别再手动写56个民族了!这个 .NET NuGet 包直接拿去用

别再手动写56个民族了!这个 .NET NuGet 包直接拿去用

云中小生
发布于 2026-05-25 12:35:33
发布于 2026-05-25 12:35:33
做后台系统、人员档案、户籍录入这类项目的时候,几乎都会碰到一个需求:民族下拉框。
56 个民族,名字要标准、编码要规范、还要支持搜索。以前我偷懒,要么直接写死一个枚举,要么从网上随便复制一份数据贴到代码里。结果过两个月需求变了:要加拼音检索、要按国标编码排序、数据库存的是“01”但前端要显示“汉族”……然后就开始漫长的 if-else 和硬编码。
后来实在不想重复造轮子了,就整理了一个小组件,把民族数据、枚举转换、模糊搜索这些事一次性封装好,于是就有了下面这个包。
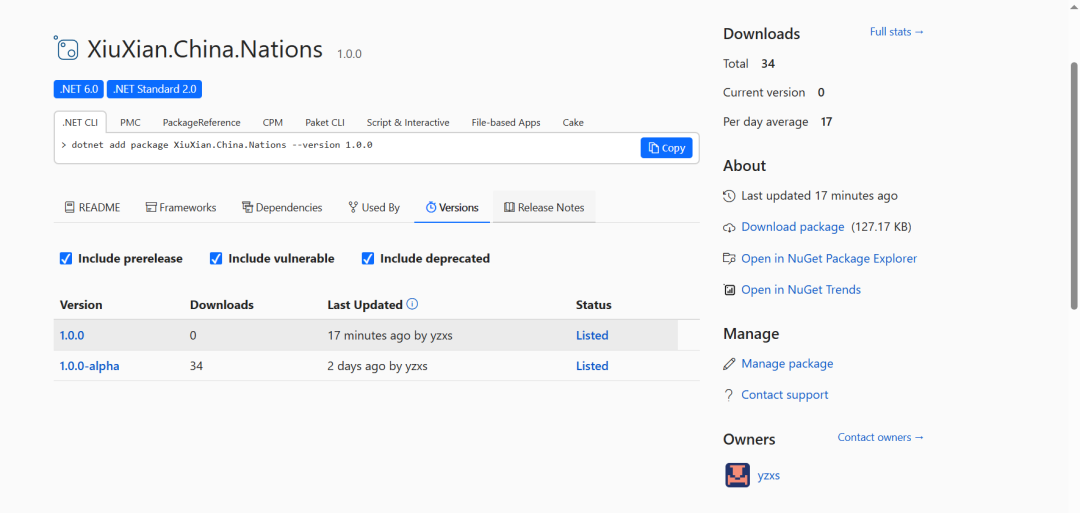
组件长什么样
其实就是一套静态方法,引入就能用,不需要建表,也不需要手动初始化。
dotnet add package XiuXian.China.Nations命名空间就一个:
using XiuXian.China.Nations.Services;最常用的几个操作
我先把日常写代码时最常用的场景列一下,基本覆盖 80% 的需求。
1. 拿全部民族列表
绑定下拉框的时候用:
var nations = NationLibrary.GetAll();
// 直接丢给 SelectList 或者前端2. 编码和民族互转
数据库存的 "01"(汉族),要显示汉字:
var nation = NationLibrary.GetByCode("01");
string name = nation?.Name; // 汉族反过来,前端选了“回族”,后端要存编码:
string code = NationLibrary.GetCodeByEnum(NationEnum.Hui);3. 模糊搜索
用户输入“蒙”、“meng”、“MG”都能搜到蒙古族相关的民族:
var result = NationLibrary.Search("蒙");这个功能在带搜索的下拉框里非常实用,不用自己写Contains或者IndexOf了。
4. 判断是不是少数民族
有时候统计口径需要区分汉族和少数民族:
if(!nation.IsHan()) {
// 少数民族单独处理
}这个数据模型是怎么设计的
内部用的 NationInfo 长这样,不复杂,但够用:
public class NationInfo
{
public string Code { get; set; } // 01-56,其他民族99
public string Name { get; set; } // 汉族、回族...
public string Pinyin { get; set; } // Han, Hui...
public string ShortCode { get; set; } // HZ, HUI 这种简写
public NationEnum EnumValue { get; set; }
}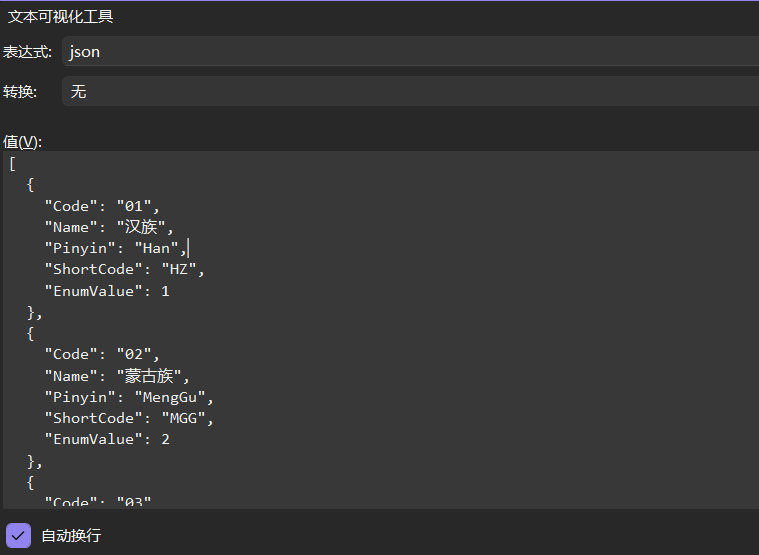
这里有一个坑要提醒一下:简码(ShortCode)是有重复的。比如不同民族可能共用同一个简码,所以按简码查会返回多条记录,业务上要自己处理。
两个排序规则
这个细节很多人会忽略。民族列表有时候要按国标编码(01 汉族、02 蒙古族…),有时候要按拼音首字母(白族、藏族、傣族…)。
组件里直接给了两种:
// 按拼音排序,适合前端展示
var list = NationLibrary.OrderByPinyin();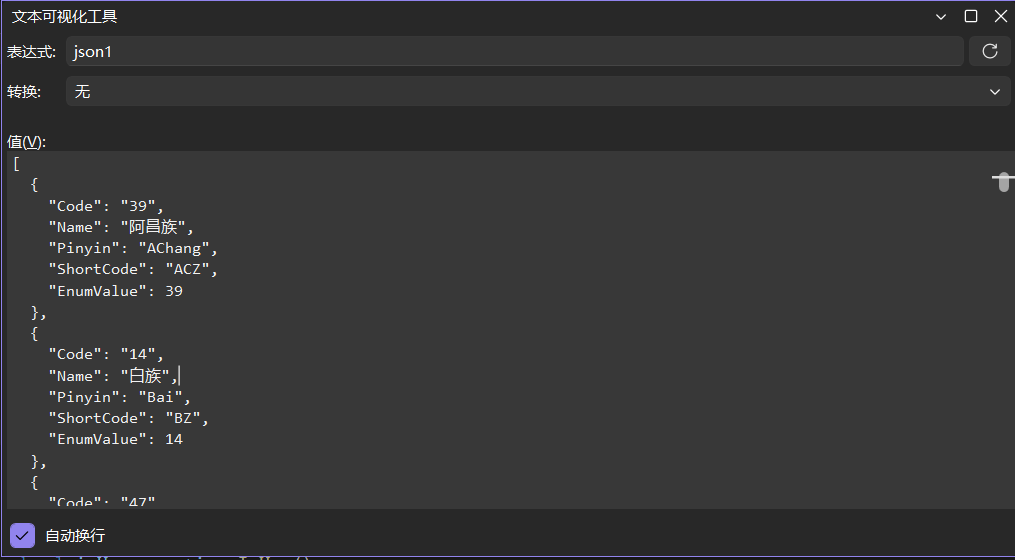
我的建议是:政府项目用编码排序,互联网项目用拼音排序。别问为什么,踩过坑的都知道。
一些不太起眼但很舒服的小设计
- 编码自动兼容:
"1"和"01"都能查到汉族,不用自己补零。 - 查不到不抛异常:返回
null或空集合,不用包一层try-catch。 - 线程安全 + 懒加载:不用手动 new,静态调用就行。
这个库适合哪些项目
- 后台管理系统的数据字典
- 人口、户籍、档案类业务
- 需要下拉框 + 搜索的民族选择组件
- 多个项目之间需要统一民族数据的场景
一点个人看法
说实话,这个组件技术含量不高,就是把国家标准数据整理成代码,再加几个常用的查询方法。但它减少的是重复劳动的烦躁感。每次新项目都要重新写一遍民族枚举、做拼音转换、处理编码对齐,真的很无聊。
如果你现在项目里民族数据还是硬编码或写在配置文件里,可以试试这个方式。至少下一个人接手代码的时候,不用再问“这个民族编码从哪来的”这种问题。
NuGet版本:
v1.0.0(netstandard2.0;netstandard2.1;net6.0;net8.0;net9.0;net10.0;)

如果有什么奇怪的需求(比如民族合并、自定义排序),可以自己继承扩展。
(点击关注,修炼不迷路👇)
▌转载请注明出处,渡人渡己
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号