【养虾那些事 06】每发1条消息,偷偷扣你「 10 倍」的钱?价值千元的小白降token手册

【养虾那些事 06】每发1条消息,偷偷扣你「 10 倍」的钱?价值千元的小白降token手册

用户1589488
发布于 2026-06-02 10:23:01
发布于 2026-06-02 10:23:01
对于小龙虾,相信大家都有切身的痛感 —— “实在是太烧token了”。
- 100万的免费token三四个问题用完,
- coding plan不到一天就能把一周用量烧光。
今天,「养虾那些事」我们来深度透视token如何被消耗的,有什么方法解决“养不起”虾的问题。
一、先看一个反直觉的事实
你以为 Token 消耗 = 你打了多少字 + AI 回了多少字。
错。你看到的部分,只占总消耗的大约 10%。
剩下 90% 是什么?每一轮对话开始前,系统会偷偷注入一堆东西:
注入内容 | 每轮消耗 | 你能看到吗? |
|---|---|---|
🔧 System Prompt(系统提示词) | ~2,000 tokens | ❌ 看不到 |
📋 Always-on Rules(项目规则) | ~2,000-6,000 tokens | ❌ 看不到 |
🧠 Memory(记忆条目) | ~800-3,000 tokens | ❌ 看不到 |
📚 Knowledge(知识库入口) | 按需,但入口可能很大 | ❌ 看不到 |
💬 你输入的那句话 | ~50-200 tokens | ✅ 看得到 |
你发了 1 条消息,付了 10条消息的钱。而且你不知道另外 9 条是什么。
二、四层诊断:按 ROI 从高到低切
一句话总结方法论:先治每轮都在收的"固定税",再治偶尔爆发的"变量开销"。
层级 | 是什么 | 为什么先治它 | 预期收益 |
|---|---|---|---|
L1 Rules | 项目规则文件 | 每轮都注入,优化一次后续每轮受益 | 800~2,000/轮 |
L2 Memory | Agent 记忆条目 | 同上,最容易无声膨胀 | 500~1,500/轮 |
L3 Knowledge | 知识库文件 | 入口文件太大 ≈ 始终加载 | 1,000~3,000/调用 |
L4 Behavior | 运行时行为 | 全量读大文件、不压缩上下文 | 变量,可省数万 |
核心原则:身份 always-on,行为 on-demand。 只有定义 Agent「我是谁」的规则才配始终加载。「收到消息怎么归档」「文件怎么命名」这种行为规范,用触发词按需加载就够了。 类比:出门不需要同时带护照、驾照、身份证、港澳通行证。日常带身份证就够。
三、实战:我怎么砍掉 30% 的固定开销
背景:OpenClaw 是一个跑了 3 个月的 AI Agent 体系(Rules + Memory + Knowledge + Skills),从未做过系统性清理。
-30%
每轮固定开销:11,500 → 8,000 tokens
手术一:合并重复规则 — 省 ~800/轮
🔍 诊断
两个 Rule 文件内容重叠 >80%,系统每轮加载两遍。 操作:删一个。纯粹的"说了两遍废话"问题。
手术二:3 条 Rules 降级为按需加载 — 省 ~1,200/轮
🔍 诊断
6 条 Rule 全部 always-on。但「企微通知」「文件归档」「双写同步」这三条只在特定场景需要。 操作:改为 on-demand + 加触发关键词。需要时自动唤回,不需要时不交税。 降级 ≠ 删除——功能没丢,只是不在每轮都付钱了。
手术三:Memory 瘦身 — 省 ~1,500/轮
🔍 诊断
记忆从十几条膨胀到 20+,其中不少已过时或已被 Rule 覆盖。每轮照样注入。
Memory 清理决策表:
类型 | 处理 | 理由 |
|---|---|---|
已被 Rule 覆盖 | 删 | Rule 每轮注入,Memory 再存一份 = 双重计费 |
一次性事件("某天删了XX") | 删 | 已无行动指导价值 |
过时信息 | 删 | 误导 > 不记 |
经验教训(持续有价值) | 留 | 用 [经验] 标题结构化 |
用户红线 | 留 | 不可删除 |
双重计费是最隐蔽的浪费—— Rule 说了一遍,Memory 又存了一遍。 两者在不同时间创建,不对比就发现不了。
手术四:知识库入口拆分
❌ 优化前
KNOWLEDGE-MAP.md (863行)每次知识调用都全量加载= 查一个电话号码 把整本黄页带在身上✅ 优化后
KNOWLEDGE-MAP.md (200行)只保留路由表(场景→文件映射)├── CROSS-DOMAIN-LINKS.md ├── BOOK-INDEX.md └── knowledge/*.md 按需加载手术五:Rules 内容精简 + 行为优化
❌ 全量读取(~3,000 tokens)
read_file("large_file.py")# 2000 行全部塞入上下文✅ 精准读取(~75 tokens)
read_file("large_file.py", offset=100, limit=50)# 只读需要的 50 行其他行为优化:
场景 | 优化前 | 优化后 |
|---|---|---|
长对话 | 等系统自动压缩 | >10 轮主动 /compact |
大规模搜索 | 主 Agent 逐个搜 | 子 Agent 分流 |
Skill 加载 | 同时加载多个 | 按需加载,用完不驻留 |
总账
指标 | 优化前 | 优化后 | 变化 |
|---|---|---|---|
Always-on Rules | 7 条 | 4 条 | -3 条 |
Memory 条目 | 20+ 条 | ~13 条 | -7 条 |
每轮固定开销 | ~11,500 | ~8,000 | -30% |
10轮累计 | ~115,000 | ~80,000 | 省 ~35,000 |
知识库入口 | 863 行 | 200 行 | -77% |
四、如何快速使用
发送Skill给openclaw,让它安装后运行审计就行,如下:
https://clawhub.ai/louisecxqiu-glitch/token-use-optimizer
运行优化技能:
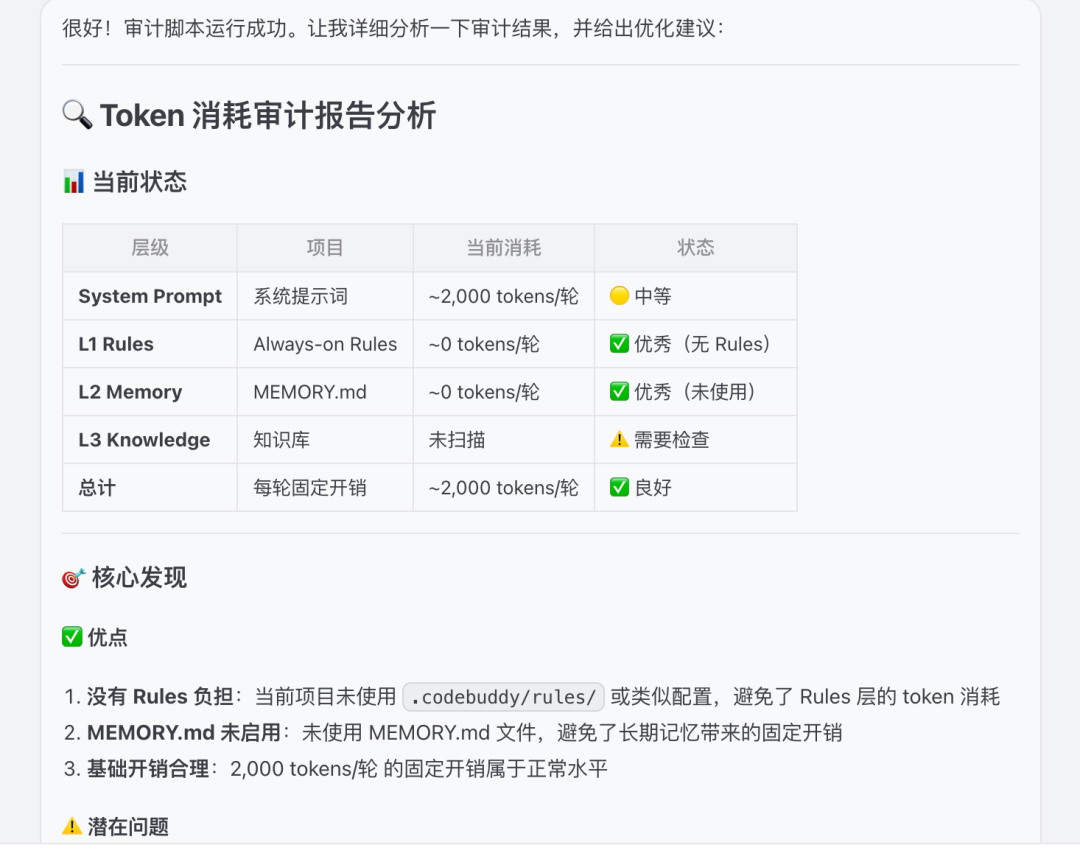
五、踩坑经验(帮你少走弯路)
🐸 温水煮青蛙 — Token 膨胀是渐进的。每次加一条 rule、一条 memory 都觉得无所谓。3 个月后回头看,吓一跳。必须定期审计。
💰 双重计费最隐蔽 — Memory 和 Rule 覆盖同一内容,这两者在不同时间创建,不交叉比对就发现不了。
🔀 降级 ≠ 删除 — Requestable rule 在需要时仍能被触发词自动唤回。降级不丢功能,只是不在每轮交税。很多人不敢降级,是因为不知道这个机制。
📏 先算 ROI 再动手 — 不要为了优化而优化。先估算每层的潜在收益,从 ROI 最高的层开始。Rules 和 Memory 是每轮注入的,永远先治它们。
🪞 手术后的反思:省钱的本质是什么
省 Token 的本质不是省钱,是治疗一种"信息肥胖症"。
人会信息过载,AI 也会。区别是人过载了效率下降,AI 过载了让你大量付钱。
Token 优化不是"没钱了才做的事",而是一种日常卫生习惯——就像定期清理手机相册、整理桌面。
🦞 AI Agent 的四条卫生习惯
1. 记忆:定期清理,过时的删、重复的合、落盘的去重
2. 规则:区分"必须常驻"和"按需加载"
3. 知识:分层索引,不要全量加载
4. 对话:一事一会话,做完就走
最反直觉的省钱方式 不是砍预算,而是看清楚你到底在付什么。
龙虾是好龙虾。但你得定期给它做体检
🦞 觉得有用?先收藏起来慢慢看。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号