AI被吹得天花乱坠,第一个企业级实战测试:全都不及格

AI被吹得天花乱坠,第一个企业级实战测试:全都不及格

随机比特
发布于 2026-05-29 13:01:08
发布于 2026-05-29 13:01:08
ITBench-AA 的第三道题是这样的:
otel-demo 命名空间里,ad 服务的 CPU 和延迟突然飙升。Agent 拿到一份离线快照——告警列表、事件流、trace 链路、metrics 面板、Kubernetes 拓扑。它可以在沙箱里跑任何 shell 命令来查日志、读配置、描依赖。
真正的根因是一个叫 flagd-config 的 ConfigMap。有人把 adHighCpu 这个 feature flag 拨到了 ON,导致 ad 服务的 Pod 被压爆了。
Agent 提交的诊断是:[ad Deployment, frontend Deployment, flagd Pod]。
第一个对了 0 个——ad Deployment 是受害人,不是凶手。第三个也是下游反应,不是根因。而真正的 ConfigMap,根本没出现在名单里。
评分规则直接给这道题判了 0 分。不是"扣一点分",是零。
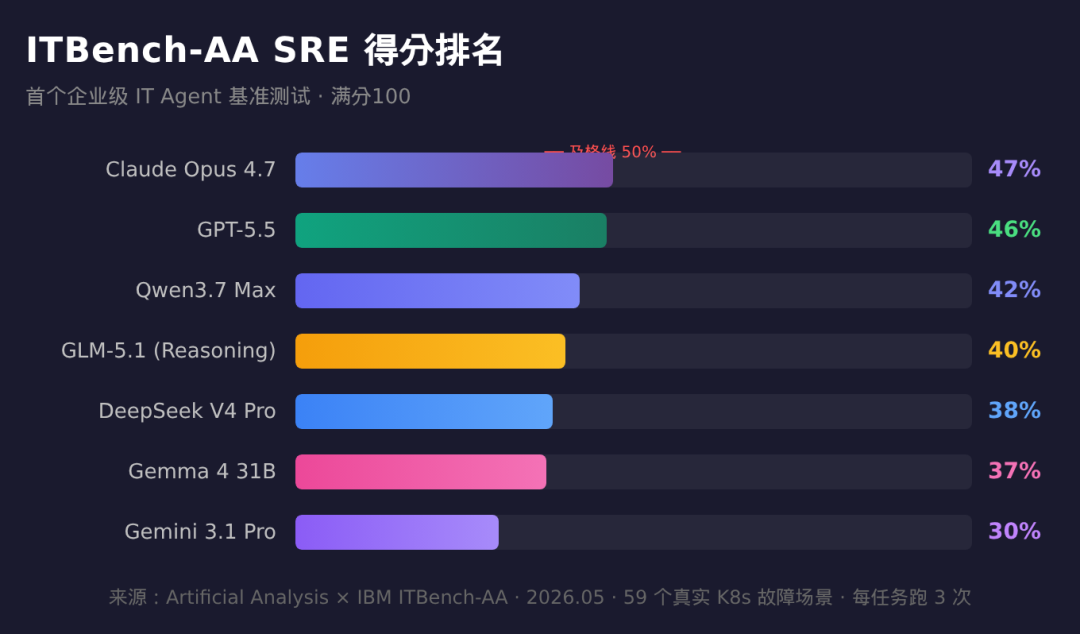
01-itbench-leaderboard
这个基准测试的核心设计,就是在惩罚好奇心
ITBench-AA 由 Artificial Analysis 和 IBM 联合发布。59 个真实 Kubernetes 故障场景,每道题跑 3 次,每次 100 轮 shell 调用上限。Agent 拿到的是和生产环境一样的离线快照:告警、事件、链路、指标、拓扑。它用 shell 命令自行探索,最后输出一份 JSON——列出所有它认为是根因的 Kubernetes 实体。
计分方式叫"recall-gated precision"。翻译成人话:漏掉任何一个真正的根因,0 分。找齐了全部根因之后,每多报一个无关实体,按比例扣分。
公式是 TP / (TP + FP)。你提交了 3 个嫌疑人,只有 1 个是对的?1/3 = 33%。它比做错扣分更狠——它让"多找多看"这件事本身变成负资产。
这套规则和此前的所有 Agent 基准测试的哲学是反的。
SWE-bench 测的是你能不能修好 bug。Terminal-Bench 测的是你能不能完成 sysadmin 任务。在这些测试里,多花几轮搜索代码库、多试几种方案,即使效率低,也不会扣你分——找到就算赢。
ITBench-AA 把逻辑倒了过来。因为在生产环境里,一个 SRE Agent 报出 8 个"根因"让值班工程师去逐一排查,比一个都找不到更灾难。你不仅没缩小排查范围,反而是拿着噪音帮倒忙。

常规基准 vs ITBench-AA 评分对比
这就是为什么它叫"IT 自动化基准"而不是"模型能力基准"。它直接测试你的 Agent 系统敢不敢放进生产流水线。
83 轮 vs 58 轮:努力的惩罚
实测数据把这个设计意图展现得极其残酷。
Claude Opus 4.7 以 47% 排名第一,每个任务平均只用了 31 轮 shell 调用。GPT-5.5 紧随其后,46%,也是 31 轮。它们查得精,停得早。
榜单底部的 Gemini 3.1 Pro Preview 是另一个极端:平均跑了 83 轮——全场最多——得分只有 30%。
一个具体的失败模式是这样的:Agent 先发现了 otel-demo 空间里有个 Pod 频繁重启。它去读 Pod 的 events,看到一串 BackOff。它接着去读 Deployment 的 describe,发现 CrashLoopBackOff。这时候它已经锁定了嫌疑人——但它没有停下来。它顺着 events 里的关联告警往下追,找到了上游的 chaos-mesh-controller 注入器——这东西确实"相关",但不是根因。它再翻 /var/log 下的应用日志,看到同一个时间段另一个服务的超时——又是"相关",又不是根因。
上下文窗口在每轮 shell 调用中不断膨胀。告警噪音、events 冗余、symlink 链、无关的 metrics 面板——全被塞进了同一个 prompt。模型开始在这些碎片之间建立虚假关联。最终提交了一份包含 7 个 false positive 的诊断报告。
而谷歌的 Gemma 4 31B——一个参数规模远小于 Gemini 3.1 Pro 的开源模型——只跑了 58 轮,得分 37%,高了整整 7 个百分点。每道任务的成本是 0.14 美元,对比 Gemini 3.1 Pro 的 2.23 美元,便宜了 16 倍。
在这个测试里,参数规模、推理深度和最终得分之间没有正相关性。正相关性出现在另一个维度上:模型在什么时候愿意停止探索。
Agent 循环设计的三个约束
如果你现在就要在运维管线里接入一个 Agent,循环应该怎么设计?
ITBench-AA 的 Stirrup harness 本身就是一个答案。它把所有模型的评估放在同一个沙箱框架里——同样的 shell 环境,同样的文件系统挂载,同样的 100 轮上限。这意味着测试的变量只有一个:模型本身。
但从结果反推,真正的杠杆不在模型选择上,在循环约束上。
第一条约束是工具白名单的粒度。Stirrup 给 Agent 的是裸 shell。但生产环境里,一个 SRE Agent 不需要 curl、不需要 rm、不需要 kubectl delete。它只需要 kubectl describe、kubectl logs --tail=200、kubectl get events --sort-by=.lastTimestamp、grep -r 'error\|fatal\|panic' /var/log/<service>/。每少一个可用命令,就少一个 Agent 可以钻进去的兔子洞。
第二条约束是强制排除逻辑。Agent 不应该只输出"我认为根因是 X",而应该输出"我认为根因是 X,因为 Y;我排除了 Z,因为 Z 的告警时间戳在故障窗口之外"。每一个进入候选人名单的实体,必须有一条独立的排除证据与之对应。这套规则的直接效果是:Agent 在提出第二个嫌疑人之前,必须先把第一个嫌疑人排除掉——或者证明关联性。它强行打断了"发现→继续发现→堆叠输出"的循环惯性。
第三条约束是输出格式本身的收敛设计。Stirrup 让 Agent 输出 JSON——一个固定 schema 的数组。这个格式本身在 prompt 层面施加了一个结构限制:你不能输出"可能是 A,也可能是 B,也可能和 C 有关"的自然语言段落。你必须给出一个确定的列表。而列表的每一项都是赌注——多一个项目,就多一个被扣分的机会。JSON schema 在此刻不是技术细节,它是约束推理发散性的第一道防线。
便宜模型 + 好约束,比贵模型 + 裸循环更能打
ITBench-AA 的排行榜上还藏着一个容易被忽视的数据点。
开源模型 GLM-5.1(Reasoning)得分 40%,每任务成本 1.23 美元。闭源的 Gemini 3.5 Flash 得分也是 40%,每任务成本 1.70 美元。DeepSeek V4 Pro 得分 38%,每任务成本 0.47 美元。Gemma 4 31B 得分 37%,每任务成本 0.14 美元——只有排名第一的 Claude Opus 4.7(5.38 美元/任务)的 2.6%。
把这些数字放在一起看:你花 5.38 美元拿 47%,或者花 0.14 美元拿 37%,两者之间只差 10 个百分点。如果加上一套设计良好的工具白名单和排除逻辑约束——这两样东西是零成本的——那个 10 个百分点的差距大概率会更小。
在企业 SRE 场景下,模型能力的边际收益已经急剧递减,Agent 循环设计的边际收益正在急剧递增。
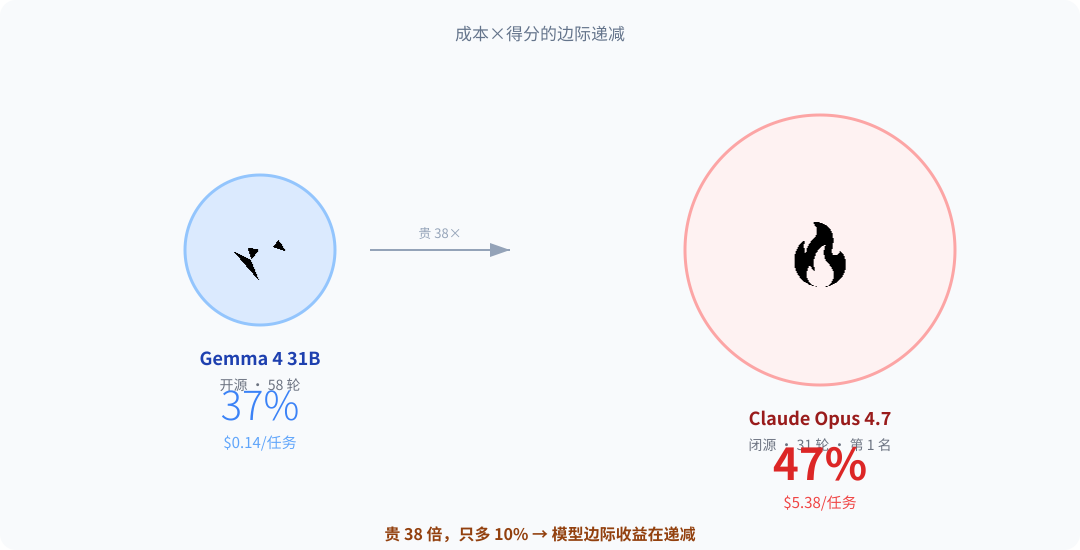
Gemma vs Claude 成本对比
这不是"换一个更强的模型"能解决的问题。这是"写一套更严格的约束"就能提升的问题——而写约束比训模型便宜一百万倍。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号