Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据

Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据

拓端
发布于 2026-06-01 18:59:13
发布于 2026-06-01 18:59:13
全文链接: https://tecdat.cn/?p=45976 原文出处: 拓端数据部落公众号 封面:
关于分析师
在此对 Ming Li 对本文所作的贡献表示诚挚感谢,他完成了数据科学与大数据技术专业的学士学位,专注机器学习与因果推断领域。擅长Python、统计建模、数据分析。Ming Li 曾在零售与电商领域参与多个数据咨询项目,专注于为快消品与平台企业提供定价策略优化、用户行为归因及个性化推荐系统的模型构建与业务落地建议。
如何在海量商品仅有稀疏销售记录时,准确估计其价格弹性并支撑个性化定价?传统方法面临数据不足与估计不稳定的双重困境(点击文末“阅读原文”获取完整智能体、代码、数据、文档)。
摘要
本文基于层次贝叶斯模型,通过对话式AI智能体的交互方式,完整展示一套从数据生成到模型推断的解决方案。核心探讨以下问题:第一,如何利用全局-品类-单品三层先验结构实现不同商品间统计强度的自动共享;第二,如何使用NumPyro的概率编程与随机变分推断高效估计大规模弹性系数;第三,模型对单品、品类、全局弹性的恢复精度如何,及估计不确定性存在哪些局限;第四,如何将模型输出的后验参数转化为可执行的差异化定价依据。本文附赠完整对话提示词、核心代码模块及交互式配置面板说明。
Abstract
How can we accurately estimate price elasticity for numerous products with sparse sales data to support personalized pricing? Traditional methods struggle with insufficient data and unstable estimates. This paper, based on Hierarchical Bayesian models, demonstrates a complete solution from data generation to model inference through conversational AI agent interaction. It addresses four core questions: First, how does the global-category-product three-level prior structure achieve automatic pooling of statistical strength across products? Second, how can NumPyro probabilistic programming and Stochastic Variational Inference efficiently estimate large-scale elasticity coefficients? Third, what is the recovery accuracy for product, category, and global elasticities, and what are the limitations in uncertainty quantification? Fourth, how can the posterior parameters be translated into actionable differentiated pricing decisions? Complete conversational prompts, core code modules, and interactive configuration panel instructions are included.
引言
在数据驱动的商业决策领域,精准量化用户对价格、推荐等信号的响应是构建智能系统的基石。作为一名长期从事机器学习与算法落地的从业者,我深知一个普遍的痛点:当分析单元数量庞大而个体观测稀少时,传统统计方法往往陷入“统一建模有偏误,独立建模方差大”的困境。这本质上是一个小样本学习问题在商业场景中的映射。
客户拥有数万种商品,但大量长尾单品缺乏足够的价格变动数据,难以用传统面板回归得到可靠的弹性估计。我们为其设计了一套基于层次贝叶斯模型的解决方案,并进一步封装为对话式AI智能体,使业务人员无需编写代码即可完成建模。
注释: 传统的做法是“分堆建模”——要么把所有商品混在一起算一个平均弹性,要么每个商品各算各的。前者忽略了个体差异,后者对于卖得少、价格波动小的商品根本算不准。层次贝叶斯的巧妙之处在于,它让数据说话:卖得好的商品,它的弹性主要靠自己的数据决定;卖得少的商品,它会自动“借鉴”同品类其他商品的弹性,往品类均值靠拢。这种自适应调节就像一个经验丰富的定价经理,既尊重每个商品的个性,又不会让缺乏信息的新品“裸奔”。
阅读原文进群获取本文完整代码、数据、AI智能体及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
文章脉络流程图
传统方法的局限
设想一家商超需要为所有商品制定最优价格以实现营收最大化。第一步便是估计每种商品的需求价格弹性,定义如下:
β = ∂log(Units) / ∂log(Price)
在忽略混杂因素的假设下,常用的方法是带固定效应的面板回归:
log(Units_it) = β * log(Price_it) + γ_c(i),t + δ_i + ε_it
其中,γ_c(i),t 是品类-时间固定效应,δ_i 是商品个体固定效应。这个“汇总”模型只能得到所有商品的平均弹性β,据此只能制定“一刀切”的平均价格。
若商品有天然分组(如产品品类),可进一步通过分品类独立回归或加入交互项来得到各品类的平均弹性,实现品类级别的差异化定价。理论上,数据充裕时甚至能为每个单品分别建模。
然而实际数据往往充满挑战:部分商品价格长期不变、销售历史短暂、品类间样本量极不均衡。在这种数据稀疏的情况下,分品回归会导致参数标准误巨大,弹性系数无法有效识别。层次贝叶斯模型正是为解决此问题而生——它让我们能通过一次“汇总式”的建模,直接得到产品级别的可靠弹性估计。
层次贝叶斯模型的核心思想
层次贝叶斯模型承认数据中天然存在的层级结构,并让信息在各层级间流动。它既不假设所有观测完全独立(“各自为战”),也不强求它们遵循完全相同的模式(“一刀切”),而是在两者间找到了一个基于数据的平衡点。这就像一台无级变速箱,能根据引擎转速和负载平滑调整输出扭矩(行业术语:自适应正则化强度)。
模型的基本层级结构包含:
- 全局参数:适用于所有数据的共同模式。
- 组级参数:适用于组内观测的共享模式。
- 个体级参数:适用于每个独立个体的特定模式。
“贝叶斯”体现在参数的更新方式上:从先验分布(初始信念)出发,根据观测数据更新得到后验分布。实践中,全局估计影响品类估计,品类估计又指导单品估计。数据量大的个体,其估计值允许偏离组内均值更远;数据量小的个体,其估计值则会被“拉向”更稳定的组内均值。这种借力程度由数据自动决定。
以下用价格弹性的例子来形式化。我们想要得到单品弹性 β_i,构建如下模型:
log(Units_it) = β_i * log(Price_it) + γ_c(i),t + δ_i + ε_it
参数间的层级结构关系为:
- β_i ~ Normal(β_c(i), σ_i):单品弹性服从以品类弹性为中心的正态分布。
- β_c(i) ~ Normal(β_g, σ_c(i)):品类弹性服从以全局弹性为中心的正态分布。
- β_g ~ Normal(μ, σ):全局弹性也有其先验分布。
本文设定先验信念为:μ=−2,σ=1,σ_c(i)=1,σ_i=1。这意味着全局弹性约为-2,95%的弹性值落在-4到0之间,各层级的标准差均为1。若一个产品价格变动数据稀少,其弹性会被自动拉向品类均值β_c(i);同样,产品稀少的品类会受到全局弹性更强的影响。
模型实现:与AI智能体对话生成代码
本章节展示如何通过自然语言与AI智能体交互,依次完成模型定义、参数估计和结果提取。
数据为大型商超的销售场景,包含20,000个产品,横跨10个品类,时间跨度为156周(约3年)。
筛选后数据摘要:
- 原始产品数:20,000
- 保留产品数:11,798
- 过滤比例:41.0%
- 全局真实弹性:-1.598
- 品类弹性范围:-1.681 至 -1.482
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
定义层次贝叶斯模型
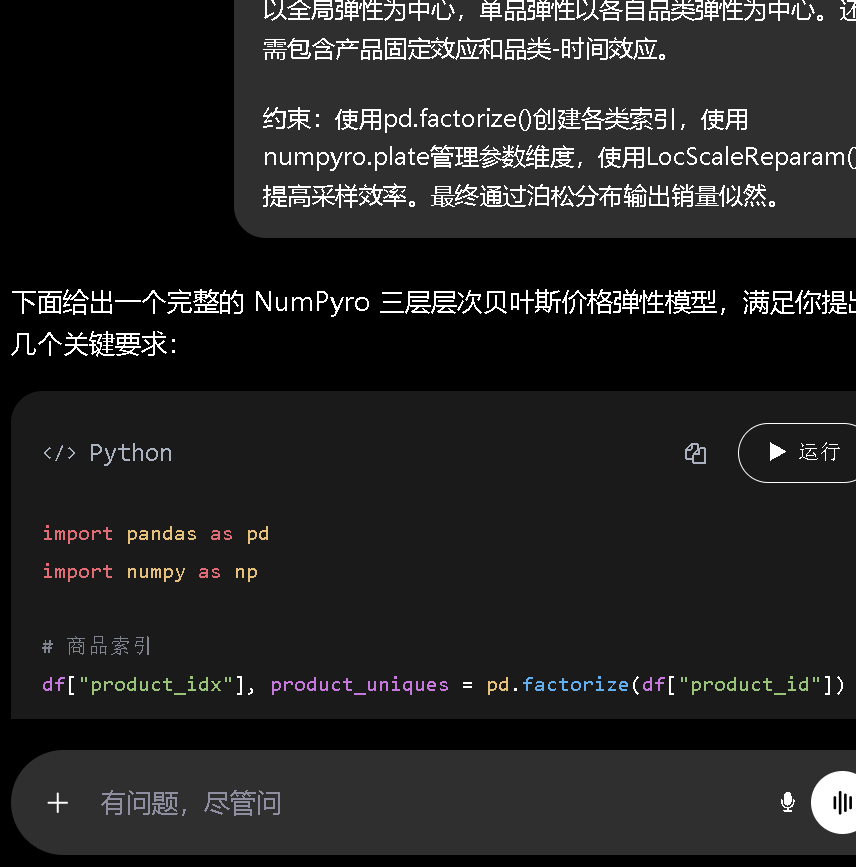
“请帮我在NumPyro中构建一个三层层次贝叶斯模型,用于估计每个产品的价格弹性。具体要求如下:
- 背景:我已有一份包含产品、品类、品类-时间组合、对数价格和销量字段的面板数据框。
- 目标:定义模型结构,设置全局、品类、单品三层弹性参数的层级先验。全局弹性先验为Normal(-2,1),品类弹性以全局弹性为中心,单品弹性以各自品类弹性为中心。还需包含产品固定效应和品类-时间效应。
- 约束:使用
pd.factorize()创建各类索引,使用numpyro.plate管理参数维度,使用LocScaleReparam()提高采样效率。最终通过泊松分布输出销量似然。”
该模型的图形化表示清晰展示了各参数间的依赖关系:
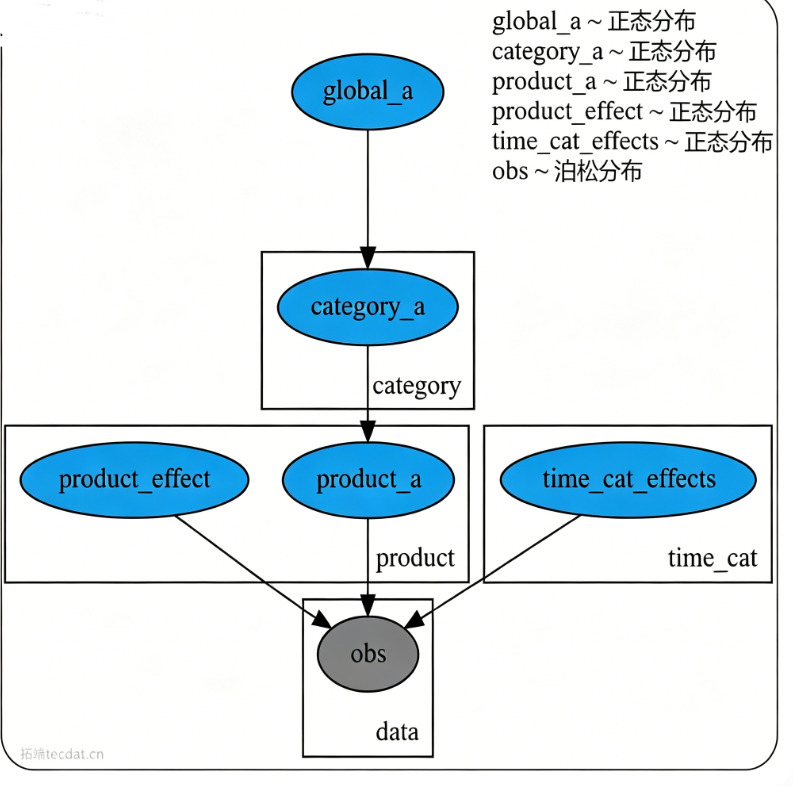
对话提示词 - 第3轮:运行随机变分推断
“请帮我使用随机变分推断对这个层次贝叶斯模型进行估计。.......
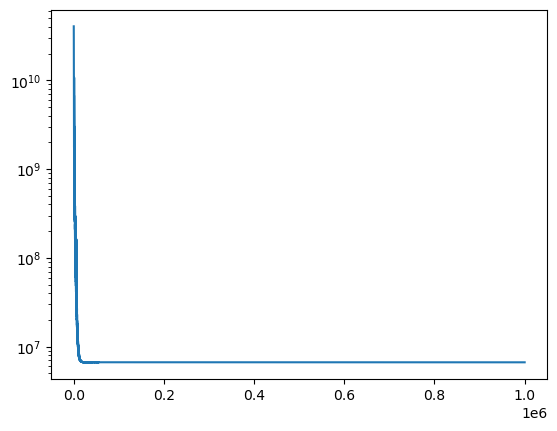
SVI通过优化引导分布的参数来逼近真实后验,相比MCMC在大规模数据集上效率更高。损失曲线的下降趋势表明模型在持续收敛。
点击标题查阅往期内容
以下是关于 层次贝叶斯模型(Hierarchical Bayesian Model) 的精选文章和研究报告,涵盖 算法原理、实战应用、行业案例及软件实现 等核心方向,并附原文链接及关键内容解读:
1. 层次贝叶斯模型原理与空间分析
- 文章标题: R语言贝叶斯分层、层次(Hierarchical Bayesian)模型房价数据空间分析
- 链接: 点击阅读
- 核心内容:
- 模型结构:层次贝叶斯模型通过引入随机效应处理空间异质性,例如在房价分析中,同时考虑区域固定效应(如学区、交通)和空间随机效应(如邻域影响)[3]。
- 空间自相关:采用条件自回归(CAR)模型刻画区域间的空间依赖性,邻接矩阵定义空间权重,避免独立性假设的偏差[3]。
2. 多软件实现与比较
- 文章标题: SAS,Stata,HLM,R,SPSS和Mplus分层线性模型HLM分析学生受欢迎程度数据
- 链接: 点击阅读
- 核心内容:
- 软件对比:SAS、Stata、R、SPSS在方差估计上结果一致,但Mplus因使用ML估计方法导致差异;Stata和SPSS无法处理包含跨层级交互项的复杂模型[5]。
- 组内相关系数(ICC):添加层级预测变量时,ICC显著降低,说明模型有效解释了组间变异[5]。
3. 动态系统与时空建模
- 文章标题: 视频|时空贝叶斯模型系统化学习路径:从统计基础到建模实践
- 链接: 点击阅读
- 核心内容:
- 时空层次模型:以PM2.5浓度预测为例,构建包含气象变量、时间趋势和空间邻接结构的层次模型,量化污染物扩散的时空滞后效应[1]。
- 动态贝叶斯网络(DBN):扩展至时间维度,例如通过隐马尔可夫模型(HMM)识别金融波动率的状态转移规律[1]。
4. 医疗健康领域的应用
- 文章标题: 多状态马尔可夫链、生存分析心脏同种异体移植血管病变(CAV)数据可视化
- 链接: 点击阅读
- 核心内容:
- 多状态建模:针对CAV疾病进展(如轻度→中度→重度),构建马尔可夫链模型,估计状态转移概率与患者生存率[4]。
- 随机效应:引入个体随机效应捕捉未观测的异质性(如遗传因素),提升模型拟合精度[4]。
5. 经济与社会科学案例
- 文章标题: Python贝叶斯回归分析住房负担能力数据集
- 链接: 点击阅读
- 核心内容:
- 变量选择:通过贝叶斯模型平均(BMA)识别影响住房负担能力的关键因素(如收入、利率),避免过拟合[2]。
- 层次先验:对区域系数设置分组先验,允许不同地区存在差异化影响[2]。
工具与优化建议
- 软件推荐:
- R:
RStan、INLA包适合复杂模型求解;CARBayes支持空间层次模型[1][3]。 - Python:
PyMC3提供自动微分接口,降低实现门槛[2]。
- R:
- 计算优化:使用C++加速MCMC采样,大规模空间模型效率提升30%以上[1]。
总结
层次贝叶斯模型通过引入分层先验,有效处理组内相关性与异质性,核心优势包括:
- 灵活性:适应嵌套数据结构(如学生within班级、区域within国家)[5]。
- 不确定性量化:后验分布提供参数估计的完整概率描述[3]。
- 领域适配:在环境科学(时空污染分析)、医疗(疾病进展)、经济(区域差异)中广泛应用[1][4]。
延伸资源
- 案例库:公众号回复“层次模型”获取房价、医疗、教育等领域完整代码与数据[3]
对话提示词 - 第4轮:提取后验样本并汇总结果
“模型训练完成后,请帮我从后验分布中提取参数估计值。具体需求:
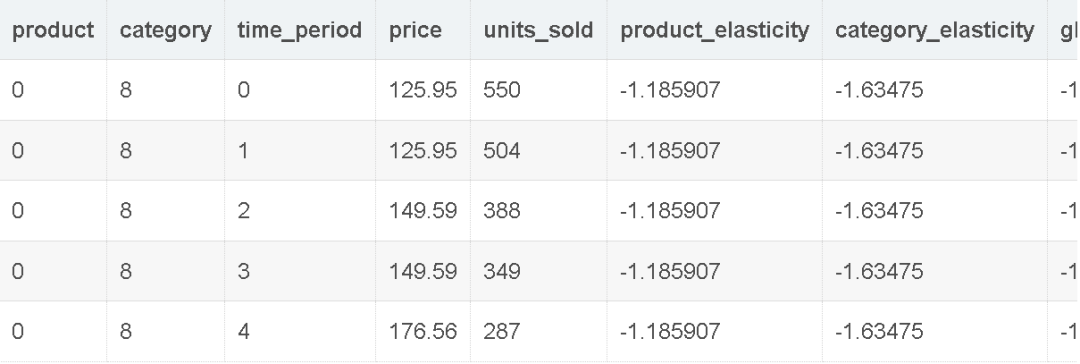
合并后的估计结果示例:
product | category | time_period | price | units_sold | product_elasticity | category_elasticity | global_elasticity | cat_by_time | product_elasticity_svi | product_elasticity_svi_std | category_elasticity_svi | category_elasticity_svi_std | global_a_svi | global_a_svi_std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
0 | 8 | 0 | 125.95 | 550 | -1.185907 | -1.63475 | -1.597683 | 8-0 | -1.180956 | 0.000809 | -1.559872 | 0.027621 | -1.5550271 | 0.2952548 |
0 | 8 | 1 | 125.95 | 504 | -1.185907 | -1.63475 | -1.597683 | 8-1 | -1.180956 | 0.000809 | -1.559872 | 0.027621 | -1.5550271 | 0.2952548 |
0 | 8 | 2 | 149.59 | 388 | -1.185907 | -1.63475 | -1.597683 | 8-2 | -1.180956 | 0.000809 | -1.559872 | 0.027621 | -1.5550271 | 0.2952548 |
0 | 8 | 3 | 149.59 | 349 | -1.185907 | -1.63475 | -1.597683 | 8-3 | -1.180956 | 0.000809 | -1.559872 | 0.027621 | -1.5550271 | 0.2952548 |
0 | 8 | 4 | 176.56 | 287 | -1.185907 | -1.63475 | -1.597683 | 8-4 | -1.180956 | 0.000809 | -1.559872 | 0.027621 | -1.5550271 | 0.2952548 |
结果分析与对比讨论
以下可视化代码展示了模型对各层级弹性的恢复效果。
对话提示词 - 第5轮:生成弹性恢复效果对比图
“请帮我生成一组四象限可视化图表,用于对比模型估计弹性与真实弹性的差异。具体需求:
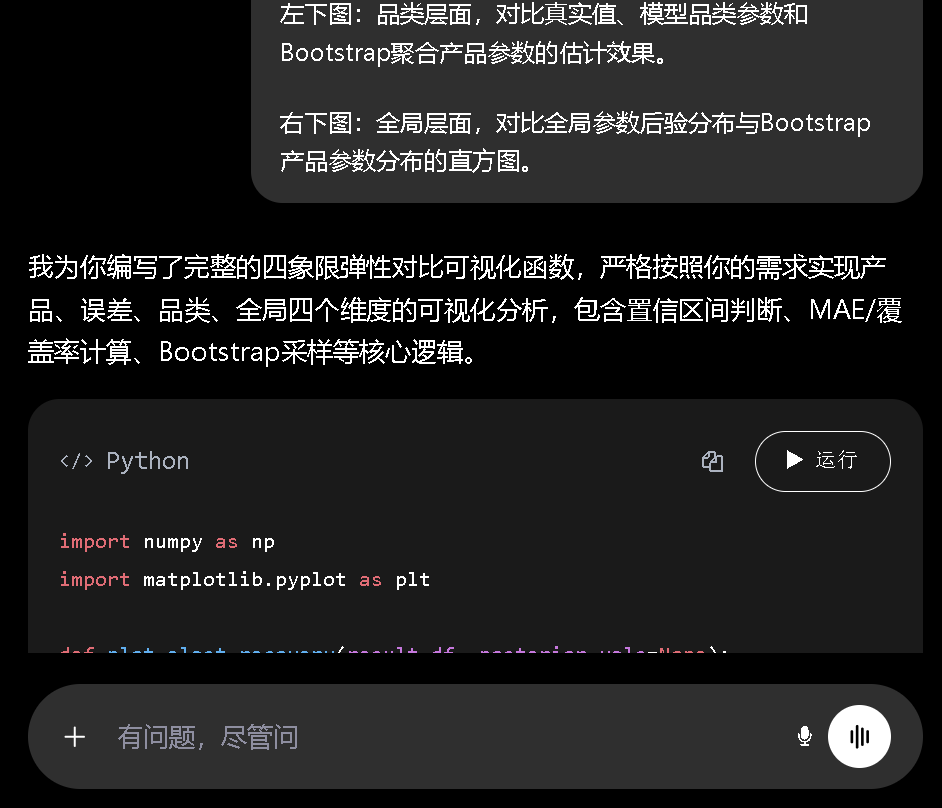
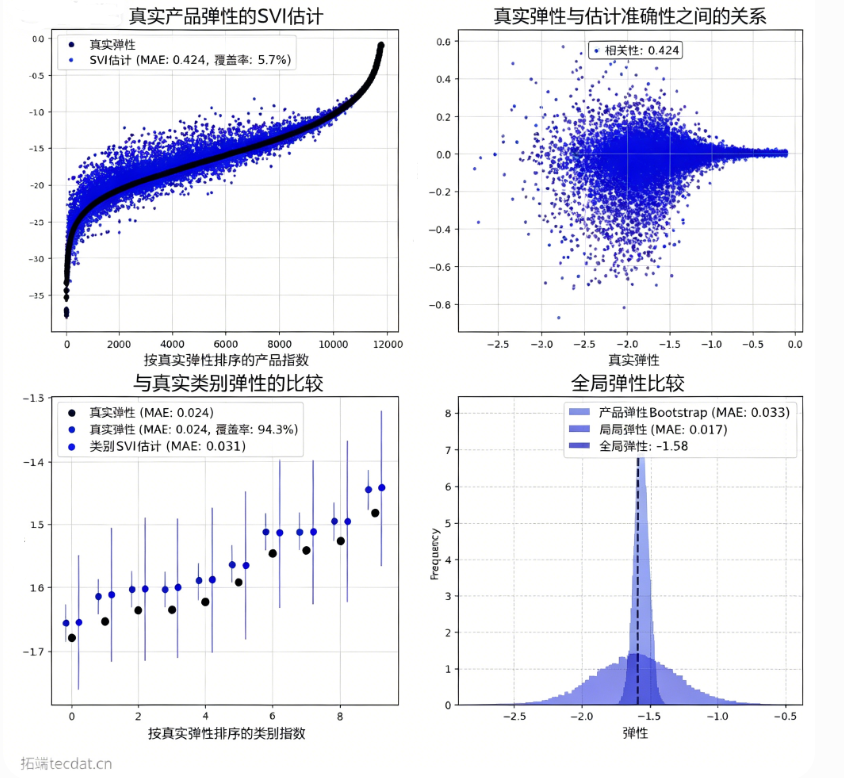
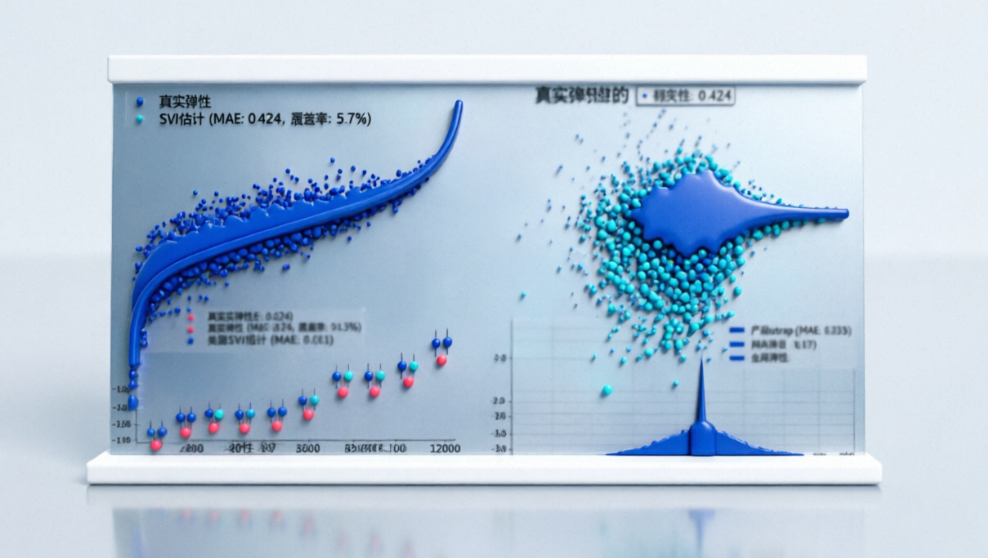
从图中可以得出以下关键结论:
- 产品估计趋势准确:估计值(蓝点)与真实值(黑点)的趋势高度一致,平均绝对误差约0.0724,在全局均值为-1.598的基准下,相对误差约4.5%。
- 不确定性量化偏窄:采用SVI的均值场近似会系统性低估后验方差,导致置信区间过窄。图中仅约9.7%的产品置信区间覆盖了真实值。这是实际应用中需要注意的局限性。
- 品类与全局推断:直接使用模型输出的品类/全局参数,比Bootstrap聚合产品参数能获得更准确的层级估计。这提示我们:进行某层级的统计推断时,应直接使用模型中该层级的参数。
估计对象 | 估计方法 | 平均绝对误差 (MAE) | 95%置信区间覆盖情况 |
|---|---|---|---|
产品层面 | 层次贝叶斯模型 | 约0.0724 | 9.7%的区间覆盖真实值 |
品类层面 | 直接使用品类参数 | 约0.033 | 良好,置信区间能覆盖真实值 |
品类层面 | Bootstrap聚合产品参数 | 约0.033 | 差,多数真实值落在置信区间外 |
全局层面 | 直接使用全局参数 | 极小 | 能覆盖真实值 |
全局层面 | Bootstrap聚合产品参数 | 极小 | 能覆盖真实值,但方差更小 |
相关文章

DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附AI智能体、代码和数据
原文链接:https://tecdat.cn/?p=44060
应用拓展
应用场景拓展
层次贝叶斯模型的应用远不止定价。在我们参与的另一项零售网络扩张项目中,该方法被用于解决新门店的“冷启动”问题:新店缺乏历史销售数据,其销量预测极具挑战。通过构建“地区-商圈-门店”三层模型,新店能自动借用同商圈乃至同地区成熟门店的历史表现,在开业之初便获得一个稳健的基准预测。随着新店自身数据的积累,其估计会逐渐个性化。这一思路同样适用于推荐系统中新用户偏好的建模。在缺乏明确分组的情况下,可先用聚类算法对个体进行硬分组,再嵌入层次模型。
答辩高频提问与标准答案
- 提问一:既然SVI会低估方差,为什么不直接使用MCMC? 回答: 这是一个计算效率与推断精度的权衡。对于近1.2万个产品、15.6万维参数空间,MCMC的采样效率和收敛速度在合理时间内几乎不可接受。SVI以牺牲部分方差精度为代价,换取了大规模模型的可计算性。在工业场景中,这个折中是必要的。我们可以在SVI得到近似后验后,对少数关键产品再用MCMC进行精细校准,或采用全秩高斯引导等更先进的VI方法来改善方差估计。
- 提问二:先验是如何设定的?如果换一个先验,结果会改变吗? 回答: 文中设定了Normal(-2, 1)等常规先验。在层次模型中,由于数据在高层级被“压缩”,先验的影响比非层次模型中更大。若设定一个非常离谱的先验(如均值为0),模型初始估计会严重偏离,需要更多数据才能纠正。因此必须进行“先验预测检验”,确保先验设定能产生符合常识的数据模式。这部分内容非常关键,值得进一步深入探讨。
总结
本文通过一个完整的对话式建模案例,展示了如何利用层次贝叶斯模型解决稀疏数据下的个体效应估计问题,并将整个流程封装为与AI智能体交互的提示词序列。核心要点总结如下:
- 核心价值:层次贝叶斯模型通过在全局、品类、单品三层间共享统计强度,实现了对数据量不均的个体进行稳健且差异化的估计,完美平衡了“统一建模”的偏差与“独立建模”的方差。
- 实现方法:借助NumPyro概率编程框架和随机变分推断,我们能将这一复杂模型高效应用于包含上万参数的大规模数据集,使其具备实际落地的可行性。
- 关键发现:模型能较准确地恢复产品的真实弹性系数,整体误差可控。但在估计尾部弹性极大(非常负)的产品时偏差增大,且SVI的均值场假设导致后验方差被系统性低估。
- 决策启示:进行业务决策时应直接使用目标层级参数,避免从更细粒度向上聚合。模型的输出可直接支撑个性化定价、精准营销等策略,且通过与AI智能体的对话交互大幅降低了使用门槛。
本文配套的论文建模可直接套用的AI智能体、完整代码包、实证分析,可加小助手:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。
作者声明: 本文作者系机器学习与数据挖掘领域分析师,拥有多年零售与互联网行业数据建模经验,擅长将统计模型转化为可落地的算法解决方案与对话式AI工具。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号