大模型搬进你的手机,端侧AI时代来了

大模型搬进你的手机,端侧AI时代来了

老周聊架构
发布于 2026-05-29 12:56:20
发布于 2026-05-29 12:56:20
一次简单的对话,几毛钱。一天几亿次对话,几千万美元。一年下来,光电费就够买一支英超球队了。
这还只是钱的问题。更要命的是:你的每一句话、每一张照片、每一段语音,都要先飞到几千公里外的数据中心,被一堆 GPU 嚼一遍,再飞回来。
延迟 200 毫秒起步。隐私?全靠信任。
所以,一个很自然的问题出现了:能不能把大模型直接塞进手机、PC、甚至耳机里?
本周,两家巨头同时给出了答案:
AMD 正在把大型 AI 模型推向更靠近设备端的位置——用 NPU(神经网络处理器)让笔记本和台式机直接跑大模型。
苹果 在推进以隐私为核心的 Siri 升级,强调端侧处理——你的数据不出手机,AI 在本地完成一切。
云端 AI 是"去北京看病",端侧 AI 是"家门口的社区医院"。 不是所有病都需要去协和,大部分日常需求在家门口就能解决——更快、更便宜、更私密。
今天拆开来看,端侧 AI 到底怎么把大模型塞进小设备,技术上做了哪些妥协,以及——这会怎样改变我们使用 AI 的方式。
一、为什么要把大模型搬下云端?
三重压力倒逼
端侧 AI 不是"锦上添花",而是被三重压力逼出来的。

压力一:成本。
云端推理的成本结构是:GPU 算力 + 网络带宽 + 数据中心运维。GPT-4 级别的模型,每 100 万 Token 的推理成本约 10-30 美元。当用户量从百万级涨到十亿级,成本会指数级增长。
把推理搬到端侧,相当于让用户自带算力。 服务商的边际成本趋近于零。
压力二:延迟。
云端推理的链路:设备 → 基站 → 骨干网 → 数据中心 → GPU 计算 → 原路返回。一个往返 200-500 毫秒,这还是网络好的情况。在地铁里、飞机上、偏远地区?可能直接超时。
端侧推理的链路:设备 → NPU 计算 → 完成。延迟 10-50 毫秒,比眨眼还快。
压力三:隐私。
这是最致命的一刀。欧盟 GDPR、中国《个人信息保护法》、加州 CCPA——全球隐私法规越来越严。用户的照片、语音、健康数据如果全部上传到云端处理,合规成本极高,数据泄露风险更大。
端侧处理意味着数据不出设备。 不是"我们承诺不看你的数据",而是"你的数据根本没离开过你的手机"。技术上的隐私保证,比合同上的隐私承诺强一万倍。
一笔账算清楚
假设一个 AI 助手每天被使用 10 次,每次消耗 1000 Token:
方案 | 单次成本 | 日成本(10亿用户) | 年成本 |
|---|---|---|---|
云端推理 | 约 0.01 美元 | 约 1000 万美元 | 约 36.5 亿美元 |
端侧推理 | 约 0(用户硬件) | 约 0 | 约 0 |
36.5 亿美元 vs 0。 这就是为什么所有硬件厂商都在疯狂推端侧 AI。
二、AMD 的策略:让每台 PC 都是 AI 工作站
NPU 是什么?
CPU 擅长通用计算,GPU 擅长并行计算,而 NPU(Neural Processing Unit,神经网络处理器) 专门为 AI 推理优化。
三者的关系:
- CPU 是"全科医生"——什么都能干,但效率一般
- GPU 是"外科医生"——并行手术特别强,但功耗高、价格贵
- NPU 是"AI 专科医生"——只做 AI 推理,但能效比极高
NPU 的核心优势是 TOPS/W(每瓦算力)——同样的功耗下,NPU 的 AI 推理性能可以是 CPU 的 10-50 倍。
AMD 在做什么?
AMD 的端侧 AI 策略可以概括为三个字:塞进去。
第一步:把 NPU 塞进 CPU。 AMD 的 Ryzen AI 系列处理器,在 CPU 芯片内部集成了专用 NPU。不需要额外买加速卡,买了电脑就自带 AI 能力。
第二步:把大模型塞进小设备。 通过模型量化(从 FP32 压缩到 INT4/INT8)、知识蒸馏(用大模型训练小模型)等技术,把原本需要几百 GB 显存的大模型压缩到 几 GB 甚至几百 MB。
第三步:把生态塞进开发者。 AMD 推出了 Ryzen AI Software SDK,让开发者可以方便地把 AI 模型部署到 NPU 上。支持 ONNX Runtime、PyTorch 等主流框架。
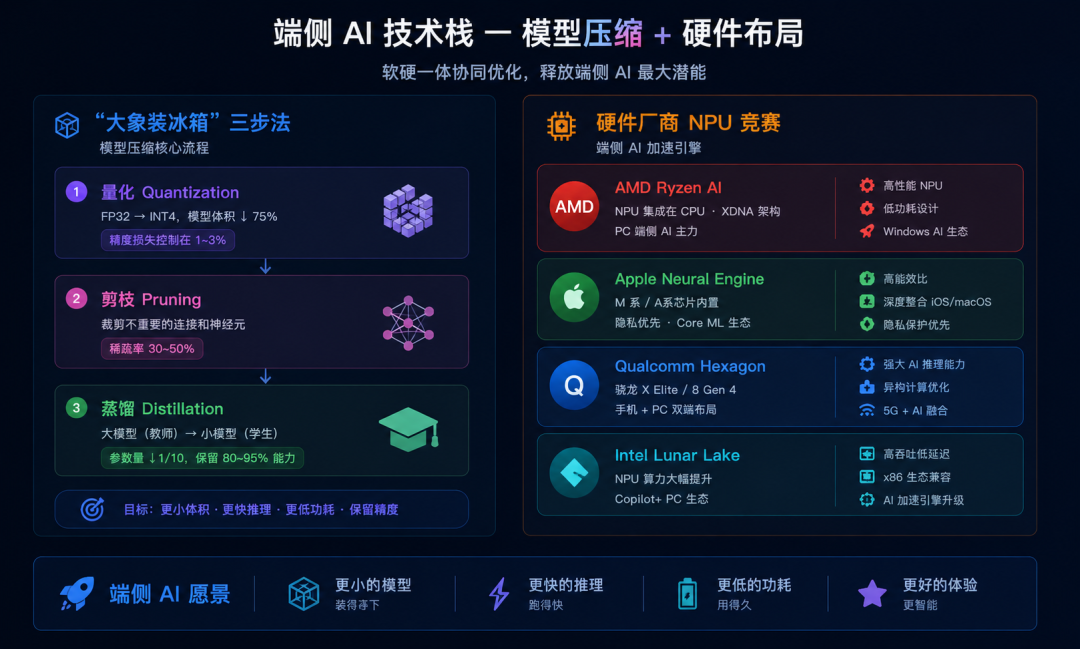
模型压缩:大象装冰箱
把一个 700 亿参数的大模型塞进 16GB 内存的笔记本,听起来像"把大象装进冰箱"。实际上,AI 工程师们真的有"三步装象法":
第一步:量化(Quantization)。 把模型参数从 32 位浮点数(FP32)压缩到 4 位整数(INT4)。精度下降约 1-3%,但模型大小缩小 8 倍。70B 参数模型从 280GB 压到 35GB。
第二步:剪枝(Pruning)。 砍掉模型中"不重要"的连接和神经元。就像修剪树枝——把不结果的枝条剪掉,树反而长得更好。通常能再压缩 30-50%。
第三步:蒸馏(Distillation)。 用大模型(教师)的知识去训练一个小模型(学生)。学生模型参数可能只有教师的 1/10,但能保留 90-95% 的能力。
三步走完,一个 70B 的云端模型可以变成一个 7B 的端侧模型,跑在普通笔记本上,延迟低于 50 毫秒。
代价是什么?复杂推理能力下降。端侧模型能流畅地做翻译、摘要、代码补全,但让它写一篇深度分析报告或者做多步数学推理,就力不从心了。
这就是"社区医院"的定位——常见病没问题,疑难杂症还是得去云端"三甲医院"。
三、苹果的策略:隐私即产品
苹果做端侧 AI 的逻辑
苹果做端侧 AI 的逻辑和 AMD 完全不同。
AMD 的逻辑是:性能驱动。 让 PC 跑得动更大的模型。
苹果的逻辑是:隐私驱动。 用户的数据一个字节都不能出设备。
这不是技术偏好,这是商业模式决定的。
Google 和 Meta 靠广告赚钱——它们需要你的数据来精准投放广告。苹果靠卖硬件赚钱——它不需要你的数据,反而可以把"不碰你的数据"当成卖点。
"你的数据留在你的设备上"——这句话对 Google 来说是成本,对苹果来说是广告语。
Siri 升级的技术路线
苹果正在推进的 Siri 升级,核心是分层处理架构:
第一层:完全端侧。 简单任务(设闹钟、发消息、查天气)完全在设备上处理。不联网,不上传,零延迟。Apple 的 Neural Engine(苹果版 NPU)负责执行。
第二层:私有云计算(Private Cloud Compute)。 复杂任务需要更大的模型时,数据会被加密发送到苹果的专用服务器集群。这些服务器运行定制的 Apple Silicon 芯片,不存储用户数据,处理完立即删除。
第三层:第三方模型(如 ChatGPT)。 最复杂的任务可以选择调用外部模型,但必须经过用户明确授权,而且苹果会尽量匿名化请求。
这套架构的核心思想是:能在本地做的绝不上云,必须上云的绝不存储,必须用外部的绝不自动授权。
隐私 vs 功能的博弈
苹果的隐私策略带来了一个根本性的矛盾:
端侧模型越小,隐私越好,但功能越弱。云端模型越大,功能越强,但隐私越差。
这就是为什么 Siri 在"智能程度"上一直被 Google Assistant 和 ChatGPT 压着打——不是苹果做不出更聪明的 AI,而是苹果选择了隐私优先的技术路线,这条路天然会牺牲一些能力上限。
苹果的赌注是:用户最终会选择"够用且安全"而不是"很强但裸奔"。
目前来看,这个赌注在高端市场是成立的。iPhone 用户为隐私付费的意愿明显高于安卓用户。
四、端侧 vs 云端:不是替代,是分层
"混合推理"才是终局
端侧 AI 不会取代云端 AI,就像社区医院不会取代三甲医院。最终的架构是混合推理——根据任务的复杂度、隐私敏感度、网络状况,动态选择在哪里计算。
场景 | 推理位置 | 原因 |
|---|---|---|
语音唤醒/人脸解锁 | 端侧 | 延迟要求极高,隐私敏感 |
实时翻译/字幕 | 端侧 | 延迟敏感,离线场景多 |
照片编辑/美颜 | 端侧 | 隐私敏感,计算量适中 |
写一封邮件 | 端侧/边缘 | 中等复杂度,可本地处理 |
深度代码分析 | 云端 | 需要大模型,复杂推理 |
训练/微调模型 | 云端 | 算力需求极大 |
决策树很简单:能本地做的本地做,本地做不了的上边缘,边缘做不了的上云端。
硬件厂商的终极目标
AMD、苹果、高通、英特尔——所有硬件厂商推端侧 AI 的终极目标其实是一样的:卖更多芯片。
"你的旧电脑/旧手机跑不了 AI"——这是自 4G 升 5G 以来,最强的换机驱动力。
高通的骁龙 X Elite、AMD 的 Ryzen AI、苹果的 M4、英特尔的 Lunar Lake——每一家都在把 NPU 算力写进芯片的广告语里。
PC 行业沉寂了五年,终于找到了让用户换电脑的理由:你的电脑不支持 AI。
手机行业也一样。"端侧大模型"正在成为旗舰手机的标配卖点,就像当年的"千万像素摄像头"。
五、对技术人的三个判断
第一,端侧推理是未来 2-3 年最确定的技术趋势。
不管你做前端、后端还是移动端,了解端侧 AI 的部署方式(ONNX、Core ML、TensorFlow Lite)都会成为加分项。模型压缩和量化技术尤其值得关注。
第二,"混合推理"架构设计将成为新的技术壁垒。
如何设计一套系统,让 AI 任务在端侧、边缘和云端之间无缝切换?这涉及模型分割、智能路由、一致性保证——这些架构问题目前还没有标准答案,谁先解决谁就有优势。
第三,隐私将成为 AI 产品的核心竞争力。
苹果已经证明"隐私可以卖钱"。随着全球隐私法规收紧,"你的数据不出设备"将从营销口号变成技术刚需。端侧 AI 不仅是性能优化,更是合规基础设施。
写在最后
云端 AI 像一座巨大的发电站——功率惊人,但电线拉不到每个角落。
端侧 AI 像每家每户的太阳能板——功率有限,但自给自足,不怕断电。
未来的 AI 基础设施,不会只有发电站,也不会只有太阳能板。而是发电站 + 太阳能板 + 储能电池的混合电网。
AMD 在造更强的太阳能板,苹果在造更安全的太阳能板。殊途同归——都是为了让 AI 从"云上的奢侈品"变成"身边的日用品"。
你的下一台电脑,可能就自带一个"小号 ChatGPT"。不需要联网,不需要付费,不需要把你的秘密告诉任何人。
那一天不远了。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号