你的 AI Coding 到底有没有工程级 Harness?

你的 AI Coding 到底有没有工程级 Harness?

苏奕嘉
发布于 2026-05-26 19:58:28
发布于 2026-05-26 19:58:28
最近一段时间,我明显感觉到,用 Vibe Coding 的人越来越多了。
而且不只是程序员。
产品经理在用,设计师在用,小老板在用,创业者也在用。
有些人拿它做内部工具,有些人拿它做小程序,有些人拿它写前端页面,有些人甚至已经开始让多个 Agent 一起推进一个复杂项目。
这个变化本身并不意外。
真正有意思的是,同样是用 AI Coding,大家之间的差距正在变得非常大。
有些大佬嘴上说“提效也就一般”,但实际已经把自己的能力放大了好几倍,甚至十倍地往前跑。
也有些人觉得“我加上 AI 已经大于等于 Linus(Linux创始人) 同志了”,结果一上来就让 AI 做大系统,需求没说清,边界没定义,测试没跑,最后不是项目烂尾,就是把一个屎山堆到公司生产环境中,没暴雷之前还沾沾自喜——“我都不用看的”。
所以今天我想讲的,不是 Vibe Coding 到底有没有用。
这个问题已经过时了。
真正值得讨论的是:怎么把 Vibe Coding 从一种兴奋感,拉回到一套接近工程级交付的工作方法。
我后面会分几篇写这件事,分别讲文生图、代码、写作和工具。今天先讲代码部分。
这篇不会写成工具榜单,也不会写成“神级 Prompt 合集”。我更想把自己这段时间真实开发里反复验证的一套方法讲清楚:为什么工具选择很重要,为什么开工前要先画原型,为什么我越来越依赖“台账”,为什么必须给 Agent 上工程规范,以及为什么长任务不是让 AI 放飞,而是更需要 Harness。
一、工具选择不是信仰问题,而是生产环境问题
先讲工具。
我第一次比较认真接触 AI Coding,大概是 2024 年年初的 Cursor。那时候它给我的感觉还比较粗糙,更像是一个增强版编辑器,加一点问答和补全能力。
真正让我开始从“古法编程”一点点切到 AI Coding,是后来它逐步接入诸如 Claude Code 等更强模型以后,跨文件理解、复杂修改、调试和重构才开始像那么回事。
后来我也试了不少国内外模型和 Coding 工具。国内几个主流模型厂商,我之前基本都有过包月、包季会员,Zhipu、MiniMax、Kimi、Qwen 都用过。海外这边,Claude Code 我也用了很长一段时间,4 月之前甚至算是忠实用户。
所以我不太想把这部分写成“谁行谁不行”的口水仗。
更准确的说法是:当 Coding Agent 进入真实开发,模型能力只是其中一项。
账号稳定性、渠道透明度、上下文质量、工具调用能力、权限控制、长任务承载能力,都会变成生产力的一部分。
Claude Code 本身能力非常顶,甚至在一段时间里,它就是最强的终端 Coding Agent。但我后来减少使用,一个重要原因是账号稳定性和使用体验的不确定性开始影响生产节奏。一个工具如果你不知道明天还能不能稳定用,它就很难成为长期工作流的底座。
至于要不要中转站,我的建议更简单:
能官方就官方,不能官方也要找可信渠道。最怕的是你以为自己用的是某个顶级模型,后面到底接的是什么却完全不透明。
这不是洁癖,是工程问题。
当你用 AI Coding 写一个真实项目时,如果模型能力波动、上下文被截断、后端模型不透明,你很难判断一次失败到底是你的需求没说清楚、工具没理解、模型能力不够,还是渠道本身在偷梁换柱。
我现在个人更倾向于用 OpenAI 官方体系来做 Coding 工作,我自己现在买了两个 20X Pro 的账号在 Running。
原因也不复杂:Codex 这条线已经从“聊天帮写代码”走到了更完整的 Coding Agent,能读代码、改代码、跑命令、做 Review,也能承接更长的任务链。对我这种高频写产品、写原型、写前端、写脚本、写市场材料的人来说,稳定和一致性比单次惊艳更重要。
当然,这不是说所有人都必须做同样选择。价格、账号、网络、团队环境,每个人情况都不一样。但如果你是认真把 AI Coding 当生产力工具,我建议至少用下面几个问题来选工具:
- • 它是否稳定可用,而不是今天能用明天被封;
- • 模型能力是否透明,而不是后端随时切换;
- • 是否能接入真实代码仓库,而不是只能写片段;
- • 是否能跑命令、跑测试、做 Review;
- • 是否有明确权限边界;
- • 是否适合长任务,而不只是一次性问答。
选 Coding Agent,不是选一个更聪明的聊天框,而是选一个能不能进入你工程流程的协作者。
二、从零做应用,第一步不是写代码,而是把需求问透
很多人一上来就对 AI 说:“帮我做一个 XX 系统。”
这句话听起来很爽,但通常不会有好结果。
不是 AI 不能做,而是你自己都还不知道要什么。你没有定义用户是谁,没有定义业务流程,没有定义权限边界,没有定义数据对象,没有定义风险和收益模型,AI 最后只能根据互联网上最常见的模板,脑补一个“看起来像”的东西。
比如你想做一个“本地生活门店会员积分小程序”,这比“校园点餐”更接近很多小老板和创业者会遇到的场景。
乍一听很简单,但稍微拆一下就会发现,里面有很多必须先讲清楚的问题:
- • 用户是谁,是消费者、门店员工、店长、平台运营,还是财务?
- • 积分从哪里来,是消费返积分、活动送积分,还是邀请奖励?
- • 积分能干什么,是抵扣现金、兑换商品、换优惠券,还是提升会员等级?
- • 退款以后积分怎么处理?
- • 多门店之间积分是否通用?
- • 店员能不能手动调整积分,谁来审核?
- • 平台靠什么赚钱,是 SaaS 订阅、交易抽佣,还是营销增值服务?
- • 如果有人刷积分、套券、恶意退款,系统怎么识别和拦截?
这些问题不聊清楚,直接开写代码,其实是在浪费 Token。
我现在做新项目,第一阶段基本不让 AI 写代码,而是让它扮演产品负责人和技术负责人,先把需求追问清楚。这个阶段要产出的不是代码,而是一组明确的业务定义:用户角色、页面结构、核心流程、数据对象、权限规则、异常场景和 MVP 范围。
你可以这样开始:
我想做一个本地生活门店会员积分小程序。你先不要写代码,先作为产品负责人和技术负责人,连续追问需求,直到用户角色、核心流程、权限边界、数据对象、风险点、商业模式和 MVP 范围都足够清楚。
这一步看起来慢,但它非常省钱。
AI Coding 的上限,往往不是模型决定的,而是你对需求的清晰度决定的。
很多人以为 Vibe Coding 的魅力是“我随口一说,它立刻开干”。真实工程里更有效的做法恰好相反:先别让它开干,先让它把你说不清楚的东西问清楚。
三、需求清楚以后,先画原型,让 AI 和你看到同一个东西
当角色、流程、功能矩阵大致清楚以后,我通常会做第一件事:画原型。
这里的原型不一定是 Figma 级高保真,也不要求第一版就像上线产品。它的核心价值,是把抽象需求变成可看的页面。
尤其现在 GPT-Image2 的文生图能力已经非常好,用它来生成初步产品原型,很划算。
你可以让 AI 按页面模块生成原型图:
根据我们前面聊过的完整项目设计框架和功能细节,
请将所有功能按页面进行归类划分,
并使用 /imageGen Skill 为每一页和每一个关键功能生成独立原型图。
要求:
1. 原型图风格统一;
2. 主色调保持一致;
3. 每张图体现页面核心功能和关键交互;
4. 命名清晰;
5. 保存至 /docs/images 目录下。很多人会把这一步理解成“设计工作”,但我觉得它更像工程前置工作。
因为很多项目写不下去,不是技术难,而是页面边界不清楚。列表页有哪些筛选?详情页有哪些操作?管理后台和用户端如何区分?状态流转在哪里体现?这些东西只靠文字,AI 很容易理解偏。
原型图出来以后,后续 Coding Agent 就有了视觉参考。尤其是前端项目,你可以要求它对照原型拆页面、拆组件、还原布局;每个页面完成后截图比对;不符合原型的地方继续迭代。
原型图的价值不是好看,而是把“我想要一个东西”,变成“我们共同看到同一个东西”。
这是很多人忽略的一点:工程协作最怕的不是代码慢,而是大家脑子里的产品根本不是同一个。
AI 也一样。
四、真正让我觉得提效明显的,是“台账”
接下来就是我这段时间实践下来最有用的一步:立台账。
很多人没听过这个词,也不用先去纠结它在传统管理语境里是什么意思。放到 Vibe Coding 里,你只需要理解一件事:台账不是 Agent 临时生成的 Plan,而是项目开发的“工程账本”。
Plan 往往是一次对话里的计划。它可能很聪明,但也很容易随着上下文漂移。台账则不同,它是你已经确认过的完整功能清单、开发顺序、依赖关系、验收标准和测试方式。它不是让 AI 临场发挥,而是把整个项目欠哪些账、先还哪些账、每笔账怎么验收,提前写清楚。
我把这个方法分享给几个群以后,反馈很快。很多人试完以后都觉得,比单纯依赖 Agent 自带 Plan 稳很多。
台账方法反馈 1
台账方法反馈 2
台账方法反馈 3
一个简化版 Prompt 可以这样写:
根据我们之前聊过的整体项目设计框架、功能细节和实现流程,
为了达成整个项目最终可完整运行且稳定的效果,
请出具一份详细的项目开发台账清单。
要求:
1. 台账必须囊括所有功能模块和功能要点;
2. 每个任务都要有清晰的开发目标;
3. 罗列合理的先后开发顺序;
4. 标注依赖关系、涉及页面、涉及接口、涉及数据对象;
5. 每个任务都要写明验收标准;
6. 每个任务都要写明测试和验证方式;
7. 保存至 /docs/plans 目录下。台账最好不要只写“开发首页”“开发后台”这种粗任务。它应该细到 Agent 能拿着其中一项独立推进。
比如会员积分小程序里,可以拆成:
- • 用户注册登录与会员身份;
- • 门店端积分发放;
- • 消费记录与积分流水;
- • 积分抵扣与退款回滚;
- • 优惠券兑换;
- • 店员权限与审核;
- • 平台运营后台;
- • 风险行为记录;
- • 数据统计面板;
- • 回归测试清单。
每一项后面都应该有涉及文件、交付结果、验证命令和验收标准。
这也是我觉得“台账”比普通 Plan 好用的地方。
普通 Plan 更像“接下来我要做什么”,台账更像“这个项目到底欠了哪些账、每一笔账怎么交付、怎么验收、怎么接力”。
一旦有了台账,Agent 的工作就不再是“看心情往前写”,而是按账本推进。
台账的本质,是把 Vibe Coding 从一次性灵感,变成可追踪、可验收、可继续接力的工程任务。
五、没有工程规范的 Agent,很容易从助手变成事故源
有了需求、原型和台账,才真正进入开发阶段。
这时候最危险的一种做法,是让 Agent 拿着台账直接放飞。因为它确实可以跑得很快,但如果没有工程规范,跑得快未必是好事。
我现在会在正式开发前,要求 Agent 写入并遵守一套核心开发规范。这个规范不复杂,但必须硬。
第一,先初始化 Git。
任何新项目,先建仓库,先提交初始状态。后面每完成一个功能模块,就做一次明确 Commit。不要让 AI 在一个脏工作区里连续改几十个文件却没有检查点。
第二,按台账开发。
每次只取一个功能点或一个场景,不要同时开太多战线。开发前先复述任务目标、涉及文件、依赖关系和验收标准。开发中如果发现台账不合理,先更新台账,再继续写代码。
第三,前端必须对照原型。
有原型图,就按原型拆页面、拆组件、还原布局。开发完要截图验证,而不是只说“我已经实现了”。页面类任务最怕 AI 自我感觉良好,实际打开一看按钮挤在一起、移动端溢出、状态根本没覆盖。
第四,开发完成后必须 Review。
这里的 Review 不只是看有没有语法错误,而是要检查实现是否偏离需求、是否有重复逻辑、是否有边界遗漏、是否有安全风险、是否存在为了通过测试而牺牲设计的情况。
第五,必须跑测试。
前端要跑 lint、typecheck、build;后端要跑接口测试、数据校验和关键路径验证;能写单元测试就写单元测试,能做回归测试就做回归测试。没有测试的“完成”,只能算“写完”,不能算“交付”。
第六,用真实操作做拟真测试。
如果有浏览器界面,就用 Computer Use 或类似工具模拟真实用户操作:打开页面、点击按钮、输入内容、提交表单、切换状态、刷新页面、检查错误提示。很多 Bug 静态 Review 看不出来,必须点一遍。
这套流程看起来啰嗦,但它解决了一个核心问题:
你不能用“AI 说它完成了”来定义完成。完成必须有命令输出、截图、测试结果或明确证据支撑。
下面这段,我建议可以写入项目的 AGENTS.md、CLAUDE.md、README_DEV.md 或专门的开发准则里:
参考 Superpowers 这类 agentic development workflow 来严格管理开发过程。
核心不是让 AI 直接写代码,而是把开发拆成一套可验证、可追踪、可审查的流程:
1. 先通过 brainstorming 澄清真实需求、边界、约束和成功标准;
2. 再沉淀成明确的设计说明 spec;
3. 经过确认后,再用 writing-plans 写出可执行计划;
4. 计划必须包含具体文件路径、任务拆分、测试方式、验证命令和预期结果;
5. 执行阶段必须按任务逐步推进,优先采用 TDD;
6. 先写失败测试,再实现最小代码,再验证通过;
7. 每个阶段都要进行代码审查、需求对齐检查和完成前验证;
8. 禁止凭感觉宣布完成;
9. 所有完成都必须有真实命令输出或明确证据支撑。如果要再严一点,还应该补上几条生产安全规则:禁止直接连接生产数据库;禁止执行删除数据、清空目录、重置数据库等高风险命令,除非用户明确确认;所有数据库迁移必须先生成 migration 文件,再人工 Review;所有涉及权限、支付、数据删除的功能必须有额外测试;不允许把 API Key、Token、密码写入代码或文档。
这些规则很朴素,但很救命。
工程级 Vibe Coding 的关键,不是让 AI 更自由,而是给 AI 一条足够清楚、足够窄、可以持续推进的路。
六、长任务可以跑,但长任务更需要台账
很多人还停留在“AI 一次对话写一小段代码”的阶段。但真正进入 Agentic Coding 以后,长任务会越来越常见。
规划比较好的任务,单任务跑十几个小时并不夸张。更长一点,如果上下文、台账、测试和权限控制都做得好,跑 24 到 48 小时也不是完全不能接受。
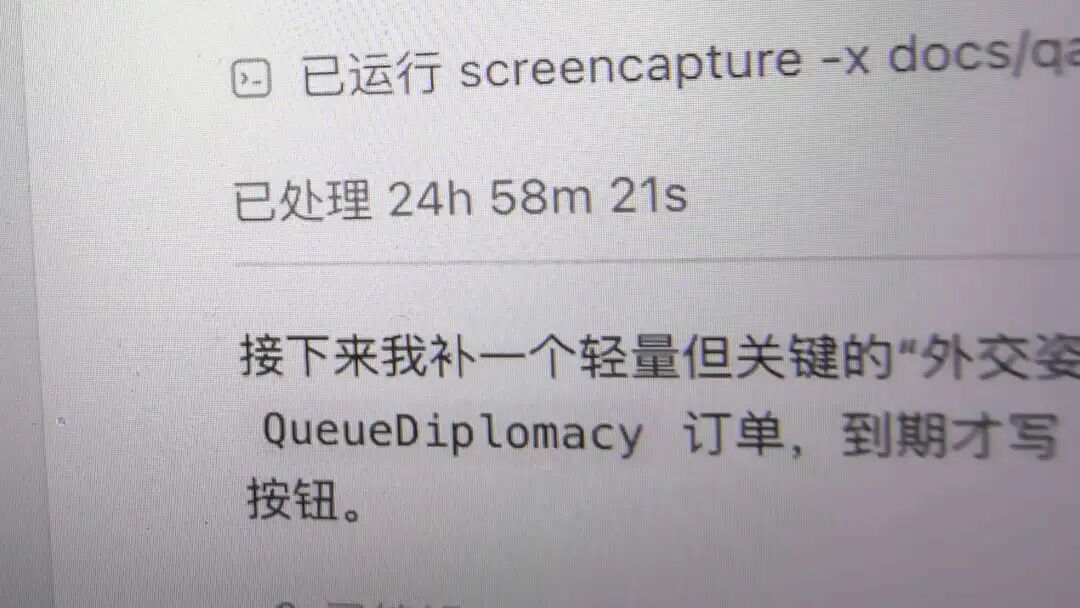
长任务执行截图 1
长任务执行截图 2

长任务执行截图 3
但这里必须讲清楚,我不是建议大家把 Agent 放出去瞎跑两天。
长任务成立,有几个前提:
- • 任务边界足够清楚;
- • 台账已经确认;
- • 每一步有验收标准;
- • 环境可以安全运行;
- • 中间有检查点;
- • 失败后能回滚;
- • 结果能被 Review。
否则跑得越久,风险越大。
有些人会问,用 /goal 不也可以吗?
我的理解是,两者不一样。
/goal 更像你给 Agent 一个目标,让它自己规划和推进。它适合一些边界清楚、风险不高、允许 Agent 自主探索的任务。
台账则是你已经确认过的开发任务总表,更适合复杂项目、多人协作、长期推进和可追溯交付。
说得更直接一点:
/goal更像“你去想办法完成这个目标”,台账更像“这是我们确认过的工程账本,请按账本逐项交付并验收”。
这两者都能用,不必互相否定。但如果你要做的是一个完整产品、后台系统、多人协作项目,我会更倾向于先立台账,再让 Agent 跑。
长任务的价值不在于“它跑了多久”,而在于它能不能在长时间里持续不偏航。
这就回到了前面那句话:没有 Harness 的长任务,本质上只是更长时间的赌博。
七、再往后看,开发会变成多 Agent 协作
我太太在做 OPCS 系统时,就已经在尝试让多 Agent 自主交互,完成复杂任务拆解和持续推进。
一个 Agent 负责需求观察,一个 Agent 负责产品协调,一个 Agent 负责代码实现,一个 Agent 负责只读观察或测试反馈。它们不是按固定流程硬跑,而是在任务过程中动态协作。
数字分身协作截图
这件事其实指向一个更大的变化:未来的软件开发,可能不再是“一个人加一个助手”,而是一个人管理一组数字员工。
有的数字员工负责需求观察,有的负责产品台账,有的负责技术实现,有的负责测试,有的负责文档,有的负责从群聊、工单、日志里捕捉需求和问题。
这时候,人类开发者的角色也会变化。
你不再只是写代码的人,而更像工作流设计者、需求裁判、工程负责人和验收人。你要决定什么能交给 Agent,什么必须自己判断;什么可以自动执行,什么必须人工确认;什么算完成,什么只是看起来完成。

多 Agent 协作截图
Vibe Coding 最终提升的不是某一行代码的速度,而是一个人组织工程劳动的能力。
这也是为什么同样用 AI,有些人只是更快地写出一堆烂代码,有些人却能把自己变成一个小型研发团队。
差别不在会不会提问这么简单。
差别在有没有方法论。
八、写在最后:Vibe Coding 不是放弃工程,而是倒逼你更工程化
很多人对 Vibe Coding 有一个误解:好像用了 AI,就可以不懂产品、不懂架构、不懂测试、不懂工程管理。
我的体感恰好相反。
AI Coding 越强,对人的工程能力要求越高。
以前你自己写代码,慢一点,但每一步都在你手里。现在 Agent 可以一次改几十个文件,可以跑命令,可以生成接口,可以改数据库,可以重构页面。它的速度越快,你越需要清楚地知道边界在哪里、风险在哪里、验收标准在哪里。
所以我越来越相信,工程级 Vibe Coding 的路线大概是这样的:
- 1. 先选稳定透明的工具,不要把生产力压在黑盒渠道上;
- 2. 先聊清楚真实需求,不要让 AI 替你脑补产品;
- 3. 先画原型,把抽象需求变成可共同观看的页面;
- 4. 再立台账,把项目拆成可追踪、可验收的工程任务;
- 5. 写入开发规范,让 Agent 按 spec、plan、test、review 推进;
- 6. 每个功能完成后必须有真实验证;
- 7. 长任务可以跑,但必须带着台账、检查点和回滚机制跑;
- 8. 最后再进入多 Agent 协作,把个人产能升级成一套小型工作系统。
这套方法听起来没有那么玄,但它很实用。
因为真正能改变开发效率的,往往不是一句神奇 Prompt,而是你是否把 AI 放进了一套正确的 Harness 里。
Vibe Coding 的分水岭,不是你敢不敢让 AI 写代码,而是你有没有能力把 AI 关进一套工程流程里,让它持续、稳定、可验证地交付。
代码只是第一篇。
后面我会继续聊文生图、写作和工具。因为无论是哪一个方向,底层逻辑其实都一样:
不要把 AI 当神像。
把它当工具、当员工、当协作者。
然后给它目标、边界、流程和验收。
这件事,才刚刚开始变得好玩。
看到这里了,来个点赞、转发呀,这是唯一更新的动力了!
我们下篇见~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-22,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Apache Doris 补习班 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号