是时候学装B了——大佬们都在说的LAM是个啥?

是时候学装B了——大佬们都在说的LAM是个啥?

乐小野
发布于 2026-06-01 21:27:17
发布于 2026-06-01 21:27:17
你让AI“帮我订下周二去上海的高铁票,靠窗”,它回你一串步骤:“1.打开12306;2.输入出发地;3.选择日期;4.勾选靠窗……”
你心里一万头草泥马奔过:我要的是你干,不是教我怎么干。
这个尴尬,在2026年大概率要被一个叫LAM的东西终结。
【出处】
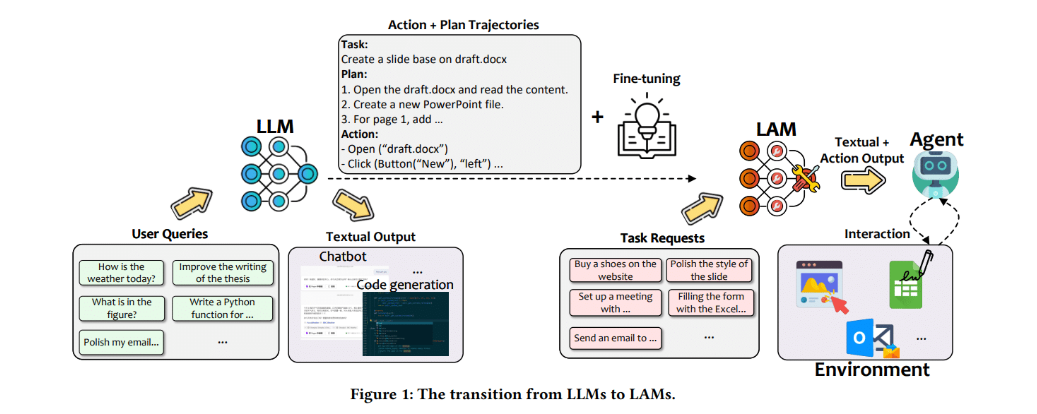
LAM(Large Action Model,大操作模型)是2026年AI技术路线图中的核心热词。
Data Science Dojo等科技媒体将其定义为“超越LLM的下一个进化方向”。
Salesforce已推出xLAM系列模型,而OpenAI在2026年2月发布的“Operator”系统,被业界认为是LAM架构的典型实现——它可以通过“视觉-动作循环”直接操作浏览器和桌面应用。
【意思】
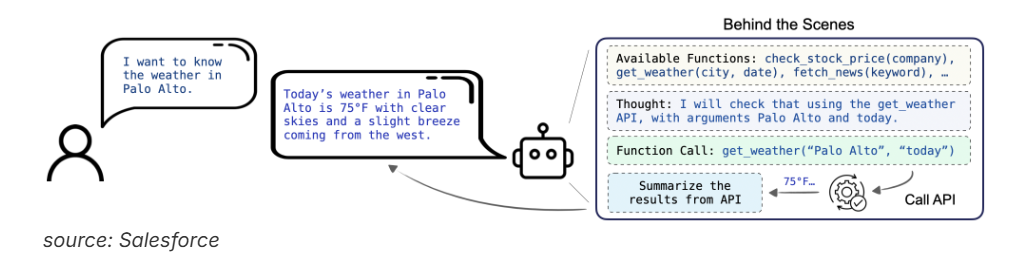
LAM和LLM的本质区别在于输出类型:LLM输出文本(建议、计划、步骤),LAM输出动作(点击、填写、调用、执行)。
一个会“说”,一个会“做”。
【技术点】
1. 核心技术架构:视觉-动作闭环
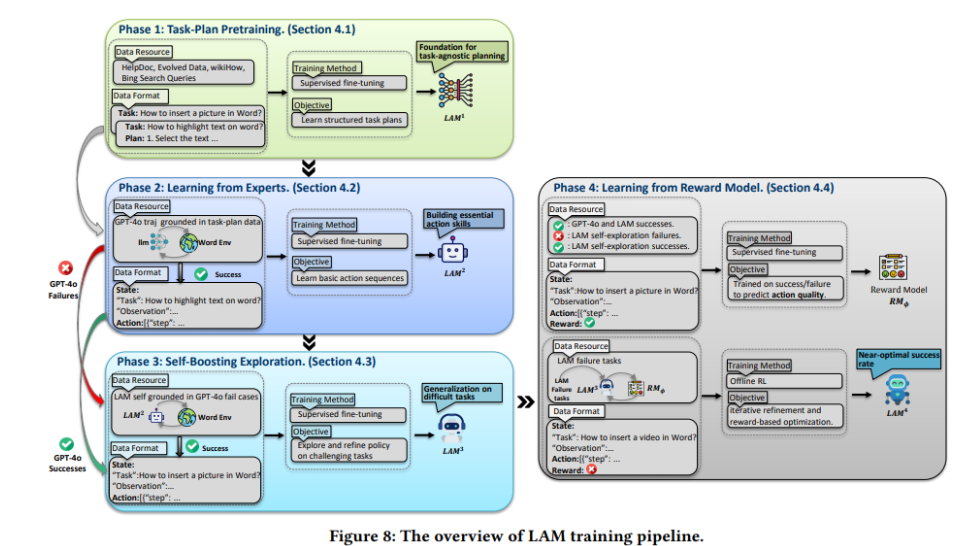
LAM的核心是“环境感知+动作生成”的闭环系统。
以OpenAI Operator为例,它采用“Vision-Action Loop”(视觉-动作循环):
通过高频截取桌面或浏览器画面,进行像素级UI元素识别——按钮、下拉菜单、输入框——像人一样“看”屏幕,而不是依赖底层HTML代码。
也就是说,即使网站前端改版,只要按钮还在那个位置、长那个样子,LAM就能找到它、点它。数据显示,这种视觉导航的成功率可达87%。
2. 神经符号AI的复兴
LAM的技术底座是神经符号AI(Neuro-symbolic AI)。它结合了:
- 神经网络的模糊模式识别能力(理解“靠窗”这个意图)
- 符号系统的结构化逻辑推理(规划“订票→选座→支付”的步骤序列)
纯LLM是靠“猜下一个词”来生成文本;纯符号系统则太死板,应付不了真实世界的混乱。
神经符号AI让LAM既能处理模糊的自然语言,又能执行结构化的多步任务。
3. 动态规划与自适应
真实任务往往需要多步流程、分支逻辑、错误处理。LAM具备实时观察环境、调整计划的能力。
例如,在保险理赔场景中,LAM能:
- 解析客户意图(报价、变更、续保)
- 拆解为子目标(更新CRM字段X、计算保费Y、生成文档Z)
- 识别当前正在操作的界面
- 执行点击、填表、API调用
- 跟踪界面状态变化
- 如果表单字段和预期不符,实时调整路径
4. 训练数据的特殊性
LAM的训练需要动作数据,而不仅仅是文本数据。
这类数据记录的是“用户执行任务时的每一步操作”:每一次点击、每一次键盘输入、每一次界面状态变化、以及触发这些动作的意图。
这种数据比纯文本语料稀缺得多,获取和清洗成本也高得多。
5. 评估的极高门槛
LAM的评估需要“离线评估+环境测试+安全护栏”多重机制。业界普遍采用的方案大概包括:
- 分层思维链:遇到验证码或意外弹窗时,启动纠错推理流程
- 接管模式:失败时交还给人类操作特定步骤,再恢复自主执行
- 强制熔断开关:符合欧盟《AI法案》对高风险系统的监管要求
【圈内话】
LAM的普及意味着“坐席经济”的终结。
以前软件按“账号数”收费(seat-based subscription),因为一个人一个账号;现在一个LAM能干十个人的活儿,企业凭啥还付十份钱?
行业正在转向按“解决任务”收费(outcome-based pricing)。
也就是SaaS模式的根本性动摇。
微软CEO萨提亚·纳德拉说:“Agent是新App”。以后你手机里可能没有携程App,但有个“能帮你订票的AI”——它会在需要时调出携程界面,操作完就消失。当前千问貌似已经实现了全链路打通。
【附录:LAM vs LLM 对比】
维度 | LLM | LAM |
|---|---|---|
输出 | 文本 | 动作 |
角色 | 建议者 | 操作员 |
核心技术 | Transformer | 神经符号AI + 视觉-动作循环 |
训练数据 | 文本语料 | 操作日志+界面状态 |
错误成本 | 低(最多被骂) | 高(可能搞崩系统) |
典型产品 | ChatGPT | OpenAI Operator |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号