Signal #14:别只看出码率了,AI Coding 的指标正在变

Signal #14:别只看出码率了,AI Coding 的指标正在变

梯度不陡
发布于 2026-06-01 19:28:03
发布于 2026-06-01 19:28:03
Info 代码生成越来越多,不代表研发效率一定同步提升。 当 AI IDE 和 Coding Agent 开始进入真实研发流程,企业需要的,已经不只是“出码率”这一类代码层指标。
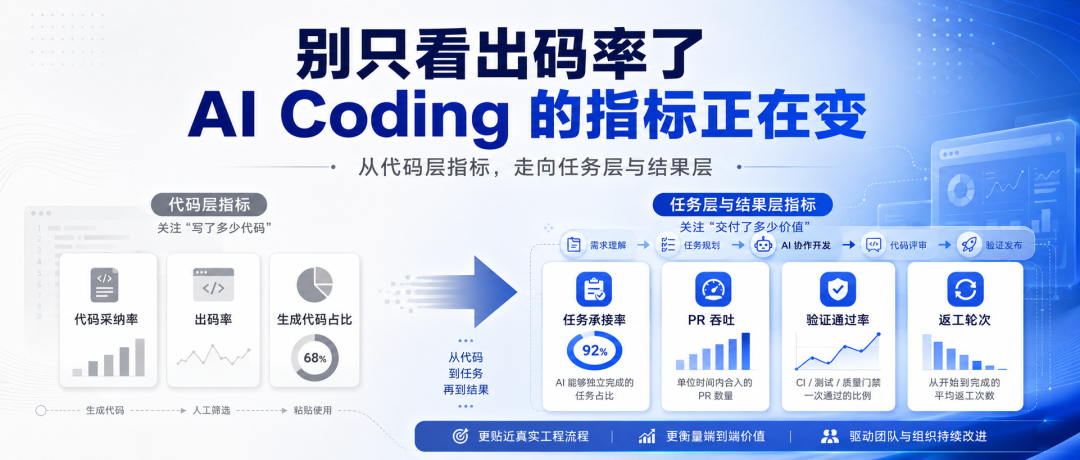
如果一个团队的 AI 生成代码占比越来越高,出码率也在上升,但 PR 吞吐量没有明显变化,返工还是很多,验证和 review 压力也没降下来,那你很难说:研发效率真的因为 AI 提升了。
这也是我最近越来越强烈的一个感觉: AI Coding 的评价口径,正在从“AI 写了多少代码”,转向“AI 承接了多少真实研发工作”。
过去一段时间,很多团队衡量 AI Coding,最常用的还是代码层指标:AI 生成代码占比、代码采纳率、活跃用户数、出码率提升了多少。
这些指标仍然有价值。它们回答的是一个很基础的问题:AI 有没有真的进入开发过程。
但问题在于,今天很多团队使用 AI IDE 或 Coding Agent,早就不只是“让它补几行代码”了。更常见的使用方式,是通过对话让它修改文件、实现需求、修 bug、补测试、处理 review feedback,甚至把一段更完整的任务交给它。
一旦使用方式变了,评价方式就会开始滞后。
如果我们还主要用代码层指标去理解 AI 的价值,往往只能看到“它参与了写代码”,却不一定能看到“它有没有真正改变研发流程”。
一个很直接的信号:平台开始重新定义 adoption
这周 GitHub 在官方更新《Copilot usage metrics API adds cohorts for AI adoption[1]》里,新增了 ai_adoption_phase。
它不再只是统计谁在用 Copilot,而是开始把用户分成几个阶段:
- • Code first
- • Agent first
- • Multi-agent
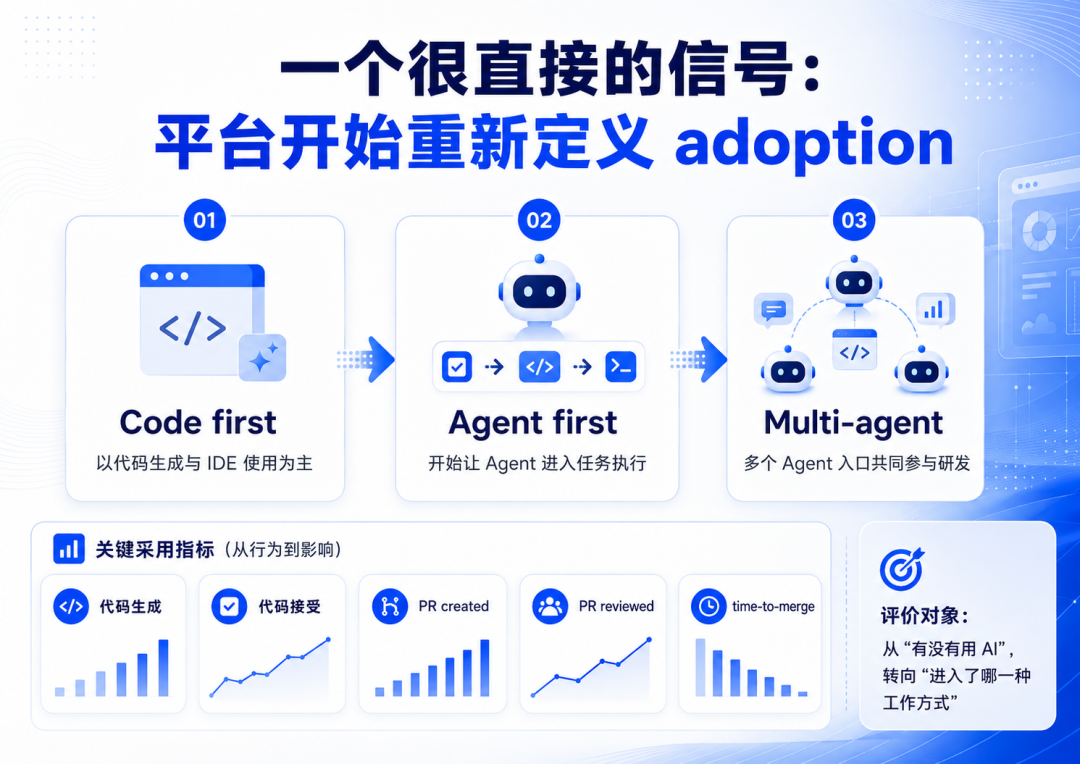
GitHub 把 Copilot 使用方式分成 Code first、Agent first、Multi-agent,背后反映的是 AI Coding adoption 口径的变化
GitHub 把 Copilot 使用方式分成 Code first、Agent first、Multi-agent,背后反映的是 AI Coding adoption 口径的变化
这个变化值得注意。
因为它背后问的,已经不是“你有没有用 AI”,而是:
你还停留在代码生成阶段,还是已经开始让 Agent 进入任务执行、多入口协作,甚至更接近真实研发流程的阶段?
更关键的是,GitHub 这套分层背后对应的统计项,也不只是代码生成和接受情况,还包括 PR created、merged、reviewed,以及 median time-to-merge 这类更接近研发流程的指标。
这说明平台方也开始意识到: AI Coding 的成熟度,不能只看“生成了多少代码”,还要看它到底进入了哪一种工作方式。
换句话说,评价对象正在从“代码生成工具的使用情况”,迁移到“Agent 对研发流程的参与程度”。
另一类信号:开始直接用工程产出来表达 AI 的价值

当平台开始用 PR 吞吐、任务承接、Review 反馈来表达 AI 价值时,评价重心已经不再只是代码生成本身
当平台开始用 PR 吞吐、任务承接、Review 反馈来表达 AI 价值时,评价重心已经不再只是代码生成本身
如果说 GitHub 代表的是“评价口径的变化”,那另一类信号则更直接:一些平台已经开始用研发产出来表达 Agent 的价值,而不是只说它写了多少代码。
比如 Cursor 这周发布的客户案例《Faire doubles PR throughput with Cursor Cloud Agents[2]》。
它强调的不是代码采纳率,而是:
- • weekly PR throughput 翻倍
- • 每周 2000+ 次 automated agent runs
- • 一个原本需要 18 个月的迁移任务,被压缩为由一个工程师管理一组 agent fleet 来推进
这套表达方式已经很不一样了。
它不再是“AI 帮开发者多写了一些代码”,而是: AI 开始承接任务、推进 PR、压缩迁移成本,并直接影响工程产出。
OpenAI 这周的案例《How Ramp engineers accelerate code review with Codex[3]》也有类似意味。Ramp 用 Codex 加速 code review,让工程师更快获得有实质内容的 PR feedback。这里 AI 的价值也不是“又写了多少代码”,而是进入了 review 和协作环节,开始影响研发流转速度。
所以我觉得,一个很清晰的变化正在出现:
AI Coding 的价值衡量,正在从“代码生成参与度”,转向“任务承接能力”和“流程推进能力”。
为什么只看出码率,已经开始不够了
“出码率”不是没用。它依然是一个重要指标,尤其是在 AI 落地早期。
因为在那个阶段,团队首先要回答的是:大家到底有没有把 AI 用起来?AI 有没有实际参与代码生产?
但问题是,出码率天生更接近“代码生产”这一层,而不是“研发交付”这一层。
代码是研发流程的一部分,不是全部。
一个任务最终能不能高质量交付,除了生成代码,还取决于很多环节:需求理解是不是准确,上下文有没有找对,修改范围是否可控,测试是否补全,验证是否通过,review feedback 能不能被吸收,最终是否能稳定合并。
所以你会看到一种越来越常见的情况:
- • AI 参与度很高
- • 代码产出很多
- • 但真实交付并没有同比例提升
问题往往不在“AI 没写代码”,而在于: 它虽然参与了代码生产,却还没有稳定进入任务推进和流程闭环。
这也是为什么,只看出码率,开始不够了。
下一阶段,指标可能会分成三层
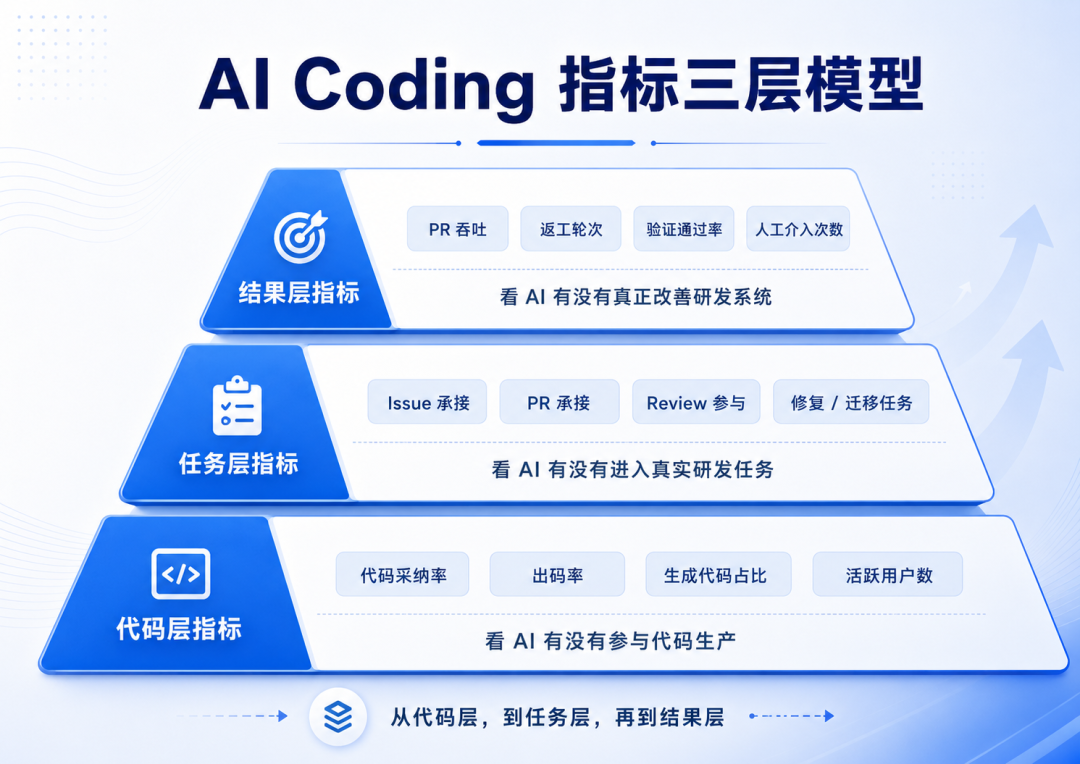
AI Coding 的指标体系,正在从代码层,逐步走向任务层和结果层
AI Coding 的指标体系,正在从代码层,逐步走向任务层和结果层
如果沿着这个方向看,我觉得下一阶段 AI Coding 的指标,可能会越来越清晰地分成三层。
第一层:代码层指标
比如:
- • AI 生成代码占比
- • 代码采纳率
- • 出码率
- • 活跃用户数
这一层回答的是:AI 有没有被用起来,以及它是否参与了代码生产。
第二层:任务层指标
比如:
- • Agent 承接了多少 issue
- • 承接了多少 PR
- • 参与了多少 review
- • 完成了多少修复任务、迁移任务、CI 处理任务
这一层回答的是:AI 有没有进入真实研发任务。
第三层:结果层指标
比如:
- • PR 吞吐量
- • 返工轮次
- • 验证通过率
- • 人工介入次数
- • 从需求到合并的周期变化
这一层回答的是:AI 有没有真正改善研发系统。
这三层指标的含义完全不同。
代码层指标看的是“参与了多少”, 任务层指标看的是“承接了多少”, 结果层指标看的是“最终改善了什么”。
很多团队现在的状态,其实不是没有指标,而是指标还主要停留在第一层。
企业真正需要的,不只是更高的 AI 活跃度
这件事放到企业研发提效里,其实更明显。
在 AI 落地早期,看活跃用户数、代码采纳率、出码率,很正常。因为第一步确实是让工具先被用起来。
但如果 AI 真的开始进入研发流程,那么企业最终关心的问题一定会变成:
- • AI 承接了多少真实任务?
- • 这些任务有没有真正进入 PR?
- • PR 有没有更快通过 review 和验证?
- • 返工轮次有没有下降?
- • 人工介入次数有没有减少?
- • 从需求到合并的周期有没有缩短?
这些问题,比“AI 生成了多少代码”更接近研发效率本身。
指标迁移之后,另一个问题也会随之出现:当 AI 不再只是个人工具,而开始进入团队工作流,企业就必须关心它是否可控、可治理。比如 Vercel 这周发布的《Team-wide provider allowlist on AI Gateway[4]》这样的更新也值得留意。平台方一边在补 Agent 的能力,一边也在补治理、边界和组织级使用方式。因为一旦 AI 不再只是个人工具,而开始进入团队工作流,企业最终一定会要求它的价值,能够落到更接近流程和结果的指标上。
结语
AI Coding 的早期问题,是 AI 能不能写代码。 后来问题变成,AI 写出来的代码能不能被接受。 而现在,一个新的问题正在变得更重要:
AI 能不能稳定承接真实研发工作,并最终转化成可验证的工程产出。
所以,出码率仍然重要,但它已经不是终点。下一阶段,企业更需要关注的,可能是任务承接率、PR 吞吐量、返工轮次、验证通过率、人工介入次数,以及从需求到交付的周期变化。
当指标开始从代码层走向任务层、结果层时,AI Coding 才算真正从一个“会写代码的工具”,进入企业研发系统。
Info 《每周 Signal|AI x SE》是我持续记录 AI 与软件工程变化的栏目 不追热点,只记录那些正在发生、且值得长期跟踪的变化。 欢迎关注和交流~
引用链接
[1] Copilot usage metrics API adds cohorts for AI adoption: https://github.blog/changelog/2026-05-29-copilot-usage-metrics-api-adds-cohorts-for-ai-adoption/
[2] Faire doubles PR throughput with Cursor Cloud Agents: https://cursor.com/blog/faire
[3] How Ramp engineers accelerate code review with Codex: https://openai.com/index/ramp/
[4] Team-wide provider allowlist on AI Gateway: https://vercel.com/changelog/team-wide-provider-allowlist-on-ai-gateway
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号