Claude封神级应用!数天干完数年科研活,长效AI智能体重构科学计算新范式

Claude封神级应用!数天干完数年科研活,长效AI智能体重构科学计算新范式

乐小野
发布于 2026-06-01 21:28:12
发布于 2026-06-01 21:28:12
AI智能体处理科研任务仍有大局限
至今为止,多数科研人员使用AI智能体时,仍局限于对话式交互模式,需人工全程管控每一个操作步骤,效率低下且依赖专业经验,说白了仍然是个摆设、鸡肋。
我们是否可以拥有一个无需介入细节,仅明确高层目标,即可让Agents自主推进任务的方法呢?
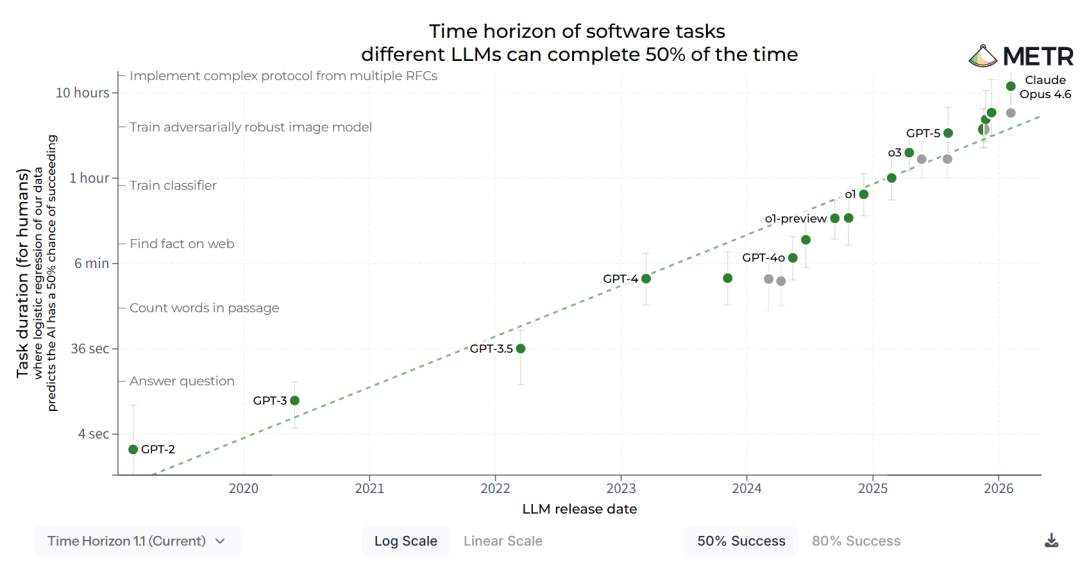
这类自主工作模式,需要适配边界清晰、成功标准明确、无需人类持续值守的科研任务,比如:重新实现数值求解器、将老旧Fortran方言编写的传统科研软件迁移至现代语言、基于参考实现调试大型代码库等。
此前,Anthropic的C编译器项目已验证了这一路线的可行性——Claude通过约2000个会话,自主构建出可编译Linux内核的C编译器。
Anthropic还对此特意开展了压力测试,比如同时设置了 16个agent从0开始编写一个基于 Rust 的 C 编译器,任务目标是让该编译器能够编译 Linux 内核。经过近 2000 次 Claude Code 会话和 2 万美元的 API 费用,Agents最终编写出了一个 10 万行的编译器,该编译器可以在 x86、ARM 和 RISC-V 架构上构建 Linux 6.9。
从技术侧分析,该项目的价值,实质上体现的是从设计长期运行的Agents 的框架中学到的东西:如何编写测试来使Agent在没有人类监督的情况下保持正轨,如何构建工作,从而让多个Agent可以并行取得进展,以及这种方法的局限性在哪里。
在此基础上,他们进一步探索了把该模式适配普通学术实验室场景,以“可微分宇宙学玻尔兹曼求解器”为具体案例,验证了Claude Code在科学计算中的长效应用价值。
🥝🥝🥝
案例拆解:数天打造可微分玻尔兹曼求解器
玻尔兹曼求解器(如CLASS、CAMB)是宇宙学领域的核心基础工具,用于预测宇宙微波背景(CMB)的统计性质,通过联立演化早期宇宙中光子、重子、中微子与暗物质的耦合方程完成计算,是约束宇宙学模型的关键。而可微分版本的求解器,能在整个流程中传递梯度,大幅加快参数估计速度,其用JAX实现可天然获得自动微分与硬件加速支持。

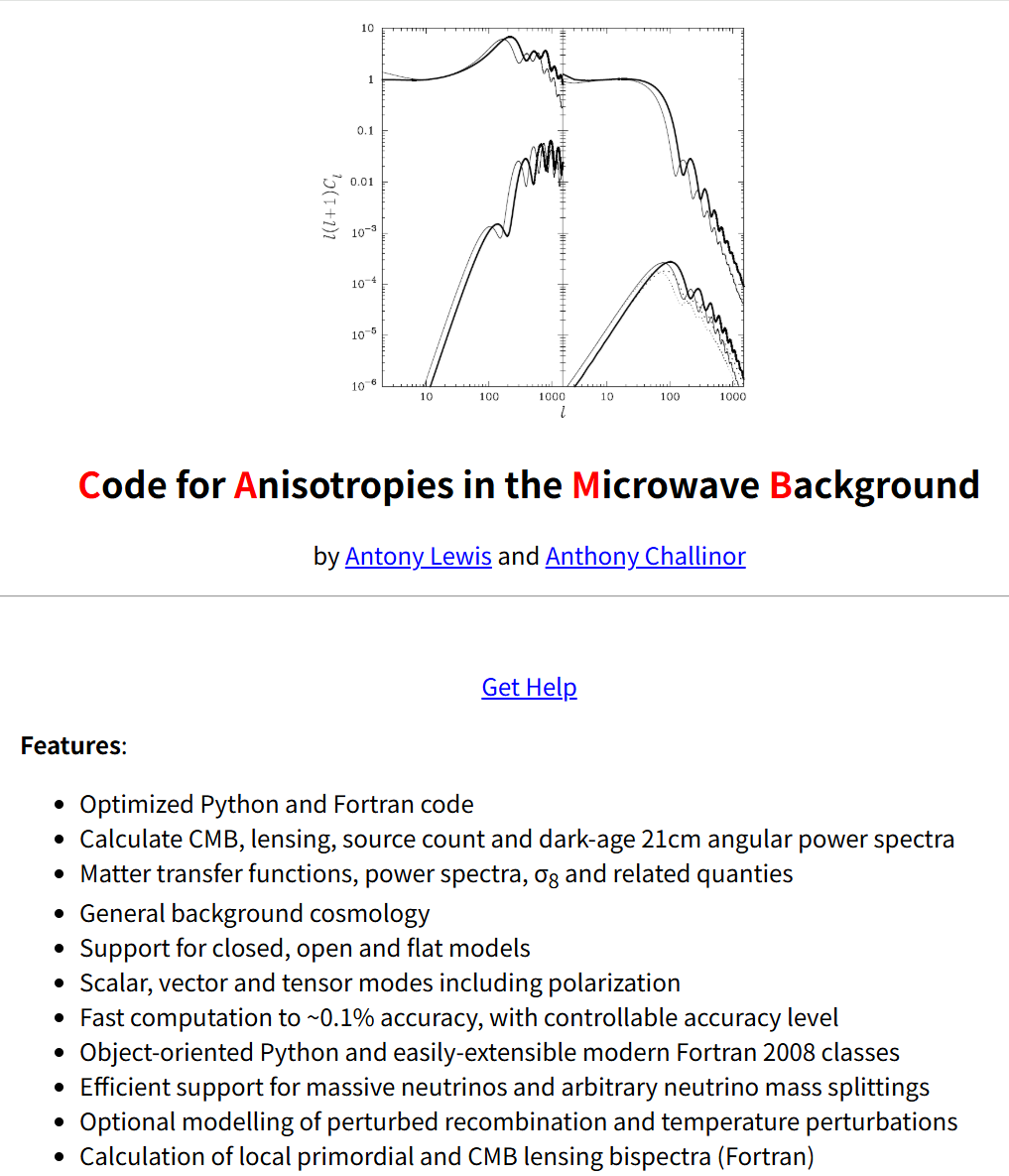
值得关注的是,该案例的实现过程,并未依赖宇宙学领域专家的深度介入——仅基于对相关工具和理论的大致了解,通过Claude智能体的自主工作,最终实现了与参考实现CLASS的亚百分级精度吻合。要知道,传统团队即便是实现CLASS的部分功能,也需投入数月到数年的人力成本。
与C编译器项目不同,玻尔兹曼求解器是高度耦合的流水线,早期宇宙复合过程中的微小数值误差或近似不当,都会逐级传导影响后续结果。因此,它更适合单个智能体串行执行,按需创建子智能体,并利用参考实现对差异进行二分定位,这也对智能体的调试能力和领域知识应用能力提出了更高要求。
该案例的计算环境基于搭载SLURM作业调度系统的高性能计算集群(HPC),但核心设计思路——进度文件、测试基准、带清晰规则的智能体提示——可适配任何Claude Code运行环境,具备极强的通用性。
🍊🍊🍊
四大核心设计:构建Claude长效科研工作流
要实现智能体的长效自主工作,关键在于搭建完善的流程框架,核心包含四大设计,既保障智能体的自主性,也确保任务推进的可控性。
1. 方案迭代:先本地打磨,再落地执行
核心是编写一份清晰的指令文件(CLAUDE.md),放置于项目根目录,明确项目交付物与相关背景。该文件将作为Claude的核心上下文,供其持续参考整体计划;同时,Claude可在执行过程中自行编辑该文件,动态更新后续方案,实现方案的自主迭代优化。
早期实验阶段写的CLAUDE.md地址:https://github.com/smsharma/clax/blob/6a6b2330cf25edded1bb31ec57a0091aa794a5d3/CLAUDE.md
以玻尔兹曼求解器项目为例,先明确三大高层目标:与CLASS完全功能对齐、全程可微分、核心科学指标与CLASS偏差控制在0.1%以内(参考两大经典玻尔兹曼代码的典型吻合水平),再通过与Claude反复迭代,形成可行方案后正式启动。
2. 持久记忆:用进度日志留存过程痕迹
为解决智能体跨会话记忆丢失的问题,需搭建持久化记忆系统——进度文件(CHANGELOG.md),相当于智能体的实验记录本。规范的进度日志需包含当前状态、已完成任务、失败方案及原因、关键节点精度表、已知局限五大核心内容。
其中,失败方案的记录尤为关键,可避免智能体在后续会话中反复踩入同一死胡同。典型记录如:“尝试用Tsit5求解扰动常微分方程,系统刚性过强,已切换为Kvaerno5”。

3. 测试基准:为智能体提供“进度标尺”
长效自主科研工作的核心,在于让智能体能够自主判断“是否在进步”。
这就需要搭建明确的测试基准,可为参考实现、可量化目标或现成测试套件,同时可要求智能体在开发过程中持续扩充测试集并运行测试,避免功能回退。
在玻尔兹曼求解器案例中,即以CLASS的C语言源码为参考,让Claude自主构建并持续运行单元测试,确保每一步开发都符合精度要求。
具体项目参考:https://github.com/lesgourg/class_public
4. 协同管理:用Git实现无侵入监控
Git可作为监控与协同智能体进度的理想工具,通过设定规则,让智能体在完成每一段有意义的工作后自动提交(commit)并推送(push)。此举不仅可在出错时回溯历史,确保本地可见进度,还能避免因计算资源配额中途耗尽导致的工作丢失。
典型规则可设定为:每完成一段有效工作就提交并推送;每次提交前运行测试命令;绝不提交破坏已有通过测试的代码。如需干预智能体,可通过SSH登录集群手动操作,或让本地Claude Code实例代为执行命令,便捷高效。
💜💜💜
执行循环与调度优化:让智能体“不偷懒、不跑偏”
智能体的长效运行,还需搭建合理的执行循环与调度机制,确保任务持续推进、不偏离目标。
执行流程可分为三步:先在本地迭代方案,形成完善的CLAUDE.md;在计算节点的tmux等终端多路复用工具中启动Claude Code会话;告知智能体代码库位置后,即可实现无人值守运行。由于会话运行在tmux中,可随时断开连接,仅偶尔查看进度即可。
在HPC集群中,可通过SLURM申请节点,借助作业脚本启动tmux与Claude Code。
#!/bin/bash
#SBATCH --job-name=claude-agent
#SBATCH --partition=GPU-shared
#SBATCH --gres=gpu:h100-32:1
#SBATCH --time=48:00:00
#SBATCH --output=agent_%j.log
cd $PROJECT/my-solver
source .venv/bin/activate
export TERM=xterm-256color
tmux new-session -d -s claude "claude; exec bash"
tmux wait-for claude任务启动后可随时接入会话下达指令、查看进度,灵活便捷。
srun --jobid=JOBID --overlap --pty tmux attach -t claude针对当前模型可能出现的“智能体惰性”——面对复杂任务找借口提前中止,可采用Ralph循环调度模式。
参考:https://ghuntley.com/loop/
该模式本质是一个for循环,当智能体声称完成任务时,将其拉回上下文并追问确认,促使其持续工作直至达到目标。
类似模式还有GSD及其领域变种,以及Claude Code原生的/loop命令,可根据需求灵活选用。
参考:https://github.com/gsd-build/get-shit-done
😂😂😂 , BTW, 这是个很有意思的开发者开源的项目:
💙💙💙
成果与启示:AI重构科研的时间维度
Claude项目还带来一个意外价值:通过查看智能体的Git提交历史,可实现对陌生领域知识的高效学习。提交日志的过程更像严谨的实验记录。虽然最终得到的求解器还达不到生产级标准,但它有效证明,由agent驱动的开发可以将研究人员数月甚至数年的工作压缩到几天之内。
🌸🌸🌸
结语
Claude长效智能体工作流在科学计算领域的应用,不仅打破了传统科研的效率瓶颈,更重新定义了科研工作的模式——无需领域专家全程介入,只需搭建完善的流程框架,就能让智能体自主完成复杂科研任务。
随着大模型能力的持续升级,智能体在科研领域的应用将更加广泛,有望推动更多学科实现突破性进展,让科研创新变得更高效、更普惠。未来,或许每一个科研实验室,都将拥有一支“永不疲倦”的AI智能体科研团队。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号