大模型终于不用一个字一个字往外蹦了

大模型终于不用一个字一个字往外蹦了

随机比特
发布于 2026-05-26 20:03:27
发布于 2026-05-26 20:03:27
你有没有发现,ChatGPT 回答问题时总是一个字一个字往外冒?
这不是它在“装思考”,而是过去十多年里,主流大模型基本都用同一种生成方式:一次只预测下一个 token。这个范式叫自回归(Autoregressive)。
它的好处很明显:稳定、成熟、效果好。代价也很直接:你要它写 1000 字,它就得跑 1000 次循环,长度越长,等待越久。
说白了,它像个特别认真、但有点死心眼的实习生:你不点“下一步”,它绝不越界半个字。
这次变化,不是堆算力,是换范式
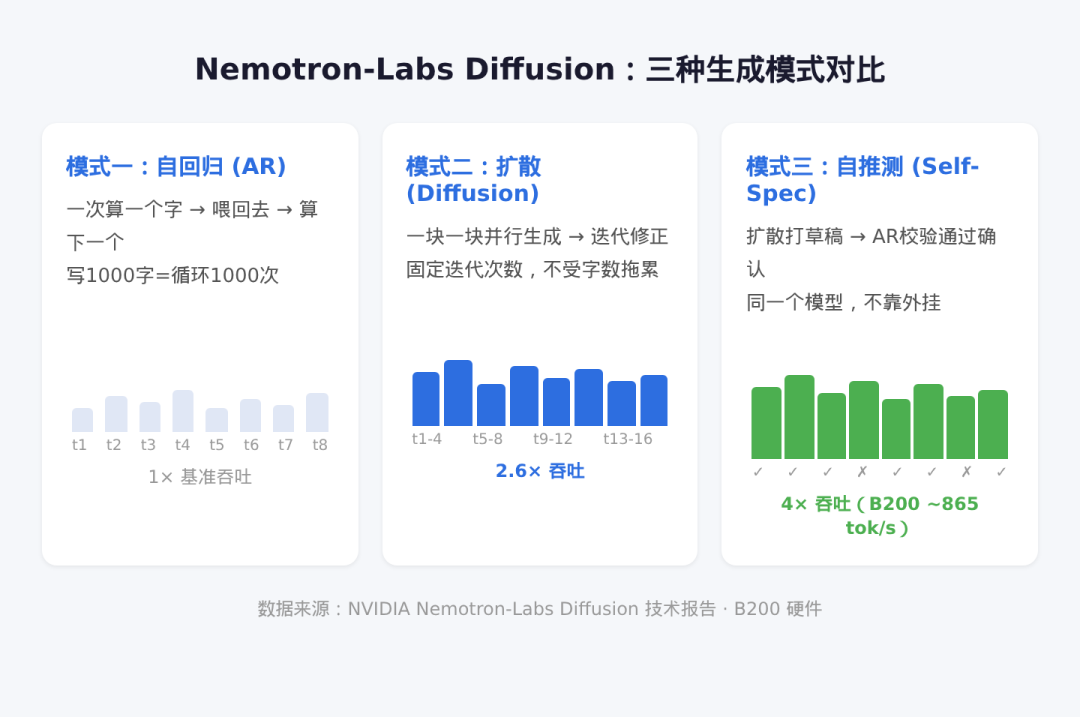
NVIDIA 这周发布了 Nemotron-Labs Diffusion(3B/8B/14B)。最值得看的,不是参数,而是它把文本生成做成了三种可切换模式:
- 传统自回归(AR)
- 扩散生成(Diffusion)
- 自推测(Self-speculation)
扩散模式的核心思路是:先并行生成一批候选,再迭代修正,而不是死磕“一个 token 接一个 token”。
你可以把两种方式理解成:
- 自回归像“逐字打字”
- 扩散像“先打草稿,再通篇改”
这不是文案层面的比喻,它会直接影响推理时延和吞吐上限。
或者你可以这样理解:
- 自回归像你在会议上边想边说,话一出口就收不回
- 扩散像你先在备忘录里写一版,再把别扭的句子统一抹平
01-three-modes
真正实用的是“自推测”
以前很多“加速解码”方案都依赖双模型:小模型先猜,大模型再验。问题是两个模型分布不一致,猜中率不稳定,batch 小时收益也不理想。
Nemotron 这套自推测做法是同一个模型自己起草、自己校验,不再依赖外部 draft 模型。对线上常见的 batch=1 场景更友好。
这就像以前是“实习生写初稿,主编改稿”,经常改到凌晨两点;现在变成“同一个老编辑先快写一版,再自己复核”,沟通成本直接砍掉。
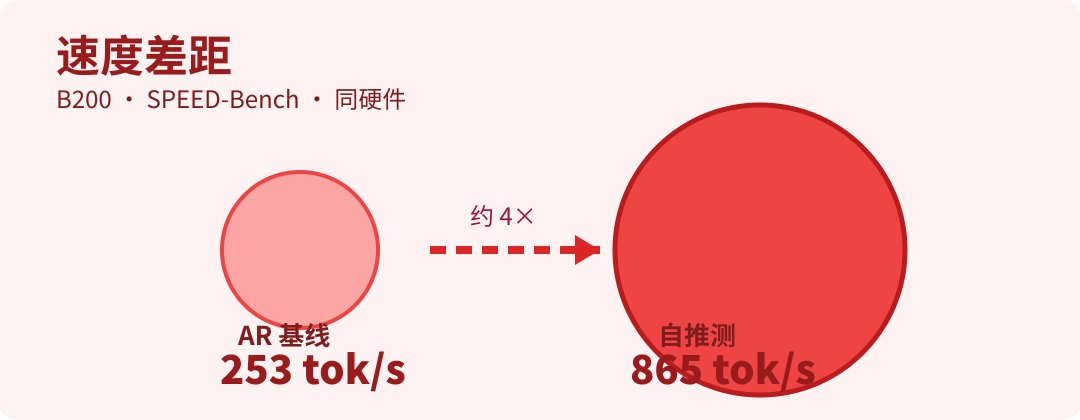
按 NVIDIA 在 B200 + SPEED-Bench 给出的结果,自推测模式吞吐约 865 tok/s,大约是对应 AR 基线的 4 倍,同时保持可校验的一致性。
02-speed-contrast
为什么说它“可能”是拐点
“可能”两个字很重要。扩散语言模型不是新概念,之前学术界做过不少,但卡在两件事上:
- 精度追不上 AR
- 工程上难接入现有推理栈
Nemotron 这次的意义在于,它把“研究原型”往“可部署方案”推了一步:从现有 AR 模型继续训练得到三模态能力,并且在 SGLang 这类栈上已有可运行路径。
所以更准确的说法不是“AR 结束了”,而是:
在开源和工业部署层面,AR 第一次遇到了一个可落地的替代路线。
这类时刻通常很像“功能机时代第一次摸到智能机”:当下不会一夜替换,但你已经能感觉到,旧路径不再是唯一正确答案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号