Python 自动管理内存:核心机制拆解与优化指南

Python 自动管理内存:核心机制拆解与优化指南

deephub
发布于 2026-05-25 12:24:35
发布于 2026-05-25 12:24:35
本文按层次拆解 Python 的内存系统,每一个结论都附上可以直接复制运行的示例。
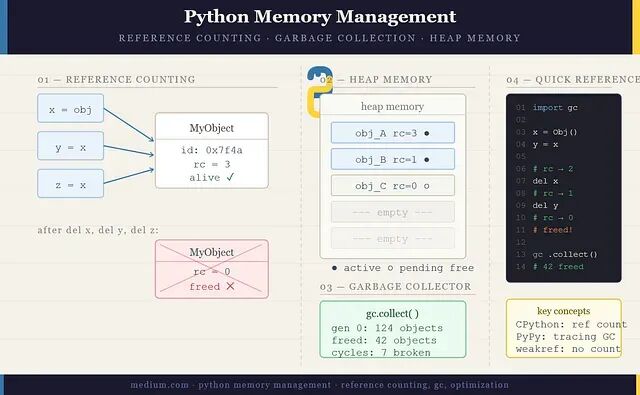
Python 如何在内存中存放对象
Python 把内存切成两块,用途差别很大。
栈(stack) 存放函数调用以及局部变量的 引用,结构是后进先出(LIFO):函数被调用时压入一个栈帧,函数返回时把这个栈帧弹出。栈访问很快,但容量有限。
堆(heap) 才是真正存放 Python 对象的地方——列表、字典、类实例、字符串都在这里。创建对象时Python 在堆上为它分配空间,并在栈上留下一个指向它的 引用(本质上就是一个指针)。
def process():
data = [1, 2, 3] # 'data' 是栈上的一个引用
# [1, 2, 3] 是堆上的真实对象这个区分之所以重要是因为 Python 从不让代码直接拿到对象本身,所有访问都经过引用这一层。后面所有机制都建立在这个事实之上。对象的内存地址和占用字节数都可以直接查看:
import sys
data = [1, 2, 3]
print(id(data)) # 堆上的内存地址
print(sys.getsizeof(data)) # 占用字节数 → 88引用计数:Python 最主要的内存工具
每个 Python 对象身上都挂着一个隐藏计数器,叫做 引用计数(reference count),它精确记录有多少变量或容器当前指向这个对象。一旦计数降为 0,Python 立即知道这个对象不再可达,并即时释放它占用的内存。
import sys
data = [1, 2, 3]
print(sys.getrefcount(data)) # → 2(一个来自 'data',一个来自 getrefcount 的参数)
copy = data
print(sys.getrefcount(data)) # → 3
del copy
print(sys.getrefcount(data)) # → 2
del data
# 引用计数归零 → [1, 2, 3] 被立即释放这就是 Python 内存管理大部分时候让人没什么感觉的原因:对象在没人需要它的那一刻就被清理掉,而不是拖到某个无法预测的时间点。当一个对象被放进另一个容器,引用计数也会同步上升:
a = [1, 2, 3]
b = [a, a, a] # 'a' 的引用计数现在是 4(1 来自 'a',3 来自 'b' 中的三个槽位)垃圾回收:补上引用计数处理不了的场景
引用计数足够快行为也可预测,但有一个关键盲点——循环引用(cyclic references)。
a = []
b = []
a.append(b) # a 引用了 b
b.append(a) # b 引用了 aa 和 b 现在引用计数都至少为 1,因为它们互相指向对方。哪怕把两个变量都删掉引用计数也永远到不了 0,内存就这样被泄漏掉了。
import gc
# 手动触发一次回收
gc.collect()
# 查看上一次回收涉及到的对象数量
print(gc.get_count()) # → (700, 10, 1),分别对应 3 代的对象数GC 采用的是 分代回收(generational collection) 策略:在多轮回收中存活下来的对象会被提升到更老的代,检查频率随之下调,这是因为大部分对象生命周期很短。
在一些性能敏感的代码段里(例如不会构造出循环结构的数据加载脚本),可以临时关掉 GC,之后再重新打开:
gc.disable()
gc.enable()
gc.collect()del 到底做了什么,没做什么
这是 Python 里最常被误解的一个点。del并不销毁对象,它做的事情是移除对该对象的一个 引用;对象本身要等到引用计数归零才会被真正释放。
a = {"user": "Alice", "score": 99}
b = a
del a # 'a' 没了,但字典还在 —— 'b' 仍然引用着它
print(b) # → {'user': 'Alice', 'score': 99} ← 还活着
del b # 引用计数 = 0 → 对象被释放不过一个有实操意义的推论:在函数里对一个变量执行 del,内存不会马上还回去,而是要等到函数返回、整个栈帧被清掉为止——除非这个变量恰好是对象的 唯一 引用。
几个内置的内存优化
Python 在常用对象上做了一些小动作这样可以降低分配成本。
整数缓存(Integer caching):Python 在解释器启动时就预先创建好了 -5 到 256 这一段整数对象。任何被赋值为这些数字的变量拿到的都是同一个对象,而不是一个新对象:
a = 100
b = 100
print(a is b) # → True(同一个对象)
x = 1000
y = 1000
print(x is y) # → False(超出缓存范围,是新建的对象)字符串驻留(String interning):看起来像合法标识符的短字符串通常会被驻留(复用),而较长或动态拼出来的字符串则不一定:
a = "hello"
b = "hello"
print(a is b) # → True(被驻留)
c = "hello world"
d = "hello world"
print(c is d) # → False(没有保证 —— 不要依赖这一点)上面的操作就引申出的一条规则:值比较请用 ==,不要用 is。驻留属于实现层面的优化,不是语言层面的承诺。
**__slots__**:默认情况下,Python 给每个实例都附带一个字典来存放属性,这本身是有开销的。当一个类需要被实例化成千上万次时,__slots__ 可以把这个字典去掉:
class RegularPoint:
def __init__(self, x, y):
self.x = x
self.y = y
class OptimizedPoint:
__slots__ = ['x', 'y']
def __init__(self, x, y):
self.x = x
self.y = y
import sys
print(sys.getsizeof(RegularPoint(1, 2))) # → 48 字节
print(sys.getsizeof(OptimizedPoint(1, 2))) # → 56 字节(包含槽位描述符的偏移)
# 真正的收益要等到实例数量上到成千上万才看得出来真实场景:处理一个 20GB 的 CSV 文件
这里引用一个实际可能遇到的案例:假设需要处理一份很大的销售导出数据。
错误写法:
with open("sales_2026.csv") as f:
data = f.readlines() # 一次性把全部 20GB 读入内存
for line in data:
process(line)Python 会同时为每一行分配堆内存。在一台 16GB 内存的机器上,这段代码会直接挂掉。
正确写法——惰性迭代:
with open("sales_2026.csv") as f:
for line in f: # 一次只读一行,内存占用近似常量
process(line)更好的写法——用生成器搭建多阶段流水线:
def read_lines(filepath):
with open(filepath) as f:
for line in f:
yield line.strip()
def filter_valid(lines):
for line in lines:
if line and not line.startswith("#"):
yield line
def parse(lines):
for line in lines:
yield line.split(",")
# 在真正去消费这条 Pipeline 之前,什么数据都不会进内存
pipeline = parse(filter_valid(read_lines("sales_2026.csv")))
for row in pipeline:
load_to_database(row)整份 20GB 的文件就这样一行行流过整条流水线,每一步的内存占用都稳定在几 KB 的级别。
总结
Python 的内存系统由三层协作完成。引用计数处理快速、常见的情况——对象在没有任何引用指向它的瞬间就被释放。垃圾回收器负责补上循环引用这个引用计数解决不了的边角场景。再加上一组内置优化(整数缓存、字符串驻留、__slots__),把高频分配对象的开销压下来。
del 移除的是一个引用;对象只有在最后一个引用消失之后才会真正消失。生成器则让大数据量的工作负载在内存上一直保持平坦。
把这一层理解透,会改变你在数据规模变大、内存预算变紧时对系统的设计方式。
by Isha Shaw
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-22,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号