缓存技术:从CPU Cache到AI KV Cache (三)数据库缓存

缓存技术:从CPU Cache到AI KV Cache (三)数据库缓存

霞姐聊IT
发布于 2026-06-03 17:58:04
发布于 2026-06-03 17:58:04
(一)数据库缓存
1.数据库为什么需要缓存
(1)数据库比内核更懂数据
内核看到的是Page1、Page2、Page3这样一个一个的数据块,但它不知道这些数据块里面存放的是哪些业务内容。所以内核的缓存策略是比较粗暴的,但数据库更懂数据,所以它能做的更细致更好。
比如,用户执行SQL语句:
select * from history_2020;
history_2020是个很大的表,比如500GB。
内核可能认为history_2020里面的数据是常用的,因此会将其驻留在缓存中,把其它的真正的热点数据都排挤出去。
而下一批OLTP请求:SELECT * FROM user WHERE id=1;来的时候,又会再次对盘进行读取操作。这就是缓存污染。
数据库则聪明的多,比如PostgreSQL,执行器发现是顺序扫描(Seq Scan)策略时,会启用Buffer Access Strategy,并为该扫描分配一个较小的Ring Buffer(几百KB、几MB级别),读取的过程中,Ring Buffer的数据会循环覆盖,不会影响其它的热点数据。
再比如,用户执行SQL语句:
select * from A join B;
内核在执行时只能看到read(page 100)、read(page 101)、read(page 102),然后启动反应式预读,预读103、104、105页;
而数据库在优化器生成执行计划时,往往可以预测后面将访问哪些数据页。例如Hash Join场景下,数据库可以提前判断需要顺序扫描整张表,从而提前发起异步IO。
所以说,如果数据库自己没有缓存机制,而是依赖内核缓存的话,查询仍然能够执行,而且对于简单顺序扫描效果也不错,但预读启动晚、覆盖范围小、对非连续访问模式(如Bitmap Scan、Join、索引访问等)支持差,最终导致更多 I/O 等待和较低的磁盘并行度。
数据库缓存可以实现主动式预读,提前准备数据页,就像在出发前已经拿到路线图,从而减少IO 等待,提高吞吐和磁盘并行度。
(2)数据库可自主掌握落盘时机
数据库需要保证用户的数据正确性,而事务就是达成这个结果的关键基础。
事务是一组操作,这组操作不可分割,执行结果要么是全部成功,要么是全部失败。
比如下面用户发起了这组事务:
BEGIN;
UPDATE A;
COMMIT;
数据库给用户反馈了COMMIT SUCCESS
这意味着,即使系统崩溃了,这个结果也不能变。
那么,如果完全采用操作系统的缓存技术,可能会出现:
虽然给用户反馈了操作成功,但OS 内核并没有马上落盘,而是在未来某天再进行刷盘操作。
而在落盘之前,如果出现断电,那么事务的语义就会被破坏了。
而数据库可以通过WAL日志机制,先保证对应的日志先落盘,返回用户事务成功,而数据页则可以延迟到后续Checkpoint阶段再统一落盘。WAL已经完成落盘,这样即使在数据页落盘之前,系统断电了,数据库也可以通过日志重做,来进行未完成的更新,从而保证了数据正确性。
另外,数据库缓存不仅保障事务正确性,还为数据库提供了额外优化能力,如异步预取、顺序读合并等,这些都是在缓存存在的前提下才能实现的性能增强手段。
2.数据库缓存设计
想要知道数据库缓存是如何设计的,必须要知道它的业务流程。
一条SQL的执行过程是什么样的?
当用户输入下面这条SQL语句进行查询时:
SELECT name FROM user WHERE id = 100;
数据库内部会大致进行下面几个步骤:
解析SQL
↓
获取表结构
↓
查找索引
↓
读取
↓
生成结果
↓
返回用户
对应就会产生元数据访问开销、索引访问开销、数据访问开销、结果计算开销。
如果涉及到写操作,那么还会产生事务持久化开销。
所以数据库缓存的设计方案,要围绕降低这五类开销展开,因此它会想办法把元数据、索引、数据、执行结果和日志这几类数据缓存起来。
本质上,数据库缓存并不是单纯缓存“数据”,而是在缓存SQL执行链路上最昂贵的中间结果。
下面我们就介绍下这几类缓存的方案:
(1)数据缓存(Data Cache)
数据缓存的缓存对象是数据表页(Table Page),目的是为了减少磁盘读取成本。
业务数据表,会被数据库拆分为固定大小的数据页进行存储,比如一张user表会被拆分为Page1、Page2、Page3等多个数据页。
以SQL SELECT * FROM user WHERE id=100为例:
首次执行该时,数据库需要从磁盘读取对应的数据页,加载至内存的缓冲池中再返回数据;
第二次执行相同查询时,数据已常驻内存,可直接从缓冲池返回结果,无需访问磁盘。
数据缓存是数据库体系中最核心的缓存机制,是各大主流数据库的基础核心组件。PostgreSQL中为Shared Buffer,Oracle中为Database Buffer Cache,InnoDB和SQL Server则统一称之为Buffer Pool。
(2)索引缓存(Index Cache)
索引缓存的缓存对象主要是B+树索引的根节点(B+Tree Root)和内部节点(B+Tree Internal Node),目的是减少定位数据的成本。
执行SQL查询时,首先不是读数据,而是通过B+树的根节点、内部节点逐层检索定位数据:
Root
↓
Internal
↓
Leaf
所以这类顶层索引节点也会被长期驻留在内存中。
索引缓存具备容量小、价值极高的显著特点,例如一张10TB的超大数据表,其索引根节点仅占用数KB的存储空间,但支撑着整张表的所有查询路由,是数据库缓存命中率最高的缓存模块。
实际工程中,大多数数据库都会将索引页和数据页统一存放在一个空间内,比如Buffer Pool。
(3)日志缓存(Log Cache)
日志缓存的缓存对象是WAL预写日志和Redo Log,目的是降低事务提交成本,主要用于数据写入、更新类事务操作。
例如执行SQL: UPDATE user SET age=20时,
如果每次都:
生成日志
↓
立即写磁盘
磁盘压力会非常大。
因此,数据库采用的方案是:
不将修改数据直接写入磁盘,而是先将事务操作日志写入日志缓存,再通过WAL(预写日志)机制完成日志落盘,最终提交事务。
同时,它能将数据库的随机数据更新操作,转化为日志的顺序写入操作,大幅降低磁盘写入的性能损耗。
日志缓存支撑了数据库ACID特性中持久性(Durability),保障了事务提交后数据不会因系统异常丢失。
(4)执行结果缓存(Result Cache)
执行结果缓存的缓存对象是高频查询SQL语句的执行结果,目的是避免重复计算。
比如执行SELECT count(*) FROM user统计查询后,数据库会直接缓存统计结果,下次执行相同SQL时,可直接返回缓存结果。
常见的执行结果缓存有Oracle Result Cache、Redis Query Cache,以及已被废弃的MySQL Query Cache。
不过在现代数据库体系中,原生执行结果缓存的应用越来越少,核心原因是缓存失效成本过高。
当数据表执行INSERT、UPDATE、DELETE等修改操作后,表内对应的所有查询结果缓存都会批量失效,频繁的数据变更会导致缓存频繁刷新,反而损耗性能。
(5)元数据缓存(Metadata Cache)
元数据缓存的缓存对象是数据库的各类元数据信息,包含表定义、索引定义、数据统计信息、系统目录数据等,目的是规避重复查询系统表的开销,减少SQL编译成本。
每一条SQL语句执行前,数据库都需要解析识别目标表结构、字段类型、索引分布等基础信息,如果每次执行SQL都重新读取磁盘上的系统表,会产生大量无效IO。
而元数据缓存可将这类固定的结构信息常驻内存,大幅提升SQL解析与执行的前置效率。
PostgreSQL依靠pg_class、pg_attribute等系统表存储元数据并缓存,Oracle则通过数据字典缓存实现。
所以总结来看,可将数据库缓存统一划分为三大类:
第一类是缓存数据,比如Buffer Pool,目标是缓存数据表页、索引页,减少磁盘读写访问次数;
第二类是缓存状态,比如WAL Buffer,目标是缓存事务日志状态,保障数据库事务的完整性与持久性;
第三类是缓存计算结果,比如Query Cache,目标是缓存SQL查询的计算结果,避免重复执行相同计算,节省CPU计算资源。
3.数据库缓存和内核缓存的关系
数据库缓存和内核缓存不是替代关系,而是不同抽象层次上的协作关系。二者分工明确、互相补充。
下面分析一下数据库缓存和内核缓存的典型协作场景:
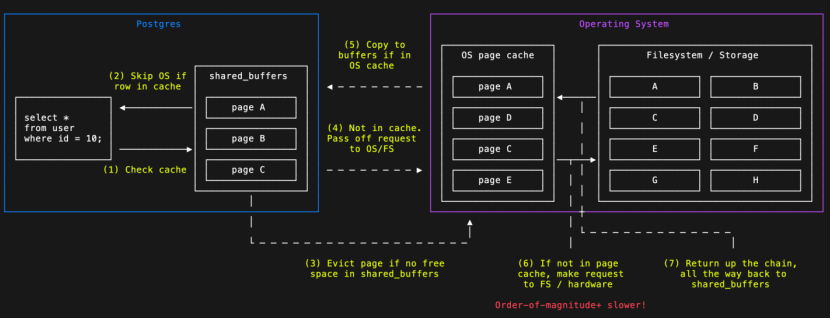
(1)使用Page Cache模式
数据库负责事务顺序、热点页长期驻留等逻辑优化,内核负责顺序预读、DMA、I/O 合并等物理 I/O优化。
PostgreSQL长期采用此策略,选择信任Page Cache优势,自身则专注于于事务语义和缓存命中率优化。
不过,这类方案下,数据页会在数据库缓存和内核Page Cache 中同时存在,读入时先进入 Page Cache 再拷贝到数据库缓存;写出时先从数据库缓存拷贝到 Page Cache 再落盘,存在内存浪费。
(2)绕开 Page Cache的O_DIRECT 模式
数据页绕过内核Page Cache,由数据库 Buffer Pool完全管理。
这样的协作方案能避免同一页在内存中存在两份副本,节省内存;另外数据库可以完全控制缓存策略、预取、淘汰和落盘时机。
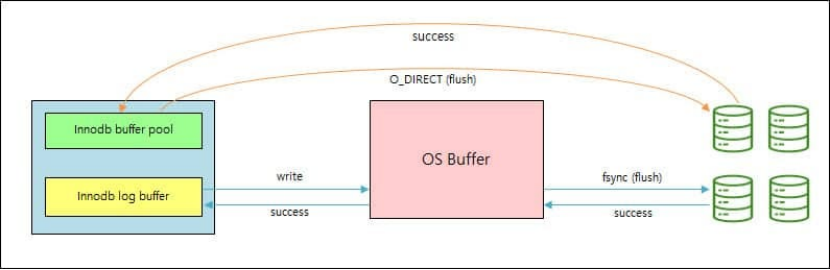
不过这也不是说Page Cache就完全被抛弃了,有一些场景仍然需要经过它:
-所有 I/O 操作的参数必须与底层存储设备的块大小对齐,否则会做通过Page Cache临时拷贝。
-元数据缓存、和日志缓存仍可能走 Page Cache。
Oracle、MySQL InnoDB和等采用的是这类协作方案。
PostgreSQL虽然长期采用Shared Buffer与Page Cache协同工作的设计方案,但近年来社区也在持续探索Direct IO相关能力,希望在减少双重缓存的同时保留PostgreSQL原有架构优势。
4.数据库缓存是数据语义型缓存
通过前几天文章的介绍,我们可以体会到:
CPU Cache并不知道程序在计算什么,它只利用时间局部性和空间局部性缓存指令与数据;
Page Cache也不知道文件中存放的是什么内容,它只能根据页访问历史猜测哪些页更重要。
而数据库缓存已经能够理解数据的业务含义。
它知道哪些页是B+树根节点,哪些页是热点用户数据,哪些页只是一次性的全表扫描结果;它知道事务何时提交、日志何时必须落盘、哪些查询未来还会再次访问。
所以数据库缓存其实已经演变成了一个数据价值管理系统。
它不仅决定哪些数据应该被缓存,更决定哪些数据不值得缓存;不仅决定数据何时被读取,更决定数据何时被写回磁盘。
它距离业务语义更近,所以能够他能做出的优化更精细,带来用户价值更大,这也是它必须拥有缓存的根本原因。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号