MiniMax M3:1M 上下文、SWE-Bench 59%,三项前沿能力一次集齐
原创
MiniMax M3:1M 上下文、SWE-Bench 59%,三项前沿能力一次集齐
原创
运维有术
发布于 2026-06-02 22:24:17
发布于 2026-06-02 22:24:17
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 128 篇,AI 星探「2026」系列第 13 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

封面图 - MiniMax M3 三项核心能力
图 1:MiniMax M3 三项核心能力概览
说明:本文内容基于 MiniMax 官方文档(minimaxi.com)和官方博客分析整理而成,数据来源为官方发布的基准测试成绩和实际任务案例。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
2026 年 6 月 1 日,MiniMax 发布了新一代旗舰语言模型 M3。
翻了一圈官方博客和技术报告,有一组数据让我有点意外:SWE-Bench Pro 评测 59.0%,超过 GPT-5.5 和 Gemini 3.1 Pro;1M tokens 上下文窗口下每 token 计算量仅为上代模型的二十分之一;原生多模态从预训练 Day 1 就开始混合训练。
说实话,这三个方向单独拎出来,都有模型做得不错。但同时把 Coding & Agentic 能力、超长上下文、原生多模态整合进一个模型里,并且各项能力都达到前沿水平 - 这件事此前只有极少数闭源模型做到了。M3 能不能撑住这个定位?下面逐项拆解。
1. MSA 架构:让 1M 上下文不再是摆设
问题在哪
标准 Transformer 的全注意力机制有个先天缺陷:计算量随上下文长度平方级增长。100K tokens 还勉强能扛,到 1M tokens 的时候,计算开销就炸了。
业界给出的方案大多围绕稀疏注意力展开 - 不对所有 token 做注意力计算,而是挑关键的算。但问题是:怎么挑?挑得准不准?挑完之后算得快不快?
MSA 的两步设计
MiniMax 给出的答案是 MSA(MiniMax Sparse Attention),一个两阶段的稀疏注意力架构:
第一步:Index Attention
用一组轻量的索引 query,对 KV(Key-Value)缓存做 Block Max Pooling,从大量的 KV 块里选出 Top-k 高相关性的块。这一步的计算成本很低,因为索引 query 的数量远少于实际的 query 数量。
第二步:Sparse Attention
只对选出的 Top-k 块执行完整的稀疏注意力计算。相比全注意力方案,计算量大幅缩减。
与 DSA(Dynamic Sparse Attention)和 MoBA(Mixture of Block Attention)等方案相比,MSA 的关键差异在于 KV 分块策略更精细——同样的初筛思路,但它能更精确地切分 KV 块,有效上下文覆盖更高。
算子层优化:KV Outer Gather
架构设计只是第一步,真正的性能瓶颈往往在底层算子。MSA 采用了 KV Outer Gather Q 的方式:以 KV 块为外层循环,聚合命中该块的 query,然后批量计算。这样做的好处是:
- 每块 KV 数据只读一次,访存连续
- 在 M3 的 head 配比下,计算访存比明显优于通行方法
- 比开源的 Flash-Sparse-Attention、Flash-MoBA 快 4 倍以上
实际性能收益
官方公布的对比数据相当亮眼:
指标 | 数据 |
|---|---|
1M 上下文每 token 计算量 | 仅为上代模型的 1/20 |
Prefilling 阶段加速 | 超过 9 倍 |
Decoding 阶段加速 | 超过 15 倍 |
而且官方强调,多个对照实验中 MSA 的绝大部分能力与全注意力打平。稀疏化没带来明显的能力损失,这一点很关键——注意力方案好不好,最终得看模型变笨了没有。
为什么 Agent 场景尤其需要长上下文
如果只是聊天问答,4K 或 8K 的上下文窗口够用了。但 Agent 场景完全不同。一个 Agent 任务可能涉及:读取几十个源代码文件、执行多条命令并分析输出、维护一个持续增长的操作日志、在多轮工具调用之间保持状态一致性。
以 M3 完成的 CUDA 优化任务为例:1959 次工具调用意味着每次调用都需要在上下文中保留之前的执行历史、分析结果和决策依据。没有足够长的上下文窗口,Agent 就像是一个每过几分钟就会失忆一次的程序员 - 再聪明也白搭。
这也是为什么 M3 的 1M 上下文窗口不只是堆参数,而是和 Agent 能力深度绑定的基础设施。MSA 把 1M 上下文的计算成本压下来,Agent 才能在长线程任务里一直工作。
2. Coding & Agent 能力:评测数据说话
M3 在多个国际权威评测基准上的成绩如下:
评测基准 | M3 成绩 | 备注 |
|---|---|---|
SWE-Bench Pro | 59.0% | 超过 GPT-5.5、Gemini 3.1 Pro,接近 Opus 4.7 |
Terminal Bench 2.1 | 66.0% | 终端命令执行能力 |
BrowseComp | 83.5 | 超越 Opus 4.7(79.3) |
MCP Atlas | 74.2% | MCP 工具调用能力 |
SVG-Bench | 超过 Opus 4.7 | SVG 矢量图生成 |
Claw-Eval | 排名靠前 | 自主 Agent 端到端评测 |
OmniDocBench | 超过 Gemini 3.1 Pro | 多模态文档理解 |
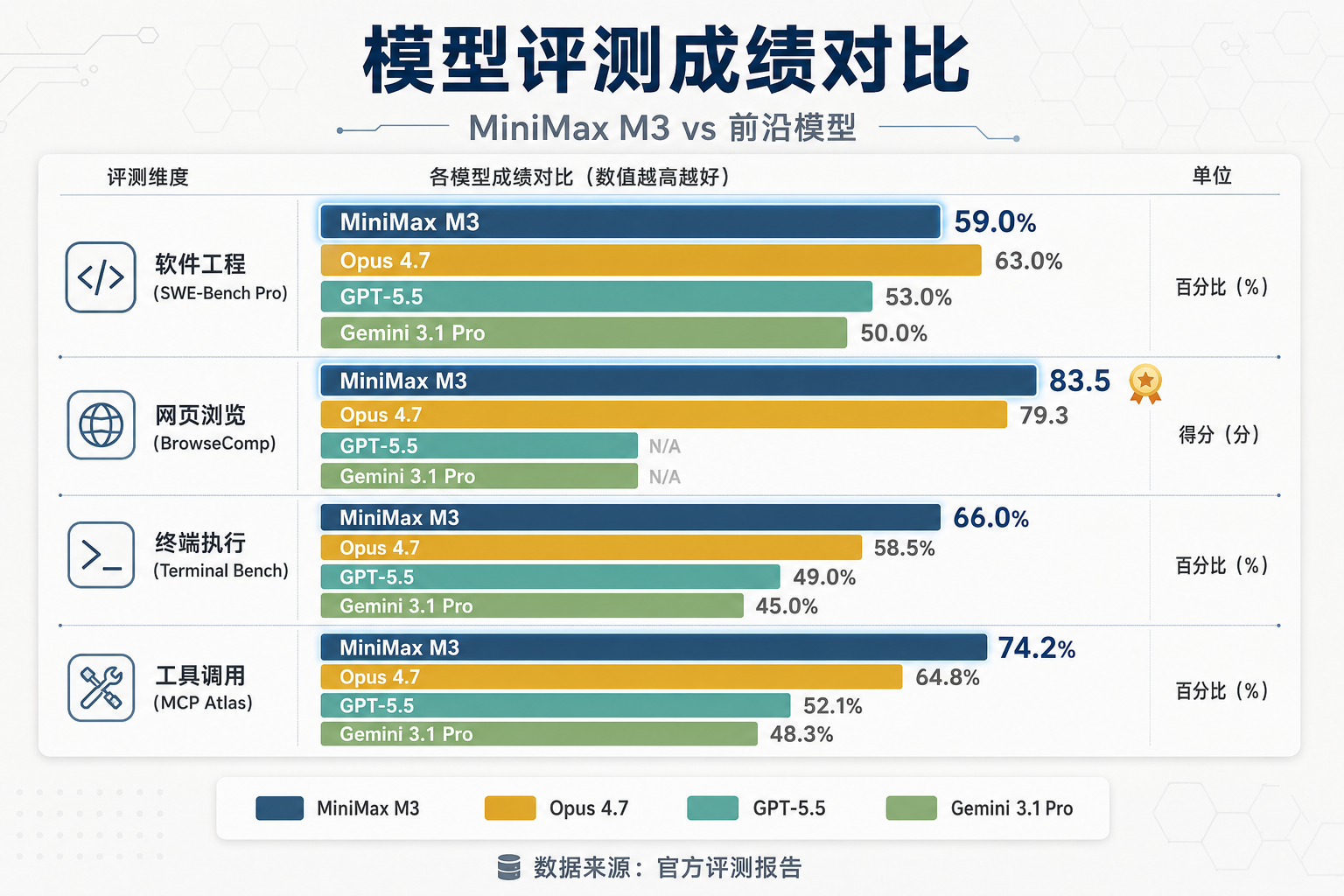
评测成绩对比图表
图 2:MiniMax M3 与前沿模型评测成绩对比
几个值得关注的数字:
BrowseComp 83.5 vs Opus 4.7 的 79.3。BrowseComp 考的是模型在真实网页环境里的信息检索和综合能力。M3 超了 Opus 4.7,对 Agent 场景来说这是硬指标。
Claw-Eval 排名靠前。这是自主 Agent 端到端评测,模拟真实开发任务的完整工作流。名次靠前说明 M3 不只是单步推理强,多步规划、工具调用、错误恢复这些 Agent 核心能力都扛得住。
SWE-Bench Pro 59.0%。排在 Opus 4.7 后面,但超过了 GPT-5.5 和 Gemini 3.1 Pro。SWE-Bench Pro 是业界公认的软件工程能力标杆,59% 的通过率意味着 M3 在真实 GitHub issue 修复场景里已经能干活了。
你在项目中用过类似的 Agent 方案吗?欢迎在评论区聊聊体验。
3. 三个实战任务:不只是刷榜
基准测试是一回事,实际任务表现是另一回事。官方给了三个具体案例,比评测分数的信息量大得多。
论文独立复现:12 小时跑通核心实验
任务:独立复现 ICLR 2025 Outstanding Paper Award 获奖论文《Learning Dynamics of LLM Finetuning》。
过程:M3 自主运行接近 12 小时,产出 18 次 commit 与 23 张实验图表。
结果:跑通了核心实验,验证了 SFT 阶段预测概率变化趋势、DPO 的 squeezing 效应、Extend 缓解方法。
这个任务难在它需要三项能力同时在线:多模态看懂论文里的图表和公式,长上下文容纳论文全文 + 代码 + 运行日志,编程和 Agent 能力驱动整个 12 小时的长线程执行。缺一项都不行。
拆开看:先读懂论文的数学推导和实验设计(多模态理解),把方法翻译成可运行代码(编程能力),跑实验对比结果(Agent + 长上下文),结果不对就分析原因再修正(持续推理)。全程 M3 自主完成,23 张实验图表验证复现正确性——不只是写代码,更像一个研究助理在干活。
CUDA 算子优化:从 7.6% 到 71.3%
这是三个案例里说服力相当强的一个。
任务:在 NVIDIA Hopper 架构上优化 FP8 GEMM kernel。
起点:仅有一份任务描述、一个 benchmark 脚本、一个无法运行的 Triton 骨架代码。没有参考实现,没有现成答案。
过程:约 24 小时,147 次 benchmark 提交,1959 次工具调用,经历了 6 轮标志性优化迭代。
结果:硬件峰值利用率从 7.6% 提升到 71.3%,实现了 9.4 倍加速。
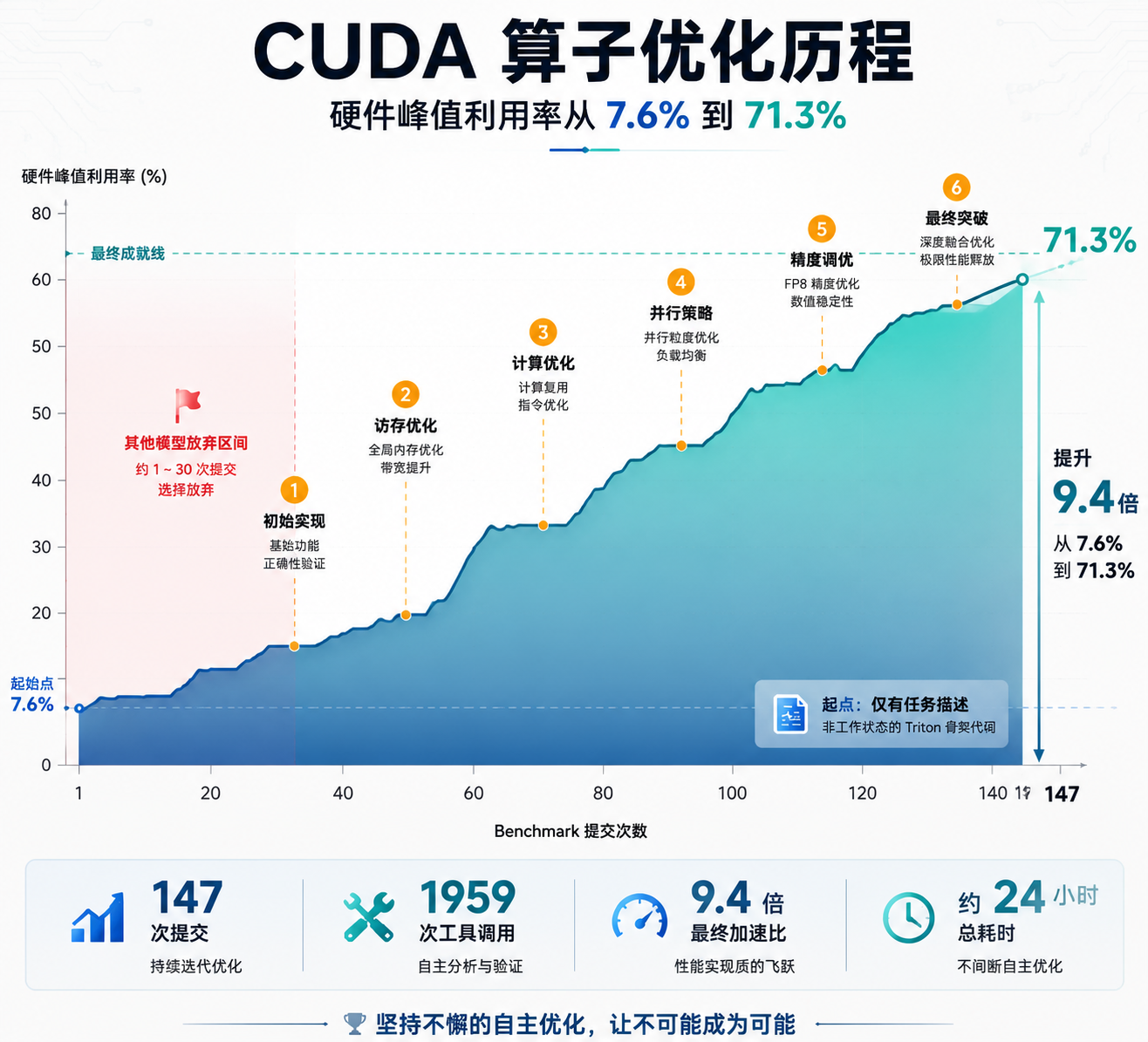
CUDA 优化过程可视化
图 3:CUDA 算子优化历程 - 硬件峰值利用率从 7.6% 到 71.3%
有个细节很有意思:最佳结果出现在第 145 次提交。据官方数据,其他参评模型大多在前 30 次内就不动了。M3 不只是代码能力强,更关键的是它有持续迭代的耐力——Agent 场景里,这个特质比单次推理能力重要得多。
PostTrainBench:让 M3 自己训练模型
任务:给 M3 四个 Base 模型,12 小时内自主完成数据合成→训练→评测→迭代全流程。
这个任务考验的不是编程能力,而是判断力:自己决定合成什么数据、选什么训练策略、根据评测结果调整方案。本质上是让模型当 AI 研究员。
得分:0.37,排第三,仅次于 Opus 4.7(0.42)和 GPT-5.5(0.39)。AI 训 AI 的闭环任务,这个成绩不差。
4. 原生多模态:从 Day 1 开始
为什么原生训练很重要
大多数多模态模型的做法是:先训一个纯文本模型,再把视觉编码器嫁接上去。效率高、实现简单,但文本和视觉的语义空间天然有缝。
M3 不走这条路——从预训练的 Day 1(官方原文是 Step 0)就开始多模态混合训练。文本和视觉的语义空间从一开始就对齐。
代价是训练流程更复杂,需要重构整个数据管线,预训练数据规模扩充到百 T 量级。但回报也明确:理解图表、公式、曲线图这类需要跨模态推理的任务上,表现更自然。
Interleaved Data 的关键作用
MiniMax 做了大量实验,发现了一个重要结论:Interleaved Data(交错数据) 对模型性能的提升比大家以为的大得多。
所谓 Interleaved Data,就是文本和图像在序列中交替自然排列的数据 - 比如一篇包含图片说明的文档,而不是文本块和图片块分开堆叠。
这个发现背后的逻辑是:模型不仅要会看图和读文字,还得理解图文之间的交替逻辑关系。论文理解、文档分析、网页浏览,都需要这种能力。
从数据工程角度看,Interleaved Data 的准备成本比普通图文对高得多。原始文档(论文、网页、教程)得保持自然格式,文本和图像交替排列,不能粗暴地拆成独立的文本数据和图像数据。MiniMax 为了适配这种训练方式重构了整个数据管线,预训练数据规模拉到了百 T 量级。
这笔投入不小。但回头看论文复现任务里 M3 对图表和公式的理解能力,这笔投入确实有回报。
多模态应用场景
从官方披露的信息看,M3 的多模态能力覆盖了以下场景:
- 论文中的图表、公式、曲线图理解(论文复现任务已经验证)
- 视频输入理解
- Computer Use - 直接操作电脑桌面完成跨应用操作
5. 交互式用户模拟器:下一代 Agent 训练范式
这一节虽然不是 M3 模型本身的功能,但能看到 MiniMax 对 Agent 能力演进的思考。
问题定义
当前大多数代码 Agent 的训练建立在单轮任务假设上:用户给需求,Agent 完成,结束。但真实开发不是这样——用户会在同一个 session 里持续协作:补充需求、讨论方案、反馈修正、切换任务、迭代项目。
框架设计
MiniMax 提出了一个交互式用户模拟器框架,模拟真实开发者的协作行为模式。具体来说,这个框架覆盖了几种典型的协作行为:
- 需求补充:用户在 Agent 工作到一半时追加新的需求
- 方案讨论:用户和 Agent 就技术方案进行来回讨论
- 反馈修正:用户对 Agent 的输出给出反馈,要求调整
- 连续任务切换:在一个 session 内处理多个不同的任务
- 复杂项目迭代:在同一个项目上持续多轮迭代改进
让 Agent 不再只是被动执行指令,而是主动与用户协同完成任务。
这个方向背后隐含的判断是:下一代 Coding 能力的比拼,不只是代码生成的准确率,更包括长期协作能力、规划能力和人与 Agent 的协同效率。
坦白讲,这个方向比单纯刷 SWE-Bench 分数难得多。但从 Agent 落地的角度看,这恰恰是当前的关键瓶颈——真实开发不是跑 benchmark。
6. 接入方式与定价
API 接入
API 地址:https://api.minimaxi.com/v1/text/chatcompletion_v2
模型名:MiniMax-M3
兼容 OpenAI API 格式,支持自动 Cache。
两种思考模式
M3 提供了 Thinking 和 Non-thinking 两种模式,共享同一套定价:
- Thinking 模式:适合复杂推理、Agentic 任务与长程协作。模型会输出中间推理过程。
- Non-thinking 模式:响应更快,适合对话、代码补全等延迟敏感场景。
两种模式可以在请求时按需切换,不用换模型。这个设计挺实用——同一个端点,想清楚再回答和快速响应两种需求都覆盖了。
服务等级
- 默认通道:适合常规请求
- 优先通道(service_tier=priority):高并发场景下获得调度优先级与更稳定的响应时延
Token Plan 定价
档位 | 月费 | Token 量 | 对标参考 |
|---|---|---|---|
Plus | ¥49/月 | 6 亿 | 约 Claude Pro 的 5 倍 |
Max | ¥119/月 | 18 亿 | 约 Claude Max 的 2 倍 |
Ultra | ¥469/月 | 55 亿 | 约 Claude Max 20x 的 3 倍 |

定价对比信息图
图 4:MiniMax M3 Token Plan 定价方案
从 token 单价来看,M3 走的是量大价低路线。Plus 档 ¥49/月给 6 亿 token,日常开发额度相当充裕。
开发者工具支持
M3 支持 10+ 主流 AI Coding 工具接入:Claude Code、Roo Code、Kilo Code、Cline、Codex CLI、OpenCode、Droid、TRAE、Grok CLI、Cursor 等。基本上主流的 AI 编程工具都覆盖了。
接入也简单——M3 兼容 OpenAI API 格式,大多数工具改一下 API endpoint 和 model name 就行。已经熟悉这些工具的开发者,切换到 M3 几乎零学习成本。
开源计划
M3 即将在 HuggingFace 和 GitHub 上完成开源,支持私有集群部署和微调。官方表示技术报告和开源模型权重将在发布后 10 天内更新。
如果开源版本能保持与闭源版本相近的能力,对国内开发者来说会很有吸引力——自己的基础设施上跑,不用担心里程碑计费和数据隐私。
7. MiniMax Code:配套 Agent 产品
MiniMax 还发布了专为 M3 设计的 Agent 产品 MiniMax Code,几个核心特性值得关注:
- Agent Team:将大型任务拆解为多阶段、可并发、可动态调整的 Workflow
- Producer + Verifier 对抗式 Harness 循环:可持续运行数天,反复验证输出质量
- Computer Use 能力:可操作电脑桌面完成跨应用操作
- 基于社区开源项目 OpenCode 和 Pi Agent 构建
其中 Producer + Verifier 的对抗式设计比较有意思——不是一次生成然后祈祷正确,而是通过持续的生成→验证→修正循环提升质量。和前面 M3 在 CUDA 优化里跑 147 次 benchmark 的行为模式一致。
总结
翻完官方资料,我对 M3 的整体印象:三项能力都不弱,没有明显短板。
MSA 架构在稀疏注意力上实现了可观的效率提升,1M 上下文不是营销噱头而是实际可用。Coding 和 Agent 能力在多个权威评测里进入了前沿梯队。原生多模态从 Day 1 开始训练,成本更高但跨模态理解能力更自然。
当然也有不确定的地方:评测成绩和实际体验之间差距多大?开源版本会保留多少能力?长期协作场景下稳定性如何?这些得等模型真正可用之后才知道。
不过从定价策略和开源计划来看,MiniMax 明显在走降低开发者试用门槛的路线。Plus 档 ¥49/月给 6 亿 token,加上即将开源的模型权重,想体验国产前沿模型的开发者,试错成本很低。
如果你也在关注国产大模型的进展,M3 值得花时间实际跑一跑。评论区说说你最想用它来做什么?
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号