 风险较大(JSON 字符串里含换行、引号易出错),改用 XML 标签包裹更鲁棒。Prompt 明确要求输出四个标签:<thinking> 思维链、<conclusion> 结论(带 [置信度: XX%] 内联标注)、<recommendations> 行动建议(P0/P1/P2 + 责任团队 + 预期效果)、<charts> 图表配置 JSON 数组。
解析函数用四个正则把对应内容截出,置信度用 置信度[::]?\s*(\d+)\s*% 正则全文匹配统计平均值。<charts> 内容尝试 JSON 解析得到结构化图表配置数组。若所有标签都没匹配到(LLM 没按格式输出),降级把全文塞入 conclusion 字段保证至少能展示给用户。这种"先严格、后降级"的策略实测 LLM 遵循率约 95%,少数不遵循也不会失败。
7.5 D3 力导向图的动态节点添加
阶段二知识图谱需要"节点随生成过程动态出现"的效果。D3 force simulation 提供了 simulation.nodes(newNodes) 重新设置节点数组的能力,但新节点的初始位置需要小心处理——直接随机分布会导致首次 tick 时节点飞向画面边缘。
解决方案:新节点初始化时给一个画布中心附近的随机位置(center ± random(0~80px)),同时 vx=vy=0;调用 simulation.alpha(0.5).restart() 让模拟从中等温度重新展开;新节点元素用 D3 transition 配合 easeBackOut 缓动函数做 380ms 的 scale 0→1 入场动画;最近添加的节点额外渲染一个 1.6 秒后淡出的天蓝色高亮 ring 标识"刚加入"。这套组合让图谱演进既视觉平滑又能清晰看到新节点。
边的处理类似:新边初始 opacity=0,transition 300ms 渐显到 0.85,让连线"画"出来的感觉。整个 simulation 用 alphaDecay=0.03 慢衰减保证布局有足够时间收敛,velocityDecay=0.42 适度阻尼避免抖动过度。
八、本体模型规范要点
本项目本体规范裁剪自《Ontology-Driven Software Modeling Framework v1.0》,仅保留 M1 / M2 / M3 / M4 / M_Metric 五个模型,去掉了 ME 事件模型、M5 主体模型、M6 异常补偿模型、M7 质量约束模型(演示系统不需要)。
M1 对象模型定义业务实体和实体间的关联关系。实体包含 id(如 ENT-ORD-001)、name(中文名)、alias(英文标识)、domain(业务域)、lifecycle(生命周期状态)、attributes(属性列表)、constraints(参照完整性约束)。关系采用 OWL ObjectProperty 风格,支持组合(COMPOSITION,红色实线粗 2px)/聚合(AGGREGATION,橙色实线 1.5px)/关联(ASSOCIATION,蓝色实线 1px)/依赖(DEPENDENCY,灰色虚线 1px)四种类型。属性的 type: Reference 字段会被图谱算法自动识别为关联边。
M2 行为模型——本项目特别约定 M2 建模的是数据分析行为(如生成经营概览、趋势分析、归因分析),而非传统的电商业务行为(下单、支付)。每个行为有 computationType(SQL_COMPUTE / STAT_ALGO / LLM_REASONING)、relatedMetrics(依赖的指标)、appliedRules(引用的规则)等字段。
M3 规则模型包含两类规则:业务口径规则(如 RULE-MTR-001 定义 GMV 口径为 status NOT IN (5,6) 的订单 payment_amount 累加并扣减退款)和数据质量规则(如 RULE-DQ-001 排除测试订单)。
M4 场景模型同样调整为分析场景(经营异常分析 / GMV 分析 / 客户流失分析)而非业务流程,每个场景定义 actors、relatedBehaviors、keyMetrics、primaryFlow(DATA_COLLECT / STAT_COMPUTE / AI_REASONING / REPORT_ASSEMBLE 步骤序列)。
M_Metric 指标模型是本规范的扩展维度,专门描述分析指标。每个指标定义如下结构:
- id:MTR-TXN-001
name:GMV
alias:gmv
description:成交总额(含退款扣减后的实际收入)
formula_description:SUM(payment_amount)WHEREstatusNOTIN(5,6)MINUSSUM(refund_amount)
computation_type:SQL_COMPUTE # SQL_COMPUTE / STAT_ALGO / LLM_REASONING
depends_on_entities:[ENT-ORD-001,ENT-ORD-004]
rule_refs:[RULE-MTR-001]
supported_grains:[DAY,WEEK,MONTH,QUARTER,YEAR]
supported_dimensions:[shop,category,channel,region]
default_visualization:line
unit:"元"
指标按业务域划分为 TXN(交易)/ TFC(流量)/ USR(用户)/ PRD(商品)/ MKT(营销)/ SCM(供应链)六大类。每个 SQL_COMPUTE 类型的指标可以可选地携带 sql_template(含 {date_format} / {date_start} / {date_end} 等占位符),用于后续 SQL 生成时的参考。
九、前端架构
9.1 组件分层与状态管理
前端不引入 Redux 等重型状态管理库,而是用 React Context 做全局状态(仅保存项目 ID、当前阶段、API 健康状态),各阶段页面内部用 useState 管理局部状态。这样既避免了状态分散到无关组件,又保持轻量。
四个阶段页面(Phase1/2/3/4Page)通过 React Router 6 路由,使用 React.lazy 做代码分割——每个页面单独成 chunk,按需加载。配合 Vite 的 manualChunks 配置把第三方库(react/echarts/d3/markdown)分别打包,使首屏只需加载 react + 主框架共约 213 KB(gzip 73 KB),其他按需。
9.2 SSE 客户端封装
SSE 是整个前后端通信的核心,但浏览器原生 EventSource 只支持 GET 请求,无法传递大体积 JSON 请求体。自定义 sseClient.ts 基于 fetch ReadableStream 实现:发起 POST 请求并标记 Accept: text/event-stream,拿到 response 后用 ReadableStream + TextDecoder 流式读取,按 \n 分行解析 data: 前缀的 JSON 消息,分别触发 onMessage / onError / onDone 回调。支持传入 AbortController 实现中途取消。
9.3 D3 与 React 集成
D3 是命令式 DOM 操作而 React 是声明式,二者集成需要小心避免冲突。OntologyGraph.tsx 的策略是用 useRef 保存 D3 simulation、selection、缩放行为等运行时状态,让 D3 完全接管 SVG 内部 DOM,React 只负责挂载/卸载组件外壳。每当 props 中的 nodes/edges 变化,组件在 useEffect 中合并新数据到 D3 状态(保留已存在节点的位置不抖动)、重新设置 simulation 的 nodes 和 links、触发 alpha 重启。这种做法既享受了 React 的组件化与状态管理,又保留了 D3 在动画和力导向布局上的强大能力。
9.4 ECharts 主题与图表构建
EChartsWrapper.tsx 按需引入 6 种 chart(line/bar/pie/scatter/heatmap)和必要 components(grid/tooltip/legend/title/dataZoom/markLine/markArea),用 CanvasRenderer 渲染,包大小相比全量引入减少 60%。全局主题用麦肯锡蓝色系(#1E3A5F / #2E6DB4 / #5BA3D9 / #A8CDF0)加对比橙绿,xAxis 隐藏轴线、yAxis 用虚线网格、tooltip 深色半透明背景,整体视觉对齐咨询公司报告风格。
chartBuilder.ts 提供三种构图器:buildEChartsOption 根据 AI 给出的 chart hint(type / x_field / y_field / series_field)+ SQL 步骤数据构造完整 option;buildMomYoyChart 把 stats 算法输出的同环比序列构造为双轴图(左轴折线显示绝对值、右轴柱状显示环比百分比、正负值用绿橙色区分);inferAutoCharts 在 AI 没指定图表配置时启发式推断(如第一列像 period 就默认折线图)。
十、关键技术要点
10.1 流式与实时反馈
整个系统所有耗时较长的 AI 调用都通过 SSE 流式呈现,避免用户面对长时间空白。流式有两个层面:一是 LLM 输出本身的 token-by-token 流(让用户看到 AI 在"打字");二是业务事件的流(如阶段二的"M1 完成 → 推送 12 个节点增量 → M3 完成 → 推送 27 条规则节点")。两者结合形成丰富的实时反馈体验,单看体感比一次性等待提升数倍。
10.2 安全与容错
SQL 安全用正则边界匹配确保关键字检查精确(避免 created_at 被误判为含 CREATE),强制 LIMIT 防止意外大查询拖垮 SQLite。所有 LLM 输出都做格式校验 + 自动重试,重试次数和兜底策略分阶段配置(YAML Schema 校验失败重试 2 次后报错;SQL 生成失败重试 2 次后切 fallback;映射生成单批失败跳过不阻塞)。LLM 调用本身用 try-except 包裹,网络异常或 API 报错时显式上报到 SSE error 事件,前端友好展示。
10.3 性能与体验细节
后端 SQL 执行均在 50ms 内(演示库小、有索引),LLM 调用每次 5-30 秒。前端代码分割让首屏快、按需加载让交互流畅。D3 force simulation 的 alpha decay 调到 0.03 让大图谱也能 2-3 秒内收敛。ECharts 图表统一用 canvas renderer(比 SVG 在大数据量下性能更优)。所有时间字段不带时区后缀避免 SQLite strftime 函数因 UTC 转换导致月份漂移。Vite 开发服务器配置 /api 代理到 5000 端口,前后端分离开发零摩擦。
十一、总结
本系统以一个完整可运行的演示项目,验证了"本体模型作为数据库与 AI 之间的业务语义中间层"这一架构思路的可行性。从用户上传需求到生成可视化分析报告的全链路,约 24 个 API 接口、近 120 个文件、几千行后端代码 + 数千行前端代码、5 份本体 YAML、3 份场景配置、9 份 AI prompt 模板共同支撑起这条流水线。整套实现严格遵循语义优先、零侵入既有系统、推理分级(确定性指标用 SQL、模式识别用统计算法、因果推理用 LLM)、结果可溯源、置信度透明这五大原则,为大模型驱动的企业数据分析场景提供了一份扎实的参考实现。

注:AI编程工具实现ClaudeCode+Opus4.7;架构作图工具:https://github.com/Cocoon-AI/architecture-diagram-generator
文档版本 1.0 | 2026 年 5 月 | 配套项目目录:ecommerce-ontology-analytics/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号