产线还在用YOLO“画框”?Qwen3-VL-Seg让质检真正“开口闭环”
原创
产线还在用YOLO“画框”?Qwen3-VL-Seg让质检真正“开口闭环”
原创
AI小怪兽
发布于 2026-06-03 10:48:40
发布于 2026-06-03 10:48:40
产线还在用YOLO“画框”?Qwen3-VL-Seg让质检真正“开口闭环”

走进任何一家工厂的质检车间,你都会发现一个心照不宣的事实:控制器里十有八九跑的是YOLO,而各大顶会里刷屏的视觉大模型(VLM),几乎找不到一台部署在生产线上。这不是技术保守,而是工业的物理规律使然。
传统方案哪怕训练得再好,也只能输出矩形框坐标——它能告诉你“这里有个缺陷”,但永远无法像一位质检工程师那样回答“这是什么类型的缺陷?”“可能是什么原因导致的?”“该怎么修?”。
YOLO负责实时定位的天花板早就被触到了,但缺陷诊断和工艺反哺的最后一公里,却迟迟无人补齐。直到Qwen3-VL-Seg的出现。
2026年5月8日,阿里巴巴通义实验室正式开源Qwen3-VL-Seg,提出了一个参数高效的框架,将MLLM预测的边界框视为语义锚定的结构先验,通过专用的轻量级掩码解码器将其解码为像素级指代分割。这不是一次简单的“版本更新”,而是让大模型从“框级定位”直接跨越到“像素级精细分割 + 语义推理”的质变。
🚨 一、工业质检的“三座大山”:为什么传统YOLO方案越做越吃力?

工业缺陷往往微小至极。以PCB板上的虚焊为例,经过YOLO骨干网络的多层卷积下采样,这些微小信号极易被深层特征图“淹没”,默认模型在10倍放大图像下的漏检率高达35%。更麻烦的是,标准YOLO在重叠目标面前经常“打架”——在螺丝分拣项目中,YOLOv8把三个重叠的螺丝识别成两个,导致后续机械手抓取失败。
最致命的问题在逻辑层面。当YOLO判定某块极片存在“暗斑”时,它无法回答“为什么是缺陷”“和哪些工艺参数相关”,也切断了质量数据向工艺优化环节的反哺链路。这导致检测和工艺改进之间始终隔着一道墙。
🚀 二、Qwen3-VL-Seg:让AI从“看见”到“看懂”再到“审断”

Qwen3-VL-Seg的核心突破在于设计了一个仅17M参数(仅占基础模型0.4%) 的轻量级边界框引导掩码解码器。在4B参数规模上,它实现了超越8B模型的分割精度,在语言密集型指令上优势显著,且无需依赖任何外部分割模型。
两大核心特性:
- 深度空间感知:它不仅能看到“缺陷在哪儿”,还能理解“缺陷和周边空间的关系是什么”。在指代分割任务上,像素级监督反向提升了MLLM的定位精度,在RefCOCO+ TestB上提升6.6%。
- 结构化诊断报告生成:Qwen3-VL已经构建了“图像→缺陷语义→工艺上下文→技术文档映射→可执行建议生成”的全链路认知闭环。在注塑件缺陷检测中,它的输出是:“气泡位于注塑件R3.5mm圆角过渡区,直径0.23mm……推测原因为保压时间不足(当前设定2.1s,建议调整至2.8s)且模具排气槽堵塞。”
⚡ 三、边缘端部署:YOLO实时定位 + Qwen3-VL-Seg离线诊断
直接让大模型逐帧全图推理的算力开销是不可接受的。“YOLOv5先行检测,Qwen3-VL按需理解”的双引擎架构,灵感来自人类质检员的工作习惯——先快速扫视整条流水线,发现异常区域再凑近细看。
协同架构伪代码:
python
# 1. 边缘端YOLO实时检测(部署于工控机/边缘盒子)
from ultralytics import YOLO
import cv2
import requests
def edge_yolo_detection():
# 加载YOLO模型(仅3.2MB,Jetson上轻松运行)
model = YOLO('yolo26n.pt') # YOLO26版本,端到端无NMS
cap = cv2.VideoCapture(0) # 产线摄像头
suspicious_queue = []
while True:
ret, frame = cap.read()
results = model(frame, conf=0.25) # 实时推理
# 筛选可疑区域(置信度>0.5的检测框)
for box in results[0].boxes:
if box.conf > 0.5:
x1, y1, x2, y2 = map(int, box.xyxy[0])
roi = frame[y1:y2, x1:x2] # 裁剪局部区域
suspicious_queue.append(roi) # 批量上传
# 异步发送到诊断队列
requests.post('http://diagnosis-queue/api/upload',
json={'image_b64': encode_image(roi)})
# 2. 云端/边缘Qwen3-VL深度诊断
from transformers import AutoModelForCausalLM, AutoProcessor
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-VL-8B-Instruct",
device_map="auto", torch_dtype="auto")
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-8B-Instruct")
def diagnose_defect(image, prompt):
"""对可疑ROI进行深度语义分析"""
messages = [
{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": prompt}
]}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(text=text, images=image, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1024)
return processor.decode(outputs[0], skip_special_tokens=True)
# 3. 结构化报告生成(Thinking模式启用链式推理)
prompt = """请以Thinking模式分析这个缺陷:1) 这是什么类型的缺陷?2) 可能的原因是什么?3) 建议调整哪些工艺参数?"""
diagnosis = diagnose_defect(roi_image, prompt)
save_report(diagnosis) # 保存JSON格式报告,关联MES系统硬件适配方面,灵活度极高:
- NVIDIA平台:TensorRT深度优化可将Qwen3-VL推理速度提升2.8倍以上,原生支持FP16/INT8量化。在24GB显存约束下,通过QLoRA微调实现高精度部署。
- 国产芯片RK3588:通过RKNN-Toolkit2将视觉部分转为rknn格式,在NPU上硬件加速。
- 轻量化极致:FP8版本的4B模型可在8GB显存下运行,保持99%以上准确率。
🏭 四、典型标杆案例:LNG储罐制造中的多模态零样本检测

LNG储罐制造是工业质检公认难度最高的领域之一——缺陷定位精度要求极高,且需要输出结构化报告。研究团队在AIHub LNG Tank Quality Inspection数据集的15,000张标注图像上微调了7款主流LVLM,综合评估缺陷定位、多属性分类与自动报告生成能力。
Qwen3-VL-8B最终以mAP@50 87.42%的高精度定位拔得头筹。 与其他LVLM相比,Qwen3-VL-8B还实现了最稳健的结构化元数据F1分数,以及生成连贯的JSON格式机读检测报告的能力。与YOLO和RT-DETR等专用检测器的对比进一步表明,LVLM可以在接近专用检测器精度的同时,提供更丰富、更可解释的输出。
🔄 五、工艺反哺:让AI诊断真正“喂”给产线
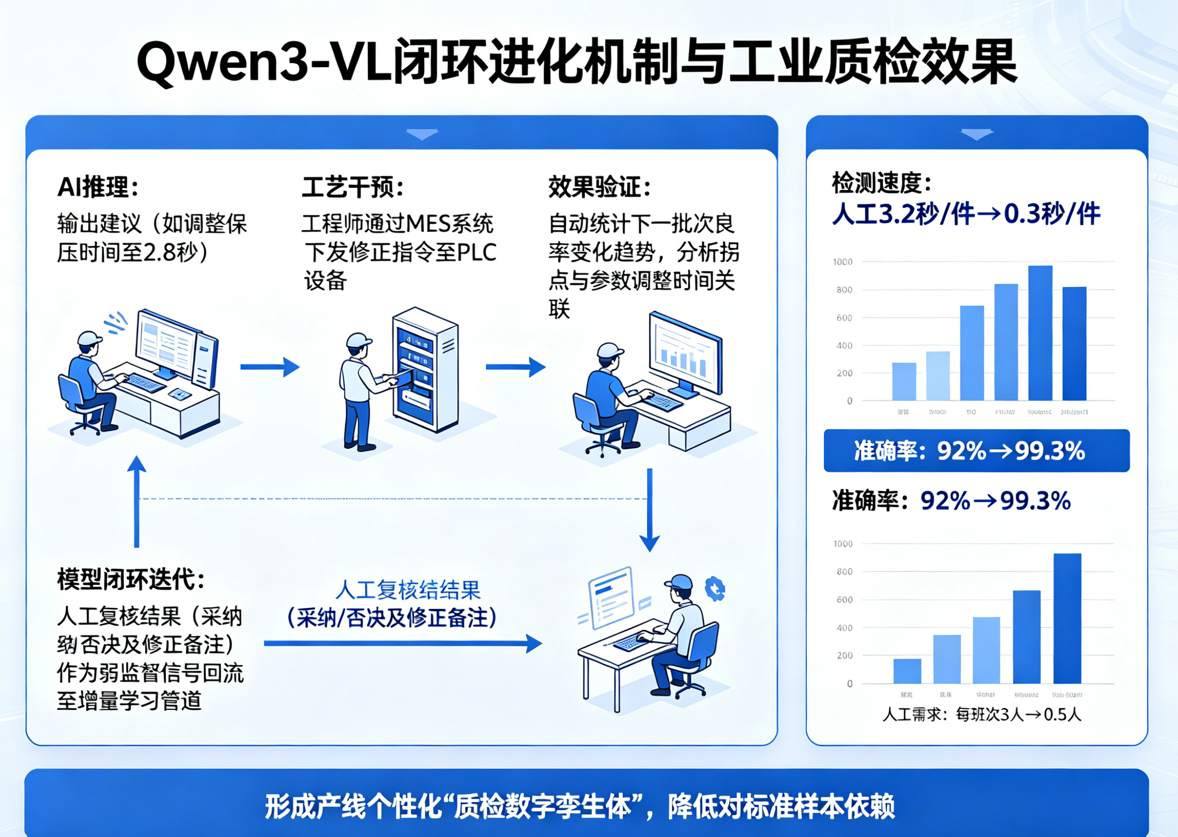
Qwen3-VL最颠覆工业界的价值在于它的“闭环进化机制”。
系统设计了闭环进化机制:每次人工复核结果(包括工程师对AI建议的采纳/否决及修正备注)均作为弱监督信号回流至增量学习管道,触发LoRA适配器的在线微调,使模型持续吸收产线真实反馈,逐步降低对标准样本的依赖,形成具备产线个性化的“质检数字孪生体”。
当模型输出“建议调整保压时间至2.8秒”后,工程师可以将修正指令通过MES系统下发到PLC设备。该工序下一批次的良率变化趋势被自动统计,拐点与参数调整之间的时间关联被分析。最终,这种“AI推理→工艺干预→效果验证→模型闭环迭代”的正向数据流将产线变成了持续进化的自适应系统。
在电子元件质检的实战中,Qwen3-VL交出了一组令人振奋的数据:检测速度从人工的3.2秒/件降至0.3秒/件,准确率从92%飙升至99.3%,人工需求从每班次3人降至0.5人。
💎 六、总结:工业质检的范式跃迁已至
维度 | 传统YOLO方案 | YOLO+Qwen3-VL-Seg协同方案 |
|---|---|---|
输出形式 | 仅边界框+类别 | 像素级掩码+JSON结构化诊断报告 |
缺陷分类 | 预定义固定类别 | 零样本开放词汇识别 |
诊断深度 | “这里有问题” | “是什么、为什么、怎么办” |
工艺闭环 | 无法反哺 | 弱监督反馈+LoRA增量优化 |
边缘部署 | 实时推理(<10ms) | YOLO实时检测+大模型离线诊断 |
工业质检正处于从“机器视觉”到“机器思维”的跃迁拐点。过去,AI只能回答“这是什么缺陷”;现在,Qwen3-VL可以回答“为什么产生这个缺陷”和“该怎么解决”。它不是一次简单更新,而是工业质检范式的根本性重构。
我的建议:如果你正在为产线质检瓶颈发愁,不妨先从一条缺陷类型明确的产线试点,在边缘设备上部署YOLO实时定位,通过API或边缘盒子与现有MES系统对接。让AI开始说人话,让质检开始有温度,让每一行代码都能真正创造价值。
让每一行代码都有温度,我们下期见!🚀
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号