InspireFace GPU (CUDA) 编译避坑指南(3)
原创
InspireFace GPU (CUDA) 编译避坑指南(3)
原创
美畅物联-南宫美
发布于 2026-05-28 16:57:39
发布于 2026-05-28 16:57:39
本文针对 Linux + NVIDIA Tesla T4 + CUDA + MNN GPU 推理 场景,对关键编译配置、链接规则、常见报错点进行梳理与说明,帮助开发者快速完成 GPU 版本编译,避免因链接规则、编译器兼容、库依赖顺序等问题导致编译失败或运行时无法加载 GPU.
一、CMakeLists.txt 链接配置修改(核心坑点集中区)
在开启 CUDA 加速的编译流程中,链接规则、库依赖顺序、编译器版本兼容是最容易出错的环节。以下为经过验证的稳定配置方案。
1.1 根目录 CMakeLists.txt
1.1.1 自动查找 MNN CUDA 相关扩展静态库
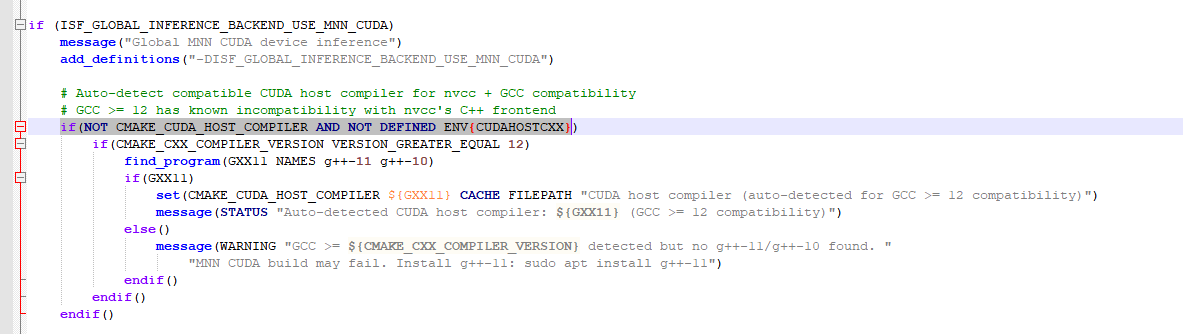
1.1.2 GCC ≥ 12 自动检测与 CUDA Host 编译器兼容处理
GCC 12 及以上版本与 nvcc 存在已知前端兼容问题,会直接导致 CUDA 代码编译失败。 因此在开启 MNN CUDA 时,脚本会自动检测 GCC 版本。当版本 ≥12 时,自动寻找 g++-11 或 g++-10 作为 CUDA Host 编译器,从根源避免编译报错。
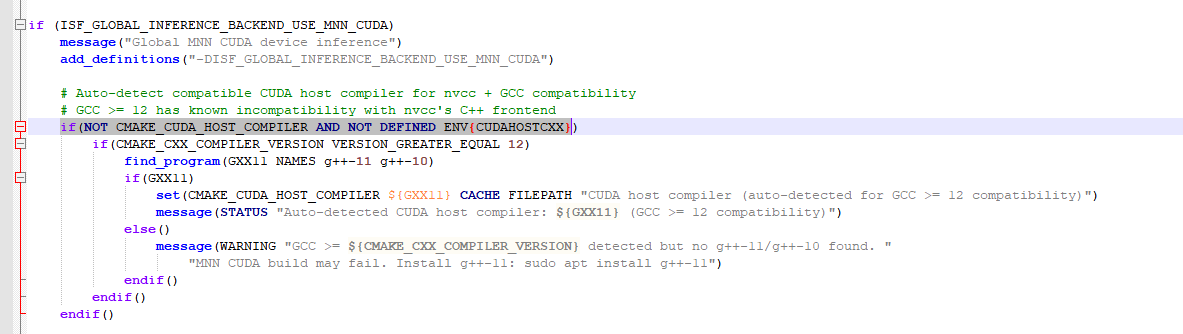
1.1.3 全局链接库添加

1.2 cpp/inspireface/CMakeLists.txt(核心修改)
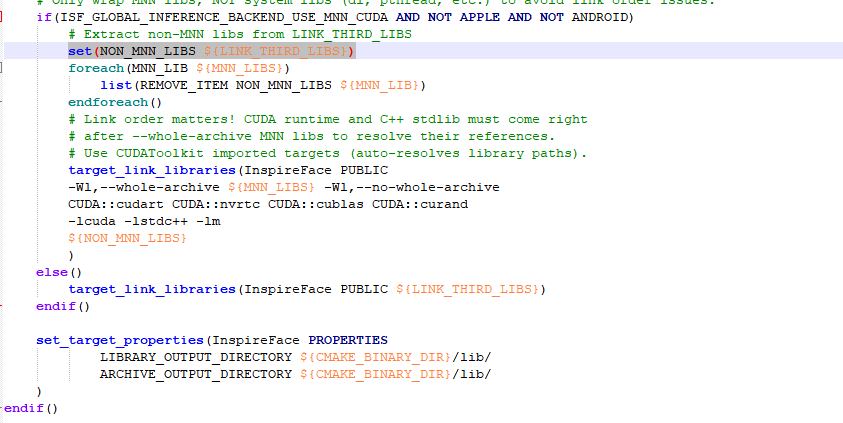
1.2.1 --whole-archive 必须只包裹 MNN 库
*错误写法*:
target_link_libraries(InspireFace PUBLIC -Wl,--whole-archive ${LINK_THIRD_LIBS} -Wl,--no-whole-archive)
这会把 `dl`、`pthread` 等系统库也包裹进去,破坏 C++ 标准库符号解析。
*正确写法*:
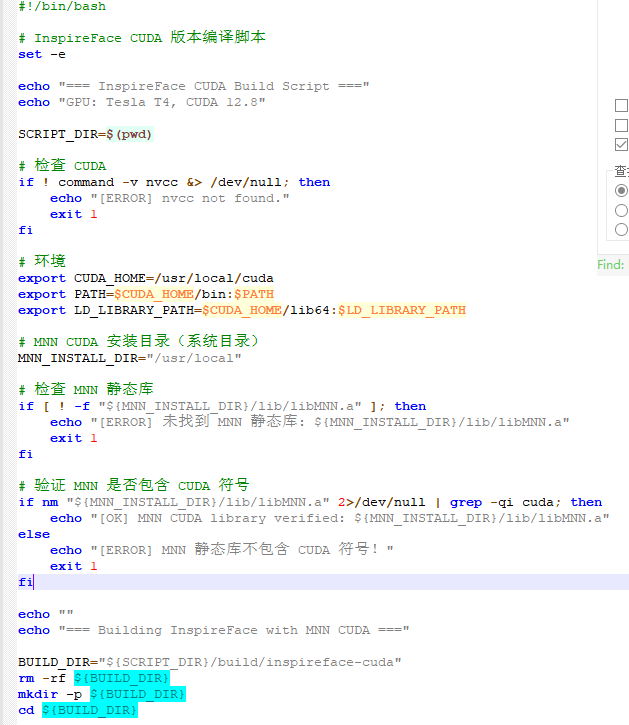
二、编译脚本
此脚本在以上修改完成后可直接运行编译

三、运行验证
3.1 正确输出示例
InspireFace SDK [Community Edition] v1.2.3 Backend: MNN(CUDA) ← 关键
[inference_wrapper_mnn.cpp][Initialize][126]: Enable CUDA ← 关键
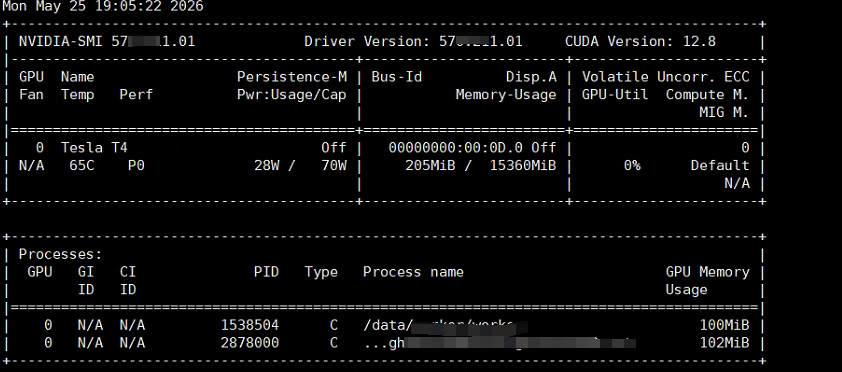
3.2 GPU 使用验证
# 运行程序时监控 GPU
nvidia-smi -l 1
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号