DeepSeek 的 10 万亿美元大战略


来源:X @bookwormengr(436K 浏览,1K+ 点赞)
你有没有想过,DeepSeek 到底怎么赚钱?而且是赚大钱?
(在之前的文章里我好奇过:基于 DeepSeek 的编程智能体 TUI 。
“看看DS后续怎么商业化吧,感觉上大模型本身应该还是会保持开源,附加的服务或者产品收费,有点类似 Linux 系统小红帽 Redhat 模式。”
之前的推测还是格局小了,今天这篇推特作者推测的一种可能,感觉非常符合逻辑。)
他们没有像智谱、月之暗面、MiniMax 那样推出有竞争力的编程套餐。他们没有多模态模型,没有语音模型,没有视频模型。
直到今天连个 harness 都没有(最近才开始招人搭建)。
DeepSeek 长期坚持开源,还特别乐意分享自己的"秘方"。
这是疯了吗?是在烧钱吗?那些准备给他们投 100 亿美元的投资人是不是在往水沟里扔钱?
不——依我之见,恰恰相反!
在这里,我总结了他们迄今为止所取得的成就,以及他们似乎正在遵循的策略。
梁文锋(DeepSeek CEO)的眼光显然更长远:他们有望实现 1 万亿美元的估值,同时助力打造一个价值 10 万亿美元的产业!

重新审视 DeepSeek 的英雄之旅
DeepSeek 一直秉持着与主流趋势相反的路线:
不追求逐步改进模型、也不试图立即将模型转化为可用的应用产品——比如编程工具之类的。
我在 2025 年 1 月 27 日发一条广为流传的推文,讲述了在我看来 DeepSeek 所经历的“英雄之旅”。
这个故事会越来越精彩。
DeepSeek 的创新清单:
- • 当大家还在死磕密集模型时,DeepSeek 转向了训练难度更大的专家混合模型(MoE)。
- • 他们从第一性原理出发,发明了新算法 GRPO 来替代主流的 PPO 强化学习算法——后者的实现成本高得多。
- • 他们发现了基于验证奖励的强化学习(RLVR),作为提升模型推理能力的关键策略。
- • 他们通过"多令牌预测"提出了投机解码的简洁方案,这一策略同时也有助于增强训练信号的效力。
- • 他们完善了"零气泡"管道技术,最大化利用有限的 GPU 资源。
- • 他们开源了专家负载均衡器,让所有人都能轻松部署 MoE 模型。尤其是采用“广域专家并行”策略时,由于可以处理大规模的数据处理任务,因此模型的部署成本会大大降低。
- • 他们发明了 MLA、DSA、CSA、HCA等技术,持续压缩 KV 缓存需求,让计算量在上下文增长时几乎保持恒定
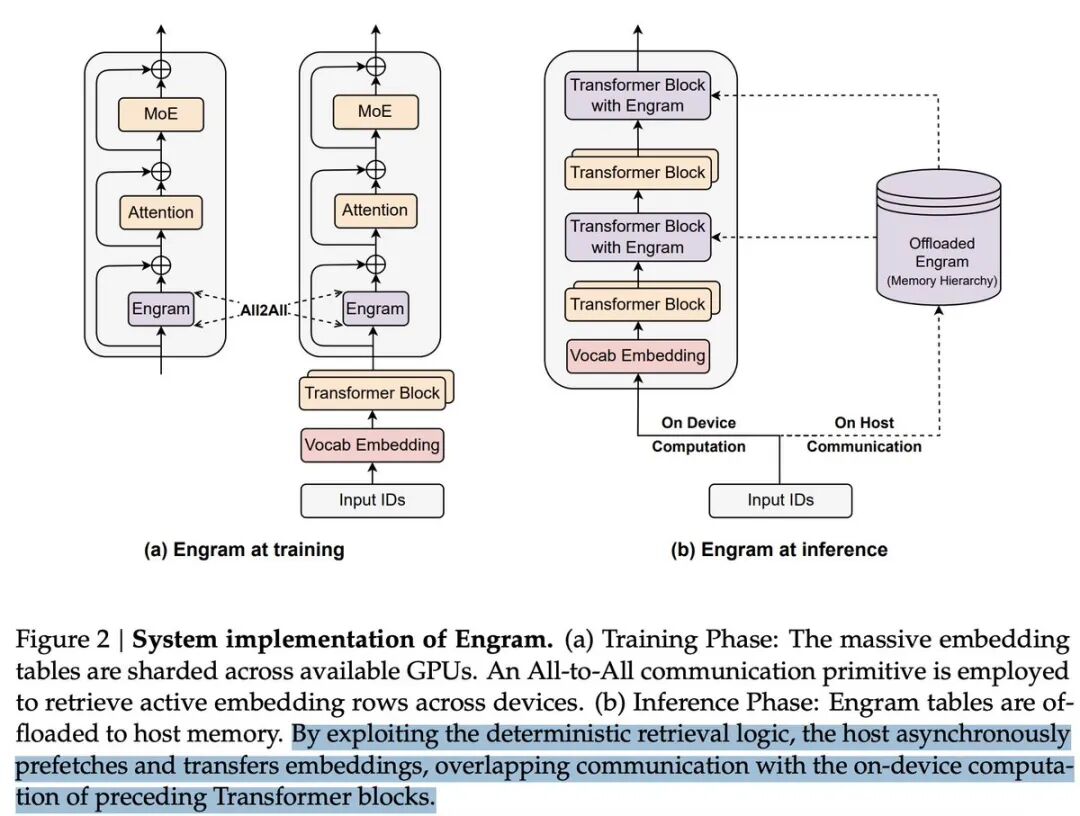
- • 他们发明了 记忆体转换器(Engram),用内存换计算能力。
- • 他们发明了 mHC,以便在模型规模不断扩大的情况下仍能保持训练的稳定性。
类似的机制还有很多....
(这些在之前讲Deepseek 论文的文章有详细说明:没人整理过的 DeepSeek 进化史:25篇论文里的技术蜕变)
在“英雄之旅”的故事中,英雄从不预设自己的道路。
他在途中不断学习,为自己确定目标,并克服一切困难去完成它。
他会遇到许多反对者,但他选择无视。
他还会遇到许多心怀不轨的人。
他自己也有缺点和不足,但他能克服这些困难来达成目标。
他面对着看似无法克服的挑战,但总能找到盟友,合理利用各种资源。
正是这些因素让大家愿意支持英雄。
这也是 DeepSeek 能够赢得粉丝、获得全球尊重的原因——当然,同时也招来了不少反对者。
DeepSeek 在这条路上已经走了足够久,并且发现了自己的终极命运:不是卖编程套餐,而是赋能一个 10 万亿美元的中国 AI 硬件生态系统,同时为自己实现 1 万亿美元的估值。
通过这种方式,DeepSeek 还将帮助许多新进入者进入西方国家的硬件生态系统。

(从这段描述看,妥妥的迷弟一个啊。)
先来点有趣的 KV 缓存计算
来看看@SemiAnalysis_发出的这条推文:

DeepSeek 已经比其他任何人都更出色地解决了这个问题!
我们用最近发布的 KV 缓存计算器来对比 DeepSeek V4 Pro、GLM5 和 Qwen3 的 KV 缓存占用。
https://kvcache.ai/tools/kv-cache-calculator/
计算条件:1M 上下文,8 位 KV 精度,16 位索引器精度。
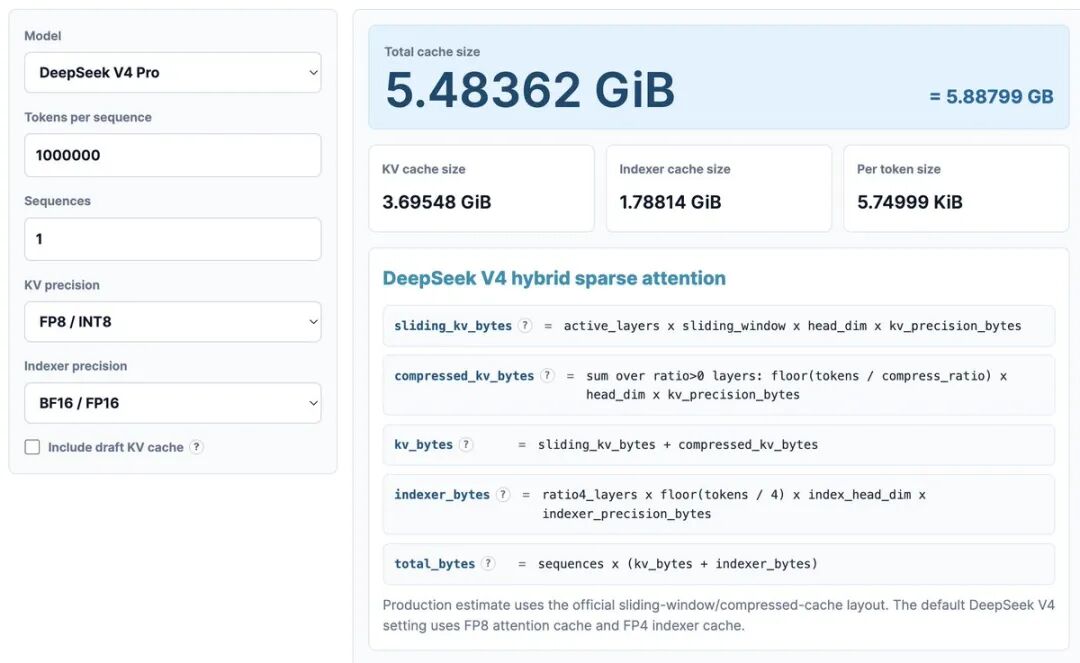
对于 1M 上下文:
模型 | 参数量 | KV 缓存占用 HBM |
|---|---|---|
DeepSeek V4 | 1.6T | 5.48GB |
GLM5 | ~700B | 60GB |
Qwen3-235B-A22B | ~235B | 89GB |
请注意:
- • DeepSeek 是 1.6 万亿参数的模型
- • GLM5 大约 7000 亿参数,已经用了 DeepSeek 的 MLA 和 DSA(但不是最新的压缩注意力)
- • Qwen3-235B-A22B 大约 2350 亿参数,使用的是 GQA 注意力
DeepSeek 在缓解内存压力方面做出了奠基性贡献。
如果被广泛采用,这一创新可以让长时程智能体变得极其经济,同时也能开启一系列新的应用场景。
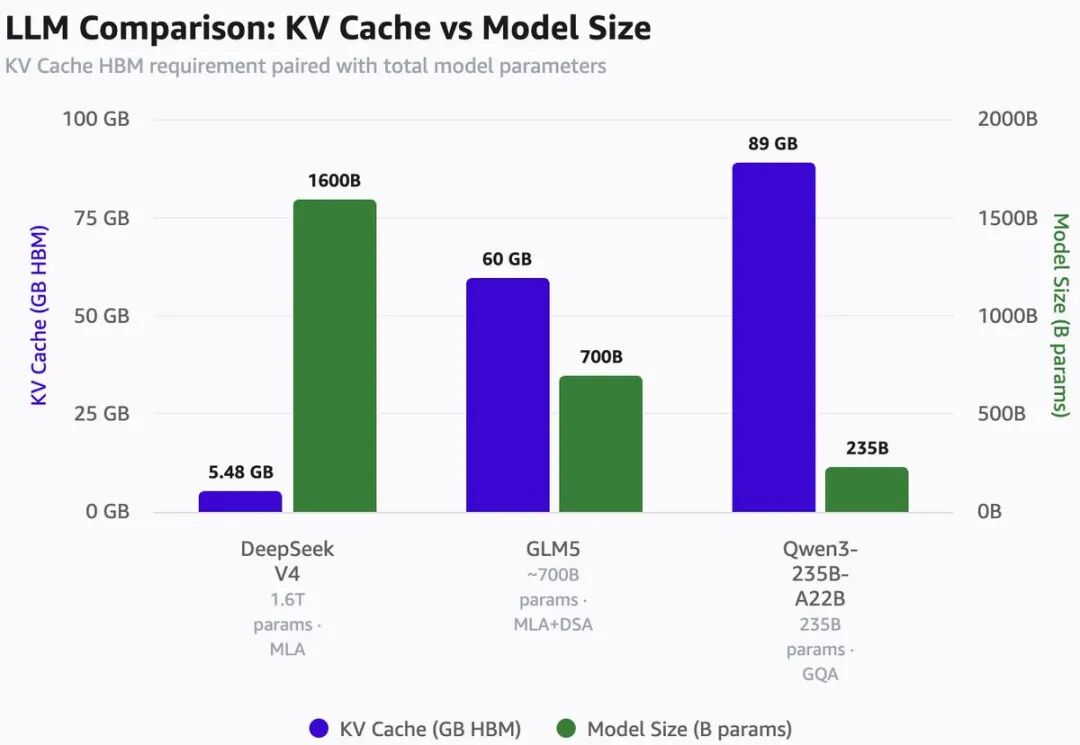
100万Token与不同模型规模对应的KV缓存占用情况对比。
疯狂背后的原理
正是这种不牺牲质量的小 KV 缓存,让他们能以极低的价格提供长时间缓存服务——不到 Sonnet 4.6 缓存命中价格的 3%,而且能保持数小时。
(因为如此,官宣deepseek-v4-pro 模型 API 价格正式调整为原定价的 1/4。看来经过20多天的实际测试,这个价格是可以长期实现的)
少量缓存 + 长时程任务 = 可以高效地卸载到 SSD 再重新加载,成本极低。
这减少了对 HBM 的需求——而从中国 AI 硬件产业的角度看,HBM 是供应最紧张、最难制造的内存。
DeepSeek 还在 Dual Path 论文中开发了从 SSD 快速加载 KV 缓存的技术。
不过,新的 DeepSeek V4 把 KV 缓存压得这么小,这招可能都不需要了。
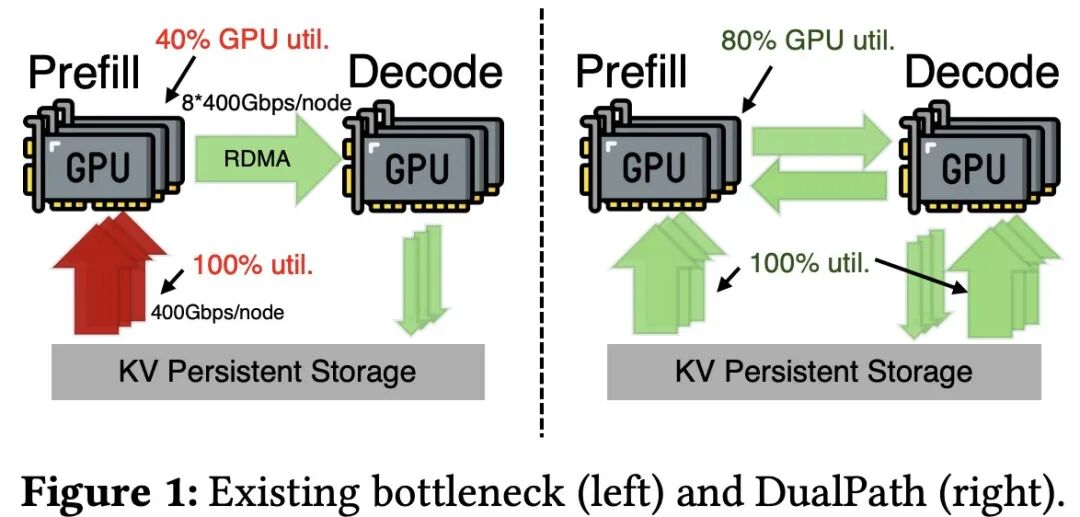
谁是KV 缓存压缩的直接受益者?
谁在大量供应固态硬盘SSD?
请记住,亿纬锂能正逐渐成为 3D NAND 领域的巨头。
NAND 技术的应用使得 DeepSeek 无需重新计算各种关键数据。
反过来,DeepSeek 又为 NAND 和固态硬盘创造了巨大的市场——不仅是亿纬锂能的产品,其他公司的产品也同样如此。

不仅仅是 NAND 和 SSD
LPDDR 内存有巨大潜力:可以存放权重,按需传输给 HBM,从而减轻 HBM 需求压力。
SGLang 团队发了一篇很棒的博客来解释这个方案。
(博客地址:https://www.lmsys.org/blog/2025-09-25-gb200-part-2/)
虽然 DeepSeek 没有专门为这一目的而进行什么特别的设计,但其基于“专家系统”架构的设计,再加上大量专家节点和 4 位精度的权重设置,使得该方案的实现变得十分容易。
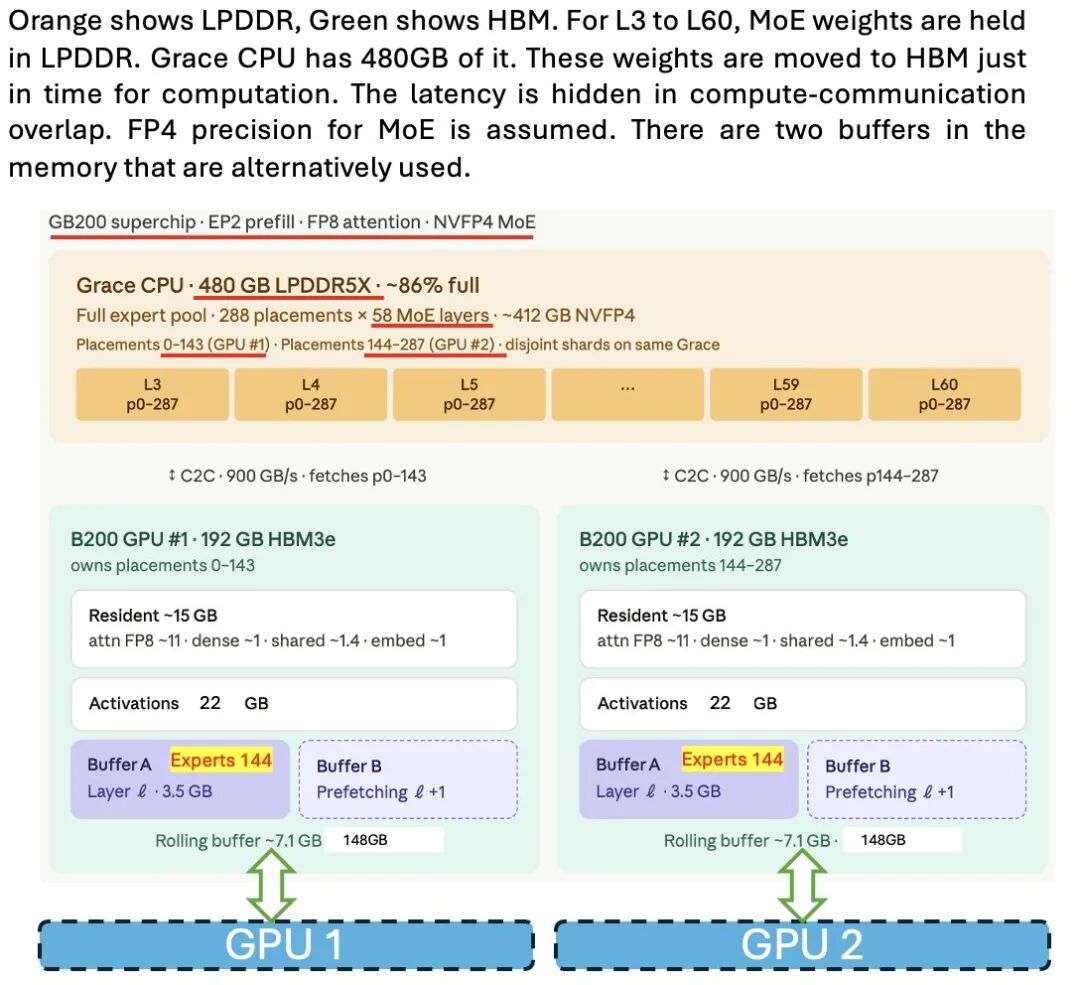
该示意图展示如何利用内存,以及如何将权重数据从LPDDR传输到HBM中。
核心思路:用 LPDDR 存权重 → 按需流入 HBM。
这一创新技术,再加上超紧凑的无损 KV 缓存,大大降低了对HBM 的需求。
在中国谁来生产 LPDDR?长鑫存储(CXMT)。
他们在速度上只落后半代,密度上则落后一代而已,差距并不大!
再加上充足的 NAND 供应,中国硬件生态很快就会有充裕的LPDDR。
这能否缓解计算领域的压力呢?当然算。继续看下去……

合理使用内存也减少了 GPU/ASIC 的压力
很明显,使用 NAND 存储器来存储键值对缓存,有助于延长缓存的有效期,从而减轻 HBM 的负担。
同时,还能避免对键值对缓存进行重新计算,进而减轻 GPU 和 ASIC 的计算压力。
那么,LPDDR 是否也能起到类似的作用呢?
此外,LPDDR 还可以作为存储权重数据的介质,实现“按需传输”数据的功能。
答案是肯定的。
LPDDR 可以存放大量的"Engram" 数据。
在相关论文中,DeepSeek 指出:虽然 MoE 通过条件计算扩展容量,但 Transformer 缺乏用于查询知识的专用机制。
因此,Transformer 不得不通过复杂的计算过程来模拟查询操作。
DeepSeek 提出了“Engram”这一机制,它将传统的 N-gram 嵌入方式升级为基于哈希表的 O(1)时间复杂度查询方式。
这样一来,就形成了一种互补的存储结构,DeepSeek 将其称为“条件记忆”。
虽然这种方式节省了计算成本,但需要足够的存储器来存储这些嵌入数据,而存储器的容量可能相当大。
这其实是一种典型的“用存储换取计算”的方式。
不过,由于每比特数据的查询成本在 LPDDR 中要低得多,因此从整体来看,这种方式的性价比非常高。
这就是他们通过牺牲存储成本来节省计算成本的方法
由于每块芯片上的晶体管密度较低(因为没有使用 EUV 技术),中国的 GPU 和 ASICS 品牌的产品的计算能力永远无法与西方品牌的 GPU 相媲美。
在封装技术方面,中国的产品也远远落后于西方品牌。
不过,这些牺牲还是值得的,尤其是当你能够大量生产 NAND 闪存和 LPDDR 内存时。
DeepSeek 的长期战略规划
从所有这些创新来看,考虑到 DeepSeek 所做出的种种选择(目前还没有多模态功能、语音模型或视频处理能力),该公司似乎无法立即获得数亿美元的利润。
不过,他们正在着眼于一个价值 10 万亿美元的长期目标,旨在推动替代性硬件生态系统的发展。
这不仅关乎让中国内存厂商成为中国和全球 AI 硬件舞台上的关键玩家,还能降低训练和运行 AI 模型所需的资源成本。
这样一来,许多 GPU/ASIC 制造商以及网络芯片制造商都将有更多的发展机会。
所有这些创新还将有助于推动西方的开源生态系统以及新兴硬件制造商的发展。
种种迹象都表明了这一点。让我们详细列举一下他们所创造的所有创新:
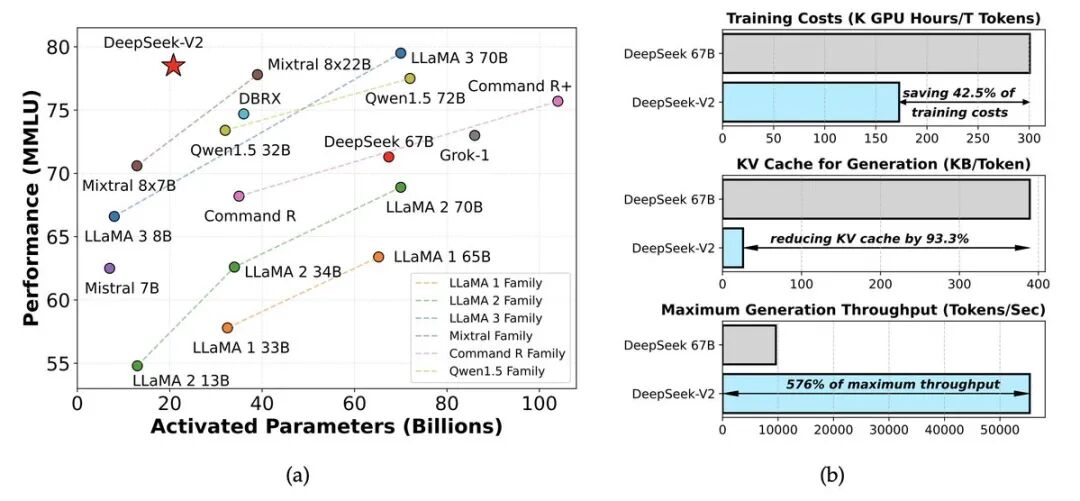
1. MoE + MLA(DeepSeek V2,2024 年 5 月)
- • MoE 让训练超级智能模型的算力需求降低了 40-50%
- • MLA 让 KV 缓存减少了 90%,卸载到 SSD 变得高效
- • 正是这些创新,让 DeepSeek V3 只用 2048 个被阉割的 H800 GPU 就训练出来了
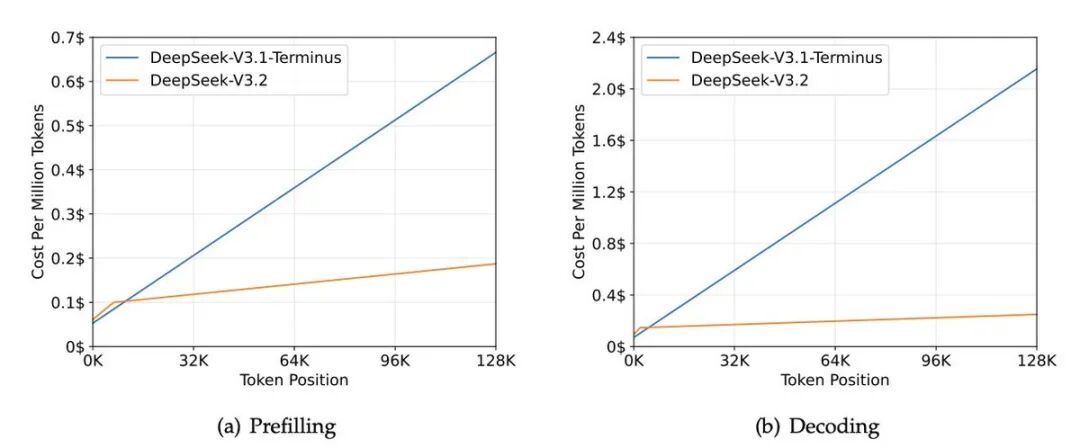
2. DSA(DeepSeek V3.2 Exp,2025 年 12 月)
- • 减少长上下文场景的计算量,缓解 HBM 带宽压力
- • 计算量不随上下文增长——DeepSeek-v3.2 的处理时间随上下文保持平坦
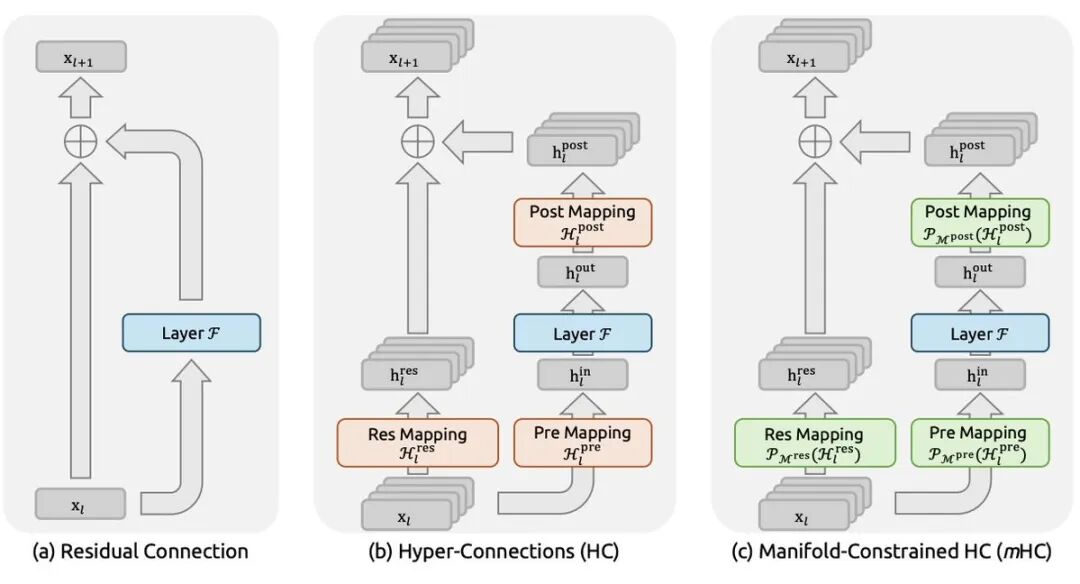
3. mHC(流形约束超连接,2025 年 12 月)
- • DeepSeek 的宏架构创新,重新发明了信息在 Transformer 层之间的流动方式
- • 将标准残差连接扩展为多条并行信息高速公路,允许学习式混合
- • 关键约束:混合矩阵为双随机矩阵,数学上保证信号幅度在任意深度上保持不变
- • 计算开销极小:仅增加 6.7% 训练时间
- • 性能提升显著:27B 参数下,BIG-Bench Hard +7.2,DROP +3.2,GSM8K +2.8,MMLU +1.4
- 本质上,mHC 通过为网络提供更复杂、更有效的信息传输拓扑结构,从而在每个参数上实现了显著更高的智能水平。而这一过程几乎不会增加额外的计算成本。
4. CSA + HSA(DeepSeek V4,2026 年 4 月)
- • 通过压缩 KV token 再减少 KV 需求 90%
- • 大幅减少所需 FLOPs,同时缓解 HBM 和 GPU/ASIC 压力
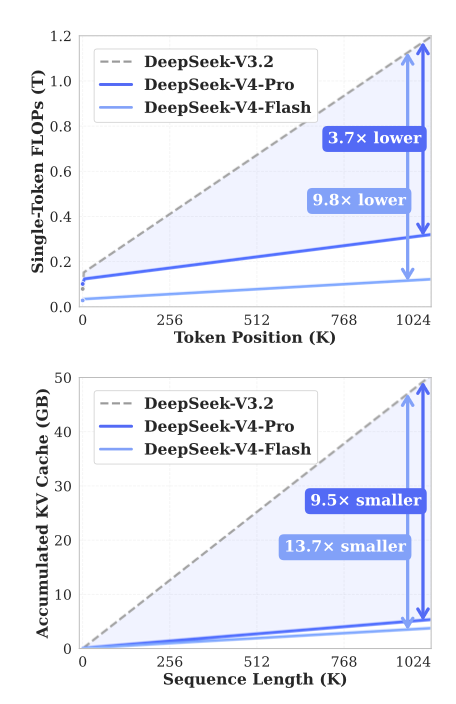
5. Engram(2026 年 Q1)
- • 用内存(LPDDR)换计算
- • 在相同参数预算下实现显著性能提升
6. 极致的计算-通信重叠 + 硬件设计建议
- • Dual Path 等创新是应对资源约束的巧妙变通
- • DeepSeek 更进一步:在 DeepSeek V4 论文中直接给硬件厂商提 ASIC 设计建议

7. 投资 TileLang——打破 CUDA 护城河
- • 目标不仅是解决自己的计算瓶颈,更是让中国硬件生态与西方竞争
- • TileLang 让内核代码一次编写,多硬件平台运行
- • 预计所有中国实验室都会加入,间接帮助中国硬件厂商应对"CUDA 护城河"

更多详细的介绍也可以看之间的文章:没人整理过的 DeepSeek 进化史:25篇论文里的技术蜕变
大规模强化学习与相对强弱指数
由于有更多硬件选项可供选择,计算能力得到了提升,同时计算需求又有所下降。
因此,DeepSeek 能够处理更复杂的训练任务,尤其是强化学习中的后训练阶段。
强化学习需要生成大量的训练数据——也就是数万亿个标记。
这样的处理过程会迅速变得非常昂贵。
此外,要训练出能够处理 100 万上下文规模的模型,就需要生成同样数量的训练数据。
通过训练能够处理如此大量数据的模型,就能实现需要较长处理时间的任务。
此外,由于选项的增加,DeepSeek 拥有更多的硬件资源,这有助于实现自动化研究。
自动化研究指的是让人工智能自行设计和执行各种实验。
不过,这种方法需要大量的试验和调整,成本也可能迅速上升。
不过,为了探索所有的设计可能性,自动化研究是非常重要的。
在实现通用人工智能和超级人工智能之前,DeepSeek 必须具备进行自动化研究的能力。
DeepSeek 今天所做的事情,其他公司明天也会去做:
DeepSeek 在“专家混合模型”、“MLA”和“DSA”方面的创新成果,已被世界各地以及中国的其他人工智能研究机构所采纳。
例如,GLM 系列模型的开发者 ZAI 就采用了 MLA 和 DSA 算法。
Kimi(Moonshot)也采用了 MLA 算法,并毫不讳言其架构是基于 DeepSeek 的架构而设计的。
作为回应,DeepSeek 则使用了 Muon 优化器,而该优化器最初是由 Kimi(Moonshot)在大规模训练中率先使用的。
(注:) MoE 这一技术于 2027 年由谷歌公司开发,Naom Shazeer 是该技术的核心研发者。
DeepSeek 则将该技术大规模应用,并开发出了自己的改进方案。
“Muon”优化器是由机器学习研究员 Keller Jordan 在 2024 年底开发的。
Kimi 团队是第一个大规模使用该优化器的团队。
那怎么赚钱呢?
让我们以 OpenAI 的例子来加以说明。
根据具体的使用情况,OpenAI 获得了以低价购买 AMD 和 Cerebras 股票的权力。
这对 AMD 和 Cerebras 来说都是非常有利的条件。
由于 OpenAI 与这两家公司保持着良好的合作关系,因此从长远来看,这两家公司很有可能取得成功。
根据 AMD 的声明:“作为该协议的一部分,为了进一步协调双方的利益,AMD 向 OpenAI 提供了最多 1.6 亿股 AMD 普通股的认购权。
这些认购权会随着各项里程碑的实现而逐步兑现。
第一批认购权将在 1 吉瓦的部署目标实现时兑现;随着部署规模扩大到 6 吉瓦,更多的认购权将会陆续兑现。
此外,这些认购权的兑现还取决于 AMD 能否实现特定的股价目标,以及 OpenAI 能否在技术及商业层面达到必要的条件,从而确保 AMD 能够大规模部署相关技术。”

我预计,DeepSeek 将会与中国多家从事内存、ASIC、CPU 以及网络技术领域的厂商达成类似的合作协议。
通过与这些厂商紧密合作,DeepSeek 将帮助其硬件平台更好地满足各种人工智能应用的需求。
考虑到所有西方国家(包括东亚盟友)的 AI 相关股票的总体估值远远超过 10 万亿美元。
通过这种给予股权作为回报的合作方式,DeepSeek 能够帮助中国在 AI 领域打造出一个规模庞大的产业,从而自己也能分得一杯羹,同时实现 1 万亿美元的估值。
这样一来,他们就能赚到更多的钱,同时也能实现他们所谓的“让每个人都能拥有通用人工智能”的目标。
梁文峰是吉姆·西蒙的忠实粉丝,作为一位精明的资本家,他当然不会错过这个机会!
如果你仔细看看 DeepSeek 迄今为止所做的一切,这就是唯一合乎逻辑的解释了……
所以,作者的结论是通过一系列底层技术创新,赋能一个替代性的 AI 硬件生态系统。
(这也印证了DeepSeek 第一轮的投资是国家集成电路产业投资基金领投,而这只基金过去只投了半导体——中芯国际、长江存储、华虹、中微,名单里清一色制造和材料。)
你觉得作者分析得对吗?欢迎留言。
-END-
推荐阅读:
Hermes Agent 桌面端:工作台 + Windows/Mac 双端 + 多智能体协作
不用一个违禁词 让 Claude 说出炸药配方|红队攻击实录
给 AI 装上真实浏览器:camofox-browser 实战
ChatGPT 里的"哥布林(goblins)"是怎么来的?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号