当 Vibe Coding 遇上一致性灾难:分治开发的五层防御体系
原创
当 Vibe Coding 遇上一致性灾难:分治开发的五层防御体系
原创
大泽同学
发布于 2026-06-03 10:15:11
发布于 2026-06-03 10:15:11
当 Vibe Coding 遇上一致性灾难:分治开发的五层防御体系
TL;DR :用 AI 分批次生成一个 15 页的 B 端系统原型,结果导航栏出现了 3 种风格、4 种分组结构。本文总结了一套"先定义一致性,再拆分任务"的方法论,包含五层防御体系,让 AI 辅助开发不再产生一致性漂移。
一、Vibe Coding 的爽与痛
前几个月,我尝试用 AI 辅助编程(俗称 Vibe Coding)快速构建一个 B 端管理系统的原型。需求很明确:一个包含仪表盘、配置管理、数据字典、业务规则等模块的完整前端原型,总共 15 个页面。
Vibe Coding 的爽点:
- 几分钟生成一个页面,进度条拉满
- 不用手写重复的代码结构
- 快速验证设计想法
但痛点在哪?
当我分三批让 AI 生成完所有页面后,打开浏览器逐一检查时,眼前的场景让我意识到问题大了:

分批生成结果
更严重的是:
- 链接断裂:页面之间无法跳转,面包屑没有指向
- 命名混乱:同一个功能模块,在不同页面叫不同名字
- 组件重复:每个页面都重新实现了一次侧边栏
用户看到原型后,严厉批评道:"这看起来像是 15 个完全不同的系统拼凑在一起,而不是一个完整的产品。"
二、问题本质:分治开发的熵增
经过复盘,我意识到这不是 AI 的锅,也不是开发者懒惰,而是一个更深层的问题:分治开发天然产生一致性漂移(Consistency Drift)。
什么是一致性漂移?
当你把一个大任务拆分成多个子任务(无论是给 AI 还是给人类团队),每个子任务独立执行时,对"共享元素应该怎么实现"的理解会逐渐偏离。这不是错误,而是熵增——系统天然趋向于混乱。
漂移的四种类型
漂移类型 | 表现 | 根因 |
|---|---|---|
视觉漂移 | 图标风格不一致、间距微小差异 | 无共享 Design Token |
结构漂移 | 导航分组不同、组件层级不同 | 无共享 Layout 定义 |
语义漂移 | 同一概念叫不同名字("参数配置" vs "系统参数配置") | 无共享命名规范 |
链接漂移 | 页面间无法跳转、面包屑无指向 | 无共享路由映射 |
核心洞察
一致性问题的本质是单源真相(Single Source of Truth, SSOT)缺失。
当同一份信息(比如"导航栏应该有哪些项目")被多个独立任务各自复制实现时,不一致是必然结果。就像"打电话传话"游戏——信息每传递一次,就会失真一点。
三、解法:五层防御体系
受微前端设计系统、Atlassian 的 SSOT 方法论、以及模板引擎实践的启发,我总结出一套五层防御体系。核心是:一致性不能靠人的纪律,必须靠架构约束和自动化校验。

五层防御体系
关键原则:从下往上,每一层都在减少"需要人工保持一致"的地方。到了第 4 层,一致性已经由架构保障;第 5 层是最后的闸门。
四、逐层实践:从理论到代码
第 1 层:规范文档(约定层)
做什么:在拆分任务之前,写一份 CONSISTENCY-RULES.md,作为后续所有自动化校验的判决依据。
## 命名规范
- 导航项:仪表盘 / 系统配置 / 数据管理 / 业务规则 / ...
- 分组:概览 / 基础管理 / 高级管理 / 系统监控
## 路由映射表
| 导航项 | 文件名 |
|-----------------|------------------------|
| 仪表盘 | 01-dashboard.html |
| 系统配置 | 02-config.html |
| ... | ... |
## 图标规范
- 统一使用 SVG inline 图标(见 icons/ 目录)
- 禁止使用 emoji 作为图标
## 链接规范
- 所有 nav-item 必须是 <a href="xx.html">
- 面包屑首级 → 01-dashboard.html
- 列表页「查看详情」→ 详情页?id=xxx为什么不能跳过:这不是文档装饰,而是后续所有自动化校验的判决依据。没有约定,就无法判定什么是对的。
第 2 层:Design Token(值一致性层)
做什么:提取所有视觉常量为 CSS 变量或 JSON Token。
/* tokens.css - 单源真相 */
:root {
--color-primary: #1565c0;
--color-primary-dark: #0d47a1;
--nav-width: 200px;
--nav-bg: var(--color-primary-dark);
--nav-item-height: 40px;
--nav-active-border: 3px solid #ff9800;
--spacing-sm: 8px;
--spacing-md: 16px;
--spacing-lg: 24px;
}关键:Token 文件是单源的——所有页面 @import 同一个文件,不许各自重写。一旦修改 Token,所有页面同步生效。
第 3 层:共享组件库(组件一致性层)
做什么:把反复出现的 UI 结构抽为独立组件文件。
components/
├── sidebar.html ← 整个侧边栏
├── topbar.html ← 顶栏+面包屑
├── filter-bar.html ← 通用筛选栏
└── pagination.html ← 分页器为什么:在之前的 15 页原型中,侧边栏分别是 15 份独立实现——任何修改要改 15 遍。抽成 1 份后,修改只需 1 处。
第 4 层:构建时注入(架构一致性层)★ 最关键
做什么:用模板引擎或构建脚本,将共享组件在构建时注入每个页面,而非手动复制粘贴。
方案对比
方案 | 适用场景 | 实现复杂度 | 一致性保障 | 真实浏览 |
|---|---|---|---|---|
客户端 Fetch 注入 | 纯静态原型(无 Node) | ⭐ 最低 | ⚠️ 弱(需本地服务器) | ✅ 直接打开 HTML |
构建时模板继承 | 中大型原型(Eleventy/Nunjucks) | ⭐⭐ 中等 | ✅ 强(build 即一致) | ⚠️ 需 build 步骤 |
SPA 组件路由 | React/Vue 前端项目 | ⭐⭐⭐ 高 | ✅ 最强 | ❌ 不适合原型 |
推荐方案:构建时脚本注入(以 Nunjucks 为例)
build/
├── templates/
│ └── layout.html ← 含 sidebar + topbar 的完整壳
├── pages/
│ ├── 01-dashboard.njk ← 只写内容区
│ └── 02-config.njk
└── build.js ← nunjucks 渲染 → 输出 static HTMLlayout.html 定义完整骨架:
<div class="layout">
<div class="sidebar">
{% include "sidebar.html" %}
</div>
<div class="main">
<div class="topbar">{% include "topbar.html" %}</div>
<div class="content">
{% block content %}{% endblock %}
</div>
</div>
</div>每个页面只写 {% block content %} 内的内容,导航自动一致。
优点:输出纯 HTML,可直接浏览器打开,一致性有架构保障
缺点:需要一次 node build.js 步骤
备选方案:客户端 Fetch 注入(零构建步骤)
如果团队不想引入构建步骤,可以用客户端 Fetch:
<!-- 每个页面只需: -->
<body>
<div id="app-layout"></div>
<script>
fetch('components/sidebar.html')
.then(r => r.text())
.then(html => {
document.getElementById('app-layout').innerHTML = html;
// 根据当前文件名标记 active
const page = location.pathname.split('/').pop();
document.querySelector(`[data-page="${page}"]`)?.classList.add('active');
});
</script>
</body>优点:零构建步骤,改一处全局生效
缺点:不能直接 file:// 打开,需 Live Server
第 5 层:自动化校验(闸门层)
做什么:写一个校验脚本,在交付前自动检查一致性规则。
# check-consistency.py
import os
import re
from bs4 import BeautifulSoup
rules = {
"nav_items_count": 14, # 必须正好14个导航项
"nav_item_names": [...], # 名称精确匹配
"svg_icons_only": True, # 禁止emoji图标
"all_nav_have_href": True, # 所有nav-item必须有href
"active_count": 1, # 每页恰好1个active
}
def check_html_file(file_path, rules):
with open(file_path, 'r', encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'html.parser')
errors = []
# 检查导航项数量
nav_items = soup.select('.nav-item')
if len(nav_items) != rules['nav_items_count']:
errors.append(f"导航项数量错误: {len(nav_items)} != {rules['nav_items_count']}")
# 检查是否使用 emoji 图标
if rules['svg_icons_only']:
for item in nav_items:
if re.search(r'[\U0001F600-\U0001F64F]', item.text):
errors.append("发现 emoji 图标,应使用 SVG")
# 检查 active 标记数量
active_items = soup.select('.nav-item.active')
if len(active_items) != rules['active_count']:
errors.append(f"active 标记数量错误: {len(active_items)} != {rules['active_count']}")
return errors
# 遍历所有 HTML 文件
html_files = [f for f in os.listdir('.') if f.endswith('.html')]
all_errors = {}
for file in html_files:
errors = check_html_file(file, rules)
if errors:
all_errors[file] = errors
# 输出结果
if all_errors:
print("❌ 一致性检查失败!")
for file, errors in all_errors.items():
print(f"\n{file}:")
for error in errors:
print(f" - {error}")
exit(1)
else:
print("✅ 一致性检查通过!")
exit(0)关键:这个脚本不是锦上添花,而是交付前的必过闸门。一致性违规 = 不允许交付。
五、完整工作流:从混乱到有序
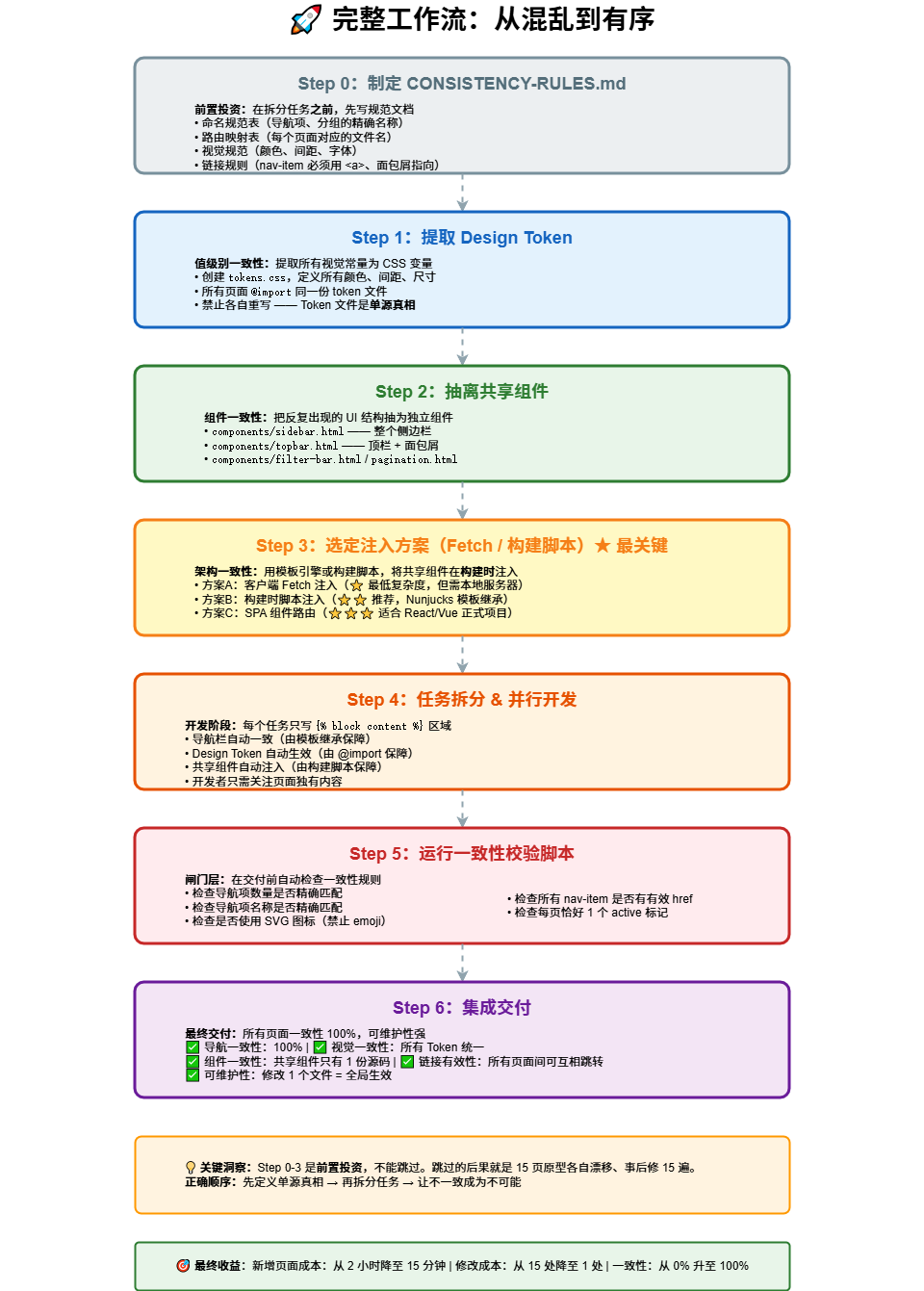
完整工作流
关键洞察:Step 0-3 是前置投资,不能跳过。跳过的后果就是 15 页原型各自漂移、事后修 15 遍。
六、实战案例:某 B 端系统的重构过程
重构前的问题清单
当我接手那个" 15 个页面像不同系统"的原型时,问题清单如下:
□ 导航项名称:7 种变体("参数配置" / "系统参数" / "参数设置" / ...)
□ 导航分组:4 种不同逻辑
□ 图标:混合使用 SVG + Emoji + 纯文本
□ 链接:60% 的导航项没有有效 href
□ 面包屑:每页自己实现,互不兼容
□ 侧边栏:15 份独立实现,修改要改 15 遍重构步骤
Day 1:制定规范
- 写
CONSISTENCY-RULES.md(包含 14 个导航项的精确名称、4 个分组的定义、路由映射表) - 提取
tokens.css(从 15 个页面中归纳出共同的视觉常量)
Day 2:抽离组件
- 创建
components/sidebar.html(统一定义侧边栏结构) - 创建
components/topbar.html(统一顶栏和面包屑) - 删除 15 个页面中的重复实现
Day 3:引入构建脚本
- 用 Nunjucks 重构(把 15 个
.html改为.njk,只保留内容区) - 运行
build.js生成最终 HTML - 验证每个页面导航栏完全一致
Day 4:编写校验脚本
- 实现
check-consistency.py - 自动检查导航项数量、名称、链接有效性
- 集成到 package.json 的
pretest钩子
结果:
- 导航一致性:100%
- 可维护性:修改 1 个文件 = 全局生效
- 新增页面成本:从 2 小时降至 15 分钟
七、速查清单:每次分治开发前打勾
□ CONSISTENCY-RULES.md 已写?
包含:命名表、路由映射、图标规范、链接规范
□ Design Token 单源?
所有页面是否 import 同一份 token 文件?
□ 共享组件已抽离?
侧边栏/顶栏/分页器等是否只有一份源码?
□ 注入机制已选定?
Fetch / Nunjucks / React Router?
□ 一致性校验脚本已写?
交付前自动跑?
□ 路由映射表完整?
每个页面都有所有其他页面的链接?如果以上任何一项为 No,就不应该开始拆分任务。
八、核心原则:一句话总结
一致性不是靠审美的纪律,而是靠架构的约束。undefined先定义单源真相,再拆分任务;让不一致成为不可能,而非靠人来避免。
九、写在最后:Vibe Coding 的正确姿势
Vibe Coding(AI 辅助编程)的最大陷阱是:以为快 = 好。
实际上,AI 生成代码的速度越快,一致性漂移的风险越高。因为:
- AI 没有"记忆",每次生成都是新的开始
- 分批生成时,AI 无法看到其他批次的决策
- 如果没有架构约束,AI 会"自由发挥",导致风格分裂
正确的 Vibe Coding 姿势:
- 先设计一致性约束(本文的五层防御)
- 再让 AI 在约束内生成
- 用自动化校验确保合规
这样,你才能真正享受 Vibe Coding 的爽点,而不用事后花 3 倍时间修一致性。
参考资料
- Micro Frontends and Design Systems (dev.to, 2025-01)
- Atlassian: Building a Single Source of Truth
- Mozilla Nunjucks: Template Inheritance
- Eleventy (11ty): Shared Layouts with Liquid/Nunjucks
作者注:本文总结的方法论已从具体项目中抽象出来,适用于任何需要分治开发的场景——无论是 AI 辅助编程,还是多人协作开发。核心思想只有一个:让架构保证一致性,而非依赖人的纪律。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号