Meta-Harness 的技术深读:为什么 Harness 搜索需要完整的执行轨迹

Meta-Harness 的技术深读:为什么 Harness 搜索需要完整的执行轨迹

乐小野
发布于 2026-06-01 21:36:10
发布于 2026-06-01 21:36:10
最近业界对 Harness的关注异常高涨。问题是,Harness 至今基本靠手工调参——工程师盯着 bad case,改几行 Prompt,跑一遍测试,不行再改。我们思考下,有没有可能让这个过程自动化?

斯坦福、MIT 等团队给出的答案是 Meta-Harness。不靠压缩摘要,也不靠固定变异算子,而是让一个编码 Agent 直接翻看所有历史 Harness 的完整源代码和执行轨迹,自己诊断失败原因、自己写新版本。在文本分类、奥数推理、智能体编程三个任务上,自动搜出来的 Harness 全面超越人类手工设计。
今天我们重点从算法设计、搜索空间选择、执行轨迹的不可替代性三个角度,解读下 Meta-Harness 为什么能 work,以及它对 Harness 工程自动化的启示。
论文:Meta-Harness: End-to-End Optimization of Model Harnesses 作者:Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, Chelsea Finn 机构:Stanford, MIT, KRAFTON 项目页:https://yoonholee.com/meta-harness/
1. 问题背景:Harness 工程的自动化困境
在固定基座模型的前提下,改变模型外部的 Harness(即决定信息存储、检索、呈现方式的代码)可以造成高达 6 倍 的性能差异 [Tian et al., 2026]。这一现象已被 OpenAI 和 Anthropic 的工程团队反复确认,但 Harness 的设计目前仍以手工迭代为主——观察失败案例、调整启发式规则、在小范围内测试。
Harness 优化天然具有长程依赖性:早期关于存储什么信息、何时检索的决策,会在几十步推理之后才显露出对最终结果的影响。因此,对 Harness 的修改很难通过局部反馈来有效指导。
一个直观的想法是将近年来发展的文本优化器(如 OPRO、TextGrad、GEPA、AlphaEvolve 等)直接应用于 Harness 优化。然而,论文 Table 1 揭示了一个关键的不匹配:

这些方法在单次评估中可利用的反馈上下文最多只有约 30,000 tokens,而 Harness 搜索中一次完整评估产生的诊断信息(源代码、执行轨迹、中间状态、模型输出)可达 10,000,000 tokens 量级。
压缩反馈的机制——无论是仅保留分数、依赖摘要,还是滑动窗口——都会系统性丢失追溯失败根源所需的结构化信息。
Meta-Harness 的设计动机即源于此:如果反馈信息不能被压缩,那就让优化器自己通过文件系统去选择性读取。
2. 形式化目标与搜索框架
对于一个固定的语言模型 和任务分布 ,Harness 在执行任务实例 时会生成一条轨迹 ,并最终获得奖励 。Harness 优化的目标是:
当存在多个目标(例如准确率与上下文开销)时,则以帕累托前沿作为评估依据。
Meta-Harness 的搜索过程由三个组件构成:
- 1. 一个编码 Agent 作为 Proposer(论文使用 Claude Code 搭载 Opus 4.6),具备文件系统读写和命令行工具调用能力。
- 2. 一个持续增长的文件系统,其中每个已评估的 Harness 对应一个目录,存放其源代码、评估分数以及完整的执行轨迹。
- 3. 一个外部评估器,对 Proposer 生成的候选 Harness 执行评估并写回结果。
与现有文本优化器不同,Meta-Harness 的外层循环几乎不包含人工设计的搜索启发式:没有固定的变异算子,没有预设的父代选择规则。Proposer 自行决定要检查哪些历史记录、诊断哪些失败模式、进行何种粒度的修改(局部修补或结构性重写)。这种设计将优化能力完全绑定在 Agent 的代码理解和推理能力上,意味着随着底层编码模型的进步,搜索效果将同步提升。
3. 为什么代码空间搜索比文本空间更适合 Harness
Harness 本质上是可执行程序。在代码空间中进行搜索有三个结构性的优势:
- 1. 修改粒度匹配问题结构。Harness 的修改通常是算法性的——改变检索策略、调整记忆更新逻辑、重构控制流——而非调整几个短语的措辞。代码作为表达载体天然适合这类修改。
- 2. 编码模型的先验偏置。在代码数据上训练的模型倾向于生成连贯的、可复用的算法,而非针对特定样本的硬编码补丁。这种偏置对泛化有利(后文 OOD 实验结果支持这一点)。
- 3. 可执行性与可验证性。代码空间中的每个候选都可以直接运行,其行为可被完整记录,形成可供未来诊断的轨迹。
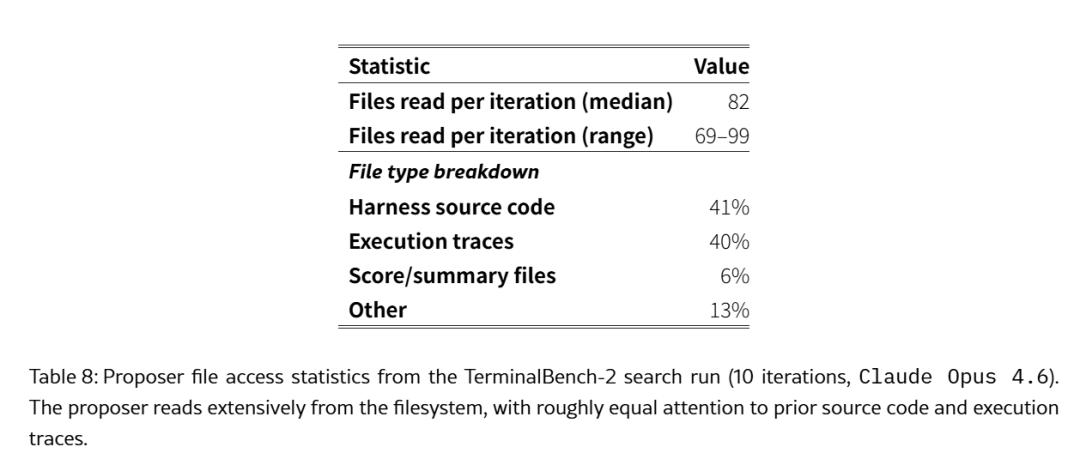
从 Appendix A 提供的 Proposer 文件访问统计来看,在 TerminalBench-2 的 10 轮搜索中,Proposer 每轮读取的中位文件数为 82 个(范围 69–99),其中约 41% 是历史 Harness 的源代码,40% 是执行轨迹,仅 6% 是分数摘要。这表明 Proposer 的访问模式显著非马尔可夫:它并非只依赖最近一次评估的结果,而是在多轮迭代中持续回溯更早的候选及其轨迹。
4. 关键消融:执行轨迹是不可替代的信号
Table 3 展示了一项决定性消融实验(在线文本分类任务)。在控制其他变量相同的前提下,比较三种 Proposer 接口:
接口类型 | 中位准确率 | 最优准确率 |
|---|---|---|
仅分数 | 34.6% | 41.3% |
分数 + LLM 摘要 | 34.9% | 38.7% |
完整 Meta-Harness 接口(含执行轨迹) | 50.0% | 56.7% |
摘要条件不仅未能恢复缺失的信号,甚至在最优值上略低于仅分数条件(38.7 vs 41.3),提示摘要可能压缩掉了诊断性细节。执行轨迹的原始信息——每一步的模型输入输出、工具调用、状态变更——才是 Proposer 能够进行有效归因的关键。
5. 搜索轨迹中的因果推理:一个定性证据
Appendix A.2 从 TerminalBench-2 的一次实际搜索中提取了一段值得注意的交互记录。在早期迭代中,Proposer 同时修改了终端标记剥离(结构性修复)和提示模板(清理指令),结果性能显著下降。Proposer 在第三轮迭代时自行推理出:
“回归的根本原因并非结构修复本身,而是提示模板中新增的清理指令导致 Agent 在任务完成前删除了必要状态。……两个结构性修复被有害的提示修改所混淆。”
此后 Proposer 回退提示模板,仅保留结构修复,损失大幅收窄(从 -5.6pp 收窄至 -1.1pp)。在后续几轮中,Proposer 继续试探完成流程和提示语言,均观察到脆弱性,最终在第七轮转为纯加性修改(环境快照引导),成为该次搜索中的最优候选。
这种识别混淆变量 → 设计对照测试 → 根据结果调整策略的行为模式,只有在 Agent 能够完整回溯历史执行轨迹的条件下才能实现。压缩反馈的优化器不具备构建此类因果假说的信息基础。
6. 实验结果中的几个技术观察
6.1 在线文本分类:帕累托前沿的自动发现
在 LawBench、Symptom2Disease、USPTO-50k 三个数据集上,Meta-Harness 搜索出的最优 Harness 比手工设计的 ACE 高 7.7 个百分点,同时使用的上下文 token 仅为 ACE 的 四分之一(Table 2)。
更重要的是,Figure 3 显示 Meta-Harness 能够生成一条平滑的准确率-上下文开销帕累托前沿,这意味着可以在不修改搜索目标的前提下,按需选择成本与精度的平衡点。
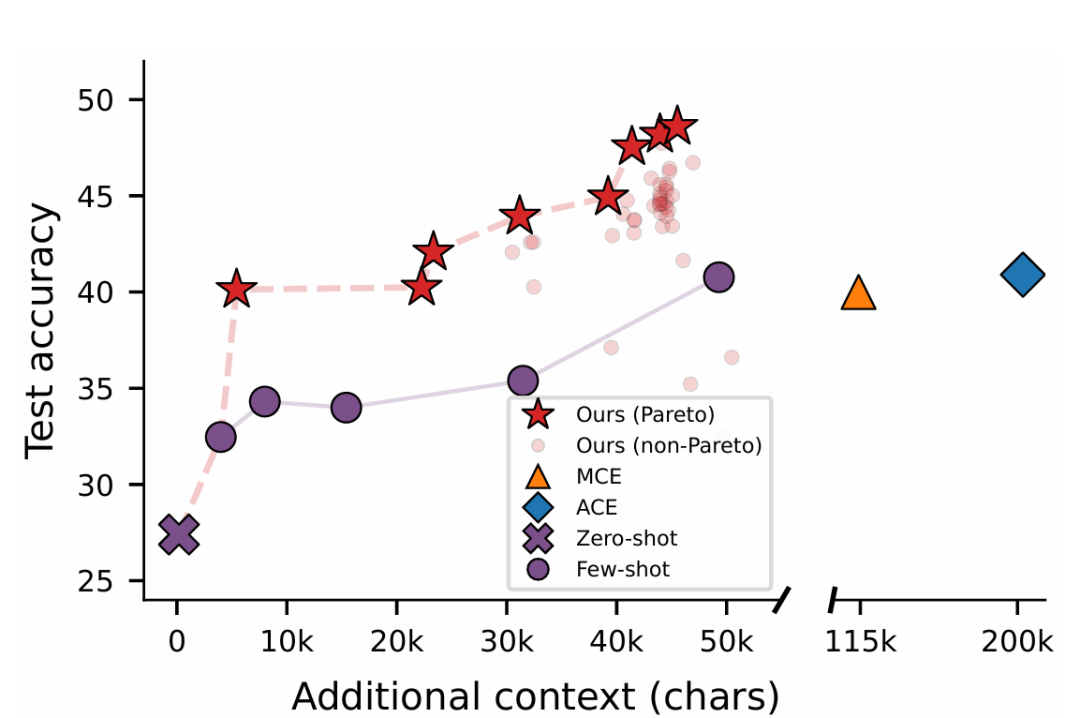
与文本优化器的对比(Table 4)显示,Meta-Harness 在 4 次评估 内就达到了 OpenEvolve 和 TTT-Discover 在 60 次评估后的准确率水平,最终精度高出 10 个百分点以上。这种效率差异直接印证了完整历史访问对搜索效率的提升。

6.2 数学推理:跨模型的检索策略迁移
实验在 200 道 IMO 级别 问题上进行(IMO-AnswerBench、IMO-ProofBench、ArXivMath),检索语料为 53 万道经过严格去污的题目。搜索出的 Harness 是一个四路路由的 BM25 程序(Figure 8),其路由谓词、重排序项、去重阈值均由外层搜索在 40 轮迭代中自主确定。
关键结果见 Table 6:同一套检索策略在 五个未参与搜索的模型(GPT-5.4-nano、GPT-5.4-mini、Gemini-3.1-Flash-Lite、Gemini-3-Flash、GPT-OSS-20B)上均获得正向提升,平均绝对增益 4.7 个百分点。
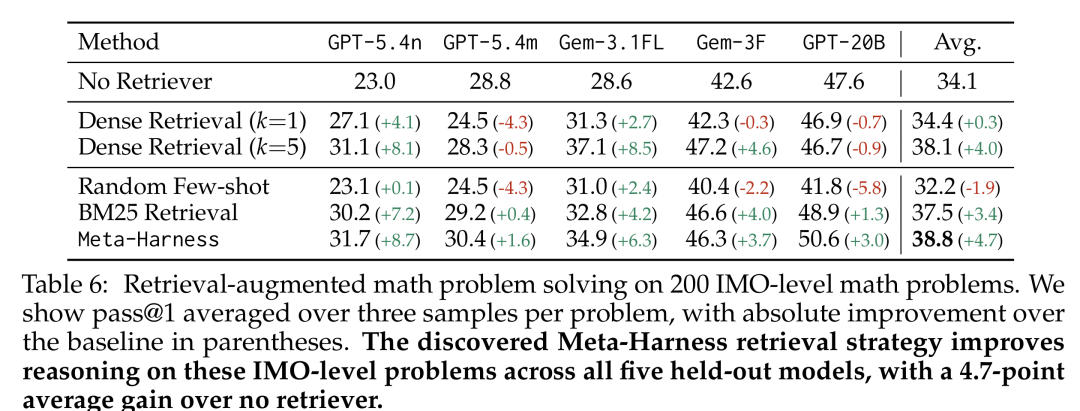
对比之下,Dense 检索在某些模型上出现明显退化(例如 Gemini-3-Flash 上仅 +0.3pp),随机 Few-shot 的跨模型稳定性更差。这表明代码空间中搜索出的 Harness 捕获的是任务结构的通用信息利用模式,而非对特定模型行为的过拟合。
6.3 TerminalBench-2:在竞争性榜单上的表现
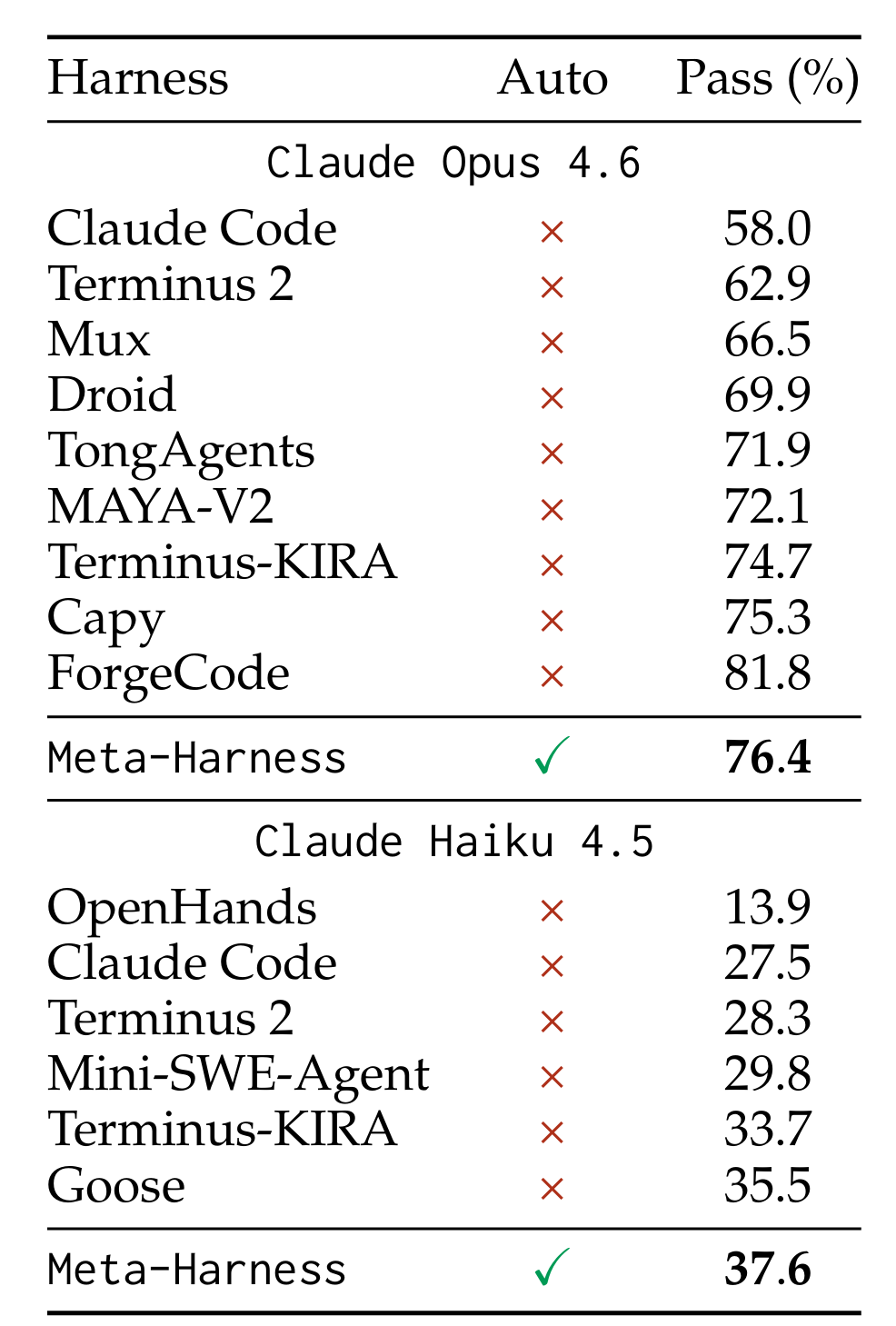
TerminalBench-2 是一个 89 项任务的终端环境智能体基准,目前处于多方公开竞争状态。从 Terminus-KIRA(64.4%)初始化,经 10 轮搜索后:
- • 在 Opus 4.6 上达到 76.4%,排名该模型下的第二(仅次于无法完全复现的 ForgeCode);
- • 在 Haiku 4.5 上达到 37.6%,位列该模型所有已报告 Agent 的 第一(Table 7)。
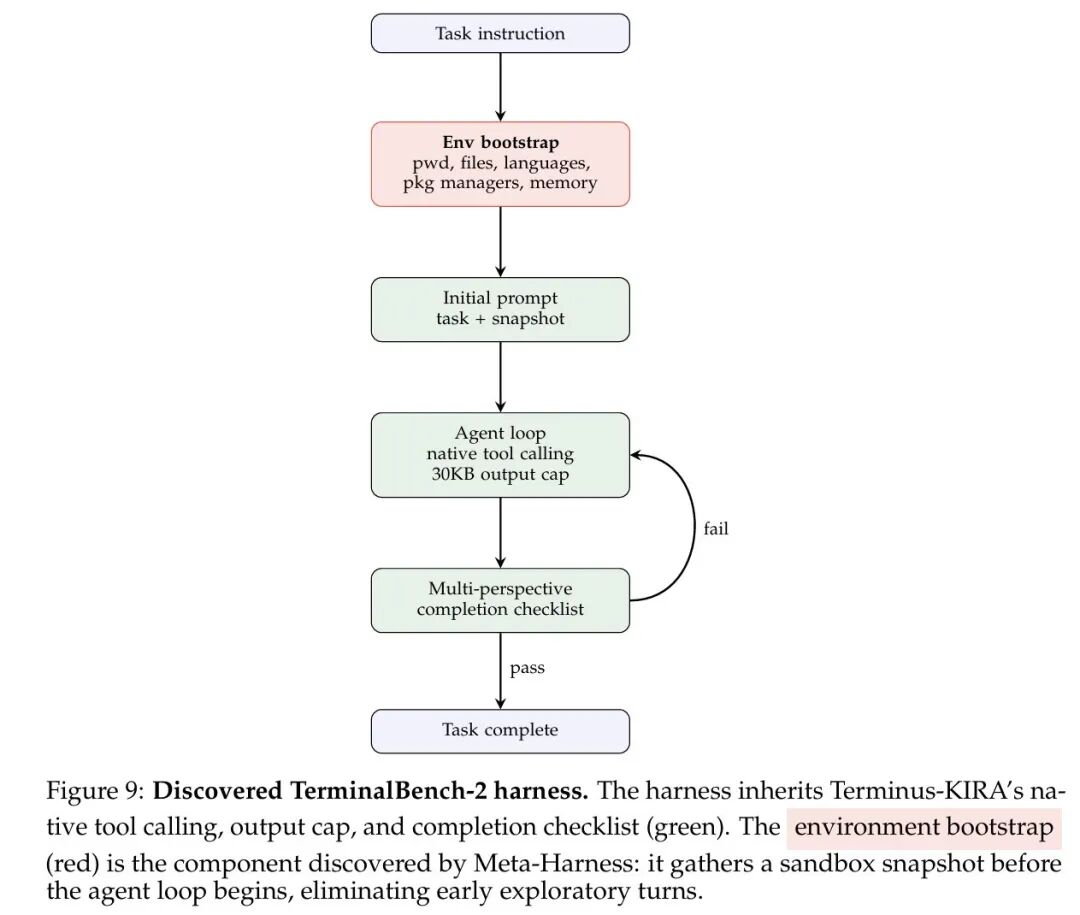
性能提升主要来自 7 个特定任务(原型类、路径追踪类),这些任务的共性是环境工具链不确定——Agent 需要首先探测环境才能制定有效策略。Meta-Harness 发现的环境快照引导机制(Figure 9)在循环开始前注入系统状态信息,节约了 2–4 个探索性轮次,在轮次预算紧张的任务中成为决定性因素。
7. 泛化性检验与过拟合控制
代码空间搜索的一个潜在风险是对搜索集过拟合(例如生成针对特定样本 ID 的硬编码分支)。论文通过两个方式验证泛化性:
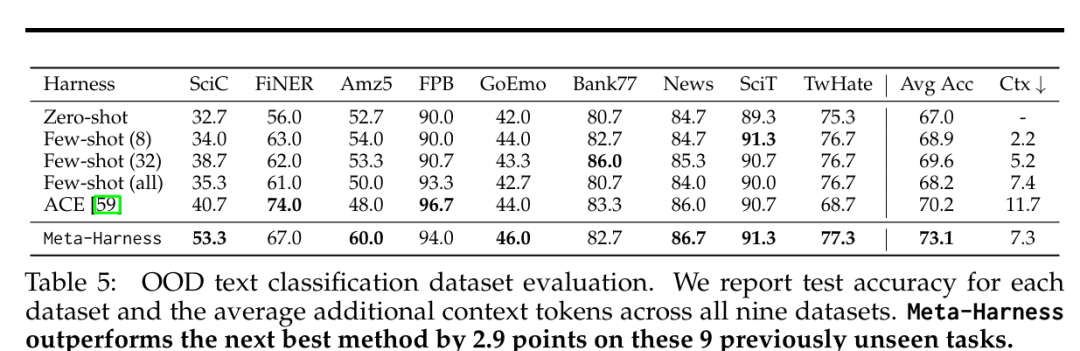
- 1. OOD 文本分类数据集(Table 5)。在 9 个未参与搜索的分类任务上,Meta-Harness 平均准确率 73.1%,比 ACE 高 2.9 个百分点,在 6/9 任务上取得最高分。值得注意的是,Few-shot(all)在 7/9 任务上出现性能下降,说明简单地增加上下文并非有效策略。
- 2. 数学推理中的跨模型迁移。前文已述,搜索出的 Harness 在所有五个未见过模型上均提升,且提升幅度超过手工基线。
此外,代码空间的可审查性提供了另一种防护:任何对任务特定字符串的泄漏(如硬编码类名)均可通过正则审计或人工检查发现。论文在 TerminalBench 实验中报告进行了此类检查,未发现泄漏。
8. 工程实践层面的建议
Appendix D 中提供了一些在实现 Meta-Harness 风格搜索时的重要经验,其中两条值得特别关注:
- 1. 日志格式的可查询性。评估代码输出的日志应采用机器可读格式(如 JSON),并以一致的层次结构和命名规范存储。这直接影响 Proposer 通过
grep等工具检索历史信息的效率。论文还建议提供一个小型 CLI 用于列出帕累托前沿、对比不同候选的代码差异等,这与编码 Agent 的训练工作流高度一致。 - 2. 轻量级验证。在运行昂贵的全量评估之前,用一个极小的验证脚本测试候选 Harness 的基本可导入性和接口正确性。这能过滤掉大部分语法错误或接口不匹配的候选,将无效候选的成本压缩到接近于零。
9. 局限与延伸
论文的结论受限于以下因素,也指向后续研究方向:
- 1. Proposer 能力依赖性。所有实验均使用 Claude Code + Opus 4.6 作为 Proposer。不同编码 Agent 的能力差异如何影响搜索效果,目前缺乏系统性比较。一个合理的推测是,对于推理能力较弱的 Proposer,搜索收益可能显著收窄。
- 2. 评估成本与预算分配。虽然论文强调 Meta-Harness 在相同评估预算下效率更高,但单次评估本身可能是昂贵的(例如 TerminalBench)。如何在有限预算下选择搜索集规模、评估样本数量以及候选数量,仍是一个需要根据领域特性调整的超参数。
- 3. 与权重更新的协同。论文在结尾处提出一个自然延伸:能否让 Harness 搜索与模型权重更新协同进行?这相当于将元学习(Meta-Learning)的适应机制从参数空间部分迁移到上下文管理空间,可能开辟新的优化维度。
10. 总结
Meta-Harness 的核心贡献不在于提出了一个新的搜索算法,而在于识别并系统性地解决了一个被现有文本优化器忽视的瓶颈:长程 Harness 优化需要完整的、未压缩的执行轨迹作为反馈信号。
通过将搜索构建为编码 Agent 对文件系统的自主探索,该方法在三个任务域上均取得了超越手工设计和现有优化器的结果,并展现出令人信服的跨任务、跨模型泛化能力。
对于 Harness 工程这一日益重要的实践领域,Meta-Harness 提供了一条从手工迭代迈向自动化搜索的可行路径。其设计的极简性(外层循环几乎不含启发式)也意味着,随着底层编码 Agent 能力的持续增强,该方法的收益曲线仍处于上升通道中。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号