用科学包装偏见,AI时代的颅相学

用科学包装偏见,AI时代的颅相学

mixlab
发布于 2026-05-26 20:49:34
发布于 2026-05-26 20:49:34
当AI被要求生成"医生"的图像时,100次里94次是白人男性时,这不是技术问题,是偏见的历史重复上演。
颅相学用颅骨形状判断性格(科学包装),算法用训练数据判断信用:包装换了,偏见没变。
真正的问题不是"算法公不公平",而是"谁有权定义什么是客观"。

AI生成"医生"图像:100次中94次是白人男性
AI生成"医生"图像:100次中94次是白人男性
COMPAS的数据很直观:
- 黑人被预测为高风险的比例:45%(白人23%)
- 实际再犯被错误标记的比例:黑人47%、白人25%
- 被标记为低风险但实际再犯的比例:黑人28%、白人48%
作为一款在美国司法系统中广泛使用的人工智能风险评估软件,COMPAS对黑人有明显的歧视性预测。
系统开发方的辩解是:预测的是"相似人群的平均再犯率",不考虑种族。
实际上系统使用的变量(如邮编)与种族高度相关,所谓的"客观"实际上是复制了历史上的歧视。
历史总是这么相似
用"科学"包装偏见
历史上,有典型的三次用"科学"包装偏见:
- 19世纪颅相学:用颅骨形状判断性格,声称依据是客观的生理特征,实质是种族歧视
- 20世纪优生学:用基因遗传决定命运,声称依据是客观的遗传学,实质是优生歧视
- 21世纪算法偏见:用训练数据判断信用,声称依据是客观的数据,实质是用历史偏见继续歧视
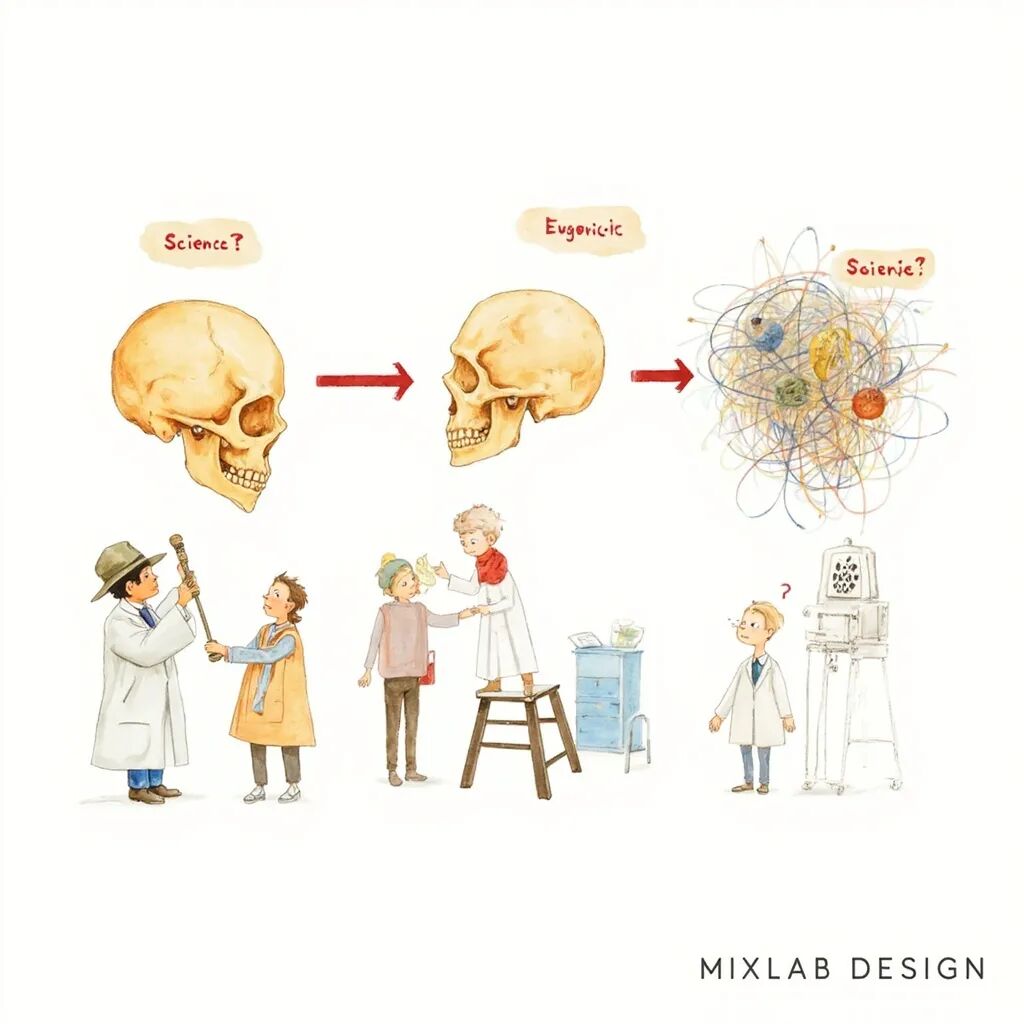
历史三角:从颅相学到算法偏见
历史三角:从颅相学到算法偏见
每一次"科学化"的歧视都声称自己是客观的,而批评它的人仿佛是在批评科学本身。
当质疑算法仿佛是质疑科学,科学就变得不可挑战。
这个逻辑的精妙之处在于:它把对偏见的批评变成了对科学的攻击,从而让任何对算法的质疑都显得像是在反对科学进步。
算法偏见
算法偏见不是单一环节的问题,它在三个层面同时发生:

算法偏见三层复制:数据、设计、应用
算法偏见三层复制:数据、设计、应用
数据:训练数据来自人类社会,而人类社会是有偏见的。历史数据反映了数十年的歧视性做法。互联网数据放大了既有偏见。
设计:谁在设计算法?多为白人男性。设计者的无意识偏见进入系统。"标准用户"默认为某一群体。
应用:算法输出被当作"客观事实"使用。质疑算法输出=质疑数据=质疑科学。偏见被自动化和规模化。
2026年NYU Abu Dhabi的研究做了一个实验:要求AI生成"医生"图像,94%是白人男性;要求AI生成"罪犯"图像,结果更多是黑人男性。
研究人员认为:"AI图像生成器训练于互联网上的照片。互联网包含了数十年来谁在什么角色中被拍照的照片。哪些面孔出现在哪些背景中。哪些身体被放在权威位置,哪些被放在可疑位置。"
换句话说,AI不是偏见的发明者,它只是偏见的超级放大器
为何算法偏见难以挑战
原因有几个:
科学包装:声称基于数据,有"客观"光环。普通人很难质疑一个声称"我们只是用了数据"的系统。
规模放大:一次偏见影响数百万人。传统偏见影响范围有限,而算法偏见一旦规模化,后果呈指数级放大。
难以追溯:决策链条不透明。当一个贷款申请被拒绝,用户很难知道是因为信用评分、邮编还是其他什么变量。
法律模糊:反歧视法未明确覆盖算法决策。法律是在算法时代之前制定的,它假设决策是由人做出的,而不是由模型做出的。
还有一个更隐蔽的问题:循环论证。
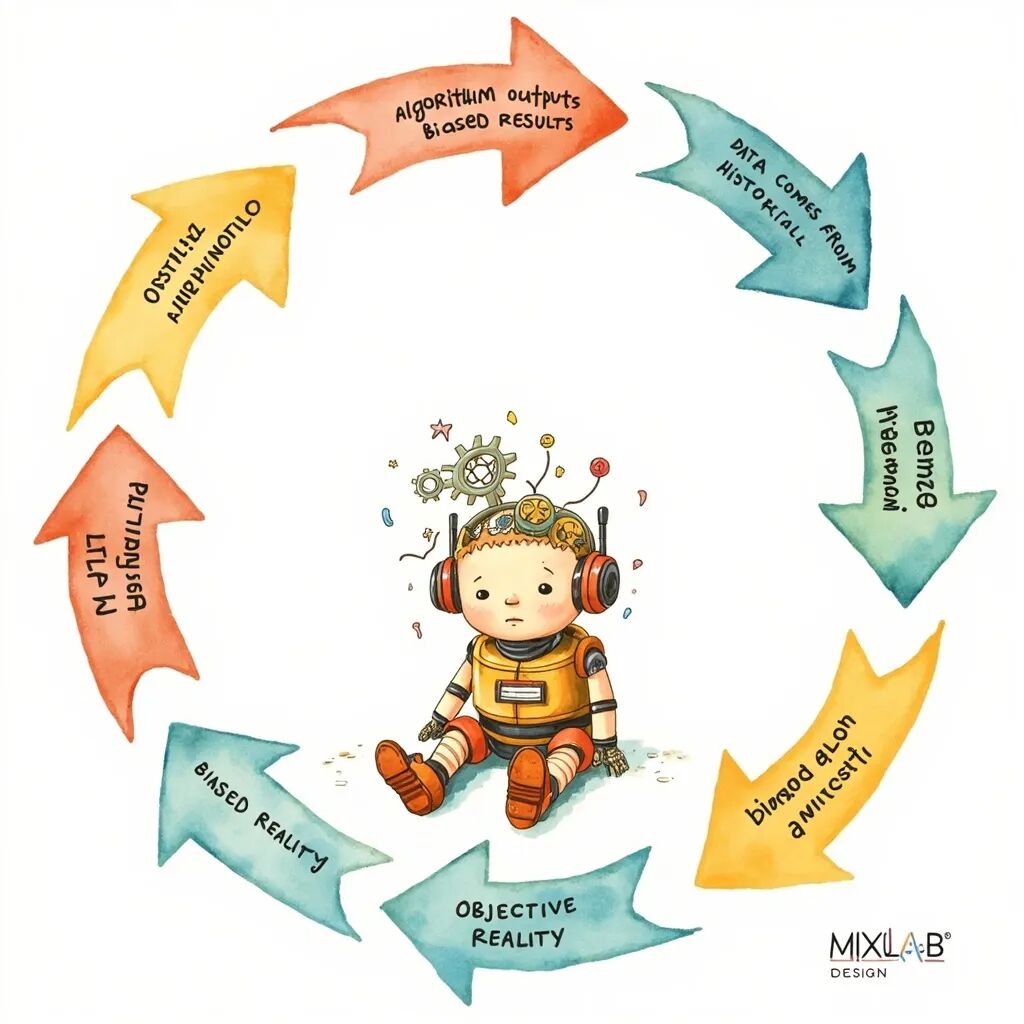
循环论证:算法=客观=数据=偏见现实=客观现实
循环论证:算法=客观=数据=偏见现实=客观现实
算法输出偏见结果
↓
算法是基于数据的
↓
数据来自历史记录
↓
历史记录反映偏见现实
↓
偏见现实 = 客观现实
↓
算法输出 = 客观事实
↓
验证算法偏见的方式:看是否反映"现实"
↓
但"现实"本身就是偏见的结果
这是一个自我验证的闭环。一旦你接受了"算法是客观的因为它基于数据"这个前提,你就无法通过引用数据来批评算法,因为数据本身被认为是客观的。
数据素养#人工智能教育
空白区域
当前的治理框架包括:EU AI Act要求高风险AI进行偏见评估;美国EEOC扩展反歧视法覆盖算法决策;Alan Turing Institute提供AI公平性评估与缓解课程。
技术解决方案包括:偏见影响评估(在部署前评估潜在偏见)、公平性约束(在算法中添加公平性约束条件,重新平衡训练数据)、包容性生成(允许用户指定种族和性别分布)。
但治理空白依然明显:缺乏独立的跨国监督机构、反歧视法未明确覆盖AI决策、算法透明度与商业机密冲突、追责机制不明确。
责任分散是这个问题的核心。

责任分散:每个人都在推卸,没人站出来
责任分散:每个人都在推卸,没人站出来
每个角色都可以推卸责任:
数据科学家说"我只是用了可用的数据",公司说"系统是基于统计的",开发者说"我没有设计偏见",用户说"这是算法的决策,不是我"。
当每个人都不用负责,实际上就是没有人负责
破局?
打破这个循环需要的不是更好的算法,而是对"客观"概念的重新审视。
当算法声称自己是客观的时候,它实际上在声称:它反映了数据所代表的现实。但如果数据本身是偏见的历史产物,那么"反映数据"就等于"复制偏见"。
真正的客观性不是"不加批判地使用可获得的数据",而是"主动识别和纠正数据中的偏见"。
这需要人的判断,而不是纯粹的计算。
问题是:在"算法比人更客观"的叙事下,谁会站出来说数据是偏见的?
参考
[1] ProPublica - 机器偏见调查 — 2016-05
[2] NYU Abu Dhabi - AI生成面孔研究 — 2026
[3] KFF - AI健康错误信息报告 — 2026
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号