【AI内参】SciMaster:突破 20 万 Token 瓶颈,ML-Master 2.0 开启“长程自主科学”新纪元

【AI内参】SciMaster:突破 20 万 Token 瓶颈,ML-Master 2.0 开启“长程自主科学”新纪元

乐小野
发布于 2026-06-01 21:04:26
发布于 2026-06-01 21:04:26
在大语言模型(LLM)进军科研领域的道路上,长期存在一种“记忆与推理的认知冲突”:面对长达数天甚至数周的实验周期,海量的执行日志与报错细节会迅速填满模型的上下文窗口,导致 AI 在琐碎细节中迷失,丧失对全局策略的把控。
ML-Master 2.0 的发布标志着一个范式转型,它将上下文管理从简单的“数据堆叠”提升为“认知积累(Cognitive Accumulation)”。这种转变不仅解决了“断片”焦虑,更让 AI 具备了像人类科学家一样从碎片经验中提炼智慧的能力。
核心突破:从“全量记忆”到“分层进化”的认知缓存 (HCC)
ML-Master 2.0 舍弃了 1.0 版本中侧重于并行搜索引导的“自适应内存”,转而引入了受计算机多级缓存系统启发、更具生物学深度的“分层认知缓存(HCC)”架构。这一设计实现了“经验在时间维度上的结构化差异”,确保了执行细节与长期战略的解耦。
L1 缓存(进化经验 / Evolving Experience)
作为 AI 的“工作内存”,存储当前阶段最原始的执行轨迹,包括代码补丁、终端日志和即时反馈。它保证了 AI 在进行底层调试和快速迭代时拥有最高保真度。
L2 缓存(精炼知识 / Refined Knowledge)
这是 AI 的“中期战略内存”,存储从已完成的实验阶段中提炼出的稳定结论。例如,“特征 X 存在数据泄露”或“Y 损失函数在当前任务中不收敛”。通过剥离冗长日志,L2 确保了在跨越数天的探索中,AI 仍能维持一致的科研航向。
L3 缓存(先验智慧 / Prior Wisdom)
作为“长期知识沉淀”,它存储跨任务的、可迁移的通用策略,如鲁棒的模型模板或通用的数据清洗管线。这使得 SciMaster 在面对新任务时,并非盲目试错,而是带着“前世智慧”高起点入场。
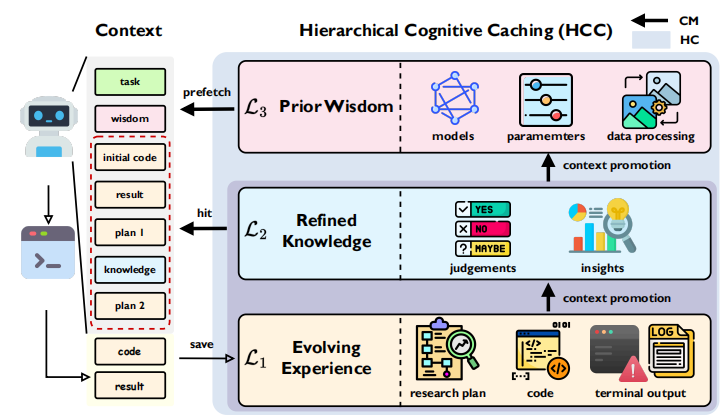
“通过分层认知缓存(HCC)架构,SciMaster 实现了执行细节与长期战略的解耦,有效克服了静态上下文窗口对智能规模化的限制,让 Agent 在面对超长程科研任务时不再受限于记忆带宽。”
治理协议:上下文迁移如何让 AI “学会忘记”
为了防止认知饱和,ML-Master 2.0 建立了一套严谨的上下文迁移协议(Context Migration)。其核心在于“回顾性抽象(Retrospective Abstraction)”,即通过主动的“遗忘”来实现更深层次的“铭记”。
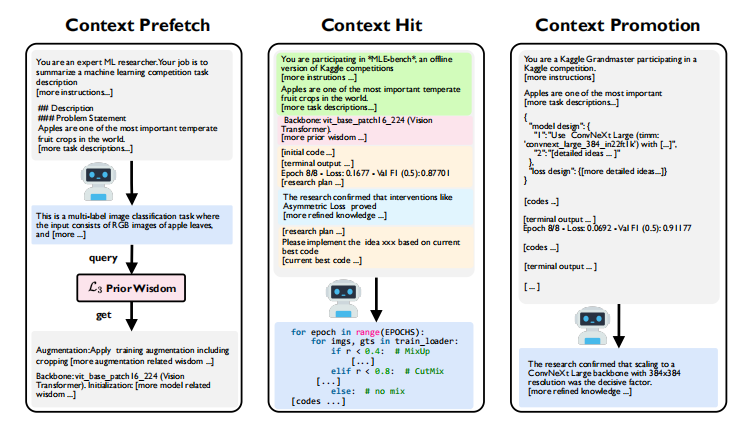
上下文预取 (Prefetching)
在任务伊始,系统基于任务描述从 L3 缓存中检索匹配的先验策略,构建强大的初始认知背景。
上下文晋升 (Promotion)
这是系统最具灵性的一步。在每个科研阶段边界,AI 会对 L1 中的原始执行痕迹进行回顾性抽象,将其压缩为 L2 的知识条目或 L3 的战略智慧,并清理过期的细节。
上下文命中 (Hit)
在推理过程中,系统优先从 L1 获取活跃细节,若信息缺失则回退至 L2 的精炼摘要,在保真度与 token 消耗之间达成了精妙的平衡。
数据亮点:在处理如“Random Acts of Pizza”这类极其复杂的科研任务时,通过 HCC 治理,系统成功将峰值上下文从超过200k tokens压缩至仅70k tokens左右。这种效能提升确保了 AI 在经历多次实验失败后,依然能保留关键洞察并最终夺魁。
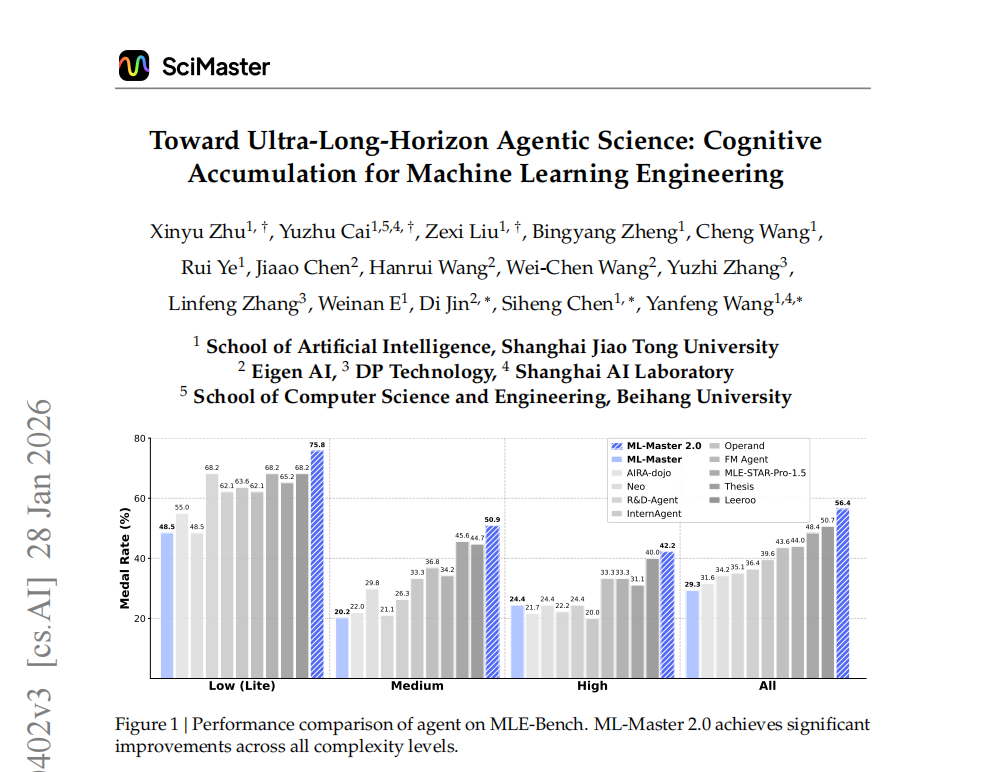
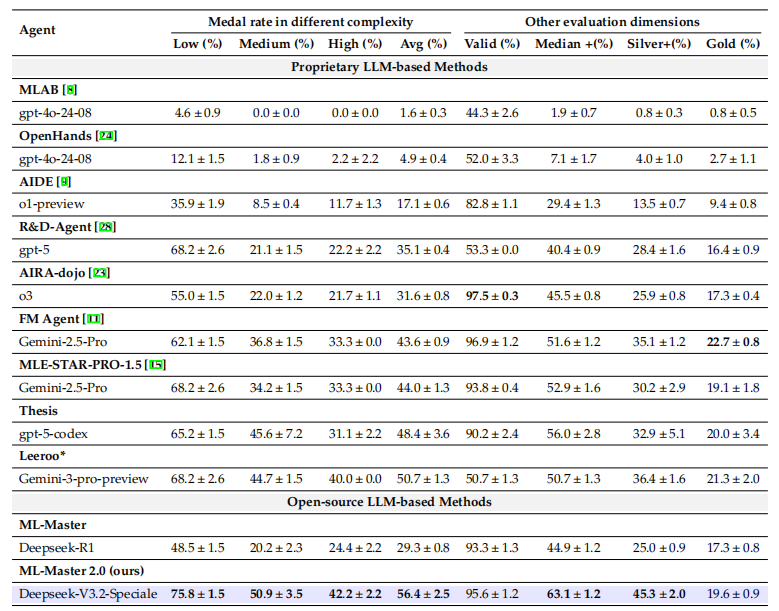
性能飞跃:不仅仅是翻倍的“奖牌率”
在权威的机器学习基准测试 MLE-Bench 上,ML-Master 2.0 展现了统治级的进化。在24 小时的实验预算下(相较于 1.0 版本的 12 小时),其平均奖牌率从29.3%飙升至56.44%,实现了约92.7%的相对提升。
ML-Master 2.0 在中等难度任务上的奖牌率从 20.2% 跨越式增长至50.9%。中等难度任务通常是“长程策略”的甜点区——它们需要比简单任务更多的实验循环,1.0 的架构在此时往往会陷入上下文饱和,而SciMaster 的 HCC 架构在此类需要“耐心”与“总结”的场景中展现了惊人的韧性。任务视野从“12 小时”扩展到支持“数天或数周”的超长程场景,真正让 AI 踏入了“科研可用”领域。
底座升级:DeepSeek 系列模型的强强联手
ML-Master 2.0 的卓越表现得益于其底层模型的精细化分工:
主干推理与编码
升级为DeepSeek-V3.2-Speciale,在复杂的科研规划与代码生成环节提供了更强的工程鲁棒性。
认知晋升 clerk
在进行阶段性的知识提炼(Context Promotion)时,SciMaster 少量且精准地引入了具有深度思考能力的DeepSeek-V3.2 with thinking。这种将“深思熟虑”作为特殊治理工具而非通用执行工具的策略,大幅提升了认知积累的质量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号