GEM记忆执行架构设计与实践——对VibeWorking基础设施记忆架构的优化
原创
GEM记忆执行架构设计与实践——对VibeWorking基础设施记忆架构的优化
原创
大泽同学
发布于 2026-06-02 14:01:15
发布于 2026-06-02 14:01:15
从三层记忆到GEM记忆架构:个人助手记忆系统进化史
摘要
本文记录了WorkBuddy个人工作助手记忆系统从三层架构到GEM架构( Gene-Executive-Memory)的演进。三层记忆架构解决了AI跨会话记忆保持问题,但在实际使用中暴露出策略信号稀释、失败经验分散、调度机制缺失、记忆类型边界模糊四大问题。GEM架构通过Gene方法论引入,将常驻注入从~6400 token精简至~1720 token(-73%),建立显式路由表、双节点蒸馏机制和三类记忆分类管理,实现"策略信号密度提升"与"懒加载真正生效"。
一、起点:三层记忆架构的建立与成果
1.1 问题的起源
2026年初,在使用各种原生大模型辅助工作时,发现一个核心问题:上下文切换成本太高。
每个平台都需要重新说明背景,重复沟通消耗了30-50%的时间。上下文断裂,信息无法跨平台流转。同样需求在不同工具中重复表达,无法形成工作流。工具之间互相独立,无法配合完成复杂任务。
更严重的是"金鱼记忆"问题:上下文窗口有限,超出后早期对话内容会被压缩或丢弃。对于需要持续数周、数月的工作,这种机制完全无法胜任。
1.2 三层记忆架构的设计
为解决上述问题,建立了三层记忆架构,借鉴人类认知模型:
层级 | 名称 | 存储内容 | 注入方式 |
|---|---|---|---|
L1 | 范式层 | 身份设定、工作原则、组织架构 | 系统强制注入 |
L2 | 档案层 | 项目档案、技术经验、用户偏好 | 自动注入 |
L3 | 会话层 | 当日对话、临时任务、实时记录 | 需主动读取 |
核心思想:不在一个篮子里放所有鸡蛋。会话上下文窗口是L3会话层的工具,L1和L2通过文件系统持久化,不受上下文窗口限制。
1.3 核心成果
三层记忆架构建立后,解决了跨会话记忆保持问题,并建立了三项核心成果:
成果一:铁律体系
在工作区根目录的导航文档中注入三条铁律:
- 根目录只放文件夹,不放散落文件
- 任何超过30分钟的工作必须建任务目录
- 删除优先用回收站机制(可恢复优先)
成果二:信息归属判定
建立判断口诀:
- 定义我是谁 → 范式层(身份设定文档)
- 定义我怎么工作 → 范式层(工作原则文档)
- 定义我知道什么 → 档案层(长期记忆文档)
成果三:实践验证
两个完整案例验证了三层记忆的有效性:
- 商机雷达面板:48小时从想法到系统上线
- HereNow桌面应用:4小时从想法到可执行文件
二、问题暴露:实际使用中的四大缺陷
随着系统不断扩展,三层记忆架构在实际使用中暴露出四个根本性问题。
2.1 缺陷一:策略信号稀释
现象:范式层文档体量膨胀,策略被背景稀释。
在工作区的范式层,有多个身份设定和工作原则文档。随着时间推移,这些文档不断积累内容,从最初的简洁策略,变成了详细的操作手册。
问题本质:同样字数,组织成"策略"才有用,组织成"摘要"没用。长文档把强模型的固有能力直接压住了,只有核心策略层真正起作用,背景说明、详细示例、模板填充都在稀释控制信号。
2.2 缺陷二:失败经验分散
现象:失败经验的警告信号分散在多个文档中,有重复有遗漏。
在工作区的各类文档中,散布着各种"不要这样做"的警告。这些警告分布在范式层的身份设定文档、工作原则文档、工具配置文档等多个位置。
问题本质:失败经验不应该原样堆砌叙事,应该提炼为警告信号。分散导致AI无法在关键时刻触发正确的约束,重复导致注入冗余,遗漏导致关键风险未被覆盖。
2.3 缺陷三:调度机制缺失
现象:缺少统一的调度路由表,AI需要从多个文档中拼凑调度逻辑。
在工作区,有大量详细的工作原则文档和技术经验文档。这些文档通过范式层的身份设定文档引导加载,但没有显式的"元路由表"。
问题本质:懒加载最大的风险不是"存了找不到",而是"不知道该找"。没有显式路由表,AI不知道"开发任务→加载哪个文档",导致懒加载机制无法真正生效。
2.4 缺陷四:记忆类型边界模糊
现象:范式层中既有硬约束(必须常驻),又有软经验(应降级为长期记忆),混合在一起。
在工作区的工具配置文档中,既有技术环境的硬约束(Python路径、Node路径,必须常驻),又有技术经验(PPT设计踩坑、Python环境配置经验,应降级为长期记忆),两者混合在一起。
问题本质:陈述性记忆(事实性知识)与程序性记忆(执行策略)混合,导致职责不清。硬约束应该常驻注入,软经验应该按需加载,但缺乏明确的分类机制。
三、理论突破:Gene方法论与认知科学框架
3.1 Gene方法论的核心发现
2026年4月22日,研读清华xEvoMap论文(arxiv 2604.15097),发现关键结论:
条件 | Skill包(~2,500 token) | Gene对象(~230 token) |
|---|---|---|
强模型Pro | 60.1→50.7 (-9.4pp) | 显著提升 |
弱模型Flash | 41.8→49.0 (+7.2pp) | 显著提升 |
核心洞察:
- Gene赢的不是长度,是形态
- 只有策略层真正起作用,背景说明、详细示例、模板填充都在稀释控制信号
- 失败经验最佳形态 = 警告信号(非原样堆砌叙事)
3.2 认知科学框架的契合
心智系统四层模型与GEM架构的映射:
认知组件 | 功能 | GEM映射 |
|---|---|---|
工作记忆 | 舞台有限,当前任务 | 会话上下文 |
中央执行系统 | 舞台总监,控制注意力 | Gene层(策略模板池+路由表) |
陈述性记忆 | 后台,事实性知识 | 长期记忆(晶体记忆+索引) |
程序性记忆 | 后台,技能性知识 | 长期记忆(策略文档) |
关键概念:
- 晶体智力 = 优质陈述性记忆 → 对应"晶体化蒸馏"
- 刻意练习→类别化→固定思维模式→共性迁移 → 对应"Gene蒸馏→匹配→执行"
四、关键策略:GEM架构设计
4.1 架构命名与定义
GEM — Gene-Executive-Memory
字母 | 含义 | 对应组件 |
|---|---|---|
G | Gene | 策略模板池(常驻注入的执行策略+警告信号+路由) |
E | Executive | 中央执行系统(调度路由、注意力控制) |
M | Memory | 长短期记忆(晶体化索引+会话日志+蒸馏循环) |
命名理由:3字母简洁有力,G-E-M恰好是三个核心支柱,gem英文意为宝石——双关晶体智力(crystallized intelligence)
4.2 架构设计图
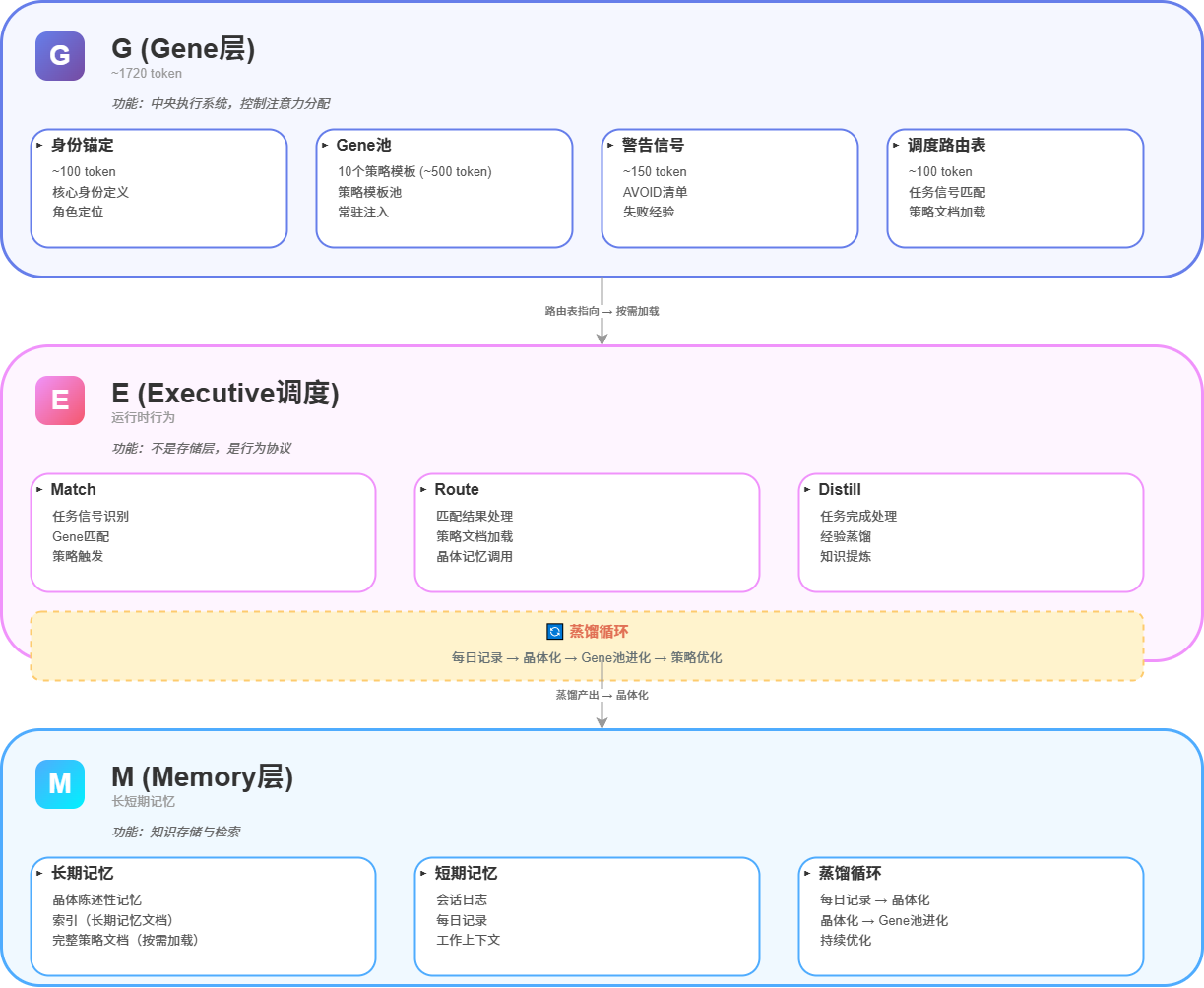
GEM架构图
4.3 与旧架构的关键区别
维度 | 旧(三层记忆架构) | 新(GEM) |
|---|---|---|
L1/G定义 | 范式层(文档集合) | Gene层(策略模板池) |
L1/G内容 | 3000 token文档 | 1720 token策略信号 |
L2/M定义 | 档案层(全量注入) | 长期记忆(索引+晶体+按需) |
调度机制 | 无(靠AI自觉) | 路由表(显式调度) |
蒸馏 | 无 | 双节点(任务完成+每日压缩) |
警告信号 | 分散叙事 | Gene constraints统一管理 |
记忆类型 | 边界模糊 | 三类分类管理 |
五、执行方案设计:Gene池与三类记忆
5.1 Gene池构建:10个策略模板
Gene结构规范(~50 token each):
## Gene: [名称]
**SIGNALS**: [触发信号,逗号分隔]
**STRATEGY**: [核心策略,2-3句话]
**CONSTRAINTS**: [警告信号,如有]十个核心Gene:
Gene | SIGNALS | 核心策略 |
|---|---|---|
Gene 1: Identity | 会话启动、身份确认 | 统领四大总监,结果导向 |
Gene 2: TaskManagement | 新任务、预估>4轮对话 | 立即创建任务目录 |
Gene 3: MemoryManagement | 任务完成、每日22:00 | 追加每日记录 + 记忆压缩 |
Gene 4: DevelopmentTask | 开发、编程、测试 | 先读开发总纲文档 |
Gene 5: SkillInvocation | 调用MCP/Skill | 先理解通信协议本质 |
Gene 6: FileOperation | 写入文件、删除文件 | 根目录只放文件夹 |
Gene 7: SafetyBoundary | 支付相关、外部通讯 | 四条红线必须征询 |
Gene 8: ToolMemory | 创建/安装新技能 | 更新源文档→同步经验文档 |
Gene 9: KnowledgeMemory | 知识密集型任务完成 | 抽取知识→输入知识库 |
Gene 10: StrategyMemory | 发现策略模式、用户显式要求 | 确认长期记忆→确认进Gene池 |
5.2 三类记忆分类管理
针对"记忆类型边界模糊"缺陷,建立三类分类管理机制:
工具类记忆(Gene 8: ToolMemory)
- 触发时机:用户显式要求创建/安装新技能时
- 执行流程:创建/安装技能完成后,立即更新源文档,同步到经验文档,失败则记录每日记录待补
- CONSTRAINTS:AVOID: 工具类同步失败未记录
知识类记忆(Gene 9: KnowledgeMemory)
- 触发时机:完成知识密集型任务后(研究报告、技术方案、行业分析等)
- 抽取标准:用户明确要求沉淀 或 Agent判断具有长期复用价值
- 执行流程:抽取知识点 → 按命名规范生成Markdown → 写入知识库 → 更新索引文件
- 命名规范:
YYYY-MM-DD_[主题]_[类型].md(类型:概念/方法/经验/技术/流程) - 目录分类:概念与方法论/ 项目经验/ 技术知识/ 工作流程/
- CONSTRAINTS:AVOID: 知识类进Gene池。AVOID: 知识文件超过500字(提炼精华)
- 关键设计:知识类记忆不进入Gene池,因为知识类是陈述性记忆,Gene池是程序性记忆(执行策略)
策略类记忆(Gene 10: StrategyMemory)
- 触发时机:用户显式要求制定策略 或 Agent在任务中发现可复用的策略模式
- 确认标准:
- 长期记忆:跨3+任务验证有效,或用户明确要求长期保留
- 进Gene池:跨会话通用 + 高频触发 + 符合Gene结构(SIGNALS+STRATEGY+CONSTRAINTS)
- 确认流程:先向用户确认是否长期记忆 → 再确认是否进Gene池 → 用户确认后创建记忆文件 → 如果进Gene池,更新常驻注入文档和完整定义文档
- 同步更新机制:更新常驻注入文档(Gene池部分)+ 更新完整定义文档(Gene详细定义部分)+ 更新警告信号汇总表(如有新约束)
- CONSTRAINTS:AVOID: 策略类未确认进Gene池。AVOID: 进Gene池后未同步完整定义文档。AVOID: 显式要求未判定就存储
- 关键设计:策略类记忆与Gene池紧密关联,进Gene池后必须同步更新完整定义文档
5.3 调度路由表:显式调度机制
针对"调度机制缺失"缺陷,建立显式路由表:
任务类型 | 加载文档类型 | 详细原文(归档) |
|---|---|---|
开发任务 | 开发规范晶体化文档 + 开发组织文档 | 开发规范源文档 + 开发组织源文档 |
记忆操作 | 记忆策略晶体化文档 | 记忆控制源文档 |
技能调用 | 技术经验晶体化文档 | 工具配置源文档(双向同步) |
组织协作 | 组织协作流程晶体化文档 | 组织架构源文档 |
原型设计 | 原型规范晶体化文档 | 原型规范源文档 |
定时任务 | 定时任务晶体化文档 | - |
任务管理 | 任务管理晶体化文档 | - |
安全边界 | 安全边界晶体化文档 | - |
知识沉淀 | 知识类记忆Obsidian规范文档 | 知识类记忆源文档 |
警告信号管理 | 警告信号汇总表 | - |
路由铁律:路由表是懒加载生效的前提,无路由则不知道该找。详细原文供深度查询时使用。
5.4 双节点蒸馏机制
针对"失败经验分散"和"进化机制缺失"问题,建立双节点蒸馏:
触发节点 | 时间点 | 蒸馏目标 | 输出 |
|---|---|---|---|
任务完成节点 | 任务结束立即 | 单任务经验 | 追加每日记录 + 可能更新长期记忆 + 可能创建晶体记忆 |
每日压缩节点 | 22:00晚间检查 | 当日所有任务 | 每日记录归档 + 长期记忆更新 + 可能Gene进化 |
六、落地修改规划与关键细节
6.1 Phase 1:Gene池构建
任务清单:
- 创建完整定义文档,写入10个Gene完整定义
- 更新常驻注入文档:精简至~1720 token
- 更新身份设定文档:精简至~100 token
- 更新用户画像文档:精简至~100 token
关键细节:
- Gene体量控制在~50 token,避免稀释
- SIGNALS明确触发条件,避免模糊
- CONSTRAINTS统一管理警告信号,避免分散
6.2 Phase 2:晶体记忆迁移
任务清单:
- 创建晶体记忆目录
- 从各类工作原则文档提炼核心策略 -> 晶体文件
- 创建归档目录
- 原文件移动到归档目录,添加【crystal源】标记
关键细节:
- 晶体化原则:保留策略形态、删除背景稀释、保持可检索、版本标记
- 归档源文档从"历史文档警告"改为"归档说明",强调这是"源文档"而非"历史文档"
6.3 Phase 3:三类记忆分类管理
任务清单:
- 创建知识类记忆Obsidian规范文档
- 创建知识类记忆源文档
- 更新技术经验晶体化文档(工具类记忆同步机制)
- 在知识库创建目录结构和索引文件
关键细节:
- 知识类记忆写入知识库:按照命名规范和目录分类
- 索引文件:定期更新,确保可检索
6.4 Phase 4:长期记忆精简
任务清单:
- 审查当前长期记忆文档内容
- 删除已在Gene中表达的策略
- 删除已在晶体记忆中表达的背景知识
- 保留:项目档案索引、里程碑、用户偏好、API配置
关键细节:
- 删除铁律汇总(已在Gene中表达)
- 精简用户偏好(删除已注入的配置)
- 保留项目档案索引、里程碑、每日记忆索引(核心价值)
6.5 Phase 5:双导航文档关系明确
任务清单:
- 更新工作区的导航文档,完整重写为GEM架构术语
- 更新根目录的导航文档,添加双导航文档关系说明
关键细节:
- 根目录导航文档 = IDE的"项目身份证",由WorkBuddy系统生成
- 工作区的导航文档 = 毕哥的"工作导航",提供快速索引和启动检查清单
- 两者互补,根目录导航文档指向工作区的导航文档
6.6 Phase 6:同步更新机制
任务清单:
- 同步常驻注入文档到系统注入位置
- 更新警告信号汇总表(补充Gene 8/9/10的警告信号)
- 更新每日记录(记录本次工作)
关键细节:
- 策略类记忆进Gene池后,必须同步更新:常驻注入文档 + 完整定义文档 + 警告信号汇总表
- Gene 10 CONSTRAINTS明确要求:AVOID: 进Gene池后未同步完整定义文档
七、结果总结:定量与定性效果
7.1 定量效果
指标 | 改造前 | 改造后 | 改善幅度 |
|---|---|---|---|
常驻注入体量 | ~6400 token | ~1720 token | -73% |
Gene数量 | 0 | 10 | +10 |
晶体记忆文件 | 0 | 10 | +10 |
归档源文档 | 0 | 9 | +9 |
路由表 | 无 | 1(10条路由) | +1 |
警告信号统一管理 | 分散6+文件 | 集中于Gene(27条) | 统一 |
7.2 定性效果
效果一:策略信号强度提升
从3000 token稀释→1720 token纯策略。Gene论文证明:同样字数,组织成"策略"才有用,组织成"摘要"没用。
效果二:调度可预测
路由表显式定义,懒加载真正生效。之前的问题是"不知道该找",现在路由表告诉AI"开发任务→加载开发规范文档"。
效果三:失败经验可用
警告信号统一管理,不再分散叙事。之前警告信号分散在6+文件中,现在统一整合到各Gene的CONSTRAINTS部分。
效果四:进化自动化
双节点蒸馏,持续提炼。任务完成节点+每日压缩节点,任一触发即可。
效果五:认知科学对齐
GEM架构符合中央执行系统+陈述性记忆+程序性记忆模型。这不是巧合,而是刻意设计的结果。
效果六:记忆分类管理
三类记忆(工具类/知识类/策略类)各有明确的触发时机、执行流程、判断标准,避免混乱。
效果七:知识沉淀自动化
知识类记忆自动输入知识库,无需手动整理,形成知识库。
效果八:Gene池同步机制
策略类记忆进Gene池后,自动触发常驻注入文档和完整定义文档同步更新,确保Gene池定义与实际一致。
八、核心洞察总结
洞察一:Gene赢的不是长度,是形态
长Skill把强模型的固有能力直接压住了。只有策略层真正起作用,背景说明、详细示例、模板填充都在稀释控制信号。
洞察二:警告信号是失败经验的最佳形态
失败经验不应该原样堆砌叙事,而应该提炼为警告信号。警告信号统一管理,不再分散叙事。
洞察三:路由表是懒加载生效的前提
懒加载最大的风险不是"存了找不到",而是"不知道该找"。路由表显式定义,AI才知道"开发任务→加载开发规范文档"。
洞察四:蒸馏需要双节点触发
单节点蒸馏容易遗漏。双节点(任务完成+每日压缩)设计,确保持续提炼。
洞察五:记忆需要分类管理
三类记忆(工具类/知识类/策略类)各有不同的触发时机、执行流程、判断标准。工具类同步到经验文档,知识类输入知识库,策略类可能进Gene池。混淆会导致管理混乱。
洞察六:知识类不进Gene池
知识类记忆是陈述性记忆(事实性知识),Gene池是程序性记忆(执行策略)。两者功能不同,不应混合。
洞察七:策略类进Gene池需要同步
策略类记忆进Gene池后,必须同步更新完整定义文档,否则会导致Gene池定义与实际不符。
洞察八:知识库是知识沉淀的最佳位置
知识库提供RAG检索能力,适合存储知识类记忆。通过命名规范和目录分类,形成知识库。
结语
三层记忆架构解决了AI跨会话记忆保持问题,但存在策略信号稀释、失败经验分散、调度机制缺失、记忆类型边界模糊四大缺陷。GEM架构通过Gene方法论引入,实现了:
- 常驻注入精简:从~6400 token → ~1720 token(-73%)
- 策略信号密度提升:从3000 token稀释 → 1720 token纯策略
- 调度可预测:路由表显式定义,懒加载真正生效
- 失败经验可用:警告信号统一管理,不再分散叙事
- 进化自动化:双节点蒸馏,持续提炼
- 记忆分类管理:三类记忆各有明确机制
- 知识沉淀自动化:知识类自动输入知识库
- Gene池同步机制:策略类进Gene池后自动同步完整定义文档
这不是终点,而是新的起点。当然产品不断在迭代,WorkBuddy将继续进化,从工具到伙伴,从伙伴到生态,作为使用者而言如何用好更新的机制将是持续的挑战。
文档附注
本文旨在完整记录笔者在VibeWorking过程中,从三层记忆到GEM架构的演进历程,开放出来给各位开发者借鉴,为后续维护和优化提供理论基础和实践参考,如果你对于技能包、工程文件感兴趣,可以在评论区探讨。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号