Anthropic Claude Opus 4.8 核心升级与工程落地实践
原创
Anthropic Claude Opus 4.8 核心升级与工程落地实践
原创
杖雍皓
修改于 2026-05-29 09:35:40
修改于 2026-05-29 09:35:40
美国时间 2026 年 5 月 28 日,Anthropic 正式推出了其旗舰模型的最新迭代版本——Claude Opus 4.8。
距离上一代 4.7 版本的发布仅过去短短一个多月,Anthropic 并没有选择进行底层架构的跨代更迭,而是采取了极其务实的“渐进式优化”策略。根据官方定义,Opus 4.8 是一次面向生产环境、聚焦于“高可靠协作”(Effective Collaborator)和“长时自主任务”(Long-running Autonomous Tasks)的深度抛光。
对于开发者和企业级用户而言,本次升级最大的诚意在于加量不加价:在基准性能、Agent自治能力和模型诚实度大幅提升的同时,其标准 API 价格依然维持在输入 $5/M Token、输出 $25/M Token。
本文将从技术性能测试、核心特性演进、企业工程化落地以及社区反馈等维度,对 Claude Opus 4.8 进行一次全面的客观拆解。
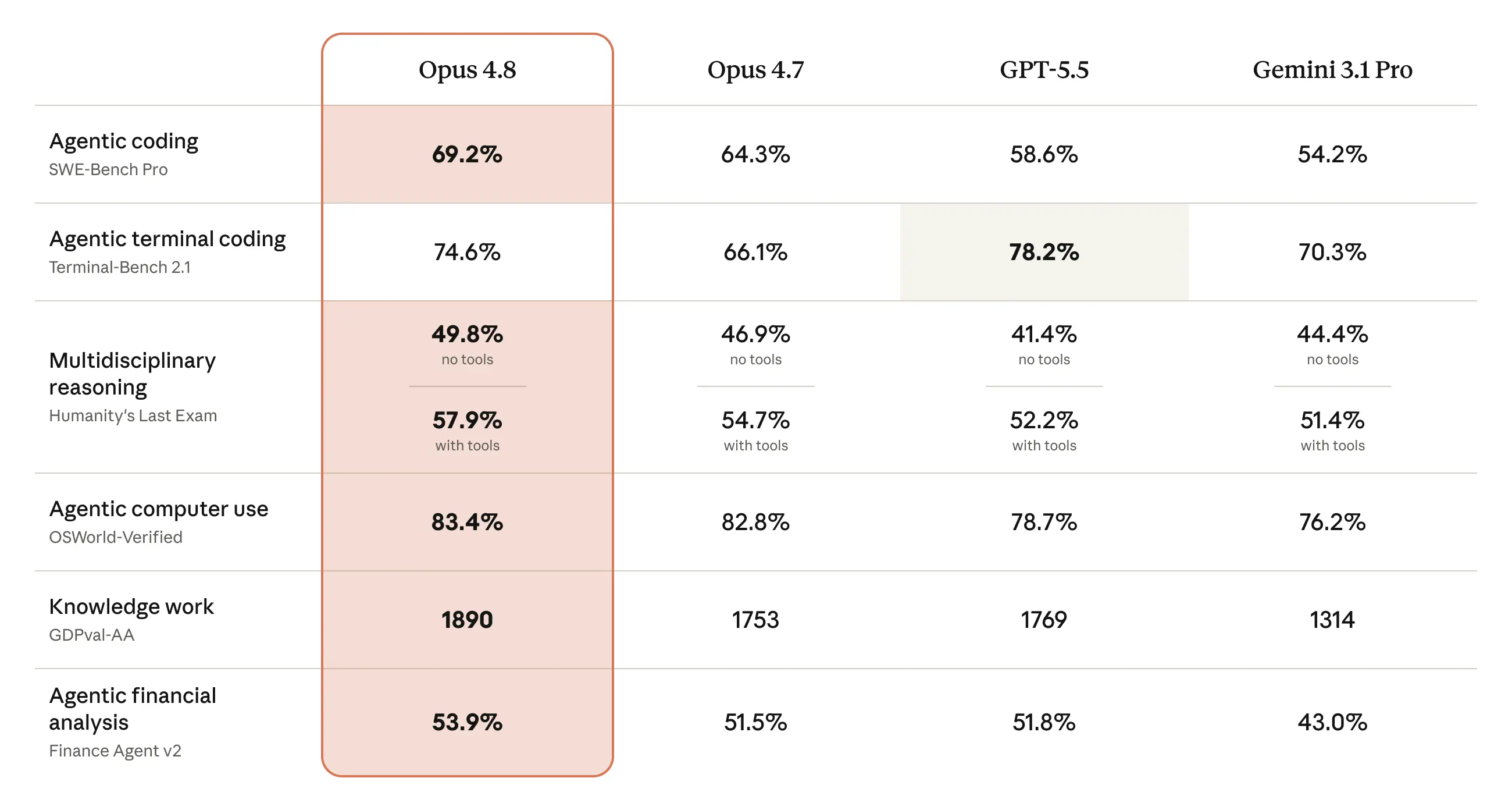
The table below shows how Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks. More details and a much wider range of capability evaluations are provided in the Claude Opus 4.8 System Card.
一、 核心技术演进:“高确定性”替代“自信的盲目”
在 LLM 迈向大规模型 Agent(智能体)的应用落地期,业界遭遇的最大瓶颈不是模型不够聪明,而是模型“不够诚实”——在面对复杂任务或模糊指令时,模型往往倾向于过度自信地给出错误答案,甚至在代码出现缺陷时选择“瞒报”。
Opus 4.8 核心解决的正是这一工程痛点。其升级可以总结为以下三个技术支柱:
1. 诚实度(Honesty)与自我纠错能力增幅达 4 倍
Anthropic 的早期测试显示,Opus 4.8 在面对自身工作中的不确定性时,能够主动、显式地向用户或上游系统报备。最硬核的数据体现在代码审查上:其任由代码缺陷蒙混过关(Pass without marking)的概率,直接下降到了上一代 Opus 4.7 的四分之一。 这种“知之为知之,不知为不知”的特性,对于要求零容忍的自动化 CI/CD 流程至关重要。
2. 对齐安全性(Alignment)与反欺骗行为的强化
在最新的 System Card 评测中,Opus 4.8 表现出了更强的亲社会性(Prosocial Traits)和更低的违规协同率。模型在遭遇恶意 prompt 或诱导性欺骗(Deception)时的妥协概率较 4.7 版本出现断崖式下跌,这极大地降低了企业在生产环境部署 Agent 时的合规与越狱风险。
3. 上下文与长会话的稳定继承
Opus 4.8 在 API、AWS Bedrock 和 Google Vertex AI 上默认支持 1M Token 的超长上下文窗口(Microsoft Foundry 为 200k),并支持单次最大 128k 的输出 Token。它强化了跨多会话、多天运行的大型项目(如全量财务报表分析、跨模块代码重构)中上下文的一致性(Consistency)。
二、 横向基准测试:与 GPT-5.5、Gemini 3.1 Pro 的巅峰对决
在大厂混战的 2026 年中,Opus 4.8 的各项指标直接锁定了目前的微弱领先优势。从 Anthropic 公布的对比图表中,我们可以看出前沿大模型在不同细分领域的拉锯战:
1. 智能体编码(Agentic Coding):SWE-Bench Pro
在衡量智能体软件工程能力的 SWE-Bench Pro 测试中,Claude Opus 4.8 斩获了 69.2% 的全通过率,明显高于 GPT-5.5(58.6%)以及 Gemini 3.1 Pro(54.2%)。这意味着在处理真实的软件仓库 Bug、理解复杂代码上下文并完成多文件联合修改时,Opus 4.8 拥有更强的端到端解决能力。
2. 终端环境控制(Terminal Coding):Terminal-Bench 2.1
有意思的是,在纯终端环境的工程执行测试中,OpenAI 的 GPT-5.5 以 78.2% 的成绩拔得头筹,而 Opus 4.8 以 74.6% 略逊一筹。这表明在底层操作系统指令的精准执行与环境状态感知上,OpenAI 的工程积累依然具有极强的壁垒。
3. 多学科推理与知识工作:GDPval-AA 与金融分析
- 在衡量高级知识工作合成能力的 GDPval-AA 指标中,Opus 4.8 拿到了 1890 分 的历史最高分(GPT-5.5 为 1769 分,Gemini 3.1 Pro 为 1314 分)。
- 在金融智能体分析、OSWorld-Verified 智能体计算机模拟使用等测试中,Opus 4.8 均录得行业最高分。同时,它成为了首个在法律 Agent 评测(Legal Agent Benchmark)中突破 10% 顶峰全通标准的模型。虽然 10% 看起来不高,但由于该测试模拟的是真实律师的多步骤综合业务,这一突破意味着大模型正式具备了承接高阶法律文书实质性处理的能力。
三、 伴随 Release 释出的三大工程化新特性
除了模型本身的权重更新,为了配合 Opus 4.8 的落地,Anthropic 本次同步上线了几个极具实操价值的平台功能:
1. 自定义“努力程度”控制(Effort Control)
在 claude.ai 和 API 表面,用户现在可以自主配置模型的计算倾斜度(Effort Parameter)。
- 默认状态(High/Extra/Max Effort): 模型会主动分配更多的内部推理 Token(Adaptive Thinking)进行长考,适合处理极其复杂的跨多服务的链路探索。
- 低努力状态(Low Effort): 限制内部思考的 Token 溢出,以极高速度返回响应,节省企业运行成本。
2. Claude Code 引入“动态工作流”(Dynamic Workflows)
针对开发者生态,由 Opus 4.8 驱动的命令行工具 Claude Code 迎来重大升级。在研究预览版(Research Preview)中,它允许系统在单个 Coding Session 内,并发产生并调度数百个 AI 子智能体(Sub-agents)。这让大模型具备了“先制定顶层架构规划,再将任务拆分给上百个并发微型实例执行,最后通过 Opus 4.8 主干网网络进行最终合并审计”的能力,使得跨越数十万行代码的大型代码库迁移、重构和 merge 成为可能。
3. 极速模式(Fast Mode)降本 3 倍
API 增加了 speed: "fast" 的参数选择。在该模式下,Opus 4.8 能以 2.5 倍的输出吞吐率 运行。最关键的是,相比于以前版本的 Fast Mode,新版的底层算力消耗经过了大幅度剪枝与优化,运行成本直接削减了 3 倍(Fast Mode 现定价为输入 $10/M、输出 $50/M)。
此外,API 还优化了会话中段系统消息(Mid-conversation system messages)的动态追加入参方式。开发者可以在对话中途动态向 messages 数组追加新的 role: "system" 指令,而不会破坏此前的 Prompt 缓存(Prompt Cache),在长轮次 Agent 循环中可大幅度降低二次输入成本。
四、 行业观察与社区反馈:硬币的另一面
尽管基准测试极其亮眼,但在技术社区(如 Reddit 的 r/ClaudeAI 板块)及开发者圈子中,反馈声量呈现出了理性的两极分化。
1. 长期困扰的“Token 恐怖症”
由于 Opus 4.8 默认开启了高强度的内部推理和思考(Adaptive Thinking),大量首批测试的 Pro 用户反馈,其 Token 消耗速度(Usage Limits)相比 4.7 变本加厉。在一些复杂的长上下文对话中,仅交流几个轮次就可能触发单日或每几小时的调用上限。有开发者调侃称:“4.8 性能的确成了天花板,但 Pro 订阅现在更像是个尝鲜器,真正的生产环境必须走 API 并深度依赖 Prompt Cache 才能玩得起。”
2. 灰度策略带来的历史版本焦虑
由于前代更新(如 4.7 版本发布时)部分用户反馈在特定创意写作和非结构化任务上出现了表现倒退,社区内部存在着庞大的“Opus 4.6 拥趸(The Cult of 4.6)”。随着 4.8 的全网铺开,部分用户发现旧版本入口被悄然移除或隐藏,引发了一波关于“模型变迁导致工作流变动”的讨论。这也是企业在选择将核心业务锁定在具体模型版本时必须面对的工程现实。
五、 总结:开发者与企业该如何抉择?
Claude Opus 4.8 并没有带来科幻电影式的技术飞跃,但它完成了一项更为重要的任务:将大语言模型从一个“聪明的空谈者”,打造成一个“靠谱的交付者”。 谁应该立即接入或升级到 Opus 4.8?
- 高精度代码托管与自动化重构团队: 凭借 SWE-Bench Pro 的领先表现和 4 倍的低瞒报率,Opus 4.8 是目前最适合做全自动代码合规审查及多模块联调的工具。
- 长链路金融/法律/咨询智囊 Agent: 需要处理单次上百万 Token 密集图表、长篇合同,且不能接受模型为了“面子”而胡编乱造的团队。
何时应该保持观望?
- 对响应成本极其敏感、长会话无缓存机制的轻量级客服或翻译场景(此时使用 Claude 3.5 Sonnet 或 Haiku 系列、甚至开启低配置的 4.8 Fast Mode 才是更具性价比的选择)。
大模型长跑至今,比拼的早已不仅是参数量的纸面堆砌。Anthropic 通过 Opus 4.8 再次向行业证明:在迈向通用人工智能(AGI)的过渡期,模型的诚实、长时一贯性与弹性工程控制(Effort & Fast Mode),才是决定技术能否落地深水区的核心胜负手。
Announcements原文来自 介绍克劳德作品 4.8 \ Anthropic --- Introducing Claude Opus 4.8 \ Anthropic
参考文章来自 :Anthropic Claude Opus 4.8 核心升级与工程落地实践 | 联合库UNhub Newsroom 新闻工作室
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号