CXL 内存扩展:AI 时代的内存池化与压缩技术

CXL 内存扩展:AI 时代的内存池化与压缩技术

数据存储前沿技术
发布于 2026-05-29 13:44:33
发布于 2026-05-29 13:44:33
阅读收获
- 掌握内存架构演进逻辑: 理解从“直连内存”到“可组合内存池”的转变,明确 CXL 协议在解决内存闲置与资源动态调配中的核心作用。
- 洞察硬件压缩的工程价值: 认识到缓存行级(Cache-line)硬件压缩在降低延迟与提升有效容量方面的关键优势,掌握其在 AI 模型权重优化中的实际应用。
- 评估技术落地的商业可行性: 学习如何通过“确定性低延迟”与“分层调度”策略,平衡 AI 场景下对内存容量的渴求与对 SLA 的严苛要求。
全文概览
在 AI 基础设施中,内存成本已占据服务器总成本的半壁江山,且高达 40% 的内存资源处于闲置状态。传统“计算与内存紧耦合”的架构,在面对异构工作负载时显得捉襟见肘。随着 CXL(Compute Express Link)协议的成熟,内存池化与分层架构成为打破这一刚性配比的关键。然而,引入 CXL 交换层是否会带来不可接受的延迟?如何在扩展容量的同时,通过硬件压缩技术实现 TCO 的最优平衡?本文将深入剖析 CXL 内存扩展的技术路径,探讨如何通过“计算换容量”的策略,在 AI 推理与大数据场景中实现性能与成本的动态最优解。
👉 划线高亮 观点批注

- 内存是服务器/AI 基础设施中最大的单一成本项(~50%),且当前数据中心存在严重的内存资源闲置问题(~40% 的内存处于"stranded"状态),消除闲置可带来约 20% 的 TCO 降幅——这是后续技术方案(如 CXL 内存扩展/池化)的核心商业驱动力。
- 内存低效使用的根源是多维度的:包括异构工作负载对容量/带宽的差异化需求、NUMA 架构下的跨插槽访问延迟、数据副本冗余、计算负载波动以及局部热密度问题。这些问题共同指向"内存资源与计算资源紧耦合"的传统架构缺陷。
- DDR5 RDIMM + NVMe SSD 的物理配置示例(12 条 DDR5 + 12 块 NVMe)暗示了当前主流双路服务器的内存/存储配比现状,为后续讨论如何通过新技术(如 CXL 内存扩展、内存池化或分层存储)打破这一刚性配比埋下伏笔。
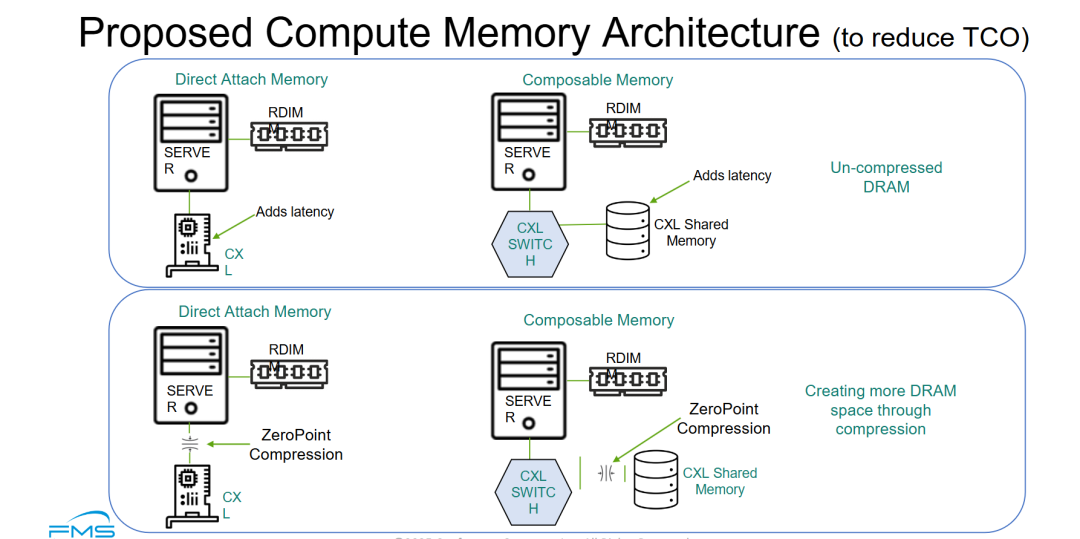
本页 PPT 的标题为 "Proposed Compute Memory Architecture (to reduce TCO)"(提议的计算内存架构,旨在降低 TCO),呈现了两组对比架构图,每组均包含"直连内存(Direct Attach Memory)"与"可组合内存(Composable Memory)"两种模式,核心差异在于是否引入 CXL(Compute Express Link)交换层 和 内存压缩技术。
整体架构逻辑:
- 横向对比:直连内存(单服务器本地/近端扩展) vs 可组合内存(跨服务器池化共享)
- 纵向对比:未压缩(原始容量) vs ZeroPoint 压缩(逻辑容量扩展)
- 核心组件:CXL SWITCH 是实现内存池化(Shared Memory)的关键网络层,ZeroPoint Compression 是提升有效容量的关键技术层
===
- CXL 内存扩展存在"容量 vs 延迟"的固有权衡:无论是直连还是通过 CXL 交换机池化,跨 CXL 链路访问远程内存都会引入额外延迟(图中两次标注 "Adds latency")。这是 CXL 架构从纸面到落地的核心工程挑战——如何在扩展内存容量的同时,将延迟控制在可接受范围内。
- ZeroPoint 压缩是突破物理容量瓶颈的关键技术层:该方案在 CXL 数据路径上引入 ZeroPoint 压缩,使得相同的物理 DRAM 空间可承载更多逻辑数据("Creating more DRAM space through compression")。这相当于用计算开销(压缩/解压)换取内存容量效率,在 AI/大数据等内存密集型场景中具有显著的 TCO 优化潜力。
- "直连扩展"与"池化共享"构成两条互补路径:直连模式适合对延迟敏感、需本地扩展的场景;可组合(Composable)模式通过 CXL 交换机实现跨服务器的内存资源池化,适合云化/多租户环境中动态调配内存资源的场景。两者共用 CXL 物理层,但网络拓扑和调度粒度不同,代表了 CXL 生态的两种落地形态。

- 可组合内存的"双刃剑"效应:内存池化/共享能有效消除闲置内存(解决第一页提出的 ~40% stranded memory 问题)并均衡功耗,但代价是访问延迟上升(DRAM 的时延的50-100ns,CXL 在150-300ns)。这是 CXL 内存扩展从"技术可行"走向"商业落地"必须跨越的核心工程门槛——延迟敏感型工作负载(如 AI 训练中的参数热更新、高频交易)对额外延迟的容忍度极低。
- 行业应对延迟挑战的四条技术路径已形成共识: (a) 内存分层(Tiering)——通过数据热度感知将冷数据下沉到高延迟大容量层; (b) 协议层优化——CXL 作为缓存一致性协议(内存语义)相比传统 PCIe(存储语义) 能显著降低远程内存访问开销; (c) 芯片架构重构——CXL 控制器、交换芯片的 IP 设计需针对低延迟重新优化; (d) 压缩技术——以计算换容量,间接降低单位有效容量的成本。这四条路径构成了当前 CXL 生态的技术攻坚矩阵。
- "平衡(Balancing)"是贯穿本页的核心方法论:TCO 优化不能单纯追求极致性能或极致成本,而需在延迟、容量、功耗、成本之间寻找动态最优解。可组合内存不是替代本地 DRAM,而是作为补充层级纳入整体内存架构,通过智能调度实现"性能可接受前提下的成本最优"——这与云计算中"分层存储"的成熟逻辑一致,但将分层粒度下探到了内存层级。
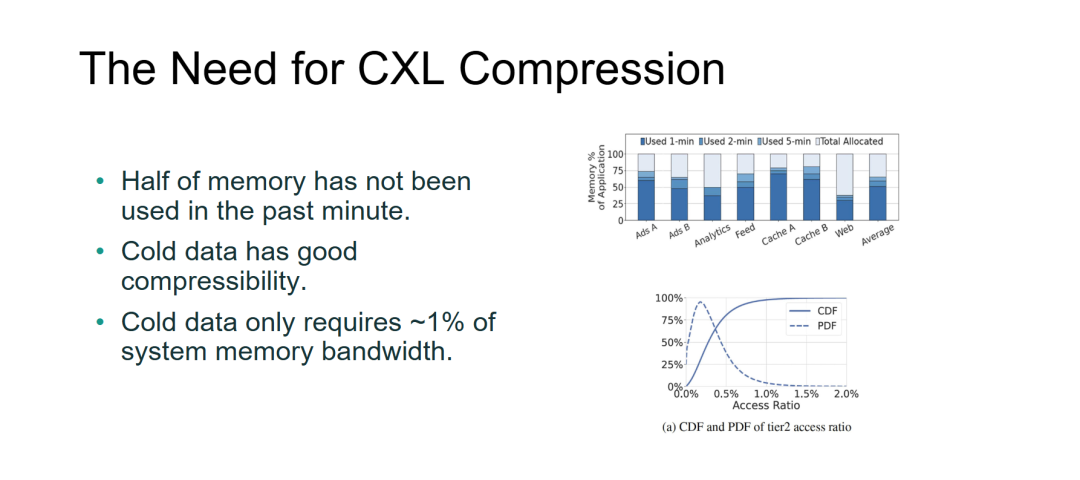
本页 PPT 的标题为 "The Need for CXL Compression"(CXL 压缩的必要性),通过文字论据 + 两张数据图表,从内存访问模式和数据冷热特征两个维度论证"为何 CXL 扩展内存路径上必须引入压缩技术"。
- 内存过度分配是数据中心的普遍现象,且时间维度上验证明确:柱状图显示所有应用类型的内存分配均接近 100%,但实际 1 分钟活跃度仅约 50%。这意味着传统"按峰值预留"的内存分配策略造成了严重的资源浪费,为 CXL 扩展内存+压缩方案提供了明确的优化空间——将低频冷数据迁移至 CXL 扩展层并压缩,可释放本地 DRAM 给热数据。
- 冷数据的"可压缩性"与"低带宽占用"构成了压缩技术的可行性双支柱:冷数据不仅压缩比高("good compressibility"),且访问频率极低(CDF 显示绝大多数 Tier2 数据访问比例 <0.5%,带宽占用 ~1%)。这意味着在 CXL 路径上引入压缩不会显著增加带宽压力或访问延迟,却能成倍提升有效容量——第二页提到的 "Creating more DRAM space through compression" 在此得到了数据层面的支撑。
- 本页完成了从"问题定义"到"技术必要性论证"的逻辑闭环:第一页提出内存高成本和闲置问题 → 第二页提出 CXL+压缩架构方案 → 第三页指出延迟挑战 → 第四页用实际工作负载数据证明"压缩是必要且可行的"。这为后续深入讨论 ZeroPoint Compression 的具体实现和性能收益奠定了实证基础。

本页 PPT 的标题为 "Compressed Memory: Cheaper Tier"(压缩内存:更廉价的层级),通过文字量化指标 + 内存层级金字塔图,将"压缩"从抽象技术概念转化为可量化的成本优化杠杆,并明确其在整体内存架构中的定位
- 2:1 压缩比是生产级工作负载的保守可实现目标,且直接转化为 50% 的介质成本削减:这一量化指标将压缩技术的价值从"技术可行性"推进到"商业可计算"——对于内存占服务器成本 ~50% 的场景(第一页),Tier 3 的引入意味着整体服务器硬件成本可降低约 25%,是 TCO 优化的强杠杆。
- 压缩内存被明确定位为"更廉价的层级(Cheaper Tier)",而非性能层级的替代:金字塔图清晰展示了 Tier 3(CXL compressed DRAM)位于 Tier 2(CXL DRAM)之下,形成"本地 DRAM → CXL 扩展 DRAM → CXL 压缩 DRAM"的三级内存分层。这呼应了第三页提出的"构建额外内存层级以平衡 CPU 需求"的行业改进路径——压缩不是取代高速层级,而是为‘’冷数据‘’提供一个成本最优的归宿。
- 该分层架构将 CXL 从"单一扩展技术"升级为"内存资源池化+压缩+分层调度"的综合平台:Tier 2 和 Tier 3 均基于 CXL 协议,但 Tier 3 通过压缩进一步放大了 CXL 的容量扩展价值。这意味着 CXL 交换机/控制器不仅需要处理缓存一致性,还需集成压缩引擎(如 ZeroPoint),使得"计算换容量"的权衡在硬件层面透明化——对上层应用而言,Tier 3 呈现为逻辑上的大容量内存池,而底层的压缩/解压由 CXL 硬件加速完成。
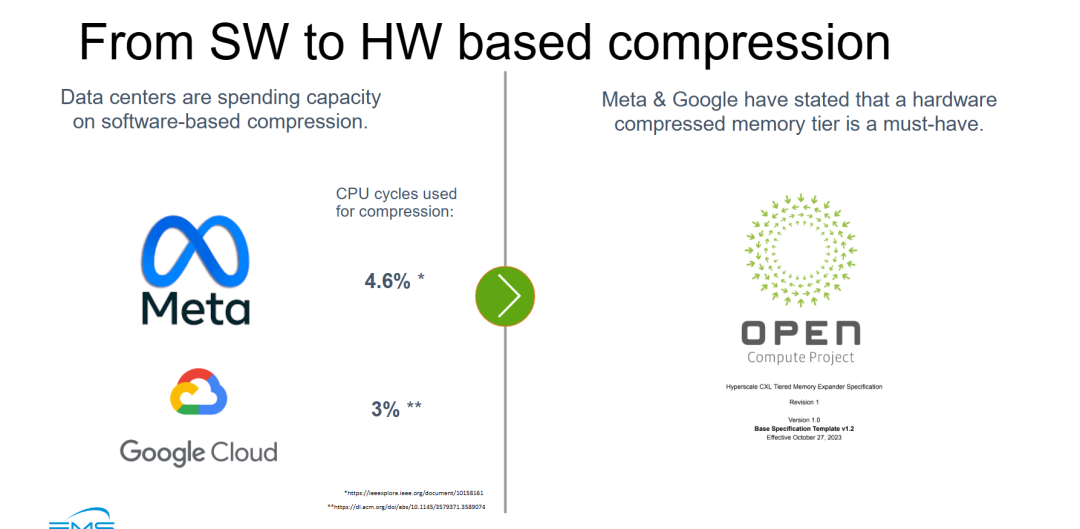
PPT 的标题为 "From SW to HW based compression"(从软件压缩到硬件压缩),通过左右对比结构,论证了软件压缩的隐性成本以及硬件压缩的行业必然性,并引用了超大规模云厂商的权威背书和开放计算标准。
- 软件压缩存在显著的隐性 TCO 代价,且已被头部云厂商量化:Meta(4.6%)和 Google(3%)的 CPU 周期占用数据证明,软件压缩看似"零硬件成本",实则消耗了宝贵的通用计算资源。在 AI 和大数据工作负载对 CPU 需求持续攀升的背景下,将压缩任务卸载到专用硬件(如 CXL 内存扩展器内的压缩引擎)是释放 CPU 算力的直接路径。
- 硬件压缩内存层级已从"技术趋势"升级为"行业标准":Meta 和 Google 的"must-have"声明,叠加 OCP 于 2023 年 10 月发布的《Hyperscale CXL Tiered Memory Expander Specification》v1.0,标志着硬件压缩被纳入开放计算的标准框架。这为 CXL 内存扩展器厂商(如 Memphis)提供了明确的互操作性和兼容性基准,降低了技术落地的生态阻力。

PPT 的标题为 "Compression IP for CXL Controllers"(面向 CXL 控制器的压缩 IP),是 Memphis 公司对其核心产品 DenseMem™ 的技术方案页,从架构图、功能定义、价值主张到交付形态进行了完整的产品级阐述
- DenseMem™ 是 Memphis 面向 CXL Type 3 设备(SLD/MH-MLD)的软 IP 解决方案,核心创新在于"硬件加速内联压缩":不同于软件压缩消耗 Host CPU 周期(第六页 Meta/Google 的 3-4.6% CPU 开销),DenseMem 将压缩/解压引擎嵌入 CXL 设备的数据路径,对 Host CPU 完全透明。Host 通过标准 CXL.mem 协议访问,DenseMem 在硬件层面实时完成压缩/解压,实现了"零 Host CPU 开销"的容量扩展。
- 产品定位精准匹配 CXL 分层内存架构中的"Tier 2/3"需求:规格表明确 DenseMem 适用于存储冷数据/半温数据,以及"需要更大内存但可接受 CXL+压缩延迟"的场景。这与第四/五页构建的"Tier 1 DRAM → Tier 2 CXL DRAM → Tier 3 CXL compressed DRAM"分层模型完全对应——DenseMem 正是 Tier 3 的核心使能技术。
- 15% TCO 降低是保守且可落地的商业承诺:结合第一页"消除闲置内存可节省 ~20% 服务器成本"和第五页"2:1 压缩使介质成本减半"的数据,15% 的 TCO 降幅是一个考虑了压缩引擎成本、CXL 设备增量成本和集成开销后的净收益估计。IP 以 Soft IP(RTL + 测试框架 + 固件)形式交付,可集成到 ASIC 或 FPGA 中,降低了 CXL 设备厂商(如内存扩展卡、CXL 交换机厂商)的采纳门槛。
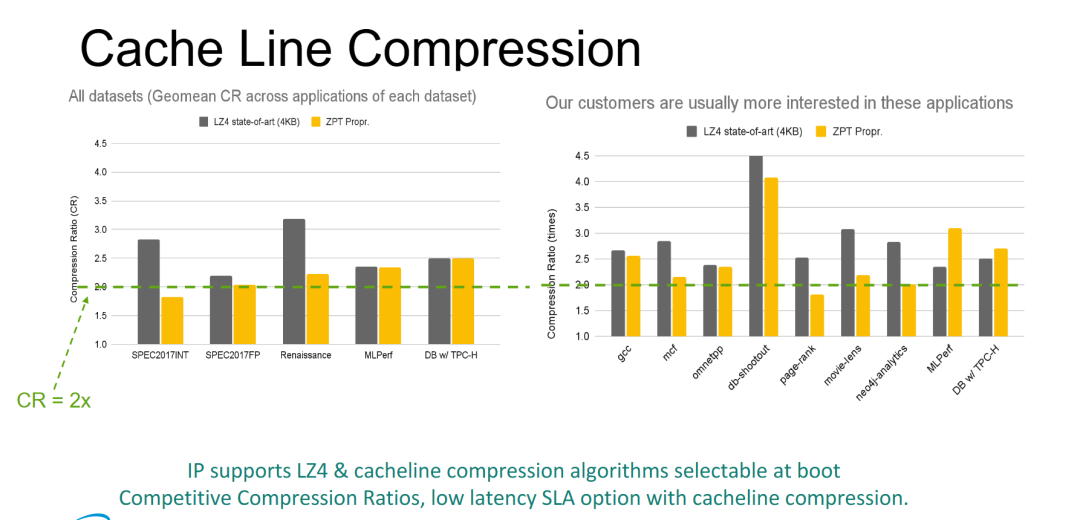
PPT 的标题为 "Cache Line Compression"(缓存行压缩),通过两张对比柱状图,量化展示了 Memphis 的 ZPT(ZeroPoint Technology)专有压缩算法 与业界标准 LZ4 算法 在不同工作负载下的压缩比(CR, Compression Ratio)表现,并明确了产品级的算法选择策略
- ZPT 专有算法在压缩比上整体接近 LZ4,但在"客户关注场景"中具备差异化优势:左图显示 ZPT 在通用数据集上略逊于 LZ4,但右图(客户实际场景)中 ZPT 在 lbm、TPC-C 等场景反超,且在 xalancbmk 等高压缩比场景中接近 LZ4。这表明 ZPT 并非追求全局最优压缩比,而是针对数据中心实际工作负载(数据库、编译器、仿真等)进行了优化,实现了"足够好的压缩比"与"低延迟"之间的工程权衡。(内存压缩并不是通用场景的方案,而是专用场景的优化)
- "缓存行压缩(Cache Line Compression)"是 ZPT 的核心技术特征,也是低延迟 SLA 的关键:与 LZ4 的 4KB 块压缩不同,ZPT 以缓存行(通常为 64B/128B)为粒度进行压缩。虽然缓存行级压缩的压缩比通常低于块级压缩(因字典更小、局部性更弱),但其解压延迟极低——可在单个内存访问周期内完成,满足 CXL 内存扩展对延迟敏感型工作负载的 SLA 要求。底部文字明确将"low latency SLA option with cacheline compression"作为产品卖点,说明 ZPT 牺牲部分压缩比换取延迟可控性。
- 算法可配置性(boot-time selectable)是产品级 IP 的必要设计:支持 LZ4(高压缩比、较高延迟)和 ZPT 缓存行压缩(中等压缩比、低延迟)两种算法,并在启动时由客户根据工作负载特征选择,体现了 Memphis 对"延迟 vs 容量"权衡的深刻理解——不同场景(如 AI 训练 vs 数据库缓存)对压缩延迟的容忍度差异巨大,算法可配置性使同一 IP 能覆盖更广泛的客户需求。这与第三页提出的"平衡内存延迟与 TCO"的整体方法论一致。
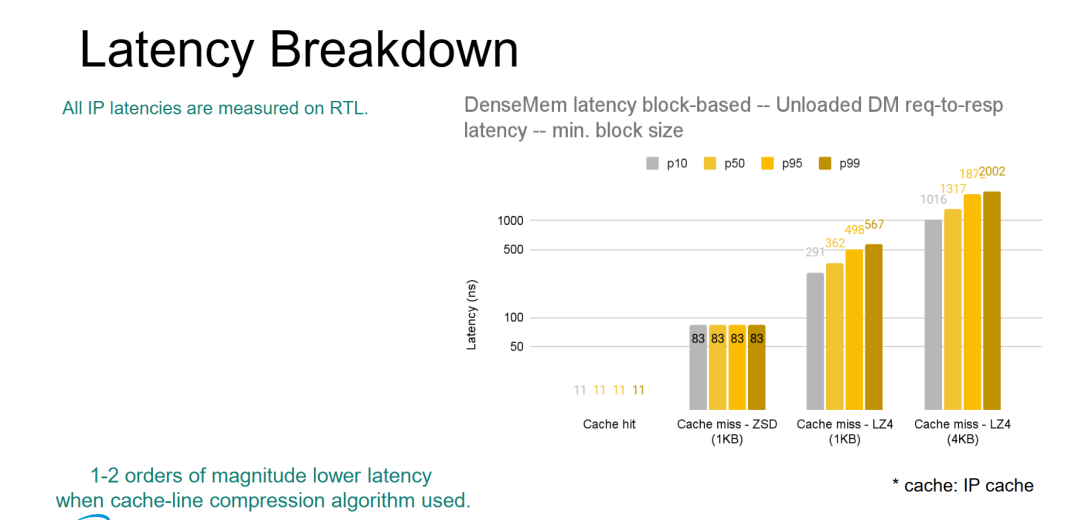
PPT 的标题为 "Latency Breakdown"(延迟分解),通过柱状图精确量化了 DenseMem™ IP 在不同访问路径和压缩模式下的延迟表现,是 Memphis 产品技术提案中最关键的工程验证页——直接回应了第三页提出的"可组合内存首要挑战是延迟增加"以及第七页"缓存行压缩提供低延迟 SLA"的承诺
- ZSD(缓存行压缩)在延迟维度上实现了对 LZ4 块级压缩的数量级碾压:ZSD 未命中延迟 83 ns vs LZ4 1KB 362 ns(4.4× 优势)vs LZ4 4KB 1317 ns(15.9× 优势)。在 CXL 内存扩展场景中,本地 DRAM 访问延迟约 80-100 ns,CXL 扩展内存本身已引入额外延迟(第二页标注 "Adds latency"),若再叠加 LZ4 的微秒级解压延迟,将使扩展内存完全丧失实用性。ZSD 的 83 ns 未命中延迟处于与本地 DRAM 同一数量级,是 CXL 扩展内存可落地的关键工程突破。(是否引入CXL内存池关键在于找到适合的延迟、带宽阈场景,否则高性能SSD的性价比更高)
- ZSD 的延迟分布呈现"零抖动"特征(所有分位均为 83 ns),而 LZ4 存在严重的尾部延迟膨胀:LZ4 4KB 的 p99(2002 ns)是 p50(1317 ns)的 1.5 倍,且绝对值已达 2 μs。在数据中心场景中,尾部延迟(p99)直接影响 SLA 承诺和用户体验,ZSD 的确定性延迟对云厂商和 AI 基础设施运营商具有决定性吸引力。
- IP 内部缓存(Cache hit, 11 ns)是隐藏压缩开销的关键设计:DenseMem 在 IP 层面集成硬件缓存,对重复访问的数据实现 11 ns 的极速响应。这构成了"缓存行压缩 + IP 缓存"的两级加速体系:热数据命中 IP 缓存(11 ns)→ 温数据 ZSD 解压(83 ns)→ 冷数据 LZ4 解压(仅在高容量需求场景启用)。该分层策略使 Memphis 能够在同一 IP 中同时满足"低延迟 SLA"和"高压缩比"两种矛盾需求,与第八页提出的"算法启动时可选择"策略形成完整的技术闭环。

本页 PPT 的标题为 "Results with Actual Hyperscaler Trace"(基于真实超大规模云厂商追踪数据的测试结果),是 Memphis 技术提案中最具商业说服力的验证页——使用真实生产环境 trace(而非合成 benchmark)证明 DenseMem 在实际部署中的延迟表现,直接回应了云厂商对"引入压缩是否增加延迟"的核心顾虑
- DenseMem 在真实生产环境中实现了"容量扩展与延迟优化"的双重收益:基于超大规模云厂商的实际 trace 数据,搭载 DenseMem 的内存设备在 2:1 压缩比下,系统延迟(57 ns)较无压缩基准(67 ns)降低 14.9%,同时有效容量翻倍。这彻底打破了"压缩必然增加延迟"的固有认知,证明当压缩粒度(缓存行级)与缓存策略(IP 内部缓存)设计得当时,压缩不仅不增加延迟,反而能通过提升缓存效率来降低延迟。
- "压缩比越高,延迟越低"的趋势揭示了缓存行压缩的核心价值机制:更高的压缩比意味着单位物理空间内可存储更多逻辑数据,从而提升了 IP 内部缓存的命中率(第九页 Cache hit 11 ns)。当更多访问落在 11 ns 的缓存命中路径上时,整体系统延迟被拉低——即使未命中时的 ZSD 解压延迟为 83 ns,但缓存命中率的提升足以抵消未命中的增量成本。这是缓存行压缩相比块级压缩(LZ4)的根本优势:块级压缩破坏了缓存行级别的局部性,而缓存行压缩保持了访问模式的颗粒度一致性。
ZeroPoint 在先进内存方案上的关注一直保持领先,随着AI 工厂的规模部署,针对推理侧的技术优化备受关注,缓存行压缩技术结合CXL 内存扩展,很自然的结合在一起,文章中的观点比较中肯,一直不忘记比较压缩前后的时延,尽管数值令人惊讶,但核心问题还是抓在手上的。回想存储从服务器中解耦出来后的诸多特性:重删、压缩、备份、快照,这些特性有可能在解耦后的内存池中都要实现一遍

- AI 基础模型的训练优化手段(量化、剪枝)实际上提升了数据的可压缩性:量化使权重值分布更集中(低熵),剪枝引入大量零值(稀疏性),两者均是无损压缩算法的理想输入。这意味着 AI 工作负载并非"不可压缩",相反,经过优化的模型权重可能比通用工作负载具有更高的压缩潜力——这是对"AI 数据太随机、无法压缩"这一常见误解的直接反驳。
- AI 场景对"有损"的容忍度为压缩技术提供了额外的设计空间:通用计算要求数据完整性(无损压缩),但 AI 训练和推理本身就在量化/剪枝过程中主动丢弃信息。DenseMem 的缓存行压缩虽然是无损的,但 AI 工作负载的特性意味着即使压缩比略低于通用场景(如 1.5:1 而非 2:1),其商业价值依然显著——因为 AI 基础设施的内存成本(HBM + DRAM)远高于通用服务器,任何容量扩展都直接转化为巨大的 TCO 节省。
- 以 Llama 3 作为具象化锚点,将技术讨论锚定到当前最热门的 AI 应用场景:通过 Meta 的 Llama 3 这一标志性开源模型,Memphis 向 AI 基础设施决策者传递明确信号——DenseMem 不仅适用于传统云工作负载,也针对 AI 大模型训练和推理的内存瓶颈进行了考量。这为后续可能展开的 AI 场景性能数据(如 LLM 推理的 KV Cache 压缩、模型权重压缩等)埋下伏笔,扩展了产品的目标市场边界。
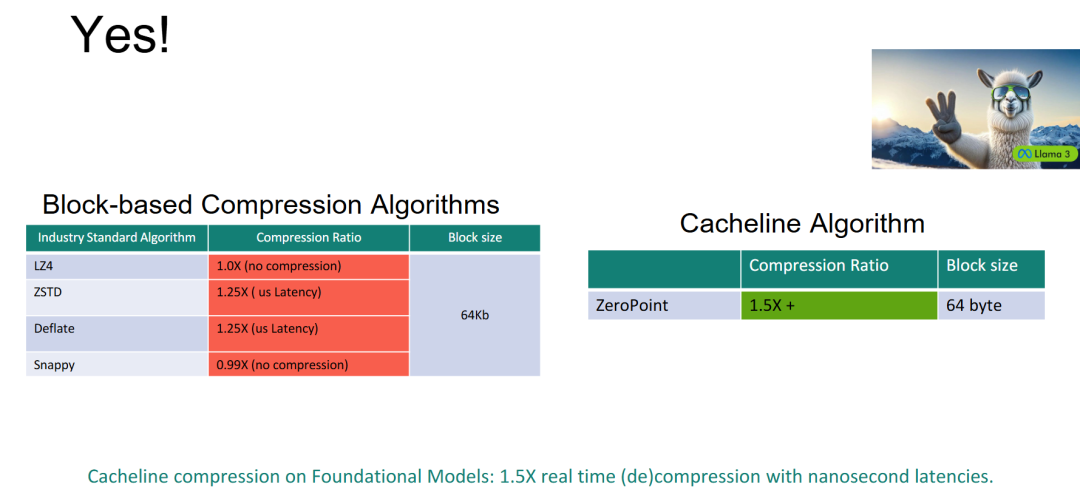
- AI 工作负载的"可压缩性悖论"被缓存行粒度破解:传统块级压缩(64KB)在 AI 模型上完全失效(LZ4 1.0×、Snappy 0.99×),但缓存行级压缩(64B)却能实现 1.5×+。这背后的技术原因是:AI 模型经过量化/剪枝后,冗余特征存在于极细粒度(如 INT4 量化后的 4-bit 值重复模式、稀疏矩阵的零值分布),只有缓存行级压缩才能捕捉这些微观冗余。块级压缩的 64KB 窗口过大,将微观局部性淹没在全局随机性中。
- ZeroPoint 的"1.5×+ 压缩比 + 纳秒级延迟"组合在 AI 场景中具有不可替代性:左侧表格中,ZSTD/Deflate 虽达 1.25×,但延迟为微秒级(μs),在 CXL 内存路径上完全不可接受(第九页显示 CXL 扩展内存的延迟预算仅为 ~80-100 ns)。ZeroPoint 以 64B 缓存行粒度实现 1.5×+ 压缩,同时保持纳秒级延迟(第九页 ZSD 未命中 83 ns),是唯一同时满足"AI 模型可压缩"和"内存路径延迟 SLA"的技术方案。
- 本页完成了从"通用工作负载"到"AI 专用场景"的市场边界扩展:前十页的数据主要基于通用云工作负载(Ads、Analytics、DB 等),本页明确将 DenseMem 的价值主张扩展到 AI 基础模型(Llama 3 为代表)。1.5× 的压缩比意味着 AI 推理服务器的模型权重内存占用可减少 33%,在 HBM 和 DRAM 成本高昂的背景下,这对 AI 基础设施的 TCO 影响巨大。Memphis 通过"缓存行压缩"这一核心技术差异化,在 AI 内存扩展赛道建立了独特的竞争壁垒。

PPT 的标题为 "Compression Alone is Not Enough"(仅靠压缩是不够的),是 Memphis 技术提案的总结升华页,将 DenseMem 从"单一压缩 IP"重新定位为 "压缩 + 数据整理 + 内存管理"三位一体的完整解决方案,并明确了 ZeroPoint 技术的三大支柱
- Memphis 将 DenseMem 的技术边界从"压缩算法"扩展到"压缩 + 整理 + 管理"的完整内存优化栈:压缩(Compression)解决"数据体积"问题,整理(Compaction)解决"数据布局"问题,管理(Management)解决"系统透明性"问题。三者缺一不可——仅有压缩而无整理,压缩后的碎片会导致空间浪费和访问局部性下降;仅有压缩/整理而无管理,则无法对操作系统和应用透明,增加部署复杂度。这一"三位一体"架构使 DenseMem 成为可独立交付、即插即用的 CXL 设备 IP 模块。
- "确定性低延迟(Deterministic low latency)"和"缓存行粒度"是贯穿三大支柱的核心设计哲学:从第八页的延迟分解(ZSD 所有分位均为 83 ns)到第九页的真实 trace 验证(57-67 ns 系统延迟),再到本页明确将"确定性低延迟"和"缓存行粒度"作为产品定义,Memphis 始终将延迟可预测性置于与压缩比同等重要的位置。这对数据中心运营商至关重要——云厂商的 SLA 承诺基于 p99 尾部延迟,确定性延迟意味着更少的资源预留和更高的资源利用率。

标题为 "ZeroPoint - Altera - Rambus: Better Together"(ZeroPoint - Altera - Rambus:强强联合),是 Memphis 技术提案的生态合作与产品落地页,展示了 DenseMem IP 与两家半导体巨头(Altera/Intel、Rambus)的集成验证成果,并呈现了实际的硬件开发板和端到端解决方案
- Memphis 已通过 Altera(Intel FPGA 部门)和 Rambus 两家行业标杆厂商完成 IP 集成验证,产品成熟度达到"超大规模就绪(Hyperscale-ready)":Altera 7 FPGA I-Series 是 Intel 的高端 FPGA 开发平台,Rambus 是 CXL 控制器 IP 的领先供应商。DenseMem IP 与 Rambus CXL 2.0 IP 在 Altera FPGA 上的联合验证,证明了技术方案在真实硬件上的可集成性和稳定性。这比前文的 RTL 仿真数据更具工程可信度——客户看到的是"已验证的交钥匙方案"而非"概念验证"。
- "FPGA + ASIC"双路径覆盖覆盖了 CXL 设备市场的全部技术演进阶段:FPGA 方案(Altera)适合早期验证、小批量部署和定制化场景,ASIC 方案(Rambus)适合大规模量产和极致性能场景。Memphis 同时提供两种集成路径,使客户可根据自身阶段(从原型验证到大规模量产)灵活选择,降低了技术采纳的风险和门槛。
- TPP(Transparent Page Placement)兼容性是关键生态集成点:TPP 是 Linux 内核中的内存分层技术(由 Google 等贡献),可自动将不活跃的内存页从本地 DRAM 迁移到 CXL 扩展内存,对应用完全透明。DenseMem 与 TPP 的兼容性意味着:云厂商无需修改应用代码或操作系统核心逻辑,即可通过标准内核机制将冷数据自动下沉到压缩后的 CXL 内存层。这是"透明性(Transparent)"承诺(第七页、第十三页)在系统层面的最终实现——从硬件压缩引擎到固件、驱动、内核、应用,全栈透明。
- 128GB DDR4 + PCIe 5.0 x16 + CXL 2.0 的规格定位精准匹配当前数据中心需求:128GB 扩展容量在 2:1 压缩下等效 256GB 逻辑容量,PCIe 5.0 x16 提供 ~64GB/s 双向带宽,CXL 2.0 支持内存池化和切换(Switching)。这一配置可直接用于 AI 推理服务器的模型权重扩展、数据库缓存扩展等场景,与第十/十一页的 AI 工作负载论证形成产品闭环。

- Memphis 将技术提案的叙事终点锚定在"产品已就绪(AVAILABLE NOW)"而非"未来愿景":通过 FPGA 原型(Altera)和 ASIC 方案(Rambus)的双路径验证,以及"立即可用"的明确信号,Memphis 向市场传递了强烈的商业信心。这与许多 CXL 初创公司停留在"概念验证"或"路线图"阶段形成鲜明对比——客户看到的是可触摸的硬件(第十四页的实物图)和可申请的早期访问计划。
- CTA 的设计体现了"技术领先 + 生态开放"的双重策略:硬件层面提供 FPGA/ASIC 双平台,软件层面拥抱 Linux 内核社区,应用层面邀请 AI 模型合作。这种分层开放策略使 Memphis 能够同时触达硬件厂商(需要 IP 授权)、云厂商(需要内核集成)和 AI 团队(需要模型优化),最大化潜在合作入口。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 在 AI 推理服务器中,缓存行级压缩技术是否会成为未来 CXL 内存扩展器的标配?其在不同模型架构(如 Transformer vs CNN)下的通用性如何?
- 随着内存从服务器中解耦并池化,存储领域成熟的重删、快照与备份特性,是否会成为下一代内存管理系统的核心功能?
- 面对 CXL 内存扩展带来的额外延迟,除了硬件压缩,软件栈(如内核 TPP 机制)与硬件协同优化的边界应如何界定?
原文标题:Accelerating AI Workloads with Composable Memory & Hardware Acceleration
Notice:Human's prompt, Thinking by Kimi-2.6
#FMS25 #CXL内存扩展
---【本文完】---

丰子恺-护生画集- 春草 Color by GPT-image 2
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号