NCP-AIN 备考(1):网络拓扑优化核心知识

NCP-AIN 备考(1):网络拓扑优化核心知识

GPUS Lady
发布于 2026-05-26 20:37:57
发布于 2026-05-26 20:37:57

本课程隶属于英伟达认证专业人工智能网络工程师(NCP-AIN)培训体系,带你掌握面向人工智能业务的高性能网络拓扑设计与优化方法。
NCP-AIN 是英伟达专业级 AI 网络认证,全称 AI Networking。该认证考核从业者运用英伟达高速网络技术,部署、配置与运维 AI 数据中心网络环境的能力。
(考试信息可以访问:https://www.nvidia.cn/training/certification/ai-networking-professional/)
从传统网络到 AI 算力网络:我的 NVIDIA AI Networking Professional 认证备考心得
非NVIDIA官方课程,仅供参考学习。
本文介绍搭建可扩展、低时延、高带宽的网络架构,高效支撑分布式人工智能训练与推理业务。网络拓扑直接决定各节点间显卡通信效率。拓扑设计缺陷易引发网络拥塞、时延骤增、资源利用率偏低等问题。本模块传授优化组网方案设计知识,助力提升网络吞吐能力,保障人工智能场景下性能稳定输出。
欢迎。今天我们将深入探讨如何优化基于英伟达架构的网络拓扑。我们将探索如何构建能够应对大规模AI工作负载独特需求的网络架构。
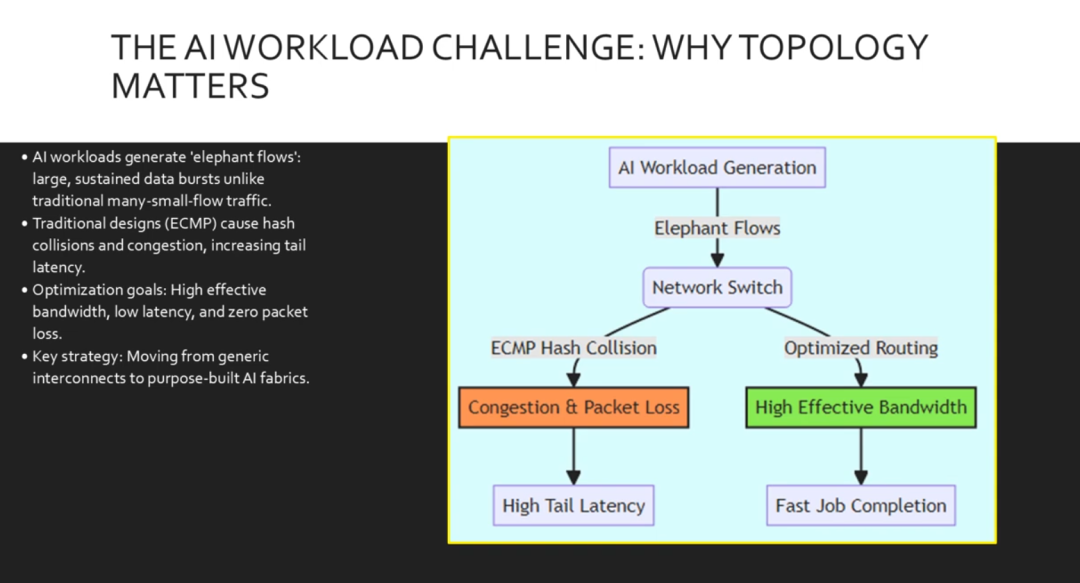
首先,让我们了解我们来这里的原因。传统数据中心处理成千上万个小型数据流,这些数据流可以通过简单的哈希算法轻松平衡。AI则不同。它会生成数量庞大的“大象流”,这些数据流可以瞬间饱和链路。如果使用标准路由(例如ECMP),就会出现冲突,导致高尾延迟,这是训练性能的敌人。为了优化英伟达环境,我们必须将重点转移到最大化有效带宽和通过专门的拓扑设计消除丢包。
看这个数据流。在左侧,我们看到AI工作负载正在生成海量数据流。如果我们依赖标准的ECMP哈希算法,多个数据流可能会试图挤过同一条链路,从而导致冲突和丢包。这会导致高尾延迟,降低整个集群的速度。然而,通过优化路由(我们稍后会讨论),我们可以高效地分配流量,确保高带宽和更快的作业完成速度。理想情况下,我们希望保持在绿色路径上。
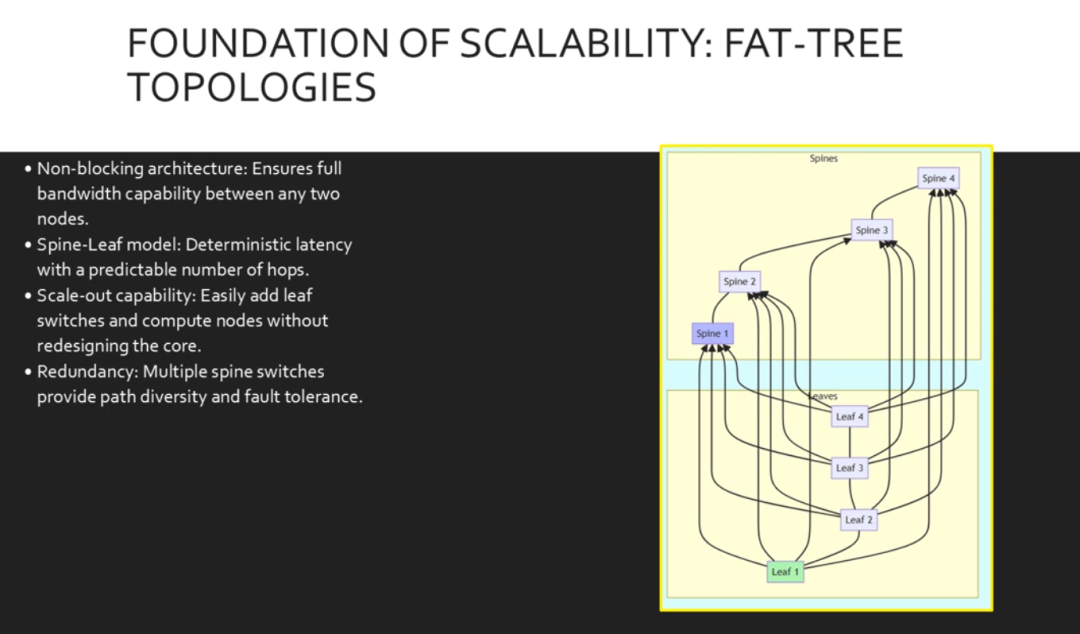
可扩展AI 网络的基础是工厂拓扑结构。与传统的三层设计不同,这种拓扑结构是无阻塞的,这意味着每个节点都可以同时以全线速进行通信。我们在这里使用脊叶模型。每个叶交换机都连接到每个脊交换机。这保证了任意两个服务器之间的流量只会跳到脊交换机,然后以可预测的低延迟返回。它还提供了强大的冗余。如果一个脊交换机发生故障,流量会重新平衡到其他脊交换机。这是一个经典的工厂拓扑结构。请注意,每个绿色叶交换机都连接到每个蓝色脊交换机。脊交换机之间或叶交换机之间没有链路。这为任何服务器之间的通信创建了一条可预测的两跳路径。如果主干网1离线,叶交换机1 到4仍然可以通过主干网2、3 和4 保持完全连接。这种网状结构确保即使在维护或故障事件期间,我们也能保持高带宽可用性。
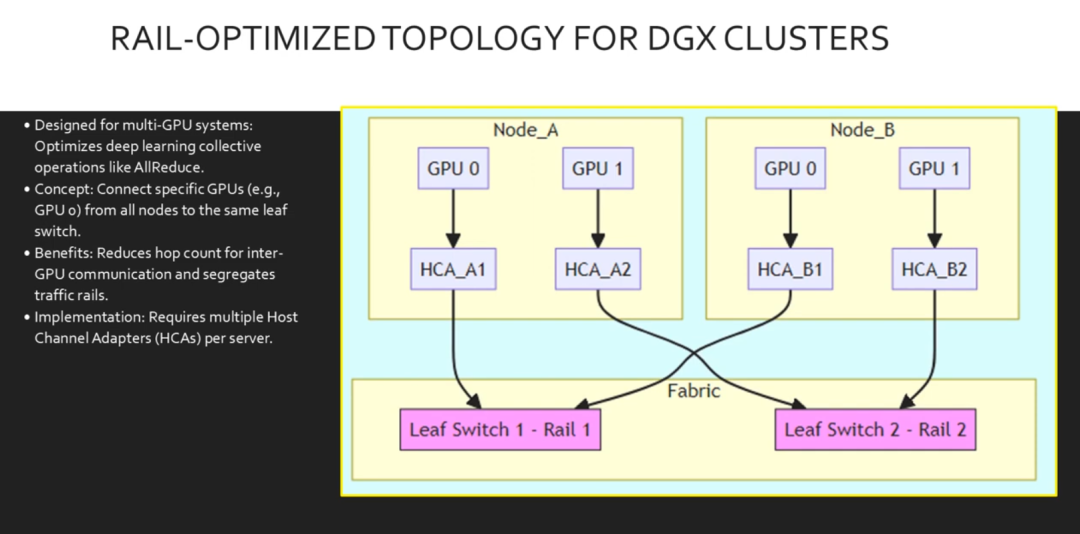
现在,让我们专门讨论NVIDIA DGX集群。我们使用轨道优化拓扑。深度学习作业经常使用名为“全部归约”的操作,其中GPU 需要与其他节点上的对等节点交换数据。在轨道优化设计中,我们将每台服务器的第一个HCA 连接到同一个交换机,第二个HCA 连接到第二个交换机,依此类推。
这创建了并行的流量轨道。它通过将同步流量保持在专用的物理隔离路径上来最大限度地减少拥塞。此图说明了轨道优化概念。请查看粉色的轨道1。节点A 的GPU0和节点B 的GPU0 都连接到叶交换机1。它们可以通过该单个交换机直接通信。同时,两个节点上的GPU 1 都连接到叶交换机2。这有效地创建了并行网络,确保来自一组GPU 的大量流量不会阻塞其他GPU。这对于扩展训练性能至关重要,尤其是在数百个节点上。
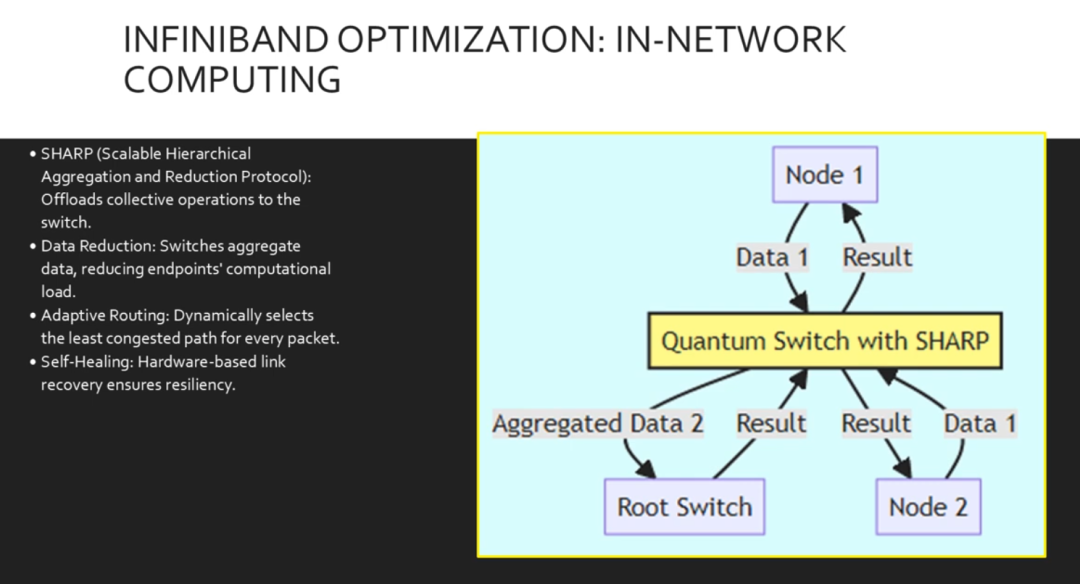
如果您使用Infiniband,特别是Nvidia Quantum 2,您将拥有强大的工具。其中最重要的工具是Sharp。在传统网络中,数据会在服务器之间多次发送以进行计算。而使用SHAP,交换机本身即可执行数据聚合和归约。我们还启用了自适应路由,交换机 ASIC 会评估出口Q 深度并动态重新路由数据包,以避免拥塞,从而确保最佳链路利用率。这里我们看到了Sharp 的实际应用。节点1 和节点2 将它们的数据值发送到量子交换机。
交换机不会将两个数据包都转发到根节点或彼此之间,而是直接在硬件中计算总和或其他运算。它仅将聚合结果上行或下行发送。这大幅减少了流经网络结构的流量,并释放了GPU 计算周期,使其可用于其他任务。

对于以太网环境,我们使用 Spectrum X 平台来克服传统网络的限制。标准以太网使用静态哈希,这会导致冲突。Spectrum X 引入了RoCE自适应路由。Spectrum 4 交换机将数据包分散到所有可用部分,以最大限度地提高吞吐量。
至关重要的是,目标端的Bluefield 3 Super NIC 会处理乱序到达的数据包,并在将其呈现给应用程序之前将其完美地重新组装。这使得以太网拥有类似Infiniband 的性能。请跟随顺序。源DPU 传感器流。
Spectrum 4 交换机并非只选择一条路径。它会根据实时负载,将数据包1、2 和3 分散到路径A、B 和C 上。注意,它们到达目标SuperNIC时顺序被打乱了。先是1,然后是3,最后是2。SuperNIC硬件会将它们重新排序为1 2 3高效地完成。因此,应用程序可以看到完美的流。这利用了95% 的网络带宽,相比之下,静态路由只能利用60% 的带宽。
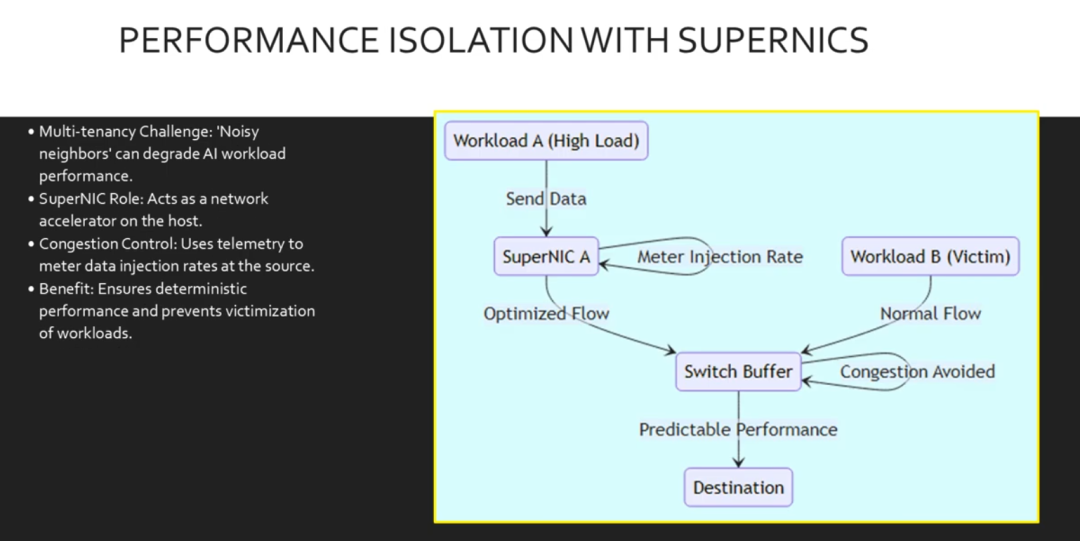
在云端或多租户 AI 工厂中,您不希望一个用户的高流量影响另一个用户的训练运行。这就是所谓的“嘈杂邻居”问题。NVIDIA SuperNIC 通过强制执行性能隔离解决了这个问题。它们不仅发送数据,还利用交换机的遥测数据参与全局拥塞控制。SuperNIC 会计量自身的数据注入速率,确保突发工作负载不会使光纤缓冲区过载,从而保护所有租户的性能完整性。
这里我们看到工作负载 A 产生了高负载。Super NIC 不会立即淹没交换机缓冲区,而是拦截了这一流量。它基于实时遥测数据计量注入速率。受控的数据流与工作负载 B 一起进入交换机。由于 Super NIC 防止了缓冲区饱和,工作负载 B 不会受到影响。两个工作负载均以可预测的性能运行。
如果没有这种计量,交换机缓冲区将会被填满,工作负载 B 将遭受丢包。
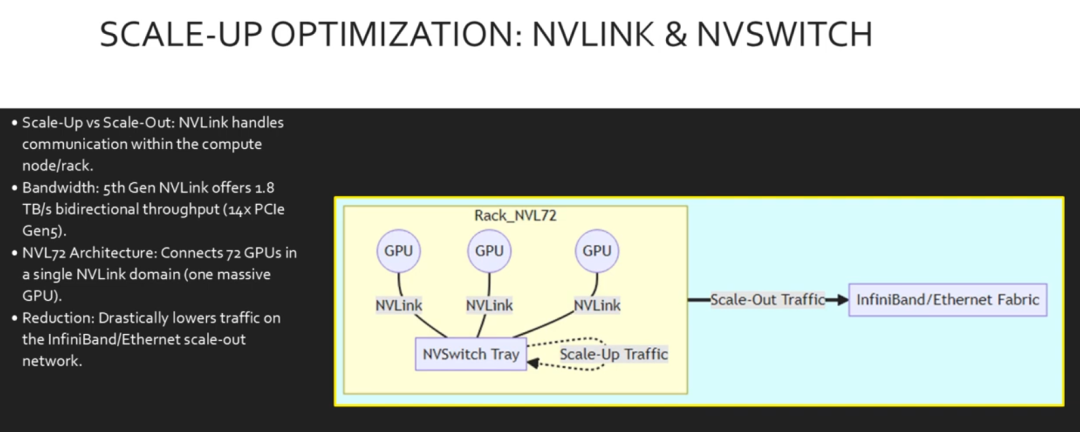
在流量到达节点之前,我们在机架内部进行优化。这就是纵向扩展。NVLINK 和NV交换机技术使 GPU 能够以极高的速度以每秒 1.8 TB 的速度相互通信。借助 NVL 72 架构,我们将72 个 GPU 连接到单个 NV Link 域中。它们像一个巨大的 GPU 一样运行。这至关重要,因为它将最繁重的通信流量(例如张量并行)完全保留在以太网或InfiniBand 网络中,从而将该带宽用于交互式横向扩展通信。
此图将机架内部的两个流量域分隔开来。
左侧的 GPU 通过 NV 交换机托架使用 NV Link 连接。这支持模型并行所需的大量带宽。只有需要离开机架的流量才会通过。横向扩展流量会流经右侧的InfiniBand 或以太网交换矩阵。通过使用 NVLink 在机架内处理繁重的计算任务,我们优化了整体拓扑性能。
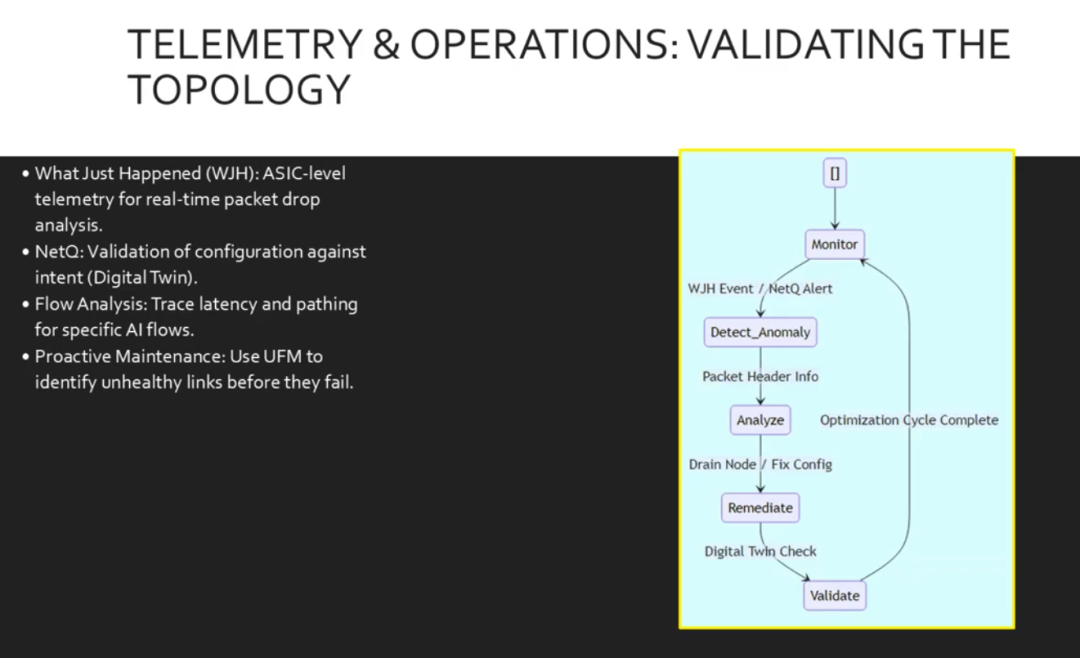
优化并非一次性事件。它是一个生命周期。为了维护这些拓扑,我们使用高级遥测技术。
What Just Happened(WJH )为我们提供了关于数据包丢失原因和位置的实时数据。它不仅仅是一个计数器,而是根本原因分析。NVIDIA NetQ 允许我们根据数字孪生验证我们的配置,从而防止配置错误。UFM 统一交换矩阵管理器监控 InfiniBand 的健康状况,识别降级的链路,以便我们在它们影响训练作业之前进行修复。
真正的优化需要持续的可见性。这就是运行循环。我们从监控开始。当 WJH 检测到丢包或 Net Q 检测到配置漂移时,我们会启动异常检测。我们分析 WJH 提供的特定数据包头部信息,以精确定位问题所在,例如电缆故障或 ACL 丢失。我们通过一些方法来修复问题,例如排空某个节点。我们根据数字孪生设计验证修复方案,然后返回监控。这个循环确保我们优化的拓扑结构始终保持最佳状态。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号