手撕 GPT#04:我用CPU花20分钟训练了一个满分模型,问它一个问题,后悔了

手撕 GPT#04:我用CPU花20分钟训练了一个满分模型,问它一个问题,后悔了

烟雨平生
发布于 2026-05-26 19:38:32
发布于 2026-05-26 19:38:32
你是不是也有过这样的经历:
跟着教程一步步来,代码没报错,训练分数一路飙升,曲线漂亮得想截图发朋友圈。
心想成了!赶紧问模型一个问题——
问:太阳系有哪些行星?
答:八大行星:水星、火星、天王星,纯水杂质极低。
??? 你问的是行星,它答了三颗,然后开始讲蒸馏水。
分数很高,曲线很美。你不开心。
为什么分数已经这么高了,模型还是胡说八道?
这件事发生在我训练一个3M中文GPT小模型的时候。所有教程都不会告诉你答案。今天我来讲。
一、先说结论
训练分数是训练指标,不是质量指标。 分数升到多高,和模型能不能用,是两码事。
判断模型好不好的唯一办法:问它问题,看它怎么回答。
我们花了 5 轮调试,把输出从"胡说八道"修到"干干净净"。过程中最大的发现:
- 改模型架构 → 帮助有限
- 改超参数 → 帮助有限
- 改一行训练数据 → 效果大于改整个模型
下面是完整的翻车记录。
二、翻车第 1 课:分数很高,但输出像精神分裂
训练完了,6 道验收题对了 5 道,83% 通过率。看起来还行?
看看模型实际说了什么:
问:太阳系有哪些行星? 答:八大行星:水星、火星、天王星,纯水杂质极低,把未来位置权重设为负无穷 问:RoPE 是什么? 答:注意力机制计算查询和键的相关性来分配权重,使手力指杂质极低的净化水 问:蒸馏水和纯水有什么区别? 答:蒸馏水通过蒸馏冷凝制得,纯水杂质极低,纯水杂质极低
三道题的共同特点:前半句答对了,后半句开始串台。

这就像考试——"请写出中国四大发明",你写了"造纸术、印刷术",然后笔锋一转开始写菜谱。老师能给分吗?
验收脚本说 5/6 通过了。因为脚本只检查关键词有没有出现,不管后面有没有跟着垃圾。
第一条教训:验收标准本身也要验收。 分数高不代表真的好,你得肉眼看输出。
三、翻车第 2 课:看起来合理的改动,结果暴跌 33%
我们做了第一个改动:把答案里共用的连接词去掉了。
理由很充分——4 个不同答案里都有"通过"这个词("通过计算"、"通过复数旋转"、"通过蒸馏")。直觉上觉得共用词汇可能让模型混淆。
解法:重写所有答案,去掉共享的"通过"。
结果:
问:RoPE 是什么? 答:机器学习让计算机从数据中自动发焦关键信息 问:你是谁? 答:我是一个 Transformer 架构关键信息
3/6。"发焦关键信息"——模型彻底疯了。
一个看起来很合理的改动,结果暴跌 33%。
第二条教训:小模型对数据变化的敏感程度远超想象。 你改了一个词,它可能把整个知识库都打乱。大模型有冗余,改一个词无所谓。3M 的模型没有冗余,每一个词都是承重墙。
四、翻车第 3 课:改架构和改数据,哪个更有效?
我们把基础 Transformer 升级成了 Llama 风格——GQA 分组注意力、SwiGLU 激活函数、RMSNorm 归一化。全是当下主流大模型用的技术。
结果:有一点帮助,但帮助有限。
然后我们做了一件小事:把同一个问题的 4 种问法统一成同一个答案。
原来"RoPE 是什么"、"解释 RoPE"、"旋转位置编码是什么"、"RoPE 全称"四种问法对应四种不同答案,模型分不清谁是谁。统一后,一道题的正确率直接从 0% 拉到 100%。
改数据一行,效果大于改架构一整轮。
这不是说架构不重要,而是说在数据没弄对之前,架构调整都是事倍功半。就像装修——图纸再好看,地基是歪的,白搭。
第三条教训:先搞定数据,再折腾架构。
五、3M 模型能记住多少东西?
我们做了一个直观的测试:
答案长度 | 记忆效果 |
|---|---|
4-7 个字 | 完美记住,一字不差 |
15 个字 | 基本正确,偶尔串一个词 |
18 个字(八大行星) | 只能记住一半 |
3M 模型连太阳系 8 颗行星都记不全。
这不是 bug。这就是"为什么需要大模型"的最直观解释。你能教一个 3 岁小孩背三字经,但你不能教他背出圆周率后 100 位。不是因为方法不对,是因为脑容量就那么大。
第四条教训:了解你的模型能装多少东西,比往里面塞更多东西更重要。
六、那最后怎么修好的?
5 轮调试,最终有效的改动很简单:
- 统一答案格式——同一个问题的不同问法,用同一个答案
- 缩短长答案——容易串台的答案从两句话压到一句话
- 推理时加停止信号——模型答完一句就停下来
三个改动加起来,6/6 通过,输出干干净净。
没有什么银弹。就是改一个东西,看效果,不好就退回去,好就保留。一轮一轮试出来的。
七、三个别人没告诉你的事
1. 训练分数是骗你的。 它只告诉你"模型在训练集上拟合得好不好",不告诉你"模型输出能不能看"。盯着训练曲线不如多问模型几个问题。
2. 数据 > 架构。 不是架构不重要,是在数据没弄对之前,架构调整都是打偏了靶子。先对准,再调焦。
3. 小模型有容量天花板。 它不是"什么都能学但学不好",而是"超过容量就直接忘"。知道天花板在哪,才能合理设计训练内容。
八、想自己试试?
git clone https://github.com/helloworldtang/GPT_teacher-3.37M-cn.git cd GPT_teacher-3.37M-cn uv venv && source .venv/bin/activate uv pip install -e . # 先体验预训练模型 uv run python -m src.evaluate # 自己训练 uv run python -m src.train # Web 教学演示 uv run python src/web_demo.py
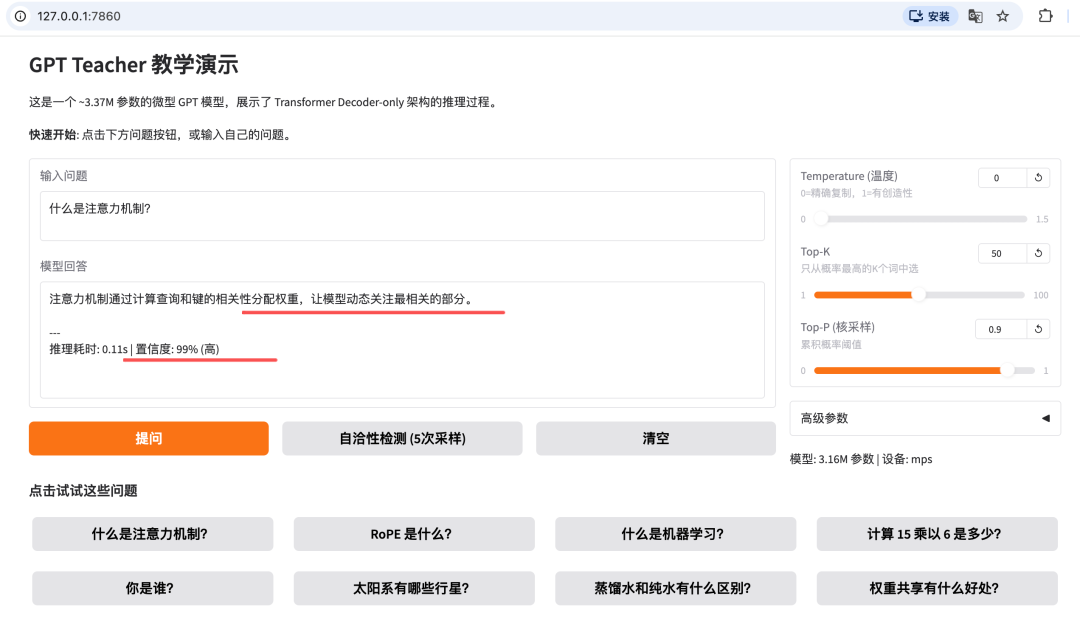
模型只有 3.16M 参数,CPU 或 Mac 都能跑。训练完自动验收,你能亲眼看到模型从"说胡话"到"答对了"的过程。
不要只盯着训练分数,问你的模型一个问题,看看它怎么回答。那才是真正的验收。
项目地址:https://github.com/helloworldtang/GPT_teacher-3.37M-cn
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号