从硬件到软件:揭秘Linux文件系统EXT的精妙设计
原创
从硬件到软件:揭秘Linux文件系统EXT的精妙设计
原创
曾高飞
发布于 2026-05-27 21:34:13
发布于 2026-05-27 21:34:13
引言
文件系统是操作系统中看似平常却极为精妙的一环,我们可以从几个简单的问题开始,慢慢走进它的世界。 系统中所有的文件都被打开了吗?其实不是。绝大多数文件都处于“安静”的状态,静静地躺在磁盘或固态硬盘上,这些存储设备为它们提供了永久的容身之所。那么,操作系统需要管理磁盘上这些沉睡的文件吗?当然需要,而且目的非常明确——就是为了能快速、准确地定位到某一个文件。 接下来的问题就是:如何把海量的文件更合理、更高效地规划在磁盘上,让我们能瞬间找到它们?答案就藏在日常再熟悉不过的“目录”里。文件在磁盘上呈现为一种树状的目录结构,而我们寻找文件的过程,就具象成了路径——无论是绝对路径还是相对路径。正是文件系统,在背后默默支撑起了这套高效的检索机制。 带着这些思考,我们先从硬件开始谈起
1. 理解硬件
1.1 磁盘
在计算机体系结构中,磁盘属于外设,也是一种精密的机械设备。凭借容量大、成本低的优势,它被广泛应用于企业级数据存储。

一块磁盘内部包含多个盘面和对应的磁头,两者一一对应。盘面负责以磁信号的形式存储数据,可读可写(这与只读的光盘有所区别)。盘面、磁头、磁道(柱面)以及扇区,各自都有唯一的编号,共同构成寻址体系。
工作时,盘面高速旋转,磁头则在盘面上方来回摆动,这个过程就叫寻址——磁头移动到指定位置进行读写操作。正因为是机械设备,磁盘在使用中有几点必须注意:
- 怕震动:开机状态下严禁搬运或强烈震动,否则磁头可能与盘面发生碰撞,导致物理损坏和数据丢失。
- 怕灰尘:磁盘内部必须保持高度无尘,微小尘埃都可能划伤盘面,造成数据损失。
最后,扇区是磁盘 I/O 的基本单位,每个扇区大小通常固定为 512 字节。不过要注意,这不一定是操作系统和磁盘交互时的 I/O 基本单位。
1.2 磁盘存储结构
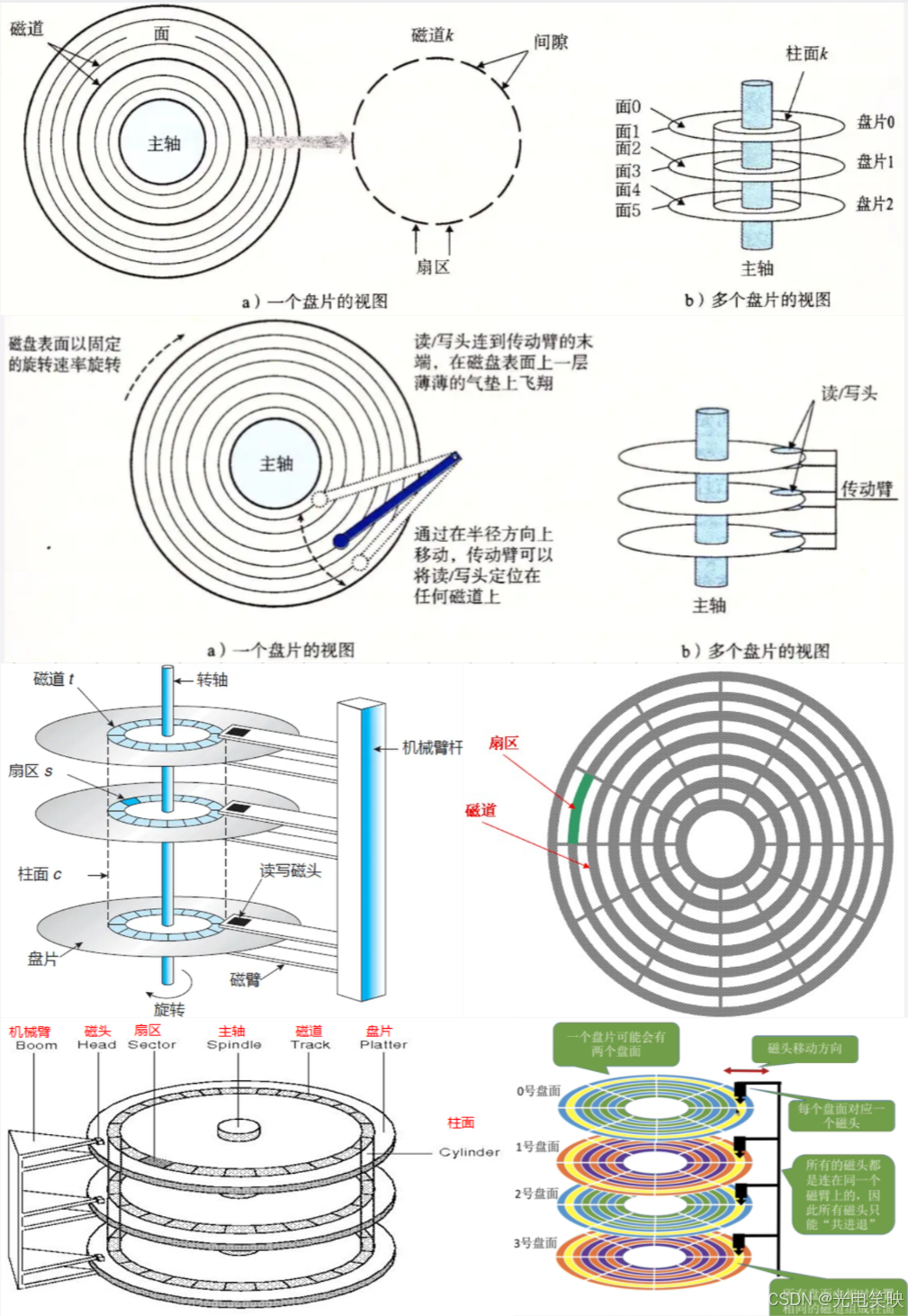
既然磁盘在写入时往往是向整个柱面批量进行的,那要如何精确找到磁盘上的某一个扇区呢?最经典的方法就是 CHS 寻址法。
CHS 是三个维度的缩写,它利用了磁盘物理结构的三个层级编号,就像用三维坐标来锁定一个点:
- C(Cylinder,柱面):先确定数据在哪个柱面,这对应了磁头臂需要把磁头移动到哪一圈。
- H(Head,磁头):柱面确定后,再指定由哪个盘面的磁头来读写,这实际上选定了具体的盘面。
- S(Sector,扇区):盘面也定好了,最后就等盘片旋转,让目标扇区转到磁头下方。
因此,一个扇区的地址就表示为 (柱面号, 磁头号, 扇区号)。早期磁盘就是靠这套“三维坐标”来定位物理扇区的,直观且直接对应硬件结构。
磁盘容量=磁头数 × 磁道(柱⾯)数 × 每道扇区数 × 每扇区字节数
我们可以用 fdisk -l 查看所有磁盘及分区信息,下面举几个关键信息 1. 扇区信息 Units: sectors of 1 * 512 = 512 bytesSector size (logical/physical): 512 bytes / 512 bytesI/O size (minimum/optimal): 512 bytes / 512 bytes一键获取完整项目代码cpp 结论: 扇区是磁盘 I/O 的最小单位确认为 512 字节。 2. 真实物理磁盘
/dev/vdaDisk /dev/vda: 40 GiB, 42949672960 bytes, 83886080 sectorsDisklabel type: gpt一键获取完整项目代码cpp 关键信息:
- 总容量:40 GiB
- 总扇区数:83,886,080 个扇区
- 分区表类型:GPT
- 分区布局
/dev/vda的三个分区 设备起始扇区结束扇区扇区数大小类型/dev/vda12048409520481MBIOS boot/dev/vda24096413695409600200MEFI System/dev/vda3413696838860468347235139.8GLinux filesystem 结论: - vda1:为兼容传统 BIOS 启动预留。
- vda2:GPT 磁盘的 EFI 系统分区,存放引导文件。
- vda3:Linux 文件系统分区,容量约 40G,这是创建 Ext 文件系统的“舞台”
1.3 磁盘的逻辑结构

磁带上⾯可以存储数据,我们可以把磁带“拉直”,形成线性结构

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在⼀起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

CHS 寻址虽然直观,但它有一个致命的缺陷:通过三维坐标 (柱面, 磁头, 扇区) 来定位扇区,不仅复杂,而且受限于磁盘的物理结构。随着磁盘容量不断增长,老旧的 CHS 寻址方式能表示的扇区数早已不够用了。于是,LBA(Logical Block Addressing,逻辑块寻址) 应运而生。
核心思想
LBA 放弃了对物理结构的直接描述,它把磁盘上所有的扇区视作一个线性序列,从 0 开始,为每个扇区分配一个唯一的逻辑编号。这样一来,定位一个扇区就变得非常简单:只需要给出它的 LBA 地址,硬盘控制器内部就会自动将这个逻辑编号转换成实际的物理位置(柱面、磁头、扇区)。
建立于这种线性扇区地址之上就是LBA(Logical Block Addressing)——它们不再关心磁头、柱面这些物理概念
在深入 LBA 之前,我们先重新审视一下磁盘的真实结构。
柱⾯是⼀个逻辑上的概念,其实就是每⼀⾯上,相同半径的磁道逻辑上构成柱⾯。
所以,磁盘物理上分了很多⾯,但是在我们看来,逻辑上,磁盘整体是由“柱⾯”卷起来的。
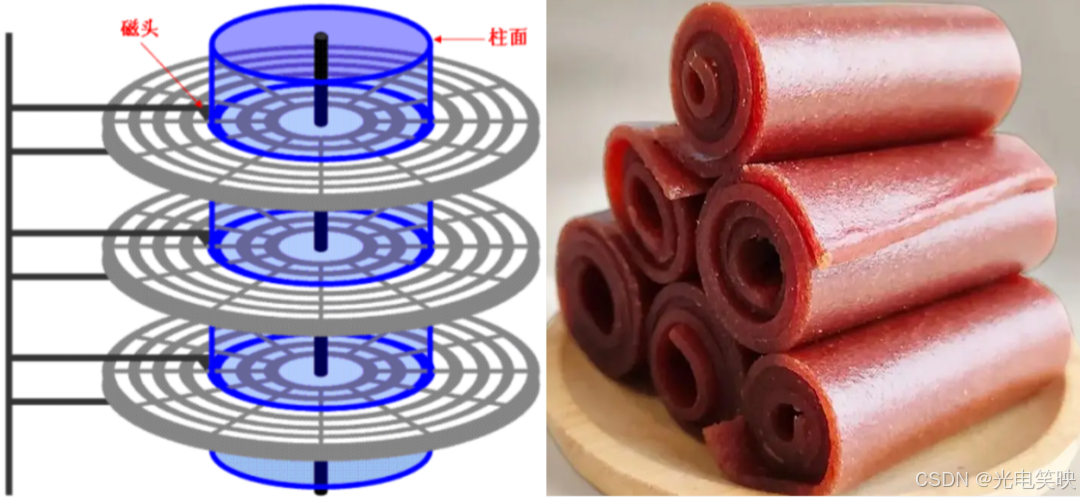
所以,磁盘的真实情况是:
- 磁道: 某⼀盘⾯的某⼀个磁道展开

即:⼀维数组
- 柱⾯: 整个磁盘所有盘⾯的同⼀个磁道,即柱⾯展开:
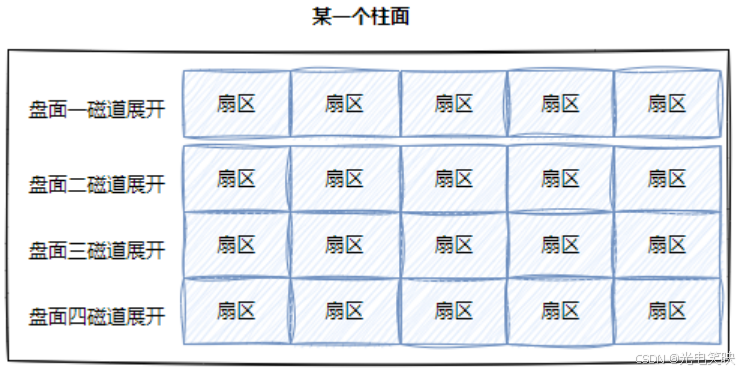
即:柱⾯上的每个磁道,扇区个数是⼀样的,这就是⼆维数组
整盘:

即:整个磁盘不就是多张⼆维的扇区数组表(三维数组?)
所以,寻址⼀个扇区:先找到哪⼀个柱⾯(Cylinder) ,在确定柱⾯内哪⼀个磁道(其实就是磁头位置Head),在确定扇区(Sector),所以就有了CHS。

OS只需要使⽤LBA就可以了!!LBA地址转成CHS地址,CHS如何转换成为LBA地址。谁做啊??磁盘⾃⼰来做!固件(硬件电路)
1.4CHS && LBA地址互相转换
在早期磁盘中,磁盘会向系统报告自己的几何参数:柱面数、磁头数、每磁道扇区数。转换正是基于这三个参数完成的。
约定说明,转换前需要了解几个重要的编号规则:
- 柱面号 C:从 0 开始编号
- 磁头号 H:从 0 开始编号
- 扇区号 S:从 1 开始编号,而 LBA 是从 0 开始的偏移量,这是转换公式中
s - 1和+ 1的由来。 - LBA 地址:从 0 开始编号(即第 0 个逻辑块)
- 这些几何参数(总柱面数、磁头数、扇区总数等)由磁盘内部自动维护,系统启动时会获取到这些信息。
公式推导:先理解“单个柱面的扇区总数”
在套公式之前,先理解一个关键的中间量:单个柱面的扇区总数 = 磁头数 × 每磁道扇区数
一个柱面包含了所有盘面上同一半径的磁道,每个磁道有固定数量的扇区,所以这个乘积就代表了一个完整柱面包含的扇区总数。
- CHS → LBA
已知扇区的物理坐标 (C, H, S)(柱面号, 磁头号, 扇区号),求逻辑块地址:
LBA = C × (磁头数 × 每磁道扇区数) + H × 每磁道扇区数 + S - 1一键获取完整项目代码cpp理解公式含义:
C × 单个柱面的扇区总数:跳过前面 C 个完整柱面H × 每磁道扇区数:在当前柱面内,跳过前面 H 个磁道S - 1:在当前磁道内,偏移到第 S 个扇区(因为 LBA 从 0 开始,扇区号从 1 开始)
- LBA → CHS
已知逻辑块地址 LBA,反推物理坐标:
C = LBA // (磁头数 × 每磁道扇区数)H = (LBA % (磁头数 × 每磁道扇区数)) // 每磁道扇区数S = (LBA % 每磁道扇区数) + 1一键获取完整项目代码bash
//表示整除(取商),%表示取余。
理解公式含义:
- 求 C:LBA 除以单个柱面的扇区总数,商就是完整跨过的柱面数,即柱面号。
- 求 H:在上一步的余数(当前柱面内的偏移)基础上,除以每磁道扇区数,商就是在该柱面内跨过的磁道数,即磁头号。
- 求 S:对每磁道扇区数取余,得到当前磁道内的扇区偏移量,加 1 即得扇区号(因为扇区号从 1 开始)。
举例验证
假设磁盘参数:磁头数 = 16,每磁道扇区数 = 63。
已知 CHS(10, 5, 30),求 LBA:
LBA = 10 × (16 × 63) + 5 × 63 + (30 - 1) = 10 × 1008 + 315 + 29 = 10080 + 315 + 29 = 10424一键获取完整项目代码bash验证:已知 LBA = 10424,反求 CHS:
C = 10424 // (16 × 63) = 10424 // 1008 = 10H = (10424 % 1008) // 63 = 344 // 63 = 5S = (10424 % 63) + 1 = 29 + 1 = 30一键获取完整项目代码bash结果一致:CHS(10, 5, 30) ↔ LBA(10424)。
补充说明
- 现代磁盘不再暴露真实几何参数。如今的磁盘普遍使用 LBA,向操作系统报告的 CHS 参数往往是不真实的最大值(通常为 16383/16/63),仅供兼容老旧软件。真正的转换由磁盘固件根据内部实际的物理布局完成。
- 操作系统只需面对一维的 LBA 空间,文件系统正是建立在这一串线性排列的逻辑块之上的。
- 转换完全由磁盘固件承担,操作系统只需要给出 LBA,不需要了解盘片、磁头的真实排列。
虽然操作系统只使用 LBA,但磁盘固件内部必须完成 LBA 到 CHS 的转换,才能驱动磁头到达正确的物理位置。反过来,当我们需要理解或调试底层问题时,也可能需要从 CHS 换算回 LBA。
2.引⼊⽂件系统
2-1 引入“块”概念
为什么需要“块”?
硬盘是典型的“块”设备。操作系统读取硬盘数据时,并不会一个一个扇区地去读——那样效率太低了。相反,它会一次性连续读取多个扇区,这个最小读取单位就叫做 “块”(Block)。
块的定义
硬盘的每个分区在格式化时,会被划分为一个个的“块”。需要注意:
- 块大小在格式化时确定,之后不可更改。
- 最常见的块大小是 4KB,即连续 8 个扇区 组成一个块(每个扇区 512 字节)。
- “块”是文件存取的最小单位。哪怕你只需要读取 1 个字节的文件,文件系统也必须把包含它的整个块读出来。
扇区与块的关系
回顾前面的知识,我们可以把磁盘抽象成这样:
磁盘本质上是一个三维物理结构,但通过 LBA,我们把它看待成一个 “一维数组”。数组的下标就是 LBA 地址,每个元素就是一个扇区。
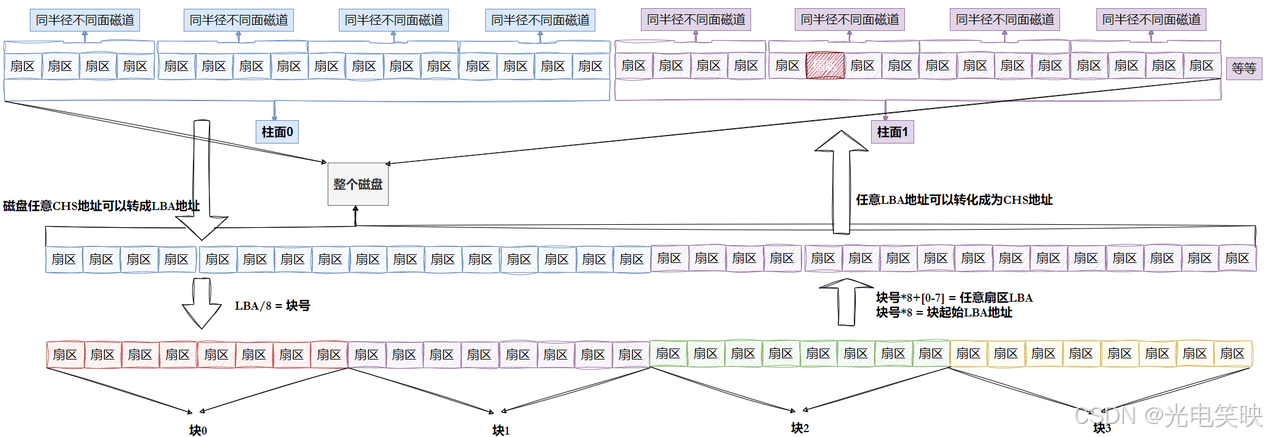
既然每个扇区都有唯一的 LBA,而 8 个连续的扇区组成一个块,那么每个块的起始地址也能轻松算出来:
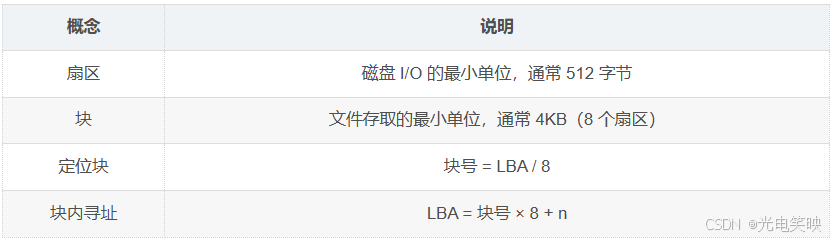
- 已知 LBA,求块号:块号 = LBA / 8 (即 LBA 整除 8)
- 已知块号,求该块内第 n 个扇区的 LBA:LBA = 块号 × 8 + n (n 的取值范围:0 ~ 7)
小结
引入“块”之后,文件系统就不再直接面对一个个扇区,而是以块为单位来组织和管理磁盘空间。接下来我们就会看到,Ext 系列文件系统是如何以块为基础,构建出超级块、块组描述符、inode 等上层结构的。
2-2 引入“分区”概念
为什么需要分区?
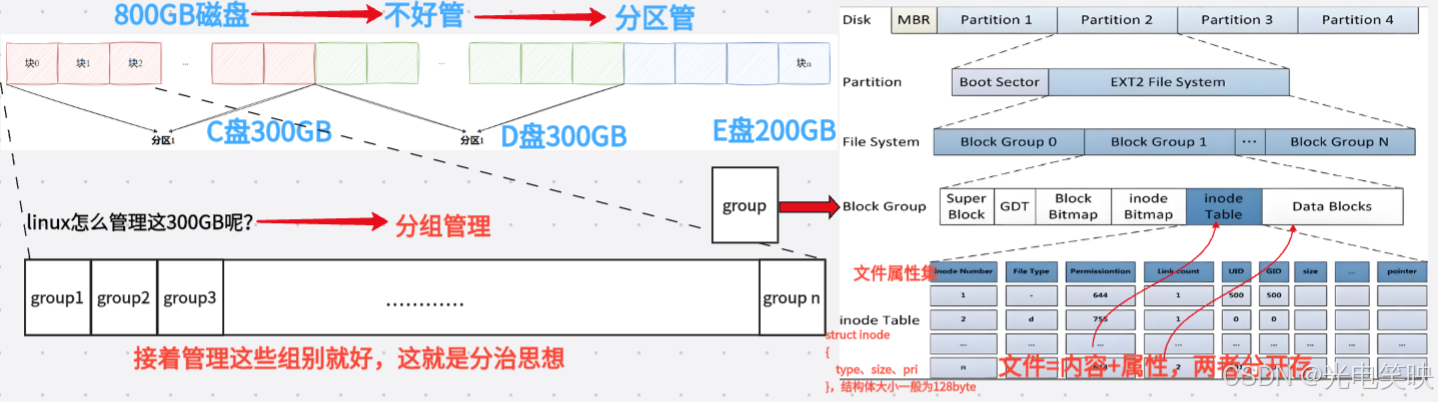
一块物理磁盘容量很大,直接管理并不方便。于是我们把它划分成多个独立的逻辑区域,这就是分区(Partition)。在 Windows 中,你熟悉的 C 盘、D 盘、E 盘就是不同的分区。分区从实质上说,就是对硬盘存储空间的一种逻辑划分。

Linux 如何看待分区?
在 Linux 中,一切皆文件。物理磁盘和分区也不例外:
/dev/vda:整块磁盘/dev/vda1:第一个分区/dev/vda2:第二个分区/dev/vda3:第三个分区
柱面是分区的最小单位
分区划分是以柱面为最小单位的。分区的过程,本质上就是设置每个分区的起始柱面号和结束柱面号。每个分区由一段连续的柱面组成,不同分区的柱面范围互不重叠。
分区与 LBA 的关系
我们可以把整个磁盘的柱面“平铺”开来,想象成一个连续的大平面。由于:

- 每个柱面大小一致
- 每个柱面内的扇区个数一致
那么,只要知道了:
- 每个分区的起始柱面号和结束柱面号
- 每个柱面有多少个扇区(即前文说的
磁头数 × 每磁道扇区数)
这个分区的容量和 LBA 范围就一目了然了:
分区 LBA 起始地址 = 起始柱面号 × 每柱面扇区数分区 LBA 结束地址 = 结束柱面号 × 每柱面扇区数 + 每柱面扇区数 - 1分区扇区总数 = (结束柱面号 - 起始柱面号 + 1) × 每柱面扇区数分区容量 = 分区扇区总数 × 512 字节一键获取完整项目代码bash
现代分区工具用 LBA 直接定义
回头看 fdisk -l 输出:
Device Start End Sectors Size Type/dev/vda1 2048 4095 2048 1M BIOS boot/dev/vda2 4096 413695 409600 200M EFI System/dev/vda3 413696 83886046 83472351 39.8G Linux filesystem一键获取完整项目代码bash
Start 和 End 两列就是分区的起始和结束 LBA 地址。现代分区工具早已不再用柱面号来定义分区边界,而是直接用 LBA 编号。但原理是一脉相承的——分区就是磁盘上一段连续的扇区范围。
2-3 引入“inode”概念
一个核心思想:属性与内容分离
Linux 下文件的存储遵循一个基本原则:属性与内容分离存储。
- 内容:文件的实际数据,大小可变,存放在数据块(Data Blocks) 中。
- 属性:文件的元信息(如权限、大小、时间戳等),每种文件的属性类别相同,结构体大小固定,存放在 inode 表(inode Tables) 中。
任何文件的内容大小可以不同,但属性结构体的大小一定是相同的。
inode 是什么?
inode(Index Node,索引节点) 是文件系统中用于存储文件属性的数据结构。
- 每个文件或目录在文件系统中都有唯一的 inode 与之对应。
- 每个 inode 内部包含一个inode 编号,它是文件或目录的唯一标识符。
- inode 大小通常是 128 字节。
- inode 不包含文件名或目录名本身。
inode 包含哪些信息?
inode 中存储了文件的有限个重点属性,可以类比 C 语言结构体来理解:
struct inode { mode_t i_mode; /* 文件类型和权限 */ uid_t i_uid; /* 文件所有者 */ gid_t i_gid; /* 文件所属组 */ ino_t i_ino; /* inode 编号 */ unsigned long *i_block; /* 指向数据块的指针数组 */ unsigned short i_nlink; /* 硬链接个数 */ blkcnt_t i_size; /* 文件大小 */ time_t i_atime; /* 最后访问时间 */ time_t i_mtime; /* 最后修改时间 */ time_t i_ctime; /* 最后状态改变时间 */};一键获取完整项目代码cpp重点属性一览:
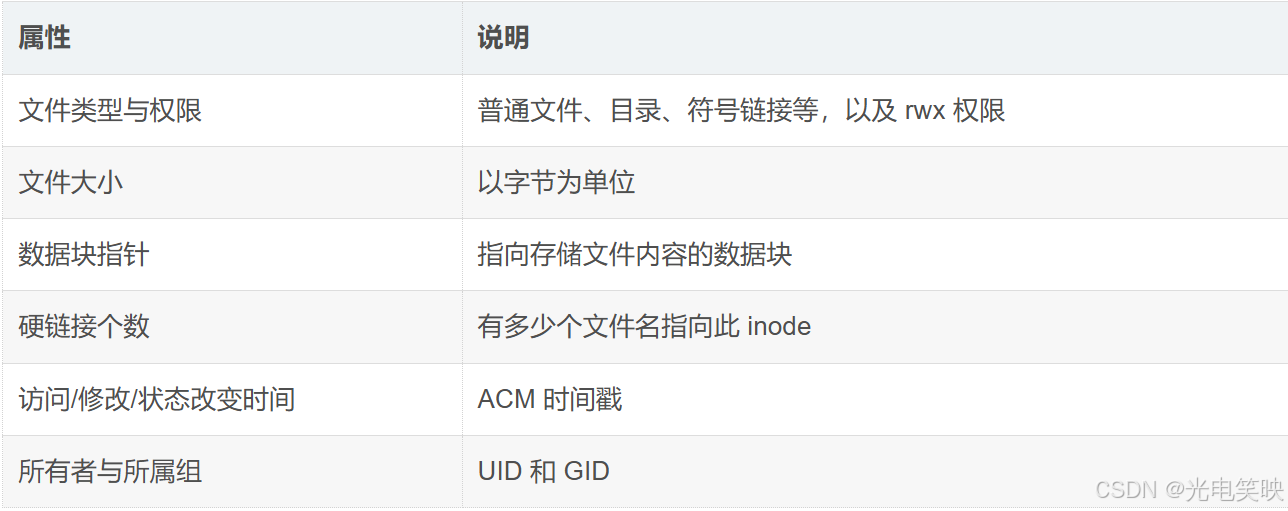
文件系统不关心文件的“本质”是什么,它只通过 inode 中这有限几个重点属性来描述和管理一个文件。
查看 inode 编号
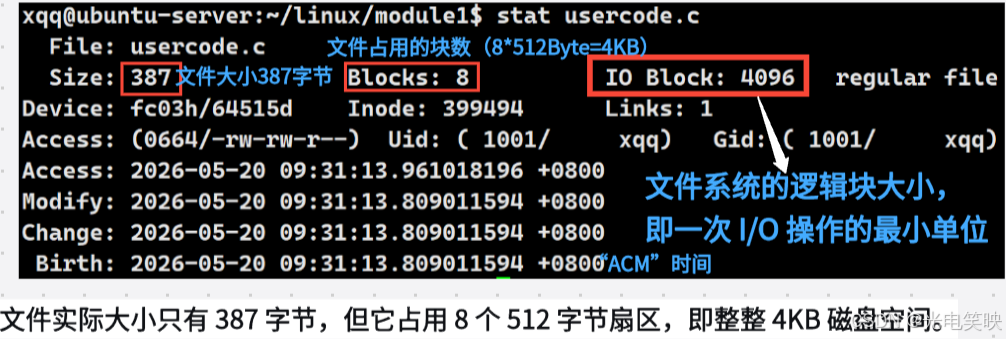
可以通过 ls -li 的 -i 选项查看文件的 inode 编号:
$ ls -litotal 16399535 -rw-rw-r-- 1 xqq xqq 89 May 20 08:47 Makefile399517 -rw-rw-r-- 1 xqq xqq 2667 May 20 15:07 mystdio.c399252 -rw-rw-r-- 1 xqq xqq 608 May 20 08:37 mystdio.h399494 -rw-rw-r-- 1 xqq xqq 387 May 20 09:31 usercode.c一键获取完整项目代码bash最左侧的数字就是 inode 编号。每个文件都有一个唯一的 inode 号,文件系统靠它来识别文件,而不是靠文件名。
stat 命令则可以查看更详细的 inode 信息,如之前所见。
inode 的作用
- 快速定位文件数据:inode 包含了指向数据块的指针数组,操作系统通过它找到文件内容在磁盘上的实际位置,从而实现高效读写。
- 实现文件的索引和访问:通过 inode,操作系统可以有效管理文件系统中大量的文件和目录,提供高效的存储和检索功能。
inode 的特点
- 唯一性:inode 编号在整个分区内唯一(注意:不是在块组内唯一),一个分区就是一个独立的 inode 编号空间。
- 不变性:文件创建后,其 inode 编号不会改变(时间戳等动态属性除外)。
- 不包含文件名:文件名存储在目录的数据块中,而非 inode 里。这一点至关重要,后续讲目录时会深入展开。
至此,相信还有两个疑问:
- 硬盘是“块”设备,块是分区下的结构。那要怎么找到某个块呢?
- 存储文件属性的 inode,又是如何放置在分区上的呢?
答案就是——文件系统。 文件系统正是为了组织和管理这些块和 inode 而存在的。下一节,我们就来揭开 Ext 系列文件系统的整体布局。
3. Ext2 文件系统
3-1 宏观认识
所有的准备工作都已经做完,是时候认识文件系统了。
我们想要在硬盘上存储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。在 Linux 系统中,最常见的是 ext2 系列的文件系统。其早期版本为 ext2,后来又发展出 ext3 和 ext4。ext3 和 ext4 虽然对 ext2 进行了增强,但是其核心设计并没有发生变化,我们仍以较老的 ext2 作为演示对象。
ext2 文件系统将整个分区划分成若干个同样大小的块组(Block Group),如下图所示。只要能管理一个块组就能管理所有块组,也就能管理整个分区,进而管理所有磁盘文件。
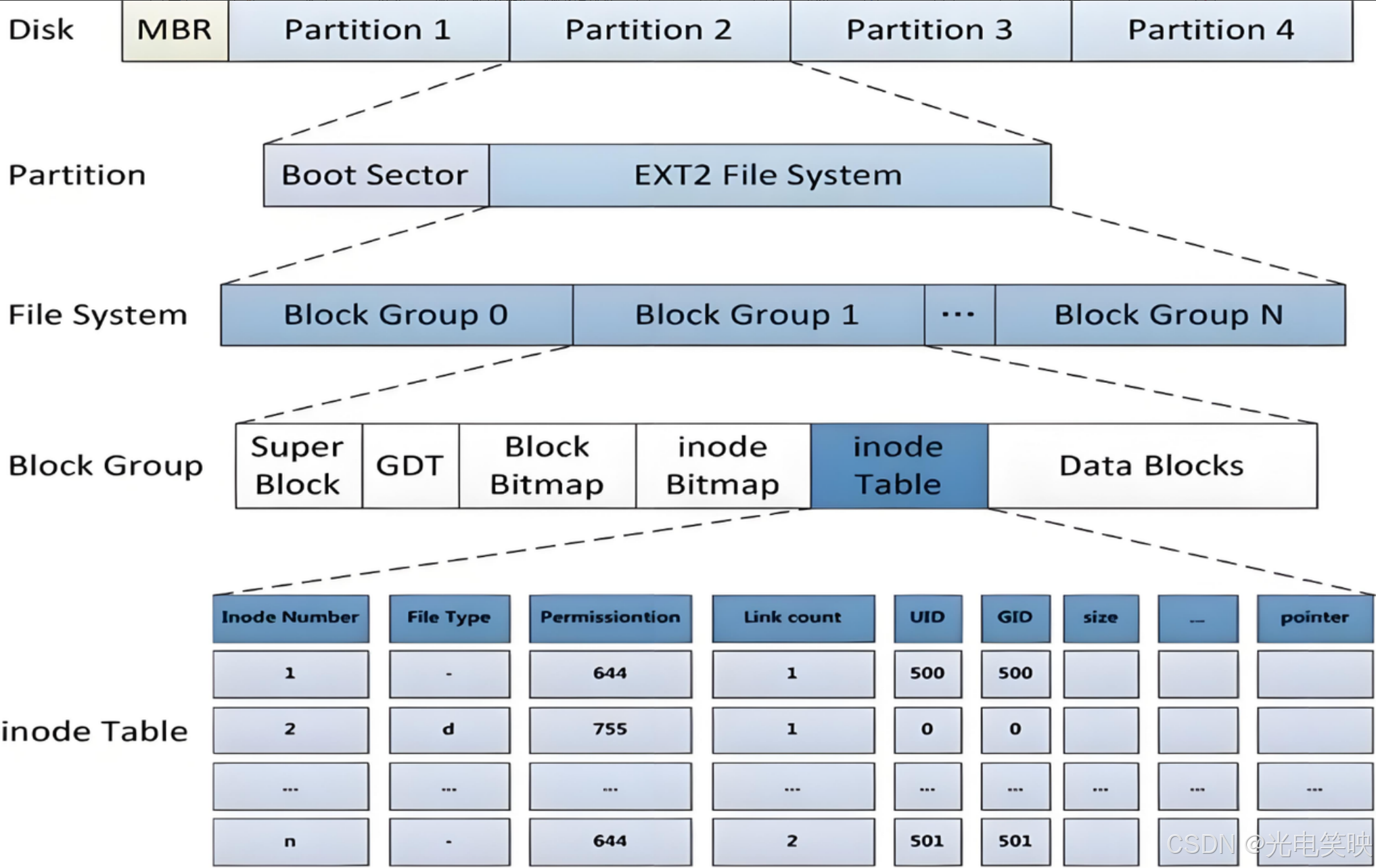
上图中有启动块(Boot Block/Sector),它的大小是确定的,为 1KB,由 PC 标准规定,用来存储磁盘分区信息和启动信息,任何文件系统都不能修改启动块。启动块之后才是 ext2 文件系统的开始。 文件系统载体是分区
3-2 Block Group
ext2 文件系统会根据分区的大小划分为数个 Block Group。而每个 Block Group 都有着相同的结构组成。这就像政府管理各个行政区,每个区的管理架构是一样的。
3-3 块组内部构成
每个块组内部包含以下六部分结构:

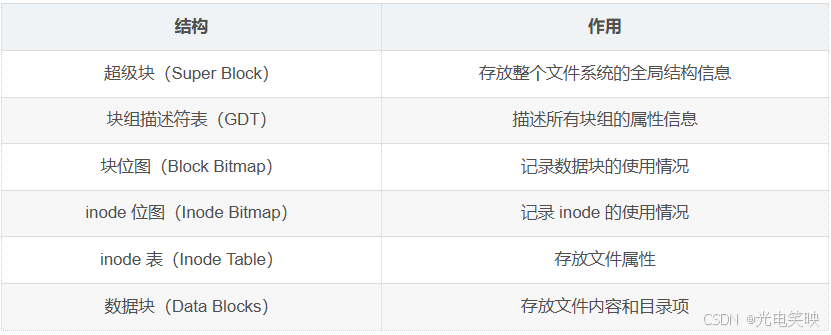
下面逐一详解。
3-3-1 超级块(Super Block)
定义:超级块是文件系统中一个全局的数据结构,存放整个文件系统的结构信息,是对整个文件系统进行管理的数据结构。
记录的主要信息:block 和 inode 的总量,未使用的 block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统相关信息。
超级块的结构体可以大致理解为:
struct ext2_super_block { /* 容量统计 */ __le32 s_inodes_count; /* inode 总数 */ __le32 s_blocks_count; /* 块总数 */ __le32 s_free_blocks_count; /* 空闲块数 */ __le32 s_free_inodes_count; /* 空闲 inode 数 */ /* 布局信息 */ __le32 s_first_data_block; /* 第一个数据块位置 */ __le32 s_log_block_size; /* 块大小(对数值,如 2 表示 4KB) */ __le32 s_blocks_per_group; /* 每个组的块数 */ __le32 s_inodes_per_group; /* 每个组的 inode 数 */ __le16 s_inode_size; /* inode 大小(通常 128 字节) */ /* 状态与标识 */ __le16 s_magic; /* 魔数 0xEF53,标识 ext2 文件系统 */ __le16 s_state; /* 文件系统是否干净卸载 */ /* 时间信息 */ __le32 s_mtime; /* 最近挂载时间 */ __le32 s_wtime; /* 最近写入时间 */};一键获取完整项目代码cpp超级块的位置与备份:
- 超级块通常保存在块组 0 中。
- 个别块组内会存储超级块的副本,以保证文件系统在磁盘部分扇区出现物理问题时还能正常工作。
为什么不在所有块组中保存超级块? 节省空间,减少冗余。 为什么个别块组内要保存副本? 可靠性与容错性。尽管超级块在全局只需存一份,但为了防止单点故障导致数据丢失,会在个别块组中存储副本。这样即使主超级块损坏,也可以从副本恢复文件系统状态。 注意:Super Block 的信息被破坏,则整个文件系统的结构就被破坏了。
我们常说“格式化一个分区”,从超级块的视角来看,这个过程本质上就是:
- 划分块组:按照分区大小和预设参数,将整个分区切分成若干个大小相等的块组(Block Group)。
- 写入管理数据:在每个块组中写入文件系统的管理结构——Super Block、GDT、Block Bitmap、Inode Bitmap、Inode Table。这些统称为文件系统的元数据。
- 初始化超级块:将上述统计结果写入 Super Block 的对应字段中。
内存中的超级块:当 OS 启动时,它会识别并挂载系统上的各个分区。在这个过程中,OS 会读取每个分区最头部的 Super Block 信息,并将其加载到内存中。为了在内存中表示这些信息,OS 会为每个挂载的文件系统创建一个 struct super_block 结构体对象,将磁盘上的 Super Block 信息填充进去,再用特定的数据结构将所有对象链接起来。对文件系统的管理,就转化为了对特定数据结构的增删查改。
3-3-2 GDT(块组描述符表)
定义:块组描述符表,是对文件系统中所有块组进行管理的数据结构。
整个分区分成多个块组,就对应有多少个块组描述符。每个块组描述符存储一个块组的描述信息,如:inode 表从哪里开始、数据块从哪里开始、空闲的 inode 和数据块还有多少等。
GDT 的结构体:
// 磁盘级blockgroup的数据结构/** Structure of a blocks group descriptor*/struct ext2_group_desc{ __le32 bg_block_bitmap; /* Blocks bitmap block */ __le32 bg_inode_bitmap; /* Inodes bitmap */ __le32 bg_inode_table; /* Inodes table block*/ __le16 bg_free_blocks_count; /* Free blocks count */ __le16 bg_free_inodes_count; /* Free inodes count */ __le16 bg_used_dirs_count; /* Directories count */ __le16 bg_pad; __le32 bg_reserved[3];};一键获取完整项目代码cppGDT 的位置与备份:
- GDT 是一个全局数据结构,描述了文件系统中所有块组的信息。
- 块组描述符在每个块组的开头都有一份拷贝,以保证可靠性。
3-3-3 块位图(Block Bitmap)
定义:用来记录块组中的数据块(Data Blocks) 是否被占用。
- 位图的位置:第几个数据块,每个比特位对应一个数据块。
- 位图的内容:对应的数据块是否被占用。
- 位为 **1**:已占用。
- 位为 **0**:空闲,可用于分配给新文件。
3-3-4 inode 位图(Inode Bitmap)
定义:用来记录块组中的 inode(inode Table) 是否被分配。
- 位图的位置:第几个 inode,每个比特位对应一个 inode。
- 位图的内容:对应的 inode 是否被分配给一个文件或目录。
- 位为 **1**:已分配。
- 位为 **0**:空闲,可用于分配给新文件或目录。
inode Bitmap 和 Block Bitmap 不属于文件本身的直接内容,而是文件系统为了管理文件而设置的额外管理字段。 删除一个文件的本质:不需要把文件的内容和属性真正擦除,只需把位图中对应的位由 1 置为 0,表明这个 inode 或数据块已失效,可以被覆盖。
注意:块位图和inode两者都是基于块为单位的,而一个bit位代表代表一个数据块或者inode块是否被占用,而一块=8*512bytes=4096bytes,而1bytes=8bit,所以1块有32678个bit位对应数据块大小为128MB,用 4KB 管理 128MB 的空间,管理开销仅占 0.003%。这就是位图节省空间的秘密
3-3-5 inode 表(Inode Table)
定义:块组中的一个数据结构,用于存储文件系统中文件或目录的属性。每个 inode 表包含一定数量的 inode 结构体。
- 存放内容:文件属性,如文件大小、所有者、最近修改时间等。
- 范围:当前块组内所有 inode 属性的集合。
- 编号规则:inode 编号以分区为单位整体划分,不可跨分区。
即在同一个分区内部,inode编号和块号是唯一的
3-3-6 数据块(Data Blocks)
定义:磁盘上的连续空间,用于存储文件系统中文件或目录的内容。它由多个连续的数据块组成,这些数据块在物理上可能并不连续,但在逻辑上是连续的,因为它们被组织在同一个块组中。
根据不同的文件类型,数据块中存放的内容不同:
- 对于普通文件:文件的实际数据存储在数据块中。
- 对于目录:该目录下的所有文件名和目录名存储在数据块中(除此之外,
ls -l看到的其他信息保存在该文件的 inode 中)。
Block 编号按照分区划分,不可跨分区。即在同一个分区内部,inode编号和块号是唯一的
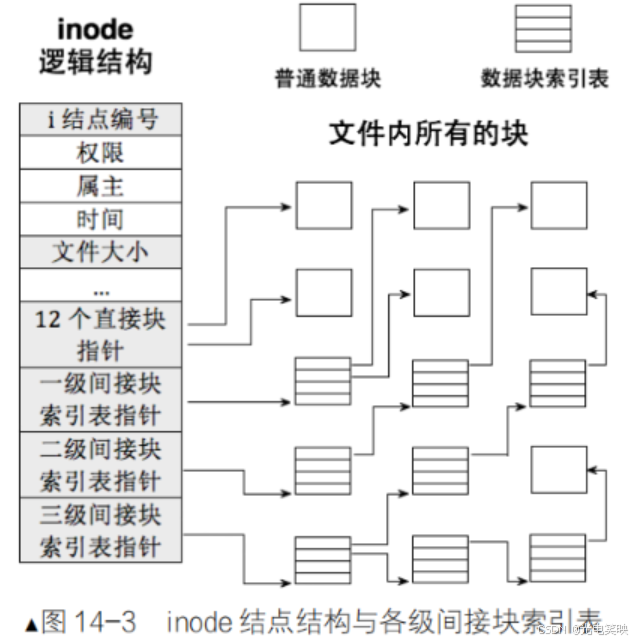
3-4* inode 与数据块的映射
inode 内部存在一个关键字段:
__le32 i_block[EXT2_N_BLOCKS]; /* Pointers to blocks */一键获取完整项目代码cpp其中 EXT2_N_BLOCKS = 15,就是用来进行 inode 和数据块之间映射的。这样,文件 = 内容 + 属性,就都能找到了。
由于这 15 个指针直接存数据块编号,最多只能表示 15 × 4KB = 60KB 的文件,这显然不够。因此 ext2 采用了多级索引:
#define EXT2_NDIR_BLOCKS 12 // 直接索引:12 个#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS // = 12,一级间接索引的起始下标#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) // = 13,二级间接索引的下标#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) // = 14,三级间接索引的下标#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) // = 15,总指针数一键获取完整项目代码cpp- 一级索引(直接索引):下标
[0, 11],直接存储数据块编号,共 12 个。 - 二级索引:下标
[12, 13],存储一个索引块的编号,该索引块再存储数据块编号。每个可存(4KB / 4字节) = 1024个数据块编号,两个共 2048 个。 - 三级索引:下标
[14],存储一个索引块编号,后者再存第二个索引块编号,第三个索引块才存数据块编号。可存1024 × 1024 = 1,048,576个数据块编号。
思想总结:在 ext 系列文件系统中,通过编号或指针找到真实存储数据的数据块。多级索引下,先找到索引块,最后一次索引才指向真正存储文件内容的数据块。
3-5 目录与文件名
问题
- 我们访问文件,用的都是文件名,没用过 inode 号啊?
- 目录是文件吗?如何理解?
答案
- 目录也是文件。磁盘上没有“目录”这个概念,只有“文件属性 + 文件内容”的概念。具体是使用indode里面的
i_mode字段来区分是目录还是文件 - 目录的属性和其他文件一样存在 inode 中。
- 目录的内容保存的是:文件名与 inode 号的映射关系。
这就是为什么 inode 本身不包含文件名——文件名存在目录的数据块里。
访问⽂件,必须打开当前⽬录,根据⽂件名,在目录的数据块获得与之对应的inode号,然后进⾏⽂件访问 ;访问⽂件必须要知道当前⼯作⽬录,本质是必须能打开当前⼯作⽬录⽂件,查看⽬录⽂件的内容!
3-6 创建一个文件的完整流程
下面通过 touch abc 来演示创建一个新文件时发生了什么:
$ touch abc$ ls -i abc263466 abc一键获取完整项目代码bash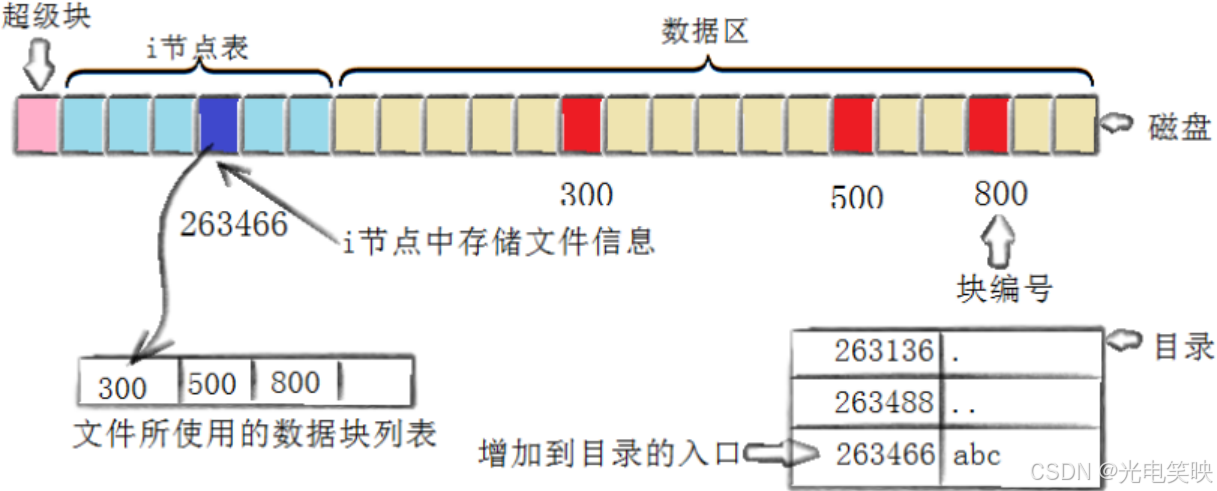
创建新文件主要有以下 4 个操作:
- 存储属性:内核找到一个空闲的 inode(这里是 263466),把文件信息记录到其中。
- 存储数据:该文件需要三个磁盘块来存数据,内核找到三个空闲块:300、500、800,将数据依次复制进去。
- 记录分配情况:内核在 inode 的
i_block数组中记录上述块列表[300, 500, 800]。 - 添加文件名到目录:内核将条目
(263466, abc)添加到当前目录文件的数据块中。文件名和 inode 之间的对应关系,将文件名和文件的内容及属性连接了起来。
3-7 思考与总结
思考1:知道 inode 号的情况下,在指定分区内,对文件进行增、删、查、改分别是在做什么?
结论:
- 分区格式化的本质:对分区进行分组,在每个块组中写入 Super Block、GDT、Block Bitmap、Inode Bitmap 等管理信息。这些管理信息统称为文件系统。
- 只要知道文件的 inode 号,就能在指定分区中确定是哪一个块组,进而在该块组中确定是哪一个 inode。
- 拿到 inode,文件的属性和内容就全部都有了。
从 inode 号定位块组
已知 inode 号,两步就能定位到它所在的块组和组内位置:
块组号 = (inode号 - 1) / 每块组inode数 ← 整除组内偏移 = (inode号 - 1) % 每块组inode数 ← 取模一键获取完整项目代码cpp
其中 每块组inode数 就存在 Super Block 的 s_inodes_per_group 字段里。拿到块组号后,通过该块组的 GDT 找到 inode Table 的起始位置,再加上 组内偏移 × inode大小,就直接读到了目标 inode。
O(1) 复杂度,一次除法和一次取模,瞬间定位——这就是 inode 编号跨组连续带来的最大好处。数据块同理,只是换成块号对
s_blocks_per_group做除法和取模。
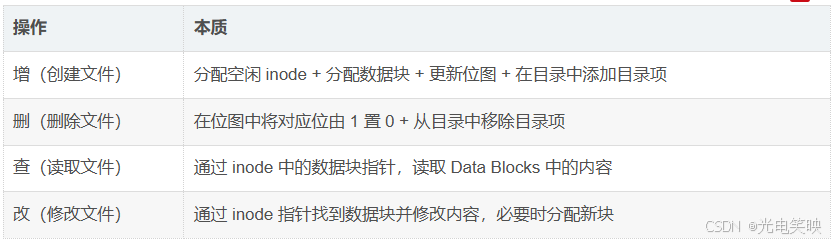
所谓申请和释放数据块,本质上就是对位图中的比特位进行置 1 或清 0 操作。
这也解释了日常使用中的一个经典现象:为什么下载一部几个 G 的电影要好几分钟甚至更久,而删除它却瞬间完成?
- 下载(写入):需要向 Data Block 里真实地写入数据,同时在 inode Bitmap 中把某个比特位置 1,在 Block Bitmap 中把成百上千个比特位置 1——每一个"1"都对应实际的数据写入和位图更新。
- 删除:根本不需要把文件内容和属性真正擦除,只需将位图中对应的 bit 位清零即可。数据块的物理内容并没有消失,只是被标记为"空闲可覆盖"。等新数据写入时,直接在此基础上覆盖掉旧内容。
总结:增是实打实的写入,删只是改几个 bit 标记而已。
思考2:如果一个文件特别大,一个 inode 所在的块组里的 Data Block 存不下怎么办?
答案:不存在“存不下”,因为数据块是跨块组分配的
核心规则:inode 和数据块都是跨组编号、以分区为单位的。一个文件的 inode 固定在某个块组的 inode Table 里,但它的数据块可以分布在分区的任意块组中,完全不受 inode 所在块组的限制。
假设一个超大文件需要分配 10000 个数据块:
- 内核首先在 inode 所在块组的 Block Bitmap 中找空闲块。
- 该块组的空闲块用完了——没关系,去下一个块组继续分配。
- 内核依次扫描各个块组的 Block Bitmap,找到空闲 bit 就置 1,把对应的数据块分给这个文件。
- 所有分配到的数据块编号(分区级别的块号),写入 inode 的
i_block[]数组或其间接索引块中。
inode 在块组 0,数据块散落在多个块组中。inode 只记录块号,不关心块在哪个组。
3-8 路径解析与路径缓存
问题的提出
我们已经知道,访问文件需要 inode 号。但日常使用中,我们从来不用 inode 号,而是用路径(如 /home/xqq/code/test.c)。那么问题来了:
要访问
test.c,需要知道它的 inode。但它的 inode 存在哪儿?存在它所在的目录里。那要访问这个目录,不也得知道这个目录的 inode 吗?这似乎陷入了一个"鸡生蛋、蛋生鸡"的循环。
答案:从根目录开始递归解析
这个循环的出口就是根目录 /。
- 根目录有固定的 inode 号(ext2 中通常为 2),系统启动时就已经知道,无需查找。
- 访问
/home/xqq/code/test.c的完整过程如下:
/ (inode 2,已知) └─> 在 / 的内容中查找 "home" → 得到 home 的 inode └─> 打开 home,在其内容中查找 "xqq" → 得到 xqq 的 inode └─> 打开 xqq,在其内容中查找 "code" → 得到 code 的 inode └─> 打开 code,在其内容中查找 "test.c" → 得到 test.c 的 inode └─> 打开 test.c,读取内容一键获取完整项目代码cpp这个过程叫做 Linux 路径解析。任何一个文件的访问,都要从根目录开始,逐层深入,直到找到目标文件。这也回答了另一个根本问题:访问文件必须有"目录 + 文件名",也就是路径。
那路径又是哪来的?
访问文件,都是指令或工具访问,本质是进程访问。进程有当前工作目录(CWD),进程提供路径。
更根本地说:
open文件时,必须提供路径。- 根目录下为什么有那么多默认目录(
/etc、/var、/home...)?这是系统帮你建好的。 - 为什么有家目录?你可以在家目录下自己建新目录吗?可以,本质就是在磁盘文件系统中新建目录文件。而新建的文件天然就在某个目录下——路径从一开始就存在了。
总结:系统和用户共同构建了 Linux 的路径结构。
路径缓存
问题 1:磁盘上存在真正的"目录"吗?
不存在。 磁盘上只有"文件属性 + 文件内容"。目录之所以是"目录",是因为它的内容保存的是"文件名 → inode 号"的映射关系。
问题 2:每次访问文件都要从根目录开始解析?
原则上是的,但这样太慢。 想象一下,每打开一个文件都要从 / 一路翻好几层目录,效率极低。
所以 Linux 会缓存历史路径。已经解析过的路径,直接在内存中就能找到,不用再一层层读磁盘。
问题 3:Linux 中"目录"的概念是怎么产生的?
打开的如果是目录文件,由 OS 自己在内存中进行路径维护。
这个维护路径结构的内核结构体叫做 struct dentry******(Directory Entry,目录项)**。这个结构是内存级的,磁盘不存在
dentry 的特点
struct dentry { atomic_t d_count; /* 引用计数 */ struct inode *d_inode; /* 指向对应的 inode */ struct dentry *d_parent; /* 指向父目录的 dentry */ struct qstr d_name; /* 文件/目录名 */ struct list_head d_lru; /* LRU 链表节点(用于淘汰) */ struct hlist_node d_hash; /* 哈希表节点(用于快速查找) */ struct list_head d_child; /* 父目录的孩子链表节点 */ struct list_head d_subdirs; /* 子目录链表头 */};一键获取完整项目代码cpp- 每个文件都有一个 dentry:包括普通文件。所有被打开的文件,通过 dentry 在内存中形成一棵完整的树状路径结构。
- 同时隶属于 LRU 链表:长时间不用的 dentry 节点会被淘汰,回收内存。
- 同时隶属于哈希表:方便根据路径名快速查找。
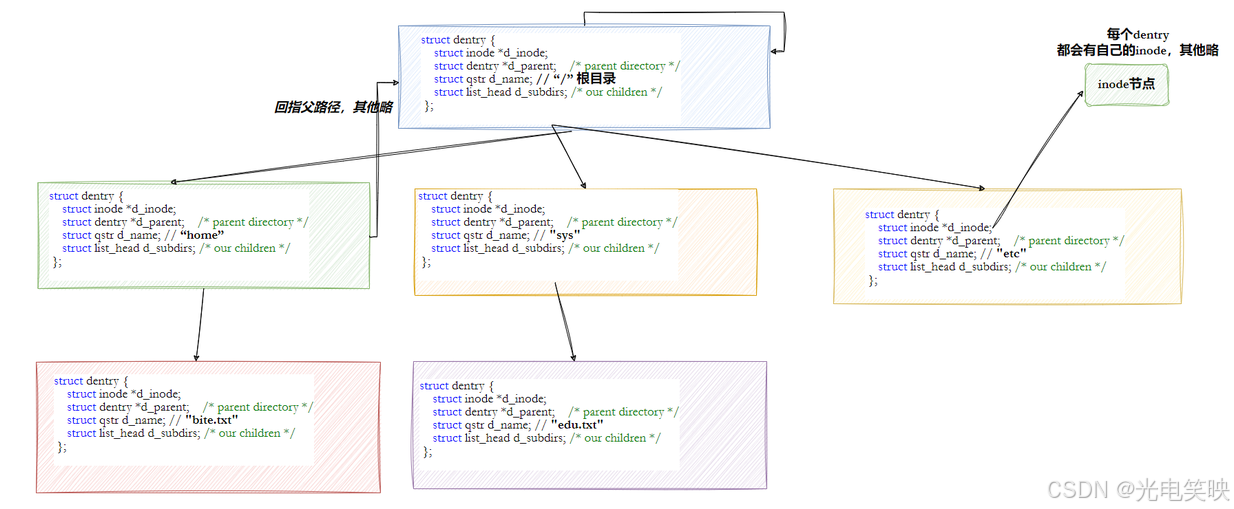
路径查找的流程

这个树形结构,整体构成了 Linux 的路径缓存。它让文件访问不再每次都从磁盘根目录开始,而是先走内存缓存,极大地提升了文件系统性能。操作系统从根目录开始建树,于是我们越访问文件,树的结构就越完善,效率也就越高
3-9 挂载分区
问题的提出
我们已经知道:
- 只要知道 inode 号,就能在指定分区里找到文件。
- 只要读取目录的 Data Block,就能根据文件名找到 inode 号。
- 但是——inode 不能跨分区。
那问题来了:Linux 系统可以有多个分区,我们怎么知道一个文件在哪个分区?
$ ls -l /dev/vda*brw-rw---- 1 root disk 252, 0 May 14 16:27 /dev/vdabrw-rw---- 1 root disk 252, 1 May 14 16:27 /dev/vda1brw-rw---- 1 root disk 252, 2 May 14 16:27 /dev/vda2brw-rw---- 1 root disk 252, 3 May 14 16:27 /dev/vda3一键获取完整项目代码bash一个结论:分区必须挂载才能使用
分区写入文件系统后,无法直接使用,必须和指定的目录关联,进行挂载后才能访问。也就是说,进入这个目录,就相当于进入了这个分区。
反过来推导:
- 任何一个文件,一定属于某个分区。
- 这个分区一定挂载到了某个目录(挂载点)。
- 所以,只要看一个文件的绝对路径前缀,就能判断它在哪个分区上。
比如:/home/xqq/code/test.c
系统只需要检查 /home 是不是一个挂载点。如果不是,就继续往前看 /。根目录 / 一定是一个挂载点,它挂载的是根分区(你机器上的 /dev/vda3)。
路径前缀匹配,就是判断文件所属分区的核心机制。
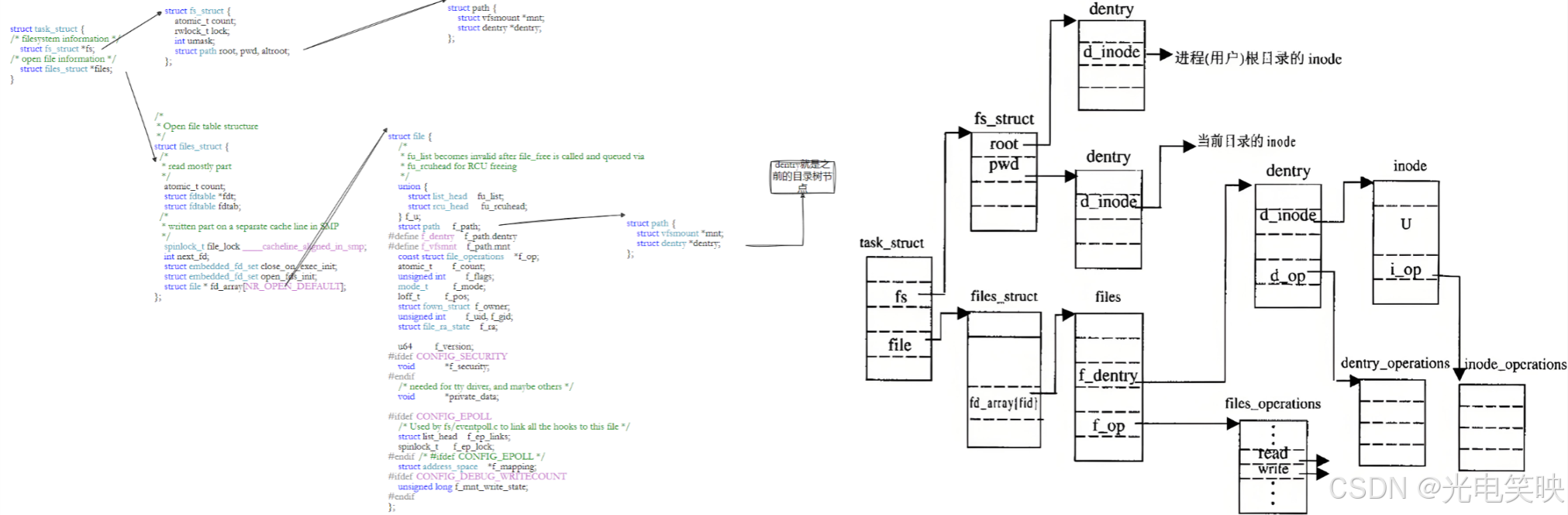
挂载的本质
挂载:将一个存储设备上的文件系统,与目录树中的某个目录(挂载点)建立关联关系。
这个过程涉及两个核心结构:

一句话总结:挂载 = Super Block 提供全局数据 + dentry 接入目录树。
关于 /dev/loop 设备
在上面的 df -h 输出中,可能注意到了这样的条目:
/dev/loop9 4.7M 24K 4.4M 1% /home/xqq/linux/module1/test/dir一键获取完整项目代码bash/dev/loop 是 Linux 中的循环设备(loop device),也叫回环设备。它是一种伪设备,允许将普通文件当作块设备来使用。比如我们用 dd 创建的 disk.img,本身只是个普通文件,但通过 loop 设备,它就能像一个真正的硬盘分区一样被挂载。
实验演示
下面完整走一遍流程,把前面分散的操作串联起来:
准备工作 创建挂载点目录xqq@ubuntu-server:~/linux/module1/test$ mkdir dir xqq@ubuntu-server:~/linux/module1/test$ ls -ltotal 12drwxrwxr-x 2 xqq xqq 4096 May 21 20:14 dir/ # 创建磁盘镜像(模拟分区) xqq@ubuntu-server:~/linux/module1/test$ dd if=/dev/zero of=./disk.img bs=1M count=55+0 records in # #制作⼀个⼤的磁盘块,就当做⼀个分区5+0 records out5242880 bytes (5.2 MB, 5.0 MiB) copied, 0.0111638 s, 470 MB/s#ext2,3,4都相似,只是3,4功能更多,这里用4xqq@ubuntu-server:~/linux/module1/test$ mkfs.extCommand 'mkfs.ext' not found, did you mean: command 'mkfs.ext3' from deb e2fsprogs (1.46.5-2ubuntu1.2) command 'mkfs.ext2' from deb e2fsprogs (1.46.5-2ubuntu1.2) command 'mkfs.ext4' from deb e2fsprogs (1.46.5-2ubuntu1.2)Try: sudo apt install <deb name> xqq@ubuntu-server:~/linux/module1/test$ ls -ldrwxrwxr-x 2 xqq xqq 4096 May 21 20:14 dir/-rw-rw-r-- 1 xqq xqq 5242880 May 21 20:16 disk.img # 格式化:写入 Ext4 文件系统xqq@ubuntu-server:~/linux/module1/test$ mkfs.ext4 disk.imgmke2fs 1.46.5 (30-Dec-2021)Creating filesystem with 5120 1k blocks and 1280 inodes...Writing superblocks and filesystem accounting information: done#成功 # 挂载前:查看分区情况Filesystem Size Used Avail Use% Mounted ontmpfs 161M 1.1M 160M 1% /run/dev/vda3 40G 9.2G 29G 25% /tmpfs 805M 0 805M 0% /dev/shmtmpfs 5.0M 0 5.0M 0% /run/lock/dev/vda2 197M 6.1M 191M 4% /boot/efitmpfs 161M 4.0K 161M 1% /run/user/1001# ← 还没有 disk.img # 挂载:将分区关联到目录xqq@ubuntu-server:~/linux/module1/test$ sudo mount -t ext4 ./disk.img ./dir # 挂载后:查看分区情况xqq@ubuntu-server:~/linux/module1/test$ df -h#.../dev/loop9 4.7M 24K 4.4M 1% /home/xqq/linux/module1/test/dir# disk.img 通过 loop 设备挂载到了 ./dir # 在挂载的分区内创建文件xqq@ubuntu-server:~/linux/module1/test$ cd dirxqq@ubuntu-server:~/linux/module1/test$ sudo touch log.txtxqq@ubuntu-server:~/linux/module1/test$ ls -ltotal 16drwxr-xr-x 3 root root 1024 May 21 20:15 ./drwxrwxr-x 3 xqq xqq 4096 May 21 20:14 ../drwx------ 2 root root 12288 May 21 20:15 lost+found/-rw-r--r-- 1 root root 0 May 21 20:15 log.txt xqq@ubuntu-server:~/linux/module1/test$ cd .. # 卸载分区xqq@ubuntu-server:~/linux/module1/test$ sudo umount ./dir # 卸载后:dir 恢复为空目录xqq@ubuntu-server:~/linux/module1/test$ ls -ldrwxrwxr-x 2 xqq xqq 4096 May 21 20:14 dir/-rw-rw-r-- 1 xqq xqq 5242880 May 21 20:20 disk.img xqq@ubuntu-server:~/linux/module1/test$$ rm -rf dir disk.img一键获取完整项目代码bash
文件系统总结
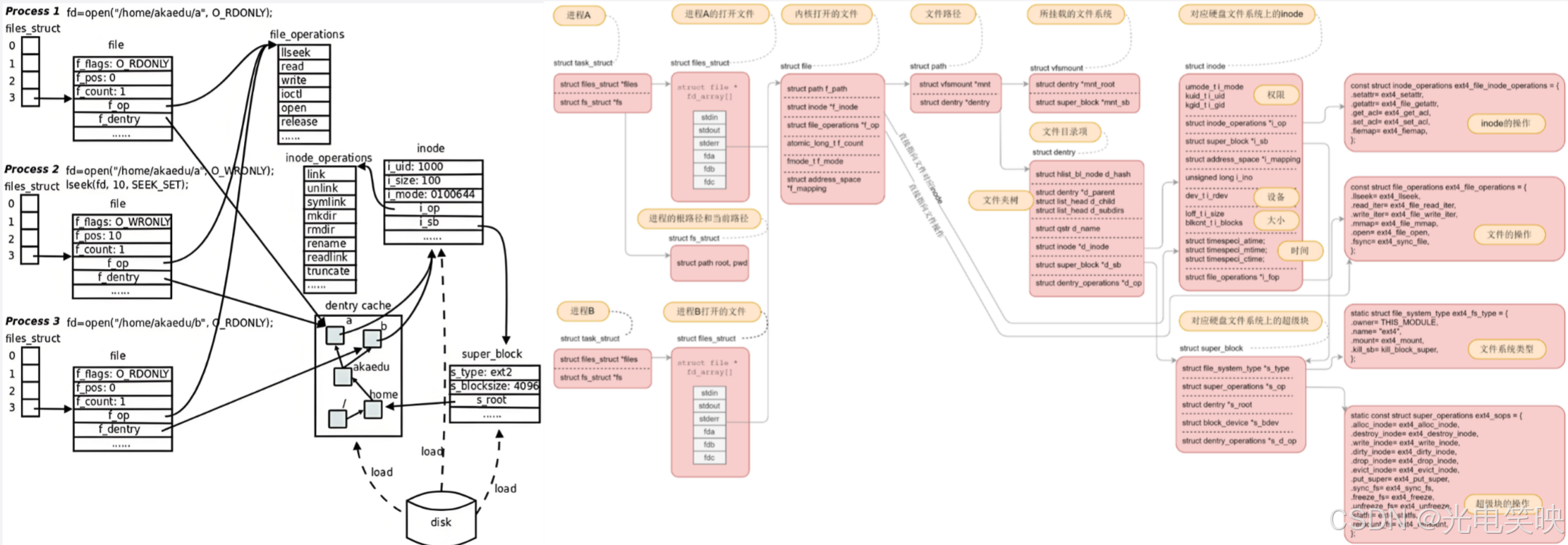
4.软硬链接
前面我们反复强调一个核心规则:inode不包含文件名,文件名存在目录的Data Block里的QQ号码。 |
|---|
目录的内容就是一张"文件名 → inode 号"的映射表。理解了这一点,软链接和硬链接的原理就一目了然了——它们本质上是对这张映射表的两种不同玩法。
- 硬链接(Hard Link)
硬链接就是在目录的 Data Block 里多写一条记录,让一个新的文件名指向同一个 inode。
也就是说,多个文件名对应同一个 inode 号,它们完全平等,没有"主次"之分。
创建方式
$ ln 目标文件 链接名一键获取完整项目代码cpp演示
xqq@ubuntu-server:~/linux/module1/testlink$ echo "hello world">orignal.txtxqq@ubuntu-server:~/linux/module1/testlink$ ln orignal.txt hardlink.txtxqq@ubuntu-server:~/linux/module1/testlink$ ls -litotal 81056959 -rw-rw-r-- 2 xqq xqq 12 May 22 10:05 hardlink.txt1056959 -rw-rw-r-- 2 xqq xqq 12 May 22 10:05 orignal.txt一键获取完整项目代码bash注意:
- inode 号相同:都是
1056959。 - 硬链接计数为 2:
ls -l第二列从 1 变成了 2。硬链接数就是 inode 里的引用计数 - 文件内容一样:因为它们指向同一个 inode,读的就是同一份 Data Block。
目录中的实际结构
original.txt 所在目录的 Data Block: "original.txt" → inode 399494 "hardlink.txt" → inode 399494 ← 多了一条记录,指向同一个 inode一键获取完整项目代码bash即本质就是在当前目录建立一组新的文件名和inode映射关系,只不过inode相同指向同一个文件
硬链接的特点

真正删除的时机
rm 删除文件时,实际做了两件事:
- 从目录的 Data Block 中移除"文件名 → inode 号"这条记录。
- 把 inode 的
i_nlink减 1。
只有当 i_nlink 变为 0,并且没有进程打开这个文件时,文件的数据块才真正被释放(Block Bitmap 对应位置 0)。这也就是硬链接用途之一-------文件备份
- 软链接(Symbolic Link)
软链接是一个全新的、独立的文件。它有自己的 inode,有自己的 Data Block。但它的 Data Block(数据内容) 里存的不像普通文件是数据,而是目标文件的路径字符串。
创建方式
$ ln -s 目标文件 链接名一键获取完整项目代码bash演示
xqq@ubuntu-server:~/linux/module1/testlink$ ls -litotal 41056959 drwxrwxr-x 3 xqq xqq 4096 May 22 09:10 1xqq@ubuntu-server:~/linux/module1/testlink$ ln -s ./1/2/3/4/5/code.exe exexqq@ubuntu-server:~/linux/module1/testlink$ ls -litotal 41056959 drwxrwxr-x 3 xqq xqq 4096 May 22 09:10 11056966 lrwxrwxrwx 1 xqq xqq 20 May 22 09:27 exe -> ./1/2/3/4/5/code.exe^有自己的inode编号,l表示链接文件xqq@ubuntu-server:~/linux/module1/testlink$ ./exeHello worldxqq@ubuntu-server:~/linux/module1/testlink$ ./1/2/3/4/5/code.exeHello world #这样太麻烦了xqq@ubuntu-server:~/linux/module1/testlink$ tree ..├── 1│ └── 2│ └── 3│ └── 4│ └── 5│ ├── code.c│ └── code.exe└── exe -> ./1/2/3/4/5/code.exe 5 directories, 3 files一键获取完整项目代码cpp悬空链接
xqq@ubuntu-server:~/linux/module1/testlink$ rm -f ./1/2/3/4/5/code.exexqq@ubuntu-server:~/linux/module1/testlink$ ls -litotal 41056959 drwxrwxr-x 3 xqq xqq 4096 May 22 09:10 11056966 lrwxrwxrwx 1 xqq xqq 20 May 22 09:27 exe -> ./1/2/3/4/5/code.exe 标成红色的了^xqq@ubuntu-server:~/linux/module1/testlink$ ./exe-bash: ./exe: No such file or directory#删除软连接 可以rm也可以unlinkxqq@ubuntu-server:~/linux/module1/testlink$ unlink exe一键获取完整项目代码bash软链接的特征
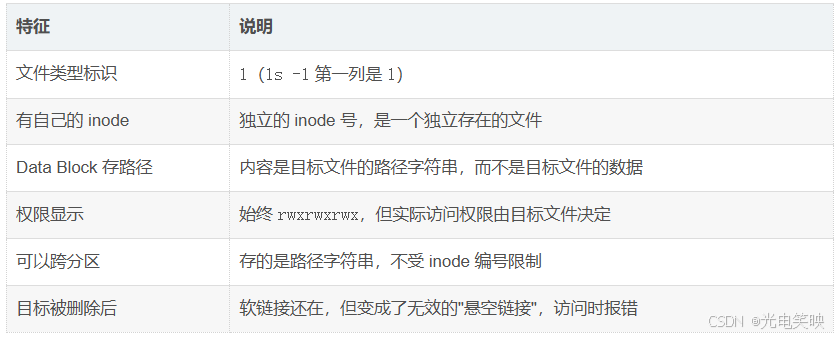
软链接就是Windows的快捷方式。它本身不存目标文件的数据,只存一个地址牌。访问它时,内核自动按地址牌上的路径跳转到目标文件。
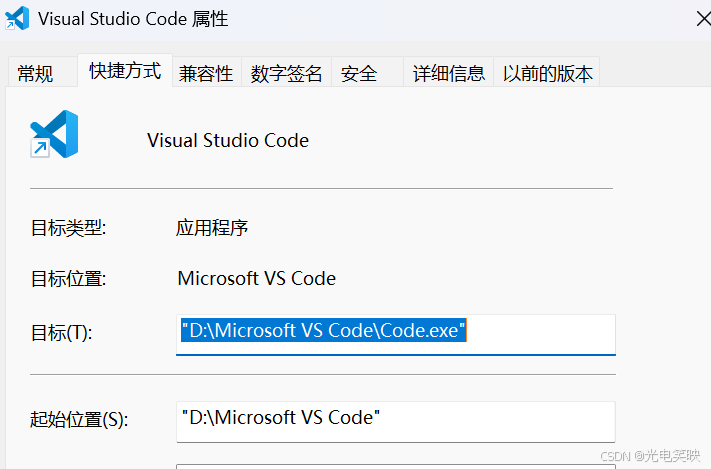
软链接 vs. 硬链接:对比总结
总结
硬链接是"同一个人(inode),多个名字"——改名不改人,删名不删人。 软链接是"路标牌"——它自己不是目的地,只写着目的地的地址。牌没坏就能顺着走过去,目的地拆了就扑个空。
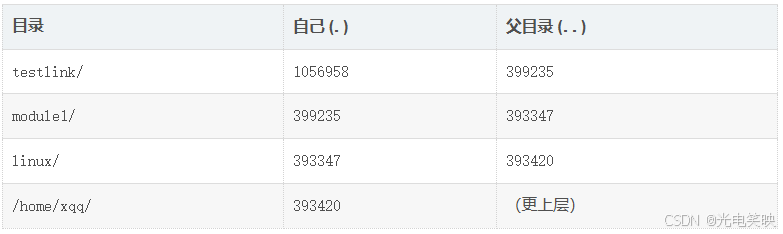
. 和 .. 的本质
每个目录被创建时,文件系统会自动为它添加两个硬链接:

逐层追踪 inode 号:
- 第一层:**
testlink/**
$ ls -lia testlink/1056958 drwxrwxr-x 2 xqq xqq 4096 May 22 10:05 . # testlink 自己的 inode 399235 drwxrwxr-x 3 xqq xqq 4096 May 22 09:09 .. # 父目录 module1 的 inode一键获取完整项目代码bash- 第二层:**
module1/**
$ ls -lia module1/ 399235 drwxrwxr-x 3 xqq xqq 4096 May 22 09:09 . # module1 自己的 inode 393347 drwxrwxr-x 6 xqq xqq 4096 May 21 19:59 .. # 父目录 linux 的 inode1056958 drwxrwxr-x 2 xqq xqq 4096 May 22 10:05 testlink/ # ← 和上面 testlink/. 相同一键获取完整项目代码bash- 第三层:**
linux/**
$ ls -lia linux/393347 drwxrwxr-x 6 xqq xqq 4096 May 21 19:59 . # linux 自己的 inode393420 drwxr-xr-x 14 xqq xqq 4096 May 22 10:00 .. # 父目录(/home/xqq)的 inode399235 drwxrwxr-x 3 xqq xqq 4096 May 22 09:09 module1/ # ← 和上面 module1/. 相同一键获取完整项目代码bash把 . 和 .. 的 inode 号做成一张对照表,形成闭环:
硬链接数的验证:

规律总结

为什么不允许手动创建目录的硬链接?
既然 . 和 .. 已经是目录的硬链接了,那我能不能自己 ln 一个目录的硬链接?
$ ln dir1 dir2ln: dir1: hard link not allowed for directory一键获取完整项目代码bash不允许。 原因是为了防止目录环路。
如果允许手动创建目录硬链接,就可能出现这种情况:
A → B → A → B → A → ... (无限循环)一键获取完整项目代码bash一旦出现环路,find、du、备份工具等递归遍历目录树的程序就会陷入死循环。而 . 和 .. 是内核自动管理的,严格遵循". 指向自己,.. 指向父目录"的规则,永远不会形成环路。
xqq@ubuntu-server:~/linux/module2$ rm -rf .rm: refusing to remove '.' or '..' directory: skipping '.'一键获取完整项目代码bash总结:
.和..不是什么魔法符号,它们就是内核帮你自动创建的两个硬链接。**.** 指向自己,**..** 指向父目录。一个目录的硬链接数 = 2 + 子目录数,每创建一个子目录,父目录的硬链接数就 +1。
补充思考,为什么数据要先加载到内存?
原因一:冯·诺依曼体系结构的必然要求
冯·诺依曼体系规定了:CPU 只能直接访问内存,不能直接访问外设(磁盘)。
磁盘是外设,读写速度比内存慢几个数量级,如果 CPU 直接等磁盘返回数据,那整个系统就卡死了。所以必须先把磁盘数据加载到内存这个"缓冲层",CPU 才能高效处理。块设备太慢,文件系统需要以"块"为单位批量读取,而不是一个一个扇区去读。
原因二:缓存写入时数据连续,提高缓存命中率
内核在写入数据时,并不是立即写到磁盘,而是先在内存的页缓存(Page Cache) 中积累:
连续写入的数据在内存中被整理成连续的页。等到合适的时机(如缓存满了、用户主动 sync、内核周期性刷写),再一次性、顺序地写回磁盘。下次读取时,如果数据还在缓存中,就直接命中,避免了磁盘 I/O。
为什么这样命中率高?
- 写的时候是连续的,读的时候大概率也是连续读取。
- 一次磁盘 I/O 把整个连续块都读进来,后续读写都在内存中完成。
- 局部性原理:程序倾向于反复访问同一片数据,缓存里待过的数据很可能马上又被用到。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号