深度学习中的激活函数:从Sigmoid到ReLU及其变体
原创

深度学习中的激活函数:从Sigmoid到ReLU及其变体 🧠➡️⚡
一、神经网络与线性变换的局限性 🤔
神经网络的基本结构通常包括输入层、隐藏层和输出层。其中,每一层的核心运算是加权求和,即线性变换:
y=wx+b多个线性层叠加后,其整体效果仍为一个线性函数。例如,两个线性层叠加:
y=w2(w1x+b1)+b2=(w2w1)x+(w2b1+b2)本质上依然是线性变换,这意味着无论网络多深,其表达能力被限制在拟合线性数据上,无法描述复杂的非线性模式,例如曲线边界、螺旋分布等。😅
二、激活函数的作用 💡
为了解决上述问题,我们需要在网络的每一线性层后引入非线性映射。这就是激活函数的核心作用:
- 引入非线性:将神经元的输出通过一个非线性函数进行变换,使网络能够学习并表达复杂的数据模式。✨
- 激活函数可表示为:给定线性层输出 y,实际输出为 f(y),其中 f为激活函数。
三、常见激活函数及其特性 📊
3.1 Sigmoid 🧮
公式:
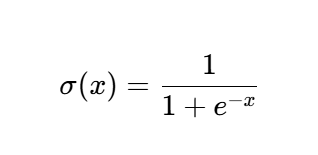
特性:
- 输出范围在 (0,1) 之间,平滑且单调递增。
- 导数计算简单:σ′(x)=σ(x)(1−σ(x))。
优势:
- 输出范围有限,不易发生数值溢出。👍
- 因其输出在 0 到 1 之间,常被用于二分类任务的输出层,可直观解释为概率。
缺点:
- 梯度消失:Sigmoid 的导数最大值仅为 0.25。在深层网络的反向传播中,梯度经过多层 Sigmoid 后会迅速衰减,趋近于 0,导致较早层的参数几乎无法更新,学习停滞。😰
3.2 ReLU ⚡
公式:
ReLU(x)=max(0,x)特性:
- 输入 x为正时,输出 x本身;为负时,输出 0。
优势:
- 缓解梯度消失:当 x>0时,其导数为 1,梯度可以无损地反向传播,极大支持了深层网络的训练。🚀
- 计算高效:只需判断输入的正负,没有复杂的指数运算,训练速度显著加快。💨
- 稀疏激活:当输入为负时,输出为 0,这模拟了人脑神经元的稀疏激活模式(通常只有 1%-4% 的神经元同时激活)。这种特性可以减少特征之间的冗余,帮助网络强化对关键特征的提取。🧠
缺点:
- 神经元死亡:在训练过程中,一旦某个神经元的权重更新后使其线性输出持续为负,ReLU 的输出及导数将恒为 0。这意味着后续训练中该神经元无法被再次激活,参数不再更新,成为“死神经元”。💀
3.3 ReLU 的改进版本 🔧
针对 ReLU 的“神经元死亡”问题,研究者提出了多种改进方案:
1. Leaky ReLU 🩹
公式:
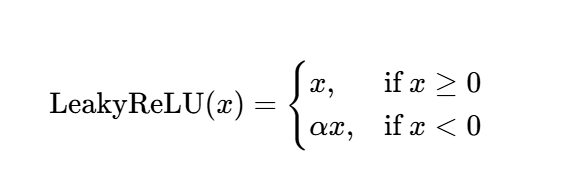
其中,α是一个很小的正常数(如 0.01)。
特性:
- 在 x<0时,赋予一个小的斜率 α,而不是直接置 0。🔄
- 这确保了负区间也有一个微小的梯度,使得参数在训练中仍有更新的可能,有效缓解了神经元死亡问题。✅
2. GELU 🏆
公式:

特性:
- GELU 结合了输入值 x和它的概率 P(X≤x)。可以理解为,它根据输入的大小,以概率方式对输入进行缩放。🎲
- 在 x为正时,输出接近 x;在 x为负时,输出接近 0,但这个过程是平滑、非线性的。📈
- 由于这种概率平滑性,GELU 在 Transformer 模型(如 BERT、GPT)中取得了巨大成功,通常比 ReLU 和其变体表现更好,尤其是在自然语言处理任务中。🌟
四、总结 🎯
激活函数是神经网络能够成为“通用函数逼近器”的关键🔑。从经典的 Sigmoid 📜 到主流的 ReLU ⚡,再到针对其缺陷的改进版如 Leaky ReLU 🩹 和性能更优的 GELU 🏆,每一次演进都旨在更好地平衡非线性表达能力、梯度传播效率和计算成本💰。在设计和选择网络时,根据具体任务和数据特性选择合适的激活函数,是模型成功的重要一环!🎉
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号