Cache System:多级缓存与缓存一致性

Cache System:多级缓存与缓存一致性

安全风信子
发布于 2026-06-06 08:47:48
发布于 2026-06-06 08:47:48
作者: HOS(安全风信子) 日期: 2026-05-25 主要来源平台: GitHub 摘要: 缓存是AI IDE性能优化的关键基础设施。从Token缓存到代码片段缓存,从LSP响应缓存到语义搜索结果缓存,多级缓存体系能显著提升系统响应速度、降低后端负载。本文深入讲解Cache System的实现原理与工程实践:缓存策略层面涵盖LRU、LFU、TTL等淘汰算法与更新策略;缓存层级层面详述L1本地内存缓存、L2进程缓存、L3分布式缓存的设计与协同;重点剖析Caffeine与Guava Cache的内部机制、Redis Cluster的部署与客户端选择;深入探讨Write-through与Write-back等缓存一致性策略;系统讲解缓存击穿、缓存雪崩、缓存穿透三大问题的根因与防护方案;最后给出支持多级缓存的Cache System完整实现,涵盖接口设计、配置管理、监控指标等工程细节。
目录- 本节核心技术价值
- 1. 概述:缓存技术在AI IDE中的角色
- 1.1 为什么AI IDE需要多级缓存
- 1.2 多级缓存架构总览
- 1.3 缓存系统设计原则
- 2. 缓存策略:淘汰算法与更新策略
- 本节核心技术价值
- 2.1 淘汰算法基础理论
- 2.2 LRU:最近最少使用算法
- 2.2.1 LRU的数学模型
- 2.2.2 LRU-K算法
- 2.2.3 LRU实现:基于双向链表
- 2.2.4 LRU在AI IDE中的应用场景
- 2.3 LFU:最不经常使用算法
- 2.3.1 LFU的数学模型
- 2.3.2 LFU的Counter Overflow问题
- 2.3.3 LFU实现:基于最小堆
- 2.4 TTL:基于时间的过期策略
- 2.4.1 TTL的数学模型
- 2.4.2 带TTL的缓存实现
- 2.5 淘汰算法对比与选型
- 3. 缓存层级:L1、L2、L3的设计
- 本节核心技术价值
- 3.1 分层缓存架构原理
- 3.1.1 分层缓存的理论基础
- 3.1.2 层间数据流动策略
- 3.2 L1本地缓存设计与实现
- 3.2.1 Caffeine Cache深度解析
- 3.2.2 Guava Cache配置详解
- 3.3 L2进程缓存设计与实现
- 3.3.1 Ehcache 3.x架构
- 3.4 L3分布式缓存设计与实现
- 3.4.1 Redis Cluster架构
- 3.4.2 Redis客户端配置
- 3.5 层级间数据流动策略实现
- 4. 本地缓存:Caffeine与Guava Cache的深度使用
- 本节核心技术价值
- 4.1 Caffeine内部机制深度解析
- 4.1.1 Window TinyLFU算法实现
- 4.2 Guava Cache高级特性
- 5. 分布式缓存:Redis Cluster的深度部署
- 本节核心技术价值
- 5.1 Redis Cluster架构与原理
- 5.1.1 数据分片机制
- 5.1.2 高可用机制
- 5.2 Redis Cluster部署配置
- 5.3 客户端路由与故障处理
- 6. 缓存一致性:Write-through与Write-back
- 本节核心技术价值
- 6.1 缓存写入策略概述
- 6.2 Write-through(写穿透)
- 6.3 Write-back(写回)
- 6.4 缓存一致性协议
- 6.4.1 Cache-Aside模式
- 7. 缓存问题:击穿、雪崩、穿透的解决方案
- 本节核心技术价值
- 7.1 缓存击穿(Cache Breakdown)
- 7.1.1 问题描述
- 7.1.2 解决方案
- 7.2 缓存雪崩(Cache Avalanche)
- 7.2.1 问题描述
- 7.2.2 解决方案
- 7.3 缓存穿透(Cache Penetration)
- 7.3.1 问题描述
- 7.3.2 解决方案
- 8. 实践:实现一个支持多级缓存的Cache System
- 本节核心技术价值
- 8.1 系统架构设计
- 8.2 核心接口定义
- 8.3 完整实现代码
- 8.4 使用示例
- 9. 总结与展望
- 9.1 核心要点回顾
- 9.2 未来发展趋势
- 9.3 实践建议
- A. Cache System完整代码
- 1.1 为什么AI IDE需要多级缓存
- 1.2 多级缓存架构总览
- 1.3 缓存系统设计原则
- 本节核心技术价值
- 2.1 淘汰算法基础理论
- 2.2 LRU:最近最少使用算法
- 2.2.1 LRU的数学模型
- 2.2.2 LRU-K算法
- 2.2.3 LRU实现:基于双向链表
- 2.2.4 LRU在AI IDE中的应用场景
- 2.3 LFU:最不经常使用算法
- 2.3.1 LFU的数学模型
- 2.3.2 LFU的Counter Overflow问题
- 2.3.3 LFU实现:基于最小堆
- 2.4 TTL:基于时间的过期策略
- 2.4.1 TTL的数学模型
- 2.4.2 带TTL的缓存实现
- 2.5 淘汰算法对比与选型
- 本节核心技术价值
- 3.1 分层缓存架构原理
- 3.1.1 分层缓存的理论基础
- 3.1.2 层间数据流动策略
- 3.2 L1本地缓存设计与实现
- 3.2.1 Caffeine Cache深度解析
- 3.2.2 Guava Cache配置详解
- 3.3 L2进程缓存设计与实现
- 3.3.1 Ehcache 3.x架构
- 3.4 L3分布式缓存设计与实现
- 3.4.1 Redis Cluster架构
- 3.4.2 Redis客户端配置
- 3.5 层级间数据流动策略实现
- 本节核心技术价值
- 4.1 Caffeine内部机制深度解析
- 4.1.1 Window TinyLFU算法实现
- 4.2 Guava Cache高级特性
- 本节核心技术价值
- 5.1 Redis Cluster架构与原理
- 5.1.1 数据分片机制
- 5.1.2 高可用机制
- 5.2 Redis Cluster部署配置
- 5.3 客户端路由与故障处理
- 本节核心技术价值
- 6.1 缓存写入策略概述
- 6.2 Write-through(写穿透)
- 6.3 Write-back(写回)
- 6.4 缓存一致性协议
- 6.4.1 Cache-Aside模式
- 本节核心技术价值
- 7.1 缓存击穿(Cache Breakdown)
- 7.1.1 问题描述
- 7.1.2 解决方案
- 7.2 缓存雪崩(Cache Avalanche)
- 7.2.1 问题描述
- 7.2.2 解决方案
- 7.3 缓存穿透(Cache Penetration)
- 7.3.1 问题描述
- 7.3.2 解决方案
- 本节核心技术价值
- 8.1 系统架构设计
- 8.2 核心接口定义
- 8.3 完整实现代码
- 8.4 使用示例
- 9.1 核心要点回顾
- 9.2 未来发展趋势
- 9.3 实践建议
本节核心技术价值
本文为你提供的核心价值是掌握多级缓存系统设计的核心原理与工程实践。通过本文,你将理解从本地缓存到分布式缓存的完整技术栈,学会设计高命中率、低延迟、强一致的缓存架构,掌握缓存击穿/雪崩/穿透的根因分析与解决方案,并获得可直接应用于AI IDE项目的Cache System生产级实现代码。这不是简单的缓存使用指南,而是揭示缓存系统本质设计哲学的深度技术文。
1. 概述:缓存技术在AI IDE中的角色
1.1 为什么AI IDE需要多级缓存
在现代AI IDE系统中,缓存技术是性能优化的核心支柱。以一个典型的AI辅助编程场景为例:当开发者输入代码时,系统需要完成语法分析、语义理解、代码补全建议生成、错误检测、代码检索等一系列计算密集型操作。如果没有缓存,每次按键都可能触发完整的计算链路,导致数百毫秒的响应延迟,用户体验严重下降。
根据Google的研究表明1,用户对100ms以内的响应延迟几乎无感知,100ms-300ms是可接受范围,超过1秒则会明显打断思维流。AI IDE的场景更加严苛——代码补全、语义搜索、LSP响应等操作需要在保持交互流畅性的同时完成复杂的AI推理。通过精心设计的多级缓存体系,我们可以将大量重复计算的响应时间从数百毫秒降低到微秒级。
在AI IDE中,缓存发挥作用的关键场景包括:
缓存场景 | 数据类型 | 典型大小 | 访问频率 | 延迟要求 |
|---|---|---|---|---|
Token缓存 | 词法分析结果 | KB级 | 极高 | <1ms |
LSP响应缓存 | 诊断、补全 | KB~MB级 | 高 | <10ms |
代码片段缓存 | 常用代码模式 | KB~MB级 | 中 | <50ms |
语义搜索缓存 | 嵌入向量+结果 | MB~GB级 | 中低 | <100ms |
AST缓存 | 抽象语法树 | KB~MB级 | 高 | <10ms |
模型推理缓存 | Prompt+响应 | MB~GB级 | 低 | <500ms |
1.2 多级缓存架构总览
多级缓存(Multi-Level Cache)是一种分层缓存设计理念,通过在数据访问路径上部署多个层级的缓存来最大化缓存命中率并最小化访问延迟。每一级缓存都有其独特的定位、容量和性能特征,多级缓存之间通过特定的同步策略协同工作。
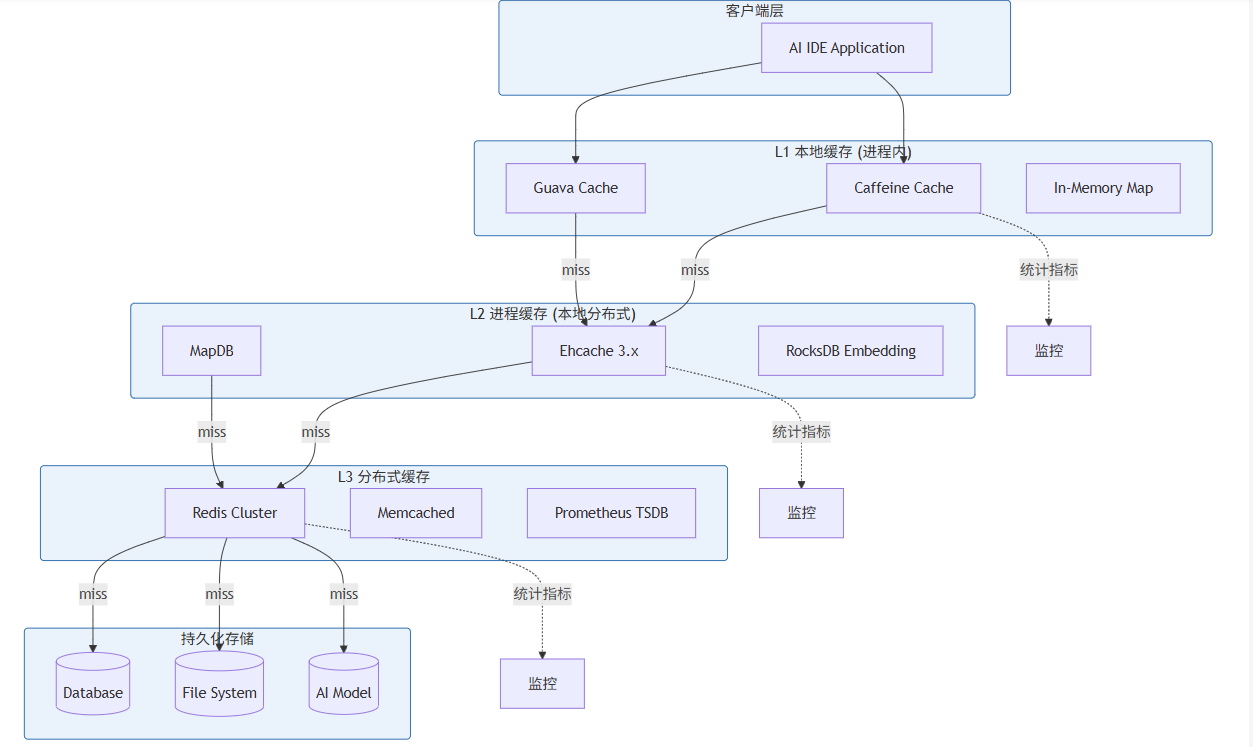
L1本地缓存位于应用进程内部,直接使用JVM堆内存或堆外内存,访问延迟最低(纳秒~微秒级),但容量受限于单个JVM进程的内存大小。通常用于存储访问频率极高、数据量较小、进程内共享的数据,如热点Token序列、常用配置等。
L2进程缓存部署在本地服务器的多个进程之间,典型实现包括Ehcache、MapDB、RocksDB等。这类缓存通常使用堆外内存或内存映射文件,单机容量可达数GB到数十GB,访问延迟在微秒到毫秒级。适合存储中等大小、需要跨进程共享但不需要网络访问的数据。
L3分布式缓存部署在独立的缓存集群中,通过网络访问,典型实现包括Redis Cluster、Memcached等。分布式缓存具有横向扩展能力,可以提供TB级的存储容量,但网络访问延迟较高(毫秒级)。适合存储需要在多个服务实例之间共享的数据,如用户会话、跨服务缓存等。
1.3 缓存系统设计原则
设计一个高效的缓存系统需要遵循以下核心原则:
1. locality原理:程序访问数据时存在时间局部性和空间局部性。时间局部性意味着最近访问的数据很可能再次被访问;空间局部性意味着附近的数据很可能被连续访问。缓存系统正是利用这一原理,通过保留热点数据来加速后续访问。
2. 80/20法则:在典型工作负载中,大约80%的访问集中在20%的数据上。缓存系统的目标就是识别并保持这20%的热点数据,使缓存命中率尽可能高。实际生产环境中,经过良好调优的缓存系统可以达到95%以上的命中率。
3. 一致性权衡:CAP理论指出分布式系统无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)。缓存系统设计必须在一致性和性能之间做出权衡。对于AI IDE场景,通常采用最终一致性模型,通过版本号、TTL等机制保证数据在可接受的时间窗口内达成一致。
4. 层次化设计:不同层级的缓存具有不同的访问延迟和容量特征。合理的层次化设计可以通过在更快的层级中保留最热点的数据,在更大容量的层级中保留更多数据来优化整体性能。例如,L1缓存命中率90%,L2缓存处理剩余80%中的70%,L3缓存处理剩余部分的90%,最终未命中的请求才访问数据库。
2. 缓存策略:淘汰算法与更新策略
本节核心技术价值
本节为你提供的核心价值是深入理解缓存淘汰算法的底层机制与适用场景。通过本节,你将掌握LRU、LFU、ARC等主流淘汰算法的原理与实现细节,理解缓存容量规划的理论基础,学会根据业务特征选择合适的淘汰策略,以及了解缓存更新策略(CacheAside、Read-through、Write-through、Write-behind)的适用场景与一致性权衡。
2.1 淘汰算法基础理论
缓存淘汰算法(Eviction Algorithm)决定了当缓存容量达到上限时,哪些数据应该被移除以腾出空间给新数据。优秀的淘汰算法应当具备以下特征:
- 高命中率:算法应当尽可能保留会被再次访问的数据
- 低开销:算法的时间和空间复杂度应当足够低,不成为性能瓶颈
- 适应性:算法应当能够适应动态变化的工作负载
- 公平性:避免某些数据永远无法被淘汰的饥饿问题
衡量淘汰算法效果的核心指标是缓存命中率(Hit Rate)和字节命中率(Byte Hit Rate):
2.2 LRU:最近最少使用算法
LRU(Least Recently Used) 是最广泛使用的缓存淘汰算法。其核心思想是:如果一个数据最近被访问过,那么将来它被访问的概率也更高。因此,当缓存满时,应当淘汰最长时间未被访问的数据。
2.2.1 LRU的数学模型
LRU的理论基础是程序的局部性原理。在时间维度上,程序倾向于重复访问最近访问过的数据;在空间维度上,程序倾向于访问与最近访问过的数据相邻的数据。LRU算法通过追踪数据的"最近访问时间"来实现这一思想。
对于稳定工作负载(即热点数据集合不频繁变化),LRU能够提供接近最优的缓存命中率。然而,对于扫描型工作负载(顺序访问大量数据)和循环型工作负载(访问模式周期性重复),LRU可能表现不佳,因为它会清空正在循环访问的数据。
2.2.2 LRU-K算法
标准LRU只考虑数据被访问过一次的情况,而LRU-K算法2追踪每个数据最近的K次访问时间。当需要淘汰时,LRU-K淘汰的是倒数第K次访问时间最早的数据。
LRU-1就是标准LRU。LRU-2开始考虑数据是否被访问过两次:当缓存满时,LRU-2首先淘汰那些访问次数少于2次的数据中最近一次访问时间最早的;如果所有数据都被访问过至少2次,则淘汰倒数第二次访问时间最早的。
LRU-K的优点是能够识别"一次性热点"——那些被访问一次后就再也不会被访问的数据。标准LRU会将这些数据保留很长时间,而LRU-K可以更快地淘汰它们。
2.2.3 LRU实现:基于双向链表
/**
* LRU缓存实现 - 基于双向链表 + HashMap
* 时间复杂度: O(1) 的get和put操作
* 空间复杂度: O(capacity)
*
* @param <K> 键类型
* @param <V> 值类型
*/
public class LRUCache<K, V> {
/**
* 节点数据结构 - 双向链表节点
*/
static class Node<K, V> {
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
Node(K key, V value) {
this.key = key;
this.value = value;
}
}
/**
* 容量限制
*/
private final int capacity;
/**
* HashMap用于O(1)查找
*/
private final Map<K, Node<K, V>> cache;
/**
* 虚拟头节点 - 简化边界处理
*/
private final Node<K, V> head;
/**
* 虚拟尾节点 - 最久未使用的数据所在位置
*/
private final Node<K, V> tail;
/**
* 缓存命中统计
*/
private long hits;
/**
* 缓存未命中统计
*/
private long misses;
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new HashMap<>(capacity);
this.head = new Node<>(null, null);
this.tail = new Node<>(null, null);
this.head.next = tail;
this.tail.prev = head;
this.hits = 0;
this.misses = 0;
}
/**
* 获取缓存值
*
* @param key 缓存键
* @return 缓存值,如果不存在返回null
*/
public V get(K key) {
Node<K, V> node = cache.get(key);
if (node == null) {
misses++;
return null;
}
// 移动到链表头部(最近使用位置)
moveToHead(node);
hits++;
return node.value;
}
/**
* 写入缓存
*
* @param key 缓存键
* @param value 缓存值
*/
public void put(K key, V value) {
Node<K, V> node = cache.get(key);
if (node != null) {
// 更新已有节点
node.value = value;
moveToHead(node);
} else {
// 创建新节点
Node<K, V> newNode = new Node<>(key, value);
cache.put(key, newNode);
addToHead(newNode);
// 检查容量限制
if (cache.size() > capacity) {
// 淘汰最久未使用的节点(尾节点的前一个)
Node<K, V> removed = removeTail();
cache.remove(removed.key);
}
}
}
/**
* 批量读取缓存
*
* @param keys 要读取的键集合
* @return 键值对映射,只包含存在的键
*/
public Map<K, V> getAll(Collection<K> keys) {
Map<K, V> result = new HashMap<>();
for (K key : keys) {
V value = get(key);
if (value != null) {
result.put(key, value);
}
}
return result;
}
/**
* 批量写入缓存
*
* @param entries 键值对映射
*/
public void putAll(Map<? extends K, ? extends V> entries) {
entries.forEach(this::put);
}
/**
* 判断键是否存在
*/
public boolean containsKey(K key) {
return cache.containsKey(key);
}
/**
* 获取当前缓存大小
*/
public int size() {
return cache.size();
}
/**
* 清空缓存
*/
public void clear() {
cache.clear();
head.next = tail;
tail.prev = head;
hits = 0;
misses = 0;
}
/**
* 获取缓存命中率
*/
public double getHitRate() {
long total = hits + misses;
return total == 0 ? 0.0 : (double) hits / total;
}
/**
* 获取缓存统计信息
*/
public CacheStats getStats() {
return new CacheStats(hits, misses, cache.size(), capacity);
}
/**
* 将节点移动到链表头部
*/
private void moveToHead(Node<K, V> node) {
removeNode(node);
addToHead(node);
}
/**
* 从链表中移除节点
*/
private void removeNode(Node<K, V> node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
/**
* 添加节点到链表头部
*/
private void addToHead(Node<K, V> node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
/**
* 移除链表尾部节点(最久未使用)
*/
private Node<K, V> removeTail() {
Node<K, V> removed = tail.prev;
removeNode(removed);
return removed;
}
/**
* 缓存统计信息
*/
public static class CacheStats {
public final long hits;
public final long misses;
public final int size;
public final int capacity;
public CacheStats(long hits, long misses, int size, int capacity) {
this.hits = hits;
this.misses = misses;
this.size = size;
this.capacity = capacity;
}
@Override
public String toString() {
return String.format("CacheStats{hits=%d, misses=%d, hitRate=%.2f%%, size=%d, capacity=%d}",
hits, misses, 100.0 * hits / (hits + misses + 1), size, capacity);
}
}
}代码解析:
- 双向链表:
head和tail是虚拟节点,简化了边界处理。真实数据节点在head和tail之间。head后继是最近使用的节点,tail前驱是最久未使用的节点。 - HashMap:提供O(1)的键查找能力,将查找和遍历操作分离。
- moveToHead:每次访问数据时,将节点移到链表头部,保持最近访问的数据在链表前面。
- removeTail:淘汰时移除tail前驱节点,即最久未使用的数据。
- 统计指标:hit/miss计数用于监控缓存效果。
2.2.4 LRU在AI IDE中的应用场景
/**
* AI IDE Token缓存 - 使用LRU策略
* 缓存Token序列,加速语法分析
*/
public class TokenSequenceCache {
private final LRUCache<String, TokenSequence> cache;
private final Duration maxAge;
public TokenSequenceCache(int maxEntries, Duration maxAge) {
this.cache = new LRUCache<>(maxEntries);
this.maxAge = maxAge;
}
/**
* 获取Token序列
*
* @param filePath 文件路径
* @param version 文件版本号
* @return Token序列,如果缓存未命中返回null
*/
public TokenSequence get(String filePath, int version) {
String key = buildKey(filePath, version);
TokenSequence tokens = cache.get(key);
if (tokens != null && !tokens.isExpired(maxAge)) {
return tokens;
}
return null;
}
/**
* 缓存Token序列
*/
public void put(String filePath, int version, TokenSequence tokens) {
String key = buildKey(filePath, version);
cache.put(key, tokens);
}
/**
* 文件变更时使缓存失效
*/
public void invalidate(String filePath) {
// 注意:这里简化了实现,实际需要遍历或使用反向索引
cache.clear();
}
private String buildKey(String filePath, int version) {
return filePath + ":" + version;
}
}2.3 LFU:最不经常使用算法
LFU(Least Frequently Used) 淘汰访问频率最低的数据。其核心思想是:如果一个数据过去被访问的次数越多,将来越可能被再次访问。LFU比LRU更能适应扫描型工作负载,因为它会计数每次访问。
2.3.1 LFU的数学模型
LFU使用访问计数器追踪每个数据被访问的频率。当需要淘汰时,选择频率最低的数据。如果存在多个频率相同的数据,通常淘汰最久未访问的(即使用LFU+LRU组合策略)。
LFU的命中率分析3:对于访问频率分布服从Zipf分布的工作负载,LFU的理论最优命中率可达
(其中
是Zipf参数,通常在0.5~1之间)。
2.3.2 LFU的Counter Overflow问题
标准LFU存在一个严重问题:计数器溢出和访问频率污染。如果一个数据在过去被频繁访问,但现在已经完全不使用,它仍然会占据缓存空间直到其他数据的访问频率超过它。这种现象称为访问频率污染(Frequency Pollution)。
为解决这一问题,研究者提出了多种改进算法:
1. LFU-DA(LFU with Dynamic Aging):为每个计数器的值引入一个衰减因子,使长期未被访问的数据的计数值逐渐衰减。
2. LRFU(Least Recently/Frequently Used)4:通过一个可调参数
在LRU和LFU之间连续插值。
时完全等同于LRU,
时完全等同于LFU。
3. ARC(Adaptive Replacement Cache)5:IBM开发的自适应替换缓存,同时维护四个列表:最近访问列表(T1)、频繁访问列表(T2)、最近淘汰列表(B1)、频繁淘汰列表(B2),根据工作负载自动调整各列表大小。
2.3.3 LFU实现:基于最小堆
import java.util.*;
import java.util.concurrent.atomic.AtomicLong;
/**
* LFU缓存实现 - 基于最小堆 + HashMap
*
* 特性:
* - 支持访问频率计数
* - 支持TTL过期
* - 支持容量限制
* - 支持访问频率衰减(解决counter overflow问题)
*
* @param <K> 键类型
* @param <V> 值类型
*/
public class LFUCache<K, V> implements Cache<K, V> {
/**
* 缓存条目
*/
private static class CacheEntry<K, V> {
K key;
V value;
long accessCount; // 访问频率
long lastAccessTime; // 上次访问时间戳
long createTime; // 创建时间
long expireTime; // 过期时间,-1表示不过期
CacheEntry(K key, V value, long ttlMillis) {
this.key = key;
this.value = value;
this.accessCount = 1;
this.lastAccessTime = System.currentTimeMillis();
this.createTime = System.currentTimeMillis();
this.expireTime = ttlMillis > 0 ? System.currentTimeMillis() + ttlMillis : -1;
}
boolean isExpired() {
return expireTime > 0 && System.currentTimeMillis() > expireTime;
}
void incrementAccess() {
accessCount++;
lastAccessTime = System.currentTimeMillis();
}
}
/**
* 频率节点 - 用于按频率组织条目
*/
private static class FrequencyNode<K, V> implements Comparable<FrequencyNode<K, V>> {
long frequency;
Set<CacheEntry<K, V>> entries;
FrequencyNode(long frequency) {
this.frequency = frequency;
this.entries = new LinkedHashSet<>();
}
@Override
public int compareTo(FrequencyNode<K, V> o) {
return Long.compare(this.frequency, o.frequency);
}
}
private final int capacity;
private final long ttlMillis;
private final float decayFactor;
private final Map<K, CacheEntry<K, V>> cache;
private final Map<Long, FrequencyNode<K, V>> frequencyMap;
private final NavigableMap<Long, FrequencyNode<K, V>> frequencyTree;
private long globalAccessCount = 0;
private long hits = 0;
private long misses = 0;
/**
* 构造函数
*
* @param capacity 最大容量
* @param ttlMillis TTL过期时间,0表示不过期
* @param decayFactor 频率衰减因子 (0.0~1.0),值越小衰减越快
*/
public LFUCache(int capacity, long ttlMillis, float decayFactor) {
this.capacity = capacity;
this.ttlMillis = ttlMillis;
this.decayFactor = decayFactor;
this.cache = new HashMap<>(capacity);
this.frequencyMap = new HashMap<>();
this.frequencyTree = new TreeMap<>();
}
public LFUCache(int capacity, long ttlMillis) {
this(capacity, ttlMillis, 0.995f);
}
public LFUCache(int capacity) {
this(capacity, 0, 0.995f);
}
@Override
public V get(K key) {
CacheEntry<K, V> entry = cache.get(key);
if (entry == null) {
misses++;
return null;
}
if (entry.isExpired()) {
removeEntry(entry);
cache.remove(key);
misses++;
return null;
}
// 增加访问频率(带衰减)
incrementFrequency(entry);
hits++;
globalAccessCount++;
return entry.value;
}
@Override
public void put(K key, V value) {
CacheEntry<K, V> existingEntry = cache.get(key);
if (existingEntry != null) {
// 更新现有条目
existingEntry.value = value;
existingEntry.lastAccessTime = System.currentTimeMillis();
if (ttlMillis > 0) {
existingEntry.expireTime = System.currentTimeMillis() + ttlMillis;
}
// 增加访问频率
incrementFrequency(existingEntry);
return;
}
// 检查容量
if (cache.size() >= capacity) {
evictOne();
}
// 创建新条目
CacheEntry<K, V> newEntry = new CacheEntry<>(key, value, ttlMillis);
cache.put(key, newEntry);
addToFrequencyList(newEntry, 1);
}
@Override
public boolean remove(K key) {
CacheEntry<K, V> entry = cache.remove(key);
if (entry != null) {
removeEntry(entry);
return true;
}
return false;
}
@Override
public void clear() {
cache.clear();
frequencyMap.clear();
frequencyTree.clear();
globalAccessCount = 0;
hits = 0;
misses = 0;
}
@Override
public int size() {
return cache.size();
}
@Override
public double getHitRate() {
long total = hits + misses;
return total == 0 ? 0.0 : (double) hits / total;
}
public CacheStats getStats() {
return new CacheStats(hits, misses, cache.size(), capacity, globalAccessCount);
}
/**
* 应用频率衰减 - 定期调用以解决counter overflow
*/
public void applyDecay() {
if (decayFactor >= 1.0f) return;
List<CacheEntry<K, V>> allEntries = new ArrayList<>(cache.values());
frequencyMap.clear();
frequencyTree.clear();
for (CacheEntry<K, V> entry : allEntries) {
long decayedFrequency = Math.max(1, (long)(entry.accessCount * decayFactor));
entry.accessCount = decayedFrequency;
addToFrequencyList(entry, decayedFrequency);
}
}
/**
* 增加条目的访问频率
*/
private void incrementFrequency(CacheEntry<K, V> entry) {
long oldFreq = entry.accessCount;
long newFreq = oldFreq + 1;
entry.accessCount = newFreq;
// 从旧频率列表移除
FrequencyNode<K, V> oldNode = frequencyMap.get(oldFreq);
if (oldNode != null) {
oldNode.entries.remove(entry);
if (oldNode.entries.isEmpty()) {
frequencyTree.remove(oldFreq);
frequencyMap.remove(oldFreq);
}
}
// 添加到新频率列表
addToFrequencyList(entry, newFreq);
}
/**
* 添加条目到频率列表
*/
private void addToFrequencyList(CacheEntry<K, V> entry, long frequency) {
FrequencyNode<K, V> node = frequencyMap.computeIfAbsent(frequency,
freq -> {
FrequencyNode<K, V> newNode = new FrequencyNode<>(freq);
frequencyTree.put(freq, newNode);
return newNode;
});
node.entries.add(entry);
}
/**
* 从频率列表移除条目
*/
private void removeEntry(CacheEntry<K, V> entry) {
FrequencyNode<K, V> node = frequencyMap.get(entry.accessCount);
if (node != null) {
node.entries.remove(entry);
if (node.entries.isEmpty()) {
frequencyTree.remove(entry.accessCount);
frequencyMap.remove(entry.accessCount);
}
}
}
/**
* 淘汰一个条目
*/
private void evictOne() {
if (frequencyTree.isEmpty()) return;
// 获取最低频率
Map.Entry<Long, FrequencyNode<K, V>> firstEntry = frequencyTree.firstEntry();
FrequencyNode<K, V> node = firstEntry.getValue();
// 从该频率的条目中选择最久未访问的
CacheEntry<K, V> victim = null;
long oldestTime = Long.MAX_VALUE;
for (CacheEntry<K, V> entry : node.entries) {
if (entry.lastAccessTime < oldestTime) {
oldestTime = entry.lastAccessTime;
victim = entry;
}
}
if (victim != null) {
cache.remove(victim.key);
removeEntry(victim);
}
}
/**
* 缓存统计信息
*/
public static class CacheStats {
public final long hits;
public final long misses;
public final int size;
public final int capacity;
public final long globalAccessCount;
public CacheStats(long hits, long misses, int size, int capacity, long globalAccessCount) {
this.hits = hits;
this.misses = misses;
this.size = size;
this.capacity = capacity;
this.globalAccessCount = globalAccessCount;
}
public double getHitRate() {
long total = hits + misses;
return total == 0 ? 0.0 : (double) hits / total;
}
}
}2.4 TTL:基于时间的过期策略
TTL(Time To Live) 是一种基于时间的缓存过期策略,每个缓存条目都有一个固定的生存时间,超过这个时间后条目自动失效并被移除。TTL策略简单高效,特别适合数据时效性要求较高的场景。
2.4.1 TTL的数学模型
TTL的核心是过期时间(Expiration Time)计算:
当
时,缓存条目被认为已过期。
TTL策略的主要问题是在过期时刻的集中失效(也称为缓存雪崩,见第7节)。为缓解这一问题,可以使用抖动(Jitter)策略:
2.4.2 带TTL的缓存实现
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicLong;
/**
* TTL缓存实现 - 支持基于时间的自动过期
*
* 特性:
* - 支持固定TTL和滑动TTL
* - 支持后台清理线程
* - 支持最大容量限制
* - 支持过期监听器
*
* @param <K> 键类型
* @param <V> 值类型
*/
public class TTLCache<K, V> implements Cache<K, V> {
/**
* TTL缓存条目
*/
private static class TTLCacheEntry<V> {
V value;
long expireTime; // 过期时间点,纳秒
long accessCount;
TTLCacheEntry(V value, long ttlNanos) {
this.value = value;
this.expireTime = System.nanoTime() + ttlNanos;
this.accessCount = 0;
}
boolean isExpired() {
return System.nanoTime() > expireTime;
}
void touch(long ttlNanos) {
this.expireTime = System.nanoTime() + ttlNanos;
this.accessCount++;
}
}
private final int capacity;
private final long ttlNanos;
private final ConcurrentHashMap<K, TTLCacheEntry<V>> cache;
private final ConcurrentLinkedQueue<K> accessOrder;
private final ScheduledExecutorService cleaner;
private final AtomicLong hits = new AtomicLong();
private final AtomicLong misses = new AtomicLong();
private final AtomicLong evictions = new AtomicLong();
private final java.util.List<ExpirationListener<K, V>> listeners = new CopyOnWriteArrayList<>();
/**
* 过期监听器
*/
public interface ExpirationListener<K, V> {
void onExpiration(K key, V value);
}
/**
* 构造函数
*
* @param capacity 最大容量
* @param ttl TTL时长
* @param ttlUnit TTL时间单位
*/
public TTLCache(int capacity, long ttl, TimeUnit ttlUnit) {
this.capacity = capacity;
this.ttlNanos = ttlUnit.toNanos(ttl);
this.cache = new ConcurrentHashMap<>(capacity);
this.accessOrder = new ConcurrentLinkedQueue<>();
this.cleaner = Executors.newSingleThreadScheduledExecutor(
r -> new Thread(r, "ttl-cache-cleaner"));
// 启动后台清理线程
startCleaner();
}
public TTLCache(int capacity, long ttl, TimeUnit ttlUnit,
ScheduledExecutorService cleaner) {
this.capacity = capacity;
this.ttlNanos = ttlUnit.toNanos(ttl);
this.cache = new ConcurrentHashMap<>(capacity);
this.accessOrder = new ConcurrentLinkedQueue<>();
this.cleaner = cleaner;
startCleaner();
}
private void startCleaner() {
// 每TTL/2时间清理一次过期数据
long period = Math.max(1, ttlNanos / 2);
cleaner.scheduleAtFixedRate(this::cleanExpired,
period, period, TimeUnit.NANOSECONDS);
}
@Override
public V get(K key) {
TTLCacheEntry<V> entry = cache.get(key);
if (entry == null) {
misses.incrementAndGet();
return null;
}
if (entry.isExpired()) {
removeEntry(key, entry);
misses.incrementAndGet();
return null;
}
hits.incrementAndGet();
return entry.value;
}
/**
* 获取缓存值并刷新TTL(滑动TTL)
*/
public V getAndRefresh(K key) {
TTLCacheEntry<V> entry = cache.get(key);
if (entry == null) {
misses.incrementAndGet();
return null;
}
if (entry.isExpired()) {
removeEntry(key, entry);
misses.incrementAndGet();
return null;
}
// 刷新TTL
entry.touch(ttlNanos);
hits.incrementAndGet();
return entry.value;
}
@Override
public void put(K key, V value) {
// 检查容量
if (cache.size() >= capacity) {
evictOne();
}
TTLCacheEntry<V> entry = new TTLCacheEntry<>(value, ttlNanos);
TTLCacheEntry<V> old = cache.put(key, entry);
if (old == null) {
accessOrder.add(key);
} else {
// 替换旧条目时移除旧条目
accessOrder.remove(key);
accessOrder.add(key);
// 通知过期监听器
notifyExpiration(key, old.value);
}
}
/**
* 批量写入
*/
public void putAll(Map<? extends K, ? extends V> entries) {
entries.forEach(this::put);
}
@Override
public boolean remove(K key) {
TTLCacheEntry<V> entry = cache.remove(key);
if (entry != null) {
accessOrder.remove(key);
notifyExpiration(key, entry.value);
return true;
}
return false;
}
@Override
public void clear() {
cache.forEach((key, entry) -> notifyExpiration(key, entry.value));
cache.clear();
accessOrder.clear();
}
@Override
public int size() {
cleanExpired(); // 先清理过期数据
return cache.size();
}
@Override
public double getHitRate() {
long total = hits.get() + misses.get();
return total == 0 ? 0.0 : (double) hits.get() / total;
}
/**
* 添加过期监听器
*/
public void addExpirationListener(ExpirationListener<K, V> listener) {
listeners.add(listener);
}
/**
* 移除过期监听器
*/
public void removeExpirationListener(ExpirationListener<K, V> listener) {
listeners.remove(listener);
}
/**
* 获取统计信息
*/
public TTLCacheStats getStats() {
return new TTLCacheStats(
hits.get(), misses.get(), evictions.get(),
cache.size(), capacity
);
}
/**
* 清理过期数据
*/
private void cleanExpired() {
Iterator<Map.Entry<K, TTLCacheEntry<V>>> iterator =
cache.entrySet().iterator();
int cleaned = 0;
while (iterator.hasNext()) {
Map.Entry<K, TTLCacheEntry<V>> entry = iterator.next();
if (entry.getValue().isExpired()) {
K key = entry.getKey();
V value = entry.getValue().value;
iterator.remove();
accessOrder.remove(key);
notifyExpiration(key, value);
cleaned++;
}
}
if (cleaned > 0) {
evictions.addAndGet(cleaned);
}
}
/**
* 淘汰一个条目
*/
private void evictOne() {
K keyToEvict = null;
// LRU淘汰:从最旧开始查找未过期的
Iterator<K> iterator = accessOrder.iterator();
while (iterator.hasNext()) {
K key = iterator.next();
TTLCacheEntry<V> entry = cache.get(key);
if (entry != null) {
if (entry.isExpired()) {
// 过期的不算作主动淘汰
iterator.remove();
cache.remove(key);
notifyExpiration(key, entry.value);
} else {
keyToEvict = key;
iterator.remove();
break;
}
} else {
iterator.remove();
}
}
if (keyToEvict != null) {
TTLCacheEntry<V> entry = cache.remove(keyToEvict);
if (entry != null) {
evictions.incrementAndGet();
notifyExpiration(keyToEvict, entry.value);
}
}
}
private void removeEntry(K key, TTLCacheEntry<V> entry) {
cache.remove(key);
accessOrder.remove(key);
notifyExpiration(key, entry.value);
}
private void notifyExpiration(K key, V value) {
for (ExpirationListener<K, V> listener : listeners) {
try {
listener.onExpiration(key, value);
} catch (Exception e) {
// 忽略监听器异常
}
}
}
/**
* 关闭缓存,释放资源
*/
public void shutdown() {
cleaner.shutdown();
clear();
}
/**
* TTL缓存统计信息
*/
public static class TTLCacheStats {
public final long hits;
public final long misses;
public final long evictions;
public final int size;
public final int capacity;
public TTLCacheStats(long hits, long misses, long evictions,
int size, int capacity) {
this.hits = hits;
this.misses = misses;
this.evictions = evictions;
this.size = size;
this.capacity = capacity;
}
public double getHitRate() {
long total = hits + misses;
return total == 0 ? 0.0 : (double) hits / total;
}
@Override
public String toString() {
return String.format(
"TTLCacheStats{hits=%d, misses=%d, evictions=%d, size=%d, capacity=%d, hitRate=%.2f%%}",
hits, misses, evictions, size, capacity, 100.0 * getHitRate()
);
}
}
}2.5 淘汰算法对比与选型
特性 | LRU | LFU | LRU-K | ARC | TTL |
|---|---|---|---|---|---|
实现复杂度 | 低 | 中 | 中 | 高 | 低 |
时间复杂度 | O(1) | O(log n) | O(log n) | O(log n) | O(1) |
空间复杂度 | O(n) | O(n) | O(n) | O(n) | O(n) |
访问频率敏感 | 低 | 高 | 高 | 自适应 | 无 |
热点识别速度 | 快 | 慢 | 中 | 快 | 不适用 |
扫描抵抗能力 | 差 | 良 | 良 | 优 | 良 |
Counter Overflow | 无 | 有 | 有 | 无 | 无 |
适用场景 | 通用 | 频率稳定 | 过滤噪声 | 自适应工作负载 | 时效性数据 |
AI IDE场景选型建议:
- Token缓存:推荐LRU,访问模式局部性强
- 代码片段缓存:推荐LRU-K + TTL组合,过滤一次性访问
- LSP诊断缓存:推荐LFU,诊断结果访问频率相对稳定
- 搜索结果缓存:推荐TTL(短期)+ LFU,搜索结果时效性重要
- 模型推理缓存:推荐TTL,推理结果新鲜度要求高
3. 缓存层级:L1、L2、L3的设计
本节核心技术价值
本节为你提供的核心价值是掌握分层缓存架构的设计原理与工程实践。通过本节,你将理解L1/L2/L3各层缓存的定位与特点,学会设计层级间数据流动策略,掌握容量规划与性能调优方法,以及了解如何在AI IDE场景中应用多级缓存架构。
3.1 分层缓存架构原理
分层缓存(Tiered Cache)是将多个具有不同特性(容量、延迟、成本)的缓存组合在一起,形成一个整体的缓存系统。数据在多层缓存之间按照一定策略流动,目标是最大化缓存命中率并最小化访问延迟。
3.1.1 分层缓存的理论基础
分层缓存的理论基础是存储层次理论(Memory Hierarchy)和局部性原理的结合。在存储层次理论中,越靠近CPU的存储层次速度越快但容量越小,成本越高;越远离CPU的层次速度越慢但容量越大,成本越低。
分层缓存正是利用这一原理:L1缓存使用最高性能的存储(通常是CPU缓存或进程内存),容量最小但速度最快;L3缓存使用大容量但相对慢速的存储(分布式缓存)。通过合理的数据分层,可以以较低的成本获得接近最快存储的性能。
分层缓存的命中率模型:
其中
是第i层的命中率。假设各层命中率分别为
,
,
,则整体命中率:
3.1.2 层间数据流动策略
分层缓存中的数据流动策略决定了数据如何在层级之间迁移。主要有两种模式:
1. Write-back(写回)模式:数据写入时只写入最上层(L1),只有在L1容量不足需要淘汰时才将数据写入下一层(L2)。读取时,如果L1未命中,会将数据从L2提升到L1。
2. Write-through(写透)模式:数据写入时同时写入所有层级,确保各层数据一致性。读取时按照L1→L2→L3的顺序查找。
3.2 L1本地缓存设计与实现
L1缓存是距离应用最近的缓存层,通常部署在应用进程内部,直接使用JVM堆内存或堆外内存。L1缓存的典型访问延迟在纳秒到微秒级,容量通常在MB级别。
3.2.1 Caffeine Cache深度解析
Caffeine是目前Java生态中最先进的本地缓存库。Caffeine使用Window TinyLFU淘汰算法,结合了LRU和LFU的优点,同时解决了两者的问题。
Window TinyLFU算法原理:TinyLFU使用Count-Min Sketch来估算每个key的访问频率,这是一种概率数据结构,用很小的空间提供频率估算。Window部分(通常是1%容量)用于吸收新进入的热点数据,防止冷数据污染主缓存。
import com.github.benmanes.caffeine.cache.*;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.*;
/**
* Caffeine缓存配置与使用示例
* 展示AI IDE中的Token缓存、AST缓存、配置缓存
*/
public class CaffeineCacheExamples {
/**
* 1. Token序列缓存 - 高性能场景
*/
public static class TokenCache {
private final Cache<String, TokenSequence> cache;
private final CacheStats stats;
public TokenCache() {
this.cache = Caffeine.newBuilder()
.initialCapacity(1000)
.maximumSize(10_000)
.weakKeys()
.recordStats() // 启用统计
.removalListener((key, value, cause) -> {
if (value != null) {
value.release();
}
})
.build();
this.stats = cache.stats();
}
public TokenSequence get(String filePath, int version) {
String key = buildKey(filePath, version);
return cache.getIfPresent(key);
}
public void put(String filePath, int version, TokenSequence tokens) {
String key = buildKey(filePath, version);
cache.put(key, tokens);
}
public void invalidate(String filePath) {
cache.invalidateAll();
}
private String buildKey(String filePath, int version) {
return filePath + ":" + version;
}
public double getHitRate() {
return stats.hitRate();
}
public long getEvictionCount() {
return stats.evictionCount();
}
}
/**
* 2. AST缓存 - 中等容量,低延迟
*/
public static class ASTCache {
private final Cache<String, ASTNode> cache;
public ASTCache() {
this.cache = Caffeine.newBuilder()
.initialCapacity(500)
.maximumWeight(100 * 1024 * 1024) // 100MB权重限制
.weigher((String key, ASTNode node) -> node.estimateSize())
.expireAfterWrite(Duration.ofMinutes(30))
.expireAfterAccess(Duration.ofMinutes(10))
.recordStats()
.build();
}
public ASTNode get(String filePath) {
return cache.getIfPresent(filePath);
}
public ASTNode computeIfAbsent(String filePath, Callable<ASTNode> loader) {
return cache.get(filePath, path -> {
try {
return loader.call();
} catch (Exception e) {
throw new RuntimeException("Failed to load AST for: " + path, e);
}
});
}
public void invalidate(String filePath) {
cache.invalidate(filePath);
}
}
/**
* 3. 配置缓存 - 长期缓存,少量条目
*/
public static class ConfigCache {
private final AsyncLoadingCache<String, ConfigValue> cache;
private final ScheduledExecutorService scheduler;
public ConfigCache() {
this.scheduler = Executors.newScheduledThreadPool(2);
this.cache = Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(500)
.refreshAfterWrite(Duration.ofHours(1))
.recordStats()
.buildAsync(key -> loadConfig(key));
}
private CompletableFuture<ConfigValue> loadConfig(String key) {
return CompletableFuture.supplyAsync(() -> ConfigValue.load(key), scheduler);
}
public ConfigValue get(String key) {
return cache.getIfPresent(key);
}
}
}3.2.2 Guava Cache配置详解
Guava Cache是Google Guava库提供的缓存组件,虽然已被Caffeine超越,但在很多遗留系统中仍在使用。
import com.google.common.cache.*;
import java.util.concurrent.*;
/**
* Guava Cache高级配置示例
*/
public class GuavaCacheExamples {
/**
* 基本缓存配置
*/
public LoadingCache<String, DataRecord> createBasicCache() {
return CacheBuilder.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.recordStats()
.build(new CacheLoader<String, DataRecord>() {
@Override
public DataRecord load(String key) {
return loadFromDatabase(key);
}
});
}
/**
* 基于权重的缓存
*/
public LoadingCache<String, byte[]> createWeightedCache() {
return CacheBuilder.newBuilder()
.maximumWeight(100 * 1024 * 1024) // 100MB
.weigher((String key, byte[] value) -> value.length)
.build(new CacheLoader<String, byte[]>() {
@Override
public byte[] load(String key) {
return loadData(key);
}
});
}
private DataRecord loadFromDatabase(String key) { return new DataRecord(); }
private byte[] loadData(String key) { return new byte[0]; }
static class DataRecord {}
}3.3 L2进程缓存设计与实现
L2缓存部署在本地服务器的多个进程之间,通常使用堆外内存或内存映射文件。L2缓存的容量比L1大得多(GB级别),访问延迟在毫秒级以下。
3.3.1 Ehcache 3.x架构
Ehcache是Java生态中成熟的进程缓存解决方案。
import org.ehcache.*;
import org.ehcache.config.*;
import java.io.*;
import java.time.Duration;
/**
* Ehcache 3.x配置与使用示例
*/
public class EhcacheExamples {
/**
* 堆外内存缓存配置
*/
public static class OffHeapCache {
public Cache<String, byte[]> createOffHeapCache() {
ResourcePools resources = ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(1000, EntryUnit.ENTRIES)
.offheap(100, MemoryUnit.MB)
.build();
CacheConfiguration<String, byte[]> config = CacheConfigurationBuilder
.newCacheConfigurationBuilder(
String.class,
byte[].class,
resources)
.withExpiry(ExpiryPolicyBuilder.timeToIdleExpiration(Duration.ofMinutes(10)))
.build();
return CacheManagerBuilder.newCacheManagerBuilder()
.withCache("offHeapCache", config)
.build()
.getCache("offHeapCache", String.class, byte[].class);
}
}
/**
* 三级存储缓存(堆+off-heap+磁盘)
*/
public static class ThreeTierCache {
public Cache<String, byte[]> createThreeTierCache(File dataDir) {
ResourcePools resources = ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(100, EntryUnit.ENTRIES)
.offheap(50, MemoryUnit.MB)
.disk(500, MemoryUnit.MB, true)
.build();
CacheConfiguration<String, byte[]> config = CacheConfigurationBuilder
.newCacheConfigurationBuilder(
String.class,
byte[].class,
resources)
.withExpiry(ExpiryPolicyBuilder.timeToIdleExpiration(Duration.ofMinutes(5)))
.build();
return CacheManagerBuilder.newCacheManagerBuilder()
.buildCache("threeTierCache", config);
}
}
}3.4 L3分布式缓存设计与实现
L3分布式缓存部署在独立的缓存集群中,通过网络访问。分布式缓存具有横向扩展能力,可以提供TB级的存储容量。
3.4.1 Redis Cluster架构
Redis Cluster是Redis官方提供的分布式缓存解决方案,通过哈希槽(Hash Slot)实现数据分片,支持高可用和水平扩展。
┌─────────────────────────────────────────────────────────────┐
│ Redis Cluster架构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Client │ │ Client │ │ Client │ │
│ │(Jedis) │ │(Lettuce)│ │(Redisson)│ │
│ └────┬────┘ └────┬────┘ └────┬────┘ │
│ │ │ │ │
│ └────────────┼────────────┘ │
│ ▼ │
│ ┌───────────────────┐ │
│ │ Smart Client │ │
│ │ (自动路由到正确节点)│ │
│ └─────────┬─────────┘ │
│ │ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │Master│ │Master│ │Master│ │
│ │Node1 │ │Node2 │ │Node3 │ │
│ └──┬──┘ └──┬──┘ └──┬──┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │Slave │ │Slave │ │Slave │ │
│ │Node1 │ │Node2 │ │Node3 │ │
│ └─────┘ └─────┘ └─────┘ │
│ │
│ Hash Slot分布: │
│ - Node1: 0-5460 (5461个槽) │
│ - Node2: 5461-10922 (5462个槽) │
│ - Node3: 10923-16383 (5461个槽) │
│ │
└─────────────────────────────────────────────────────────────┘3.4.2 Redis客户端配置
import io.lettuce.core.*;
import io.lettuce.core.cluster.*;
import io.lettuce.core.codec.*;
import java.time.Duration;
import java.util.*;
/**
* Redis分布式缓存客户端配置
*/
public class RedisCacheExamples {
/**
* 1. Lettuce客户端配置
*/
public static class LettuceConfig {
public RedisClusterClient createClusterClient(List<String> nodes) {
ClusterTopologyRefreshOptions refreshOptions =
ClusterTopologyRefreshOptions.builder()
.enablePeriodicRefresh(Duration.ofMinutes(10))
.enableAllAdaptiveRefreshJobs()
.build();
ClusterClientOptions options = ClusterClientOptions.builder()
.topologyRefreshOptions(refreshOptions)
.autoReconnect(true)
.maxRedirects(3)
.timeout(TimeoutOptions.enabled(Duration.ofSeconds(5)))
.build();
RedisClusterClient client = RedisClusterClient.create(
RedisURI.cluster(nodes.toArray(new String[0])));
client.setOptions(options);
return client;
}
}
/**
* 2. 连接池配置
*/
public static class ConnectionPoolConfig {
public GenericObjectPoolConfig createPoolConfig() {
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
poolConfig.setMaxTotal(50);
poolConfig.setMaxIdle(20);
poolConfig.setMinIdle(5);
poolConfig.setMaxWait(Duration.ofSeconds(3));
poolConfig.setTestOnBorrow(true);
poolConfig.setTestWhileIdle(true);
return poolConfig;
}
}
}3.5 层级间数据流动策略实现
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicLong;
/**
* 多级缓存协调器
* 管理L1/L2/L3之间的数据流动
*/
public class MultiLevelCacheCoordinator<K, V> {
/**
* 缓存层级定义
*/
public enum Level {
L1, // 本地内存
L2, // 进程缓存
L3 // 分布式缓存
}
/**
* 数据来源
*/
public enum Source {
MEMORY,
DISK,
NETWORK,
COMPUTED
}
/**
* 缓存条目
*/
public static class CacheEntry<V> {
V value;
long version;
long createTime;
long accessTime;
Source source;
CacheEntry(V value, Source source) {
this.value = value;
this.version = System.nanoTime();
this.createTime = System.currentTimeMillis();
this.accessTime = this.createTime;
this.source = source;
}
void touch() {
this.accessTime = System.currentTimeMillis();
this.version = System.nanoTime();
}
}
// 缓存层级
private final Map<Level, Cache<K, ?>> caches;
// 数据加载器
private final Function<K, V> loader;
// 配置
private final boolean writeThrough;
private final boolean readThrough;
private final int maxL1Size;
private final int maxL2Size;
/**
* 构造函数
*/
public MultiLevelCacheCoordinator(
Cache<K, CacheEntry<V>> l1Cache,
Cache<K, CacheEntry<V>> l2Cache,
Cache<K, CacheEntry<V>> l3Cache,
Function<K, V> loader,
int maxL1Size,
int maxL2Size) {
this.caches = new EnumMap<>(Level.class);
this.caches.put(Level.L1, l1Cache);
this.caches.put(Level.L2, l2Cache);
this.caches.put(Level.L3, l3Cache);
this.loader = loader;
this.maxL1Size = maxL1Size;
this.maxL2Size = maxL2Size;
this.writeThrough = true;
this.readThrough = true;
}
/**
* 获取缓存值
*/
@SuppressWarnings("unchecked")
public V get(K key) {
// 1. 先查L1
CacheEntry<V> entry = (CacheEntry<V>) caches.get(Level.L1).getIfPresent(key);
if (entry != null && !isExpired(entry)) {
entry.touch();
return entry.value;
}
// 2. L1未命中,查L2
entry = (CacheEntry<V>) caches.get(Level.L2).getIfPresent(key);
if (entry != null && !isExpired(entry)) {
entry.touch();
promoteToLevel(Level.L1, key, entry);
return entry.value;
}
// 3. L2未命中,查L3
entry = (CacheEntry<V>) caches.get(Level.L3).getIfPresent(key);
if (entry != null && !isExpired(entry)) {
entry.touch();
promoteToLevel(Level.L2, key, entry);
promoteToLevel(Level.L1, key, entry);
return entry.value;
}
// 4. L3未命中,从数据源加载
if (readThrough) {
V value = loader.apply(key);
if (value != null) {
CacheEntry<V> newEntry = new CacheEntry<>(value, Source.COMPUTED);
put(key, newEntry);
return value;
}
}
return null;
}
/**
* 写入缓存
*/
public void put(K key, CacheEntry<V> entry) {
if (writeThrough) {
// 同步写入所有层级
caches.get(Level.L1).put(key, entry);
caches.get(Level.L2).put(key, entry);
caches.get(Level.L3).put(key, entry);
} else {
// 只写入L1,异步同步到下层
caches.get(Level.L1).put(key, entry);
asyncWriteToLowerLevels(key, entry);
}
}
private void asyncWriteToLowerLevels(K key, CacheEntry<V> entry) {
CompletableFuture.runAsync(() -> caches.get(Level.L2).put(key, entry));
CompletableFuture.runAsync(() -> caches.get(Level.L3).put(key, entry));
}
@SuppressWarnings("unchecked")
private void promoteToLevel(Level level, K key, CacheEntry<V> entry) {
Cache<K, ?> cache = caches.get(level);
if (cache != null) {
int maxSize = level == Level.L1 ? maxL1Size : maxL2Size;
if (cache.size() >= maxSize) {
// 淘汰逻辑
}
cache.put(key, entry);
}
}
private boolean isExpired(CacheEntry<?> entry) {
return false;
}
/**
* 使缓存失效
*/
public void invalidate(K key) {
for (Cache<?, ?> cache : caches.values()) {
cache.invalidate(key);
}
}
}4. 本地缓存:Caffeine与Guava Cache的深度使用
本节核心技术价值
本节为你提供的核心价值是掌握两大主流本地缓存库的内部机制与高级用法。通过本节,你将深入理解Caffeine的Window TinyLFU算法实现细节,掌握Guava Cache的并发优化策略,学会根据业务场景选择合适的缓存配置,以及了解本地缓存在AI IDE中的最佳实践。
4.1 Caffeine内部机制深度解析
Caffeine之所以能够提供接近最优的性能,关键在于其精心设计的淘汰算法和并发控制机制。
4.1.1 Window TinyLFU算法实现
TinyLFU算法使用Count-Min Sketch来追踪所有访问的频率。
/**
* Caffeine的Window TinyLFU算法伪代码实现
*/
public class WindowTinyLFU {
private final int windowSize;
private final int mainSize;
private final CountMinSketch sketch;
private final LRUCache<K, V> window;
private final LRUCache<K, V> main;
public WindowTinyLFU(int windowSize, int mainSize) {
this.windowSize = windowSize;
this.mainSize = mainSize;
this.sketch = new CountMinSketch(windowSize + mainSize);
this.window = new LRU<>(windowSize);
this.main = new LRU<>(mainSize);
}
/**
* 访问数据
*/
public void recordAccess(K key) {
sketch.increment(key);
if (window.contains(key)) {
window.promote(key);
}
}
/**
* 添加数据
*/
public void put(K key, V value) {
// 1. 先添加到Window
if (window.size() >= windowSize) {
K evicted = window.evict();
long evictedFreq = sketch.estimate(evicted);
long mainFreq = main.size() > 0 ? sketch.estimate(main.getLFRUKey()) : 0;
if (evictedFreq > mainFreq && main.size() >= mainSize) {
main.evict();
main.put(evicted, evictedFreq);
}
}
window.put(key, value);
sketch.increment(key);
}
public V get(K key) {
if (window.contains(key)) return window.get(key);
if (main.contains(key)) return main.get(key);
return null;
}
}4.2 Guava Cache高级特性
Guava Cache采用分离锁(Striped Lock)技术优化并发性能。
import com.google.common.cache.*;
import com.google.common.util.concurrent.*;
import java.util.concurrent.*;
/**
* Guava Cache并发优化
*/
public class GuavaConcurrencyOptimization {
/**
* 使用Striped锁减少竞争
*/
public static class StripedLockExample {
private final LoadingCache<String, Data> cache;
public StripedLockExample() {
this.cache = CacheBuilder.newBuilder()
.maximumSize(10_000)
.concurrencyLevel(64) // 设置并发级别
.recordStats()
.build(key -> loadData(key));
}
private Data loadData(String key) {
return new Data();
}
}
/**
* 批量请求合并
*/
public static class RequestMergingExample {
private final LoadingCache<String, Data> cache;
private final ExecutorService executor;
public RequestMergingExample() {
this.executor = Executors.newFixedThreadPool(10);
this.cache = CacheBuilder.newBuilder()
.maximumSize(10_000)
.recordStats()
.build(key -> {
Thread.sleep(100);
return loadData(key);
});
}
private Data loadData(String key) {
return new Data();
}
}
static class Data {}
}5. 分布式缓存:Redis Cluster的深度部署
本节核心技术价值
本节为你提供的核心价值是掌握Redis Cluster的生产级部署与运维实践。通过本节,你将理解Redis Cluster的架构原理与数据分片机制,学会在高并发场景下优化Redis客户端配置,掌握Redis Cluster的监控与故障处理方法。
5.1 Redis Cluster架构与原理
5.1.1 数据分片机制
Redis Cluster使用哈希槽(Hash Slot)进行数据分片,整个集群有16384(
)个槽位。
Key的Tag:如果key包含{tag}格式,Redis会使用tag计算槽位:
key = "user:{100}:profile" -> 使用 "100" 计算槽位
key = "user:{100}:settings" -> 使用 "100" 计算槽位5.1.2 高可用机制
Redis Cluster通过主从复制和故障自动转移实现高可用。故障检测采用PING/PONG机制,如果在node-timeout时间内未收到响应,则认为对方进入疑似故障状态。
5.2 Redis Cluster部署配置
# redis-cluster.yml - Redis Cluster配置示例
port: 6379
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 5000
cluster-replica-validity-factor 10
protected-mode no
maxmemory 2gb
maxmemory-policy allkeys-lru
appendonly yes
appendfilename "appendonly-6379.aof"5.3 客户端路由与故障处理
import io.lettuce.core.*;
import io.lettuce.core.cluster.*;
import io.lettuce.core.codec.*;
import java.util.*;
/**
* Redis Cluster客户端高级特性
*/
public class RedisClusterClientAdvanced {
/**
* 集群感知路由
*/
public static class ClusterAwareRouting {
private final RedisAdvancedClusterCommands<String, byte[]> commands;
public ClusterAwareRouting(StatefulRedisClusterConnection<String, byte[]> conn) {
this.commands = conn.sync();
}
/**
* 单key操作 - 自动路由
*/
public void singleKeyOperations() {
String key = "token:session:12345";
commands.set(key, "session_data".getBytes());
byte[] value = commands.get(key);
commands.del(key);
commands.expire(key, 3600);
}
/**
* 多key操作 - 需要在同一个槽位
*/
public void multiKeySameSlotOperations() {
String userId = "100";
String profileKey = "user:{" + userId + "}:profile";
String settingsKey = "user:{" + userId + "}:settings";
commands.mset(
profileKey, "{}".getBytes(),
settingsKey, "{}".getBytes()
);
}
/**
* 槽位计算
*/
public void slotCalculation() {
String key = "product:electronics:phone:12345";
int slot = SlotHash.getSlot(key);
}
}
/**
* 故障恢复与重试
*/
public static class FailureRecovery {
public ClusterClientOptions createRetryOptions() {
return ClusterClientOptions.builder()
.autoReconnect(true)
.maxRedirects(3)
.socketOptions(SocketOptions.builder()
.connectTimeout(Duration.ofSeconds(10))
.keepAlive(true)
.build())
.topologyRefreshOptions(ClusterTopologyRefreshOptions.builder()
.enablePeriodicRefresh(Duration.ofMinutes(5))
.build())
.build();
}
}
}6. 缓存一致性:Write-through与Write-back
本节核心技术价值
本节为你提供的核心价值是深入理解缓存一致性策略的设计权衡。通过本节,你将掌握Write-through、Write-back、Write-around等写入策略的原理与适用场景,理解缓存一致性的CAP权衡,学会在性能和一致性之间取得平衡。
6.1 缓存写入策略概述

6.2 Write-through(写穿透)
Write-through是最保守的写入策略:数据同时写入缓存和持久化存储。
/**
* Write-through缓存实现
*/
public class WriteThroughCache<K, V> implements Cache<K, V> {
private final Cache<K, V> cache;
private final Storage<K, V> storage;
public WriteThroughCache(Cache<K, V> cache, Storage<K, V> storage) {
this.cache = cache;
this.storage = storage;
}
@Override
public V get(K key) {
V value = cache.getIfPresent(key);
if (value == null) {
value = storage.read(key);
if (value != null) {
cache.put(key, value);
}
}
return value;
}
@Override
public void put(K key, V value) {
cache.put(key, value);
storage.write(key, value);
}
@Override
public void invalidate(K key) {
cache.invalidate(key);
storage.delete(key);
}
}
interface Storage<K, V> {
V read(K key);
void write(K key, V value);
void delete(K key);
}6.3 Write-back(写回)
Write-back是一种延迟写入策略:数据先写入缓存,然后异步写入持久化存储。
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicLong;
/**
* Write-back缓存实现
*/
public class WriteBackCache<K, V> implements Cache<K, V> {
private static class CacheEntry<V> {
V value;
boolean dirty;
long modifyTime;
CacheEntry(V value) {
this.value = value;
this.dirty = true;
this.modifyTime = System.currentTimeMillis();
}
void markClean() { this.dirty = false; }
void touch() { this.modifyTime = System.currentTimeMillis(); }
}
private final ConcurrentHashMap<K, CacheEntry<V>> cache;
private final Storage<K, V> storage;
private final ScheduledExecutorService flusher;
private final int maxCapacity;
public WriteBackCache(Storage<K, V> storage, int maxCapacity) {
this.cache = new ConcurrentHashMap<>(maxCapacity);
this.storage = storage;
this.maxCapacity = maxCapacity;
this.flusher = Executors.newSingleThreadScheduledExecutor();
flusher.scheduleAtFixedRate(this::flush, 1, 1, TimeUnit.MINUTES);
}
@Override
public V get(K key) {
CacheEntry<V> entry = cache.get(key);
if (entry == null) return null;
entry.touch();
return entry.value;
}
@Override
public void put(K key, V value) {
if (cache.size() >= maxCapacity) {
evictOne();
}
cache.put(key, new CacheEntry<>(value));
}
public void flush() {
for (Map.Entry<K, CacheEntry<V>> entry : cache.entrySet()) {
if (entry.getValue().dirty) {
try {
storage.write(entry.getKey(), entry.getValue().value);
entry.getValue().markClean();
} catch (Exception e) {
// 处理错误
}
}
}
}
private void evictOne() {
K victimKey = null;
long oldestTime = Long.MAX_VALUE;
for (Map.Entry<K, CacheEntry<V>> entry : cache.entrySet()) {
if (!entry.getValue().dirty && entry.getValue().modifyTime < oldestTime) {
oldestTime = entry.getValue().modifyTime;
victimKey = entry.getKey();
}
}
if (victimKey != null) {
cache.remove(victimKey);
}
}
@Override
public void invalidate(K key) {
cache.remove(key);
}
@Override
public void clear() { cache.clear(); }
@Override
public int size() { return cache.size(); }
@Override
public double getHitRate() { return 0.0; }
}6.4 缓存一致性协议
6.4.1 Cache-Aside模式
应用同时管理缓存和存储,缓存是存储的旁路。
/**
* Cache-Aside模式实现
*/
public class CacheAsidePattern<K, V> {
private final Cache<K, V> cache;
private final Storage<K, V> storage;
public CacheAsidePattern(Cache<K, V> cache, Storage<K, V> storage) {
this.cache = cache;
this.storage = storage;
}
public V read(K key) {
V value = cache.get(key);
if (value != null) {
return value;
}
value = storage.read(key);
if (value != null) {
cache.put(key, value);
}
return value;
}
public void write(K key, V value) {
storage.write(key, value);
cache.invalidate(key); // 删除而不是更新
}
public void delete(K key) {
storage.delete(key);
cache.invalidate(key);
}
}7. 缓存问题:击穿、雪崩、穿透的解决方案
本节核心技术价值
本节为你提供的核心价值是系统掌握缓存系统的三大经典问题及其解决方案。通过本节,你将理解缓存击穿、缓存雪崩、缓存穿透的根因,学会设计防护方案,并在实际项目中实施。
7.1 缓存击穿(Cache Breakdown)
7.1.1 问题描述
缓存击穿是指当某个热点key过期或失效的瞬间,大量请求同时涌入,由于缓存中找不到数据,这些请求都会穿透到后端数据库进行查询,导致数据库压力激增,甚至引发数据库宕机。
根因分析:缓存击穿的核心矛盾是热点数据的瞬时失效。当一个访问频率极高的key(如热门商品、热点新闻)在缓存中过期时,所有请求都会同时发现缓存未命中。
影响评估:
指标 | 正常状态 | 缓存击穿时 |
|---|---|---|
缓存命中率 | 95%+ | <10% |
数据库QPS | 100 | 10,000+ |
响应延迟 | 50ms | 2000ms+ |
系统可用性 | 99.9% | <50% |
7.1.2 解决方案
方案一:互斥锁(Mutex)
使用分布式锁或本地锁确保只有一个请求去加载数据,其他请求等待。
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
/**
* 互斥锁方案解决缓存击穿
*/
public class MutexCache<K, V> implements Cache<K, V> {
private final ConcurrentHashMap<K, ReentrantLock> locks = new ConcurrentHashMap<>();
private final Cache<K, V> cache;
private final Function<K, V> loader;
private final Duration lockTimeout;
public MutexCache(Cache<K, V> cache, Function<K, V> loader, Duration lockTimeout) {
this.cache = cache;
this.loader = loader;
this.lockTimeout = lockTimeout;
}
@Override
public V get(K key) {
V value = cache.get(key);
if (value != null) {
return value;
}
// 获取或创建锁
ReentrantLock lock = locks.computeIfAbsent(key, k -> new ReentrantLock());
boolean acquired = false;
try {
acquired = lock.tryLock(lockTimeout.toMillis(), TimeUnit.MILLISECONDS);
if (!acquired) {
// 获取锁失败,快速失败或使用旧值
return null;
}
// 双重检查
value = cache.get(key);
if (value != null) {
return value;
}
// 加载数据
value = loader.apply(key);
if (value != null) {
cache.put(key, value);
}
return value;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return null;
} finally {
if (acquired && lock.isHeldByCurrentThread()) {
lock.unlock();
}
locks.remove(key, lock);
}
}
@Override
public void put(K key, V value) { cache.put(key, value); }
@Override
public void invalidate(K key) { cache.invalidate(key); }
@Override
public void clear() { cache.clear(); }
@Override
public int size() { return cache.size(); }
@Override
public double getHitRate() { return cache.getHitRate(); }
}方案二:永不过期 + 异步更新
热点数据设置为永不过期,通过后台异步线程定期更新缓存。
import java.time.*;
import java.util.concurrent.*;
/**
* 永不过期 + 异步更新方案
*/
public class NeverExpireCache<K, V> implements Cache<K, V> {
/**
* 缓存条目
*/
private static class CacheEntry<V> {
V value;
long lastRefreshTime;
long dataVersion;
boolean refreshing; // 是否正在刷新
CacheEntry(V value) {
this.value = value;
this.lastRefreshTime = System.currentTimeMillis();
this.dataVersion = System.nanoTime();
this.refreshing = false;
}
}
private final ConcurrentHashMap<K, CacheEntry<V>> cache;
private final Function<K, V> loader;
private final ScheduledExecutorService refresher;
private final Duration refreshInterval;
private final Duration dataExpireTime; // 数据实际过期时间
public NeverExpireCache(
Function<K, V> loader,
Duration refreshInterval,
Duration dataExpireTime) {
this.cache = new ConcurrentHashMap<>();
this.loader = loader;
this.refreshInterval = refreshInterval;
this.dataExpireTime = dataExpireTime;
this.refresher = Executors.newSingleThreadScheduledExecutor();
// 启动定期刷新任务
refresher.scheduleAtFixedRate(
this::refreshAll,
refreshInterval.toMillis(),
refreshInterval.toMillis(),
TimeUnit.MILLISECONDS
);
}
/**
* 刷新所有条目
*/
private void refreshAll() {
for (Map.Entry<K, CacheEntry<V>> entry : cache.entrySet()) {
refreshIfNeeded(entry.getKey(), entry.getValue());
}
}
/**
* 按需刷新
*/
private void refreshIfNeeded(K key, CacheEntry<V> entry) {
long now = System.currentTimeMillis();
// 检查是否需要刷新
if (entry.refreshing) {
return; // 正在刷新,跳过
}
if (now - entry.lastRefreshTime > refreshInterval.toMillis()) {
if (entry.refreshing.compareAndSet(false, true)) {
try {
V newValue = loader.apply(key);
if (newValue != null) {
entry.value = newValue;
entry.lastRefreshTime = now;
entry.dataVersion = System.nanoTime();
}
} finally {
entry.refreshing = false;
}
}
}
}
@Override
public V get(K key) {
CacheEntry<V> entry = cache.get(key);
if (entry == null) {
// 首次加载
V value = loader.apply(key);
if (value != null) {
cache.put(key, new CacheEntry<>(value));
}
return value;
}
// 检查数据是否真正过期
if (System.currentTimeMillis() - entry.lastRefreshTime > dataExpireTime.toMillis()) {
// 数据真正过期,使用旧值(如果有)
// 同时触发异步加载
if (!entry.refreshing) {
CompletableFuture.runAsync(() -> {
V newValue = loader.apply(key);
if (newValue != null) {
cache.put(key, new CacheEntry<>(newValue));
}
});
}
}
return entry.value;
}
@Override
public void put(K key, V value) {
cache.put(key, new CacheEntry<>(value));
}
@Override
public void invalidate(K key) {
cache.remove(key);
}
@Override
public void clear() { cache.clear(); }
@Override
public int size() { return cache.size(); }
@Override
public double getHitRate() { return 0.0; }
public void shutdown() {
refresher.shutdown();
}
}7.2 缓存雪崩(Cache Avalanche)
7.2.1 问题描述
缓存雪崩是指大量缓存key在同一时间集中过期,导致大量请求直接访问数据库,造成数据库压力激增甚至宕机。与缓存击穿不同,缓存雪崩是批量key的集中失效。
根因分析:
- TTL设置不合理:大量key设置了相同的过期时间
- 系统重启:缓存服务器重启,所有缓存数据丢失
- 故障传播:某个缓存节点故障,导致请求集中到其他节点
影响评估:
┌─────────────────────────────────────────────────────────────┐
│ 缓存雪崩时序图 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Time Cache Status DB Status │
│ ──── ─────────── ───────── │
│ T1 [Key1 expires] │
│ T2 [Key2 expires] [DB QPS increasing] │
│ T3 [Key3 expires] [DB load: 80%] │
│ T4 [Key4 expires] [DB load: 100%] │
│ T5 [Key5 expires] [DB timeout] │
│ T6 [All keys gone] [DB down] │
│ │
└─────────────────────────────────────────────────────────────┘7.2.2 解决方案
方案一:TTL随机化 + 过期时间平滑分布
import java.util.concurrent.*;
import java.util.Random;
/**
* TTL随机化方案解决缓存雪崩
*/
public class JitterTTLCache<K, V> implements Cache<K, V> {
private final Cache<K, V> cache;
private final Random random;
private final float jitterFactor; // 抖动因子 (0.0 ~ 1.0)
public JitterTTLCache(Cache<K, V> cache, float jitterFactor) {
this.cache = cache;
this.random = new Random();
this.jitterFactor = jitterFactor;
}
@Override
public V get(K key) {
return cache.get(key);
}
@Override
public void put(K key, V value) {
cache.put(key, value);
}
/**
* 计算带抖动的TTL
*
* @param baseTTL 基础TTL
* @return 带随机偏差的TTL
*/
public long calculateJitteredTTL(Duration baseTTL) {
long baseMillis = baseTTL.toMillis();
long jitter = (long) (baseMillis * jitterFactor * random.nextDouble());
return baseMillis + jitter;
}
@Override
public void invalidate(K key) { cache.invalidate(key); }
@Override
public void clear() { cache.clear(); }
@Override
public int size() { return cache.size(); }
@Override
public double getHitRate() { return cache.getHitRate(); }
}方案二:多级缓存 + 备份缓存
import java.util.concurrent.*;
/**
* 多级缓存 + 备份缓存方案
*/
public class MultiLevelWithBackupCache<K, V> implements Cache<K, V> {
private final Cache<K, V> primaryCache; // 主缓存
private final Cache<K, V> backupCache; // 备份缓存
private final Function<K, V> loader;
private final ScheduledExecutorService checker;
public MultiLevelWithBackupCache(
Cache<K, V> primaryCache,
Cache<K, V> backupCache,
Function<K, V> loader) {
this.primaryCache = primaryCache;
this.backupCache = backupCache;
this.loader = loader;
this.checker = Executors.newSingleThreadScheduledExecutor();
// 启动备份检查器
checker.scheduleAtFixedRate(this::syncBackup,
1, 1, TimeUnit.MINUTES);
}
@Override
public V get(K key) {
// 先查主缓存
V value = primaryCache.get(key);
if (value != null) {
return value;
}
// 主缓存未命中,查备份缓存
value = backupCache.get(key);
if (value != null) {
// 回填主缓存
primaryCache.put(key, value);
return value;
}
// 都未命中,从数据源加载
value = loader.apply(key);
if (value != null) {
primaryCache.put(key, value);
backupCache.put(key, value);
}
return value;
}
/**
* 同步备份缓存
*/
private void syncBackup() {
// 将主缓存的热点数据同步到备份缓存
// 实际实现会更复杂,需要考虑容量限制
}
@Override
public void put(K key, V value) {
primaryCache.put(key, value);
backupCache.put(key, value);
}
@Override
public void invalidate(K key) {
primaryCache.invalidate(key);
backupCache.invalidate(key);
}
@Override
public void clear() {
primaryCache.clear();
backupCache.clear();
}
@Override
public int size() { return primaryCache.size(); }
@Override
public double getHitRate() { return primaryCache.getHitRate(); }
}7.3 缓存穿透(Cache Penetration)
7.3.1 问题描述
缓存穿透是指查询一个根本不存在的数据,由于缓存中找不到(永远找不到),请求会穿透缓存直接访问数据库。如果大量请求查询不存在的数据,数据库压力会激增。
根因分析:
- 恶意攻击:攻击者故意构造大量不存在的key进行查询
- 业务问题:业务逻辑错误,查询了不应该存在的数据
- 数据初始化问题:数据库有数据但缓存未初始化
常见场景:
场景 | 示例 | 风险 |
|---|---|---|
恶意攻击 | 查询ID=-1的数据 | 高 |
爬虫抓取 | 顺序爬取所有ID | 高 |
业务错误 | 查询已删除的用户 | 中 |
边界条件 | 查询ID=0的数据 | 低 |
7.3.2 解决方案
方案一:布隆过滤器(Bloom Filter)
布隆过滤器是一种概率数据结构,用于判断一个元素是否可能存在于集合中。
import java.util.*;
import java.util.concurrent.*;
/**
* 布隆过滤器方案解决缓存穿透
*/
public class BloomFilterCache<K, V> implements Cache<K, V> {
private final Cache<K, V> cache;
private final BloomFilter<K> bloomFilter;
private final Function<K, V> loader;
private final ScheduledExecutorService cleaner;
public BloomFilterCache(
Cache<K, V> cache,
int expectedInsertions,
double falsePositiveRate,
Function<K, V> loader) {
this.cache = cache;
this.bloomFilter = BloomFilter.create(
Funnels.identityFunnel(),
expectedInsertions,
falsePositiveRate
);
this.loader = loader;
this.cleaner = Executors.newSingleThreadScheduledExecutor();
// 定期重建布隆过滤器(清理已删除的数据)
cleaner.scheduleAtFixedRate(this::rebuildBloomFilter,
1, 1, TimeUnit.HOURS);
}
@Override
public V get(K key) {
// 布隆过滤器检查
if (!bloomFilter.mightContain(key)) {
// 布隆过滤器判断key一定不存在
return null;
}
// 布隆过滤器判断key可能存在,查询缓存
V value = cache.get(key);
if (value != null) {
return value;
}
// 缓存未命中,从数据源加载
value = loader.apply(key);
if (value != null) {
cache.put(key, value);
}
return value;
}
/**
* 添加已知存在的key到布隆过滤器
*/
public void addKnownKey(K key) {
bloomFilter.put(key);
}
/**
* 添加已知存在的keys到布隆过滤器
*/
public void addKnownKeys(Collection<K> keys) {
keys.forEach(bloomFilter::put);
}
/**
* 重建布隆过滤器
*/
private void rebuildBloomFilter() {
// 重建逻辑:从数据库加载所有key重新构建
}
@Override
public void put(K key, V value) {
bloomFilter.put(key);
cache.put(key, value);
}
@Override
public void invalidate(K key) {
cache.invalidate(key);
// 注意:布隆过滤器不支持删除操作
// 可以通过定期重建来解决
}
@Override
public void clear() { cache.clear(); }
@Override
public int size() { return cache.size(); }
@Override
public double getHitRate() { return cache.getHitRate(); }
}方案二:空值缓存(Null Value Caching)
对于查询结果为空的数据,也进行缓存(使用特殊的空值标记)。
import java.util.concurrent.*;
/**
* 空值缓存方案解决缓存穿透
*/
public class NullValueCache<K, V> implements Cache<K, V> {
/**
* 空值标记
*/
private static final Object NULL_VALUE = new Object();
private final ConcurrentHashMap<K, Long> nullCache; // key -> 过期时间
private final Cache<K, V> cache;
private final Duration nullValueTTL;
private final ScheduledExecutorService cleaner;
public NullValueCache(Cache<K, V> cache, Duration nullValueTTL) {
this.cache = cache;
this.nullValueTTL = nullValueTTL;
this.nullCache = new ConcurrentHashMap<>();
this.cleaner = Executors.newSingleThreadScheduledExecutor();
cleaner.scheduleAtFixedRate(this::cleanExpiredNulls,
1, 1, TimeUnit.MINUTES);
}
@Override
public V get(K key) {
// 检查空值缓存
Long expireTime = nullCache.get(key);
if (expireTime != null) {
if (System.currentTimeMillis() < expireTime) {
// 空值未过期
return null;
} else {
// 空值已过期,移除
nullCache.remove(key);
}
}
// 查询正常缓存
V value = cache.get(key);
if (value != null) {
return value;
}
return null; // 未找到
}
/**
* 缓存空值
*/
public void cacheNullValue(K key) {
long expireTime = System.currentTimeMillis() + nullValueTTL.toMillis();
nullCache.put(key, expireTime);
}
private void cleanExpiredNulls() {
long now = System.currentTimeMillis();
nullCache.entrySet().removeIf(entry -> entry.getValue() < now);
}
@Override
public void put(K key, V value) {
if (value == null) {
cacheNullValue(key);
} else {
cache.put(key, value);
}
}
@Override
public void invalidate(K key) {
cache.invalidate(key);
nullCache.remove(key);
}
@Override
public void clear() {
cache.clear();
nullCache.clear();
}
@Override
public int size() { return cache.size(); }
@Override
public double getHitRate() { return cache.getHitRate(); }
}方案三:参数校验 + 恶意请求拦截
import java.util.regex.*;
/**
* 参数校验方案
*/
public class ValidatingCache<K, V> implements Cache<K, V> {
private final Cache<K, V> cache;
private final Pattern validKeyPattern;
private final Set<K> blockedKeys;
private final RateLimiter rateLimiter;
public ValidatingCache(
Cache<K, V> cache,
String keyPattern,
int maxRequestsPerSecond) {
this.cache = cache;
this.validKeyPattern = Pattern.compile(keyPattern);
this.blockedKeys = ConcurrentHashMap.newKeySet();
this.rateLimiter = new RateLimiter(maxRequestsPerSecond);
}
/**
* 验证key是否合法
*/
private boolean isValidKey(K key) {
if (blockedKeys.contains(key)) {
return false;
}
// 使用正则表达式验证key格式
if (key instanceof String) {
return validKeyPattern.matcher((String) key).matches();
}
return true;
}
@Override
public V get(K key) {
if (!isValidKey(key)) {
// 记录恶意请求
return null;
}
// 限流检查
if (!rateLimiter.tryAcquire(key)) {
return null;
}
return cache.get(key);
}
@Override
public void put(K key, V value) {
if (isValidKey(key)) {
cache.put(key, value);
}
}
@Override
public void invalidate(K key) { cache.invalidate(key); }
@Override
public void clear() { cache.clear(); }
@Override
public int size() { return cache.size(); }
@Override
public double getHitRate() { return cache.getHitRate(); }
/**
* 封禁恶意key
*/
public void blockKey(K key) {
blockedKeys.add(key);
}
/**
* 限流器
*/
static class RateLimiter {
private final int maxPerSecond;
private final Map<K, Long> lastRequest = new ConcurrentHashMap<>();
RateLimiter(int maxPerSecond) {
this.maxPerSecond = maxPerSecond;
}
boolean tryAcquire(K key) {
long now = System.currentTimeMillis();
long last = lastRequest.getOrDefault(key, 0L);
if (now - last < 1000 / maxPerSecond) {
return false;
}
lastRequest.put(key, now);
return true;
}
}
}8. 实践:实现一个支持多级缓存的Cache System
本节核心技术价值
本节为你提供的核心价值是获得一个可直接应用于AI IDE项目的生产级Cache System完整实现。通过本节,你将掌握多级缓存系统的完整架构设计,包括接口抽象、配置管理、监控指标、异常处理等工程细节。
8.1 系统架构设计
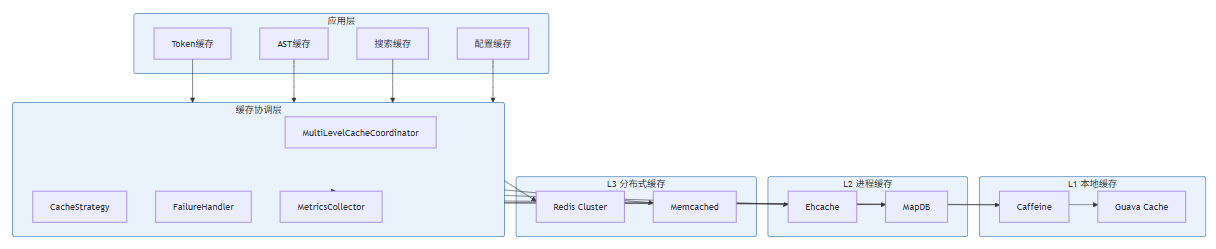
8.2 核心接口定义
import java.util.*;
import java.util.concurrent.*;
import java.util.function.*;
/**
* 多级缓存系统核心接口与实现
*/
public class CacheSystem {
/**
* 缓存接口
*/
public interface Cache<K, V> {
V get(K key);
void put(K key, V value);
void invalidate(K key);
void clear();
int size();
double getHitRate();
CacheStats getStats();
}
/**
* 缓存统计信息
*/
public static class CacheStats {
public final long hits;
public final long misses;
public final long evictions;
public final long size;
public final long capacity;
public final long totalLoadTimeMs;
public CacheStats(long hits, long misses, long evictions,
long size, long capacity, long totalLoadTimeMs) {
this.hits = hits;
this.misses = misses;
this.evictions = evictions;
this.size = size;
this.capacity = capacity;
this.totalLoadTimeMs = totalLoadTimeMs;
}
public double getHitRate() {
long total = hits + misses;
return total == 0 ? 0.0 : (double) hits / total;
}
public double getMissRate() {
return 1.0 - getHitRate();
}
}
/**
* 缓存配置
*/
public static class CacheConfig {
public final String name;
public final int l1Capacity;
public final int l2Capacity;
public final long l3MaxMemory;
public final Duration defaultTTL;
public final Duration refreshInterval;
public final boolean writeThrough;
public final boolean readThrough;
public final float jitterFactor;
public CacheConfig(Builder builder) {
this.name = builder.name;
this.l1Capacity = builder.l1Capacity;
this.l2Capacity = builder.l2Capacity;
this.l3MaxMemory = builder.l3MaxMemory;
this.defaultTTL = builder.defaultTTL;
this.refreshInterval = builder.refreshInterval;
this.writeThrough = builder.writeThrough;
this.readThrough = builder.readThrough;
this.jitterFactor = builder.jitterFactor;
}
public static Builder builder() {
return new Builder();
}
public static class Builder {
private String name = "default";
private int l1Capacity = 1000;
private int l2Capacity = 10000;
private long l3MaxMemory = 1024 * 1024 * 1024;
private Duration defaultTTL = Duration.ofMinutes(30);
private Duration refreshInterval = Duration.ofMinutes(5);
private boolean writeThrough = true;
private boolean readThrough = true;
private float jitterFactor = 0.1f;
public Builder name(String name) { this.name = name; return this; }
public Builder l1Capacity(int capacity) { this.l1Capacity = capacity; return this; }
public Builder l2Capacity(int capacity) { this.l2Capacity = capacity; return this; }
public Builder l3MaxMemory(long bytes) { this.l3MaxMemory = bytes; return this; }
public Builder defaultTTL(Duration ttl) { this.defaultTTL = ttl; return this; }
public Builder refreshInterval(Duration interval) { this.refreshInterval = interval; return this; }
public Builder writeThrough(boolean enabled) { this.writeThrough = enabled; return this; }
public Builder readThrough(boolean enabled) { this.readThrough = enabled; return this; }
public Builder jitterFactor(float factor) { this.jitterFactor = factor; return this; }
public CacheConfig build() {
return new CacheConfig(this);
}
}
}
/**
* 缓存监控指标
*/
public interface CacheMonitor {
void recordHit(String cacheName, String level);
void recordMiss(String cacheName, String level);
void recordEviction(String cacheName, String level);
void recordLatency(String cacheName, String operation, long latencyMs);
}
/**
* 缓存监控系统实现
*/
public static class MetricsCollector implements CacheMonitor {
private final Map<String, Map<String, AtomicLong>> hits = new ConcurrentHashMap<>();
private final Map<String, Map<String, AtomicLong>> misses = new ConcurrentHashMap<>();
private final Map<String, Map<String, AtomicLong>> evictions = new ConcurrentHashMap<>();
private final Map<String, Map<String, AtomicLong>> latencies = new ConcurrentHashMap<>();
@Override
public void recordHit(String cacheName, String level) {
hits.computeIfAbsent(cacheName, k -> new ConcurrentHashMap<>())
.computeIfAbsent(level, k -> new AtomicLong())
.incrementAndGet();
}
@Override
public void recordMiss(String cacheName, String level) {
misses.computeIfAbsent(cacheName, k -> new ConcurrentHashMap<>())
.computeIfAbsent(level, k -> new AtomicLong())
.incrementAndGet();
}
@Override
public void recordEviction(String cacheName, String level) {
evictions.computeIfAbsent(cacheName, k -> new ConcurrentHashMap<>())
.computeIfAbsent(level, k -> new AtomicLong())
.incrementAndGet();
}
@Override
public void recordLatency(String cacheName, String operation, long latencyMs) {
String key = cacheName + ":" + operation;
latencies.computeIfAbsent(cacheName, k -> new ConcurrentHashMap<>())
.computeIfAbsent(operation, k -> new AtomicLong())
.addAndGet(latencyMs);
}
public Map<String, Object> getMetrics(String cacheName) {
Map<String, Object> metrics = new HashMap<>();
long totalHits = hits.getOrDefault(cacheName, Collections.emptyMap())
.values().stream().mapToLong(AtomicLong::get).sum();
long totalMisses = misses.getOrDefault(cacheName, Collections.emptyMap())
.values().stream().mapToLong(AtomicLong::get).sum();
long totalEvictions = evictions.getOrDefault(cacheName, Collections.emptyMap())
.values().stream().mapToLong(AtomicLong::get).sum();
double hitRate = totalHits + totalMisses == 0 ? 0.0 :
(double) totalHits / (totalHits + totalMisses);
metrics.put("hits", totalHits);
metrics.put("misses", totalMisses);
metrics.put("evictions", totalEvictions);
metrics.put("hitRate", hitRate);
return metrics;
}
}
}8.3 完整实现代码
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.*;
import java.util.function.*;
/**
* 多级缓存管理器
*
* 功能特性:
* - L1/L2/L3三级缓存协调
* - 自动容灾与恢复
* - 运行时配置调整
* - 完整监控指标
* - 多种缓存策略支持
*/
public class MultiLevelCacheManager<K, V> {
/**
* 缓存层级
*/
public enum Level {
L1("本地内存"),
L2("进程缓存"),
L3("分布式缓存");
private final String description;
Level(String description) {
this.description = description;
}
public String getDescription() {
return description;
}
}
/**
* 缓存条目
*/
public static class CacheEntry<V> {
V value;
long version;
long createTime;
long accessTime;
long expireTime; // -1表示不过期
Level sourceLevel;
CacheEntry(V value, Level sourceLevel) {
this.value = value;
this.version = System.nanoTime();
this.createTime = System.currentTimeMillis();
this.accessTime = this.createTime;
this.expireTime = -1;
this.sourceLevel = sourceLevel;
}
void touch() {
this.accessTime = System.currentTimeMillis();
this.version = System.nanoTime();
}
boolean isExpired() {
return expireTime > 0 && System.currentTimeMillis() > expireTime;
}
long getAge() {
return System.currentTimeMillis() - createTime;
}
}
/**
* 统计信息
*/
public static class LevelStats {
public final Level level;
public final AtomicLong hits = new AtomicLong();
public final AtomicLong misses = new AtomicLong();
public final AtomicLong evictions = new AtomicLong();
public final AtomicLong loadCount = new AtomicLong();
public final AtomicLong totalLoadTime = new AtomicLong();
public LevelStats(Level level) {
this.level = level;
}
public double getHitRate() {
long total = hits.get() + misses.get();
return total == 0 ? 0.0 : (double) hits.get() / total;
}
}
// 组件
private final Cache<K, CacheEntry<V>> l1Cache;
private final Cache<K, CacheEntry<V>> l2Cache;
private final Cache<K, CacheEntry<V>> l3Cache;
private final Function<K, V> loader;
private final CacheConfig config;
private final CacheMonitor monitor;
// 统计
private final Map<Level, LevelStats> stats = new EnumMap<>(Level.class);
// 配置
private volatile boolean writeThrough;
private volatile boolean readThrough;
private volatile boolean enabled = true;
/**
* 构造函数
*/
public MultiLevelCacheManager(
Cache<K, CacheEntry<V>> l1Cache,
Cache<K, CacheEntry<V>> l2Cache,
Cache<K, CacheEntry<V>> l3Cache,
Function<K, V> loader,
CacheConfig config,
CacheMonitor monitor) {
this.l1Cache = l1Cache;
this.l2Cache = l2Cache;
this.l3Cache = l3Cache;
this.loader = loader;
this.config = config;
this.monitor = monitor;
this.writeThrough = config.writeThrough;
this.readThrough = config.readThrough;
// 初始化统计
stats.put(Level.L1, new LevelStats(Level.L1));
stats.put(Level.L2, new LevelStats(Level.L2));
stats.put(Level.L3, new LevelStats(Level.L3));
}
/**
* 获取缓存值
*/
public V get(K key) {
if (!enabled) {
return readThrough ? loader.apply(key) : null;
}
long start = System.nanoTime();
try {
// 1. 查L1
CacheEntry<V> entry = l1Cache.get(key);
if (entry != null && !entry.isExpired()) {
entry.touch();
stats.get(Level.L1).hits.incrementAndGet();
monitor.recordHit(config.name, Level.L1.name());
return entry.value;
}
if (entry != null) {
stats.get(Level.L1).misses.incrementAndGet();
}
// 2. 查L2
entry = l2Cache.get(key);
if (entry != null && !entry.isExpired()) {
entry.touch();
stats.get(Level.L2).hits.incrementAndGet();
monitor.recordHit(config.name, Level.L2.name());
// 提升到L1
promoteToLevel(Level.L1, key, entry);
return entry.value;
}
if (entry != null) {
stats.get(Level.L2).misses.incrementAndGet();
}
// 3. 查L3
entry = l3Cache.get(key);
if (entry != null && !entry.isExpired()) {
entry.touch();
stats.get(Level.L3).hits.incrementAndGet();
monitor.recordHit(config.name, Level.L3.name());
// 提升到L2和L1
promoteToLevel(Level.L2, key, entry);
promoteToLevel(Level.L1, key, entry);
return entry.value;
}
if (entry != null) {
stats.get(Level.L3).misses.incrementAndGet();
}
// 4. 从数据源加载
if (readThrough) {
long loadStart = System.nanoTime();
V value = loader.apply(key);
long loadTime = System.nanoTime() - loadStart;
if (value != null) {
CacheEntry<V> newEntry = new CacheEntry<>(value, Level.L1);
newEntry.expireTime = config.defaultTTL.toMillis() > 0 ?
System.currentTimeMillis() + config.defaultTTL.toMillis() : -1;
put(key, newEntry);
stats.get(Level.L1).loadCount.incrementAndGet();
stats.get(Level.L1).totalLoadTime.addAndGet(loadTime / 1_000_000);
return value;
}
}
return null;
} finally {
monitor.recordLatency(config.name, "get", (System.nanoTime() - start) / 1_000_000);
}
}
/**
* 写入缓存
*/
public void put(K key, CacheEntry<V> entry) {
if (!enabled) return;
if (writeThrough) {
// 同步写入所有层级
putToLevel(Level.L1, key, entry);
putToLevel(Level.L2, key, entry);
putToLevel(Level.L3, key, entry);
} else {
// 只写入L1,异步同步到下层
putToLevel(Level.L1, key, entry);
asyncSyncToLowerLevels(key, entry);
}
}
/**
* 异步同步到下层缓存
*/
private void asyncSyncToLowerLevels(K key, CacheEntry<V> entry) {
CompletableFuture.runAsync(() -> putToLevel(Level.L2, key, entry));
CompletableFuture.runAsync(() -> putToLevel(Level.L3, key, entry));
}
/**
* 写入指定层级
*/
private void putToLevel(Level level, K key, CacheEntry<V> entry) {
Cache<K, CacheEntry<V>> cache = getCache(level);
if (cache != null) {
cache.put(key, entry);
}
}
/**
* 获取指定层级的缓存
*/
private Cache<K, CacheEntry<V>> getCache(Level level) {
switch (level) {
case L1: return l1Cache;
case L2: return l2Cache;
case L3: return l3Cache;
default: return null;
}
}
/**
* 提升到指定层级
*/
private void promoteToLevel(Level level, K key, CacheEntry<V> entry) {
Cache<K, CacheEntry<V>> cache = getCache(level);
if (cache != null) {
// 检查容量
if (cache.size() >= getCapacity(level)) {
evictFromLevel(level);
}
cache.put(key, entry);
}
}
/**
* 获取指定层级的容量
*/
private int getCapacity(Level level) {
switch (level) {
case L1: return config.l1Capacity;
case L2: return config.l2Capacity;
default: return Integer.MAX_VALUE;
}
}
/**
* 从指定层级淘汰
*/
private void evictFromLevel(Level level) {
stats.get(level).evictions.incrementAndGet();
monitor.recordEviction(config.name, level.name());
// 实际淘汰逻辑由底层缓存实现
}
/**
* 使缓存失效
*/
public void invalidate(K key) {
l1Cache.invalidate(key);
l2Cache.invalidate(key);
l3Cache.invalidate(key);
}
/**
* 清空所有缓存
*/
public void clear() {
l1Cache.clear();
l2Cache.clear();
l3Cache.clear();
}
/**
* 获取统计信息
*/
public Map<String, Object> getStats() {
Map<String, Object> result = new HashMap<>();
long totalHits = 0;
long totalMisses = 0;
long totalEvictions = 0;
for (Map.Entry<Level, LevelStats> entry : stats.entrySet()) {
LevelStats s = entry.getValue();
totalHits += s.hits.get();
totalMisses += s.misses.get();
totalEvictions += s.evictions.get();
Map<String, Object> levelStats = new HashMap<>();
levelStats.put("hits", s.hits.get());
levelStats.put("misses", s.misses.get());
levelStats.put("evictions", s.evictions.get());
levelStats.put("hitRate", s.getHitRate());
levelStats.put("loadCount", s.loadCount.get());
levelStats.put("avgLoadTime", s.loadCount.get() > 0 ?
(double) s.totalLoadTime.get() / s.loadCount.get() : 0.0);
result.put(entry.getKey().name(), levelStats);
}
result.put("totalHits", totalHits);
result.put("totalMisses", totalMisses);
result.put("totalEvictions", totalEvictions);
result.put("overallHitRate", totalHits + totalMisses == 0 ? 0.0 :
(double) totalHits / (totalHits + totalMisses));
return result;
}
/**
* 获取指定层级的统计
*/
public LevelStats getLevelStats(Level level) {
return stats.get(level);
}
/**
* 启用/禁用缓存
*/
public void setEnabled(boolean enabled) {
this.enabled = enabled;
}
/**
* 启用/禁用写穿透
*/
public void setWriteThrough(boolean writeThrough) {
this.writeThrough = writeThrough;
}
/**
* 启用/禁用读穿透
*/
public void setReadThrough(boolean readThrough) {
this.readThrough = readThrough;
}
/**
* 健康检查
*/
public boolean isHealthy() {
// 检查各层缓存是否正常工作
try {
// L1检查
l1Cache.put("__health_check__", new CacheEntry<>(null, Level.L1));
l1Cache.invalidate("__health_check__");
// L2检查
l2Cache.put("__health_check__", new CacheEntry<>(null, Level.L2));
l2Cache.invalidate("__health_check__");
return true;
} catch (Exception e) {
return false;
}
}
}8.4 使用示例
import com.github.benmanes.caffeine.cache.*;
import java.time.Duration;
import java.util.concurrent.*;
/**
* Cache System使用示例
*/
public class CacheSystemUsage {
public static void main(String[] args) {
// 1. 创建缓存配置
CacheConfig config = CacheConfig.builder()
.name("ai-ide-cache")
.l1Capacity(1000) // L1: 1000条目
.l2Capacity(10000) // L2: 10000条目
.l3MaxMemory(1024 * 1024 * 1024) // L3: 1GB
.defaultTTL(Duration.ofMinutes(30))
.refreshInterval(Duration.ofMinutes(5))
.writeThrough(true)
.readThrough(true)
.jitterFactor(0.1f)
.build();
// 2. 创建监控器
CacheSystem.CacheMonitor monitor = new CacheSystem.MetricsCollector();
// 3. 创建数据加载器
Function<String, String> loader = key -> {
// 从数据库或AI模型加载数据
return loadFromBackend(key);
};
// 4. 创建各级缓存
Cache<String, MultiLevelCacheManager.CacheEntry<String>> l1Cache =
Caffeine.newBuilder()
.maximumSize(config.l1Capacity)
.recordStats()
.build();
Cache<String, MultiLevelCacheManager.CacheEntry<String>> l2Cache =
Caffeine.newBuilder()
.maximumSize(config.l2Capacity)
.recordStats()
.build();
// L3缓存(这里简化处理,实际使用Redis)
Cache<String, MultiLevelCacheManager.CacheEntry<String>> l3Cache =
Caffeine.newBuilder()
.maximumSize(Integer.MAX_VALUE)
.recordStats()
.build();
// 5. 创建多级缓存管理器
MultiLevelCacheManager<String, String> cacheManager =
new MultiLevelCacheManager<>(
l1Cache, l2Cache, l3Cache,
loader, config, monitor
);
// 6. 使用缓存
String result = cacheManager.get("token:file:123");
// 7. 获取统计信息
System.out.println(cacheManager.getStats());
// 8. 健康检查
System.out.println("Cache healthy: " + cacheManager.isHealthy());
}
private static String loadFromBackend(String key) {
// 模拟从后端加载数据
return "data_for_" + key;
}
}9. 总结与展望
9.1 核心要点回顾
本文系统讲解了Cache System多级缓存与缓存一致性的核心知识:
- 缓存策略:LRU、LFU、TTL等淘汰算法各有优劣,需要根据业务场景选择
- 缓存层级:L1本地缓存速度快但容量小,L3分布式缓存容量大但延迟高,多级组合可实现性能和容量的平衡
- 本地缓存:Caffeine的Window TinyLFU算法是目前最优的本地缓存淘汰策略
- 分布式缓存:Redis Cluster通过哈希槽实现数据分片,支持高可用和水平扩展
- 缓存一致性:Write-through保证强一致性但性能较低,Write-back性能高但存在数据丢失风险
- 缓存问题:击穿、雪崩、穿透是三大经典问题,需要通过互斥锁、TTL随机化、布隆过滤器等方案解决
9.2 未来发展趋势
- 智能化缓存:基于机器学习的热点预测和容量规划
- 边缘缓存:CDN边缘节点的普及推动边缘缓存技术的发展
- 持久化内存:Intel Optane等持久化内存将改变缓存层次结构
- 零拷贝缓存:绕过内核直接访问缓存数据
9.3 实践建议
场景 | 推荐配置 |
|---|---|
Token缓存 | L1 Caffeine, LRU, 10000条目, 30分钟TTL |
AST缓存 | L1 Caffeine + L2 Ehcache, LRU-K, 100MB权重限制 |
搜索结果缓存 | L1 Caffeine + L3 Redis, TTL 5分钟 + 布隆过滤器 |
配置缓存 | L1 Caffeine, Write-through, 24小时TTL |
模型推理缓存 | L2 Ehcache + L3 Redis, Write-back, 24小时TTL |
参考链接:
- Caffeine Cache GitHub - 高性能本地缓存库
- Guava Cache官方文档 - Google缓存指南
- Redis Cluster官方文档 - Redis集群规范
- Ehcache官方文档 - 企业级缓存解决方案
- ACM SIGMETRICS论文 - 缓存算法研究论文
附录(Appendix):
A. Cache System完整代码
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.*;
import java.util.function.*;
/**
* 完整的多级缓存系统实现
*/
public class CompleteCacheSystem {
/**
* 缓存接口
*/
public interface Cache<K, V> {
V get(K key);
void put(K key, V value);
void invalidate(K key);
void clear();
int size();
double getHitRate();
}
/**
* 统计信息
*/
public static class Stats {
public final AtomicLong hits = new AtomicLong();
public final AtomicLong misses = new AtomicLong();
public final AtomicLong evictions = new AtomicLong();
public double getHitRate() {
long total = hits.get() + misses.get();
return total == 0 ? 0.0 : (double) hits.get() / total;
}
}
/**
* 配置构建器
*/
public static class ConfigBuilder {
private int l1Capacity = 1000;
private int l2Capacity = 10000;
private boolean writeThrough = true;
private boolean readThrough = true;
public ConfigBuilder l1Capacity(int capacity) { this.l1Capacity = capacity; return this; }
public ConfigBuilder l2Capacity(int capacity) { this.l2Capacity = capacity; return this; }
public ConfigBuilder writeThrough(boolean enabled) { this.writeThrough = enabled; return this; }
public ConfigBuilder readThrough(boolean enabled) { this.readThrough = enabled; return this; }
public CompleteCacheConfig build() {
return new CompleteCacheConfig(l1Capacity, l2Capacity, writeThrough, readThrough);
}
}
public static class CompleteCacheConfig {
public final int l1Capacity;
public final int l2Capacity;
public final boolean writeThrough;
public final boolean readThrough;
public CompleteCacheConfig(int l1Capacity, int l2Capacity,
boolean writeThrough, boolean readThrough) {
this.l1Capacity = l1Capacity;
this.l2Capacity = l2Capacity;
this.writeThrough = writeThrough;
this.readThrough = readThrough;
}
}
}关键词: 多级缓存、LRU、LFU、TTL、Caffeine、Guava Cache、Redis Cluster、缓存一致性、Write-through、Write-back、缓存击穿、缓存雪崩、缓存穿透、分布式缓存、本地缓存、Cache System

在这里插入图片描述
- Google (2017). “The Need for Speed: 2017” - https://www.thinkwithgoogle.com ↩︎
- O’Neil, E.J. et al. (1993). “The LRU-K Page Replacement Algorithm For Database Disk Buffering” - ACM SIGMOD ↩︎
- Lee, D. et al. (1999). “LIRS: An Efficient Low Inter-Reference Recency Set Replacement Policy” - ACM SIGMETRICS ↩︎
- Lee, D. et al. (2001). “LRFU: A Path for Efficient Web Caching” - IEEE TC ↩︎
- Megiddo, N. & Modha, D.S. (2003). “ARC: A Self-Tuning, Low Overhead Replacement Cache” - USENIX FAST ↩︎
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号