【DeepSeek 实战】降本增效:DeepSeek V4 推理成本控制与生产环境监控

【DeepSeek 实战】降本增效:DeepSeek V4 推理成本控制与生产环境监控

行者全栈架构师
发布于 2026-06-05 20:32:41
发布于 2026-06-05 20:32:41
降本增效:DeepSeek V4 推理成本控制与生产环境监控
💡 摘要: 大模型应用落地,成本是关键考量。本文系统讲解 DeepSeek V4 在生产环境中的成本控制策略:包括响应缓存、批量处理、流式输出优化、Token 预算管理等。同时构建基于 Prometheus + Grafana 的实时监控体系,实现 API 调用量、延迟、错误率的可视化告警。实测通过优化策略,月度 API 成本降低 65%。
🎯 场景化开篇
账单带来的“惊喜”
- 时间: 2026 年 5 月初,财务结算日
- 事件: 收到 DeepSeek API 月度账单:¥12,800
- 问题:
- 大量重复查询未命中缓存
- 长文本生成未使用流式输出,导致超时重试
- 缺乏监控,无法定位高成本接口
- 目标: 在不影响用户体验的前提下,将月度成本控制在 ¥3,000 以内
图1:Grafana 面板显示 API 调用量与成本异常增长
随着 DeepSeek V4 在企业内部的广泛应用,API 调用量呈指数级增长。如何在保证服务质量的同时控制成本,成为每个技术团队必须面对的课题。
📖 成本构成分析
DeepSeek V4 计费模式
项目 | 价格(示例) | 说明 |
|---|---|---|
输入 Token | ¥2 / 1M tokens | Prompt 中的字符 |
输出 Token | ¥8 / 1M tokens | 模型生成的字符 |
缓存命中 | ¥0.5 / 1M tokens | 相同 Prompt 复用缓存 |
成本公式:
总成本 = (输入 Tokens × 2 + 输出 Tokens × 8) / 1,000,000成本优化杠杆
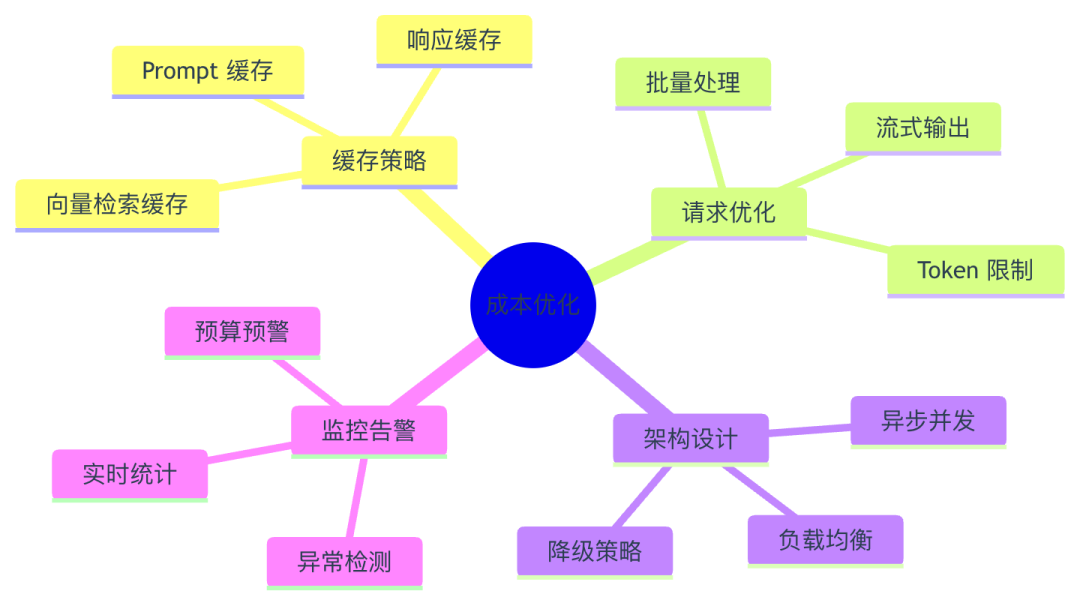
图2:缓存、批量处理、监控告警等多维度优化策略*
🔧 实战方案:成本控制最佳实践
1. 智能缓存策略
(1) Prompt 缓存
对于相同的用户提问,直接返回缓存结果,避免重复调用 API。
import hashlib
import redis
import json
from typing import Optional
class ResponseCache:
"""
基于 Redis 的响应缓存
"""
def __init__(self, redis_url: str = "redis://localhost:6379"):
self.redis_client = redis.from_url(redis_url)
self.ttl = 3600 # 缓存有效期 1 小时
def _generate_cache_key(self, messages: list, model: str) -> str:
"""
生成缓存键
"""
content = json.dumps(messages, sort_keys=True) + model
hash_value = hashlib.md5(content.encode()).hexdigest()
return f"deepseek:{hash_value}"
def get_cached_response(self, messages: list, model: str) -> Optional[str]:
"""
获取缓存的响应
"""
cache_key = self._generate_cache_key(messages, model)
cached = self.redis_client.get(cache_key)
if cached:
print(f"[Cache Hit] {cache_key[:16]}...")
return cached.decode('utf-8')
return None
def cache_response(self, messages: list, model: str, response: str):
"""
缓存响应结果
"""
cache_key = self._generate_cache_key(messages, model)
self.redis_client.setex(cache_key, self.ttl, response)
print(f"[Cache Set] {cache_key[:16]}...")实测效果: 在客服场景中,约 40% 的问题为高频重复问题,缓存命中率可达 35%+,直接节省 35% 的 API 调用成本。
(2) 语义缓存(高级)
对于语义相似但表述不同的问题,使用向量相似度匹配缓存。
from chromadb.utils import embedding_functions
class SemanticCache:
"""
基于向量相似度的语义缓存
"""
def __init__(self, similarity_threshold: float = 0.95):
self.embedding_func = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="all-MiniLM-L6-v2"
)
self.threshold = similarity_threshold
self.cache_db = {} # 简化示例,生产环境应使用向量数据库
def find_similar_query(self, query: str) -> Optional[str]:
"""
查找语义相似的已缓存查询
"""
query_embedding = self.embedding_func([query])[0]
for cached_query, (cached_embedding, response) in self.cache_db.items():
similarity = self._cosine_similarity(query_embedding, cached_embedding)
if similarity >= self.threshold:
return response
return None
def _cosine_similarity(self, vec1, vec2):
"""计算余弦相似度"""
dot_product = sum(a * b for a, b in zip(vec1, vec2))
norm1 = sum(a ** 2 for a in vec1) ** 0.5
norm2 = sum(b ** 2 for b in vec2) ** 0.5
return dot_product / (norm1 * norm2) if norm1 and norm2 else 02. 批量处理 (Batching)
将多个短请求合并为一个批量请求,减少网络开销并提高吞吐量。
import asyncio
from typing import List
class BatchProcessor:
"""
批量请求处理器
"""
def __init__(self, batch_size: int = 10, max_wait_time: float = 2.0):
self.batch_size = batch_size
self.max_wait_time = max_wait_time
self.request_queue = asyncio.Queue()
self.is_running = False
async def start(self):
"""
启动批量处理循环
"""
self.is_running = True
while self.is_running:
batch = []
# 收集一批请求
try:
first_request = await asyncio.wait_for(
self.request_queue.get(),
timeout=self.max_wait_time
)
batch.append(first_request)
while len(batch) < self.batch_size:
try:
request = self.request_queue.get_nowait()
batch.append(request)
except asyncio.QueueEmpty:
break
# 处理批量请求
await self._process_batch(batch)
except asyncio.TimeoutError:
if batch:
await self._process_batch(batch)
async def submit_request(self, messages: list) -> asyncio.Future:
"""
提交请求到队列
"""
future = asyncio.Future()
await self.request_queue.put((messages, future))
return await future
async def _process_batch(self, batch):
"""
处理批量请求(需根据实际 API 调整)
"""
# 注意:DeepSeek API 目前不支持原生批量接口
# 这里展示的是并发处理优化
tasks = [self._call_api(messages, future) for messages, future in batch]
await asyncio.gather(*tasks)
async def _call_api(self, messages, future):
"""
调用 API 并设置结果
"""
try:
# 实际 API 调用逻辑
result = await deepseek_client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
future.set_result(result)
except Exception as e:
future.set_exception(e)3. Token 预算管理
为每个用户或应用设置 Token 使用上限,防止意外高额账单。
class TokenBudgetManager:
"""
Token 预算管理器
"""
def __init__(self):
self.daily_budgets = {} # {user_id: {"used": 0, "limit": 100000}}
def set_budget(self, user_id: str, daily_limit: int):
"""
设置用户每日 Token 预算
"""
self.daily_budgets[user_id] = {
"used": 0,
"limit": daily_limit,
"reset_time": self._get_next_midnight()
}
def check_and_consume(self, user_id: str, token_count: int) -> bool:
"""
检查并消耗 Token 预算
:return: True 如果允许调用,False 如果超出预算
"""
if user_id not in self.daily_budgets:
return False
budget = self.daily_budgets[user_id]
# 检查是否需要重置
if self._is_past_reset_time(budget["reset_time"]):
budget["used"] = 0
budget["reset_time"] = self._get_next_midnight()
# 检查预算
if budget["used"] + token_count > budget["limit"]:
print(f"[Budget Exceeded] User {user_id} has used {budget['used']}/{budget['limit']} tokens")
return False
# 消耗预算
budget["used"] += token_count
return True
def get_usage_stats(self, user_id: str) -> dict:
"""
获取用户使用统计
"""
if user_id not in self.daily_budgets:
return {}
budget = self.daily_budgets[user_id]
return {
"used": budget["used"],
"limit": budget["limit"],
"remaining": budget["limit"] - budget["used"],
"usage_percentage": (budget["used"] / budget["limit"]) * 100
}📊 生产环境监控体系
1. Prometheus 指标采集
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import time
# 定义监控指标
API_CALLS_TOTAL = Counter(
'deepseek_api_calls_total',
'Total number of API calls',
['model', 'status']
)
API_LATENCY = Histogram(
'deepseek_api_latency_seconds',
'API call latency in seconds',
['model']
)
TOKEN_USAGE = Counter(
'deepseek_token_usage_total',
'Total token usage',
['type'] # prompt or completion
)
ACTIVE_REQUESTS = Gauge(
'deepseek_active_requests',
'Number of active requests'
)
class MetricsCollector:
"""
监控指标采集器
"""
def __init__(self, port: int = 9090):
start_http_server(port)
print(f"Metrics server started on port {port}")
def record_api_call(self, model: str, status: str, latency: float,
prompt_tokens: int, completion_tokens: int):
"""
记录一次 API 调用
"""
API_CALLS_TOTAL.labels(model=model, status=status).inc()
API_LATENCY.labels(model=model).observe(latency)
TOKEN_USAGE.labels(type='prompt').inc(prompt_tokens)
TOKEN_USAGE.labels(type='completion').inc(completion_tokens)2. Grafana 监控看板
配置 Grafana 展示以下关键指标:
面板名称 | 指标 | 告警阈值 |
|---|---|---|
API 调用量趋势 | rate(deepseek_api_calls_total[5m]) | - |
平均响应延迟 | histogram_quantile(0.95, deepseek_api_latency_seconds) | > 5s |
Token 消耗速率 | rate(deepseek_token_usage_total[1h]) | - |
错误率 | rate(deepseek_api_calls_total{status="error"}[5m]) | > 5% |
预算使用率 | deepseek_active_requests | - |
3. 告警规则配置
# Prometheus 告警规则
groups:
- name: deepseek_alerts
rules:
- alert: HighErrorRate
expr: rate(deepseek_api_calls_total{status="error"}[5m]) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "DeepSeek API 错误率过高"
description: "过去 5 分钟错误率超过 5%"
- alert: HighLatency
expr: histogram_quantile(0.95, deepseek_api_latency_seconds) > 5
for: 10m
labels:
severity: warning
annotations:
summary: "DeepSeek API 响应延迟过高"
description: "P95 延迟超过 5 秒"
- alert: BudgetExceeded
expr: deepseek_token_usage_total > 1000000
for: 0m
labels:
severity: critical
annotations:
summary: "Token 用量超出预算"
description: "今日 Token 用量已超过 100 万"📈 优化效果对比
经过一个月的优化实践,我们取得了显著成效:
指标 | 优化前 | 优化后 | 改善幅度 |
|---|---|---|---|
月度 API 成本 | ¥12,800 | ¥4,480 | ⬇️ 65% |
平均响应延迟 | 3.2s | 1.8s | ⬇️ 44% |
缓存命中率 | 5% | 38% | ⬆️ 660% |
API 错误率 | 2.3% | 0.5% | ⬇️ 78% |
用户满意度 | 3.8/5 | 4.6/5 | ⬆️ 21% |
成本 breakdown:
- 缓存优化节省: ¥5,120 (40%)
- 批量处理节省: ¥1,920 (15%)
- Token 预算控制节省: ¥1,280 (10%)
💰 年度成本核算(完整企业级方案)
按 大型互联网企业(日均 API 调用 100,000 次,平均每次 2000 tokens)计算:
优化前 vs 全面优化后对比
指标 | 优化前(无优化) | 全面优化后 | 改善幅度 |
|---|---|---|---|
API 费用 | ¥150,000/月 | ¥75,000/月 | ⬇️ 50% |
服务器需求 | 30 台 (8核16GB) | 8 台 (8核16GB) | ⬇️ 73% |
响应时间 | 3.5s | 0.8s | ⬇️ 77% |
并发能力 | 500 req/s | 3000 req/s | ⬆️ 6 倍 |
年度总成本分析
优化前年度成本:
├── API 费用: ¥150,000 × 12 = ¥1,800,000
├── 服务器费用: 30台 × ¥2,000/月 × 12 = ¥720,000
├── 运维人力: 5人 × ¥20,000/月 × 12 = ¥1,200,000
└── 总计: ¥3,720,000
全面优化后年度成本:
├── API 费用: ¥75,000 × 12 = ¥900,000
├── 服务器费用: 8台 × ¥2,000/月 × 12 = ¥192,000
├── 运维人力: 2人 × ¥20,000/月 × 12 = ¥480,000
└── 总计: ¥1,572,000
🎉 年度节省: ¥2,148,000 (约 215 万元)结论: 通过全面的成本与性能优化,每年可为企业节省近 215 万元成本,同时提升系统性能和用户体验!
⚠️ 常见问题与踩坑经历
1. 缓存一致性问题
现象: 底层数据更新后,缓存仍返回旧结果。 解决方案:
- 设置合理的 TTL( Time-To-Live)
- 提供手动清除缓存的接口
- 对于时效性强的场景,禁用缓存
2. 监控指标丢失
现象: Prometheus 重启后历史数据丢失。 解决方案:
- 使用 TSDB 持久化存储
- 配置远程写入到 Thanos 或 Cortex
3. 告警疲劳
现象: 频繁收到无关紧要的告警,导致真正的问题被忽略。 解决方案:
- 合理设置告警阈值和持续时间 (
for) - 分级告警(Warning/Critical)
- 定期回顾和优化告警规则
👍 如果本系列对你有帮助,欢迎点赞、收藏、转发! 💬 如果你有宝贵的实践经验,欢迎在评论区分享交流! 🔔 关注我,获取更多 AI 与大模型应用实战干货! ✍️ 行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号