vLLM 0.22大版本升级,DeepSeek V4 生产级优化,KV Cache 极致压缩

vLLM 0.22大版本升级,DeepSeek V4 生产级优化,KV Cache 极致压缩

Ai学习的老章
发布于 2026-06-01 16:42:40
发布于 2026-06-01 16:42:40
大家好,我是 vLLM 区博主 Ai 学习的老章
vLLM 0.22 稳定版来了,大量更新、优化
我认真看了 Release Notes 和相关技术博客,提炼出最值得关注的六大变化,帮你快速判断——升还是不升,怎么升
先看全景图,这次升级的六大核心方向:

vLLM 0.22 六大核心升级全景图
vLLM 0.22 六大核心升级全景图
DeepSeek V4:从"能跑"到"能打"
如果你关注大模型推理,DeepSeek V4 一定在你的雷达上——1.6T 总参数、49B 激活参数的 MoE 架构,支持 100 万 token 上下文
但在 v0.20 的时候,vLLM 对 V4 的支持还停留在"能跑起来"的阶段。v0.22 做的事情,是让它真正可以上生产
架构重构:模型代码从散落各处重组为独立的 vllm/models/deepseek_v4/ 包。这不只是代码整洁度的问题——独立包意味着 V4 的推理路径拥有完全专属的优化管线,不再被通用模型基类的抽象开销拖后腿
内核级加速:一口气落地了 6 类融合内核
- NVFP4 Fused MoE:利用 FP4 在 Blackwell 上实现专家混合计算融合
- MegaMoE 内核:输入预处理迁移到 GPU 侧,减少 host-device 数据搬运
- Sparse MLA + 压缩器重构:CSA/HCA 混合注意力的稀疏路径优化
- Q-norm / Indexer 融合内核:量化归一化与索引查找一步完成
- Fused Q norm + KV RoPE + K insert:静态 warpID 派发,零跨 warp 通信,实测 10-20x 加速
- Inverse RoPE + fp8 量化融合:消除背靠背 HBM 读写,2-3x 加速
CUDA Graph 全量支持:Full + Piecewise 两种模式均已支持,decode 路径的 kernel launch 开销基本消除
MTP 投机解码:Multi-Token Prediction 首次在 V4 上落地,进一步提升生成速度
KV Cache 压缩有多猛?
V4 的注意力机制引入了 c4a(~4x 压缩)和 c128a(~128x 压缩)两级压缩。在 bf16 下,100 万 token 上下文的 KV Cache 只需要 9.62 GiB——同等规模的 V3.2 需要 83.9 GiB,直接 8.7x 压缩
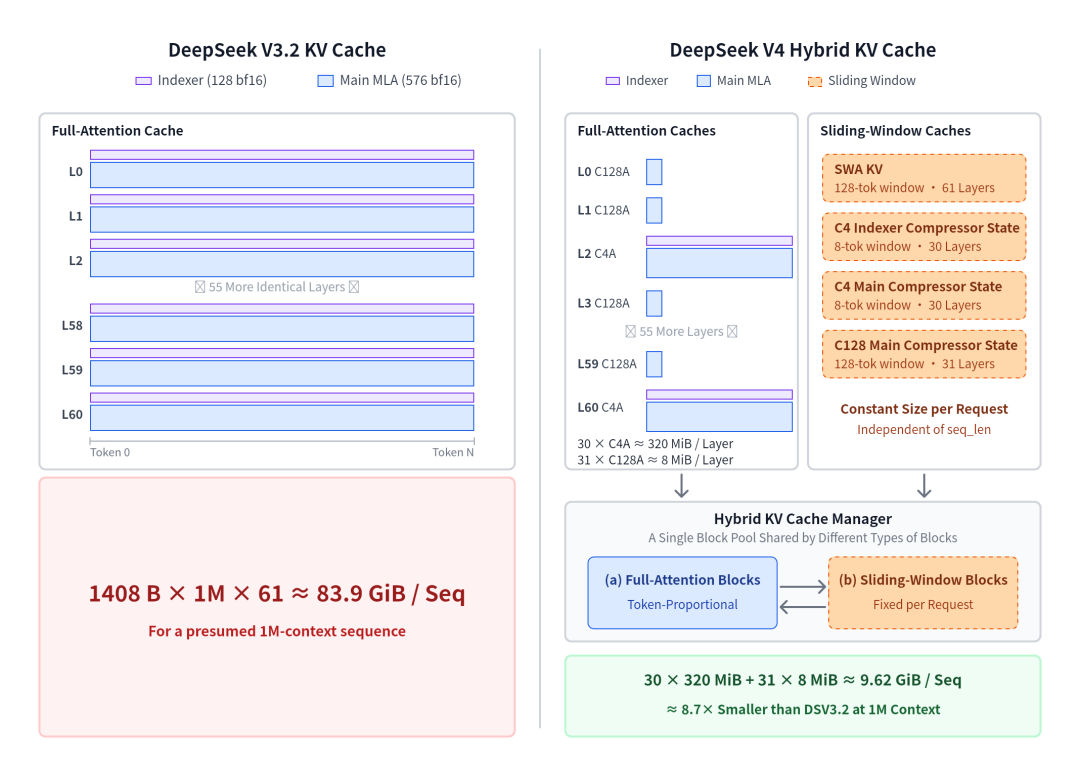
DeepSeek V4 vs V3.2 KV Cache 对比
DeepSeek V4 vs V3.2 KV Cache 对比
再加上 FP4 indexer + fp8 attention cache,还能再压一倍
如果你正在评估 DeepSeek V4-Pro 的生产部署,v0.22 是第一个可以认真考虑的 vLLM 版本
Batch Invariance:28.9% 延迟改善,精度和速度可以兼得了
Batch Invariance(批次不变性)保证相同的 prompt 在不同 batch 组合下产生完全一致的输出。这对评测、合规审计、RL 训练的可复现性至关重要
过去开启 Batch Invariance 的代价是明显的性能倒退——确定性内核 + 禁用 all-reduce 优化,换来的是"正确但慢"
v0.22 在这个方向实现了质变:
- Cutlass FP8 路径:端到端延迟改善 28.9%
- CutlassFP8 Padding 预处理:首 Token 延迟(TTFT)改善 13.5%
- SM80 编译模式支持:A100 用户也能享受 Batch Invariance + 编译优化
- NVFP4 Cutlass Linear:FP4 量化路径同样获得 Batch Invariance 支持
- TRITON_MLA decode 全量 CUDA Graph 捕获
这意味着 Batch Invariance 不再是"正确但慢"的选项,而是可以考虑默认开启的特性
开启方式也很简单:
export VLLM_BATCH_INVARIANT=1
vllm serve meta-llama/Llama-3.1-8B-Instruct
目前已验证的模型包括 DeepSeek V3/R1、Qwen3 全系、Qwen2.5、Llama 3 等主流模型族
Rust 前端:Python 推理热路径的终结号角
这可能是 v0.22 最具前瞻性的变化
vLLM 原有的 Python 前端在高并发场景下是已知的性能瓶颈——请求调度、Token 分发、数据并行管理都受限于 GIL 和异步调度开销。v0.22 引入了实验性 Rust 前端,直指这个问题:
- 代码入树:Rust 实现正式合入 vLLM 主仓库,不再是外部实验项目
- DP Supervisor:数据并行场景的 Supervisor 进程用 Rust 实现,负责跨 Worker 请求分发
- 构建集成:通过
setuptools-rust集成到 Python 构建流程,对用户透明
联系 vLLM 此前已有的 Rust Router(高性能负载均衡器),一条清晰的趋势已经浮现:推理热路径从 Python 向 Rust 迁移
目前还是实验性质,但方向很明确。对于重度使用 vLLM 的团队,可以开始关注这个变化了
多层级 KV Cache 卸载:显存不够?磁盘来凑
KV Cache 管理是长上下文推理的核心瓶颈。过去的做法是 GPU 满了就 preempt 请求、丢弃 KV Cache,下次重新计算——代价极高
v0.22 构建了完整的多层级卸载框架:
GPU HBM → CPU DRAM → 文件系统 / 磁盘
核心能力:
- 多层级框架:统一的卸载/加载接口,支持任意层级组合
- Python 文件系统二级存储:通过标准文件系统 API 将 KV Block 持久化到磁盘
- DeepSeek V4 适配:专门适配了 DSv4 的混合注意力 KV 布局
- Mooncake 磁盘卸载:MooncakeStoreConnector 支持直接写盘
- Per-Request 追踪:每请求粒度的 KV 块生命周期管理
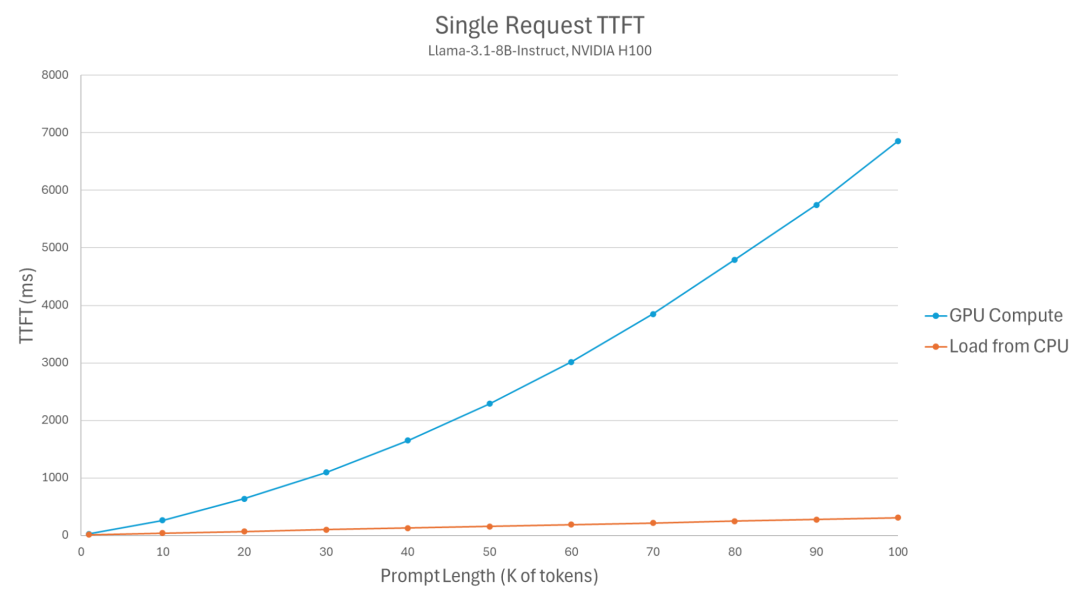
KV Cache 卸载 TTFT 性能对比
KV Cache 卸载 TTFT 性能对比
根据 vLLM 团队的测试数据,从 CPU 加载 KV Cache 可以将 TTFT 降低 2-22x(取决于 prompt 长度),并发吞吐量提升最高达 9x
实际意义:一台 8xH100(640GB HBM)的机器,通过 CPU 内存 + NVMe SSD 卸载,能服务的有效上下文长度可以翻倍甚至更多。代价是延迟增加,但对于 prefill-heavy 的批处理场景,这个 trade-off 非常划算
硬件生态:不绑定任何供应商
v0.22 在硬件覆盖上的野心很明显:
NVIDIA Blackwell(SM12x):
- FlashInfer b12x MoE + FP4 GEMM
- Per-tensor FP8 CUTLASS(SM121)
head_dim=512支持——大 head 维度模型不再需要回退到低效路径- GDN Prefill Kernel(SM100/SM120)
AMD ROCm:
- DSV4 全功能 + 精度修复 + Tilelang MHC
- Flash Sparse MLA Triton 内核
- Gluon Paged MQA(gfx950/MI355X)
- RMSNorm + Quant 融合(gfx950)
- XGMI 高速互连后端
CPU / RISC-V(最意外的更新):
- RISC-V Vector Extension 优化的 Attention 内核(VLEN=256)——是的,RISC-V 也能跑 LLM 推理了
- AMX CPU 上的 Fused GDN
- MXFP4 W4A16 MoE——CPU 上也能跑 MoE 量化模型
- 实验性 Triton + MRv2 CPU 支持
Intel XPU:
- GPTQ INT4、MXFP8 MoE、FP8 Block-Scaled 量化
- 多种稀疏注意力内核
- MoE TopK 路由 + MXFP4 回退
一句话:vLLM 正在从"NVIDIA 推理框架"变成"全硬件推理基础设施"
Model Runner V2:温水煮青蛙式接管
MRv2 是 vLLM 的下一代推理运行时,v0.22 的接管策略很聪明——不搞大爆炸迁移,逐模型验证、逐步扩大默认启用范围:
- Oracle 机制:系统自动判断当前模型是否适合 MRv2,Qwen3 Dense 已默认走 MRv2
- 自动回退:检测到 KV Connector 时自动降级到 MRv1,零风险
- Sleep Mode:推理空闲时释放 GPU 显存,需要时重新加载权重——对于多模型共享 GPU 的场景非常实用
- 共享 KV Cache 层:多模型场景下复用 KV Cache 内存
其他值得关注的变化
量化生态——MXFP4 和 NVFP4 全面铺开,quantization_config 重构为 QuantKey + 激活覆盖模式,为"不同层使用不同量化策略"铺平道路
解聚合推理——NIXL 方案持续完善,GDN 支持 PD 解聚、多节点 TP>8 修复
LoRA——One-Shot Triton 内核加速 MoE LoRA,同时支持 2D 和 3D MoE LoRA 适配器
API——thinking_token_budget 支持,reasoning_effort 映射为 enable_thinking,与 OpenAI API 语义对齐
Breaking Changes——旧版 get_tokenizer 路径已移除,MLA prefill 参数已废弃,升级前务必检查
升级建议
场景 | 建议 |
|---|---|
DeepSeek V4 用户 | 强烈升级,第一个生产就绪版本 |
需要 Batch Invariance | 强烈升级,28.9% 延迟改善消除了精度-速度权衡 |
Blackwell 用户 | 建议升级,SM12x 专属优化首次大规模落地 |
AMD ROCm 用户 | 建议升级,ROCm 平等性有实质性进展 |
长上下文推理 | 建议评估,多层级 KV 卸载显著扩展有效上下文 |
稳定运行中 | 谨慎升级,注意 Breaking Changes |
总结
vLLM 0.22 的关键词是成熟化
DeepSeek V4 从实验走向生产,Batch Invariance 从"慢"变"快",KV 卸载从单层走向多层,Rust 前端从概念走向代码入树
横向上,从 NVIDIA 独占走向 AMD/Intel/CPU/RISC-V 全覆盖;纵向上,从纯推理引擎走向包含 Rust Router、DP Supervisor、解聚合推理在内的完整推理基础设施
对于做推理基础设施的团队来说,vLLM 0.22 不是一个可以跳过的版本
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号