TraceML:用三行代码为训练循环加入 step 级诊断

TraceML:用三行代码为训练循环加入 step 级诊断

deephub
发布于 2026-05-25 12:23:54
发布于 2026-05-25 12:23:54
一直以来,你都能盯着 loss 曲线看;TraceML 让你看见训练循环内部的效率。
在每个训练步骤内部,时间究竟是如何在数据加载、前向、反向和优化器之间分配的,你其实并不清楚。在查看训练运行时,工程师常用的工具链大致是这样:
nvidia-smi和集群仪表盘,用于查看 GPU 利用率- W&B、MLflow 或 TensorBoard,用于查看 loss 曲线和运行历史
- PyTorch Profiler 或 Nsight Systems,用于需要深入检查的场景
这些工具都有用,但在"任务正在运行"和"打开一个重量级 profiler"之间还缺了一层:正常训练期间、step 粒度的轻量级可见性,并且只需要极少的配置。
系统监控看到的是机器;实验追踪器看到的是结果;深度 profiler 看到的是 kernel 和 timeline,前提是你已经怀疑了某个具体问题,并且愿意承担相应的开销。
但如果只是想知道,在任意一次运行中,时间是如何在训练 step 内部分配的,又该怎么办?
这正是 TraceML 提供的能力。
TraceML 集成只需少量代码改动。把训练 step 标记一次:
import traceml
traceml.init(mode="auto")
for batch in dataloader:
with traceml.trace_step(model):
optimizer.zero_grad(set_to_none=True)
outputs = model(batch["x"])
loss = criterion(outputs, batch["y"])
loss.backward()
optimizer.step()然后运行:
traceml run train.py把训练 step 标记一次,TraceML 把这个边界变成结构化的诊断信息:TraceML 利用 step 边界,把时序、内存、rank、进程和系统信号组织起来,整合成一份关于"运行把时间浪费在了哪里"的诊断。
任务运行时,TraceML 会在日志旁边打开一个实时终端视图。
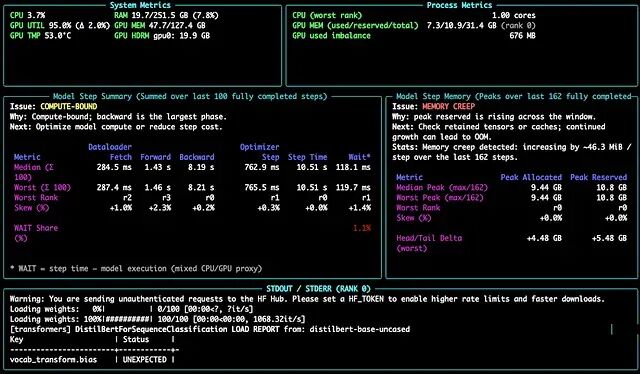
在一次 PyTorch 训练运行上的实时仪表盘。这次运行被判定为 compute-bound(计算受限),反向传播占据了 step 时间的主要部分,内存面板则提示在观察窗口内 reserved memory 持续增长。
一眼就能回答这些问题:
- dataloader fetch 是否占用了过多的 step 时间?
- 计算是不是主导部分?
- 在支持的分布式运行中,各个 rank 的表现是否存在差异?
- 内存是稳定的,还是出现了压力?
- 这次运行是否足够均衡,到不需要再做更深入 profiling 的程度?
运行结束时,TraceML 会写出 final_summary.json——结构化的 JSON,而不是一份庞大的 trace 文件。它足够小,便于存储,容易记录到日志,也方便在不同运行之间做对比。下面是一个简化后的 summary 示例:
{
"step_time": {
"diagnosis": "INPUT_BOUND",
"dataloader_pct": 47.0,
"forward_pct": 31.0,
"backward_pct": 18.0,
"optimizer_pct": 4.0
},
"step_memory": {
"diagnosis": "BALANCED"
}
}每一项诊断都直接对应到下一步该看哪里:

很多工程时间都花在了去调查那些其实并不需要调查的运行上。知道一次运行是均衡的,就意味着可以放心去做别的事情。
TraceML 没有打算取代 PyTorch Profiler 或 Nsight Systems。需要 kernel 级别的 trace、CUDA timeline 或 NCCL 行为信息时那些才是合适的工具。
他的定位是轻量化的profiler,先跑 TraceML给这次运行做分类,再决定更深入的 profiling 是否值得做、应该指向哪里。
TraceML 是 PyTorch 训练诊断中的 tool zero(零号工具)。
TraceML 最有用的部分不只是实时视图,而是 final_summary.json。
这个文件很小、结构化、容易在每个任务上收集。它可以被记录到 W&B 或 MLflow,作为 CI 工件存储,也可以与之前的运行做差异对比。TraceML 还提供了一个 compare 工作流:
traceml compare run_a.json run_b.json当一次训练性能回退出现时,问题不应该只是吞吐量是否下降了?,而应该是时间转移到哪里去了?。这正是 final_summary.json 设计要在不同运行之间收集的那种信号。
pip install traceml-ai
traceml run train.py仓库地址:https://github.com/traceopt-ai/traceml
TraceML 是开源的目前支持单 GPU 以及单节点 DDP/FSDP;多节点支持很快会推出。
如果你从事 PyTorch 训练、分布式任务或 ML 基础设施相关的工作,可以事实这个包,他能让你在打开 profiler 之前,先弄清楚自己面对的是哪一种"慢"。
作者:TraceOpt
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号