排查定位I/O问题思路分享

排查定位I/O问题思路分享

悠悠12138
发布于 2026-06-01 19:34:04
发布于 2026-06-01 19:34:04
从全局到具体,分层诊断是关键
碰到 I/O 问题,别急着干,得先问自己几个问题:
1. 系统层面,I/O 到底有没有问题?
这时候 iostat 就派上用场了。我通常这么用:
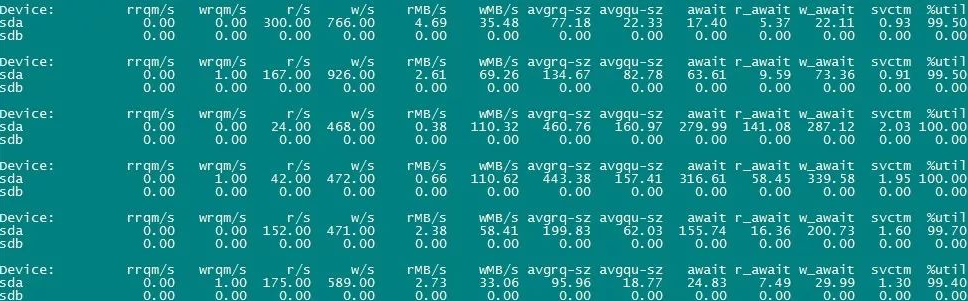
iostat -x -d 1 5这个命令会每隔1秒打一次,共5次,输出每个磁盘设备的详细 I/O 统计。关键指标看这几个:
- •
%util:磁盘使用率。如果超过 80%,说明磁盘压力确实大 - •
await:平均等待时间,单位毫秒。这东西告诉你一个 I/O 请求平均要等多久才能完成 - •
r/s和w/s:每秒读写操作数。对比这俩能看出是读多还是写多
看这个数据我大概就能判断,I/O 是真的有问题,还是只是某个进程干了坏事。
2. 哪个进程这么能折腾?
光知道系统 I/O 压力大还不够,得找到元凶。这时候 iotop 就是神器:
sudo iotop -o加 -o 参数的意思是只显示有 I/O 活动的进程,这样不会被一堆没干活的进程刷屏。输出里能直接看到:哪个进程、多少读写速度、I/O 等等时间。
这玩意儿一下子就能说清楚,你的 I/O 问题到底是 MySQL 在干全表扫描,还是某个备份进程在一个劲儿地读文件,还是应用代码里有个 bug 疯狂写日志。
从现象到原因,这是诊断的核心
拿到了数据以后,得分析。一般 I/O 问题无外乎这几种情况:
磁盘设备本身性能差
有时候你会发现 await 奇高,但 %util 其实不算太高。这就说明问题不在磁盘忙不忙,而在于单个请求耗时太长。这种情况常见于:
- • 用了比较渣的 SATA 盘,或者 HDD(机械硬盘)
- • 磁盘阵列配置不合理,或者某块盘在重建
- • SSD 性能下降,要检查是不是频繁 GC 或者内存不足导致频繁掉页
有个同事的库就遇过这事——一开始以为是 SQL 慢,后来发现是磁盘本身 await 就高,换了块新 SSD 以后,问题立竿见影。
应用 SQL 效率低下
这种情况通常表现为:I/O 利用率高,但大量请求排队等待。根本原因常常是:
- • 没建索引,每次查询都得全表扫
- • 一次性读取大量数据,比如不加 limit
- • 存储过程里有循环查询
我就见过一个生产事故,某个报表功能一夜间变得贼慢。一查才发现,新上线的代码里加了个 for 循环,每次循环都要查一次数据库。你想啊,10万条数据,就是10万次查询,磁盘能不累吗?
内存太紧张
这是我经常忽视的一点。当可用内存不足时,操作系统会把内存中的页面写回磁盘(page out),这会导致大量的写 I/O。此时看 iostat,你会发现写操作突然激增。
看内存状态,用 free -h 看看 available 还剩多少。如果经常接近0,说明内存成了瓶颈。这时候要么增加内存,要么调整缓冲池大小(对 MySQL 来说就是调 innodb_buffer_pool_size)。
I/O 调度器配置不当
Linux 提供了几种 I/O 调度器,不同的工作负载适合不同的调度器。有些老服务器默认用的是 CFQ(完全公平队列),它会尽力保证公平,但吞吐量不一定最优。对于高并发场景,noop 或者 deadline 往往更好。
查一下现在用的调度器:
cat /sys/block/sda/queue/scheduler如果是 cfq,而你的业务是高并发数据库,可以尝试改成 deadline:
echo deadline | sudo tee /sys/block/sda/queue/scheduler不过这个改动需要谨慎,最好先在测试环境验证,再上生产。
从根因到解决,这是治本的事
一旦定位了问题根源,就要对症下药。
假如是 SQL 效率问题,就去优化 SQL、加索引、调整参数。这通常能改善个50%以上。
假如是内存不足,那就加内存或者调整缓冲池。这个改动会立竿见影,因为减少了 page out,I/O 压力瞬间就下来了。
假如是磁盘本身差,那可能得换硬件。但在换之前,先看看有没有其他方法——比如调整 RAID 级别、或者启用磁盘缓存(如果业务能接受的话)。
有个细节值得一提,当你在调优的时候,最好同时开着 iostat 和应用监控,这样就能看到改动的效果。我习惯用这个组合:
# 终端1:持续监控 I/O
iostat -x -d 1
# 终端2:持续监控进程
iotop -o
# 终端3 或应用日志:看应用响应时间这样三管齐下,改动前后对比一下数据,就能判断效果如何。
一些小技巧
用 blktrace 追踪磁盘 I/O
如果 iostat 和 iotop 都看过了,问题还是扑朔迷离,可以用 blktrace 打印出每一个 I/O 请求的详细信息。这玩意儿有点底层,但能帮你看到 I/O 的完整生命周期。
监控磁盘队列深度
这个参数决定了有多少个 I/O 请求能同时被处理。队列太浅,吞吐量上不去;太深,延迟就高了。看 /sys/block/sda/queue/nr_requests 这个文件就能查。
对比不同条件下的 iostat 数据
别光看一瞬间的数据,要看趋势。我一般会记录早高峰、晚高峰、凌晨各一份 iostat 数据,对比一下。有时候问题并不是真的突然出现,而是长期积累,某个临界点就爆发了。
小结
排查 I/O 问题的思路,就是从全局到具体,从表象到根因,从诊断到治疗。工具只是辅助,关键是要问对问题。
下次碰到 iowait 高的情况,先冷静想想:
- 1. I/O 真的有问题吗?(看 iostat)
- 2. 是谁在搞鬼?(看 iotop)
- 3. 根本原因是啥?(分析数据)
- 4. 怎么解决?(对症下药)
这么走一遍,基本没啥问题解决不了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号