任意输入任意输出,AI的世界模型时代来了

任意输入任意输出,AI的世界模型时代来了

老周聊架构
发布于 2026-06-02 13:33:05
发布于 2026-06-02 13:33:05
文字进去,视频出来。图片进去,3D 模型出来。视频进去,代码出来。你甚至可以给它一段视频,让它预测"接下来会发生什么"。
这不是科幻电影里的设定,这是 Google 上周发布的 Gemini Omni 的实际能力。
Google 把它定义为"世界理解的一次飞跃"。翻译成人话就是:AI 不仅能"看懂"世界,还能"想象"世界接下来会变成什么样。
与此同时,OpenAI、Kakao、ElevenLabs 本周宣布采用 Google 的 SynthID 水印技术——没错,连竞争对手都在用 Google 的技术来给 AI 生成内容打"防伪标签"。
NVIDIA 更早之前就已经加入了这个阵营。
当所有竞争对手联合起来用你的技术做标准,这说明什么?说明这个问题比竞争本身更紧迫。
今天拆开来看,多模态生成到底走到了哪一步,"世界模型"是什么概念,以及——为什么 AI 水印比你想的重要得多。
一、Gemini Omni:从"理解"到"创造"的跨越
多模态模型的三个阶段
回顾一下多模态 AI 的发展路径:
- 阶段一:单模态理解。 GPT-3 只懂文字,DALL-E 只会画画,Whisper 只能听声音。每个模型都是"偏科生"。
- 阶段二:多模态理解。 GPT-4V 能看图说话,Gemini 1.5 能理解视频。模型变成了"全科生",但只会考试(理解),不会做实验(生成)。
- 阶段三:多模态生成。 Gemini Omni 能从任意模态输入,生成任意模态输出。不仅会考试,还会做实验、写论文、画图表。全能选手。
Gemini Omni 的"任意到任意"(any-to-any)能力具体意味着什么?
输入端: 文本、图片、视频、音频、代码——任意组合都能接受。
输出端: 文本、图片、视频、音频、代码——任意组合都能生成。
关键突破: 这不是把 5 个模型拼在一起。Gemini Omni 是一个统一模型,内部用同一套表示空间处理所有模态。就像一个真正的"通才",不是 5 个专家坐在一起开会,而是一个人同时精通 5 个领域。
为什么"统一模型"比"拼接模型"强?
以前做多模态的方式是"流水线拼接":
1 文字 → 文本模型理解 → 传给图像模型 → 生成图片问题是:信息在传递过程中会损失。 文本模型觉得重要的细节,图像模型可能完全忽略。
Gemini Omni 的方式是"端到端统一":
1 任意输入 → 统一理解空间 → 任意输出所有信息在同一个表示空间中流动,不存在"翻译损失"。
举个例子:你给模型一段做菜的视频,让它生成一个分步教程。拼接模型会先用视频模型提取关键帧,再用文本模型写描述,最后拼成文档——可能漏掉"翻炒时要不断颠锅"这种视觉细节。统一模型直接在同一个表示空间里理解视频的每一帧,生成的教程会包含你注意不到的操作细节。
二、"世界模型":AI 的物理直觉
什么是世界模型?
Google 把 Gemini Omni 定位为世界理解的飞跃。这个概念背后,是 AI 领域一个越来越重要的方向——世界模型(World Model)。
世界模型的核心思想很简单:让 AI 在"脑子里"模拟物理世界的运行规律。
人类天生就有世界模型。你把一个杯子推到桌子边缘,不用看结果就知道它会掉下去。你看到一个人抬起手,你能预测他接下来可能要挥手或者拿东西。
这种"物理直觉"是人类从小通过观察世界学到的。AI 以前没有这个能力——它能识别杯子,但不知道杯子会掉。
世界模型就是要给 AI 装上这个"物理直觉引擎"。

世界模型概念图
世界模型的三层能力
第一层:物理预测。 给一张图片或一段视频的前几帧,模型能预测"接下来会发生什么"。球会弹到哪里?水会怎么流?这辆车会往哪个方向转?
第二层:因果推理。 不仅预测"会发生什么",还理解"为什么会发生"。杯子掉下去是因为重力,水流变快是因为管道变窄。理解因果关系,才能在新场景中做出正确判断。
第三层:反事实想象。 "如果我没有推杯子,它就不会掉"——这种反事实推理能力是人类智能的核心,也是世界模型的终极目标。
Gemini Omni 目前大约处在第一层到第二层之间。它能从视频中学习物理世界的规律,能做一些简单的预测,但距离真正的因果推理和反事实想象还有距离。
世界模型 vs 大语言模型
维度 | 大语言模型(LLM) | 世界模型(World Model) |
|---|---|---|
学习材料 | 文本 | 视频 + 多模态数据 |
理解范围 | 语言知识 | 物理世界规律 |
核心能力 | 文本生成 | 物理预测 + 内容创造 |
"幻觉"后果 | 说错话 | 预测错物理现象 |
类比 | 读了所有书 | 看了所有视频 |
目标 | 数字世界的大脑 | 物理世界的大脑 |
如果说 LLM 是通过"读书"来理解世界,世界模型就是通过"看视频"来理解世界。
一个读了所有书的人可能知道"苹果会从树上掉下来"这个知识,但一个看了苹果掉落过程的人,理解的是掉落的速度、轨迹和落地时的反弹——前者是知识,后者是直觉。
三、SynthID:给 AI 内容盖个"防伪章"
为什么突然所有人都在搞水印?
本周最值得关注的行业动向不是哪家公司又发了个新模型,而是:OpenAI、Kakao、ElevenLabs 同时宣布采用 Google 的 SynthID 水印技术。
加上此前已经加入的 NVIDIA,这意味着全球最主要的 AI 内容生成厂商,正在形成一个跨公司的水印联盟。
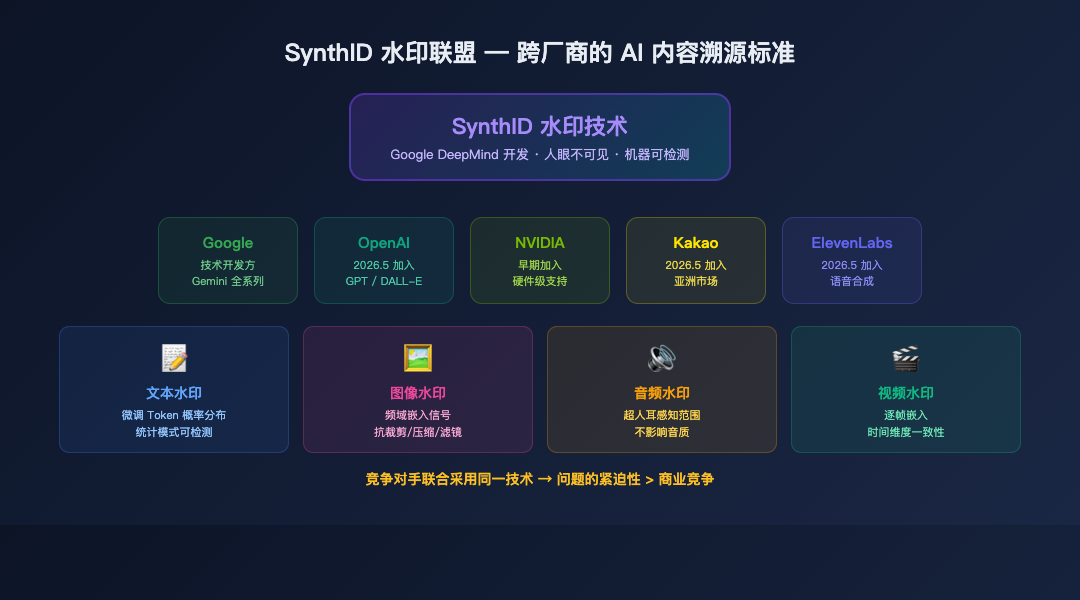
SynthID 水印生态
竞争对手联合采用同一家的技术,这在科技行业极为罕见。上一次出现类似的事情,可能要追溯到各浏览器厂商联合支持 Web 标准。
这说明"AI 内容溯源"的紧迫性,已经超过了商业竞争。
SynthID 是什么?
SynthID 是 Google DeepMind 开发的 AI 内容水印技术。核心原理:
在 AI 生成内容中嵌入人眼不可见但机器可检测的"数字指纹"。
具体来说:
- 文本水印: 在 Token 生成过程中微调概率分布,使得生成的文本在统计上具有可检测的模式。人类读不出来,但检测算法能识别。
- 图像水印: 在图像的频域中嵌入不可见的信号。即使图片被裁剪、压缩、加滤镜,水印仍然可以被检测到。
- 音频水印: 在音频信号中嵌入超出人耳感知范围的标记。
- 视频水印: 在每一帧中嵌入水印,同时保证时间维度的一致性。
为什么 AI 水印很难做?
AI 水印面临一个根本性的矛盾:水印越强,越容易被检测到;水印越强,也越容易影响内容质量。
这就像在一幅画上盖章——章盖得太小看不清,盖得太大影响画面。
SynthID 的技术突破在于:在不降低内容质量的前提下,实现高鲁棒性的水印。
但目前的技术仍然有局限:
- 可靠性约 99%,不是 100%——仍然有 1% 的误检率或漏检率
- 对抗攻击: 专门设计的对抗样本可以绕过水印检测
- 跨模型检测: 目前水印主要针对特定模型的输出设计,跨模型检测能力有限
这对行业意味着什么?
第一,AI 生成内容的"身份证"时代来了。
就像每张银行卡都有防伪芯片,未来每段 AI 生成的内容都会带有"数字身份证"。你看到一张图片,扫一下就知道它是不是 AI 生成的、用的是哪个模型、什么时候生成的。
第二,监管的基础设施正在成型。
各国都在立法监管 AI 生成内容(欧盟 AI Act、中国《生成式人工智能服务管理暂行办法》)。但监管的前提是能识别——如果分不清哪些是 AI 生成的,法律就是一纸空文。SynthID 联盟正在提供这个"识别"的基础设施。
第三,"眼见不再为实"成为常态。
当 AI 能生成以假乱真的图片、视频、音频时,"眼见为实"这个人类的基本认知模式被彻底颠覆。水印技术本质上是在重建这个信任——不是用眼睛判断,而是用算法判断。
四、从"理解世界"到"创造世界":范式转变
内容创作的三次革命
第一次:工具革命。 Photoshop、Premiere、AutoCAD——人类用数字工具替代了物理工具。设计师从画板搬到了电脑前。
第二次:模板革命。 Canva、剪映、Notion——降低了创作门槛。不会设计的人也能做出好看的图。
第三次:生成革命。 Gemini Omni、Sora、DALL-E 3——AI 直接生成内容。你只需要描述你想要什么,AI 来"创造"。
每一次革命都在降低"创意到产出"的距离。 第一次从 100 步降到 50 步,第二次从 50 步降到 10 步,第三次从 10 步降到 1 步——一句话描述,直接出成品。
"创造世界"的技术门槛
但"任意到任意"的生成能力,对算力和数据的要求是指数级增长的。
算力: 一个能处理所有模态的统一模型,参数量可能是纯文本模型的 5-10 倍。训练成本从几千万美元飙升到几亿美元。
数据: 需要大量的多模态对齐数据——同一个场景的文本描述、图片、视频、音频要能对应起来。这种高质量对齐数据极度稀缺。
推理成本: 生成一段 10 秒的视频,消耗的算力可能是生成一段 1000 字文本的 100-1000 倍。按照目前的定价,大规模商用的成本仍然很高。
这就是为什么目前只有 Google、OpenAI 这种级别的公司才能做"任意到任意"——不是技术壁垒,是钞票壁垒。
五、对技术人的三个判断
第一,多模态统一模型是 AI 的终局形态。
人类的认知就是多模态的——我们同时看、听、摸、闻,然后做出决策。AI 模型最终也会走向这种统一的多模态形态。Gemini Omni 是这个方向的先行者,但不会是唯一的参与者。
第二,世界模型将催生全新的应用品类。
当 AI 能"想象"物理世界的运行规律时,一批新应用会出现:AI 导演(描述剧情自动生成电影)、AI 建筑师(描述需求自动生成建筑设计)、AI 游戏引擎(实时生成游戏世界)。"创作"的定义会被彻底改写。
第三,AI 内容溯源是基础设施级的机会。
SynthID 联盟的形成说明,AI 内容溯源不是一个"锦上添花"的功能,而是一个基础设施级别的需求。就像 HTTPS 对互联网一样,AI 水印将成为所有 AI 生成内容的标配。这个领域目前还在早期,技术和标准都在快速演化。
写在最后
从"理解语言"到"理解世界",从"看懂图片"到"创造视频",AI 正在从"偏科生"进化成"全能选手"。
Gemini Omni 的发布标志着一个转折点:AI 的能力边界,从"理解"扩展到了"创造"。
但"创造"的能力越强,"鉴别"的需求就越大。SynthID 联盟的出现,本质上是行业在为"AI 无处不在"的未来修建信任基础设施。
就像互联网早期,大家先疯狂建网站,然后才想起来要搞 HTTPS 加密。AI 行业也在经历同样的路径——先疯狂生成内容,然后才想起来要搞水印溯源。
不同的是,这一次行业学聪明了,没等出大事就开始建标准了。
希望这个"聪明"能持续下去。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号