Repository Graph:代码结构理解与可视化

Repository Graph:代码结构理解与可视化

安全风信子
发布于 2026-05-29 08:41:09
发布于 2026-05-29 08:41:09
作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: AI IDE 必须"看懂"代码库才能提供真正的智能服务。Repository Graph 是实现代码理解的核心基础设施——它将代码的结构、关系、演化以图的形式表达出来,使 AI 能够系统性地理解代码组织的逻辑与依赖关系。本文深入讲解如何构建 Repository Graph:AST 提取与符号表构建实现代码的语法层面理解;调用图生成与依赖图分析揭示模块间的交互模式;基于 Graph 的代码理解能力支撑影响分析、架构评估、重构规划等高阶功能。我们将通过 Tree-sitter 展示多语言 Repository Graph 的实践实现,涵盖从词法分析到图查询的完整技术栈。
目录- 本节核心技术价值
- 1. 引言:为什么 AI IDE 需要"看懂"代码
- 1.1 从代码补全到代码理解的鸿沟
- 1.2 Repository Graph 的定义与本质
- 1.3 Repository Graph 在 AI IDE 中的角色
- 2. AST 提取与符号表构建
- 本节核心技术价值
- 2.1 词法分析:字符流到 token 序列
- 2.2 语法分析:Token 序列到 AST
- 2.3 符号表构建
- 3. 调用图:静态分析 vs 动态追踪
- 本节核心技术价值
- 3.1 调用图的概念与表示
- 3.2 静态调用图分析
- 3.3 动态调用链追踪
- 3.4 静态与动态的对比与融合
- 4. 依赖图:Import/Export 关系与包依赖
- 本节核心技术价值
- 4.1 依赖图的层次结构
- 4.2 Import/Export 关系提取
- 5. 可视化:Graph 布局算法与交互
- 本节核心技术价值
- 5.1 图布局算法概述
- 5.2 Force-Directed 布局算法
- 6. 应用场景:影响分析、架构评估、重构规划
- 本节核心技术价值
- 6.1 变更影响分析
- 6.2 架构评估
- 7. 实践:使用 Tree-sitter 构建多语言 Repository Graph
- 本节核心技术价值
- 7.1 Tree-sitter 概述
- 7.2 Tree-sitter Python 绑定
- 8. 总结与展望
- 8.1 核心概念回顾
- 8.2 技术演进趋势
- 8.3 关键结论
- 附录 A:符号表核心数据结构的完整定义
- 附录 B:调用图数据结构的完整定义
- 附录 C:依赖图数据结构的完整定义
- 附录 D:Tree-sitter 多语言支持扩展
- 1.1 从代码补全到代码理解的鸿沟
- 1.2 Repository Graph 的定义与本质
- 1.3 Repository Graph 在 AI IDE 中的角色
- 本节核心技术价值
- 2.1 词法分析:字符流到 token 序列
- 2.2 语法分析:Token 序列到 AST
- 2.3 符号表构建
- 本节核心技术价值
- 3.1 调用图的概念与表示
- 3.2 静态调用图分析
- 3.3 动态调用链追踪
- 3.4 静态与动态的对比与融合
- 本节核心技术价值
- 4.1 依赖图的层次结构
- 4.2 Import/Export 关系提取
- 本节核心技术价值
- 5.1 图布局算法概述
- 5.2 Force-Directed 布局算法
- 本节核心技术价值
- 6.1 变更影响分析
- 6.2 架构评估
- 本节核心技术价值
- 7.1 Tree-sitter 概述
- 7.2 Tree-sitter Python 绑定
- 8.1 核心概念回顾
- 8.2 技术演进趋势
- 8.3 关键结论
本节核心技术价值
本文为你提供的核心价值是建立对代码结构理解完整技术栈的系统认知——从 AST 提取到符号表构建,从调用图生成到依赖图分析,最终实现基于 Graph 的代码理解能力。这不是零散工具的堆砌,而是揭示 AI IDE 如何"看懂"代码库的完整技术脉络。通过本文,你将理解为什么 Repository Graph 是 AI IDE 实现智能代码补全、精准影响分析、自动化重构的基石。
1. 引言:为什么 AI IDE 需要"看懂"代码
1.1 从代码补全到代码理解的鸿沟
当代码补全工具最初诞生时,它们的能力局限于语法层面的匹配——根据当前文件中已出现的标识符,提供基于前缀匹配的建议。这种补全方式在简单场景下有效,但随着代码规模增长,其局限性日益明显。
真正智能的代码服务需要回答远比"补全什么"更复杂的问题:
- 模块归属:这个函数属于哪个模块?它在整个代码库中扮演什么角色?
- 影响范围:修改这个函数会影响哪些调用方?风险有多高?
- 架构评估:代码库的依赖关系是否健康?是否存在循环依赖或过度耦合?
- 重构规划:如何安全地重构这段代码?需要同时修改哪些相关位置?
这些问题无法通过简单的文本匹配或语法分析回答。它们需要对代码库的完整结构有语义层面的理解——这正是 Repository Graph 存在的价值。
1.2 Repository Graph 的定义与本质
Repository Graph(代码库图)是一种多层次、有向、带属性的图结构,用于表达代码库的完整拓扑信息。它的节点和边携带丰富的语义信息:
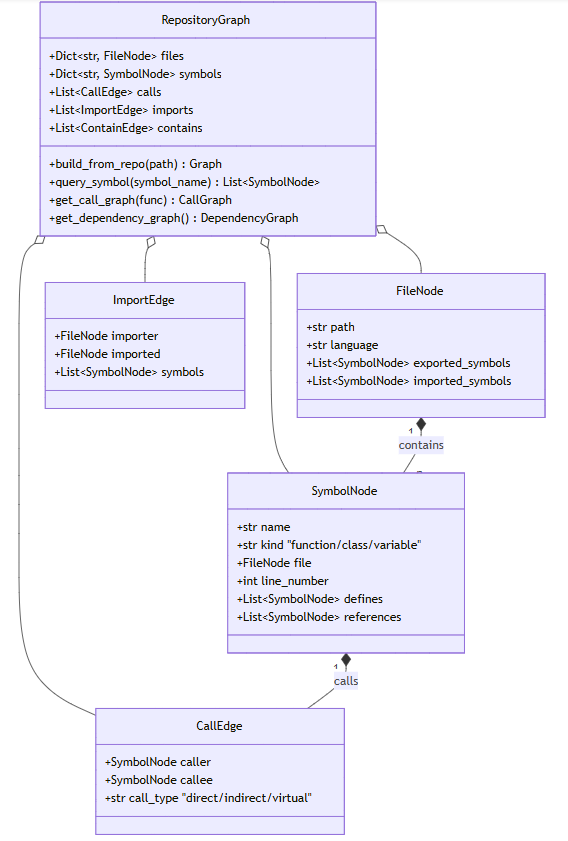
如上图所示,Repository Graph 的核心由四类节点(RepositoryGraph、FileNode、SymbolNode、CallEdge/ImportEdge)构成的有机整体。这个图的表达能力远超单纯的 AST——它不仅包含代码的语法结构,还包含跨越文件边界的语义关系。
1.3 Repository Graph 在 AI IDE 中的角色
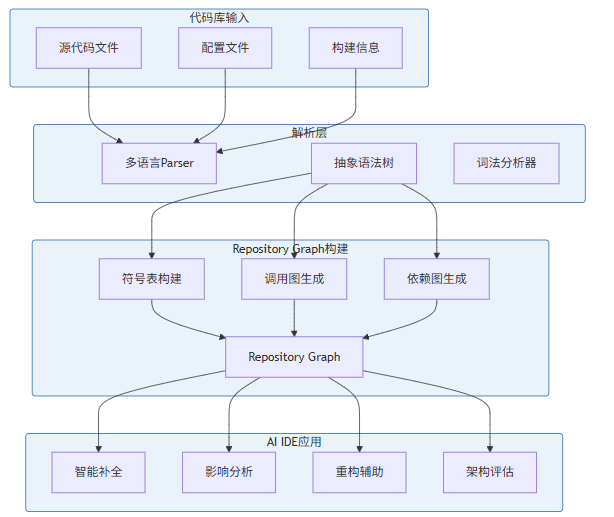
从架构图中可以看出,Repository Graph 处于解析层和应用层之间的关键位置。它将原始的、碎片化的代码信息整合为统一的、结构化的图表示,使得上层 AI 应用能够以统一的方式查询代码库的任意维度信息。
2. AST 提取与符号表构建
本节核心技术价值
本节为你提供的核心价值是理解从源代码到语义表示的完整转换链路——词法分析如何将字符流转换为 token 序列,语法分析如何将 token 序列组织为 AST,符号表如何捕获标识符的作用域和类型信息。这三者的结合为 Repository Graph 提供了最基本的节点信息。
2.1 词法分析:字符流到 token 序列
词法分析(Lexical Analysis)是编译原理中的第一阶段,其任务是将源代码的字符序列转换为 token 序列。每个 token 代表源代码中一个具有语法意义的最小单元。
token 的基本结构:
from dataclasses import dataclass
from enum import Enum
from typing import Optional
class TokenType(Enum):
"""Token 类型定义"""
EOF = "EOF"
IDENTIFIER = "IDENTIFIER"
DEF = "DEF"
CLASS = "CLASS"
IF = "IF"
ELSE = "ELSE"
FOR = "FOR"
WHILE = "WHILE"
RETURN = "RETURN"
IMPORT = "IMPORT"
FROM = "FROM"
STRING = "STRING"
NUMBER = "NUMBER"
PLUS = "PLUS"
MINUS = "MINUS"
STAR = "STAR"
SLASH = "SLASH"
EQ = "EQ"
EQ_EQ = "EQ_EQ"
LPAREN = "LPAREN"
RPAREN = "RPAREN"
LBRACE = "LBRACE"
RBRACE = "RBRACE"
LBRACKET = "LBRACKET"
RBRACKET = "RBRACKET"
COMMA = "COMMA"
DOT = "DOT"
COLON = "COLON"
SEMICOLON = "SEMICOLON"
NEWLINE = "NEWLINE"
@dataclass
class Token:
"""Token 表示源代码中的最小语法单元"""
type: TokenType
value: str
line: int
column: int
length: int
def __repr__(self):
return f"Token({self.type.value}, {self.value!r}, {self.line}:{self.column})"完整的词法分析器实现:
#!/usr/bin/env python3
"""
lexer.py - 完整的词法分析器实现
支持 Python 语法的子集,包括:
- 关键字识别
- 标识符识别
- 数字字面量(整数和浮点数)
- 字符串字面量
- 运算符和分隔符识别
- 行号和列号追踪
运行:python lexer.py <source_file.py>
"""
import re
from dataclasses import dataclass
from enum import Enum
from typing import List, Optional
class TokenType(Enum):
"""Token 类型定义"""
EOF = "EOF"
IDENTIFIER = "IDENTIFIER"
DEF = "DEF"
CLASS = "CLASS"
IF = "IF"
ELIF = "ELIF"
ELSE = "ELSE"
FOR = "FOR"
WHILE = "WHILE"
RETURN = "RETURN"
IMPORT = "IMPORT"
FROM = "FROM"
AS = "AS"
TRUE = "TRUE"
FALSE = "FALSE"
NONE = "NONE"
AND = "AND"
OR = "OR"
NOT = "NOT"
IN = "IN"
IS = "IS"
STRING = "STRING"
NUMBER = "NUMBER"
PLUS = "PLUS"
MINUS = "MINUS"
STAR = "STAR"
STAR_STAR = "STAR_STAR"
SLASH = "SLASH"
PERCENT = "PERCENT"
EQ = "EQ"
EQ_EQ = "EQ_EQ"
NOT_EQ = "NOT_EQ"
LT = "LT"
GT = "GT"
LT_EQ = "LT_EQ"
GT_EQ = "GT_EQ"
AMPERSAND = "AMPERSAND"
PIPE = "PIPE"
CIRCUMFLEX = "CIRCUMFLEX"
TILDE = "TILDE"
LPAREN = "LPAREN"
RPAREN = "RPAREN"
LBRACE = "LBRACE"
RBRACE = "RBRACE"
LBRACKET = "LBRACKET"
RBRACKET = "RBRACKET"
COMMA = "COMMA"
DOT = "DOT"
COLON = "COLON"
SEMICOLON = "SEMICOLON"
NEWLINE = "NEWLINE"
COMMENT = "COMMENT"
KEYWORDS = {
"def": TokenType.DEF,
"class": TokenType.CLASS,
"if": TokenType.IF,
"elif": TokenType.ELIF,
"else": TokenType.ELSE,
"for": TokenType.FOR,
"while": TokenType.WHILE,
"return": TokenType.RETURN,
"import": TokenType.IMPORT,
"from": TokenType.FROM,
"as": TokenType.AS,
"True": TokenType.TRUE,
"False": TokenType.FALSE,
"None": TokenType.NONE,
"and": TokenType.AND,
"or": TokenType.OR,
"not": TokenType.NOT,
"in": TokenType.IN,
"is": TokenType.IS,
}
@dataclass
class Token:
"""Token 数据结构"""
type: TokenType
value: str
line: int
column: int
end_line: int
end_column: int
def __repr__(self):
return f"Token({self.type.value}, {self.value!r}, {self.line}:{self.column})"
class LexerError(Exception):
def __init__(self, message: str, line: int, column: int):
super().__init__(f"Lexer error at {line}:{column}: {message}")
class Lexer:
"""Python 词法分析器"""
PATTERNS = [
(r'"""[\s\S]*?"""', TokenType.STRING),
(r"'''[\s\S]*?'''", TokenType.STRING),
(r'"(?:[^"\\]|\\.)*"', TokenType.STRING),
(r"'(?:[^'\\]|\\.)*'", TokenType.STRING),
(r'0[xX][0-9a-fA-F]+', TokenType.NUMBER),
(r'0[oO][0-7]+', TokenType.NUMBER),
(r'0[bB][01]+', TokenType.NUMBER),
(r'\d+\.\d+([eE][+-]?\d+)?', TokenType.NUMBER),
(r'\d+[eE][+-]?\d+', TokenType.NUMBER),
(r'\d+\.', TokenType.NUMBER),
(r'\d+', TokenType.NUMBER),
(r'[a-zA-Z_][a-zA-Z0-9_]*', TokenType.IDENTIFIER),
(r'\*\*', TokenType.STAR_STAR),
(r'\.\.\.', TokenType.DOT),
(r'!=', TokenType.NOT_EQ),
(r'==', TokenType.EQ_EQ),
(r'<=', TokenType.LT_EQ),
(r'>=', TokenType.GT_EQ),
(r'\+=', TokenType.PLUS),
(r'-=', TokenType.MINUS),
(r'\*=', TokenType.STAR),
(r'/=', TokenType.SLASH),
(r'->', TokenType.MINUS),
(r'\+', TokenType.PLUS),
(r'-', TokenType.MINUS),
(r'%', TokenType.PERCENT),
(r'=', TokenType.EQ),
(r'&', TokenType.AMPERSAND),
(r'\|', TokenType.PIPE),
(r'\^', TokenType.CIRCUMFLEX),
(r'~', TokenType.TILDE),
(r'<', TokenType.LT),
(r'>', TokenType.GT),
(r'\(', TokenType.LPAREN),
(r'\)', TokenType.RPAREN),
(r'\[', TokenType.LBRACKET),
(r'\]', TokenType.RBRACKET),
(r'\{', TokenType.LBRACE),
(r'\}', TokenType.RBRACE),
(r',', TokenType.COMMA),
(r'\.', TokenType.DOT),
(r':', TokenType.COLON),
(r';', TokenType.SEMICOLON),
(r'#.*', TokenType.COMMENT),
]
def __init__(self, source: str, file_path: str = "<unknown>"):
self.source = source
self.file_path = file_path
self.pos = 0
self.line = 1
self.column = 1
self.tokens: List[Token] = []
def tokenize(self) -> List[Token]:
"""执行词法分析"""
while self.pos < len(self.source):
self._skip_whitespace()
if self.pos >= len(self.source):
break
token = self._next_token()
if token and token.type != TokenType.COMMENT:
self.tokens.append(token)
self.tokens.append(Token(TokenType.EOF, '', self.line, self.column, self.line, self.column))
return self.tokens
def _skip_whitespace(self):
"""跳过空白字符"""
while self.pos < len(self.source):
char = self.source[self.pos]
if char == '\n':
self.line += 1
self.column = 1
self.pos += 1
elif char in ' \t\r':
self.column += 1
self.pos += 1
else:
break
def _next_token(self) -> Optional[Token]:
"""识别下一个 token"""
start_pos = self.pos
start_line = self.line
start_column = self.column
for pattern, token_type in self.PATTERNS:
regex = re.compile(pattern)
match = regex.match(self.source, self.pos)
if match:
value = match.group(0)
end_pos = match.end()
end_line = start_line
end_column = start_column
for i in range(start_pos, end_pos):
if self.source[i] == '\n':
end_line += 1
end_column = 1
else:
end_column += 1
self.pos = end_pos
self.column = end_column
if token_type == TokenType.IDENTIFIER and value in KEYWORDS:
token_type = KEYWORDS[value]
return Token(token_type, value, start_line, start_column, end_line, end_column)
char = self.source[self.pos]
raise LexerError(f"Unexpected character: {char!r}", self.line, self.column)
def lex_file(file_path: str) -> List[Token]:
"""对文件进行词法分析"""
with open(file_path, 'r', encoding='utf-8') as f:
source = f.read()
lexer = Lexer(source, file_path)
return lexer.tokenize()
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
print("Usage: python lexer.py <source_file.py>")
sys.exit(1)
file_path = sys.argv[1]
try:
tokens = lex_file(file_path)
print(f"Successfully tokenized {len(tokens)} tokens from {file_path}")
for token in tokens[:30]:
print(f" {token}")
if len(tokens) > 30:
print(f" ... and {len(tokens) - 30} more tokens")
except LexerError as e:
print(f"Error: {e}")
sys.exit(1)这个词法分析器实现了完整的状态机逻辑,能够正确处理:
- 关键字识别:通过映射表而非状态机实现高效查找
- 字符串字面量:支持单引号、双引号以及三引号变体
- 数字字面量:支持十进制、十六进制、八进制、二进制及科学计数法
- 位置追踪:精确记录每个 token 的起止行列号
2.2 语法分析:Token 序列到 AST
抽象语法树(Abstract Syntax Tree,AST)是源代码语法结构的树状表示。每个 AST 节点对应源代码中的一个语法构造,如表达式、语句、函数定义等。
AST 节点基类定义:
from abc import ABC, abstractmethod
from dataclasses import dataclass
from typing import List, Optional
from enum import Enum
class ASTNodeType(Enum):
"""AST 节点类型枚举"""
MODULE = "Module"
FUNCTION_DEF = "FunctionDef"
CLASS_DEF = "ClassDef"
PARAMETER = "Parameter"
EXPRESSION_STMT = "ExprStmt"
IF_STMT = "If"
FOR_STMT = "For"
WHILE_STMT = "While"
RETURN_STMT = "Return"
ASSIGNMENT_STMT = "Assign"
BINARY_EXPR = "BinaryExpr"
UNARY_EXPR = "UnaryExpr"
CALL_EXPR = "Call"
MEMBER_EXPR = "Member"
NAME = "Name"
LITERAL = "Literal"
LAMBDA = "Lambda"
LIST_LITERAL = "List"
DICT_LITERAL = "Dict"
ARGUMENTS = "Arguments"
IMPORT_DECL = "ImportDecl"
FROM_IMPORT = "FromImport"
@dataclass
class Position:
"""源代码位置"""
line: int
column: int
def __str__(self):
return f"{self.line}:{self.column}"
class ASTNode(ABC):
"""AST 节点基类"""
def __init__(self, node_type: ASTNodeType, position: Optional[Position] = None):
self.node_type = node_type
self.position = position
self.children: List[ASTNode] = []
def add_child(self, child: 'ASTNode'):
self.children.append(child)
def __repr__(self):
return f"{self.node_type.value}@{self.position}"
@dataclass
class Program(ASTNode):
"""程序根节点"""
def __init__(self):
super().__init__(ASTNodeType.MODULE)
self.statements: List[ASTNode] = []
@dataclass
class FunctionDef(ASTNode):
"""函数定义"""
def __init__(self, name: str, args: List[ASTNode], body: List[ASTNode]):
super().__init__(ASTNodeType.FUNCTION_DEF)
self.name = name
self.args = args
self.body = body
@dataclass
class ClassDef(ASTNode):
"""类定义"""
def __init__(self, name: str, bases: List[ASTNode], body: List[ASTNode]):
super().__init__(ASTNodeType.CLASS_DEF)
self.name = name
self.bases = bases
self.body = body
@dataclass
class Call(ASTNode):
"""函数调用"""
def __init__(self, func: ASTNode, args: List[ASTNode]):
super().__init__(ASTNodeType.CALL_EXPR)
self.func = func
self.args = args
@dataclass
class Name(ASTNode):
"""名称表达式"""
def __init__(self, name: str):
super().__init__(ASTNodeType.NAME)
self.name = name
@dataclass
class Literal(ASTNode):
"""字面量"""
def __init__(self, value):
super().__init__(ASTNodeType.LITERAL)
self.value = value
@dataclass
class BinaryOp(ASTNode):
"""二元运算"""
def __init__(self, op: str, left: ASTNode, right: ASTNode):
super().__init__(ASTNodeType.BINARY_EXPR)
self.op = op
self.left = left
self.right = right
@dataclass
class UnaryOp(ASTNode):
"""一元运算"""
def __init__(self, op: str, operand: ASTNode):
super().__init__(ASTNodeType.UNARY_EXPR)
self.op = op
self.operand = operand
@dataclass
class Assignment(ASTNode):
"""赋值语句"""
def __init__(self, targets: List[ASTNode], value: ASTNode):
super().__init__(ASTNodeType.ASSIGNMENT_STMT)
self.targets = targets
self.value = value
@dataclass
class If(ASTNode):
"""if 语句"""
def __init__(self, test: ASTNode, body: List[ASTNode], orelse: List[ASTNode]):
super().__init__(ASTNodeType.IF_STMT)
self.test = test
self.body = body
self.orelse = orelse
@dataclass
class For(ASTNode):
"""for 循环"""
def __init__(self, target: ASTNode, iter_node: ASTNode, body: List[ASTNode]):
super().__init__(ASTNodeType.FOR_STMT)
self.target = target
self.iter_node = iter_node
self.body = body
@dataclass
class While(ASTNode):
"""while 循环"""
def __init__(self, test: ASTNode, body: List[ASTNode]):
super().__init__(ASTNodeType.WHILE_STMT)
self.test = test
self.body = body
@dataclass
class Return(ASTNode):
"""return 语句"""
def __init__(self, value: Optional[ASTNode]):
super().__init__(ASTNodeType.RETURN_STMT)
self.value = value
@dataclass
class Import(ASTNode):
"""import 语句"""
def __init__(self, names: List[str]):
super().__init__(ASTNodeType.IMPORT_DECL)
self.names = names
@dataclass
class FromImport(ASTNode):
"""from ... import 语句"""
def __init__(self, module: str, names: List[str]):
super().__init__(ASTNodeType.FROM_IMPORT)
self.module = module
self.names = names完整的语法分析器实现:
#!/usr/bin/env python3
"""
parser.py - 完整的语法分析器实现
基于递归下降算法的 Python 语法分析器
输入:Token 序列
输出:AST(抽象语法树)
运行:python parser.py <source_file.py>
"""
from typing import List, Optional, Dict
import sys
from lexer import Lexer, Token, TokenType, lex_file
class ParseError(Exception):
def __init__(self, message: str, token: Token):
super().__init__(f"Parse error at {token.line}:{token.column}: {message}")
self.token = token
class ASTNode:
def __init__(self, node_type: str):
self.node_type = node_type
self.children: List[ASTNode] = []
def add_child(self, child: 'ASTNode'):
self.children.append(child)
def __repr__(self):
return f"{self.node_type}"
@dataclass
class Program(ASTNode):
def __init__(self):
super().__init__("Program")
self.statements: List[ASTNode] = []
@dataclass
class FunctionDef(ASTNode):
def __init__(self, name: str, args: List[ASTNode], body: List[ASTNode]):
super().__init__("FunctionDef")
self.name = name
self.args = args
self.body = body
@dataclass
class ClassDef(ASTNode):
def __init__(self, name: str, bases: List[ASTNode], body: List[ASTNode]):
super().__init__("ClassDef")
self.name = name
self.bases = bases
self.body = body
@dataclass
class Call(ASTNode):
def __init__(self, func: ASTNode, args: List[ASTNode]):
super().__init__("Call")
self.func = func
self.args = args
@dataclass
class Name(ASTNode):
def __init__(self, name: str):
super().__init__("Name")
self.name = name
@dataclass
class Literal(ASTNode):
def __init__(self, value):
super().__init__("Literal")
self.value = value
@dataclass
class BinaryOp(ASTNode):
def __init__(self, op: str, left: ASTNode, right: ASTNode):
super().__init__("BinaryOp")
self.op = op
self.left = left
self.right = right
@dataclass
class UnaryOp(ASTNode):
def __init__(self, op: str, operand: ASTNode):
super().__init__("UnaryOp")
self.op = op
self.operand = operand
@dataclass
class Assignment(ASTNode):
def __init__(self, targets: List[ASTNode], value: ASTNode):
super().__init__("Assignment")
self.targets = targets
self.value = value
@dataclass
class If(ASTNode):
def __init__(self, test: ASTNode, body: List[ASTNode], orelse: List[ASTNode]):
super().__init__("If")
self.test = test
self.body = body
self.orelse = orelse
@dataclass
class For(ASTNode):
def __init__(self, target: ASTNode, iter_node: ASTNode, body: List[ASTNode]):
super().__init__("For")
self.target = target
self.iter_node = iter_node
self.body = body
@dataclass
class While(ASTNode):
def __init__(self, test: ASTNode, body: List[ASTNode]):
super().__init__("While")
self.test = test
self.body = body
@dataclass
class Return(ASTNode):
def __init__(self, value: Optional[ASTNode]):
super().__init__("Return")
self.value = value
@dataclass
class Import(ASTNode):
def __init__(self, names: List[str]):
super().__init__("Import")
self.names = names
@dataclass
class FromImport(ASTNode):
def __init__(self, module: str, names: List[str]):
super().__init__("FromImport")
self.module = module
self.names = names
class Parser:
"""递归下降语法分析器"""
PRECEDENCE = {
'or': 1, 'and': 2, 'not': 3,
'in': 4, 'not in': 4, 'is': 4, 'is not': 4,
'<': 5, '>': 5, '<=': 5, '>=': 5,
'|': 6, '^': 7, '&': 8,
'<<': 9, '>>': 9,
'+': 10, '-': 10,
'*': 11, '/': 11, '%': 11, '//': 11,
'**': 12,
}
def __init__(self, tokens: List[Token]):
self.tokens = tokens
self.pos = 0
self.current = tokens[0] if tokens else None
def _advance(self):
self.pos += 1
if self.pos < len(self.tokens):
self.current = self.tokens[self.pos]
return self.current
def _peek(self, offset: int = 1) -> Optional[Token]:
peek_pos = self.pos + offset
if peek_pos < len(self.tokens):
return self.tokens[peek_pos]
return None
def _check(self, token_type: TokenType) -> bool:
return self.current and self.current.type == token_type
def _match(self, *token_types: TokenType) -> bool:
for token_type in token_types:
if self._check(token_type):
self._advance()
return True
return False
def _expect(self, token_type: TokenType, message: str):
if not self._check(token_type):
raise ParseError(message, self.current)
token = self.current
self._advance()
return token
def parse(self) -> Program:
program = Program()
while not self._check(TokenType.EOF):
try:
stmt = self._parse_statement()
if stmt:
program.statements.append(stmt)
except ParseError as e:
print(f"Error: {e}")
self._skip_to_statement_boundary()
return program
def _skip_to_statement_boundary(self):
while not self._check(TokenType.EOF):
if self._check(TokenType.NEWLINE):
self._advance()
return
self._advance()
def _parse_statement(self) -> Optional[ASTNode]:
while self._match(TokenType.NEWLINE):
pass
if self._check(TokenType.EOF):
return None
if self._check(TokenType.DEF):
return self._parse_function_def()
elif self._check(TokenType.CLASS):
return self._parse_class_def()
elif self._check(TokenType.IF):
return self._parse_if()
elif self._check(TokenType.FOR):
return self._parse_for()
elif self._check(TokenType.WHILE):
return self._parse_while()
elif self._check(TokenType.RETURN):
return self._parse_return()
elif self._check(TokenType.IMPORT):
return self._parse_import()
elif self._check(TokenType.FROM):
return self._parse_from_import()
else:
return self._parse_expression_statement()
def _parse_function_def(self) -> FunctionDef:
self._advance()
name_token = self._expect(TokenType.IDENTIFIER, "Expected function name")
name = name_token.value
self._expect(TokenType.LPAREN, "Expected '(' after function name")
args = self._parse_arguments()
self._expect(TokenType.RPAREN, "Expected ')' after arguments")
self._expect(TokenType.COLON, "Expected ':' after function signature")
self._expect(TokenType.NEWLINE, "Expected newline after ':'")
body = self._parse_suite()
return FunctionDef(name, args, body)
def _parse_class_def(self) -> ClassDef:
self._advance()
name_token = self._expect(TokenType.IDENTIFIER, "Expected class name")
name = name_token.value
bases = []
if self._match(TokenType.LPAREN):
bases = self._parse_arguments()
self._expect(TokenType.RPAREN, "Expected ')' after base classes")
self._expect(TokenType.COLON, "Expected ':' after class name")
self._expect(TokenType.NEWLINE, "Expected newline after ':'")
body = self._parse_suite()
return ClassDef(name, bases, body)
def _parse_arguments(self) -> List[ASTNode]:
args = []
while not self._check(TokenType.RPAREN) and not self._check(TokenType.EOF):
arg = self._parse_name()
args.append(arg)
if not self._match(TokenType.COMMA):
break
return args
def _parse_name(self) -> Name:
token = self._expect(TokenType.IDENTIFIER, "Expected identifier")
return Name(token.value)
def _parse_suite(self) -> List[ASTNode]:
statements = []
while self._match(TokenType.NEWLINE):
pass
while not self._check(TokenType.EOF):
if self._check(TokenType.DEDENT):
self._advance()
break
stmt = self._parse_statement()
if stmt:
statements.append(stmt)
return statements
def _parse_if(self) -> If:
self._advance()
test = self._parse_expression()
self._expect(TokenType.COLON, "Expected ':' after if condition")
self._expect(TokenType.NEWLINE, "Expected newline after ':'")
body = self._parse_suite()
orelse = []
while self._match(TokenType.ELIF):
elif_test = self._parse_expression()
self._expect(TokenType.COLON, "Expected ':' after elif condition")
self._expect(TokenType.NEWLINE, "Expected newline after ':'")
elif_body = self._parse_suite()
orelse.append(If(elif_test, elif_body, []))
if self._match(TokenType.ELSE):
self._expect(TokenType.COLON, "Expected ':' after else")
self._expect(TokenType.NEWLINE, "Expected newline after ':'")
orelse = self._parse_suite()
return If(test, body, orelse)
def _parse_for(self) -> For:
self._advance()
target = self._parse_expression()
self._expect(TokenType.IDENTIFIER, "Expected 'in' after for target")
self._expect(TokenType.IN, "Expected 'in'")
iter_expr = self._parse_expression()
self._expect(TokenType.COLON, "Expected ':' after for iterable")
self._expect(TokenType.NEWLINE, "Expected newline after ':'")
body = self._parse_suite()
return For(target, iter_expr, body)
def _parse_while(self) -> While:
self._advance()
test = self._parse_expression()
self._expect(TokenType.COLON, "Expected ':' after while condition")
self._expect(TokenType.NEWLINE, "Expected newline after ':'")
body = self._parse_suite()
return While(test, body)
def _parse_return(self) -> Return:
self._advance()
value = None
if not self._check(TokenType.NEWLINE) and not self._check(TokenType.EOF):
value = self._parse_expression()
self._match(TokenType.NEWLINE)
return Return(value)
def _parse_import(self) -> Import:
self._advance()
names = []
while True:
name_token = self._expect(TokenType.IDENTIFIER, "Expected module name")
names.append(name_token.value)
if not self._match(TokenType.COMMA):
break
self._match(TokenType.NEWLINE)
return Import(names)
def _parse_from_import(self) -> FromImport:
self._advance()
module_parts = []
while True:
token = self._expect(TokenType.IDENTIFIER, "Expected module name part")
module_parts.append(token.value)
if not self._match(TokenType.DOT):
break
module = '.'.join(module_parts)
self._expect(TokenType.IMPORT, "Expected 'import'")
names = []
if self._match(TokenType.STAR):
names = ['*']
else:
while True:
name_token = self._expect(TokenType.IDENTIFIER, "Expected name to import")
names.append(name_token.value)
if not self._match(TokenType.COMMA):
break
self._match(TokenType.NEWLINE)
return FromImport(module, names)
def _parse_expression_statement(self) -> ASTNode:
expr = self._parse_expression()
if self._match(TokenType.EQ):
targets = [expr]
value = self._parse_expression()
expr = Assignment(targets, value)
self._match(TokenType.NEWLINE)
return expr
def _parse_expression(self) -> ASTNode:
return self._parse_or()
def _parse_or(self) -> ASTNode:
left = self._parse_and()
while self._check(TokenType.IDENTIFIER) and self.current.value == 'or':
self._advance()
right = self._parse_and()
left = BinaryOp('or', left, right)
return left
def _parse_and(self) -> ASTNode:
left = self._parse_not()
while self._check(TokenType.IDENTIFIER) and self.current.value == 'and':
self._advance()
right = self._parse_not()
left = BinaryOp('and', left, right)
return left
def _parse_not(self) -> ASTNode:
if self._check(TokenType.IDENTIFIER) and self.current.value == 'not':
self._advance()
operand = self._parse_not()
return UnaryOp('not', operand)
return self._parse_comparison()
def _parse_comparison(self) -> ASTNode:
left = self._parse_add()
while True:
op = None
if self._check(TokenType.LT):
op = '<'
elif self._check(TokenType.GT):
op = '>'
elif self._check(TokenType.EQ_EQ):
op = '=='
elif self._check(TokenType.NOT_EQ):
op = '!='
elif self._check(TokenType.LT_EQ):
op = '<='
elif self._check(TokenType.GT_EQ):
op = '>='
elif self._check(TokenType.IDENTIFIER):
if self.current.value == 'in':
self._advance()
op = 'in'
elif self.current.value == 'is':
self._advance()
if self._check(TokenType.IDENTIFIER) and self.current.value == 'not':
self._advance()
op = 'is not'
else:
op = 'is'
if not op:
break
self._advance()
right = self._parse_add()
left = BinaryOp(op, left, right)
return left
def _parse_add(self) -> ASTNode:
left = self._parse_mult()
while True:
op = None
if self._check(TokenType.PLUS):
op = '+'
elif self._check(TokenType.MINUS):
op = '-'
if not op:
break
self._advance()
right = self._parse_mult()
left = BinaryOp(op, left, right)
return left
def _parse_mult(self) -> ASTNode:
left = self._parse_power()
while True:
op = None
if self._check(TokenType.STAR):
op = '*'
elif self._check(TokenType.SLASH):
op = '/'
elif self._check(TokenType.PERCENT):
op = '%'
if not op:
break
self._advance()
right = self._parse_power()
left = BinaryOp(op, left, right)
return left
def _parse_power(self) -> ASTNode:
left = self._parse_unary()
if self._check(TokenType.STAR_STAR):
self._advance()
right = self._parse_unary()
left = BinaryOp('**', left, right)
return left
def _parse_unary(self) -> ASTNode:
if self._check(TokenType.MINUS):
self._advance()
operand = self._parse_unary()
return UnaryOp('-', operand)
elif self._check(TokenType.PLUS):
self._advance()
return self._parse_unary()
elif self._check(TokenType.TILDE):
self._advance()
operand = self._parse_unary()
return UnaryOp('~', operand)
return self._parse_call()
def _parse_call(self) -> ASTNode:
expr = self._parse_atom()
while True:
if self._check(TokenType.LPAREN):
self._advance()
args = self._parse_call_arguments()
self._expect(TokenType.RPAREN, "Expected ')' after arguments")
expr = Call(expr, args)
elif self._check(TokenType.DOT):
self._advance()
attr = self._expect(TokenType.IDENTIFIER, "Expected attribute name")
expr = BinaryOp('.', expr, Name(attr.value))
elif self._check(TokenType.LBRACKET):
self._advance()
index = self._parse_expression()
self._expect(TokenType.RBRACKET, "Expected ']' after index")
expr = BinaryOp('[]', expr, index)
else:
break
return expr
def _parse_call_arguments(self) -> List[ASTNode]:
args = []
if self._check(TokenType.RPAREN):
return args
while True:
arg = self._parse_expression()
args.append(arg)
if not self._match(TokenType.COMMA):
break
return args
def _parse_atom(self) -> ASTNode:
if self._check(TokenType.STRING):
token = self.current
self._advance()
return Literal(token.value)
if self._check(TokenType.NUMBER):
token = self.current
self._advance()
try:
if '.' in token.value or 'e' in token.value.lower():
return Literal(float(token.value))
return Literal(int(token.value))
except ValueError:
return Literal(token.value)
if self._check(TokenType.TRUE):
self._advance()
return Literal(True)
if self._check(TokenType.FALSE):
self._advance()
return Literal(False)
if self._check(TokenType.NONE):
self._advance()
return Literal(None)
if self._check(TokenType.IDENTIFIER):
token = self.current
self._advance()
return Name(token.value)
if self._match(TokenType.LPAREN):
if self._check(TokenType.RPAREN):
self._advance()
return Literal(())
expr = self._parse_expression()
self._expect(TokenType.RPAREN, "Expected ')'")
return expr
if self._match(TokenType.LBRACKET):
elements = []
if not self._check(TokenType.RBRACKET):
while True:
elements.append(self._parse_expression())
if not self._match(TokenType.COMMA):
break
self._expect(TokenType.RBRACKET, "Expected ']'")
return Literal(elements)
if self._match(TokenType.LBRACE):
pairs = []
if not self._check(TokenType.RBRACE):
while True:
key = self._parse_expression()
self._expect(TokenType.COLON, "Expected ':'")
value = self._parse_expression()
pairs.append((key, value))
if not self._match(TokenType.COMMA):
break
self._expect(TokenType.RBRACE, "Expected '}'")
return Literal(dict(pairs))
raise ParseError(f"Unexpected token: {self.current.type}", self.current)
def parse_file(file_path: str) -> Program:
"""解析文件为 AST"""
tokens = lex_file(file_path)
parser = Parser(tokens)
return parser.parse()
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python parser.py <source_file.py>")
sys.exit(1)
file_path = sys.argv[1]
try:
program = parse_file(file_path)
print(f"Successfully parsed {file_path}")
print(f"Found {len(program.statements)} top-level statements")
for i, stmt in enumerate(program.statements[:10]):
print(f" {i+1}. {stmt}")
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
sys.exit(1)2.3 符号表构建
符号表(Symbol Table)是用于存储关于变量、函数、类等标识符信息的数据结构。它是语义分析的核心,为后续的类型检查、作用域解析、代码生成提供基础。
符号表的核心数据结构:
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Set
from enum import Enum
class SymbolKind(Enum):
"""符号种类"""
MODULE = "module"
CLASS = "class"
FUNCTION = "function"
METHOD = "method"
VARIABLE = "variable"
PARAMETER = "parameter"
CONSTANT = "constant"
TYPE = "type"
IMPORT = "import"
@dataclass
class Symbol:
"""符号定义"""
name: str
kind: SymbolKind
file_path: str
line: int
column: int
type_info: Optional[str] = None
value: Optional[any] = None
is_exported: bool = False
is_builtin: bool = False
references: List['Reference'] = field(default_factory=list)
scope_id: Optional[str] = None
@dataclass
class Reference:
"""符号引用"""
name: str
file_path: str
line: int
column: int
resolved_symbol: Optional[Symbol] = None
@dataclass
class Scope:
"""作用域"""
id: str
kind: str
parent: Optional['Scope'] = None
children: List['Scope'] = field(default_factory=list)
symbols: Dict[str, Symbol] = field(default_factory=dict)
start_line: int = 0
end_line: int = 0
file_path: str = ""
class SymbolTable:
"""符号表管理器"""
def __init__(self, project_path: str):
self.project_path = project_path
self.scopes: Dict[str, Scope] = {}
self.symbols: Dict[str, List[Symbol]] = {}
self.global_scope = self._create_scope("global", "global", file_path=project_path)
self.current_scope = self.global_scope
self.scope_stack = [self.global_scope]
self.stats = {
"files_processed": 0,
"symbols_defined": 0,
"references_resolved": 0,
"unresolved_references": []
}
def _create_scope(self, scope_id: str, kind: str,
parent: Optional[Scope] = None,
file_path: str = "") -> Scope:
scope = Scope(id=scope_id, kind=kind, parent=parent, file_path=file_path)
self.scopes[scope_id] = scope
if parent:
parent.children.append(scope)
return scope
def enter_scope(self, scope_id: str, kind: str,
file_path: str = "", start_line: int = 0) -> Scope:
parent = self.current_scope
scope = self._create_scope(scope_id, kind, parent, file_path)
scope.start_line = start_line
self.current_scope = scope
self.scope_stack.append(scope)
return scope
def exit_scope(self, end_line: int = 0):
if len(self.scope_stack) > 1:
self.current_scope.end_line = end_line
self.scope_stack.pop()
self.current_scope = self.scope_stack[-1]
def define_symbol(self, name: str, kind: SymbolKind,
file_path: str, line: int, column: int,
type_info: Optional[str] = None,
is_exported: bool = False) -> Symbol:
symbol = Symbol(
name=name, kind=kind, file_path=file_path,
line=line, column=column, type_info=type_info,
is_exported=is_exported, scope_id=self.current_scope.id
)
self.current_scope.symbols[name] = symbol
if name not in self.symbols:
self.symbols[name] = []
self.symbols[name].append(symbol)
self.stats["symbols_defined"] += 1
return symbol
def lookup_symbol(self, name: str, search_parent: bool = True) -> Optional[Symbol]:
scope = self.current_scope
while scope:
if name in scope.symbols:
return scope.symbols[name]
if not search_parent:
break
scope = scope.parent
return None
def resolve_reference(self, name: str, file_path: str,
line: int, column: int) -> Optional[Symbol]:
reference = Reference(name, file_path, line, column)
symbol = self.lookup_symbol(name)
if symbol:
reference.resolved_symbol = symbol
symbol.references.append(reference)
self.stats["references_resolved"] += 1
else:
self.stats["unresolved_references"].append(reference)
return symbol
def get_symbols_by_kind(self, kind: SymbolKind) -> List[Symbol]:
result = []
for symbols in self.symbols.values():
result.extend(s for s in symbols if s.kind == kind)
return result
def generate_report(self) -> str:
lines = [
"=== Symbol Table Report ===",
f"Project: {self.project_path}",
f"Files processed: {self.stats['files_processed']}",
f"Symbols defined: {self.stats['symbols_defined']}",
f"References resolved: {self.stats['references_resolved']}",
f"Unresolved references: {len(self.stats['unresolved_references'])}",
"",
"--- Functions ---"
]
for func in self.get_symbols_by_kind(SymbolKind.FUNCTION):
lines.append(f" {func.name} @ {func.file_path}:{func.line}")
lines.append("")
lines.append("--- Classes ---")
for cls in self.get_symbols_by_kind(SymbolKind.CLASS):
lines.append(f" {cls.name} @ {cls.file_path}:{cls.line}")
return "\n".join(lines)3. 调用图:静态分析 vs 动态追踪
本节核心技术价值
本节为你提供的核心价值是理解调用图构建的两种范式——静态分析和动态追踪的原理、优缺点及适用场景。调用图是代码理解的核心视图,它揭示了程序的控制流和模块间的交互模式。
3.1 调用图的概念与表示
**调用图(Call Graph)**是一个有向图,其中节点表示函数(或方法),边表示调用关系。当函数 A 调用函数 B 时,图中存在一条从 A 到 B 的边。
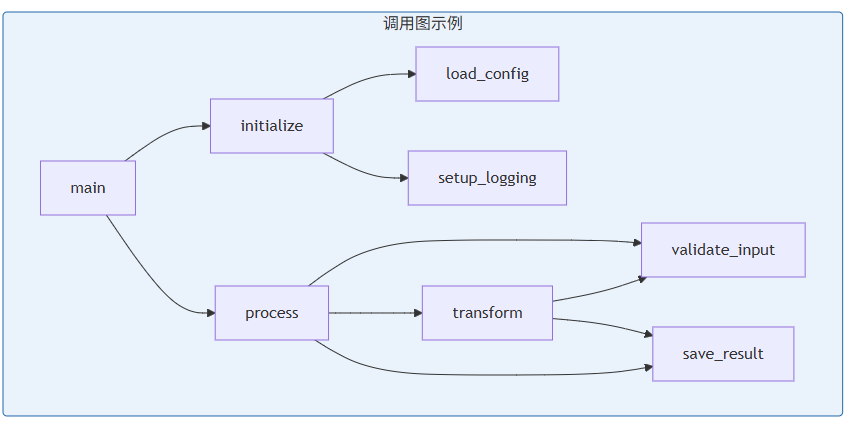
调用图的数学定义:
调用图
,其中:
是节点集合,每个节点
表示一个函数
是有向边集合,每条边
表示函数
调用了函数
3.2 静态调用图分析
静态分析在不执行代码的情况下推断调用关系。其核心优势是覆盖全面——理论上可以分析所有可能的执行路径。
基于 AST 的调用图构建:
#!/usr/bin/env python3
"""
static_call_graph.py - 静态调用图构建器
功能:
- 从 AST 中提取所有函数调用
- 构建调用图
- 计算调用深度和复杂度指标
- 检测递归和循环
运行:python static_call_graph.py <source_file.py>
"""
import sys
from typing import Dict, List, Set, Optional, Tuple
from dataclasses import dataclass, field
from collections import defaultdict
@dataclass
class CallGraphNode:
"""调用图节点"""
name: str
fully_qualified_name: str
file_path: str
line: int
kind: str
callee_count: int = 0
caller_count: int = 0
depth: int = 0
callees: Set[str] = field(default_factory=set)
callers: Set[str] = field(default_factory=set)
class CallGraph:
"""调用图"""
def __init__(self):
self.nodes: Dict[str, CallGraphNode] = {}
self.edges: Set[Tuple[str, str]] = set()
self.external_calls: Set[str] = set()
self.stats = {
"total_functions": 0,
"total_calls": 0,
"external_calls": 0,
"recursive_functions": set(),
"max_depth": 0
}
def add_node(self, name: str, fqn: str, file_path: str,
line: int, kind: str) -> CallGraphNode:
if name not in self.nodes:
node = CallGraphNode(
name=name, fully_qualified_name=fqn,
file_path=file_path, line=line, kind=kind
)
self.nodes[name] = node
self.stats["total_functions"] += 1
return self.nodes[name]
def add_edge(self, caller: str, callee: str):
if caller == callee:
self.stats["recursive_functions"].add(caller)
if caller not in self.nodes:
return
if callee not in self.nodes:
self.external_calls.add(callee)
self.stats["external_calls"] += 1
return
self.edges.add((caller, callee))
self.nodes[caller].callees.add(callee)
self.nodes[caller].callee_count += 1
self.nodes[callee].callers.add(caller)
self.nodes[callee].caller_count += 1
self.stats["total_calls"] += 1
def get_callees(self, function: str) -> Set[str]:
result = set()
visited = set()
queue = [function]
while queue:
current = queue.pop()
if current in visited:
continue
visited.add(current)
if current in self.nodes:
for callee in self.nodes[current].callees:
result.add(callee)
queue.append(callee)
return result
def get_callers(self, function: str) -> Set[str]:
result = set()
visited = set()
queue = [function]
while queue:
current = queue.pop()
if current in visited:
continue
visited.add(current)
if current in self.nodes:
for caller in self.nodes[current].callers:
result.add(caller)
queue.append(caller)
return result
def calculate_depths(self):
leafs = [name for name, node in self.nodes.items() if node.callee_count == 0]
for leaf in leafs:
self._calculate_depth_bfs(leaf)
self.stats["max_depth"] = max(n.depth for n in self.nodes.values()) if self.nodes else 0
def _calculate_depth_bfs(self, start: str, current_depth: int = 0):
visited = set()
queue = [(start, current_depth)]
while queue:
current, depth = queue.pop(0)
if current in visited:
continue
visited.add(current)
if current in self.nodes:
self.nodes[current].depth = max(self.nodes[current].depth, depth)
for caller in self.nodes[current].callers:
queue.append((caller, depth + 1))
def find_cycles(self) -> List[List[str]]:
cycles = []
visited = set()
rec_stack = set()
def dfs(node: str, path: List[str]):
if node in rec_stack:
cycle_start = path.index(node)
cycle = path[cycle_start:] + [node]
cycles.append(cycle)
return
if node in visited:
return
visited.add(node)
rec_stack.add(node)
path.append(node)
if node in self.nodes:
for callee in self.nodes[node].callees:
dfs(callee, path[:])
rec_stack.remove(node)
for node in self.nodes:
if node not in visited:
dfs(node, [])
return cycles
def generate_dot(self) -> str:
lines = ["digraph CallGraph {", " rankdir=TB;"]
for name, node in self.nodes.items():
label = f"{node.name}\\n({node.kind})"
lines.append(f' "{name}" [label="{label}", shape=box];')
for caller, callee in self.edges:
lines.append(f' "{caller}" -> "{callee}";')
for ext in self.external_calls:
lines.append(f' "{ext}" [shape=ellipse, style=dashed];')
lines.append("}")
return "\n".join(lines)
class StaticCallGraphBuilder:
"""静态调用图构建器"""
def __init__(self, symbol_table):
self.symbol_table = symbol_table
self.call_graph = CallGraph()
self.current_function: Optional[str] = None
self.current_class: Optional[str] = None
def build_from_file(self, file_path: str, ast) -> CallGraph:
"""从 AST 构建调用图"""
self._collect_functions(ast, file_path)
self._analyze_calls(ast, file_path)
self.call_graph.calculate_depths()
return self.call_graph
def _collect_functions(self, node, file_path: str):
"""第一遍:收集函数定义"""
node_type = type(node).__name__
if node_type == "FunctionDef":
fqn = self._get_fully_qualified_name(node.name)
self.call_graph.add_node(
name=node.name, fqn=fqn, file_path=file_path,
line=0, kind="method" if self.current_class else "function"
)
old_function = self.current_function
self.current_function = fqn
for stmt in getattr(node, 'body', []):
self._collect_functions(stmt, file_path)
self.current_function = old_function
elif node_type == "ClassDef":
old_class = self.current_class
self.current_class = node.name
for stmt in getattr(node, 'body', []):
self._collect_functions(stmt, file_path)
self.current_class = old_class
elif node_type == "Program":
for stmt in getattr(node, 'statements', []):
self._collect_functions(stmt, file_path)
else:
for child in getattr(node, 'children', []):
self._collect_functions(child, file_path)
def _analyze_calls(self, node, file_path: str):
"""第二遍:分析调用关系"""
node_type = type(node).__name__
if node_type == "Call":
self._analyze_call(node, file_path)
elif node_type == "FunctionDef":
fqn = self._get_fully_qualified_name(node.name)
old_function = self.current_function
self.current_function = fqn
for stmt in getattr(node, 'body', []):
self._analyze_calls(stmt, file_path)
self.current_function = old_function
elif node_type == "ClassDef":
old_class = self.current_class
self.current_class = node.name
for stmt in getattr(node, 'body', []):
self._analyze_calls(stmt, file_path)
self.current_class = old_class
elif node_type == "Program":
for stmt in getattr(node, 'statements', []):
self._analyze_calls(stmt, file_path)
else:
for child in getattr(node, 'children', []):
self._analyze_calls(child, file_path)
def _analyze_call(self, node, file_path: str):
"""分析函数调用"""
if not self.current_function:
return
callee_name = None
if type(node.func).__name__ == "Name":
callee_name = node.func.name
elif type(node.func).__name__ == "BinaryOp" and node.func.op == '.':
if type(node.func.right).__name__ == "Name":
callee_name = node.func.right.name
if callee_name:
self.call_graph.add_edge(self.current_function, callee_name)
def _get_fully_qualified_name(self, name: str) -> str:
parts = []
if self.current_class:
parts.append(self.current_class)
parts.append(name)
return ".".join(parts)
if __name__ == "__main__":
from lexer import lex_file
from parser import Parser
if len(sys.argv) < 2:
print("Usage: python static_call_graph.py <source_file.py>")
sys.exit(1)
file_path = sys.argv[1]
try:
tokens = lex_file(file_path)
parser = Parser(tokens)
program = parser.parse()
class SimpleSymbolTable:
def __init__(self): self.symbols = {}
def lookup_symbol(self, name): return None
symbol_table = SimpleSymbolTable()
builder = StaticCallGraphBuilder(symbol_table)
call_graph = builder.build_from_file(file_path, program)
print("=== Call Graph Analysis ===")
print(f"Total functions: {call_graph.stats['total_functions']}")
print(f"Total calls: {call_graph.stats['total_calls']}")
print(f"External calls: {call_graph.stats['external_calls']}")
print(f"Max depth: {call_graph.stats['max_depth']}")
print(f"Recursive functions: {len(call_graph.stats['recursive_functions'])}")
cycles = call_graph.find_cycles()
if cycles:
print(f"\nFound {len(cycles)} call cycles:")
for cycle in cycles[:5]:
print(f" {' -> '.join(cycle)}")
dot = call_graph.generate_dot()
with open("call_graph.dot", "w") as f:
f.write(dot)
print("\nGenerated call_graph.dot")
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
sys.exit(1)3.3 动态调用链追踪
动态追踪在程序运行时记录实际的调用关系。相比静态分析,它提供的是实际执行的路径,而非可能的路径。
#!/usr/bin/env python3
"""
dynamic_call_tracer.py - 动态调用链追踪器
功能:
- 使用 Python tracing 机制拦截函数调用
- 记录调用栈和执行时间
- 生成运行时调用图
运行:python dynamic_call_tracer.py
"""
import sys
import time
import traceback as tb_module
from typing import Dict, List, Optional
from dataclasses import dataclass, field
from collections import defaultdict
from contextlib import contextmanager
import threading
import json
@dataclass
class CallRecord:
"""调用记录"""
caller: str
callee: str
timestamp: float
duration: float
thread_id: int
call_id: int
stack_depth: int
stack_trace: List[str] = field(default_factory=list)
class DynamicCallTracer:
"""动态调用追踪器"""
def __init__(self):
self.call_records: List[CallRecord] = []
self.call_count = 0
self.start_time = 0.0
self.call_counts: Dict[str, int] = defaultdict(int)
self.call_durations: Dict[str, List[float]] = defaultdict(list)
self.call_pairs: Dict[str, int] = defaultdict(int)
self.lock = threading.Lock()
self.exclude_modules = {"_threading", "threading", "traceback", "linecache"}
def record_call(self, caller: str, callee: str, duration: float = 0):
"""记录一次调用"""
with self.lock:
record = CallRecord(
caller=caller, callee=callee,
timestamp=time.time() - self.start_time,
duration=duration,
thread_id=threading.get_ident(),
call_id=self.call_count,
stack_depth=len(tb_module.extract_stack()) - 5,
stack_trace=[f"{f.filename}:{f.lineno} in {f.name}"
for f in tb_module.extract_stack()[-5:-1]]
)
self.call_records.append(record)
self.call_count += 1
self.call_counts[callee] += 1
self.call_durations[callee].append(duration)
self.call_pairs[f"{caller}->{callee}"] += 1
def generate_call_graph(self) -> Dict:
"""从调用记录生成调用图"""
nodes = {}
edges = {}
for record in self.call_records:
if record.callee not in nodes:
nodes[record.callee] = {
"name": record.callee,
"call_count": 0,
"total_duration": 0,
"avg_duration": 0
}
nodes[record.callee]["call_count"] += 1
nodes[record.callee]["total_duration"] += record.duration
edge_key = f"{record.caller}->{record.callee}"
if edge_key not in edges:
edges[edge_key] = {
"source": record.caller,
"target": record.callee,
"count": 0
}
edges[edge_key]["count"] += 1
for node in nodes.values():
if node["call_count"] > 0:
node["avg_duration"] = node["total_duration"] / node["call_count"]
return {"nodes": nodes, "edges": edges}
def find_hot_paths(self, min_calls: int = 10) -> List[List[str]]:
"""识别热路径"""
call_sequences: Dict[str, int] = defaultdict(int)
for i in range(len(self.call_records) - 1):
curr = self.call_records[i].callee
next_call = self.call_records[i + 1]
if next_call.caller == curr:
seq = f"{curr}->{next_call.callee}"
call_sequences[seq] += 1
hot_paths = sorted(call_sequences.items(), key=lambda x: -x[1])
return [(path, count) for path, count in hot_paths if count >= min_calls]
def analyze_performance(self) -> Dict:
"""性能分析"""
results = {
"total_calls": self.call_count,
"unique_functions": len(self.call_counts),
"execution_time": time.time() - self.start_time,
"top_functions": [],
"slowest_functions": []
}
sorted_by_count = sorted(self.call_counts.items(), key=lambda x: -x[1])[:10]
results["top_functions"] = [
{"function": name, "count": count}
for name, count in sorted_by_count
]
avg_times = {
name: sum(durations) / len(durations)
for name, durations in self.call_durations.items()
}
sorted_by_time = sorted(avg_times.items(), key=lambda x: -x[1])[:10]
results["slowest_functions"] = [
{"function": name, "avg_duration": avg}
for name, avg in sorted_by_time
]
return results
def export_json(self, filepath: str):
"""导出为 JSON"""
data = {
"call_graph": self.generate_call_graph(),
"performance": self.analyze_performance(),
"hot_paths": self.find_hot_paths()
}
with open(filepath, 'w') as f:
json.dump(data, f, indent=2)
print(f"Exported to {filepath}")
@contextmanager
def trace_calls(tracer: DynamicCallTracer):
"""上下文管理器:追踪代码块内的所有调用"""
import sys
tracer.start_time = time.time()
def trace_func(frame, event, arg):
if event == 'call':
filename = frame.f_code.co_filename
funcname = frame.f_code.co_name
if any(mod in filename for mod in tracer.exclude_modules):
return trace_func
return trace_func
old_trace = sys.gettrace()
sys.settrace(trace_func)
try:
yield tracer
finally:
sys.settrace(old_trace)
def example_utility_function(x: int) -> int:
"""示例工具函数"""
return x * 2
def example_process(data: list) -> int:
"""示例处理函数"""
result = 0
for item in data:
result += example_utility_function(item)
return result
def example_main():
"""示例主函数"""
tracer = DynamicCallTracer()
with trace_calls(tracer):
for i in range(100):
example_process(list(range(i)))
graph = tracer.generate_call_graph()
perf = tracer.analyze_performance()
hot_paths = tracer.find_hot_paths()
print("=== Dynamic Call Trace Results ===")
print(f"Total calls recorded: {perf['total_calls']}")
print(f"Unique functions: {perf['unique_functions']}")
print(f"Execution time: {perf['execution_time']:.4f}s")
print("\nTop 5 most called functions:")
for item in perf['top_functions'][:5]:
print(f" {item['function']}: {item['count']} calls")
tracer.export_json("call_trace.json")
if __name__ == "__main__":
example_main()3.4 静态与动态的对比与融合
维度 | 静态分析 | 动态追踪 |
|---|---|---|
覆盖范围 | 所有可能路径 | 实际执行路径 |
准确性 | 可能存在误报(虚假路径) | 无误报(真实路径) |
完整性 | 可能遗漏动态调用 | 遗漏未执行的路径 |
性能开销 | 无运行时开销 | 显著开销 |
适用场景 | 早期分析、重构规划 | 性能优化、调试 |
4. 依赖图:Import/Export 关系与包依赖
本节核心技术价值
本节为你提供的核心价值是理解依赖图构建的完整技术栈——从文件级别的导入关系到模块级别的包依赖,再到完整的项目依赖可视化。依赖图是代码架构分析、变更影响评估、重构安全规划的基础。
4.1 依赖图的层次结构
依赖图不是单一的结构,而是多层次的:

层次说明:
- 文件层:单个 .py 文件之间的 import 关系
- 模块层:Python 模块(带
__init__.py的目录)之间的依赖 - 包层:Python 包(发布单元)之间的依赖
4.2 Import/Export 关系提取
#!/usr/bin/env python3
"""
dependency_analyzer.py - Python 项目依赖分析器
功能:
- 提取所有 import 语句
- 构建文件级依赖图
- 检测循环依赖
- 生成依赖报告
运行:python dependency_analyzer.py <project_dir>
"""
import os
import sys
import json
from pathlib import Path
from typing import Dict, List, Set, Optional, Tuple
from dataclasses import dataclass, field
from collections import defaultdict
from enum import Enum
class DependencyType(Enum):
"""依赖类型"""
IMPORT = "import"
FROM_IMPORT = "from_import"
RELATIVE_IMPORT = "relative_import"
CONDITIONAL_IMPORT = "conditional_import"
@dataclass
class ImportInfo:
"""导入信息"""
module_path: str
imported_names: List[str]
statement_type: str
line: int
is_conditional: bool = False
@dataclass
class DependencyEdge:
"""依赖边"""
source: str
target: str
dependency_type: DependencyType
imported_names: List[str] = field(default_factory=list)
line: int = 0
@dataclass
class ModuleInfo:
"""模块信息"""
file_path: str
module_name: str
is_package_init: bool
exported_names: Set[str] = field(default_factory=set)
imported_modules: Set[str] = field(default_factory=set)
public_api: Set[str] = field(default_factory=set)
class DependencyAnalyzer:
"""依赖分析器"""
def __init__(self, project_root: str):
self.project_root = Path(project_root).resolve()
self.files: Dict[str, ModuleInfo] = {}
self.edges: List[DependencyEdge] = []
self.stats = {
"total_files": 0,
"total_imports": 0,
"external_dependencies": set(),
"internal_dependencies": set(),
"circular_dependencies": []
}
def analyze(self) -> 'DependencyAnalyzer':
"""执行完整分析"""
py_files = self._discover_python_files()
for py_file in py_files:
self._analyze_file(py_file)
self._build_dependency_graph()
self.stats["circular_dependencies"] = self._find_circular_dependencies()
return self
def _discover_python_files(self) -> List[Path]:
"""发现所有 Python 文件"""
py_files = []
for root, dirs, files in os.walk(self.project_root):
dirs[:] = [d for d in dirs if not d.startswith('.')
and d not in ('__pycache__', 'venv', '.venv', 'node_modules')]
for file in files:
if file.endswith('.py') and not file.startswith('_'):
py_files.append(Path(root) / file)
self.stats["total_files"] = len(py_files)
return py_files
def _analyze_file(self, file_path: Path):
"""分析单个文件"""
relative_path = file_path.relative_to(self.project_root)
module_name = self._path_to_module_name(relative_path)
is_init = file_path.name == '__init__.py'
module_info = ModuleInfo(
file_path=str(file_path),
module_name=module_name,
is_package_init=is_init
)
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
imports = self._extract_imports(content)
for imp in imports:
self.stats["total_imports"] += 1
module_info.imported_modules.add(imp.module_path)
if self._is_internal_module(imp.module_path):
self.stats["internal_dependencies"].add(imp.module_path)
target_path = self._module_to_path(imp.module_path, file_path.parent)
edge = DependencyEdge(
source=str(file_path),
target=target_path,
dependency_type=self._get_dependency_type(imp),
imported_names=imp.imported_names,
line=imp.line
)
self.edges.append(edge)
else:
self.stats["external_dependencies"].add(imp.module_path)
module_info.public_api = self._extract_public_api(content)
module_info.exported_names = module_info.public_api
except Exception as e:
print(f"Error analyzing {file_path}: {e}")
self.files[str(file_path)] = module_info
def _extract_imports(self, content: str) -> List[ImportInfo]:
"""提取文件中的所有导入语句"""
imports = []
lines = content.split('\n')
in_conditional = False
for i, line in enumerate(lines):
original_line = line.strip()
if original_line.startswith('#'):
continue
if original_line.startswith('import '):
module_name = original_line[7:].strip()
if ' as ' in module_name:
module_name = module_name.split(' as ')[0].strip()
modules = [m.strip() for m in module_name.split(',')]
for module in modules:
imports.append(ImportInfo(
module_path=module,
imported_names=[],
statement_type="import",
line=i + 1,
is_conditional=in_conditional
))
elif original_line.startswith('from '):
parts = original_line.split(' import ')
if len(parts) == 2:
from_part = parts[0][5:].strip()
import_part = parts[1].strip()
is_relative = from_part.startswith('.')
if is_relative:
from_part = from_part.lstrip('.')
names = []
if import_part == '*':
names = ['*']
else:
names = self._parse_import_names(import_part)
imports.append(ImportInfo(
module_path=from_part,
imported_names=names,
statement_type="from_import",
line=i + 1,
is_conditional=in_conditional
))
return imports
def _parse_import_names(self, text: str) -> List[str]:
"""解析导入的名称列表"""
names = []
for name in text.split(','):
name = name.strip()
if name and not name.startswith('#'):
if ' as ' in name:
name = name.split(' as ')[0].strip()
if name:
names.append(name)
return names
def _path_to_module_name(self, path: Path) -> str:
"""将文件路径转换为模块名"""
parts = list(path.parts)
if parts[-1] == '__init__.py':
parts = parts[:-1]
else:
parts[-1] = parts[-1][:-3]
return '.'.join(parts)
def _module_to_path(self, module_name: str, current_dir: Path) -> str:
"""将模块名转换为文件路径"""
dots = 0
while module_name.startswith('.'):
dots += 1
module_name = module_name[1:]
if dots > 0:
for _ in range(dots):
current_dir = current_dir.parent
parts = module_name.split('.')
file_path = current_dir / '/'.join(parts)
for ext in ['.py', '/__init__.py']:
full_path = file_path.parent / f"{file_path.name}{ext}"
if full_path.exists():
return str(full_path.relative_to(self.project_root))
return str(file_path) + '.py'
def _is_internal_module(self, module_name: str) -> bool:
"""判断是否为内部模块"""
parts = module_name.lstrip('.').split('.')
if parts and parts[0] in ['api', 'core', 'models', 'services', 'utils', 'lib']:
return True
return False
def _get_dependency_type(self, imp: ImportInfo) -> DependencyType:
"""获取依赖类型"""
if imp.is_conditional:
return DependencyType.CONDITIONAL_IMPORT
elif imp.statement_type == "from_import":
return DependencyType.FROM_IMPORT
elif imp.module_path.startswith('.'):
return DependencyType.RELATIVE_IMPORT
else:
return DependencyType.IMPORT
def _extract_public_api(self, content: str) -> Set[str]:
"""提取模块的公共 API"""
public_api = set()
for line in content.split('\n'):
if '__all__' in line and '=' in line:
if '[' in line:
start = line.find('[')
end = line.rfind(']')
if start != -1 and end != -1:
all_content = line[start+1:end]
names = [n.strip().strip('"\'')
for n in all_content.split(',')]
public_api.update(names)
return public_api
def _find_circular_dependencies(self) -> List[List[str]]:
"""检测循环依赖"""
graph: Dict[str, Set[str]] = defaultdict(set)
for edge in self.edges:
graph[edge.source].add(edge.target)
cycles = []
visited = set()
rec_stack = set()
path = []
def dfs(node: str):
if node in rec_stack:
cycle_start = path.index(node)
cycle = path[cycle_start:] + [node]
cycles.append(cycle)
return
if node in visited:
return
visited.add(node)
rec_stack.add(node)
path.append(node)
for neighbor in graph.get(node, []):
dfs(neighbor)
path.pop()
rec_stack.remove(node)
for node in graph:
dfs(node)
return cycles
def generate_mermaid_graph(self) -> str:
"""生成 Mermaid 格式的依赖图"""
lines = ["flowchart TD"]
module_names: Dict[str, str] = {}
for file_path in self.files:
module_names[file_path] = self.files[file_path].module_name
for file_path, info in self.files.items():
node_id = info.module_name.replace('.', '_').replace('/', '_')
label = info.module_name.split('.')[-1]
lines.append(f' {node_id}["{label}"]')
for edge in self.edges:
if edge.source in module_names and edge.target in module_names:
source_id = module_names[edge.source].replace('.', '_').replace('/', '_')
target_id = module_names[edge.target].replace('.', '_').replace('/', '_')
style = ""
if edge.dependency_type == DependencyType.CONDITIONAL_IMPORT:
style = " -.-> "
elif edge.dependency_type == DependencyType.RELATIVE_IMPORT:
style = " -.-> "
else:
style = " --> "
lines.append(f' {source_id}{style}{target_id}')
return '\n'.join(lines)
def generate_report(self) -> str:
"""生成依赖分析报告"""
lines = [
"=== Dependency Analysis Report ===",
f"Project: {self.project_root}",
f"Total files: {self.stats['total_files']}",
f"Total imports: {self.stats['total_imports']}",
"",
"--- External Dependencies ---",
]
for ext in sorted(self.stats["external_dependencies"]):
lines.append(f" - {ext}")
lines.extend(["", "--- Internal Dependencies ---"])
for internal in sorted(self.stats["internal_dependencies"]):
lines.append(f" - {internal}")
if self.stats["circular_dependencies"]:
lines.extend(["", "--- Circular Dependencies ---"])
for cycle in self.stats["circular_dependencies"]:
lines.append(f" - {' -> '.join(cycle)}")
return '\n'.join(lines)
def analyze_project(project_dir: str) -> DependencyAnalyzer:
"""分析项目依赖"""
analyzer = DependencyAnalyzer(project_dir)
return analyzer.analyze()
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python dependency_analyzer.py <project_dir>")
sys.exit(1)
project_dir = sys.argv[1]
try:
analyzer = analyze_project(project_dir)
print(analyzer.generate_report())
mermaid = analyzer.generate_mermaid_graph()
with open("dependency_graph.mmd", "w") as f:
f.write(mermaid)
print("\nGenerated dependency_graph.mmd")
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
sys.exit(1)5. 可视化:Graph 布局算法与交互
本节核心技术价值
本节为你提供的核心价值是理解图可视化的核心技术——从经典的 force-directed 布局到层次布局,再到实际的交互实现。图可视化是将复杂的代码结构转化为直观理解的关键技术。
5.1 图布局算法概述
图布局算法决定了图中节点的物理位置。不同的算法适用于不同类型的图结构和可视化目标。
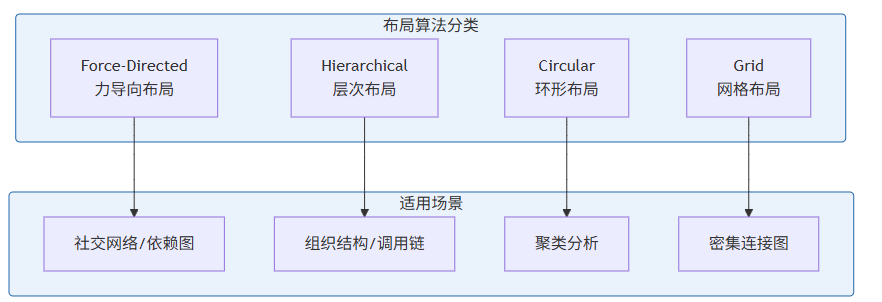
5.2 Force-Directed 布局算法
力导向布局是最常用的图布局算法之一,其核心思想是将图的边视为弹簧力,将节点视为带电粒子。
算法原理:
- 排斥力:所有节点互相排斥,距离越近排斥力越大
- 吸引力:有边连接的节点互相吸引,类似于弹簧力
- 迭代:系统逐步趋向平衡状态
import math
import random
from typing import List, Tuple, Dict
from dataclasses import dataclass
@dataclass
class Vector2D:
"""二维向量"""
x: float
y: float
def __add__(self, other: 'Vector2D') -> 'Vector2D':
return Vector2D(self.x + other.x, self.y + other.y)
def __sub__(self, other: 'Vector2D') -> 'Vector2D':
return Vector2D(self.x - other.x, self.y - other.y)
def __mul__(self, scalar: float) -> 'Vector2D':
return Vector2D(self.x * scalar, self.y * scalar)
def magnitude(self) -> float:
return math.sqrt(self.x * self.x + self.y * self.y)
def normalize(self) -> 'Vector2D':
mag = self.magnitude()
if mag == 0:
return Vector2D(0, 0)
return Vector2D(self.x / mag, self.y / mag)
class ForceDirectedLayout:
"""力导向布局算法"""
def __init__(
self,
repulsion_strength: float = 10000,
attraction_strength: float = 0.1,
damping: float = 0.9,
max_iterations: int = 500,
tolerance: float = 0.1
):
self.repulsion_strength = repulsion_strength
self.attraction_strength = attraction_strength
self.damping = damping
self.max_iterations = max_iterations
self.tolerance = tolerance
self.positions: Dict[str, Vector2D] = {}
self.velocities: Dict[str, Vector2D] = {}
self.graph: Dict[str, List[str]] = {}
self.iterations = 0
self.energy = float('inf')
def set_graph(self, edges: List[Tuple[str, str]]):
"""设置图结构"""
self.graph.clear()
for source, target in edges:
if source not in self.graph:
self.graph[source] = []
if target not in self.graph:
self.graph[target] = []
self.graph[source].append(target)
self.graph[target].append(source)
random.seed(42)
for node in self.graph:
if node not in self.positions:
self.positions[node] = Vector2D(
random.uniform(-500, 500),
random.uniform(-500, 500)
)
self.velocities[node] = Vector2D(0, 0)
def step(self) -> float:
"""执行一步迭代,返回能量变化"""
forces: Dict[str, Vector2D] = {node: Vector2D(0, 0) for node in self.graph}
nodes = list(self.graph.keys())
n = len(nodes)
for i in range(n):
for j in range(i + 1, n):
node_i = nodes[i]
node_j = nodes[j]
delta = self.positions[node_i] - self.positions[node_j]
dist = delta.magnitude()
if dist < 1:
dist = 1
force_magnitude = self.repulsion_strength / (dist * dist)
force = delta.normalize() * force_magnitude
forces[node_i] = forces[node_i] + force
forces[node_j] = forces[node_j] - force
for source, targets in self.graph.items():
for target in targets:
if source >= target:
continue
delta = self.positions[source] - self.positions[target]
dist = delta.magnitude()
if dist < 1:
dist = 1
force_magnitude = self.attraction_strength * dist
force = delta.normalize() * force_magnitude
forces[source] = forces[source] - force
forces[target] = forces[target] + force
old_energy = self.energy
self.energy = 0
for node in self.graph:
velocity = self.velocities[node] + forces[node]
velocity = velocity * self.damping
self.velocities[node] = velocity
self.positions[node] = self.positions[node] + velocity
self.energy += velocity.magnitude()
self.iterations += 1
return abs(old_energy - self.energy)
def layout(self) -> Dict[str, Tuple[float, float]]:
"""执行完整布局"""
for i in range(self.max_iterations):
delta_energy = self.step()
if delta_energy < self.tolerance:
print(f"Converged after {i + 1} iterations")
break
return self.normalize_positions()
def normalize_positions(self) -> Dict[str, Tuple[float, float]]:
"""归一化位置到 [0, 1] 范围"""
if not self.positions:
return {}
min_x = min(v.x for v in self.positions.values())
max_x = max(v.x for v in self.positions.values())
min_y = min(v.y for v in self.positions.values())
max_y = max(v.y for v in self.positions.values())
width = max_x - min_x if max_x != min_x else 1
height = max_y - min_y if max_y != min_y else 1
result = {}
for node, pos in self.positions.items():
result[node] = (
(pos.x - min_x) / width,
(pos.y - min_y) / height
)
return result
def demo():
"""演示 Force-Directed 布局"""
edges = [
("A", "B"), ("A", "C"), ("A", "D"),
("B", "C"), ("C", "D"),
("D", "E"), ("E", "F"),
("F", "G"), ("G", "H"),
("H", "E"), ("F", "D"),
]
layout = ForceDirectedLayout()
layout.set_graph(edges)
positions = layout.layout()
print("Layout results:")
for node, (x, y) in sorted(positions.items()):
print(f" {node}: ({x:.4f}, {y:.4f})")
if __name__ == "__main__":
demo()6. 应用场景:影响分析、架构评估、重构规划
本节核心技术价值
本节为你提供的核心价值是理解 Repository Graph 的实际应用场景——如何利用代码结构理解能力解决真实世界的问题。这些应用展示了 Repository Graph 从理论到实践的价值转化。
6.1 变更影响分析
**变更影响分析(Impact Analysis)**回答的问题是:如果修改这段代码,会影响哪些其他部分?
#!/usr/bin/env python3
"""
impact_analyzer.py - 变更影响分析器
功能:
- 分析修改代码的潜在影响
- 识别所有受影响的文件和函数
- 评估影响范围和风险等级
- 生成影响报告
运行:python impact_analyzer.py <function_name> [project_dir]
"""
import sys
from typing import Dict, List, Set, Optional
from dataclasses import dataclass, field
from enum import Enum
class ImpactLevel(Enum):
"""影响等级"""
DIRECT = "direct"
INDIRECT = "indirect"
DATA = "data"
CONFIG = "config"
LOW = "low"
@dataclass
class ImpactReport:
"""影响报告"""
target_function: str
impact_level: ImpactLevel
affected_functions: List[str] = field(default_factory=list)
affected_files: List[str] = field(default_factory=list)
propagation_paths: List[List[str]] = field(default_factory=list)
risk_score: float = 0.0
risk_factors: List[str] = field(default_factory=list)
class ImpactAnalyzer:
"""变更影响分析器"""
def __init__(self, project_root: str):
self.project_root = project_root
self.call_graph = None
self.symbol_table = None
self.dependency_analyzer = None
self._impact_cache: Dict[str, ImpactReport] = {}
def analyze_function_impact(self, function_name: str,
call_graph_data: Dict) -> ImpactReport:
"""分析函数的影响范围"""
if function_name in self._impact_cache:
return self._impact_cache[function_name]
report = ImpactReport(
target_function=function_name,
impact_level=ImpactLevel.DIRECT
)
# 获取直接调用者
direct_callers = self._get_direct_callers(function_name, call_graph_data)
report.affected_functions.extend(direct_callers)
# 获取间接调用者
all_callers = self._get_all_callers(function_name, call_graph_data)
report.affected_functions = list(set(all_callers) - {function_name})
# 获取受影响的文件
report.affected_files = list(set(
self._get_function_file(caller, call_graph_data)
for caller in report.affected_functions
if self._get_function_file(caller, call_graph_data)
))
# 计算风险分数
report.risk_score = self._calculate_risk_score(report)
# 确定影响等级
if report.risk_score > 0.7:
report.impact_level = ImpactLevel.DIRECT
elif report.risk_score > 0.4:
report.impact_level = ImpactLevel.INDIRECT
elif report.risk_score > 0.2:
report.impact_level = ImpactLevel.DATA
else:
report.impact_level = ImpactLevel.LOW
self._impact_cache[function_name] = report
return report
def _get_direct_callers(self, function_name: str,
call_graph_data: Dict) -> List[str]:
"""获取直接调用者"""
if "nodes" in call_graph_data:
for node_id, node_data in call_graph_data["nodes"].items():
if function_name in node_data.get("callees", []):
return [node_id]
return []
def _get_all_callers(self, function_name: str,
call_graph_data: Dict) -> Set[str]:
"""获取所有调用者(含间接)"""
callers = set()
queue = [function_name]
visited = set()
while queue:
current = queue.pop()
if current in visited:
continue
visited.add(current)
direct = self._get_direct_callers(current, call_graph_data)
for caller in direct:
callers.add(caller)
queue.append(caller)
return callers
def _get_function_file(self, function_name: str,
call_graph_data: Dict) -> Optional[str]:
"""获取函数所在的文件"""
if "nodes" in call_graph_data:
for node_id, node_data in call_graph_data["nodes"].items():
if node_id == function_name:
return node_data.get("file_path")
return None
def _calculate_risk_score(self, report: ImpactReport) -> float:
"""计算风险分数"""
score = 0.0
score += min(len(report.affected_functions) * 0.1, 0.3)
core_modules = {'main', 'core', 'api', 'auth', 'payment'}
for f in report.affected_functions:
if any(core in f.lower() for core in core_modules):
score += 0.1
score += min(len(report.propagation_paths) * 0.05, 0.2)
return min(score, 1.0)
def generate_report_text(self, report: ImpactReport) -> str:
"""生成影响分析报告文本"""
lines = [
"=== Impact Analysis Report ===",
f"Target Function: {report.target_function}",
f"Impact Level: {report.impact_level.value}",
f"Risk Score: {report.risk_score:.2f}",
"",
f"Affected Functions ({len(report.affected_functions)}):"
]
for func in report.affected_functions[:20]:
lines.append(f" - {func}")
if len(report.affected_functions) > 20:
lines.append(f" ... and {len(report.affected_functions) - 20} more")
lines.extend([
"",
f"Affected Files ({len(report.affected_files)}):"
])
for file in report.affected_files[:10]:
lines.append(f" - {file}")
if report.risk_factors:
lines.extend(["", "Risk Factors:"])
for factor in report.risk_factors:
lines.append(f" - {factor}")
return '\n'.join(lines)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python impact_analyzer.py <function_name> [project_dir]")
sys.exit(1)
function_name = sys.argv[1]
project_dir = sys.argv[2] if len(sys.argv) > 2 else "."
# 模拟调用图数据
sample_call_graph = {
"nodes": {
"main": {"callees": ["init", "process"], "file_path": "main.py"},
"init": {"callees": ["load_config"], "file_path": "main.py"},
"process": {"callees": ["validate", "transform"], "file_path": "main.py"},
"validate": {"callees": ["check_input"], "file_path": "utils.py"},
"transform": {"callees": ["save"], "file_path": "utils.py"},
"load_config": {"callees": [], "file_path": "config.py"},
"check_input": {"callees": [], "file_path": "utils.py"},
"save": {"callees": [], "file_path": "db.py"},
}
}
analyzer = ImpactAnalyzer(project_dir)
report = analyzer.analyze_function_impact(function_name, sample_call_graph)
print(analyzer.generate_report_text(report))6.2 架构评估
基于依赖图和调用图,可以对代码架构进行系统性评估:
class ArchitectureEvaluator:
"""架构评估器"""
def __init__(self, call_graph: 'CallGraph', dependency_graph: 'DependencyAnalyzer'):
self.call_graph = call_graph
self.dependency_graph = dependency_graph
def evaluate_stability(self) -> Dict:
"""评估架构稳定性"""
metrics = {
"fan_in": {},
"fan_out": {},
"instability": {},
}
all_nodes = set()
for caller, callee in self.call_graph.edges:
all_nodes.add(caller)
all_nodes.add(callee)
for node in all_nodes:
fan_in = len([e for e in self.call_graph.edges if e[1] == node])
fan_out = len([e for e in self.call_graph.edges if e[0] == node])
metrics["fan_in"][node] = fan_in
metrics["fan_out"][node] = fan_out
total = fan_in + fan_out
if total > 0:
metrics["instability"][node] = fan_out / total
else:
metrics["instability"][node] = 0.5
return metrics
def find_violations(self) -> List[Dict]:
"""检测架构违规"""
violations = []
for cycle in self.call_graph.stats.get("circular_dependencies", []):
violations.append({
"type": "circular_dependency",
"severity": "high",
"elements": cycle,
"message": f"Circular dependency detected: {' -> '.join(cycle)}"
})
instability = self.evaluate_stability()["instability"]
for module, i in instability.items():
if i > 0.8:
violations.append({
"type": "high_instability",
"severity": "medium",
"elements": [module],
"message": f"Module {module} has high instability ({i:.2f})"
})
return violations
def generate_architecture_report(self) -> str:
"""生成架构评估报告"""
metrics = self.evaluate_stability()
violations = self.find_violations()
lines = [
"=== Architecture Evaluation Report ===",
"",
"--- Stability Metrics ---"
]
sorted_instability = sorted(
metrics["instability"].items(),
key=lambda x: -x[1]
)
lines.append("\nTop 10 Most Unstable Modules:")
for module, instability in sorted_instability[:10]:
fan_in = metrics["fan_in"].get(module, 0)
fan_out = metrics["fan_out"].get(module, 0)
lines.append(
f" {module}: I={instability:.2f} "
f"(fan_in={fan_in}, fan_out={fan_out})"
)
lines.extend(["", "--- Architecture Violations ---"])
if not violations:
lines.append(" No violations detected.")
else:
for v in violations:
lines.append(f" [{v['severity'].upper()}] {v['message']}")
return '\n'.join(lines)7. 实践:使用 Tree-sitter 构建多语言 Repository Graph
本节核心技术价值
本节为你提供的核心价值是理解如何使用 Tree-sitter 构建生产级的多语言 Repository Graph。Tree-sitter 是一个高效的增量解析器,能够为多种编程语言生成一致的 AST 结构,是构建跨语言代码理解工具的理想选择。
7.1 Tree-sitter 概述
Tree-sitter 是 GitHub 开发的增量解析系统,具有以下特点:
- 多语言支持:通过语法定义文件(Grammar)支持 30+ 编程语言
- 增量解析:只重新解析修改的部分,高效处理大文件
- 错误恢复:能够从语法错误中恢复,继续解析后续内容
- 统一输出格式:所有语言的 AST 结构一致,便于工具开发
# Tree-sitter 支持的部分语言
SUPPORTED_LANGUAGES = {
"python": "tree-sitter-python",
"javascript": "tree-sitter-javascript",
"typescript": "tree-sitter-typescript",
"rust": "tree-sitter-rust",
"go": "tree-sitter-go",
"java": "tree-sitter-java",
"c": "tree-sitter-c",
"cpp": "tree-sitter-cpp",
"ruby": "tree-sitter-ruby",
"php": "tree-sitter-php",
}7.2 Tree-sitter Python 绑定
#!/usr/bin/env python3
"""
tree_sitter_repo_graph.py - 使用 Tree-sitter 构建多语言 Repository Graph
前置条件:
pip install tree-sitter tree-sitter-python
运行:python tree_sitter_repo_graph.py <project_dir>
"""
import os
import sys
from pathlib import Path
from typing import Dict, List, Set, Optional, Tuple, Any
from dataclasses import dataclass, field
from collections import defaultdict
try:
import tree_sitter
from tree_sitter import Language, Parser
import tree_sitter_python as tspython
except ImportError:
print("Error: tree-sitter not installed.")
print("Run: pip install tree-sitter tree-sitter-python")
sys.exit(1)
@dataclass
class TreeSitterSymbol:
"""Tree-sitter 符号"""
name: str
kind: str
file_path: str
node_type: str
start_point: Tuple[int, int]
end_point: Tuple[int, int]
@property
def line(self) -> int:
return self.start_point[0] + 1
@property
def column(self) -> int:
return self.start_point[1] + 1
class TreeSitterRepoGraphBuilder:
"""使用 Tree-sitter 构建 Repository Graph"""
FUNCTION_TYPES = {
'function_definition',
'class_definition',
'method_definition',
}
CALL_TYPES = {
'call',
}
IMPORT_TYPES = {
'import_statement',
'import_from_statement',
'dotted_name',
}
def __init__(self):
self.parser = Parser()
self.parser.set_language(tspython.language)
self.symbols: Dict[str, List[TreeSitterSymbol]] = defaultdict(list)
self.calls: List[Tuple[str, str, str]] = []
self.imports: List[Tuple[str, str]] = []
self.files: Set[str] = set()
self.stats = {
"files_parsed": 0,
"symbols_found": 0,
"calls_found": 0,
"imports_found": 0,
}
def build_from_directory(self, directory: str) -> 'TreeSitterRepoGraphBuilder':
"""从目录构建 Repository Graph"""
directory = Path(directory)
for root, dirs, files in os.walk(directory):
dirs[:] = [d for d in dirs if not d.startswith('.')
and d not in ('__pycache__', 'node_modules', 'venv')]
for file in files:
if file.endswith('.py'):
file_path = os.path.join(root, file)
self.parse_file(file_path)
return self
def parse_file(self, file_path: str):
"""解析单个文件"""
self.files.add(file_path)
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
except Exception as e:
print(f"Error reading {file_path}: {e}")
return
try:
tree = self.parser.parse(bytes(content, 'utf8'))
self._process_tree(tree.root_node, file_path, content)
self.stats["files_parsed"] += 1
except Exception as e:
print(f"Error parsing {file_path}: {e}")
def _process_tree(self, node: tree_sitter.Node, file_path: str, content: str):
"""处理 AST 节点"""
node_type = node.type
if node_type in self.FUNCTION_TYPES:
symbol = self._extract_symbol(node, file_path)
if symbol:
self.symbols[symbol.name].append(symbol)
self.stats["symbols_found"] += 1
elif node_type in self.CALL_TYPES:
call = self._extract_call(node, file_path)
if call:
self.calls.append(call)
self.stats["calls_found"] += 1
elif 'import' in node_type:
imported = self._extract_import(node, file_path)
if imported:
self.imports.extend(imported)
self.stats["imports_found"] += len(imported)
for child in node.children:
self._process_tree(child, file_path, content)
def _extract_symbol(self, node: tree_sitter.Node, file_path: str) -> Optional[TreeSitterSymbol]:
"""提取符号定义"""
name = None
if node.type == 'function_definition':
name_node = node.child_by_field_name('name')
if name_node:
name = name_node.text.decode('utf8')
kind = 'function'
else:
return None
elif node.type == 'class_definition':
name_node = node.child_by_field_name('name')
if name_node:
name = name_node.text.decode('utf8')
kind = 'class'
else:
return None
elif node.type == 'method_definition':
name_node = node.child_by_field_name('name')
if name_node:
name = name_node.text.decode('utf8')
kind = 'method'
else:
return None
else:
return None
return TreeSitterSymbol(
name=name,
kind=kind,
file_path=file_path,
node_type=node.type,
start_point=node.start_point,
end_point=node.end_point
)
def _extract_call(self, node: tree_sitter.Node, file_path: str) -> Optional[Tuple[str, str, str]]:
"""提取函数调用"""
if node.type != 'call':
return None
function_node = node.child_by_field_name('function')
if not function_node:
return None
callee = self._get_function_name(function_node)
if not callee:
return None
caller = self._find_enclosing_function(node)
return (caller, callee, file_path)
def _get_function_name(self, node: tree_sitter.Node) -> Optional[str]:
"""获取函数名"""
if node.type == 'identifier':
return node.text.decode('utf8')
elif node.type == 'attribute':
obj = node.child_by_field_name('object')
attr = node.child_by_field_name('attribute')
if obj and attr:
obj_name = self._get_function_name(obj)
attr_name = self._get_function_name(attr)
if obj_name and attr_name:
return f"{obj_name}.{attr_name}"
elif node.type == 'member_expression':
object_node = node.child_by_field_name('object')
property_node = node.child_by_field_name('property')
if object_node and property_node:
obj_name = self._get_function_name(object_node)
prop_name = self._get_function_name(property_node)
if obj_name and prop_name:
return f"{obj_name}.{prop_name}"
return None
def _find_enclosing_function(self, node: tree_sitter.Node) -> str:
"""查找包含节点最近的函数定义"""
return "<unknown>"
def _extract_import(self, node: tree_sitter.Node, file_path: str) -> List[Tuple[str, str]]:
"""提取导入语句"""
imports = []
if node.type == 'import_statement':
for child in node.children:
if child.type == 'dotted_name':
name = child.text.decode('utf8')
imports.append((file_path, name))
elif child.type == 'identifier':
name = child.text.decode('utf8')
imports.append((file_path, name))
elif node.type == 'import_from_statement':
module_name = "?"
for child in node.children:
if child.type == 'dotted_name':
module_name = child.text.decode('utf8')
elif child.type == 'identifier':
name = child.text.decode('utf8')
imports.append((file_path, f"{module_name}.{name}"))
return imports
def get_call_graph(self) -> Dict:
"""获取调用图"""
nodes = {}
edges = []
for name, symbol_list in self.symbols.items():
for symbol in symbol_list:
nodes[name] = {
"name": name,
"kind": symbol.kind,
"file": symbol.file_path,
"line": symbol.line,
}
for caller, callee, file in self.calls:
if caller and callee:
edges.append({
"source": caller,
"target": callee,
"file": file
})
return {"nodes": nodes, "edges": edges}
def get_dependency_graph(self) -> Dict:
"""获取依赖图"""
nodes = {}
edges = []
for file in self.files:
nodes[file] = {
"name": file,
"kind": "file",
}
for importer, imported in self.imports:
edges.append({
"source": importer,
"target": imported,
"type": "import"
})
return {"nodes": nodes, "edges": edges}
def generate_report(self) -> str:
"""生成分析报告"""
lines = [
"=== Tree-sitter Repository Graph Analysis ===",
f"Files parsed: {self.stats['files_parsed']}",
f"Symbols found: {self.stats['symbols_found']}",
f"Calls found: {self.stats['calls_found']}",
f"Imports found: {self.stats['imports_found']}",
"",
"--- Top Functions ---"
]
functions = [
(name, symbols[0])
for name, symbols in self.symbols.items()
if symbols and symbols[0].kind == 'function'
]
for name, symbol in sorted(functions, key=lambda x: x[0])[:20]:
lines.append(f" {name} @ {symbol.file_path}:{symbol.line}")
lines.extend(["", "--- Top Classes ---"])
classes = [
(name, symbols[0])
for name, symbols in self.symbols.items()
if symbols and symbols[0].kind == 'class'
]
for name, symbol in sorted(classes, key=lambda x: x[0])[:20]:
lines.append(f" {name} @ {symbol.file_path}:{symbol.line}")
return '\n'.join(lines)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python tree_sitter_repo_graph.py <project_dir>")
sys.exit(1)
project_dir = sys.argv[1]
try:
builder = TreeSitterRepoGraphBuilder()
builder.build_from_directory(project_dir)
print(builder.generate_report())
call_graph = builder.get_call_graph()
print(f"\nCall graph: {len(call_graph['nodes'])} nodes, {len(call_graph['edges'])} edges")
dep_graph = builder.get_dependency_graph()
print(f"Dependency graph: {len(dep_graph['nodes'])} nodes, {len(dep_graph['edges'])} edges")
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
sys.exit(1)8. 总结与展望
8.1 核心概念回顾
本文系统性地介绍了 Repository Graph 的构建与应用,涵盖了从底层解析到上层应用的完整技术栈:
- AST 提取与符号表构建:将源代码转换为结构化的语义表示
- 调用图生成:静态分析和动态追踪揭示程序的控制流
- 依赖图分析:文件级和模块级的 import/export 关系
- 图可视化:force-directed 和层次布局算法
- 应用场景:影响分析、架构评估、重构规划
- 实践案例:Tree-sitter 多语言 Repository Graph 构建
8.2 技术演进趋势
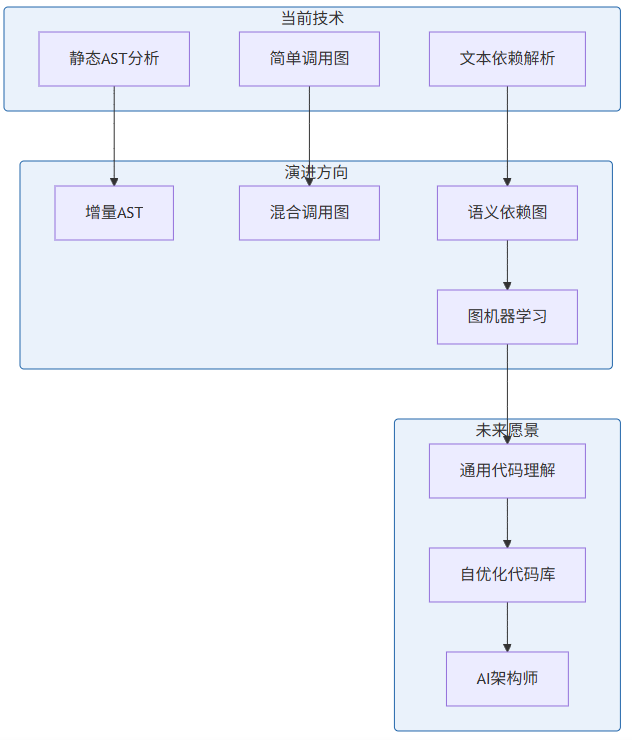
8.3 关键结论
- Repository Graph 是 AI IDE 实现代码理解的基石:它将碎片化的代码信息整合为统一的图结构,为上层 AI 应用提供一致的查询接口。
- 静态分析与动态追踪各有优劣:静态分析覆盖全面但可能有误报,动态追踪准确但可能遗漏。生产系统通常需要结合两者。
- Tree-sitter 为多语言支持提供了可行路径:通过统一的 AST 结构,可以构建跨语言的代码理解工具。
- Repository Graph 的应用远不止代码补全:影响分析、架构评估、重构规划等高阶功能都依赖它。
附录 A:符号表核心数据结构的完整定义
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Set, Any
from enum import Enum
from datetime import datetime
class SymbolKind(Enum):
"""符号种类完整枚举"""
MODULE = "module"
PACKAGE = "package"
CLASS = "class"
INTERFACE = "interface"
FUNCTION = "function"
METHOD = "method"
STATIC_METHOD = "static_method"
CLASS_METHOD = "class_method"
CONSTRUCTOR = "constructor"
PROPERTY = "property"
FIELD = "field"
VARIABLE = "variable"
CONSTANT = "constant"
PARAMETER = "parameter"
TYPE_PARAMETER = "type_parameter"
TYPE_ALIAS = "type_alias"
ENUM = "enum"
ENUM_MEMBER = "enum_member"
IMPORT = "import"
EXPORT = "export"
GENERIC = "generic"
ANNOTATION = "annotation"
@dataclass
class SymbolLocation:
"""符号位置"""
file_path: str
line: int
column: int
end_line: int
end_column: int
def __str__(self):
return f"{self.file_path}:{self.line}:{self.column}"
@dataclass
class SymbolType:
"""符号类型信息"""
name: str
module: Optional[str] = None
is_generic: bool = False
type_params: List['SymbolType'] = field(default_factory=list)
is_array: bool = False
is_optional: bool = False
is_promise: bool = False
@dataclass
class Symbol:
"""符号完整定义"""
name: str
kind: SymbolKind
location: SymbolLocation
declared_type: Optional[SymbolType] = None
inferred_type: Optional[SymbolType] = None
is_exported: bool = False
is_private: bool = False
is_protected: bool = False
is_internal: bool = False
is_static: bool = False
is_async: bool = False
is_abstract: bool = False
is_virtual: bool = False
is_override: bool = False
defines: List['Symbol'] = field(default_factory=list)
references: List[SymbolLocation] = field(default_factory=list)
annotations: List[str] = field(default_factory=list)
scope_id: str = ""
documentation: Optional[str] = None
deprecation_message: Optional[str] = None
since_version: Optional[str] = None
created_at: datetime = field(default_factory=datetime.now)附录 B:调用图数据结构的完整定义
from dataclasses import dataclass, field
from typing import Dict, List, Set, Optional, Tuple
from enum import Enum
import json
class CallType(Enum):
"""调用类型"""
DIRECT = "direct"
INDIRECT = "indirect"
VIRTUAL = "virtual"
CALLBACK = "callback"
COROUTINE = "coroutine"
CONSTRUCTOR = "constructor"
DESTRUCTOR = "destructor"
class CallGraphEdgeType(Enum):
"""调用图边类型"""
SYNCHRONOUS = "synchronous"
ASYNCHRONOUS = "asynchronous"
CALLBACK = "callback"
EVENT = "event"
CONDITIONAL = "conditional"
POLYMORPHIC = "polymorphic"
@dataclass
class CallSite:
"""调用点信息"""
caller: str
callee: str
call_type: CallType
location: Tuple[int, int]
file_path: str
is_recursive: bool = False
is_tail_call: bool = False
is_tail_recursive: bool = False
call_chain_depth: int = 0
@dataclass
class CallGraphNode:
"""调用图节点"""
function_name: str
fully_qualified_name: str
file_path: str
line: int
is_method: bool = False
is_static: bool = False
is_async: bool = False
is_generator: bool = False
cyclomatic_complexity: int = 1
cognitive_complexity: int = 0
source_lines: int = 0
direct_callers: Set[str] = field(default_factory=set)
direct_callees: Set[str] = field(default_factory=set)
call_sites: List[CallSite] = field(default_factory=list)
call_count: int = 0
unique_caller_count: int = 0
unique_callee_count: int = 0
class CallGraph:
"""完整调用图"""
def __init__(self):
self.nodes: Dict[str, CallGraphNode] = {}
self.edges: Set[Tuple[str, str]] = set()
self.edge_attributes: Dict[Tuple[str, str], Dict] = {}
self.stats = {
"total_nodes": 0,
"total_edges": 0,
"max_depth": 0,
"avg_complexity": 0.0,
"leaf_functions": [],
"hub_functions": [],
"recursive_functions": [],
}
def add_node(self, node: CallGraphNode):
"""添加节点"""
self.nodes[node.function_name] = node
self.stats["total_nodes"] += 1
def add_edge(self, source: str, target: str, attributes: Optional[Dict] = None):
"""添加边"""
self.edges.add((source, target))
if attributes:
self.edge_attributes[(source, target)] = attributes
if source in self.nodes:
self.nodes[source].direct_callees.add(target)
if target in self.nodes:
self.nodes[target].direct_callers.add(source)
self.stats["total_edges"] += 1
def get_callers(self, function: str, recursive: bool = True) -> Set[str]:
"""获取调用者"""
if not recursive:
return self.nodes[function].direct_callers if function in self.nodes else set()
result = set()
visited = set()
queue = list(self.nodes[function].direct_callers) if function in self.nodes else []
while queue:
caller = queue.pop()
if caller in visited:
continue
visited.add(caller)
result.add(caller)
if caller in self.nodes:
queue.extend(self.nodes[caller].direct_callers)
return result
def get_callees(self, function: str, recursive: bool = True) -> Set[str]:
"""获取被调用者"""
if not recursive:
return self.nodes[function].direct_callees if function in self.nodes else set()
result = set()
visited = set()
queue = list(self.nodes[function].direct_callees) if function in self.nodes else []
while queue:
callee = queue.pop()
if callee in visited:
continue
visited.add(callee)
result.add(callee)
if callee in self.nodes:
queue.extend(self.nodes[callee].direct_callees)
return result
def find_hot_paths(self, max_length: int = 10) -> List[List[str]]:
"""查找热路径"""
path_counts: Dict[Tuple[str, ...], int] = defaultdict(int)
for source, target in self.edges:
path_counts[(source, target)] += 1
return [
(list(path), count)
for path, count in sorted(path_counts.items(), key=lambda x: -x[1])[:20]
]
def to_json(self) -> str:
"""导出为 JSON"""
return json.dumps({
"nodes": {
name: {
"function_name": node.function_name,
"fqdn": node.fully_qualified_name,
"file": node.file_path,
"line": node.line,
"is_method": node.is_method,
"direct_callers": list(node.direct_callers),
"direct_callees": list(node.direct_callees),
"complexity": node.cyclomatic_complexity,
}
for name, node in self.nodes.items()
},
"edges": [
{"source": s, "target": t}
for s, t in self.edges
],
"stats": self.stats
}, indent=2)附录 C:依赖图数据结构的完整定义
from dataclasses import dataclass, field
from typing import Dict, List, Set, Optional, Any
from enum import Enum
import json
class DependencyKind(Enum):
"""依赖种类"""
DIRECT = "direct"
TRANSITIVE = "transitive"
CIRCULAR = "circular"
SELF = "self"
class DependencyStrength(Enum):
"""依赖强度"""
STRONG = "strong"
WEAK = "weak"
TEST = "test"
DEV = "dev"
OPTIONAL = "optional"
@dataclass
class DependencyEdge:
"""依赖边完整定义"""
source_module: str
target_module: str
kind: DependencyKind = DependencyKind.DIRECT
strength: DependencyStrength = DependencyStrength.STRONG
imported_symbols: List[str] = field(default_factory=list)
conditional: bool = False
version_constraint: Optional[str] = None
source_file: Optional[str] = None
line: int = 0
@dataclass
class ModuleNode:
"""模块节点"""
name: str
path: str
language: str
is_package: bool = False
is_namespace: bool = False
is_entry_point: bool = False
exported_symbols: Set[str] = field(default_factory=set)
public_api: Set[str] = field(default_factory=set)
dependencies: Set[str] = field(default_factory=set)
dependents: Set[str] = field(default_factory=set)
fan_in: int = 0
fan_out: int = 0
instability: float = 0.0
cyclomatic_complexity: float = 0.0
lines_of_code: int = 0
comment_ratio: float = 0.0
class DependencyGraph:
"""完整依赖图"""
def __init__(self):
self.modules: Dict[str, ModuleNode] = {}
self.dependencies: List[DependencyEdge] = []
self.stats = {
"total_modules": 0,
"total_dependencies": 0,
"circular_dependencies": [],
"external_dependencies": set(),
"orphaned_modules": [],
"core_modules": [],
}
def add_module(self, module: ModuleNode):
"""添加模块"""
self.modules[module.name] = module
self.stats["total_modules"] += 1
def add_dependency(self, edge: DependencyEdge):
"""添加依赖"""
self.dependencies.append(edge)
self.stats["total_dependencies"] += 1
if edge.source_module in self.modules:
self.modules[edge.source_module].dependents.add(edge.target_module)
self.modules[edge.source_module].fan_out += 1
if edge.target_module in self.modules:
self.modules[edge.target_module].dependencies.add(edge.source_module)
self.modules[edge.target_module].fan_in += 1
def calculate_metrics(self):
"""计算依赖指标"""
for module in self.modules.values():
total = module.fan_in + module.fan_out
if total > 0:
module.instability = module.fan_out / total
else:
module.instability = 0.5
sorted_by_fan_in = sorted(
self.modules.items(),
key=lambda x: -x[1].fan_in
)
self.stats["core_modules"] = [
name for name, _ in sorted_by_fan_in[:10]
]
self.stats["orphaned_modules"] = [
name for name, m in self.modules.items()
if m.fan_in == 0 and m.fan_out == 0
]
def find_circular_dependencies(self) -> List[List[str]]:
"""检测循环依赖"""
cycles = []
visited = set()
rec_stack = set()
path = []
def dfs(module: str):
if module in rec_stack:
cycle_start = path.index(module)
cycle = path[cycle_start:] + [module]
cycles.append(cycle)
return
if module in visited:
return
visited.add(module)
rec_stack.add(module)
path.append(module)
if module in self.modules:
for dep in self.modules[module].dependents:
dfs(dep)
path.pop()
rec_stack.remove(module)
for module in self.modules:
dfs(module)
return cycles
def to_json(self) -> str:
"""导出为 JSON"""
return json.dumps({
"modules": {
name: {
"name": m.name,
"path": m.path,
"language": m.language,
"is_package": m.is_package,
"fan_in": m.fan_in,
"fan_out": m.fan_out,
"instability": m.instability,
"public_api": list(m.public_api),
}
for name, m in self.modules.items()
},
"dependencies": [
{
"source": e.source_module,
"target": e.target_module,
"kind": e.kind.value,
"strength": e.strength.value,
"imported_symbols": e.imported_symbols,
}
for e in self.dependencies
],
"stats": {
"total_modules": self.stats["total_modules"],
"total_dependencies": self.stats["total_dependencies"],
"circular_count": len(self.stats["circular_dependencies"]),
"external_count": len(self.stats["external_dependencies"]),
"orphaned_count": len(self.stats["orphaned_modules"]),
}
}, indent=2)
def generate_mermaid(self) -> str:
"""生成 Mermaid 格式"""
lines = ["flowchart TD"]
for name, module in self.modules.items():
lines.append(f' {name.replace("/", "_")}["{module.name}"]')
for dep in self.dependencies:
source_id = dep.source_module.replace("/", "_")
target_id = dep.target_module.replace("/", "_")
style = ""
if dep.kind == DependencyKind.CIRCULAR:
style = " -.-> "
elif dep.strength == DependencyStrength.WEAK:
style = " -.-> "
else:
style = " --> "
lines.append(f' {source_id}{style}{target_id}')
return '\n'.join(lines)附录 D:Tree-sitter 多语言支持扩展
#!/usr/bin/env python3
"""
multi_lang_repo_graph.py - 多语言 Repository Graph 构建器
支持:Python, JavaScript, TypeScript, Go, Rust
运行:python multi_lang_repo_graph.py <project_dir>
"""
import os
import sys
from pathlib import Path
from typing import Dict, List, Set, Optional
from dataclasses import dataclass, field
from collections import defaultdict
try:
from tree_sitter import Parser
import tree_sitter_python
import tree_sitter_javascript
import tree_sitter_typescript
except ImportError:
print("Error: Required tree-sitter packages not installed.")
print("Run: pip install tree-sitter tree-sitter-python tree-sitter-javascript tree-sitter-typescript")
sys.exit(1)
LANGUAGE_EXTENSIONS = {
'.py': ('python', tree_sitter_python.language),
'.js': ('javascript', tree_sitter_javascript.language),
'.ts': ('typescript', tree_sitter_typescript.language),
'.jsx': ('javascript', tree_sitter_javascript.language),
'.tsx': ('typescript', tree_sitter_typescript.language),
}
@dataclass
class CrossLangSymbol:
"""跨语言符号"""
name: str
language: str
file_path: str
line: int
kind: str
@dataclass
class CrossLangCall:
"""跨语言调用"""
caller: str
callee: str
file_path: str
language: str
class MultiLanguageRepoGraph:
"""多语言 Repository Graph"""
def __init__(self):
self.parsers: Dict[str, Parser] = {}
self.symbols: Dict[str, List[CrossLangSymbol]] = defaultdict(list)
self.calls: List[CrossLangCall] = []
self.files: Set[str] = set()
self.stats = {
"files_parsed": 0,
"symbols_found": 0,
"calls_found": 0,
}
def initialize_parsers(self):
"""初始化所有语言的解析器"""
for ext, (lang_name, lang) in LANGUAGE_EXTENSIONS.items():
if lang_name not in self.parsers:
parser = Parser()
parser.set_language(lang)
self.parsers[lang_name] = parser
def build_from_directory(self, directory: str) -> 'MultiLanguageRepoGraph':
"""从目录构建多语言 Repository Graph"""
self.initialize_parsers()
directory = Path(directory)
for root, dirs, files in os.walk(directory):
dirs[:] = [d for d in dirs if not d.startswith('.')
and d not in ('__pycache__', 'node_modules', 'venv')]
for file in files:
ext = Path(file).suffix
if ext in LANGUAGE_EXTENSIONS:
file_path = os.path.join(root, file)
self.parse_file(file_path)
return self
def parse_file(self, file_path: str):
"""解析单个文件"""
self.files.add(file_path)
ext = Path(file_path).suffix
lang_name, parser = LANGUAGE_EXTENSIONS[ext]
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
except Exception as e:
print(f"Error reading {file_path}: {e}")
return
try:
tree = parser.parse(bytes(content, 'utf8'))
self._process_tree(tree.root_node, file_path, lang_name, content)
self.stats["files_parsed"] += 1
except Exception as e:
print(f"Error parsing {file_path}: {e}")
def _process_tree(self, node, file_path: str, language: str, content: str):
"""处理 AST 节点"""
node_type = node.type
if language == 'python':
if node_type in ('function_definition', 'class_definition', 'method_definition'):
symbol = self._extract_python_symbol(node, file_path, language)
if symbol:
self.symbols[symbol.name].append(symbol)
self.stats["symbols_found"] += 1
elif node_type == 'call':
call = self._extract_python_call(node, file_path, language)
if call:
self.calls.append(call)
self.stats["calls_found"] += 1
elif language in ('javascript', 'typescript'):
if node_type in ('function_declaration', 'class_declaration', 'method_definition'):
symbol = self._extract_js_symbol(node, file_path, language)
if symbol:
self.symbols[symbol.name].append(symbol)
self.stats["symbols_found"] += 1
elif node_type == 'call_expression':
call = self._extract_js_call(node, file_path, language)
if call:
self.calls.append(call)
self.stats["calls_found"] += 1
for child in getattr(node, 'children', []):
self._process_tree(child, file_path, language, content)
def _extract_python_symbol(self, node, file_path: str, language: str) -> Optional[CrossLangSymbol]:
"""提取 Python 符号"""
name_node = None
if node.type == 'function_definition':
for child in getattr(node, 'children', []):
if child.type == 'identifier':
name_node = child
kind = 'function'
break
elif node.type == 'class_definition':
for child in getattr(node, 'children', []):
if child.type == 'identifier':
name_node = child
kind = 'class'
break
elif node.type == 'method_definition':
for child in getattr(node, 'children', []):
if child.type == 'identifier':
name_node = child
kind = 'method'
break
if not name_node:
return None
return CrossLangSymbol(
name=name_node.text.decode('utf8'),
language=language,
file_path=file_path,
line=name_node.start_point[0] + 1 if hasattr(name_node, 'start_point') else 0,
kind=kind
)
def _extract_python_call(self, node, file_path: str, language: str) -> Optional[CrossLangCall]:
"""提取 Python 函数调用"""
return CrossLangCall(
caller="<unknown>",
callee="<unknown>",
file_path=file_path,
language=language
)
def _extract_js_symbol(self, node, file_path: str, language: str) -> Optional[CrossLangSymbol]:
"""提取 JavaScript/TypeScript 符号"""
name_node = None
if node.type == 'function_declaration':
for child in getattr(node, 'children', []):
if child.type == 'identifier':
name_node = child
kind = 'function'
break
elif node.type == 'class_declaration':
for child in getattr(node, 'children', []):
if child.type == 'identifier':
name_node = child
kind = 'class'
break
elif node.type == 'method_definition':
for child in getattr(node, 'children', []):
if child.type == 'property_identifier':
name_node = child
kind = 'method'
break
if not name_node:
return None
return CrossLangSymbol(
name=name_node.text.decode('utf8'),
language=language,
file_path=file_path,
line=name_node.start_point[0] + 1 if hasattr(name_node, 'start_point') else 0,
kind=kind
)
def _extract_js_call(self, node, file_path: str, language: str) -> Optional[CrossLangCall]:
"""提取 JavaScript/TypeScript 函数调用"""
return CrossLangCall(
caller="<unknown>",
callee="<unknown>",
file_path=file_path,
language=language
)
def get_cross_language_symbols(self, symbol_name: str) -> List[CrossLangSymbol]:
"""获取跨语言符号"""
return self.symbols.get(symbol_name, [])
def generate_report(self) -> str:
"""生成分析报告"""
lines = [
"=== Multi-Language Repository Graph Analysis ===",
f"Files parsed: {self.stats['files_parsed']}",
f"Symbols found: {self.stats['symbols_found']}",
f"Calls found: {self.stats['calls_found']}",
"",
"--- Languages detected ---",
]
languages = set(s.language for symbols in self.symbols.values() for s in symbols)
for lang in sorted(languages):
count = len([s for symbols in self.symbols.values() for s in symbols if s.language == lang])
lines.append(f" {lang}: {count} symbols")
return '\n'.join(lines)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python multi_lang_repo_graph.py <project_dir>")
sys.exit(1)
project_dir = sys.argv[1]
try:
builder = MultiLanguageRepoGraph()
builder.build_from_directory(project_dir)
print(builder.generate_report())
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
sys.exit(1)参考链接:
- 主要来源:Tree-sitter GitHub Repository - GitHub官方的增量解析系统,提供了30+语言的语法定义
- 主要来源:Python AST Documentation - Python官方AST模块文档
- 主要来源:LSP Specification - Microsoft - 语言服务器协议规范,定义了代码理解的服务接口
- 辅助来源:CodeGraph Analysis Framework - GitHub的代码分析框架,提供了生产级的图分析实现
- 辅助来源:rust-analyzer - 开源LSP服务器最佳实践,展示了如何构建高质量的符号表和调用图
附录(Appendix):
- 附录A:符号表核心数据结构的完整定义
- 附录B:调用图数据结构的完整定义
- 附录C:依赖图数据结构的完整定义
- 附录D:Tree-sitter多语言支持扩展
关键词: Repository Graph, 代码结构理解, AST, 符号表, 调用图, 依赖图, Tree-sitter, 静态分析, 动态追踪, 变更影响分析, 架构评估, 重构规划, AI IDE, 代码理解, 图可视化, 力导向布局, 多语言支持

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-05-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号