CacheDiT、TaylorSeer 与 SCM:DiT 扩散模型推理加速到底在加速什么?

CacheDiT、TaylorSeer 与 SCM:DiT 扩散模型推理加速到底在加速什么?

Michael阿明
发布于 2026-05-26 20:45:59
发布于 2026-05-26 20:45:59
文章目录
- 1. DiT 是什么?
- 2. CacheDiT 为什么能加速?
- 3. DBCache:按 Transformer Block 做缓存
- 4. TaylorSeer:不是直接复用,而是预测未来特征
- 5. SCM:不是所有 step 都同等重要
- 6. 三者怎么协同?
- 7. Diffusers + CacheDiT 示例
- 1. 安装环境
- 2. Baseline:不启用缓存
- 3. 启用 CacheDiT, 自定义 DBCache 配置
- 5. 加入 TaylorSeer
- 8. torch.compile 要不要开?
- 9. vLLM-Omni 中如何使用 cache?
- 1. vLLM-Omni:TeaCache 示例
- 2. vLLM-Omni:Cache-DiT 示例
- 10. 参数怎么调?
- 1. DBCache 参数
- 2. TaylorSeer 参数
- 3. SCM 参数
- 11. 常见踩坑
- 1. 不要把 Diffusion Cache 和 LLM KV Cache 混淆
- 2. few-step 模型收益有限
- 3. CPU offload 会影响 benchmark 结果
- 4. torch.compile 不适合动态 shape
- 5. 阈值越激进,质量风险越大
- 12. 总结
在图像、视频生成模型里, Diffusion Transformer,简称 DiT
DiT 的推理不是一个 token 接一个 token 地生成,而是从纯噪声开始,经过多个 denoising step,一步步去噪得到最终图像。因此,DiT 加速的关键问题变成了:
❝每一个去噪 step 都必须完整跑一遍 Transformer 吗?
CacheDiT 的答案是:不一定。
Diffusers 官方文档将 CacheDiT 定义为一个面向 Diffusers DiT-based pipelines 的统一、免训练缓存加速框架,支持 Flux、Mochi、CogVideoX、Wan、HunyuanVideo、QwenImage、StableDiffusion3、PixArt、Sana、HunyuanDiT 等多类 pipeline。
1. DiT 是什么?
DiT = Diffusion Transformer。
它的核心思想是:把传统扩散模型里的 U-Net 去噪网络替换成 Transformer。
传统 Stable Diffusion / SDXL:
噪声 latent → U-Net → 预测噪声 → 更新 latent
DiT / FLUX / SD3 / Qwen-Image / PixArt:
噪声 latent → Transformer Blocks → 预测噪声 → 更新 latent
DiT 推理通常要跑很多步:
t = T → ... → 3 → 2 → 1 → 0
注意:diffusion timestep 通常是从大到小执行的。大的 timestep 对应高噪声,越往后噪声越低,图像越清晰。
可以理解成:
大 timestep:高噪声,决定大结构
中 timestep:主体逐渐稳定
小 timestep:细节、纹理、锐化
2. CacheDiT 为什么能加速?
DiT 推理有一个很重要的经验事实:
❝相邻 denoising step 的中间特征通常很相似。
比如:
F(t=20) → F(t=19) → F(t=18) → F(t=17)
这些 hidden states / residuals 不会突然剧烈跳变。
既然如此,每个 step 都完整跑所有 Transformer Blocks 就有冗余。
CacheDiT 的基本思路是:
正常推理:
每个 step 都完整跑 Transformer
CacheDiT:
先判断当前 step 和缓存 step 是否足够相似
如果相似,就复用或预测部分中间特征
如果不相似,就退回完整计算
Cache-DiT 通过智能缓存机制加速 diffusion transformer,主要包含 DBCache、TaylorSeer 和 SCM 三种机制。
3. DBCache:按 Transformer Block 做缓存
DBCache = Dual Block Cache,可以理解成一种 block 级别的缓存机制。
一个 DiT Transformer 可以看作很多 blocks:
Block 1 → Block 2 → Block 3 → ... → Block N
DBCache 把它拆成三段:
[前部 Fn blocks] [中间可缓存 blocks] [后部 Bn blocks]
其中:
Fn_compute_blocks:
前面几个 blocks 必须计算,用来判断当前 step 和缓存 step
的 residual diff 是否足够小。
Bn_compute_blocks:
后面几个 blocks 可用于融合和修正,提升质量。
如果 residual diff 很小,说明当前 step 与前面 step 很相似,那么中间大量 blocks 可以复用缓存,减少计算。
4. TaylorSeer:不是直接复用,而是预测未来特征
普通 cache 容易有一个问题:如果直接拿过去的特征来用,间隔小还可以,间隔大了就容易出错。
TaylorSeer 的思路更聪明:
❝不直接照抄旧特征,而是根据过去几个 timestep 的变化趋势,用 Taylor 展开预测未来特征。
比如已经完整计算了:
F20, F19, F18
那么后面的:
F17, F16
可以不完整计算,而是用 Taylor 展开预测:
F(t + Δt) ≈ F(t)
+ Δt · F'(t)
+ 1/2 · Δt² · F''(t)
+ ...
在扩散推理里,由于 timestep 是从大到小走,所以更直观的写法是:
已经观察:
F20 → F19 → F18
预测后续:
F17' → F16'
这里的 F17'、F16' 是预测特征,不是完整 Transformer 真实算出来的特征。
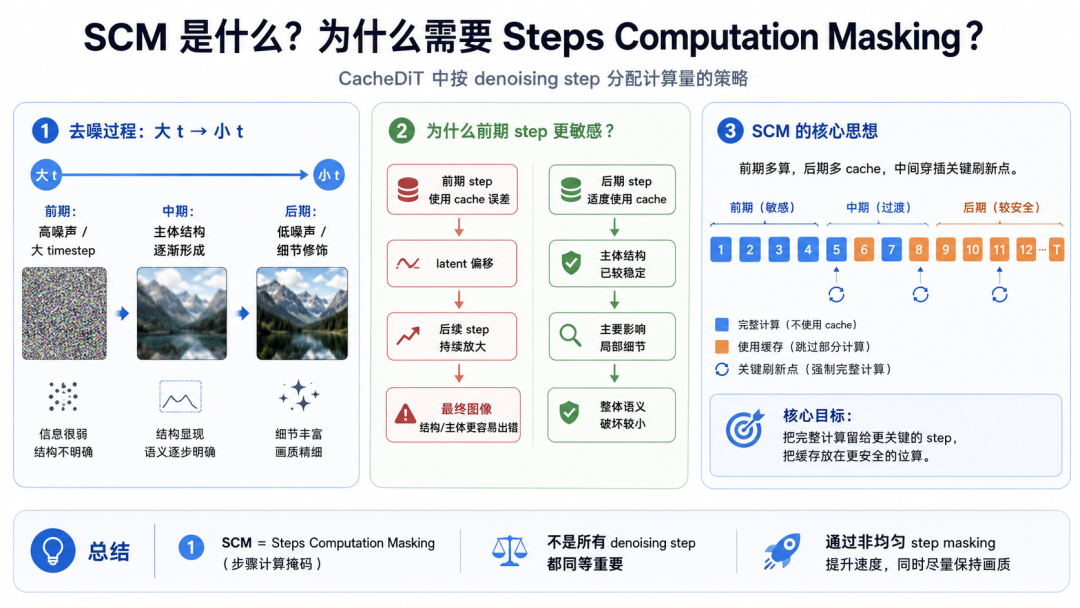
5. SCM:不是所有 step 都同等重要
SCM = Step Computation Masking,可以翻译成“步骤计算掩码”。
它解决的问题是:
❝哪些 denoising step 必须完整计算?哪些 step 可以使用缓存?
扩散模型不同阶段的重要性不同:
前期:高噪声,决定大结构,误差容易被后续放大
中期:主体结构形成,需要定期刷新
后期:低噪声,主要修细节,更适合缓存
在这里插入图片描述
在这里插入图片描述
所以 SCM 的策略不是均匀跳步,而是:
前期多完整计算
中期穿插刷新点
后期更积极使用 cache
SCM 本质上就是给每个 step 一个 0/1 mask:
1 = 完整计算
0 = 使用缓存
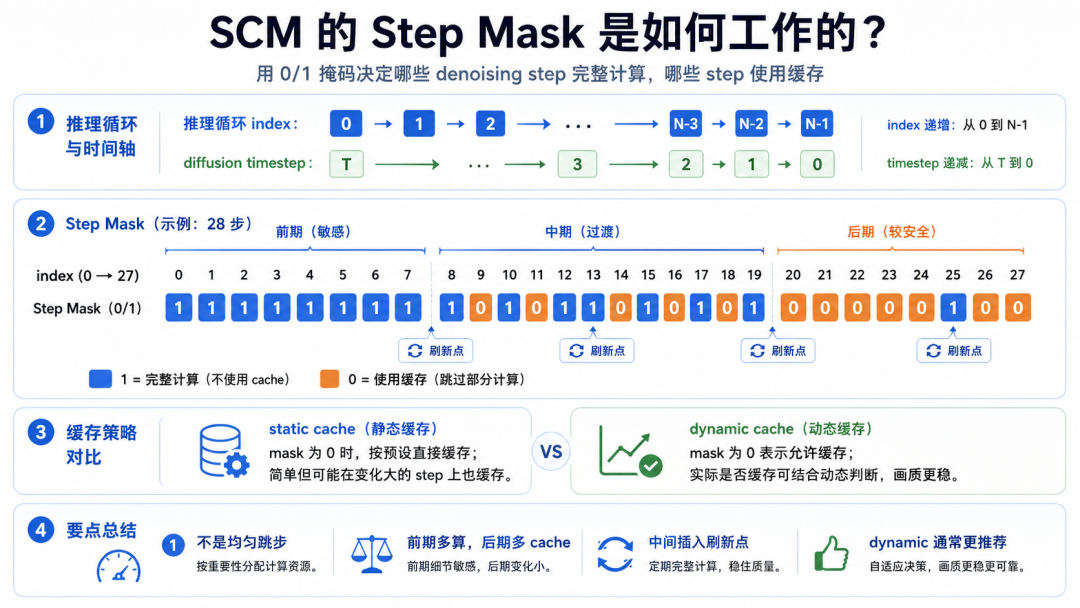
例如 28 steps:
index: 0 1 2 3 4 5 6 7 ... 27
mask: 1 1 1 1 1 1 0 1 ... 0
在这里插入图片描述
在这里插入图片描述
vLLM-Omni 文档中,SCM 的 mask policy 包括 slow、medium、fast、ultra。
以 28 steps 为例,slow 计算 18/28 个 step,
medium 计算 15/28 个 step,
fast 计算 11/28 个 step,
ultra 计算 8/28 个 step;
文档也建议优先从 medium 开始,并且 dynamic 通常比 static 质量更好。(vLLM[1])
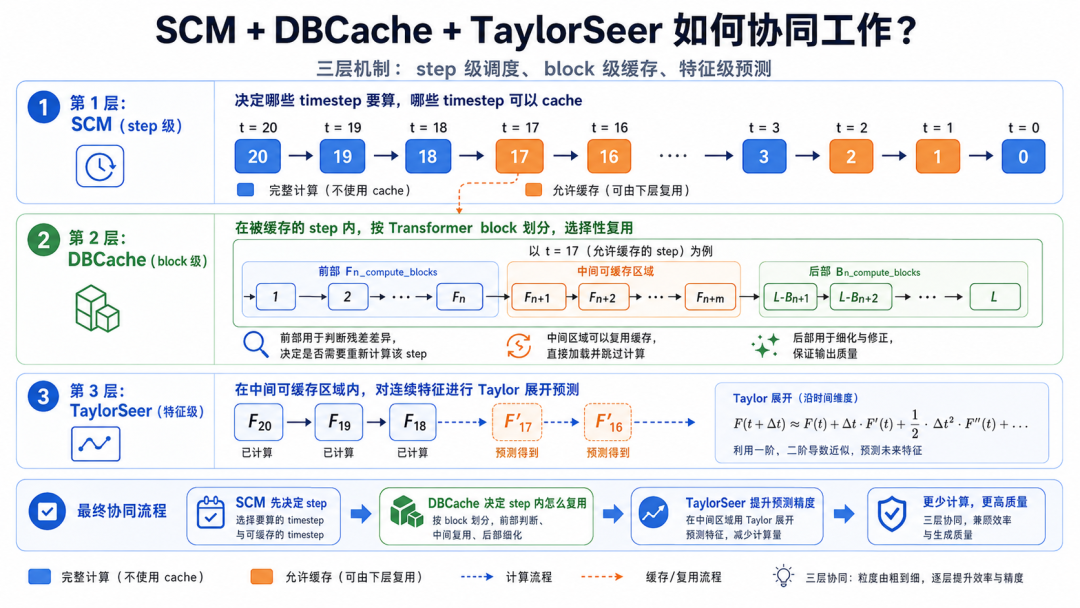
6. 三者怎么协同?
CacheDiT 可以理解成三层机制:
SCM:step 级别
决定哪个 timestep 要完整算,哪个 timestep 可以 cache。
DBCache:block 级别
在允许 cache 的 step 内,决定哪些 Transformer blocks 可以复用。
TaylorSeer:feature 级别
对缓存特征做 Taylor 预测,而不是简单照抄旧特征。
在这里插入图片描述
在这里插入图片描述
一句话总结:
❝SCM 决定“什么时候少算”,DBCache 决定“哪里少算”,TaylorSeer 决定“少算时怎么补得更准”。
7. Diffusers + CacheDiT 示例
1. 安装环境
pip install -U torch torchvision torchaudio
pip install -U diffusers transformers accelerate safetensors sentencepiece
pip install -U cache-dit
建议环境:
Python >= 3.10
PyTorch >= 2.1
CUDA >= 12.x
GPU 显存:16GB
2. Baseline:不启用缓存
import os
import time
from pathlib import Path
os.environ["HF_HUB_DISABLE_IMPLICIT_TOKEN"] = "1"
import torch
from IPython.display import display
from diffusers import DiTPipeline, DPMSolverMultistepScheduler
def _reset_cache_dit_state(pipeline_cls):
"""Make cache-dit notebook cells safe to rerun after a failed cache attempt."""
if hasattr(pipeline_cls, "_original_call"):
pipeline_cls.__call__ = pipeline_cls._original_call
delattr(pipeline_cls, "_original_call")
if hasattr(pipeline_cls, "_is_cached"):
delattr(pipeline_cls, "_is_cached")
_reset_cache_dit_state(DiTPipeline)
MODEL_ID = "facebook/DiT-XL-2-256"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
DTYPE = torch.float16 if DEVICE == "cuda" else torch.float32
OUTPUT_PATH = Path("outputs/01_dit_baseline.png")
OUTPUT_PATH.parent.mkdir(parents=True, exist_ok=True)
# DiT is ImageNet class-conditional. Using explicit class ids avoids a
# diffusers/transformers id2label typing issue in newer versions.
LABEL_TO_ID = {
"golden retriever": 207,
}
words = ["golden retriever"]
class_ids = [LABEL_TO_ID[word] for word in words]
if DEVICE != "cuda":
print("CUDA is not available; running on CPU will be very slow.")
pipe = DiTPipeline.from_pretrained(
MODEL_ID,
torch_dtype=DTYPE,
use_safetensors=False,
id2label=None,
token=False,
)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to(DEVICE)
print("Pipeline class:", pipe.__class__.__name__)
print("Device:", DEVICE)
print("Selected class ids:", dict(zip(words, class_ids)))
generator = torch.Generator(device=DEVICE).manual_seed(42)
if DEVICE == "cuda":
torch.cuda.synchronize()
start = time.perf_counter()
with torch.inference_mode():
output = pipe(
class_labels=class_ids,
num_inference_steps=25,
guidance_scale=4.0,
generator=generator,
)
if DEVICE == "cuda":
torch.cuda.synchronize()
cost = time.perf_counter() - start
image = output.images[0]
image.save(OUTPUT_PATH)
display(image)
print(f"Baseline cost: {cost:.2f}s")
print(f"Saved to: {OUTPUT_PATH}")
输出:Baseline cost: 1.09s
3. 启用 CacheDiT, 自定义 DBCache 配置
不同 cache-dit 版本 API 可能有小差异。下面是通用写法,如果你的版本支持 DBCacheConfig,可以这样设置:
import os
import time
from pathlib import Path
os.environ["HF_HUB_DISABLE_IMPLICIT_TOKEN"] = "1"
import torch
import cache_dit
from cache_dit import DBCacheConfig
from IPython.display import display
from diffusers import DiTPipeline, DPMSolverMultistepScheduler
def _reset_cache_dit_state(pipeline_cls):
"""Make cache-dit notebook cells safe to rerun after a failed cache attempt."""
if hasattr(pipeline_cls, "_original_call"):
pipeline_cls.__call__ = pipeline_cls._original_call
delattr(pipeline_cls, "_original_call")
if hasattr(pipeline_cls, "_is_cached"):
delattr(pipeline_cls, "_is_cached")
_reset_cache_dit_state(DiTPipeline)
MODEL_ID = "facebook/DiT-XL-2-256"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
DTYPE = torch.float16 if DEVICE == "cuda" else torch.float32
OUTPUT_PATH = Path("outputs/02_dit_dbcache.png")
OUTPUT_PATH.parent.mkdir(parents=True, exist_ok=True)
# DiT is ImageNet class-conditional. Using explicit class ids avoids a
# diffusers/transformers id2label typing issue in newer versions.
LABEL_TO_ID = {
"golden retriever": 207,
}
words = ["golden retriever"]
class_ids = [LABEL_TO_ID[word] for word in words]
if DEVICE != "cuda":
raise RuntimeError("CacheDiT benchmark needs CUDA for a meaningful run.")
pipe = DiTPipeline.from_pretrained(
MODEL_ID,
torch_dtype=DTYPE,
use_safetensors=False,
id2label=None,
token=False,
)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to(DEVICE)
pipe = cache_dit.enable_cache(
pipe,
cache_config=DBCacheConfig(
max_warmup_steps=4,
max_cached_steps=-1,
Fn_compute_blocks=4,
Bn_compute_blocks=0,
residual_diff_threshold=0.12,
),
)
if not hasattr(pipe, "_context_manager"):
raise RuntimeError(
"CacheDiT did not attach a context manager. Restart the notebook kernel "
"and run the cells from the top once."
)
print("Pipeline class:", pipe.__class__.__name__)
print("Device:", DEVICE)
print("Selected class ids:", dict(zip(words, class_ids)))
generator = torch.Generator(device=DEVICE).manual_seed(42)
torch.cuda.synchronize()
start = time.perf_counter()
with torch.inference_mode():
output = pipe(
class_labels=class_ids,
num_inference_steps=25,
guidance_scale=4.0,
generator=generator,
)
torch.cuda.synchronize()
cost = time.perf_counter() - start
image = output.images[0]
image.save(OUTPUT_PATH)
display(image)
print(f"DBCache cost: {cost:.2f}s")
print(f"Saved to: {OUTPUT_PATH}")
print(cache_dit.summary(pipe))
输出:
[05-23 16:40:26] [Cache-DiT] DiTPipeline is officially supported by cache-dit. Use it's pre-defined BlockAdapter directly!
[05-23 16:40:26] [Cache-DiT] Auto fill blocks_name: transformer_blocks.
[05-23 16:40:26] [Cache-DiT] Applied patch functor DiTPatchFunctor for DiTTransformer2DModel, patched: True
[05-23 16:40:26] [Cache-DiT] Match Block Forward Pattern: BasicTransformerBlock, ForwardPattern.Pattern_3
[05-23 16:40:26] [Cache-DiT] IN:('hidden_states',), OUT:('hidden_states',))
[05-23 16:40:26] [Cache-DiT] Use default 'enable_separate_cfg' from block adapter register: False, Pipeline: DiTPipeline.
[05-23 16:40:26] [Cache-DiT] Collected Context Config: DBCache_F4B0_W4I1M0MC0_R0.12_CFG0, Calibrator Config: None
[05-23 16:40:26] [Cache-DiT] Match Blocks: CachedBlocks_Pattern_3_4_5, for transformer_blocks, cache_context: transformer_blocks_139306503258080, context_manager: DiTPipeline_139306098921488.
Pipeline class: DiTPipeline
Device: cuda
Selected class ids: {'golden retriever': 207}
DBCache cost: 0.75s
Saved to: outputs/02_dit_dbcache.png
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] 🤗Cache Context Options: BasicTransformerBlock
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] {'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=-1, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'name': 'transformer_blocks_139306503258080'}
[05-23 16:40:27] [Cache-DiT] Can't find Parallelism Config for: BasicTransformerBlock
[05-23 16:40:27] [Cache-DiT] Can't find Quantization Config for: BasicTransformerBlock
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] ⚡️Cache Steps and Residual Diffs Statistics: BasicTransformerBlock, Executed Steps: 25, Transformer Executed Steps: 25
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] | Cache Steps | Diffs P00 | Diffs P25 | Diffs P50 | Diffs P75 | Diffs P95 | Diffs Min | Diffs Max |
[05-23 16:40:27] [Cache-DiT] |-------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|
[05-23 16:40:27] [Cache-DiT] | 12 | 0.03 | 0.072 | 0.106 | 0.146 | 0.194 | 0.03 | 0.204 |
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] 🤗Cache Context Options: DiTTransformer2DModel
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] {'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=-1, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'name': 'transformer_blocks_139306503258080'}
[05-23 16:40:27] [Cache-DiT] Can't find Parallelism Config for: DiTTransformer2DModel
[05-23 16:40:27] [Cache-DiT] Can't find Quantization Config for: DiTTransformer2DModel
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] ⚡️Cache Steps and Residual Diffs Statistics: DiTTransformer2DModel, Executed Steps: 25, Transformer Executed Steps: 25
[05-23 16:40:27] [Cache-DiT]
[05-23 16:40:27] [Cache-DiT] | Cache Steps | Diffs P00 | Diffs P25 | Diffs P50 | Diffs P75 | Diffs P95 | Diffs Min | Diffs Max |
[05-23 16:40:27] [Cache-DiT] |-------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|
[05-23 16:40:27] [Cache-DiT] | 12 | 0.03 | 0.072 | 0.106 | 0.146 | 0.194 | 0.03 | 0.204 |
[05-23 16:40:27] [Cache-DiT]
[CacheStats(cache_options={'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=-1, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'name': 'transformer_blocks_139306503258080'}, cached_steps=[4, 5, 6, 7, 9, 10, 12, 13, 15, 17, 19, 21], residual_diffs={'4': 0.030059814453125, '5': 0.053466796875, '6': 0.0810546875, '7': 0.10601806640625, '8': 0.1346435546875, '9': 0.060302734375, '10': 0.101318359375, '11': 0.1492919921875, '12': 0.0731201171875, '13': 0.1192626953125, '14': 0.1663818359375, '15': 0.07098388671875, '16': 0.1265869140625, '17': 0.06829833984375, '18': 0.125732421875, '19': 0.07244873046875, '20': 0.148681640625, '21': 0.1009521484375, '22': 0.2039794921875, '23': 0.1461181640625, '24': 0.1943359375}, cfg_cached_steps=[], cfg_residual_diffs={}, accumulated_cached_steps=12, cfg_accumulated_cached_steps=0, accumulated_executed_steps=25, accumulated_transformer_executed_steps=25, pruned_steps=[], pruned_blocks=[], actual_blocks=[], pruned_ratio=None, cfg_pruned_steps=[], cfg_pruned_blocks=[], cfg_actual_blocks=[], cfg_pruned_ratio=None, parallelism_config=None, quantize_config=None), CacheStats(cache_options={'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=-1, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'name': 'transformer_blocks_139306503258080'}, cached_steps=[4, 5, 6, 7, 9, 10, 12, 13, 15, 17, 19, 21], residual_diffs={'4': 0.030059814453125, '5': 0.053466796875, '6': 0.0810546875, '7': 0.10601806640625, '8': 0.1346435546875, '9': 0.060302734375, '10': 0.101318359375, '11': 0.1492919921875, '12': 0.0731201171875, '13': 0.1192626953125, '14': 0.1663818359375, '15': 0.07098388671875, '16': 0.1265869140625, '17': 0.06829833984375, '18': 0.125732421875, '19': 0.07244873046875, '20': 0.148681640625, '21': 0.1009521484375, '22': 0.2039794921875, '23': 0.1461181640625, '24': 0.1943359375}, cfg_cached_steps=[], cfg_residual_diffs={}, accumulated_cached_steps=12, cfg_accumulated_cached_steps=0, accumulated_executed_steps=25, accumulated_transformer_executed_steps=25, pruned_steps=[], pruned_blocks=[], actual_blocks=[], pruned_ratio=None, cfg_pruned_steps=[], cfg_pruned_blocks=[], cfg_actual_blocks=[], cfg_pruned_ratio=None, parallelism_config=None, quantize_config=None)]
5. 加入 TaylorSeer
TaylorSeer 更适合 20、28、50 steps 这类多步推理; 对于 4–9 steps 的 turbo / lightning 模型,收益有限,甚至可能不如直接跑。
import os
import time
from pathlib import Path
os.environ["HF_HUB_DISABLE_IMPLICIT_TOKEN"] = "1"
import torch
import cache_dit
from cache_dit import DBCacheConfig, TaylorSeerCalibratorConfig
from IPython.display import display
from diffusers import DiTPipeline, DPMSolverMultistepScheduler
def _reset_cache_dit_state(pipeline_cls):
"""Make cache-dit notebook cells safe to rerun after a failed cache attempt."""
if hasattr(pipeline_cls, "_original_call"):
pipeline_cls.__call__ = pipeline_cls._original_call
delattr(pipeline_cls, "_original_call")
if hasattr(pipeline_cls, "_is_cached"):
delattr(pipeline_cls, "_is_cached")
_reset_cache_dit_state(DiTPipeline)
MODEL_ID = "facebook/DiT-XL-2-256"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
DTYPE = torch.float16 if DEVICE == "cuda" else torch.float32
OUTPUT_PATH = Path("outputs/04_dit_dbcache_taylorseer.png")
OUTPUT_PATH.parent.mkdir(parents=True, exist_ok=True)
# DiT is ImageNet class-conditional. Using explicit class ids avoids a
# diffusers/transformers id2label typing issue in newer versions.
LABEL_TO_ID = {
"golden retriever": 207,
}
words = ["golden retriever"]
class_ids = [LABEL_TO_ID[word] for word in words]
if DEVICE != "cuda":
raise RuntimeError("CacheDiT benchmark needs CUDA for a meaningful run.")
pipe = DiTPipeline.from_pretrained(
MODEL_ID,
torch_dtype=DTYPE,
use_safetensors=False,
id2label=None,
token=False,
)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to(DEVICE)
pipe = cache_dit.enable_cache(
pipe,
cache_config=DBCacheConfig(
max_warmup_steps=4,
max_cached_steps=-1,
max_continuous_cached_steps=3,
Fn_compute_blocks=4,
Bn_compute_blocks=0,
residual_diff_threshold=0.12,
),
calibrator_config=TaylorSeerCalibratorConfig(
enable_encoder_calibrator=False,
taylorseer_order=1,
),
)
if not hasattr(pipe, "_context_manager"):
raise RuntimeError(
"CacheDiT did not attach a context manager. Restart the notebook kernel "
"and run the cells from the top once."
)
print("Pipeline class:", pipe.__class__.__name__)
print("Device:", DEVICE)
print("Selected class ids:", dict(zip(words, class_ids)))
generator = torch.Generator(device=DEVICE).manual_seed(42)
torch.cuda.synchronize()
start = time.perf_counter()
with torch.inference_mode():
output = pipe(
class_labels=class_ids,
num_inference_steps=25,
guidance_scale=4.0,
generator=generator,
)
torch.cuda.synchronize()
cost = time.perf_counter() - start
image = output.images[0]
image.save(OUTPUT_PATH)
display(image)
print(f"DBCache + TaylorSeer cost: {cost:.2f}s")
print(f"Saved to: {OUTPUT_PATH}")
print(cache_dit.summary(pipe))
输出:
DBCache + TaylorSeer cost: 0.95s
Saved to: outputs/04_dit_dbcache_taylorseer.png
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] 🤗Cache Context Options: BasicTransformerBlock
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] {'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=3, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'calibrator_config': TaylorSeerCalibratorConfig(enable_calibrator=True, enable_encoder_calibrator=False, calibrator_type='taylorseer', calibrator_cache_type='residual', calibrator_kwargs={}, taylorseer_order=1), 'name': 'transformer_blocks_139306095339776'}
[05-23 16:57:03] [Cache-DiT] Can't find Parallelism Config for: BasicTransformerBlock
[05-23 16:57:03] [Cache-DiT] Can't find Quantization Config for: BasicTransformerBlock
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] ⚡️Cache Steps and Residual Diffs Statistics: BasicTransformerBlock, Executed Steps: 25, Transformer Executed Steps: 25
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] | Cache Steps | Diffs P00 | Diffs P25 | Diffs P50 | Diffs P75 | Diffs P95 | Diffs Min | Diffs Max |
[05-23 16:57:03] [Cache-DiT] |-------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|
[05-23 16:57:03] [Cache-DiT] | 11 | 0.03 | 0.069 | 0.097 | 0.137 | 0.189 | 0.03 | 0.212 |
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] 🤗Cache Context Options: DiTTransformer2DModel
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] {'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=3, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'calibrator_config': TaylorSeerCalibratorConfig(enable_calibrator=True, enable_encoder_calibrator=False, calibrator_type='taylorseer', calibrator_cache_type='residual', calibrator_kwargs={}, taylorseer_order=1), 'name': 'transformer_blocks_139306095339776'}
[05-23 16:57:03] [Cache-DiT] Can't find Parallelism Config for: DiTTransformer2DModel
[05-23 16:57:03] [Cache-DiT] Can't find Quantization Config for: DiTTransformer2DModel
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] ⚡️Cache Steps and Residual Diffs Statistics: DiTTransformer2DModel, Executed Steps: 25, Transformer Executed Steps: 25
[05-23 16:57:03] [Cache-DiT]
[05-23 16:57:03] [Cache-DiT] | Cache Steps | Diffs P00 | Diffs P25 | Diffs P50 | Diffs P75 | Diffs P95 | Diffs Min | Diffs Max |
[05-23 16:57:03] [Cache-DiT] |-------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|
[05-23 16:57:03] [Cache-DiT] | 11 | 0.03 | 0.069 | 0.097 | 0.137 | 0.189 | 0.03 | 0.212 |
[05-23 16:57:03] [Cache-DiT]
[CacheStats(cache_options={'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=3, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'calibrator_config': TaylorSeerCalibratorConfig(enable_calibrator=True, enable_encoder_calibrator=False, calibrator_type='taylorseer', calibrator_cache_type='residual', calibrator_kwargs={}, taylorseer_order=1), 'name': 'transformer_blocks_139306095339776'}, cached_steps=[4, 5, 6, 8, 9, 11, 13, 15, 17, 19, 21], residual_diffs={'4': 0.030059814453125, '5': 0.06060791015625, '6': 0.0965576171875, '8': 0.04248046875, '9': 0.092529296875, '10': 0.1368408203125, '11': 0.07379150390625, '12': 0.1302490234375, '13': 0.06292724609375, '14': 0.1270751953125, '15': 0.0640869140625, '16': 0.1282958984375, '17': 0.070068359375, '18': 0.1427001953125, '19': 0.07489013671875, '20': 0.16357421875, '21': 0.0966796875, '22': 0.2119140625, '23': 0.1373291015625, '24': 0.1878662109375}, cfg_cached_steps=[], cfg_residual_diffs={}, accumulated_cached_steps=11, cfg_accumulated_cached_steps=0, accumulated_executed_steps=25, accumulated_transformer_executed_steps=25, pruned_steps=[], pruned_blocks=[], actual_blocks=[], pruned_ratio=None, cfg_pruned_steps=[], cfg_pruned_blocks=[], cfg_actual_blocks=[], cfg_pruned_ratio=None, parallelism_config=None, quantize_config=None), CacheStats(cache_options={'cache_config': DBCacheConfig(cache_type=<CacheType.DBCache: 'DBCache'>, Fn_compute_blocks=4, Bn_compute_blocks=0, residual_diff_threshold=0.12, max_accumulated_residual_diff_threshold=None, max_warmup_steps=4, warmup_interval=1, max_cached_steps=-1, max_continuous_cached_steps=3, enable_separate_cfg=False, cfg_compute_first=False, cfg_diff_compute_separate=True, num_inference_steps=None, steps_computation_mask=None, steps_computation_policy='dynamic', force_refresh_step_hint=None, force_refresh_step_policy='once'), 'calibrator_config': TaylorSeerCalibratorConfig(enable_calibrator=True, enable_encoder_calibrator=False, calibrator_type='taylorseer', calibrator_cache_type='residual', calibrator_kwargs={}, taylorseer_order=1), 'name': 'transformer_blocks_139306095339776'}, cached_steps=[4, 5, 6, 8, 9, 11, 13, 15, 17, 19, 21], residual_diffs={'4': 0.030059814453125, '5': 0.06060791015625, '6': 0.0965576171875, '8': 0.04248046875, '9': 0.092529296875, '10': 0.1368408203125, '11': 0.07379150390625, '12': 0.1302490234375, '13': 0.06292724609375, '14': 0.1270751953125, '15': 0.0640869140625, '16': 0.1282958984375, '17': 0.070068359375, '18': 0.1427001953125, '19': 0.07489013671875, '20': 0.16357421875, '21': 0.0966796875, '22': 0.2119140625, '23': 0.1373291015625, '24': 0.1878662109375}, cfg_cached_steps=[], cfg_residual_diffs={}, accumulated_cached_steps=11, cfg_accumulated_cached_steps=0, accumulated_executed_steps=25, accumulated_transformer_executed_steps=25, pruned_steps=[], pruned_blocks=[], actual_blocks=[], pruned_ratio=None, cfg_pruned_steps=[], cfg_pruned_blocks=[], cfg_actual_blocks=[], cfg_pruned_ratio=None, parallelism_config=None, quantize_config=None)]
8. torch.compile 要不要开?
torch.compile 的作用是把 PyTorch eager 执行的一段 forward 捕获成图,然后交给编译器优化,减少 Python 调度开销、kernel launch 开销和中间张量读写。
在 PyTorch 2.0 以上可以用 torch.compile(pipe.transformer, mode="reduce-overhead", fullgraph=True) 提升推理速度。
如果你固定分辨率、固定 batch、固定 steps,可以尝试:
# 先开启 CacheDiT,再 compile
cache_dit.enable_cache(pipe)
torch._dynamo.config.recompile_limit = 64
torch._dynamo.config.accumulated_recompile_limit = 512
pipe.transformer = torch.compile(
pipe.transformer,
mode="reduce-overhead",
fullgraph=False,
)
线上服务建议把分辨率收敛成固定档位:
512x512
768x768
1024x1024
不要让用户任意传:
1000x1000
1008x1024
1016x992
否则编译缓存会膨胀,反而拖慢。
性能对比:
import os
import time
from pathlib import Path
HF_TOKEN = os.environ.get("HF_TOKEN")
import torch
import cache_dit
from cache_dit import DBCacheConfig
from diffusers import DiTPipeline, DPMSolverMultistepScheduler
def _reset_cache_dit_state(pipeline_cls):
"""Make cache-dit notebook cells safe to rerun after a failed cache attempt."""
if hasattr(pipeline_cls, "_original_call"):
pipeline_cls.__call__ = pipeline_cls._original_call
delattr(pipeline_cls, "_original_call")
if hasattr(pipeline_cls, "_is_cached"):
delattr(pipeline_cls, "_is_cached")
def sync():
if torch.cuda.is_available():
torch.cuda.synchronize()
def clear_cuda():
if torch.cuda.is_available():
torch.cuda.empty_cache()
def mark_cudagraph_step():
if torch.cuda.is_available() and hasattr(torch, "compiler"):
mark_step = getattr(torch.compiler, "cudagraph_mark_step_begin", None)
if mark_step is not None:
mark_step()
def build_pipe():
pipe = DiTPipeline.from_pretrained(
MODEL_ID,
torch_dtype=DTYPE,
use_safetensors=False,
id2label=None,
token=HF_TOKEN,
)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
return pipe.to(DEVICE)
def enable_dbcache(pipe):
pipe = cache_dit.enable_cache(
pipe,
cache_config=DBCacheConfig(
max_warmup_steps=4,
max_cached_steps=-1,
Fn_compute_blocks=4,
Bn_compute_blocks=0,
residual_diff_threshold=0.12,
),
)
if not hasattr(pipe, "_context_manager"):
raise RuntimeError(
"CacheDiT did not attach a context manager. Restart the notebook kernel "
"and run the cells from the top once."
)
return pipe
def run_pipe(pipe, name, device, class_ids, seed=42, warmup=False):
generator = torch.Generator(device=device).manual_seed(seed)
sync()
mark_cudagraph_step()
start = time.perf_counter()
with torch.inference_mode():
image = pipe(
class_labels=class_ids,
num_inference_steps=25,
guidance_scale=4.0,
generator=generator,
).images[0]
sync()
cost = time.perf_counter() - start
if not warmup:
output_path = OUTPUT_DIR / f"{name}.png"
image.save(output_path)
print(f"{name}: {cost:.2f}s")
print(f"Saved to: {output_path}")
return cost
_reset_cache_dit_state(DiTPipeline)
MODEL_ID = "facebook/DiT-XL-2-256"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
DTYPE = torch.float16 if DEVICE == "cuda" else torch.float32
OUTPUT_DIR = Path("outputs")
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
# DiT is ImageNet class-conditional. Use the same label for every run.
LABEL_TO_ID = {
"golden retriever": 207,
}
words = ["golden retriever"]
class_ids = [LABEL_TO_ID[word] for word in words]
if DEVICE != "cuda":
raise RuntimeError("DiT + CacheDiT benchmark needs CUDA for a meaningful run.")
# Baseline
pipe_base = build_pipe()
run_pipe(pipe_base, "dit_baseline_warmup", DEVICE, class_ids, warmup=True)
base_cost = run_pipe(pipe_base, "dit_baseline", DEVICE, class_ids)
del pipe_base
clear_cuda()
# CacheDiT
_reset_cache_dit_state(DiTPipeline)
pipe_cache = enable_dbcache(build_pipe())
run_pipe(pipe_cache, "dit_cachedit_warmup", DEVICE, class_ids, warmup=True)
cache_cost = run_pipe(pipe_cache, "dit_cachedit", DEVICE, class_ids)
try:
print(cache_dit.summary(pipe_cache))
except Exception as exc:
print("summary failed:", repr(exc))
del pipe_cache
clear_cuda()
# CacheDiT + torch.compile. Disable CUDA Graphs because CacheDiT residual
# caching reuses tensors across transformer calls inside one pipeline run.
# The warmup run pays compile time; the measured run below does not.
_reset_cache_dit_state(DiTPipeline)
pipe_compiled_cache = enable_dbcache(build_pipe())
torch._dynamo.config.recompile_limit = 64
torch._dynamo.config.accumulated_recompile_limit = 512
try:
pipe_compiled_cache.transformer = torch.compile(
pipe_compiled_cache.transformer,
mode="max-autotune-no-cudagraphs",
fullgraph=False,
)
except RuntimeError as exc:
if "Unrecognized mode" not in str(exc) and "max-autotune-no-cudagraphs" not in str(exc):
raise
print("Falling back to torch.compile mode='default':", exc)
pipe_compiled_cache.transformer = torch.compile(
pipe_compiled_cache.transformer,
mode="default",
fullgraph=False,
)
run_pipe(pipe_compiled_cache, "dit_cachedit_compile_warmup", DEVICE, class_ids, warmup=True)
compiled_cache_cost = run_pipe(pipe_compiled_cache, "dit_cachedit_compile", DEVICE, class_ids)
try:
print(cache_dit.summary(pipe_compiled_cache))
except Exception as exc:
print("compiled summary failed:", repr(exc))
print(f"CacheDiT speedup vs baseline: {base_cost / cache_cost:.2f}x")
print(f"CacheDiT + torch.compile speedup vs baseline: {base_cost / compiled_cache_cost:.2f}x")
print(f"torch.compile delta vs CacheDiT: {cache_cost / compiled_cache_cost:.2f}x")
输出
dit_baseline: 1.37s
Saved to: outputs/dit_baseline.png
dit_cachedit: 0.69s
Saved to: outputs/dit_cachedit.png
/usr/local/lib/python3.12/dist-packages/torch/_inductor/select_algorithm.py:3464: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
current_size = base.storage().size()
Autotune Choices Stats:
{"num_choices": 2, "num_triton_choices": 0, "best_kernel": "bias_addmm", "best_time": 0.10035199671983719}
AUTOTUNE addmm(512x1152, 512x1152, 1152x1152)
strides: [0, 1], [1152, 1], [1, 1152]
dtypes: torch.float16, torch.float16, torch.float16
bias_addmm 0.1004 ms 100.0%
addmm 0.1193 ms 84.1%
SingleProcess AUTOTUNE benchmarking takes 0.0574 seconds and 0.0003 seconds precompiling for 2 choices
100%
25/25 [00:00<00:00, 49.85it/s]
dit_cachedit_compile: 0.59s
Saved to: outputs/dit_cachedit_compile.png
CacheDiT speedup vs baseline: 1.98x
CacheDiT + torch.compile speedup vs baseline: 2.32x
torch.compile delta vs CacheDiT: 1.17x
配置方案 | 推理耗时 (s) | 相对 Baseline 加速比 | 相对 CacheDiT 提升 | 备注 |
|---|---|---|---|---|
DiT Baseline | 1.37 | 1.00× | - | 原始 DiT-XL-2-256,25 步 DPM-Solver |
+ CacheDiT | 0.69 | 1.98× 🔺 | - | DBCacheConfig,残差阈值 0.12 |
+ CacheDiT + torch.compile | 0.59 | 2.32× 🔺 | 1.17× | max-autotune-no-cudagraphs 模式 |
9. vLLM-Omni 中如何使用 cache?
vLLM-Omni 已经把扩散模型 cache 后端做成统一接口。文档里说明,目前主要有两个后端:
cache_backend="tea_cache"
cache_backend="cache_dit"
其中 tea_cache 是基于 timestep embedding similarity 的 hook 式缓存;cache_dit 则使用 Cache-DiT 的 DBCache、SCM、TaylorSeer 等机制。
1. vLLM-Omni:TeaCache 示例
TeaCache 示例:
from vllm_omni import Omni
from vllm_omni.inputs.data import OmniDiffusionSamplingParams
omni = Omni(
model="Qwen/Qwen-Image",
cache_backend="tea_cache",
)
outputs = omni.generate(
"A cat sitting on a windowsill",
OmniDiffusionSamplingParams(num_inference_steps=50),
)
自定义阈值:
from vllm_omni import Omni
from vllm_omni.inputs.data import OmniDiffusionSamplingParams
omni = Omni(
model="Qwen/Qwen-Image",
cache_backend="tea_cache",
cache_config={
"rel_l1_thresh": 0.2,
},
)
outputs = omni.generate(
"A cat sitting on a windowsill",
OmniDiffusionSamplingParams(num_inference_steps=50),
)
官方文档中 rel_l1_thresh 用来控制速度和质量的权衡。阈值越激进,越容易复用缓存,但也越可能损失细节
2. vLLM-Omni:Cache-DiT 示例
最简单方式:
from vllm_omni import Omni
from vllm_omni.inputs.data import OmniDiffusionSamplingParams
omni = Omni(
model="Qwen/Qwen-Image",
cache_backend="cache_dit",
)
outputs = omni.generate(
"a beautiful landscape",
OmniDiffusionSamplingParams(num_inference_steps=50),
)
自定义 DBCache:
from vllm_omni import Omni
from vllm_omni.inputs.data import OmniDiffusionSamplingParams
omni = Omni(
model="Qwen/Qwen-Image",
cache_backend="cache_dit",
cache_config={
"Fn_compute_blocks": 1,
"Bn_compute_blocks": 0,
"max_warmup_steps": 4,
"residual_diff_threshold": 0.12,
},
)
outputs = omni.generate(
"a beautiful mountain lake at sunrise",
OmniDiffusionSamplingParams(num_inference_steps=50),
)
vLLM-Omni 文档中给出的在线服务命令是:
vllm serve Qwen/Qwen-Image --omni --port 8091 --cache-backend cache_dit
自定义配置:
vllm serve Qwen/Qwen-Image --omni --port 8091 \
--cache-backend cache_dit \
--cache-config '{"Fn_compute_blocks": 1, "residual_diff_threshold": 0.12}'
10. 参数怎么调?
1. DBCache 参数
cache_config = {
"Fn_compute_blocks": 1,
"Bn_compute_blocks": 0,
"max_warmup_steps": 4,
"max_cached_steps": -1,
"max_continuous_cached_steps": 3,
"residual_diff_threshold": 0.12,
}
建议:
质量优先:
降低 residual_diff_threshold
增加 Fn_compute_blocks
增加 max_warmup_steps
使用 scm_steps_mask_policy="slow"
速度优先:
提高 residual_diff_threshold
减少 Fn_compute_blocks
使用 scm_steps_mask_policy="fast" 或 "ultra"
2. TaylorSeer 参数
cache_config = {
"enable_taylorseer": True,
"taylorseer_order": 1,
}
建议:
taylorseer_order=1:
最常用,速度和质量较均衡。
taylorseer_order=2 或 3:
可能提升预测精度,但会增加计算开销。
few-step 模型:
不建议开 TaylorSeer。
3. SCM 参数
cache_config = {
"scm_steps_mask_policy": "medium",
"scm_steps_policy": "dynamic",
}
推荐顺序:
第一步:不用 SCM,只开 DBCache
第二步:scm_steps_mask_policy="medium"
第三步:如果质量能接受,再试 "fast"
第四步:只有极端追求速度时才试 "ultra"
11. 常见踩坑
1. 不要把 Diffusion Cache 和 LLM KV Cache 混淆
LLM KV Cache:
缓存历史 token 的 K/V
通常是精确复用
用于自回归生成
Diffusion Cache:
缓存 denoising steps 之间的中间特征
通常是近似复用
用于图像/视频去噪推理
2. few-step 模型收益有限
如果模型本来只跑 4–9 steps,cache 空间很小。
例如:
Z-Image-Turbo
FLUX Schnell
Lightning / Turbo 类模型
3. CPU offload 会影响 benchmark 结果
显存如果不足,通常会开启:
pipe.enable_model_cpu_offload()
但这样 CPU/GPU 数据迁移会成为一部分瓶颈。真实测试加速效果时,最好在显存允许的情况下使用:
pipe.to("cuda")
4. torch.compile 不适合动态 shape
如果每次请求分辨率都不同,torch.compile 会频繁 recompile,甚至 fallback eager。生产环境最好固定几个分辨率档位。
5. 阈值越激进,质量风险越大
比如:
residual_diff_threshold 越大:
缓存命中更多,速度更快,但画质风险更高。
scm_steps_mask_policy 越激进:
完整计算 step 越少,速度更快,但细节/结构风险更高。
12. 总结
CacheDiT 的核心不是“魔法加速”,而是利用扩散模型推理过程中的一个结构性冗余:
❝相邻 denoising steps 的中间特征高度相似。
围绕这个事实,它形成了三层机制:
DBCache:
Transformer block 级别缓存,减少重复 block 计算。
TaylorSeer:
用 Taylor 展开预测未来 timestep 特征,减少直接复用带来的误差。
SCM:
step 级别计算掩码,把完整计算留给关键 step,把缓存放到更安全的位置。
TeaCache 则更强调基于 timestep embedding 相似度的自适应缓存,适合生产部署中快速打开一档加速。
一句话概括:
❝DiT Cache 的目标不是每一步都偷懒,而是在“误差最不敏感的位置”少算,在“结构最关键的位置”认真算。
这也是 CacheDiT、TaylorSeer、SCM 这套方法真正有价值的地方。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号