Qwen3.7-Max 杀进 Code Arena 全球第 4:1541 分紧咬 Claude,中国大模型在编码赛道加速追赶

Qwen3.7-Max 杀进 Code Arena 全球第 4:1541 分紧咬 Claude,中国大模型在编码赛道加速追赶

做棵大树
发布于 2026-05-29 10:45:52
发布于 2026-05-29 10:45:52
“我是大树,一个差点开始放弃折腾的AGI学习与实践者。 最近在探索和从事的事儿:
- 企业出海与AI自动化转型咨询,AGI创作与出海
- 重新拾起自媒体平台,继续倒逼自己动脑和记录日常的所思所感,不止技术
欢迎大家关注微信公众号 做棵大树,有想要长期联系的朋友也可以通过公众号菜单栏找到我~
”
兄弟们,Code Arena 榜单又更新了,昨天看到消息的时候 Qwen3.7还是第2,今天就编程第4了。不过可以看到基本上也是只落后于 anthropic 的顶端模型了。
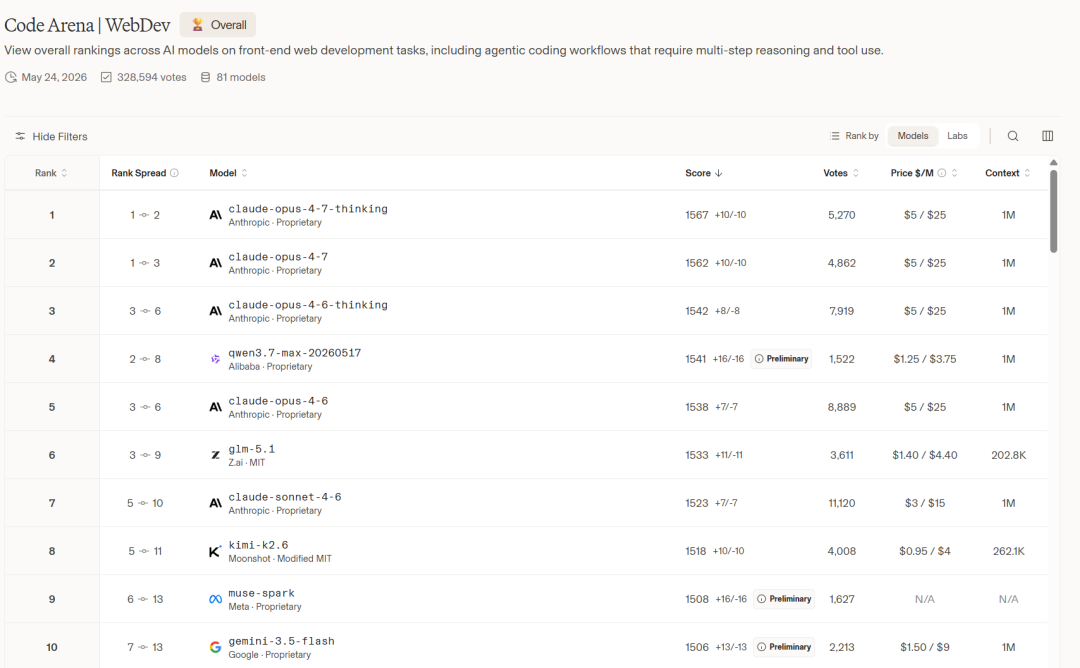
image.png
code arena 排行
就在 5 月 24 日的最新排名里,阿里 Qwen3.7-Max 以 1541 分 稳居全球第 4。前面是 Claude 的几款 Opus 系列(1567、1562、1542),它只差几分,紧紧咬住第三名。把 GPT、Gemini 等一众模型都甩在了身后。
看到这个名次,我第一感觉是:中国大模型在编码这个硬核战场上,真的在快步前进。
不是刷分,是真能打生产硬仗
Qwen3.7-Max 最让人服气的,不是单纯的分数,而是它专为生产环境打造的实力。
它被设计成能扛长跑的选手:稳定执行 35 小时以上的复杂任务、完成上千次工具调用,把原本两周才能完成的项目压缩到几个小时交付。这不是实验室玩具,而是真正能落地干活的 agent。
不少开发者已经在真实项目里测过:从需求拆解、多文件工程构建、debug 到性能优化,它能自己把整个链路走完,中间不用你频繁干预。以前我们吐槽 AI 像实习生,现在 Qwen3.7-Max 给人的感觉更像一个抗压能力强、执行力在线的 Senior Engineer。
1M token 上下文只是基础,它在长链路 agent 任务上的稳定性、工具调用协调能力,才是真正亮点。Terminal Bench、SWE-Pro 等考验真实工程能力的榜单,它的表现都非常扎实。
中国团队在追赶路上越跑越有劲
过去我们常说“追赶”,而现在 Qwen3.7-Max 这个第 4 的位置,让人明显感觉到中国大模型在 agentic coding 赛道上的进步速度正在加快。
尤其难得的是:它强,而且性价比高。能打到这个水平,价格却比 Claude 系列亲民不少。对国内团队和独立开发者来说,这意味着可以更大胆地把复杂项目交给 AI,不用再为 token 费用反复算账。
这也说明,在决定未来生产力的编码 agent 方向上,中国团队的迭代节奏和实用思路,已经越来越有竞争力。
目前官网也在 限时五折,有兴趣的同学也可以体验一下 100 万token的免费
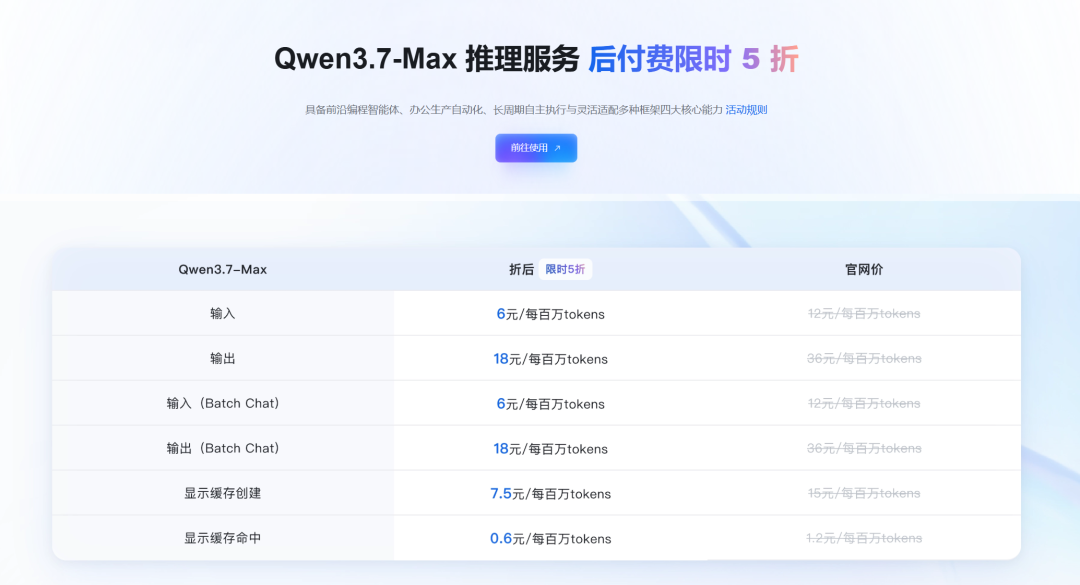
image.png
官网价格
榜单只是参考,真正牛的是能把活干完
分数重要,但更重要的是它能不能真正帮我们把 deadline 干掉、把项目推上线。
Qwen3.7-Max 现在的定位,就是这样一个“靠谱干活型”选手。它不跟你玩虚的,而是踏踏实实陪你搬砖——而且搬得又快又稳,还特别能持久。
对我们这些天天和代码死磕的人来说,2026 年看到这样的进步,确实挺爽的。
一个越来越能打的生产力 AI 编码伙伴来了,而且是中国团队造的。
你最近试过 Qwen3.7-Max 了吗?把它扔到你手上最棘手的项目里,感受一下那种“终于有个能长期作战的队友”的爽感。
欢迎大家在评论区聊聊:
- 你已经用 Qwen3.7-Max 做过什么项目了?实际体验如何?
- 它和 Claude 相比,你觉得哪个更适合你的日常工作流?
- 你觉得它什么时候能冲进前三?
如果这篇文章对你有一点启发:
- 💬 欢迎在 评论 区聊聊你的看法,批评指正文章内容
- 👍 点个爱心,让我知道这类内容有人看,我也好更好的选择创作方向
- 🔁 转发/收藏备用 如果内容有用,可以转发或者收藏备用~
你的每次互动,都是我继续写实战内容的动力。
推荐阅读
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号