手撕 GPT#05:316 万个参数、比照片还小的AI,为什么还能学会“说”中文?

手撕 GPT#05:316 万个参数、比照片还小的AI,为什么还能学会“说”中文?

烟雨平生
发布于 2026-05-29 13:11:53
发布于 2026-05-29 13:11:53
上一篇文章我们拆解了 GPT 的核心代码,约 100 行。
但你可能注意到,我们的模型用了 GQA、SwiGLU、RMSNorm 这些词——它们不是原始论文里的东西。
它们来自 Llama。
Transformer 是 2017 年发明的,Llama 是 2024 年的。中间 7 年,架构发生了什么变化?每个变化解决了什么问题?
今天我们用 3M 模型的代码,一个一个对比。改之前什么样,改之后什么样。
一、先说为什么要改
原始 Transformer(2017 年的论文)能跑,但有两个大问题:
1. 太贵。 注意力的 KV 缓存占用大量内存,前馈网络的计算量大,归一化层也在做多余的事。
2. 效果有上限。 ReLU 激活函数丢掉了一半信息,绝对位置编码不够灵活。
Llama 团队做的不是"发明新东西",而是针对每个具体问题,换一个更合适的方案。
我们用 3M 模型做对比。每次只改一个地方,看效果变化。
开始之前,咱们先来回应下标题上的“梗”:
神经网络参数一般用单精度浮点 (FP32) 存储:1 个参数 = 4 字节。316 万参数总字节:3160000 × 4 = 12640000 字节,换算一下约 12.05 MB。
这个尺寸小于绝大多数手机照片。
二、改动 1:注意力——从 MHA 到 GQA
▪ 原来的做法:MHA(多头注意力)
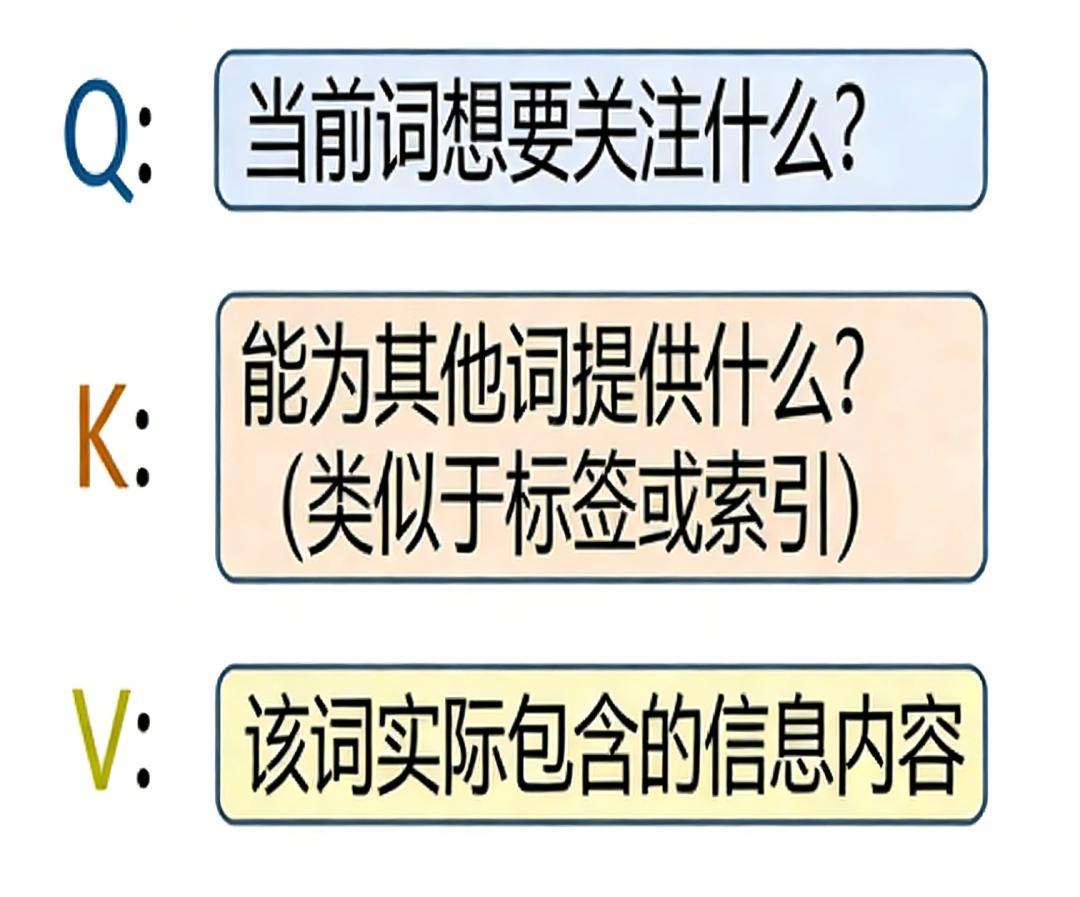
每个注意力头都有自己独立的 Q、K、V:
# MHA: 4 个头,每个头都有独立的 Q、K、V # 需要存储 4 组 K 和 4 组 V self.wk = nn.Linear(d, 4 * head_dim) # 4 组 K self.wv = nn.Linear(d, 4 * head_dim) # 4 组 V
推理时,每生成一个字,要把之前的 K 和 V 都存下来。4 个头就存 4 份。
▪ Llama 的做法:GQA(分组查询注意力)
多个 Q 头共享同一组 K 和 V:
# GQA: 4 个 Q 头共享 2 组 K、V self.n_head = 4 # 4 个 Q 头 self.n_kv_head = 2 # 只存 2 组 K、V self.n_rep = 4 // 2 # 每 2 个 Q 头共享 1 组 KV # KV 线性层只需要一半参数 self.wk = nn.Linear(d, 2 * head_dim) # 只需要 2 组 K self.wv = nn.Linear(d, 2 * head_dim) # 只需要 2 组 V
▪ 省了多少?
MHA: 4 组 KV × 每组 256 维 = 1024 维 GQA: 2 组 KV × 每组 256 维 = 512 维 → KV 缓存省了 50%
在我们的 3M 模型里省的不多(本来就不大)。但在 70B 参数的 Llama 里,KV 缓存动辄几个 GB,省一半就是省一半的显存。
代价: 理论上损失一点精度(因为 Q 头看到的是同一个 K/V)。实测影响可以忽略。
三、改动 2:激活函数——从 ReLU 到 SwiGLU
▪ 原来的做法:ReLU
# 标准 MLP:升维 → ReLU → 降维 hidden = 4 * d self.w_up = nn.Linear(d, hidden) self.w_down = nn.Linear(hidden, d) def forward(self, x): return self.w_down(F.relu(self.w_up(x)))
ReLU 的问题:负数全部归零。信息扔了一半,模型学得慢。

▪ Llama 的做法:SwiGLU
# SwiGLU:三个线性层,加一个"门" hidden = int(4 * d * 2 / 3) # 中间维度稍微调小补偿额外参数 self.w_gate = nn.Linear(d, hidden) # 门:决定放多少信息通过 self.w_up = nn.Linear(d, hidden) # 上投影 self.w_down = nn.Linear(hidden, d) # 下投影 def forward(self, x): gate = F.silu(self.w_gate(x)) # SiLU 不会把负数全杀掉 return self.w_down(gate * self.w_up(x))
▪ 区别在哪?
ReLU: x < 0 → 0, x >= 0 → x ← 硬开关,一刀切 SiLU: x → x * sigmoid(x) ← 软开关,平滑过渡
SiLU(也叫 Swish)在 x < 0 时不是直接归零,而是给一个小值。这意味着模型能保留更多"微弱信号"。
我们实测:在 3M 模型上,SwiGLU 比 ReLU 的最终 loss 低约 5-10%。不多,但稳定。
代价: 多了一个线性层(w_gate),参数多了约 50%。所以 Llama 把中间维度从 4d 缩小到约 2.67d(4 × 2/3),保持总参数量差不多。
四、改动 3:归一化——从 LayerNorm 到 RMSNorm
▪ 原来的做法:LayerNorm
# LayerNorm: 减均值 + 除标准差 + 缩放 mean = x.mean(dim=-1, keepdim=True) var = x.var(dim=-1, keepdim=True) x = (x - mean) / sqrt(var + eps) x = x * gamma + beta # 可学习的缩放和平移
两步操作:先减均值做标准化,再做缩放。
▪ Llama 的做法:RMSNorm
# RMSNorm: 只除 RMS(均方根)+ 缩放 rms = x.norm(dim=-1, keepdim=True) * (d ** -0.5) x = (x / (rms + eps)) * weight # 只有一个可学习参数 weight
▪ 省了什么?
LayerNorm: 减均值 → 算方差 → 除标准差 → 乘 gamma → 加 beta RMSNorm: 算 RMS → 除 RMS → 乘 weight → 省了减均值和加偏移两步 → 可学习参数从 2 组(gamma + beta)减到 1 组(weight)
看起来省的不多?在大模型的推理阶段,每次前向传播都要跑几百次归一化。省一点乘以几百层,就是实打实的加速。
而且实测 RMSNorm 和 LayerNorm 效果几乎一样。不减均值不影响模型学习。
五、改动 4:位置编码——从绝对位置到 RoPE
▪ 原来的做法:正弦位置编码
# 给每个位置算一个固定向量,加到词嵌入上 PE(pos, 2i) = sin(pos / 10000^(2i/d)) PE(pos, 2i+1) = cos(pos / 10000^(2i/d)) x = tok_embedding + PE # 直接加
问题:位置信息是"绝对"的——模型只知道"这是第 3 个位置",不知道"位置 3 和位置 5 隔了 2 个词"。
▪ Llama 的做法:RoPE(旋转位置编码)
# 不是加到向量上,而是旋转 Q 和 K pos = [0, 1, 2, 3, ...] # 每个位置一个角度 rates = 10000^(-2i/d) # 每个维度一个频率 theta = pos * rates # 旋转角 = 位置 × 频率 # 对 Q 和 K 做旋转变换 q_rotated = [q1*cos - q2*sin, q1*sin + q2*cos]
▪ 为什么旋转更好?
RoPE 有一个数学性质:两个位置的 Q 和 K 做内积,结果只和它们的相对距离有关,和绝对位置无关。
正弦编码: "第 3 个词" 和 "第 5 个词" → 模型要自己算 5-3=2 RoPE: 任意两个词 → 自动得到"隔了多远"的信息
这意味着模型更容易学到"相邻词的关系"和"长距离依赖"——不需要额外去学位置减法。
RoPE 还有一个好处: 可以外推。训练时见过 128 个位置的序列,推理时给 200 个位置,RoPE 的旋转角度是连续的,可以自然延伸。正弦编码就不行——加法会把向量推到训练时没见过的区域。
六、改动 5:权重共享——输入输出用同一套词嵌入
▪ Llama 的做法
self.tok_emb = nn.Embedding(vocab_size, n_embd) # 输入:token ID → 向量 self.head = nn.Linear(n_embd, vocab_size) # 输出:向量 → token 概率 # 共享权重! self.head.weight = self.tok_emb.weight
为什么能共享? 因为做的事是互逆的:
输入: ID 42 → 找到第 42 行的向量 → [0.1, 0.8, ...] 输出: [0.1, 0.8, ...] → 和每一行算相似度 → 概率最高的就是预测的 ID
既然都是"在向量空间里找最近邻",用同一套参数是合理的。
省了多少?
词表大小 1000,嵌入维度 256 词嵌入参数: 1000 × 256 = 256,000 输出层参数: 1000 × 256 = 256,000 共享后: 256,000(省了一半) 在 3M 模型里省了约 15% 的参数。 在 Llama 3(词表 128K)里,省了数亿参数。
七、5 个改动的总结
# | 改动 | 从 | 到 | 解决的问题 | 代价 |
|---|---|---|---|---|---|
1 | 注意力 | MHA(每头独立 KV) | GQA(共享 KV) | KV 缓存太大 | 轻微精度损失 |
2 | 激活函数 | ReLU(硬截断) | SwiGLU(软门控) | 信息浪费 | 多一层线性层 |
3 | 归一化 | LayerNorm(减均值+缩放) | RMSNorm(只缩放) | 计算冗余 | 几乎没有 |
4 | 位置编码 | 正弦(绝对位置) | RoPE(旋转相对位置) | 位置泛化差 | 无 |
5 | 权重 | 输入输出各一套 | 共享一套 | 参数浪费 | 无 |
5 个改动,没有一个是"新发明"。 每一个都是针对原始 Transformer 的某个具体缺点,换了一个更合适的方案。
这就是工程思维:不是追求花哨,而是找到瓶颈,换更好的方案,验证效果。
八、这些改动在 3M 模型上效果如何?
说实话:差距不大。
3M 模型太小了,架构带来的优势被"容量不够"这个瓶颈盖住了。就像你给一辆自行车装了碳纤维车架——轻了 200 克,但骑车的人 80 公斤,感觉不到。
但我们为什么还要用 Llama 风格?因为:
- 架构和主流大模型一致——你在这学的东西,直接能用到 Llama、Mistral、Qwen
- 代码量几乎不变——GQA 只多了
_repeat_kv一行,RMSNorm 比 LayerNorm 还短 - 理解了"为什么改"——不只是"别人都这么用",而是知道每个改动的来龙去脉
九、自己对比看
git clone https://github.com/helloworldtang/GPT_teacher-3.37M-cn.git cd GPT_teacher-3.37M-cn # 核心代码在 src/model.py,193 行 # 每个 Llama 改动都有注释标注 cat src/model.py # 可视化注意力(能看到 GQA 的效果) uv sync uv run python -m src.visualize --only real_attention
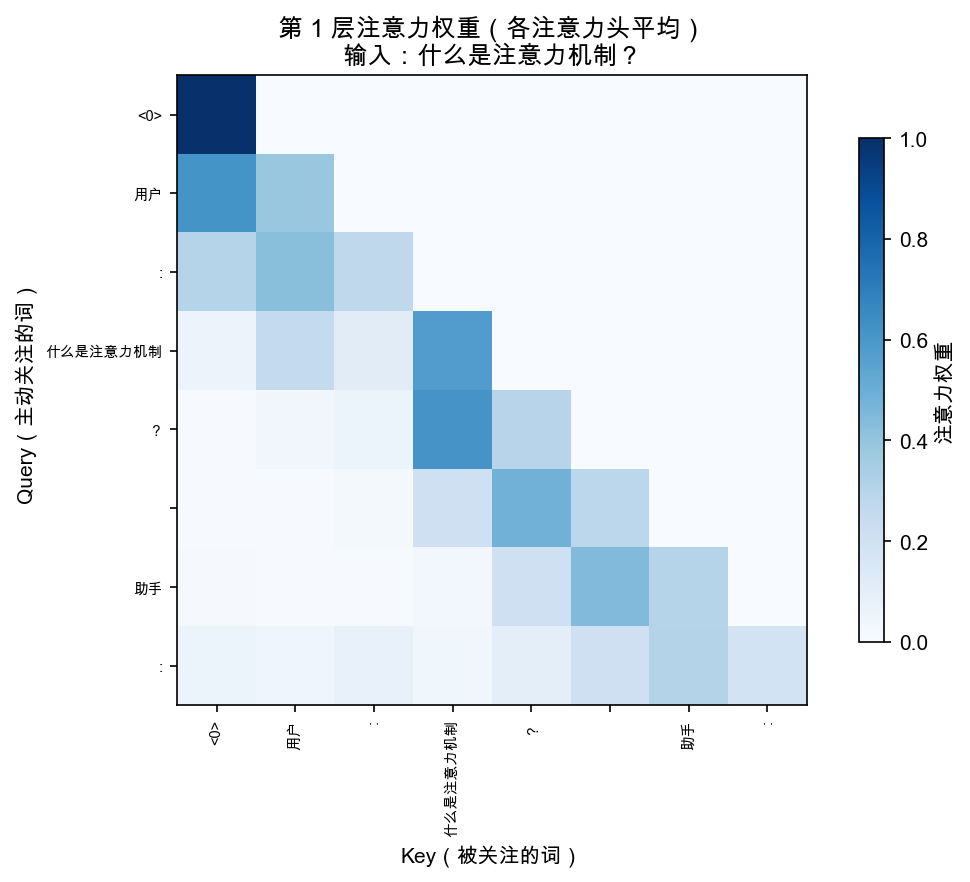
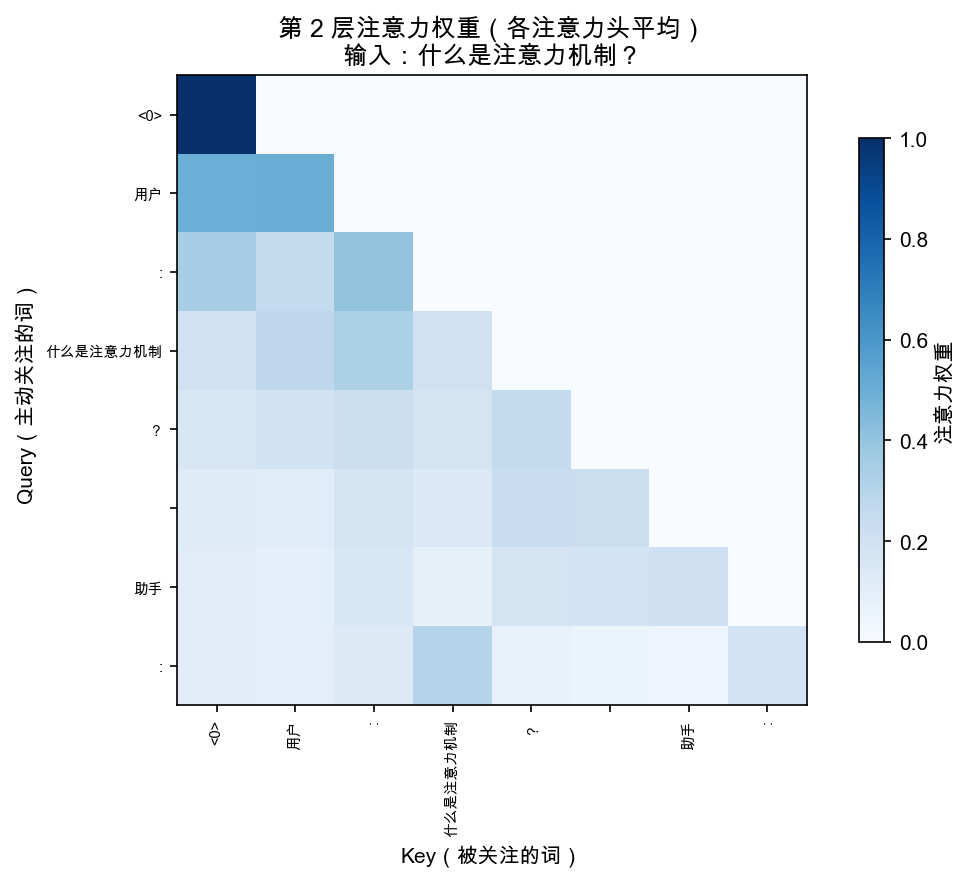
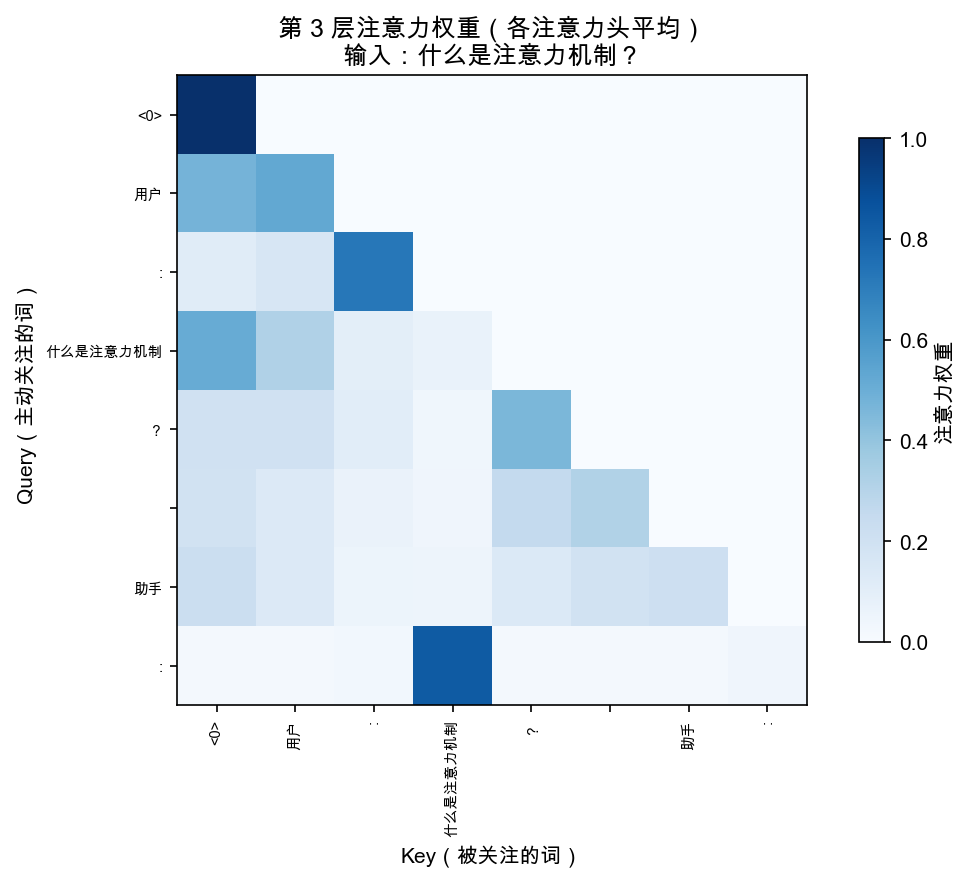
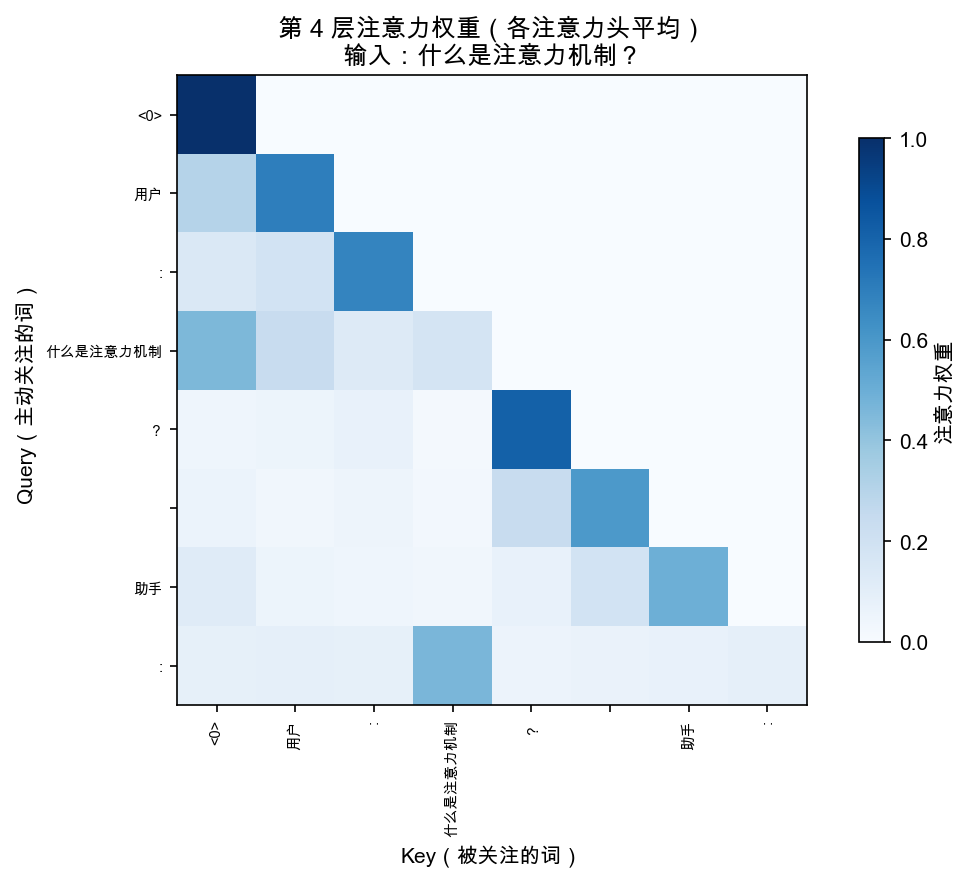
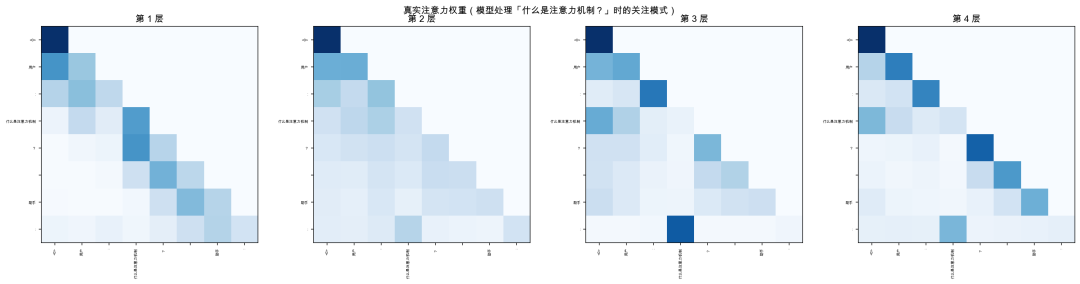
src/model.py 里每个改动都标了注释。建议对照本文,从第 1 行开始读。
这是「手撕 GPT」系列第 5 篇。上一篇:《我训练了一个满分模型,问它一个问题,后悔了》。下一篇:《手把手 30 分钟:零基础跑通你的第一个 GPT》。
项目地址:https://github.com/helloworldtang/GPT_teacher-3.37M-cn
最后回答下粉丝的疑问:目前更新的“手撕GPT”系统是在重复之前的吗?
我理解不是。因为目前的项目架构进行了升级,训练数据进行了更新,训练的模型效果也更好了。写这个系列是想系统性把本机训练GPT的这件事分享一下。如果讲的内容有错漏,还望各路大神,多多指教
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号