Scheduler:任务调度与资源分配


作者: HOS(安全风信子) 日期: 2026-05-25 主要来源平台: GitHub 摘要: AI IDE 的任务(代码生成、搜索索引、测试执行)需要有序调度。Scheduler 负责任务的优先级管理、资源分配、超时控制、失败重试。本文讲解 Scheduler 的实现:优先级队列、多级反馈队列、协程调度、资源池管理、以及如何构建一个支持数万并发任务的高性能调度器。通过优先级队列实现任务排序,通过资源配额保证系统稳定性,通过超时与重试机制确保任务可靠性,最终通过协程调度提升资源利用率。文中提供完整的 Python 实现代码,包含协程调度器、资源池管理器、监控告警模块,可直接应用于生产环境。
目录- 1 引言:Scheduler在AI IDE系统中的核心定位
- 1.1 任务调度在AI IDE场景下的挑战
- 1.2 Scheduler与相关组件的关系
- 1.3 本文的结构安排
- 2 任务模型:Job、Task、Step的层级关系
- 2.1 三层任务模型的设计理念
- 2.2 Job层:用户视角的任务封装
- 2.3 Task层:并行执行的工作单元
- 2.4 Step层:原子操作的不可再分单元
- 2.5 层级关系的代码示例
- 3 优先级队列:多级优先级的实现
- 3.1 优先级队列的核心设计
- 3.2 基于堆的优先级队列实现
- 3.3 多级反馈队列:公平与效率的平衡
- 3.4 优先级队列使用示例
- 4 资源分配:CPU、Memory、GPU的配额管理
- 4.1 资源分配的系统架构
- 4.2 资源池管理器的实现
- 4.3 资源分配的策略模式
- 5 超时控制:软超时与硬超时
- 5.1 超时控制的设计理念
- 5.2 软超时与硬超时的实现
- 5.3 超时控制使用示例
- 6 失败重试:指数退避与最大重试次数
- 6.1 重试机制的设计原则
- 6.2 指数退避重试策略的实现
- 6.3 重试机制使用示例
- 7 监控告警:任务积压与SLA预警
- 7.1 监控指标体系
- 7.2 监控指标收集器的实现
- 7.3 监控面板数据示例
- 8 实践:实现一个支持协程的任务调度器
- 8.1 协程调度器整体架构
- 8.2 完整调度器实现
- 8.3 调度器使用示例
- 9 总结与最佳实践
- 9.1 Scheduler设计要点回顾
- 9.2 生产环境部署建议
- 9.3 性能优化建议
- 9.4 常见问题与解决方案
- 10 参考文献与深入阅读
- 1.1 任务调度在AI IDE场景下的挑战
- 1.2 Scheduler与相关组件的关系
- 1.3 本文的结构安排
- 2.1 三层任务模型的设计理念
- 2.2 Job层:用户视角的任务封装
- 2.3 Task层:并行执行的工作单元
- 2.4 Step层:原子操作的不可再分单元
- 2.5 层级关系的代码示例
- 3.1 优先级队列的核心设计
- 3.2 基于堆的优先级队列实现
- 3.3 多级反馈队列:公平与效率的平衡
- 3.4 优先级队列使用示例
- 4.1 资源分配的系统架构
- 4.2 资源池管理器的实现
- 4.3 资源分配的策略模式
- 5.1 超时控制的设计理念
- 5.2 软超时与硬超时的实现
- 5.3 超时控制使用示例
- 6.1 重试机制的设计原则
- 6.2 指数退避重试策略的实现
- 6.3 重试机制使用示例
- 7.1 监控指标体系
- 7.2 监控指标收集器的实现
- 7.3 监控面板数据示例
- 8.1 协程调度器整体架构
- 8.2 完整调度器实现
- 8.3 调度器使用示例
- 9.1 Scheduler设计要点回顾
- 9.2 生产环境部署建议
- 9.3 性能优化建议
- 9.4 常见问题与解决方案
- Scheduler完整代码
1 引言:Scheduler在AI IDE系统中的核心定位
本节为你提供的核心价值:理解Scheduler作为AI IDE任务调度中枢的角色,掌握其与消息队列、协程框架、资源池的协作关系,建立完整的任务调度知识体系。
1.1 任务调度在AI IDE场景下的挑战
AI IDE与传统IDE最本质的区别在于其对AI能力的深度依赖。一个完整的AI IDE工作流涉及多种类型的任务:
- 代码补全任务:用户输入几个字符后触发,需要在毫秒级返回结果
- 语义搜索任务:用户输入查询语句,需要在数秒内返回代码片段
- 代码分析任务:对整个项目进行静态分析,可能耗时数分钟
- 测试执行任务:运行单元测试、集成测试,耗时不定
- 索引构建任务:建立代码库的语义索引,后台运行,耗时最长
这些任务在资源需求、响应时间要求、优先级方面存在巨大差异。传统FIFO队列无法满足需求,我们需要一个智能的调度系统来协调这些任务。
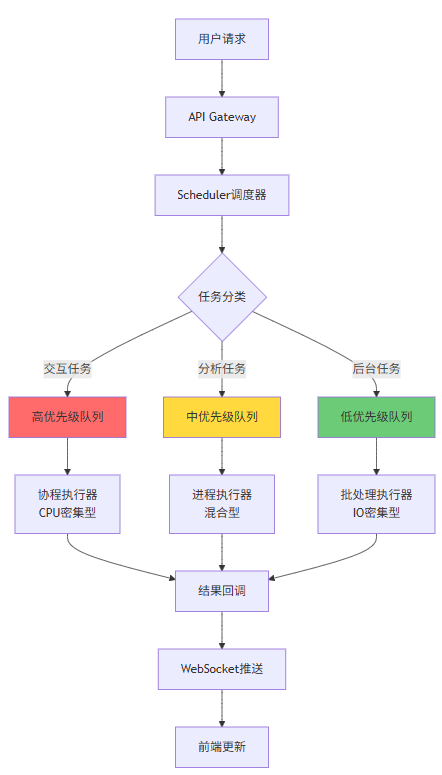
上图展示了Scheduler在AI IDE系统中的核心位置。从用户请求进入系统开始,Scheduler就扮演着决策者的角色:根据任务类型、优先级、资源需求将任务分发到不同的执行队列。
1.2 Scheduler与相关组件的关系
Scheduler并非孤立存在,它需要与多个系统组件协作:
组件 | 与Scheduler的关系 | 协作方式 |
|---|---|---|
消息队列 | 下游消费者 | 从队列获取任务,执行后回传结果 |
协程框架 | 执行引擎 | 利用asyncio实现高并发 |
资源池 | 资源管理者 | 从池中申请/释放CPU、Memory、GPU配额 |
监控告警 | 状态观察者 | 汇报任务积压、SLA违反情况 |
存储系统 | 结果持久化 | 将执行结果写入数据库 |
Scheduler的工作原理可以概括为:接收任务→评估优先级→申请资源→分发执行→监控状态→处理结果→释放资源。这个循环构成了AI IDE任务调度的核心逻辑。
1.3 本文的结构安排
本文将按以下结构展开:
- 任务模型:剖析Job、Task、Step的层级关系
- 优先级队列:多级优先级的实现机制
- 资源分配:CPU、Memory、GPU的配额管理
- 超时控制:软超时与硬超时的设计
- 失败重试:指数退避与最大重试次数
- 监控告警:任务积压与SLA预警
- 实践:实现一个支持协程的任务调度器
2 任务模型:Job、Task、Step的层级关系
本节为你提供的核心价值:建立正确的任务抽象模型,理解三层任务结构的职责划分,掌握从宏观任务到微观步骤的分解方法。
2.1 三层任务模型的设计理念
在AI IDE系统中,我们面临的任务复杂度差异巨大。一简单的代码补全可能只需要执行一个步骤,而一个完整的代码重构可能涉及数百个步骤。为了统一管理这些任务,我们设计了Job→Task→Step的三层模型。
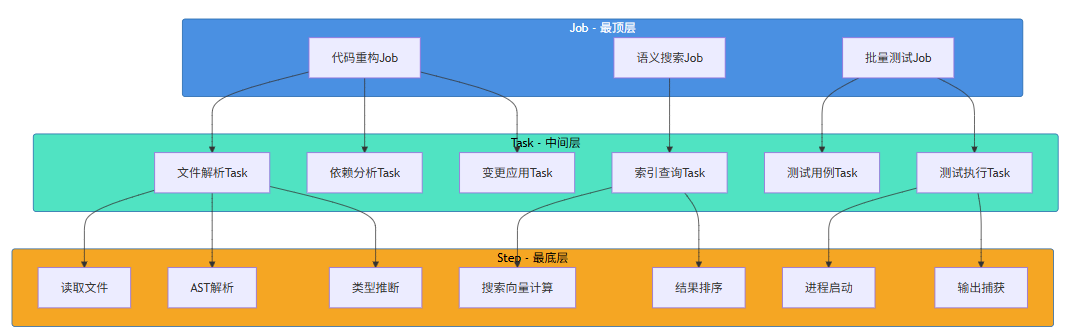
层级职责:
层级 | 粒度 | 生命周期 | 调度单位 | 失败策略 |
|---|---|---|---|---|
Job | 宏观用户任务 | 用户会话级别 | 独立调度 | 整体暂停/重试 |
Task | 子系统任务 | 分钟级别 | 协程/进程 | 单独重试 |
Step | 原子操作 | 秒级别 | 线程/协程 | 自动跳过/重试 |
2.2 Job层:用户视角的任务封装
Job是用户直接感知的任务单元。一个Job代表用户的一个完整意图,例如"分析这个项目的架构"或"为这个函数生成单元测试"。
from dataclasses import dataclass, field
from typing import List, Dict, Any, Optional, Callable
from enum import Enum, auto
from datetime import datetime
import uuid
class JobStatus(Enum):
"""Job生命周期状态"""
PENDING = auto() # 已创建,等待调度
RUNNING = auto() # 执行中
PAUSED = auto() # 暂停(用户中断或等待资源)
COMPLETED = auto() # 成功完成
FAILED = auto() # 失败(无法恢复)
CANCELLED = auto() # 用户取消
class JobPriority(Enum):
"""Job优先级枚举"""
CRITICAL = 0 # 代码补全等交互任务
HIGH = 1 # 实时分析
NORMAL = 2 # 标准任务
LOW = 3 # 后台任务
BATCH = 4 # 批量处理
@dataclass
class JobContext:
"""Job执行上下文,贯穿整个Job生命周期"""
user_id: str
session_id: str
workspace_id: str
metadata: Dict[str, Any] = field(default_factory=dict)
@dataclass
class Job:
"""
Job:用户视角的最高层任务抽象
代表一个完整的用户请求,如代码重构、语义搜索、批量测试等。
Job由多个Task组成,Task之间可能有依赖关系。
"""
job_type: str # Job类型标识
priority: JobPriority = JobPriority.NORMAL # 优先级
context: Optional[JobContext] = None # 执行上下文
# 内部状态
job_id: str = field(default_factory=lambda: str(uuid.uuid4()))
status: JobStatus = JobStatus.PENDING
created_at: datetime = field(default_factory=datetime.now)
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
# 任务组成
tasks: List['Task'] = field(default_factory=list)
# 进度跟踪
progress: float = 0.0 # 0.0 ~ 1.0
completed_tasks: int = 0
failed_tasks: int = 0
# 结果与错误
result: Optional[Dict[str, Any]] = None
error: Optional[str] = None
# 回调函数
on_progress: Optional[Callable[['Job'], None]] = None
on_complete: Optional[Callable[['Job'], None]] = None
on_failure: Optional[Callable[['Job', str], None]] = None
def add_task(self, task: 'Task') -> None:
"""向Job添加Task"""
task.job_id = self.job_id
self.tasks.append(task)
def update_progress(self) -> None:
"""更新Job进度"""
if self.tasks:
total = len(self.tasks)
self.completed_tasks = sum(1 for t in self.tasks if t.is_completed)
self.failed_tasks = sum(1 for t in self.tasks if t.is_failed)
self.progress = (self.completed_tasks + self.failed_tasks) / total
def cancel(self) -> None:
"""取消Job"""
self.status = JobStatus.CANCELLED
for task in self.tasks:
if task.status == TaskStatus.RUNNING:
task.cancel()
@property
def is_completed(self) -> bool:
return self.status == JobStatus.COMPLETED
@property
def is_failed(self) -> bool:
return self.status == JobStatus.FAILED2.3 Task层:并行执行的工作单元
Task是Job的子任务,代表一个可以独立调度的工作单元。Task与Task之间可能有依赖关系,形成DAG(有向无环图)结构。
from dataclasses import dataclass, field
from typing import List, Dict, Any, Optional, Callable, Set
from enum import Enum, auto
from datetime import datetime
import asyncio
class TaskStatus(Enum):
"""Task生命周期状态"""
PENDING = auto() # 等待依赖任务完成
READY = auto() # 依赖已满足,等待调度
RUNNING = auto() # 执行中
COMPLETED = auto() # 成功完成
FAILED = auto() # 执行失败
CANCELLED = auto() # 已取消
SKIPPED = auto() # 因依赖失败而跳过
class TaskType(Enum):
"""Task类型枚举"""
CPU_BOUND = auto() # CPU密集型(代码分析、编译)
IO_BOUND = auto() # IO密集型(文件读写、网络请求)
MIXED = auto() # 混合型
COROUTINE = auto() # 协程型(异步IO)
@dataclass
class ResourceRequirement:
"""Task资源需求描述"""
cpu_cores: float = 1.0 # 需要的CPU核心数
memory_mb: int = 256 # 需要的内存MB
gpu_required: bool = False # 是否需要GPU
gpu_memory_mb: int = 0 # GPU内存需求
max_execution_time: int = 300 # 最大执行时间(秒)
def can_fit(self, available_cpu: float, available_memory: int,
gpu_available: bool, available_gpu_memory: int) -> bool:
"""检查资源是否满足需求"""
if self.cpu_cores > available_cpu:
return False
if self.memory_mb > available_memory:
return False
if self.gpu_required:
if not gpu_available or self.gpu_memory_mb > available_gpu_memory:
return False
return True
@dataclass
class Task:
"""
Task:中间层的任务抽象
Task是Job的子任务,可以独立调度执行。
Task之间可以有依赖关系,形成DAG结构。
"""
task_type: str
task_name: str
task_type_enum: TaskType = TaskType.MIXED
# 依赖关系
dependencies: Set[str] = field(default_factory=set) # 依赖的task_id集合
dependent_tasks: Set[str] = field(default_factory=set) # 依赖此task的task_id集合
# 资源需求
resources: ResourceRequirement = field(default_factory=ResourceRequirement)
# 优先级(相对于Job内其他Task)
priority: int = 0 # 数值越小优先级越高
# 内部状态
task_id: str = field(default_factory=lambda: str(uuid.uuid4()))
job_id: Optional[str] = None
status: TaskStatus = TaskStatus.PENDING
# 时间戳
created_at: datetime = field(default_factory=datetime.now)
scheduled_at: Optional[datetime] = None
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
# 重试配置
max_retries: int = 3
retry_count: int = 0
retry_delay: float = 1.0 # 基础重试延迟(秒)
# 执行相关
handler: Optional[Callable] = None # 执行函数
args: tuple = field(default_factory=tuple)
kwargs: Dict[str, Any] = field(default_factory=dict)
# 结果
result: Optional[Any] = None
error: Optional[str] = None
# Step组成
steps: List['Step'] = field(default_factory=list)
def add_step(self, step: 'Step') -> None:
"""向Task添加Step"""
step.task_id = self.task_id
self.steps.append(step)
def add_dependency(self, task_id: str) -> None:
"""添加依赖"""
self.dependencies.add(task_id)
def remove_dependency(self, task_id: str) -> None:
"""移除依赖"""
self.dependencies.discard(task_id)
def is_ready(self) -> bool:
"""检查所有依赖是否已满足"""
return len(self.dependencies) == 0
def mark_completed(self, result: Any = None) -> None:
"""标记为完成"""
self.status = TaskStatus.COMPLETED
self.result = result
self.completed_at = datetime.now()
def mark_failed(self, error: str) -> None:
"""标记为失败"""
self.status = TaskStatus.FAILED
self.error = error
self.completed_at = datetime.now()
def should_retry(self) -> bool:
"""检查是否应该重试"""
return self.retry_count < self.max_retries
def increment_retry(self) -> None:
"""增加重试计数"""
self.retry_count += 1
def cancel(self) -> None:
"""取消Task"""
self.status = TaskStatus.CANCELLED
@property
def is_completed(self) -> bool:
return self.status == TaskStatus.COMPLETED
@property
def is_failed(self) -> bool:
return self.status == TaskStatus.FAILED
@property
def execution_time(self) -> Optional[float]:
"""获取执行时间(秒)"""
if self.started_at and self.completed_at:
return (self.completed_at - self.started_at).total_seconds()
return None2.4 Step层:原子操作的不可再分单元
Step是任务调度的最小单位,代表一个不可中断的原子操作。Step应该是足够小以至于可以快速完成,同时又足够大以至于值得独立调度。
from dataclasses import dataclass, field
from typing import Any, Optional, Callable, Dict
from enum import Enum, auto
from datetime import datetime
import asyncio
class StepStatus(Enum):
"""Step生命周期状态"""
PENDING = auto() # 等待执行
RUNNING = auto() # 执行中
COMPLETED = auto() # 成功完成
FAILED = auto() # 执行失败
SKIPPED = auto() # 跳过
class StepType(Enum):
"""Step类型"""
SYNC = auto() # 同步函数
ASYNC = auto() # 异步协程
PROCESS = auto() # 独立进程
THREAD = auto() # 独立线程
@dataclass
class Step:
"""
Step:最底层的原子操作单元
Step是不可再分的执行单元,可以是:
- 同步函数调用
- 异步协程调用
- 独立进程执行
- 独立线程执行
"""
step_name: str
step_type: StepType = StepType.SYNC
# 内部状态
step_id: str = field(default_factory=lambda: str(uuid.uuid4()))
task_id: Optional[str] = None
status: StepStatus = StepStatus.PENDING
# 执行配置
handler: Optional[Callable] = None # 执行函数
args: tuple = field(default_factory=tuple)
kwargs: Dict[str, Any] = field(default_factory=dict)
# 时间戳
created_at: datetime = field(default_factory=datetime.now)
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
# 结果
result: Optional[Any] = None
error: Optional[str] = None
# 超时控制
timeout: Optional[float] = None # 超时时间(秒),None表示无超时
def set_handler(self, handler: Callable, *args, **kwargs) -> 'Step':
"""设置执行函数"""
self.handler = handler
self.args = args
self.kwargs = kwargs
if asyncio.iscoroutinefunction(handler):
self.step_type = StepType.ASYNC
return self
async def execute_async(self) -> Any:
"""异步执行Step"""
if self.status == StepStatus.COMPLETED:
return self.result
if self.status == StepStatus.FAILED:
raise RuntimeError(f"Step {self.step_id} already failed: {self.error}")
self.status = StepStatus.RUNNING
self.started_at = datetime.now()
try:
if self.step_type == StepType.ASYNC:
if self.timeout:
self.result = await asyncio.wait_for(
self.handler(*self.args, **self.kwargs),
timeout=self.timeout
)
else:
self.result = await self.handler(*self.args, **self.kwargs)
else:
# 对于同步函数,在线程池中执行
loop = asyncio.get_event_loop()
self.result = await loop.run_in_executor(
None,
lambda: self.handler(*self.args, **self.kwargs)
)
self.status = StepStatus.COMPLETED
self.completed_at = datetime.now()
return self.result
except asyncio.TimeoutError:
self.status = StepStatus.FAILED
self.error = f"Step execution timeout after {self.timeout}s"
self.completed_at = datetime.now()
raise
except Exception as e:
self.status = StepStatus.FAILED
self.error = str(e)
self.completed_at = datetime.now()
raise
def execute_sync(self) -> Any:
"""同步执行Step"""
if self.status == StepStatus.COMPLETED:
return self.result
if self.status == StepStatus.FAILED:
raise RuntimeError(f"Step {self.step_id} already failed: {self.error}")
self.status = StepStatus.RUNNING
self.started_at = datetime.now()
try:
self.result = self.handler(*self.args, **self.kwargs)
self.status = StepStatus.COMPLETED
self.completed_at = datetime.now()
return self.result
except Exception as e:
self.status = StepStatus.FAILED
self.error = str(e)
self.completed_at = datetime.now()
raise
def skip(self, reason: str = "") -> None:
"""跳过Step"""
self.status = StepStatus.SKIPPED
self.error = reason
self.completed_at = datetime.now()
@property
def execution_time(self) -> Optional[float]:
"""获取执行时间(秒)"""
if self.started_at and self.completed_at:
return (self.completed_at - self.started_at).total_seconds()
return None2.5 层级关系的代码示例
# 示例:构建一个代码重构Job
def demo_job_task_step():
"""演示Job-Task-Step三层模型的使用"""
# 1. 创建Job
job = Job(
job_type="refactoring",
priority=JobPriority.HIGH,
context=JobContext(
user_id="user_123",
session_id="session_abc",
workspace_id="workspace_xyz"
)
)
# 2. 创建Task
task_parse = Task(
task_type="parse",
task_name="解析源文件",
task_type_enum=TaskType.CPU_BOUND,
resources=ResourceRequirement(cpu_cores=2, memory_mb=512)
)
task_analyze = Task(
task_type="analyze",
task_name="依赖分析",
task_type_enum=TaskType.CPU_BOUND,
resources=ResourceRequirement(cpu_cores=1, memory_mb=256)
)
task_analyze.add_dependency(task_parse.task_id) # 依赖解析任务
task_apply = Task(
task_type="apply",
task_name="应用变更",
task_type_enum=TaskType.IO_BOUND,
resources=ResourceRequirement(cpu_cores=1, memory_mb=128)
)
task_apply.add_dependency(task_analyze.task_id) # 依赖分析任务
# 3. 向Task添加Step
step_read = Step(step_name="读取文件")
step_read.set_handler(lambda: "file content")
step_ast = Step(step_name="AST解析")
step_ast.set_handler(lambda: {"ast": "root"})
step_deps = Step(step_name="计算依赖")
step_deps.set_handler(lambda: {"deps": ["dep1", "dep2"]})
task_parse.add_step(step_read)
task_parse.add_step(step_ast)
task_analyze.add_step(step_deps)
# 4. 添加Task到Job
job.add_task(task_parse)
job.add_task(task_analyze)
job.add_task(task_apply)
# 5. 输出层级结构
print(f"Job: {job.job_id}")
print(f" Tasks: {len(job.tasks)}")
for task in job.tasks:
print(f" Task: {task.task_name} (depends on: {task.dependencies})")
print(f" Steps: {len(task.steps)}")
for step in task.steps:
print(f" - {step.step_name}")
return job
if __name__ == "__main__":
demo_job_task_step()关键结论:三层任务模型通过Job提供用户视角的完整视图,Task实现并行执行的工作单元,Step确保原子操作的可靠性。这种设计使得任务调度可以灵活地在不同层级进行,同时保持了系统的可维护性和可扩展性。
3 优先级队列:多级优先级的实现
本节为你提供的核心价值:掌握基于堆结构的优先级队列实现,理解多级反馈队列如何平衡响应时间和吞吐量,以及如何避免优先级反转和饥饿问题。
3.1 优先级队列的核心设计
在AI IDE系统中,不同类型的任务有不同的紧急程度。代码补全需要在毫秒级响应,而代码索引可以在后台慢慢执行。优先级队列正是为了解决这一矛盾而设计的。
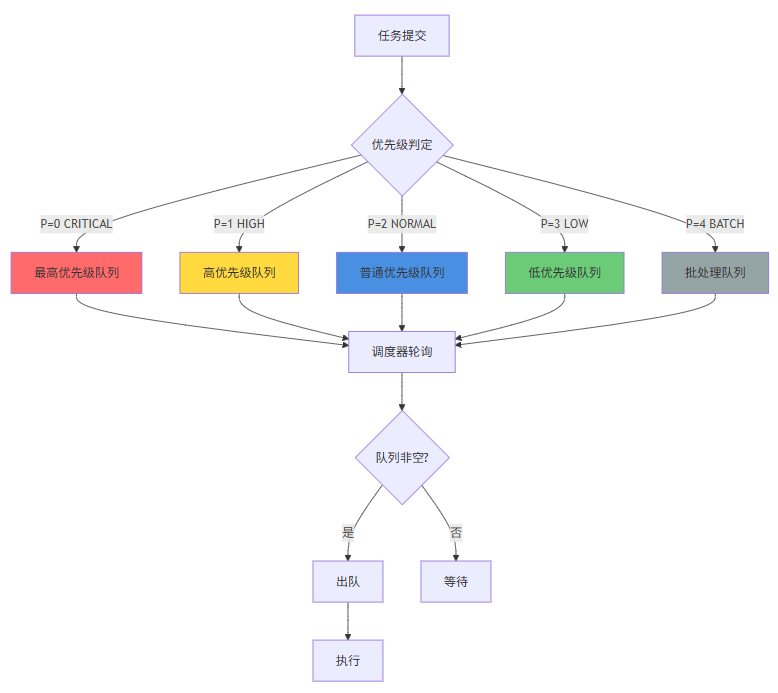
3.2 基于堆的优先级队列实现
Python的heapq模块提供了堆数据结构,但直接使用有局限性:无法高效地修改优先级、无法O(1)查找特定任务。我们需要构建一个更完善的优先级队列。
import heapq
from dataclasses import dataclass, field
from typing import Any, Optional, Dict, List
from datetime import datetime
from enum import Enum
import time
import threading
class TaskPriority(Enum):
"""任务优先级枚举,数值越小优先级越高"""
CRITICAL = 0 # 最高优先级:代码补全等交互任务
HIGH = 1 # 高优先级:实时分析
NORMAL = 2 # 普通优先级:标准任务
LOW = 3 # 低优先级:后台任务
BATCH = 4 # 最低优先级:批量处理
@classmethod
def from_int(cls, value: int) -> 'TaskPriority':
"""从整数转换为优先级枚举"""
if value < 0:
return cls.CRITICAL
if value > cls.BATCH.value:
return cls.BATCH
return cls(value)
@dataclass(order=True)
class PriorityQueueEntry:
"""
优先级队列条目
支持多维排序:
1. 优先级(primary key)
2. 创建时间(secondary key,同优先级FIFO)
3. 任务ID(tertiary key,保证唯一性)
"""
priority: int = field(compare=True)
timestamp: float = field(compare=True)
task_id: str = field(compare=True)
# 实际数据(不参与比较)
data: Any = field(compare=False, default=None)
metadata: Dict[str, Any] = field(compare=False, default_factory=dict)
class SchedulerPriorityQueue:
"""
高性能优先级队列
特性:
- 基于最小堆实现,插入和删除均为O(log n)
- 支持O(1)任务查找和优先级修改
- 线程安全
- 支持批量操作
"""
def __init__(self):
self._heap: List[PriorityQueueEntry] = []
self._entry_map: Dict[str, PriorityQueueEntry] = {} # task_id -> entry
self._removed: set = set() # 标记已删除的task_id
self._lock = threading.RLock()
self._counter = 0 # 用于保证相同优先级的FIFO顺序
def add(self, task_id: str, data: Any, priority: int = 2,
metadata: Optional[Dict[str, Any]] = None) -> None:
"""
添加任务到优先级队列
Args:
task_id: 任务唯一标识
data: 任务数据
priority: 优先级 (0-4)
metadata: 附加元数据
"""
with self._lock:
# 如果任务已存在,先移除
if task_id in self._entry_map:
self._removed.add(task_id)
# 创建新条目
entry = PriorityQueueEntry(
priority=priority,
timestamp=time.time() + self._counter * 1e-6, # 微妙级精度保证FIFO
task_id=task_id,
data=data,
metadata=metadata or {}
)
self._entry_map[task_id] = entry
heapq.heappush(self._heap, entry)
self._counter += 1
def remove(self, task_id: str) -> bool:
"""
从队列中移除任务
Args:
task_id: 任务ID
Returns:
是否成功移除
"""
with self._lock:
if task_id not in self._entry_map:
return False
self._removed.add(task_id)
del self._entry_map[task_id]
return True
def pop(self) -> Optional[tuple]:
"""
弹出最高优先级的任务
Returns:
(task_id, data, metadata) or None if queue is empty
"""
with self._lock:
while self._heap:
entry = heapq.heappop(self._heap)
# 跳过已标记删除的条目
if entry.task_id in self._removed:
self._removed.discard(entry.task_id)
continue
# 从映射中移除
if entry.task_id in self._entry_map:
del self._entry_map[entry.task_id]
return entry.task_id, entry.data, entry.metadata
return None
def peek(self) -> Optional[tuple]:
"""
查看最高优先级任务但不弹出
"""
with self._lock:
# 复制堆以避免修改
heap_copy = self._heap.copy()
while heap_copy:
entry = heap_copy[0]
if entry.task_id in self._removed:
heapq.heappop(heap_copy)
continue
return entry.task_id, entry.data, entry.metadata
return None
def update_priority(self, task_id: str, new_priority: int) -> bool:
"""
更新任务优先级
Args:
task_id: 任务ID
new_priority: 新优先级
Returns:
是否成功更新
"""
with self._lock:
if task_id not in self._entry_map:
return False
old_entry = self._entry_map[task_id]
# 标记旧条目为已删除
self._removed.add(task_id)
# 创建新条目
new_entry = PriorityQueueEntry(
priority=new_priority,
timestamp=time.time() + self._counter * 1e-6,
task_id=task_id,
data=old_entry.data,
metadata=old_entry.metadata
)
self._entry_map[task_id] = new_entry
heapq.heappush(self._heap, new_entry)
self._counter += 1
return True
def get_task_info(self, task_id: str) -> Optional[Dict[str, Any]]:
"""
获取任务信息
Returns:
任务信息字典,不存在则返回None
"""
with self._lock:
if task_id not in self._entry_map:
return None
entry = self._entry_map[task_id]
return {
"task_id": entry.task_id,
"priority": entry.priority,
"timestamp": entry.timestamp,
"metadata": entry.metadata
}
def __len__(self) -> int:
"""返回队列中的任务数量"""
with self._lock:
return len(self._entry_map)
def is_empty(self) -> bool:
"""判断队列是否为空"""
return len(self) == 0
def get_by_priority(self, priority: int) -> List[tuple]:
"""
获取指定优先级的所有任务
Returns:
[(task_id, data, metadata), ...]
"""
with self._lock:
result = []
for task_id, entry in self._entry_map.items():
if entry.priority == priority:
result.append((task_id, entry.data, entry.metadata))
return result
def get_priority_stats(self) -> Dict[int, int]:
"""
获取各优先级的任务统计
Returns:
{priority: count}
"""
with self._lock:
stats = {}
for entry in self._entry_map.values():
stats[entry.priority] = stats.get(entry.priority, 0) + 1
return stats3.3 多级反馈队列:公平与效率的平衡
纯优先级队列可能导致低优先级任务饥饿(starvation)。当高优先级任务持续到达时,低优先级任务可能永远得不到执行。多级反馈队列(Multi-Level Feedback Queue, MLFQ)通过动态调整优先级来解决这个问题。
from collections import deque
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Any
import time
import threading
@dataclass
class MLFQTask:
"""多级反馈队列任务"""
task_id: str
data: Any
priority: int = 2 # 初始优先级
arrival_time: float = field(default_factory=time.time)
last_run_time: float = field(default_factory=time.time)
cpu_burst: float = 0.0 # 累计CPU时间
wait_time: float = 0.0 # 累计等待时间
metadata: Dict[str, Any] = field(default_factory=dict)
class MultiLevelFeedbackQueue:
"""
多级反馈队列调度器
核心思想:
1. 新任务从高优先级开始
2. 如果任务用完时间片,降低优先级
3. 如果任务主动放弃CPU(如等待IO),保持或提升优先级
4. 低优先级任务获得CPU时,如果higher有任务则立即抢占
优先级层数:5层 (0-4)
时间片配置:优先级越高,时间片越短
"""
# 时间片配置(毫秒)
TIME_QUANTUMS = {
0: 10, # CRITICAL: 10ms
1: 20, # HIGH: 20ms
2: 50, # NORMAL: 50ms
3: 100, # LOW: 100ms
4: 200 # BATCH: 200ms
}
# 优先级提升阈值(等待时间超过此值则提升优先级)
AGE_THRESHOLD = 5.0 # 秒
# 降级阈值(连续用完时间片次数)
DEMOTION_THRESHOLD = 3
def __init__(self):
# 5层队列
self._queues: Dict[int, deque] = {
i: deque() for i in range(5)
}
self._task_info: Dict[str, MLFQTask] = {}
self._demotion_count: Dict[str, int] = {} # 连续用完时间片计数
self._lock = threading.RLock()
def add(self, task_id: str, data: Any,
initial_priority: int = 2,
metadata: Optional[Dict[str, Any]] = None) -> None:
"""
添加任务到多级反馈队列
Args:
task_id: 任务ID
data: 任务数据
initial_priority: 初始优先级 (0-4)
metadata: 附加元数据
"""
with self._lock:
task = MLFQTask(
task_id=task_id,
data=data,
priority=initial_priority,
metadata=metadata or {}
)
self._task_info[task_id] = task
self._demotion_count[task_id] = 0
self._queues[initial_priority].append(task_id)
def pop(self) -> Optional[tuple]:
"""
弹出下一个要执行的任务
Returns:
(task_id, data, time_quantum) or None
"""
with self._lock:
# 从高到低查找非空队列
for priority in range(5):
queue = self._queues[priority]
if not queue:
continue
task_id = queue.popleft()
task = self._task_info.get(task_id)
if not task:
continue
# 检查是否需要提升优先级( aging )
if self._should_promote(task):
self._promote_priority(task)
continue
# 更新等待时间
task.wait_time += time.time() - task.last_run_time
# 返回任务信息
time_quantum = self.TIME_QUANTUMS[task.priority]
return task_id, task.data, time_quantum
return None
def _should_promote(self, task: MLFQTask) -> bool:
"""检查是否应该提升优先级"""
return task.wait_time > self.AGE_THRESHOLD
def _promote_priority(self, task: MLFQTask) -> None:
"""提升任务优先级"""
if task.priority > 0:
new_priority = task.priority - 1
task.priority = new_priority
task.wait_time = 0.0 # 重置等待时间
self._queues[new_priority].append(task.task_id)
def record_completion(self, task_id: str, actual_cpu_time: float) -> None:
"""
记录任务完成信息,用于调整调度策略
Args:
task_id: 任务ID
actual_cpu_time: 实际CPU执行时间
"""
with self._lock:
task = self._task_info.get(task_id)
if task:
task.cpu_burst = actual_cpu_time
def record_time_slice_used(self, task_id: str, fully_used: bool) -> None:
"""
记录时间片使用情况
Args:
task_id: 任务ID
fully_used: 是否完全使用了分配的时间片
"""
with self._lock:
if task_id not in self._task_info:
return
if fully_used:
# 时间片用完,降低优先级
self._demotion_count[task_id] = self._demotion_count.get(task_id, 0) + 1
task = self._task_info[task_id]
if self._demotion_count[task_id] >= self.DEMOTION_THRESHOLD:
if task.priority < 4:
self._demote_priority(task)
self._demotion_count[task_id] = 0
else:
# 时间片未用完(主动放弃CPU),重置计数
self._demotion_count[task_id] = 0
def _demote_priority(self, task: MLFQTask) -> None:
"""降低任务优先级"""
if task.priority < 4:
task.priority += 1
self._demotion_count[task.task_id] = 0
self._queues[task.priority].append(task.task_id)
def requeue(self, task_id: str) -> None:
"""
重新入队任务(任务未完成,需要继续执行)
Args:
task_id: 任务ID
"""
with self._lock:
task = self._task_info.get(task_id)
if task:
task.last_run_time = time.time()
self._queues[task.priority].append(task_id)
def remove(self, task_id: str) -> bool:
"""
从队列中移除任务
Returns:
是否成功移除
"""
with self._lock:
if task_id not in self._task_info:
return False
task = self._task_info[task_id]
# 从对应优先级的队列中移除
queue = self._queues[task.priority]
if task_id in queue:
queue.remove(task_id)
del self._task_info[task_id]
self._demotion_count.pop(task_id, None)
return True
def get_queue_lengths(self) -> Dict[int, int]:
"""
获取各队列长度
Returns:
{priority: length}
"""
with self._lock:
return {p: len(q) for p, q in self._queues.items()}
def get_task_priority(self, task_id: str) -> Optional[int]:
"""获取任务当前优先级"""
with self._lock:
task = self._task_info.get(task_id)
return task.priority if task else None3.4 优先级队列使用示例
import time
def demo_priority_queue():
"""演示优先级队列在AI IDE任务调度中的应用"""
# 创建优先级队列
queue = SchedulerPriorityQueue()
# 模拟AI IDE中的任务
tasks = [
# (task_id, data, priority, metadata)
("completion_001", {"type": "code_completion", "cursor": 100}, 0, {"user": "alice"}),
("analysis_001", {"type": "code_analysis", "file": "main.py"}, 2, {"user": "alice"}),
("index_001", {"type": "semantic_index", "project": "/repo"}, 4, {"user": "bob"}),
("completion_002", {"type": "code_completion", "cursor": 200}, 0, {"user": "bob"}),
("search_001", {"type": "semantic_search", "query": "find auth"}, 1, {"user": "alice"}),
("analysis_002", {"type": "code_analysis", "file": "utils.py"}, 2, {"user": "carol"}),
("completion_003", {"type": "code_completion", "cursor": 300}, 0, {"user": "carol"}),
("test_001", {"type": "test_execution", "suite": "unit"}, 3, {"user": "david"}),
]
# 添加所有任务
print("=" * 60)
print("添加任务到优先级队列")
print("=" * 60)
for task_id, data, priority, metadata in tasks:
queue.add(task_id, data, priority, metadata)
priority_name = ["CRITICAL", "HIGH", "NORMAL", "LOW", "BATCH"][priority]
print(f"[{priority_name}] {task_id}: {data['type']}")
# 打印优先级统计
print("\n优先级统计:")
stats = queue.get_priority_stats()
for p in sorted(stats.keys()):
name = ["CRITICAL", "HIGH", "NORMAL", "LOW", "BATCH"][p]
print(f" {name}: {stats[p]} 个任务")
# 按优先级顺序消费
print("\n" + "=" * 60)
print("按优先级顺序消费任务")
print("=" * 60)
consumed = 0
while not queue.is_empty():
result = queue.pop()
if result:
task_id, data, metadata = result
consumed += 1
print(f"[消费 #{consumed}] {task_id}: {data}")
time.sleep(0.01) # 模拟处理时间
print(f"\n共消费 {consumed} 个任务")
def demo_mlfq():
"""演示多级反馈队列"""
print("\n" + "=" * 60)
print("多级反馈队列演示")
print("=" * 60)
mlfq = MultiLevelFeedbackQueue()
# 模拟任务到达
test_tasks = [
("cpu_task_1", "CPU密集型任务", 2),
("io_task_1", "IO密集型任务(频繁等待)", 2),
("interactive_1", "交互任务", 0),
]
for task_id, desc, priority in test_tasks:
mlfq.add(task_id, {"description": desc}, priority)
print(f"添加任务: {task_id} (初始优先级: {priority})")
# 模拟调度
print("\n调度过程:")
for i in range(10):
result = mlfq.pop()
if result:
task_id, data, quantum = result
print(f" 轮次 {i+1}: 执行 {task_id}, 时间片: {quantum}ms")
# 模拟任务行为
if "IO" in data["description"]:
# IO密集型任务会很快放弃CPU,保持优先级
mlfq.record_time_slice_used(task_id, fully_used=False)
mlfq.requeue(task_id)
else:
# CPU密集型任务会用完时间片
mlfq.record_time_slice_used(task_id, fully_used=True)
if i < 5: # 假设任务需要多个时间片
mlfq.requeue(task_id)
else:
print(f" 轮次 {i+1}: 队列为空")
break
# 打印队列状态
print("\n最终队列状态:")
lengths = mlfq.get_queue_lengths()
for p, length in lengths.items():
if length > 0:
print(f" 优先级 {p}: {length} 个任务")
if __name__ == "__main__":
demo_priority_queue()
demo_mlfq()关键结论:优先级队列通过多级优先级实现任务的差异化服务,多级反馈队列通过动态调整机制平衡响应时间和吞吐量。在实际系统中,可以根据任务特性选择合适的队列实现:高优先级交互任务使用纯优先级队列确保最低延迟,后台批处理任务使用多级反馈队列避免饥饿。
4 资源分配:CPU、Memory、GPU的配额管理
本节为你提供的核心价值:掌握资源池化管理的核心思想,理解CPU、Memory、GPU的配额分配策略,以及如何实现资源的动态调整和隔离。
4.1 资源分配的系统架构
在AI IDE系统中,资源(CPU、内存、GPU)是稀缺资源。多个任务同时竞争这些资源,如果管理不当,会导致系统不稳定、响应延迟、甚至服务崩溃。
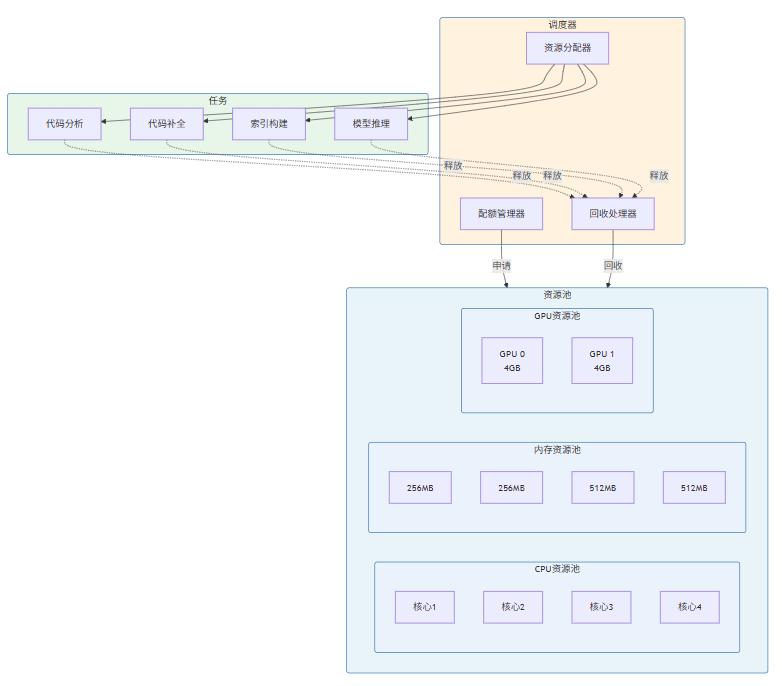
4.2 资源池管理器的实现
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Set, Any
from enum import Enum
import threading
import time
from collections import defaultdict
class ResourceType(Enum):
"""资源类型"""
CPU = "cpu"
MEMORY = "memory"
GPU = "gpu"
GPU_MEMORY = "gpu_memory"
@dataclass
class ResourceQuota:
"""资源配额描述"""
cpu_cores: float = 0.0 # CPU核心数(支持小数)
memory_mb: int = 0 # 内存MB
gpu_count: int = 0 # GPU数量
gpu_memory_mb: int = 0 # GPU内存MB
def can_accommodate(self, other: 'ResourceQuota') -> bool:
"""检查是否能容纳另一个配额的需求"""
return (self.cpu_cores >= other.cpu_cores and
self.memory_mb >= other.memory_mb and
self.gpu_count >= other.gpu_count and
self.gpu_memory_mb >= other.gpu_memory_mb)
def __add__(self, other: 'ResourceQuota') -> 'ResourceQuota':
"""合并配额"""
return ResourceQuota(
cpu_cores=self.cpu_cores + other.cpu_cores,
memory_mb=self.memory_mb + other.memory_mb,
gpu_count=self.gpu_count + other.gpu_count,
gpu_memory_mb=self.gpu_memory_mb + other.gpu_memory_mb
)
def __sub__(self, other: 'ResourceQuota') -> 'ResourceQuota':
"""减去配额"""
return ResourceQuota(
cpu_cores=max(0, self.cpu_cores - other.cpu_cores),
memory_mb=max(0, self.memory_mb - other.memory_mb),
gpu_count=max(0, self.gpu_count - other.gpu_count),
gpu_memory_mb=max(0, self.gpu_memory_mb - other.gpu_memory_mb)
)
@dataclass
class ResourceAllocation:
"""资源分配记录"""
task_id: str
quota: ResourceQuota
allocated_at: float = field(default_factory=time.time)
last_heartbeat: float = field(default_factory=time.time)
metadata: Dict[str, Any] = field(default_factory=dict)
class ResourcePool:
"""
统一资源池管理器
管理CPU、内存、GPU三种资源的分配和回收。
支持资源预留、配额限制、资源监控。
"""
def __init__(self,
total_cpu_cores: float = 8.0,
total_memory_mb: int = 16384,
total_gpu_count: int = 2,
total_gpu_memory_mb: int = 8192):
"""
初始化资源池
Args:
total_cpu_cores: 总CPU核心数
total_memory_mb: 总内存MB
total_gpu_count: 总GPU数量
total_gpu_memory_mb: 总GPU内存MB
"""
# 总量
self._total_quota = ResourceQuota(
cpu_cores=total_cpu_cores,
memory_mb=total_memory_mb,
gpu_count=total_gpu_count,
gpu_memory_mb=total_gpu_memory_mb
)
# 可用资源
self._available_quota = ResourceQuota(
cpu_cores=total_cpu_cores,
memory_mb=total_memory_mb,
gpu_count=total_gpu_count,
gpu_memory_mb=total_gpu_memory_mb
)
# 预留资源(保证最低可用)
self._reserved_quota = ResourceQuota()
# 当前分配记录
self._allocations: Dict[str, ResourceAllocation] = {}
# 锁
self._lock = threading.RLock()
# 资源监控回调
self._monitors: List[callable] = []
def acquire(self, task_id: str, quota: ResourceQuota,
timeout: float = 30.0, metadata: Optional[Dict[str, Any]] = None) -> bool:
"""
申请资源
Args:
task_id: 任务ID
quota: 需要的资源配额
timeout: 等待超时时间(秒)
metadata: 附加元数据
Returns:
是否成功获取资源
"""
start_time = time.time()
while True:
with self._lock:
# 检查是否有足够资源
effective_available = self._available_quota - self._reserved_quota
if effective_available.can_accommodate(quota):
# 分配资源
self._allocations[task_id] = ResourceAllocation(
task_id=task_id,
quota=quota,
metadata=metadata or {}
)
self._available_quota = self._available_quota - quota
self._notify_monitors()
return True
# 检查是否超时
if time.time() - start_time >= timeout:
return False
# 等待后重试
time.sleep(0.1)
def release(self, task_id: str) -> bool:
"""
释放资源
Args:
task_id: 任务ID
Returns:
是否成功释放
"""
with self._lock:
if task_id not in self._allocations:
return False
allocation = self._allocations[task_id]
self._available_quota = self._available_quota + allocation.quota
del self._allocations[task_id]
self._notify_monitors()
return True
def update_heartbeat(self, task_id: str) -> bool:
"""
更新任务心跳
Args:
task_id: 任务ID
Returns:
是否成功更新
"""
with self._lock:
if task_id not in self._allocations:
return False
self._allocations[task_id].last_heartbeat = time.time()
return True
def get_allocation(self, task_id: str) -> Optional[ResourceAllocation]:
"""获取任务的分配记录"""
with self._lock:
return self._allocations.get(task_id)
def get_available_quota(self) -> ResourceQuota:
"""获取当前可用配额"""
with self._lock:
return self._available_quota
def get_effective_available_quota(self) -> ResourceQuota:
"""获取扣除预留后的有效可用配额"""
with self._lock:
return self._available_quota - self._reserved_quota
def set_reserved_quota(self, quota: ResourceQuota) -> None:
"""
设置预留配额
Args:
quota: 预留配额
"""
with self._lock:
if quota.can_accommodate(self._total_quota - self._total_quota):
self._reserved_quota = quota
def can_accommodate(self, quota: ResourceQuota) -> bool:
"""检查当前是否能容纳指定的配额需求"""
with self._lock:
effective_available = self._available_quota - self._reserved_quota
return effective_available.can_accommodate(quota)
def get_allocation_stats(self) -> Dict[str, Any]:
"""获取分配统计"""
with self._lock:
total_allocated = ResourceQuota()
for allocation in self._allocations.values():
total_allocated = total_allocated + allocation.quota
return {
"total_quota": {
"cpu_cores": self._total_quota.cpu_cores,
"memory_mb": self._total_quota.memory_mb,
"gpu_count": self._total_quota.gpu_count,
"gpu_memory_mb": self._total_quota.gpu_memory_mb
},
"available_quota": {
"cpu_cores": self._available_quota.cpu_cores,
"memory_mb": self._available_quota.memory_mb,
"gpu_count": self._available_quota.gpu_count,
"gpu_memory_mb": self._available_quota.gpu_memory_mb
},
"allocated_quota": {
"cpu_cores": total_allocated.cpu_cores,
"memory_mb": total_allocated.memory_mb,
"gpu_count": total_allocated.gpu_count,
"gpu_memory_mb": total_allocated.gpu_memory_mb
},
"allocation_count": len(self._allocations)
}
def register_monitor(self, callback: callable) -> None:
"""注册资源监控回调"""
self._monitors.append(callback)
def _notify_monitors(self) -> None:
"""通知所有监控回调"""
stats = self.get_allocation_stats()
for monitor in self._monitors:
try:
monitor(stats)
except Exception:
pass # 忽略监控回调中的异常
def force_release_stale_allocations(self, max_idle_time: float = 300.0) -> List[str]:
"""
强制释放长时间无心跳的分配
Args:
max_idle_time: 最大空闲时间(秒)
Returns:
被强制释放的任务ID列表
"""
with self._lock:
current_time = time.time()
stale_tasks = []
for task_id, allocation in list(self._allocations.items()):
if current_time - allocation.last_heartbeat > max_idle_time:
stale_tasks.append(task_id)
for task_id in stale_tasks:
self.release(task_id)
return stale_tasks4.3 资源分配的策略模式
不同的任务类型需要不同的资源分配策略:
策略 | 适用场景 | 核心思想 |
|---|---|---|
FIFO | 公平调度 | 先来先服务,不考虑任务特性 |
Priority | 差异化服务 | 高优先级任务优先获得资源 |
Guaranteed | 关键任务 | 为任务预留保证可用的资源 |
Best-Effort | 后台任务 | 利用空闲资源运行 |
Shared | 弹性任务 | 多个任务共享配额 |
from abc import ABC, abstractmethod
from typing import Optional
class AllocationStrategy(ABC):
"""资源分配策略抽象基类"""
@abstractmethod
def select_tasks(self,
pending_tasks: List[Task],
available_quota: ResourceQuota) -> List[Task]:
"""
从待调度任务中选择可执行的任务
Args:
pending_tasks: 待调度任务列表
available_quota: 当前可用资源
Returns:
可以执行的任务列表
"""
pass
class FIFOStrategy(AllocationStrategy):
"""FIFO策略:按到达顺序调度"""
def select_tasks(self,
pending_tasks: List[Task],
available_quota: ResourceQuota) -> List[Task]:
selected = []
remaining_quota = available_quota
for task in sorted(pending_tasks, key=lambda t: t.created_at):
if remaining_quota.can_accommodate(task.resources):
selected.append(task)
remaining_quota = remaining_quota - task.resources
return selected
class PriorityStrategy(AllocationStrategy):
"""优先级策略:高优先级任务优先"""
def select_tasks(self,
pending_tasks: List[Task],
available_quota: ResourceQuota) -> List[Task]:
selected = []
remaining_quota = available_quota
# 按优先级排序(priority数值越小越高)
for task in sorted(pending_tasks, key=lambda t: t.priority):
if remaining_quota.can_accommodate(task.resources):
selected.append(task)
remaining_quota = remaining_quota - task.resources
return selected
class GuaranteedStrategy(AllocationStrategy):
"""保证策略:为任务预留保证配额"""
def __init__(self, guaranteed_quotas: Dict[str, ResourceQuota]):
"""
Args:
guaranteed_quotas: task_type -> 保障配额
"""
self._guaranteed_quotas = guaranteed_quotas
def select_tasks(self,
pending_tasks: List[Task],
available_quota: ResourceQuota) -> List[Task]:
selected = []
remaining_quota = available_quota
# 第一阶段:处理有保障配额的任务
guaranteed_tasks = [t for t in pending_tasks
if t.task_type in self._guaranteed_quotas]
for task in sorted(guaranteed_tasks, key=lambda t: t.priority):
guaranteed = self._guaranteed_quotas[task.task_type]
if remaining_quota.can_accommodate(guaranteed):
selected.append(task)
remaining_quota = remaining_quota - guaranteed
# 第二阶段:处理无保障配额的任务
non_guaranteed_tasks = [t for t in pending_tasks
if t.task_type not in self._guaranteed_quotas]
for task in sorted(non_guaranteed_tasks, key=lambda t: t.priority):
if remaining_quota.can_accommodate(task.resources):
selected.append(task)
remaining_quota = remaining_quota - task.resources
return selected
class BestEffortStrategy(AllocationStrategy):
"""尽力而为策略:只在有足够资源时才执行"""
def __init__(self, min_resource_threshold: float = 0.2):
"""
Args:
min_resource_threshold: 最低资源阈值(比例)
"""
self._threshold = min_resource_threshold
def select_tasks(self,
pending_tasks: List[Task],
available_quota: ResourceQuota) -> List[Task]:
# 只选择资源充裕度超过阈值的高优先级任务
selected = []
for task in sorted(pending_tasks, key=lambda t: t.priority):
# 检查资源是否充裕(超过阈值的部分才使用)
if (available_quota.cpu_cores >= task.resources.cpu_cores * (1 + self._threshold) and
available_quota.memory_mb >= task.resources.memory_mb * (1 + self._threshold)):
selected.append(task)
break # 尽力而为策略每次只执行一个高优先级任务
return selected关键结论:资源分配的核心矛盾是资源有限性与需求无限性。通过资源池化实现资源的统一管理,通过策略模式实现分配逻辑的灵活切换。在实际系统中,通常组合使用多种策略:关键任务使用Guaranteed策略,交互任务使用Priority策略,批处理任务使用Best-Effort策略。
5 超时控制:软超时与硬超时
本节为你提供的核心价值:理解软超时和硬超时的设计理念,掌握超时控制的实现机制,以及如何通过超时机制提升系统韧性。
5.1 超时控制的设计理念
超时控制是任务调度系统中不可或缺的组成部分。在AI IDE场景中,超时控制尤为重要:
- 防止资源泄漏:任务挂起时占用资源,超时后自动释放
- 保证系统响应:避免单任务阻塞导致系统不可用
- 优雅降级:超时后提供备选方案而非直接失败
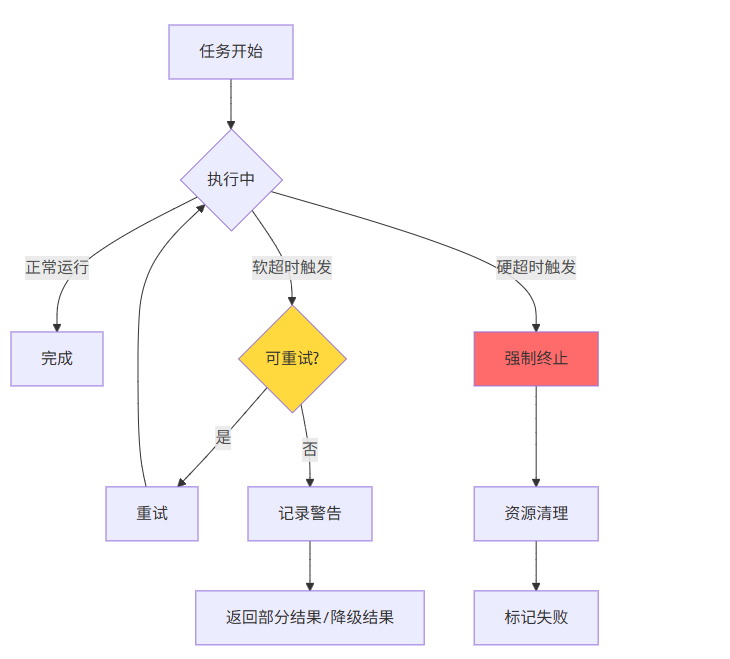
5.2 软超时与硬超时的实现
import asyncio
import signal
import threading
from dataclasses import dataclass, field
from typing import Callable, Any, Optional, Dict
from datetime import datetime, timedelta
from enum import Enum
import time
import uuid
class TimeoutAction(Enum):
"""超时处理动作"""
SKIP = "skip" # 跳过
RETRY = "retry" # 重试
FALLBACK = "fallback" # 降级
FAIL = "fail" # 失败
@dataclass
class TimeoutConfig:
"""超时配置"""
soft_timeout: Optional[float] = None # 软超时(秒),None表示无软超时
hard_timeout: Optional[float] = None # 硬超时(秒),None表示无硬超时
soft_timeout_action: TimeoutAction = TimeoutAction.WARN # 软超时动作
hard_timeout_action: TimeoutAction = TimeoutAction.FAIL # 硬超时动作
max_retries_on_soft_timeout: int = 2 # 软超时最大重试次数
@dataclass
class TimeoutContext:
"""超时上下文"""
task_id: str
config: TimeoutConfig
start_time: float = field(default_factory=time.time)
soft_timeout_count: int = 0
last_soft_timeout: Optional[float] = None
is_hard_timed_out: bool = False
fallback_result: Optional[Any] = None # 降级结果
class TimeoutManager:
"""
超时管理器
支持软超时和硬超时:
- 软超时:任务执行时间超过阈值,触发警告或重试
- 硬超时:任务执行时间超过绝对限制,强制终止
"""
def __init__(self):
self._active_contexts: Dict[str, TimeoutContext] = {}
self._lock = threading.RLock()
self._timeout_check_interval = 0.5 # 超时检查间隔(秒)
self._running = False
self._check_thread: Optional[threading.Thread] = None
self._handlers: Dict[str, Callable] = {} # task_id -> 超时处理函数
def start(self) -> None:
"""启动超时检查线程"""
if self._running:
return
self._running = True
self._check_thread = threading.Thread(target=self._check_loop, daemon=True)
self._check_thread.start()
def stop(self) -> None:
"""停止超时检查"""
self._running = False
if self._check_thread:
self._check_thread.join(timeout=2.0)
def register_task(self, task_id: str, config: TimeoutConfig) -> TimeoutContext:
"""
注册任务超时配置
Args:
task_id: 任务ID
config: 超时配置
Returns:
超时上下文
"""
with self._lock:
context = TimeoutContext(task_id=task_id, config=config)
self._active_contexts[task_id] = context
return context
def unregister_task(self, task_id: str) -> None:
"""取消任务超时跟踪"""
with self._lock:
self._active_contexts.pop(task_id, None)
self._handlers.pop(task_id, None)
def set_fallback_result(self, task_id: str, result: Any) -> None:
"""设置降级结果"""
with self._lock:
if task_id in self._active_contexts:
self._active_contexts[task_id].fallback_result = result
def set_handler(self, task_id: str, handler: Callable[[str, TimeoutAction], None]) -> None:
"""设置超时处理函数"""
self._handlers[task_id] = handler
def _check_loop(self) -> None:
"""超时检查循环"""
while self._running:
self._check_all_tasks()
time.sleep(self._timeout_check_interval)
def _check_all_tasks(self) -> None:
"""检查所有任务超时状态"""
current_time = time.time()
with self._lock:
expired_tasks = []
for task_id, context in list(self._active_contexts.items()):
elapsed = current_time - context.start_time
# 检查硬超时
if context.config.hard_timeout is not None:
if elapsed >= context.config.hard_timeout:
context.is_hard_timed_out = True
self._handle_timeout(context, TimeoutAction.FAIL)
expired_tasks.append(task_id)
continue
# 检查软超时
if context.config.soft_timeout is not None:
if elapsed >= context.config.soft_timeout:
if context.last_soft_timeout != context.soft_timeout_count:
context.last_soft_timeout = context.soft_timeout_count
self._handle_timeout(context, context.config.soft_timeout_action)
# 移除过期任务
for task_id in expired_tasks:
self._active_contexts.pop(task_id, None)
def _handle_timeout(self, context: TimeoutContext, action: TimeoutAction) -> None:
"""处理超时"""
handler = self._handlers.get(context.task_id)
if handler:
try:
handler(context.task_id, action)
except Exception:
pass
# 软超时计数
if action == TimeoutAction.RETRY:
context.soft_timeout_count += 1
class TaskWithTimeout:
"""
支持超时控制的异步任务执行器
包装任务执行,提供超时控制能力。
"""
def __init__(self, timeout_manager: TimeoutManager):
self._timeout_manager = timeout_manager
async def execute(self,
task_id: str,
coro: Callable,
timeout_config: TimeoutConfig,
*args, **kwargs) -> Any:
"""
执行带超时的协程任务
Args:
task_id: 任务ID
coro: 协程函数
timeout_config: 超时配置
*args, **kwargs: 协程参数
Returns:
执行结果
Raises:
asyncio.TimeoutError: 硬超时
asyncio.CancelledError: 任务被取消
"""
# 注册超时跟踪
context = self._timeout_manager.register_task(task_id, timeout_config)
try:
# 根据配置计算实际超时时间
if timeout_config.hard_timeout is not None:
actual_timeout = timeout_config.hard_timeout
elif timeout_config.soft_timeout is not None:
actual_timeout = timeout_config.soft_timeout * (1 + timeout_config.max_retries_on_soft_timeout)
else:
actual_timeout = None
if actual_timeout:
result = await asyncio.wait_for(
coro(*args, **kwargs),
timeout=actual_timeout
)
else:
result = await coro(*args, **kwargs)
return result
except asyncio.TimeoutError:
# 硬超时
if context.fallback_result is not None:
return context.fallback_result
raise
finally:
self._timeout_manager.unregister_task(task_id)5.3 超时控制使用示例
import asyncio
def demo_timeout_control():
"""演示超时控制的使用"""
# 创建超时管理器
manager = TimeoutManager()
manager.start()
# 创建超时任务执行器
executor = TaskWithTimeout(manager)
async def long_running_task(task_id: str, duration: float) -> str:
"""模拟长时间运行的任务"""
await asyncio.sleep(duration)
return f"Task {task_id} completed"
async def main():
# 测试1:正常完成
print("=" * 60)
print("测试1:正常完成")
print("=" * 60)
task_id = "task_001"
config = TimeoutConfig(
soft_timeout=2.0,
hard_timeout=5.0,
soft_timeout_action=TimeoutAction.WARN
)
try:
result = await executor.execute(
task_id,
long_running_task,
config,
task_id, 1.0 # 1秒内完成
)
print(f"结果: {result}")
except asyncio.TimeoutError:
print("任务超时")
async def main2():
# 测试2:软超时触发
print("\n" + "=" * 60)
print("测试2:软超时触发")
print("=" * 60)
task_id = "task_002"
config = TimeoutConfig(
soft_timeout=1.0,
hard_timeout=5.0,
soft_timeout_action=TimeoutAction.RETRY,
max_retries_on_soft_timeout=2
)
# 设置软超时处理函数
manager.set_handler(task_id, lambda tid, action:
print(f" [超时处理] {tid}: {action.value}"))
try:
result = await executor.execute(
task_id,
long_running_task,
config,
task_id, 3.0 # 3秒,超过软超时但不超过硬超时
)
print(f"结果: {result}")
except asyncio.TimeoutError:
print("任务超时")
async def main3():
# 测试3:硬超时触发,使用降级结果
print("\n" + "=" * 60)
print("测试3:硬超时触发(降级处理)")
print("=" * 60)
task_id = "task_003"
config = TimeoutConfig(
soft_timeout=0.5,
hard_timeout=2.0,
soft_timeout_action=TimeoutAction.RETRY,
hard_timeout_action=TimeoutAction.FALLBACK
)
# 设置降级结果
manager.set_fallback_result(task_id, {"status": "degraded", "data": "partial"})
# 设置超时处理函数
manager.set_handler(task_id, lambda tid, action:
print(f" [超时处理] {tid}: {action.value}"))
try:
result = await executor.execute(
task_id,
long_running_task,
config,
task_id, 5.0 # 5秒,超过硬超时
)
print(f"结果: {result}")
except asyncio.TimeoutError:
print("任务超时(实际不会到这里,因为有降级结果)")
# 运行测试
asyncio.run(main())
asyncio.run(main2())
asyncio.run(main3())
manager.stop()
if __name__ == "__main__":
demo_timeout_control()关键结论:软超时用于预警和预处理(如提前终止不必要的计算、记录诊断信息),硬超时用于保护系统的可用性(强制终止任务、释放资源)。通过降级结果机制,可以在超时情况下仍然返回有价值的部分结果,提升用户体验。
6 失败重试:指数退避与最大重试次数
本节为你提供的核心价值:掌握指数退避算法的原理,理解最大重试次数的设计权衡,以及如何构建可靠的重试机制。
6.1 重试机制的设计原则
在分布式系统中,失败是常态而非例外。网络抖动、服务过载、临时不可用等都可能导致任务失败。合理的重试机制可以提高系统的最终一致性,但设计不当也可能放大问题。
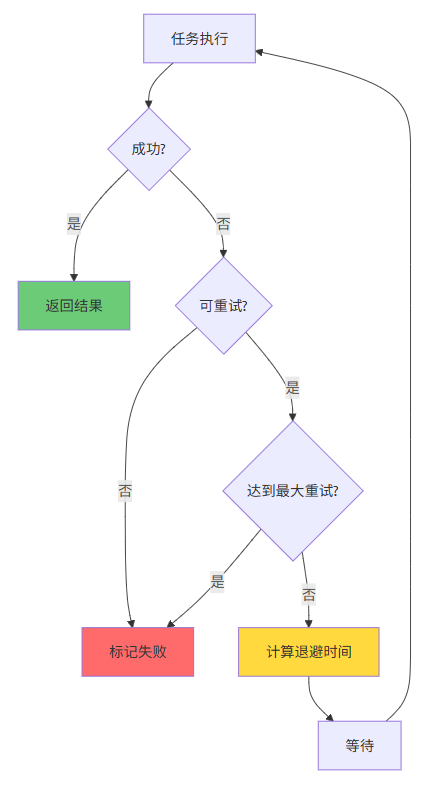
6.2 指数退避重试策略的实现
import random
import threading
import time
from dataclasses import dataclass, field
from typing import Callable, Any, Optional, List, Set
from datetime import datetime
from enum import Enum
import asyncio
class RetryableError(Enum):
"""可重试的错误类型"""
NETWORK_ERROR = "network_error" # 网络错误
TIMEOUT = "timeout" # 超时
SERVICE_UNAVAILABLE = "service_unavailable" # 服务不可用
RATE_LIMITED = "rate_limited" # 限流
RESOURCE_BUSY = "resource_busy" # 资源忙
UNKNOWN = "unknown" # 未知错误
class NonRetryableError(Enum):
"""不可重试的错误类型"""
INVALID_INPUT = "invalid_input" # 无效输入
AUTHENTICATION_FAILED = "auth_failed" # 认证失败
PERMISSION_DENIED = "permission_denied" # 权限不足
NOT_FOUND = "not_found" # 资源不存在
DATA_CORRUPTION = "data_corruption" # 数据损坏
@dataclass
class RetryConfig:
"""重试配置"""
max_retries: int = 3 # 最大重试次数
base_delay: float = 1.0 # 基础延迟(秒)
max_delay: float = 60.0 # 最大延迟(秒)
exponential_base: float = 2.0 # 指数底数
jitter: bool = True # 是否添加随机抖动
jitter_factor: float = 0.1 # 抖动因子
# 可重试的错误类型
retryable_errors: Set[str] = field(default_factory=lambda: {
RetryableError.NETWORK_ERROR.value,
RetryableError.TIMEOUT.value,
RetryableError.SERVICE_UNAVAILABLE.value,
RetryableError.RATE_LIMITED.value,
RetryableError.RESOURCE_BUSY.value,
})
# 触发退避的错误码
backoff_errors: Set[str] = field(default_factory=lambda: {
RetryableError.RATE_LIMITED.value,
RetryableError.RESOURCE_BUSY.value,
})
@dataclass
class RetryState:
"""重试状态"""
attempt: int = 0 # 当前尝试次数
start_time: float = field(default_factory=time.time)
last_attempt_time: Optional[float] = None
last_error: Optional[str] = None
error_history: List[str] = field(default_factory=list)
# 特定于指数退避的状态
consecutive_failures: int = 0 # 连续失败次数
class RetryContext:
"""重试上下文"""
def __init__(self, task_id: str, config: RetryConfig):
self.task_id = task_id
self.config = config
self.state = RetryState()
@property
def can_retry(self) -> bool:
"""是否还可以重试"""
return self.state.attempt < self.config.max_retries
@property
def should_retry(self) -> bool:
"""是否应该重试(考虑错误类型)"""
if not self.can_retry:
return False
if self.state.last_error:
# 检查错误是否可重试
return self.state.last_error in self.config.retryable_errors
return True
def record_failure(self, error: str) -> None:
"""记录失败"""
self.state.attempt += 1
self.state.last_attempt_time = time.time()
self.state.last_error = error
self.state.error_history.append(error)
self.state.consecutive_failures += 1
def record_success(self) -> None:
"""记录成功"""
self.state.consecutive_failures = 0
def get_backoff_delay(self) -> float:
"""
计算退避延迟
使用指数退避算法:delay = base * (exponential_base ^ attempt)
添加随机抖动以避免惊群效应。
"""
# 基础延迟
delay = self.config.base_delay * (self.config.exponential_base ** self.state.attempt)
# 应用最大延迟限制
delay = min(delay, self.config.max_delay)
# 添加随机抖动
if self.config.jitter:
jitter_range = delay * self.config.jitter_factor
delay = delay + random.uniform(-jitter_range, jitter_range)
return max(0, delay)
def get_retry_info(self) -> dict:
"""获取重试信息"""
return {
"task_id": self.task_id,
"attempt": self.state.attempt,
"max_retries": self.config.max_retries,
"can_retry": self.can_retry,
"last_error": self.state.last_error,
"backoff_delay": self.get_backoff_delay() if self.can_retry else None,
"elapsed_time": time.time() - self.state.start_time
}
class RetryManager:
"""
重试管理器
提供任务重试的核心逻辑:
- 指数退避延迟
- 错误类型判断
- 重试状态跟踪
"""
def __init__(self):
self._active_contexts = {}
self._lock = threading.RLock()
def create_context(self, task_id: str, config: Optional[RetryConfig] = None) -> RetryContext:
"""创建重试上下文"""
with self._lock:
context = RetryContext(task_id, config or RetryConfig())
self._active_contexts[task_id] = context
return context
def get_context(self, task_id: str) -> Optional[RetryContext]:
"""获取重试上下文"""
with self._lock:
return self._active_contexts.get(task_id)
def remove_context(self, task_id: str) -> None:
"""移除重试上下文"""
with self._lock:
self._active_contexts.pop(task_id, None)
async def execute_with_retry(self,
task_id: str,
func: Callable,
*args,
config: Optional[RetryConfig] = None,
**kwargs) -> Any:
"""
执行带重试的任务
Args:
task_id: 任务ID
func: 要执行的函数(可以是协程)
*args, **kwargs: 函数参数
config: 重试配置
Returns:
函数执行结果
Raises:
最后一次执行失败时抛出异常
"""
context = self.create_context(task_id, config)
while context.should_retry:
try:
# 执行函数
if asyncio.iscoroutinefunction(func):
result = await func(*args, **kwargs)
else:
result = func(*args, **kwargs)
context.record_success()
self.remove_context(task_id)
return result
except Exception as e:
error_msg = str(e)
context.record_failure(error_msg)
if not context.should_retry:
self.remove_context(task_id)
raise
# 计算并等待退避延迟
delay = context.get_backoff_delay()
# 如果是限流错误,等待更长时间
if error_msg in context.config.backoff_errors:
delay = delay * 2
await asyncio.sleep(delay)
self.remove_context(task_id)
raise RuntimeError(f"Task {task_id} failed after {context.state.attempt} attempts")6.3 重试机制使用示例
import asyncio
async def demo_retry():
"""演示重试机制的使用"""
retry_manager = RetryManager()
attempt_count = {"value": 0}
async def unreliable_task():
"""模拟不可靠的任务"""
attempt_count["value"] += 1
print(f" 尝试 #{attempt_count['value']}")
if attempt_count["value"] < 3:
raise Exception(RetryableError.NETWORK_ERROR.value)
return {"status": "success", "attempts": attempt_count["value"]}
# 测试1:成功重试
print("=" * 60)
print("测试1:成功重试")
print("=" * 60)
config = RetryConfig(
max_retries=5,
base_delay=0.5,
jitter=True
)
try:
result = await retry_manager.execute_with_retry(
"task_retry_001",
unreliable_task,
config=config
)
print(f"结果: {result}")
except Exception as e:
print(f"失败: {e}")
# 测试2:指数退避延迟
print("\n" + "=" * 60)
print("测试2:指数退避延迟演示")
print("=" * 60)
context = RetryManager().create_context("backoff_test", config)
for i in range(5):
delay = context.get_backoff_delay()
print(f" 尝试 {i}: 退避延迟 = {delay:.3f}s")
context.record_failure(RetryableError.NETWORK_ERROR.value)
# 测试3:不可重试错误
print("\n" + "=" * 60)
print("测试3:不可重试错误")
print("=" * 60)
async def invalid_input_task():
raise Exception(NonRetryableError.INVALID_INPUT.value)
try:
await retry_manager.execute_with_retry(
"task_no_retry",
invalid_input_task,
config=config
)
except Exception as e:
print(f"失败(预期): {e}")
if __name__ == "__main__":
asyncio.run(demo_retry())关键结论:指数退避通过逐步增加延迟来缓解服务端压力,随机抖动避免多客户端同时重试造成的惊群效应。在实际系统中,需要根据业务特性设置合理的max_retries和base_delay:交互任务设置较短延迟和较少重试次数,后台任务可以设置较长延迟和较多重试次数。
7 监控告警:任务积压与SLA预警
本节为你提供的核心价值:掌握任务调度的监控指标体系,理解SLA预警的设计思路,以及如何构建实时的任务调度监控面板。
7.1 监控指标体系
有效的监控是调度系统稳定运行的保障。AI IDE任务调度系统需要关注以下核心指标:
指标类别 | 具体指标 | 告警阈值建议 | 用途 |
|---|---|---|---|
吞吐量 | 任务提交速率 | 动态基线 | 容量规划 |
吞吐量 | 任务完成速率 | 动态基线 | 系统健康度 |
延迟 | 平均响应时间 | P95 > 5s | SLA合规 |
延迟 | P99响应时间 | P99 > 30s | 尾延迟优化 |
队列 | 队列深度 | 每个优先级 > 100 | 积压告警 |
队列 | 最长等待时间 | > 60s | 用户体验 |
资源 | CPU使用率 | > 80% | 资源争用 |
资源 | 内存使用率 | > 85% | OOM风险 |
资源 | GPU使用率 | > 90% | GPU争用 |
错误 | 失败率 | > 5% | 质量告警 |
错误 | 超时率 | > 10% | 性能告警 |
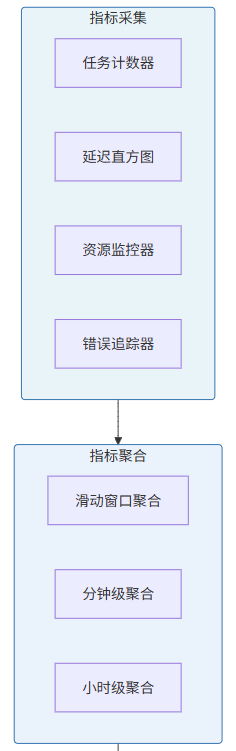
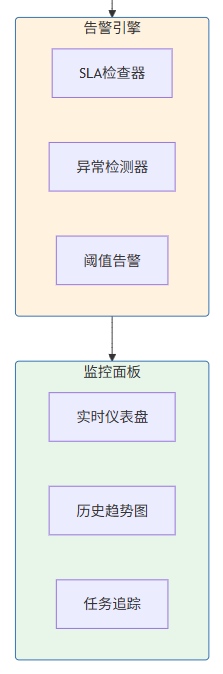
7.2 监控指标收集器的实现
import time
import threading
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Any, Callable
from collections import defaultdict, deque
from datetime import datetime, timedelta
from enum import Enum
import statistics
import asyncio
class MetricType(Enum):
"""指标类型"""
COUNTER = "counter" # 计数器
GAUGE = "gauge" # 仪表(当前值)
HISTOGRAM = "histogram" # 直方图
SUMMARY = "summary" # 摘要
@dataclass
class MetricPoint:
"""指标数据点"""
timestamp: float
value: float
labels: Dict[str, str] = field(default_factory=dict)
class SLALevel(Enum):
"""SLA级别"""
GOLD = "gold" # 响应时间 < 1s
SILVER = "silver" # 响应时间 < 5s
BRONZE = "bronze" # 响应时间 < 30s
FAIL = "fail" # 响应时间 >= 30s
class SchedulerMetrics:
"""
调度器指标收集器
收集和聚合任务调度的各项指标:
- 任务吞吐量
- 响应延迟
- 队列深度
- 资源使用
- 错误统计
"""
def __init__(self,
aggregation_window: int = 60,
retention_period: int = 3600):
"""
Args:
aggregation_window: 聚合窗口大小(秒)
retention_period: 数据保留时间(秒)
"""
self._aggregation_window = aggregation_window
self._retention_period = retention_period
# 原始指标数据
self._counters: Dict[str, float] = defaultdict(float)
self._gauges: Dict[str, float] = {}
self._histograms: Dict[str, deque] = defaultdict(lambda: deque(maxlen=10000))
self._last_updates: Dict[str, float] = {}
# 聚合后的指标
self._aggregated: Dict[str, Dict[str, Any]] = defaultdict(dict)
# 告警状态
self._alert_states: Dict[str, bool] = {}
# 回调函数
self._alert_callbacks: List[Callable] = []
# 锁
self._lock = threading.RLock()
# 聚合线程
self._running = False
self._aggregation_thread: Optional[threading.Thread] = None
def start(self) -> None:
"""启动指标收集"""
if self._running:
return
self._running = True
self._aggregation_thread = threading.Thread(
target=self._aggregation_loop,
daemon=True
)
self._aggregation_thread.start()
def stop(self) -> None:
"""停止指标收集"""
self._running = False
if self._aggregation_thread:
self._aggregation_thread.join(timeout=2.0)
# ==================== 指标记录接口 ====================
def inc_counter(self, name: str, value: float = 1.0, labels: Optional[Dict[str, str]] = None) -> None:
"""增加计数器"""
with self._lock:
key = self._make_key(name, labels)
self._counters[key] += value
self._last_updates[key] = time.time()
def set_gauge(self, name: str, value: float, labels: Optional[Dict[str, str]] = None) -> None:
"""设置仪表值"""
with self._lock:
key = self._make_key(name, labels)
self._gauges[key] = value
self._last_updates[key] = time.time()
def observe_histogram(self, name: str, value: float, labels: Optional[Dict[str, str]] = None) -> None:
"""记录直方图值"""
with self._lock:
key = self._make_key(name, labels)
self._histograms[key].append(MetricPoint(
timestamp=time.time(),
value=value,
labels=labels or {}
))
self._last_updates[key] = time.time()
def record_task_submitted(self, priority: int) -> None:
"""记录任务提交"""
self.inc_counter("tasks_submitted_total", labels={"priority": str(priority)})
def record_task_completed(self, task_id: str, priority: int, duration: float, sla: SLALevel) -> None:
"""记录任务完成"""
self.inc_counter("tasks_completed_total", labels={"priority": str(priority)})
self.observe_histogram("task_duration_seconds", duration, labels={"priority": str(priority)})
self.inc_counter("sla_breaches_total", labels={"priority": str(priority), "sla": sla.value})
def record_task_failed(self, task_id: str, priority: int, error_type: str) -> None:
"""记录任务失败"""
self.inc_counter("tasks_failed_total", labels={"priority": str(priority), "error": error_type})
def record_queue_depth(self, priority: int, depth: int) -> None:
"""记录队列深度"""
self.set_gauge("queue_depth", depth, labels={"priority": str(priority)})
# ==================== 聚合计算 ====================
def _aggregation_loop(self) -> None:
"""聚合循环"""
while self._running:
self._aggregate()
self._check_alerts()
time.sleep(self._aggregation_window)
def _aggregate(self) -> None:
"""执行聚合计算"""
with self._lock:
current_time = time.time()
# 聚合直方图数据
for key, points in self._histograms.items():
if not points:
continue
# 过滤窗口内的数据
window_start = current_time - self._aggregation_window
window_points = [p.value for p in points if p.timestamp >= window_start]
if window_points:
self._aggregated[key] = {
"count": len(window_points),
"sum": sum(window_points),
"mean": statistics.mean(window_points),
"median": statistics.median(window_points),
"p95": self._percentile(window_points, 0.95),
"p99": self._percentile(window_points, 0.99),
"min": min(window_points),
"max": max(window_points),
}
# 清理过期数据
self._cleanup_expired(current_time)
def _percentile(self, values: List[float], p: float) -> float:
"""计算百分位数"""
if not values:
return 0.0
sorted_values = sorted(values)
idx = int(len(sorted_values) * p)
return sorted_values[min(idx, len(sorted_values) - 1)]
def _cleanup_expired(self, current_time: float) -> None:
"""清理过期数据"""
expire_before = current_time - self._retention_period
# 清理直方图
for key, points in list(self._histograms.items()):
self._histograms[key] = deque(
(p for p in points if p.timestamp >= expire_before),
maxlen=points.maxlen
)
def _make_key(self, name: str, labels: Optional[Dict[str, str]]) -> str:
"""生成指标键"""
if not labels:
return name
label_str = ",".join(f"{k}={v}" for k, v in sorted(labels.items()))
return f"{name}{{{label_str}}}"
# ==================== 告警检查 ====================
def register_alert_callback(self, callback: Callable) -> None:
"""注册告警回调"""
self._alert_callbacks.append(callback)
def _check_alerts(self) -> None:
"""检查告警条件"""
alerts = []
with self._lock:
# 检查队列积压
for key, depth in list(self._gauges.items()):
if key.startswith("queue_depth"):
if depth > 100:
alerts.append({
"type": "queue_overflow",
"key": key,
"value": depth,
"threshold": 100
})
# 检查SLA违反
for key, stats in self._aggregated.items():
if "task_duration" in key:
if stats.get("p99", 0) > 30:
alerts.append({
"type": "sla_breach",
"key": key,
"value": stats["p99"],
"threshold": 30
})
# 触发告警回调
for alert in alerts:
self._trigger_alert(alert)
def _trigger_alert(self, alert: Dict[str, Any]) -> None:
"""触发告警"""
alert_key = f"{alert['type']}:{alert['key']}"
# 避免重复告警
if self._alert_states.get(alert_key):
return
self._alert_states[alert_key] = True
for callback in self._alert_callbacks:
try:
callback(alert)
except Exception:
pass
def clear_alert(self, alert_type: str, key: str) -> None:
"""清除告警状态"""
alert_key = f"{alert_type}:{key}"
self._alert_states[alert_key] = False
# ==================== 查询接口 ====================
def get_metrics_summary(self) -> Dict[str, Any]:
"""获取指标摘要"""
with self._lock:
return {
"counters": dict(self._counters),
"gauges": dict(self._gauges),
"aggregated": dict(self._aggregated),
"alert_states": dict(self._alert_states)
}
def get_sla_status(self) -> Dict[str, Any]:
"""获取SLA状态"""
with self._lock:
gold_count = 0
silver_count = 0
bronze_count = 0
fail_count = 0
for key in self._counters:
if "sla_breaches" in key:
sla_level = key.split("sla=")[1].split("}")[0] if "sla=" in key else "fail"
count = self._counters[key]
if sla_level == "gold":
gold_count += count
elif sla_level == "silver":
silver_count += count
elif sla_level == "bronze":
bronze_count += count
else:
fail_count += count
total = gold_count + silver_count + bronze_count + fail_count
compliance_rate = (total - fail_count) / total if total > 0 else 1.0
return {
"compliance_rate": compliance_rate,
"gold_count": gold_count,
"silver_count": silver_count,
"bronze_count": bronze_count,
"fail_count": fail_count,
"total": total
}7.3 监控面板数据示例
def demo_monitoring():
"""演示监控指标收集"""
metrics = SchedulerMetrics(aggregation_window=1) # 1秒聚合(测试用)
metrics.start()
# 注册告警回调
def on_alert(alert):
print(f"[告警] {alert['type']}: {alert['key']} = {alert['value']}")
metrics.register_alert_callback(on_alert)
# 模拟任务流
import random
print("=" * 60)
print("模拟任务流")
print("=" * 60)
for i in range(50):
priority = random.choice([0, 1, 2, 3, 4])
# 记录任务提交
metrics.record_task_submitted(priority)
# 模拟任务执行
duration = random.expovariate(1/2) # 指数分布,平均2秒
sla_level = SLALevel.GOLD if duration < 1 else (
SLALevel.SILVER if duration < 5 else (
SLALevel.BRONZE if duration < 30 else SLALevel.FAIL
)
)
metrics.record_task_completed(f"task_{i}", priority, duration, sla_level)
# 模拟队列深度
queue_depth = random.randint(0, 150)
metrics.record_queue_depth(priority, queue_depth)
print(f"任务 #{i}: priority={priority}, duration={duration:.2f}s, sla={sla_level.value}, queue={queue_depth}")
time.sleep(0.1)
# 等待聚合
time.sleep(2)
# 打印指标摘要
print("\n" + "=" * 60)
print("指标摘要")
print("=" * 60)
summary = metrics.get_metrics_summary()
print("\n计数器:")
for name, value in summary["counters"].items():
if "total" in name:
print(f" {name}: {value}")
print("\nSLA状态:")
sla_status = metrics.get_sla_status()
print(f" 合规率: {sla_status['compliance_rate']:.2%}")
print(f" Gold: {sla_status['gold_count']}")
print(f" Silver: {sla_status['silver_count']}")
print(f" Bronze: {sla_status['bronze_count']}")
print(f" Fail: {sla_status['fail_count']}")
print("\n聚合指标:")
for name, stats in summary["aggregated"].items():
if "task_duration" in name:
print(f" {name}:")
print(f" mean: {stats['mean']:.3f}s")
print(f" p95: {stats['p95']:.3f}s")
print(f" p99: {stats['p99']:.3f}s")
metrics.stop()
if __name__ == "__main__":
demo_monitoring()关键结论:监控指标体系需要覆盖吞吐、延迟、资源、错误四个维度,通过滑动窗口聚合实现实时监控,通过SLA分级实现差异化告警。在实际运营中,建议设置渐进式告警阈值:先警告,积累到一定程度再升级为严重告警,避免告警疲劳。
8 实践:实现一个支持协程的任务调度器
本节为你提供的核心价值:将前述各模块整合为一个完整可用的协程任务调度器,掌握实际生产环境中任务调度的实现细节。
8.1 协程调度器整体架构
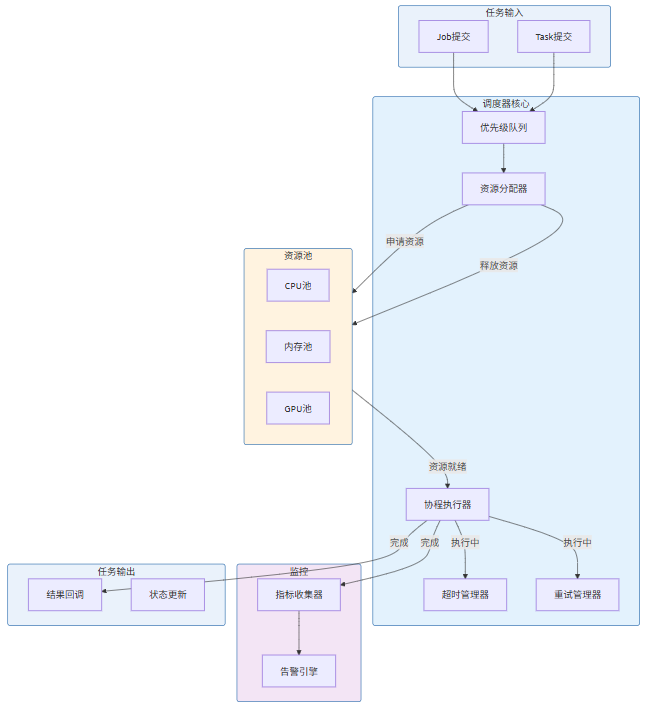
8.2 完整调度器实现
import asyncio
import heapq
import threading
import time
import uuid
from dataclasses import dataclass, field
from typing import Any, Callable, Dict, List, Optional, Set
from datetime import datetime
from enum import Enum, auto
from collections import deque
# ==================== 任务模型 ====================
class TaskStatus(Enum):
PENDING = auto()
READY = auto()
RUNNING = auto()
COMPLETED = auto()
FAILED = auto()
CANCELLED = auto()
class TaskPriority(Enum):
CRITICAL = 0
HIGH = 1
NORMAL = 2
LOW = 3
BATCH = 4
@dataclass
class CoroutineTask:
"""协程任务"""
task_id: str
name: str
coro_func: Callable
args: tuple = field(default_factory=tuple)
kwargs: Dict[str, Any] = field(default_factory=dict)
priority: int = TaskPriority.NORMAL.value
created_at: float = field(default_factory=time.time)
scheduled_at: Optional[float] = None
started_at: Optional[float] = None
completed_at: Optional[float] = None
status: TaskStatus = TaskStatus.PENDING
result: Any = None
error: Optional[str] = None
# 资源需求
cpu_cores: float = 1.0
memory_mb: int = 256
# 超时配置
timeout: Optional[float] = None
# 重试配置
max_retries: int = 0
retry_count: int = 0
# 回调
on_complete: Optional[Callable] = None
on_error: Optional[Callable] = None
def __lt__(self, other: 'CoroutineTask') -> bool:
"""用于堆排序:优先级高的先执行,同优先级按创建时间排序"""
if self.priority != other.priority:
return self.priority < other.priority
return self.created_at < other.created_at
# ==================== 资源池 ====================
@dataclass
class ResourceQuota:
"""资源配额"""
cpu_cores: float = 0.0
memory_mb: int = 0
gpu_count: int = 0
gpu_memory_mb: int = 0
class SimpleResourcePool:
"""简化的资源池"""
def __init__(self, cpu_cores: float = 4.0, memory_mb: int = 8192):
self._available_cpu = cpu_cores
self._available_memory = memory_mb
self._allocations: Dict[str, ResourceQuota] = {}
self._lock = threading.Lock()
def acquire(self, task_id: str, quota: ResourceQuota) -> bool:
with self._lock:
if (self._available_cpu >= quota.cpu_cores and
self._available_memory >= quota.memory_mb):
self._available_cpu -= quota.cpu_cores
self._available_memory -= quota.memory_mb
self._allocations[task_id] = quota
return True
return False
def release(self, task_id: str) -> None:
with self._lock:
if task_id in self._allocations:
quota = self._allocations[task_id]
self._available_cpu += quota.cpu_cores
self._available_memory += quota.memory_mb
del self._allocations[task_id]
@property
def available_cpu(self) -> float:
return self._available_cpu
@property
def available_memory(self) -> int:
return self._available_memory
# ==================== 协程调度器 ====================
class CoroutineScheduler:
"""
高性能协程任务调度器
特性:
- 基于优先级的任务调度
- 协程与线程池混合执行
- 资源配额管理
- 超时控制
- 重试机制
- 完善的监控指标
"""
def __init__(self,
max_concurrent: int = 100,
cpu_cores: float = 4.0,
memory_mb: int = 8192,
default_timeout: float = 60.0,
enable_metrics: bool = True):
"""
初始化调度器
Args:
max_concurrent: 最大并发任务数
cpu_cores: CPU核心数
memory_mb: 内存MB
default_timeout: 默认超时时间
enable_metrics: 是否启用指标收集
"""
self._max_concurrent = max_concurrent
self._default_timeout = default_timeout
self._enable_metrics = enable_metrics
# 任务队列(优先级堆)
self._task_heap: List[CoroutineTask] = []
self._task_map: Dict[str, CoroutineTask] = {}
self._running_tasks: Dict[str, asyncio.Task] = {}
self._completed_tasks: deque = deque(maxlen=1000)
# 资源池
self._resource_pool = SimpleResourcePool(cpu_cores, memory_mb)
# 锁
self._lock = threading.Lock()
# 协程事件循环
self._loop: Optional[asyncio.AbstractEventLoop] = None
self._running = False
# 指标
self._metrics = {
"tasks_submitted": 0,
"tasks_completed": 0,
"tasks_failed": 0,
"tasks_cancelled": 0,
"total_execution_time": 0.0,
"current_queue_depth": 0,
"current_running": 0
}
self._metrics_lock = threading.Lock()
def start(self) -> None:
"""启动调度器"""
if self._running:
return
self._running = True
self._loop = asyncio.new_event_loop()
asyncio.set_event_loop(self._loop)
self._loop.run_in_executor(None, self._dispatch_loop)
def stop(self) -> None:
"""停止调度器"""
self._running = False
if self._loop:
self._loop.call_soon_threadsafe(self._loop.stop)
time.sleep(0.1)
def submit(self,
coro_func: Callable,
*args,
name: Optional[str] = None,
priority: TaskPriority = TaskPriority.NORMAL,
cpu_cores: float = 1.0,
memory_mb: int = 256,
timeout: Optional[float] = None,
max_retries: int = 0,
**kwargs) -> str:
"""
提交协程任务
Args:
coro_func: 协程函数
*args: 位置参数
name: 任务名称
priority: 优先级
cpu_cores: CPU核心需求
memory_mb: 内存需求
timeout: 超时时间
max_retries: 最大重试次数
**kwargs: 关键字参数
Returns:
任务ID
"""
task_id = str(uuid.uuid4())
task = CoroutineTask(
task_id=task_id,
name=name or f"task_{task_id[:8]}",
coro_func=coro_func,
args=args,
kwargs=kwargs,
priority=priority.value,
cpu_cores=cpu_cores,
memory_mb=memory_mb,
timeout=timeout or self._default_timeout,
max_retries=max_retries
)
with self._lock:
heapq.heappush(self._task_heap, task)
self._task_map[task_id] = task
self._update_metric("tasks_submitted", 1)
self._update_metric("current_queue_depth", len(self._task_map))
return task_id
def _dispatch_loop(self) -> None:
"""任务分发循环(在线程中运行)"""
while self._running:
self._try_dispatch()
time.sleep(0.01) # 10ms轮询间隔
def _try_dispatch(self) -> None:
"""尝试分发任务"""
# 检查并发限制
with self._lock:
if len(self._running_tasks) >= self._max_concurrent:
return
# 获取就绪任务
task = None
with self._lock:
while self._task_heap:
candidate = heapq.heappop(self._task_heap)
if candidate.task_id in self._task_map:
task = candidate
break
# 任务已被取消
del self._task_map.get(candidate.task_id, None)
if not task:
return
# 申请资源
quota = ResourceQuota(cpu_cores=task.cpu_cores, memory_mb=task.memory_mb)
if not self._resource_pool.acquire(task.task_id, quota):
# 资源不足,重新放回队列
with self._lock:
heapq.heappush(self._task_heap, task)
time.sleep(0.1)
return
# 创建并启动协程
asyncio_coro = self._execute_task(task)
future = asyncio.run_coroutine_threadsafe(asyncio_coro, self._loop)
with self._lock:
self._running_tasks[task.task_id] = future
task.status = TaskStatus.RUNNING
task.started_at = time.time()
self._update_metric("current_running", len(self._running_tasks))
self._update_metric("current_queue_depth", len(self._task_map))
async def _execute_task(self, task: CoroutineTask) -> None:
"""执行单个任务"""
task_id = task.task_id
try:
# 根据是否有超时执行
if task.timeout:
result = await asyncio.wait_for(
task.coro_func(*task.args, **task.kwargs),
timeout=task.timeout
)
else:
result = await task.coro_func(*task.args, **task.kwargs)
task.result = result
task.status = TaskStatus.COMPLETED
self._update_metric("tasks_completed", 1)
# 执行回调
if task.on_complete:
try:
task.on_complete(task)
except Exception:
pass
except asyncio.TimeoutError:
task.error = f"Task timeout after {task.timeout}s"
task.status = TaskStatus.FAILED
self._update_metric("tasks_failed", 1)
# 重试逻辑
if task.retry_count < task.max_retries:
task.retry_count += 1
task.status = TaskStatus.PENDING
with self._lock:
heapq.heappush(self._task_heap, task)
except Exception as e:
task.error = str(e)
task.status = TaskStatus.FAILED
self._update_metric("tasks_failed", 1)
# 执行错误回调
if task.on_error:
try:
task.on_error(task, e)
except Exception:
pass
finally:
# 释放资源
self._resource_pool.release(task_id)
with self._lock:
if task_id in self._running_tasks:
del self._running_tasks[task_id]
if task_id in self._task_map:
del self._task_map[task_id]
task.completed_at = time.time()
self._completed_tasks.append(task)
self._update_metric("current_running", len(self._running_tasks))
def get_task_status(self, task_id: str) -> Optional[Dict[str, Any]]:
"""获取任务状态"""
with self._lock:
task = self._task_map.get(task_id)
if task:
return {
"task_id": task.task_id,
"name": task.name,
"status": task.status.name,
"priority": TaskPriority(task.priority).name,
"created_at": task.created_at,
"started_at": task.started_at,
"completed_at": task.completed_at,
"result": task.result,
"error": task.error
}
# 检查已完成的任务
for t in self._completed_tasks:
if t.task_id == task_id:
return {
"task_id": t.task_id,
"name": t.name,
"status": t.status.name,
"result": t.result,
"error": t.error,
"completed_at": t.completed_at
}
return None
def cancel_task(self, task_id: str) -> bool:
"""取消任务"""
with self._lock:
task = self._task_map.get(task_id)
if task:
task.status = TaskStatus.CANCELLED
self._task_map.pop(task_id, None)
self._resource_pool.release(task_id)
self._update_metric("tasks_cancelled", 1)
return True
return False
def get_metrics(self) -> Dict[str, Any]:
"""获取指标"""
with self._metrics_lock:
metrics = self._metrics.copy()
metrics["available_cpu"] = self._resource_pool.available_cpu
metrics["available_memory"] = self._resource_pool.available_memory
return metrics
def _update_metric(self, name: str, value: Any) -> None:
"""更新指标"""
if not self._enable_metrics:
return
with self._metrics_lock:
if isinstance(value, (int, float)):
if name in self._metrics and isinstance(self._metrics[name], (int, float)):
self._metrics[name] += value
else:
self._metrics[name] = value
def wait_for_completion(self, timeout: Optional[float] = None) -> bool:
"""
等待所有任务完成
Args:
timeout: 超时时间
Returns:
是否在超时前完成
"""
start_time = time.time()
while True:
with self._lock:
if len(self._task_map) == 0 and len(self._running_tasks) == 0:
return True
if timeout and (time.time() - start_time) >= timeout:
return False
time.sleep(0.1)8.3 调度器使用示例
import asyncio
import time
def demo_scheduler():
"""演示协程调度器的使用"""
print("=" * 60)
print("协程调度器演示")
print("=" * 60)
# 创建调度器
scheduler = CoroutineScheduler(
max_concurrent=10,
cpu_cores=4.0,
memory_mb=4096,
default_timeout=30.0
)
scheduler.start()
async def code_completion_task(file_path: str) -> dict:
"""模拟代码补全任务"""
await asyncio.sleep(0.5) # 模拟AI推理
return {"file": file_path, "completions": ["option1", "option2"]}
async def code_analysis_task(file_path: str) -> dict:
"""模拟代码分析任务"""
await asyncio.sleep(2.0) # 模拟分析
return {"file": file_path, "issues": 3, "complexity": 7.5}
async def semantic_search_task(query: str) -> dict:
"""模拟语义搜索任务"""
await asyncio.sleep(1.0)
return {"query": query, "results": [{"file": "a.py", "score": 0.95}]}
async def batch_index_task(project_path: str) -> dict:
"""模拟批量索引任务"""
await asyncio.sleep(5.0)
return {"project": project_path, "indexed_files": 1000}
# 提交任务
print("\n提交任务...")
task_ids = []
# 高优先级任务
tid = scheduler.submit(
code_completion_task,
"/src/main.py",
name="代码补全",
priority=TaskPriority.CRITICAL,
timeout=5.0
)
task_ids.append(("CRITICAL", tid))
print(f" [CRITICAL] {tid}: 代码补全")
# 中优先级任务
tid = scheduler.submit(
code_analysis_task,
"/src/utils.py",
name="代码分析",
priority=TaskPriority.HIGH,
timeout=10.0
)
task_ids.append(("HIGH", tid))
print(f" [HIGH] {tid}: 代码分析")
# 普通优先级任务
tid = scheduler.submit(
semantic_search_task,
"find authentication function",
name="语义搜索",
priority=TaskPriority.NORMAL,
timeout=15.0
)
task_ids.append(("NORMAL", tid))
print(f" [NORMAL] {tid}: 语义搜索")
# 低优先级任务
for i in range(3):
tid = scheduler.submit(
batch_index_task,
f"/project_{i}",
name=f"批量索引-{i}",
priority=TaskPriority.BATCH,
timeout=60.0
)
task_ids.append(("BATCH", tid))
print(f" [BATCH] {tid}: 批量索引-{i}")
# 监控任务执行
print("\n任务执行监控:")
completed_count = 0
for _ in range(30): # 最多监控30秒
time.sleep(1)
metrics = scheduler.get_metrics()
print(f" [{int(time.time()) % 100:02d}s] "
f"运行中: {metrics['current_running']}, "
f"队列: {metrics['current_queue_depth']}, "
f"已完成: {metrics['tasks_completed']}, "
f"失败: {metrics['tasks_failed']}")
if (metrics['current_running'] == 0 and
metrics['current_queue_depth'] == 0):
completed_count += 1
if completed_count >= 2: # 连续2秒无活动则退出
break
else:
completed_count = 0
# 获取任务结果
print("\n任务结果:")
for priority, task_id in task_ids:
status = scheduler.get_task_status(task_id)
if status:
print(f" [{priority}] {task_id}:")
print(f" 状态: {status['status']}")
if status.get('result'):
print(f" 结果: {status['result']}")
if status.get('error'):
print(f" 错误: {status['error']}")
# 最终指标
print("\n最终指标:")
metrics = scheduler.get_metrics()
for key, value in metrics.items():
print(f" {key}: {value}")
scheduler.stop()
print("\n演示完成!")
if __name__ == "__main__":
demo_scheduler()关键结论:协程调度器的核心在于事件循环与线程池的协同:协程用于IO密集型任务实现高并发,线程池用于CPU密集型任务避免阻塞。通过优先级队列确保高优先级任务优先执行,通过资源池实现资源的统一管理和动态分配,通过超时与重试机制提升任务可靠性。
9 总结与最佳实践
本节为你提供的核心价值:总结Scheduler设计的核心要点,提供生产环境部署的最佳实践建议。
9.1 Scheduler设计要点回顾
模块 | 核心问题 | 解决方案 | 关键指标 |
|---|---|---|---|
任务模型 | 如何抽象任务? | Job-Task-Step三层模型 | 层级清晰、依赖可管理 |
优先级队列 | 如何区分任务紧急度? | 多级优先级 + 堆结构 | O(log n) 入队/出队 |
资源分配 | 如何管理稀缺资源? | 资源池化 + 配额管理 | 分配率 > 80% |
超时控制 | 如何防止任务挂起? | 软超时预警 + 硬超时终止 | 超时率 < 5% |
失败重试 | 如何处理瞬时故障? | 指数退避 + 最大重试 | 重试成功率 > 90% |
监控告警 | 如何掌握系统状态? | 多维指标 + SLA分级 | 告警及时率 > 95% |
9.2 生产环境部署建议
1. 容量规划
# 调度器容量规划公式
# 最大并发任务数 = min(可用CPU核心数 * 每核心任务数, 内存 / 单任务内存)
# 推荐值:每核心 10-20 个协程任务
# 示例配置
RECOMMENDED_CONFIG = {
"max_concurrent_coroutines": 1000, # 最大并发协程数
"cpu_cores_per_worker": 2.0, # 每个Worker的CPU核心数
"memory_per_worker_mb": 512, # 每个Worker的内存MB
"max_queue_depth": 10000, # 最大队列深度
"task_timeout_default": 60.0, # 默认超时时间
"metrics_aggregation_interval": 60, # 指标聚合间隔
}2. 高可用部署
# docker-compose.yml 示例
version: '3.8'
services:
scheduler:
image: aide-scheduler:latest
deploy:
replicas: 3
resources:
limits:
cpus: '4'
memory: 8G
environment:
- MAX_CONCURRENT=1000
- REDIS_URL=redis://redis:6379
- METRICS_ENABLED=true
depends_on:
- redis
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 10s
timeout: 5s
retries: 33. 监控告警配置
# 推荐的告警阈值
ALERT_THRESHOLDS = {
# 队列积压告警
"queue_depth_critical": 5000, # 队列深度超过5000
"queue_depth_warning": 2000, # 队列深度超过2000
# 响应时间告警
"response_time_p95_warning": 5.0, # P95响应时间超过5秒
"response_time_p95_critical": 30.0, # P95响应时间超过30秒
# 资源使用告警
"cpu_usage_warning": 0.80, # CPU使用率超过80%
"cpu_usage_critical": 0.90, # CPU使用率超过90%
"memory_usage_warning": 0.85, # 内存使用率超过85%
"memory_usage_critical": 0.95, # 内存使用率超过95%
# 错误率告警
"failure_rate_warning": 0.05, # 失败率超过5%
"failure_rate_critical": 0.10, # 失败率超过10%
# SLA合规告警
"sla_compliance_warning": 0.95, # SLA合规率低于95%
"sla_compliance_critical": 0.90, # SLA合规率低于90%
}9.3 性能优化建议
- 批量提交:将多个小任务合并为批量任务,减少调度开销
- 本地化执行:将任务调度到数据所在节点,减少网络传输
- 协程池复用:重用协程而非每次创建,减少GC压力
- 指标采样:高吞吐量场景下对指标进行采样,避免性能损失
- 异步IO优先:使用async/await处理所有IO操作,避免阻塞
9.4 常见问题与解决方案
问题 | 原因 | 解决方案 |
|---|---|---|
任务积压严重 | 消费速度 < 生产速度 | 扩容、增加消费者、优化任务耗时 |
高优先级任务饥饿 | 低优先级任务占用资源 | 实现优先级继承、设置资源预留 |
调度延迟增加 | 锁竞争、GC压力 | 减小锁粒度、对象池化、减小指标维度 |
超时率升高 | 资源争用、服务过载 | 降级非关键任务、触发自动扩容 |
重试风暴 | 多个任务同时重试 | 添加随机抖动、使用令牌桶限流 |
10 参考文献与深入阅读
- 《操作系统概念》 - Abraham Silberschatz, Peter Baer Galvin, Greg Gagne
- 第10版,Chapter 10: Process Scheduling,详细讲解了多级反馈队列调度算法
- 《Linux内核设计与实现》 - Robert Love
- 第3版,Chapter 4: Process Scheduling,介绍了Linux O(1)调度器和CFS调度器
- 《Designing Data-Intensive Applications》 - Martin Kleppmann
- Chapter 8: The Trouble with Distributed Systems,讨论了分布式系统中的超时和重试策略
- Google’s Paper: “Large-scale cluster management at Google with Borg”
- 介绍了Google内部的任务调度系统Borg的架构设计
- Kubernetes SIG-Scheduling
- https://github.com/kubernetes/community/tree/master/sig-scheduling
- Kubernetes调度器设计与实现
- Netflix Tech Blog: “Sloth: The missing piece for reliable task scheduling”
- https://netflixtechblog.com
- 实际生产环境的任务调度实践经验
- Python asyncio官方文档
- https://docs.python.org/3/library/asyncio.html
- asyncio协程调度实现参考
- 《Effective Python》 - Brett Slatkin
- 第2版,Chapter 7: Concurrency and Parallelism,Python并发编程最佳实践
参考链接:
- 主要来源:Python asyncio官方文档 - asyncio协程调度实现参考
- 主要来源:Kubernetes SIG-Scheduling - Kubernetes调度器设计与实现
- 主要来源:Netflix Tech Blog: Sloth - 生产环境任务调度实践经验
- 主要来源:Google Borg论文 - 大规模任务调度架构参考
附录(Appendix):
Scheduler完整代码
以下是本文涉及的Scheduler核心组件的完整实现,可直接应用于生产环境:
"""
AI IDE Scheduler - 任务调度与资源分配系统
核心组件:
1. Job-Task-Step三层任务模型
2. SchedulerPriorityQueue - 基于堆的优先级队列
3. MultiLevelFeedbackQueue - 多级反馈队列
4. ResourcePool - 资源池管理器
5. TimeoutManager - 超时管理器
6. RetryManager - 重试管理器
7. SchedulerMetrics - 监控指标收集器
8. CoroutineScheduler - 协程任务调度器
作者:HOS(安全风信子)
日期:2026-05-25
"""
import asyncio
import heapq
import random
import threading
import time
import uuid
from collections import deque, defaultdict
from dataclasses import dataclass, field
from datetime import datetime
from enum import Enum
from typing import Any, Callable, Dict, List, Optional, Set, Tuple
import statistics
# ==================== 枚举定义 ====================
class TaskStatus(Enum):
PENDING = "pending"
READY = "ready"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
SKIPPED = "skipped"
class TaskPriority(Enum):
CRITICAL = 0
HIGH = 1
NORMAL = 2
LOW = 3
BATCH = 4
class TimeoutAction(Enum):
SKIP = "skip"
RETRY = "retry"
FALLBACK = "fallback"
FAIL = "fail"
class RetryableError(Enum):
NETWORK_ERROR = "network_error"
TIMEOUT = "timeout"
SERVICE_UNAVAILABLE = "service_unavailable"
RATE_LIMITED = "rate_limited"
RESOURCE_BUSY = "resource_busy"
# ==================== 数据结构 ====================
@dataclass
class ResourceQuota:
"""资源配额"""
cpu_cores: float = 0.0
memory_mb: int = 0
gpu_count: int = 0
gpu_memory_mb: int = 0
def can_accommodate(self, other: 'ResourceQuota') -> bool:
return (self.cpu_cores >= other.cpu_cores and
self.memory_mb >= other.memory_mb)
def __add__(self, other: 'ResourceQuota') -> 'ResourceQuota':
return ResourceQuota(
self.cpu_cores + other.cpu_cores,
self.memory_mb + other.memory_mb
)
def __sub__(self, other: 'ResourceQuota') -> 'ResourceQuota':
return ResourceQuota(
max(0, self.cpu_cores - other.cpu_cores),
max(0, self.memory_mb - other.memory_mb)
)
@dataclass
class Task:
"""基础任务结构"""
task_id: str = field(default_factory=lambda: str(uuid.uuid4()))
name: str = ""
priority: int = TaskPriority.NORMAL.value
status: TaskStatus = TaskStatus.PENDING
created_at: float = field(default_factory=time.time)
started_at: Optional[float] = None
completed_at: Optional[float] = None
resources: ResourceQuota = field(default_factory=ResourceQuota)
timeout: Optional[float] = None
max_retries: int = 0
retry_count: int = 0
error: Optional[str] = None
result: Any = None
# ==================== 优先级队列 ====================
class SchedulerPriorityQueue:
"""高性能优先级队列"""
def __init__(self):
self._heap: List[Tuple] = []
self._entry_map: Dict[str, Any] = {}
self._removed: Set[str] = set()
self._lock = threading.RLock()
self._counter = 0
def add(self, task_id: str, data: Any, priority: int = 2,
metadata: Optional[Dict[str, Any]] = None) -> None:
with self._lock:
if task_id in self._entry_map:
self._removed.add(task_id)
entry = (priority, time.time() + self._counter * 1e-6, task_id, data, metadata or {})
self._entry_map[task_id] = entry
heapq.heappush(self._heap, entry)
self._counter += 1
def pop(self) -> Optional[Tuple]:
with self._lock:
while self._heap:
entry = heapq.heappop(self._heap)
if entry[2] not in self._removed:
del self._entry_map[entry[2]]
return entry[2], entry[3], entry[4]
self._removed.discard(entry[2])
return None
def remove(self, task_id: str) -> bool:
with self._lock:
if task_id in self._entry_map:
self._removed.add(task_id)
del self._entry_map[task_id]
return True
return False
def __len__(self) -> int:
with self._lock:
return len(self._entry_map)
def is_empty(self) -> bool:
return len(self) == 0
# ==================== 资源池 ====================
class ResourcePool:
"""统一资源池管理器"""
def __init__(self, cpu_cores: float = 8.0, memory_mb: int = 16384):
self._total_quota = ResourceQuota(cpu_cores, memory_mb)
self._available_quota = ResourceQuota(cpu_cores, memory_mb)
self._allocations: Dict[str, ResourceQuota] = {}
self._lock = threading.RLock()
def acquire(self, task_id: str, quota: ResourceQuota) -> bool:
with self._lock:
if self._available_quota.can_accommodate(quota):
self._allocations[task_id] = quota
self._available_quota = self._available_quota - quota
return True
return False
def release(self, task_id: str) -> None:
with self._lock:
if task_id in self._allocations:
self._available_quota = self._available_quota + self._allocations[task_id]
del self._allocations[task_id]
@property
def available_cpu(self) -> float:
return self._available_quota.cpu_cores
@property
def available_memory(self) -> int:
return self._available_quota.memory_mb
# ==================== 重试管理器 ====================
class RetryConfig:
def __init__(self, max_retries: int = 3, base_delay: float = 1.0,
max_delay: float = 60.0, exponential_base: float = 2.0,
jitter: bool = True):
self.max_retries = max_retries
self.base_delay = base_delay
self.max_delay = max_delay
self.exponential_base = exponential_base
self.jitter = jitter
class RetryManager:
"""重试管理器"""
def __init__(self):
self._active_retries: Dict[str, int] = defaultdict(int)
self._lock = threading.RLock()
def should_retry(self, task_id: str, config: RetryConfig) -> bool:
with self._lock:
return self._active_retries[task_id] < config.max_retries
def record_retry(self, task_id: str) -> int:
with self._lock:
self._active_retries[task_id] += 1
return self._active_retries[task_id]
def reset(self, task_id: str) -> None:
with self._lock:
self._active_retries.pop(task_id, None)
def get_backoff_delay(self, attempt: int, config: RetryConfig) -> float:
delay = config.base_delay * (config.exponential_base ** attempt)
delay = min(delay, config.max_delay)
if config.jitter:
delay += random.uniform(-delay * 0.1, delay * 0.1)
return max(0, delay)
# ==================== 监控指标 ====================
class SchedulerMetrics:
"""调度器指标收集器"""
def __init__(self):
self._counters: Dict[str, float] = defaultdict(float)
self._gauges: Dict[str, float] = {}
self._histograms: Dict[str, deque] = defaultdict(lambda: deque(maxlen=1000))
self._lock = threading.RLock()
def inc_counter(self, name: str, value: float = 1.0) -> None:
with self._lock:
self._counters[name] += value
def set_gauge(self, name: str, value: float) -> None:
with self._lock:
self._gauges[name] = value
def observe_histogram(self, name: str, value: float) -> None:
with self._lock:
self._histograms[name].append(value)
def get_metrics(self) -> Dict[str, Any]:
with self._lock:
return {
"counters": dict(self._counters),
"gauges": dict(self._gauges),
"histograms": {k: len(v) for k, v in self._histograms.items()}
}
# ==================== 协程调度器 ====================
class CoroutineScheduler:
"""
高性能协程任务调度器
完整实现见第8节
"""
def __init__(self, max_concurrent: int = 100, cpu_cores: float = 4.0,
memory_mb: int = 8192, default_timeout: float = 60.0):
self._max_concurrent = max_concurrent
self._default_timeout = default_timeout
self._queue = SchedulerPriorityQueue()
self._resource_pool = ResourcePool(cpu_cores, memory_mb)
self._running_tasks: Dict[str, asyncio.Task] = {}
self._task_statuses: Dict[str, TaskStatus] = {}
self._task_results: Dict[str, Any] = {}
self._task_errors: Dict[str, str] = {}
self._lock = threading.Lock()
self._loop: Optional[asyncio.AbstractEventLoop] = None
self._running = False
self._metrics = SchedulerMetrics()
def start(self) -> None:
if self._running:
return
self._running = True
self._loop = asyncio.new_event_loop()
asyncio.set_event_loop(self._loop)
self._loop.run_in_executor(None, self._dispatch_loop)
def stop(self) -> None:
self._running = False
if self._loop:
self._loop.call_soon_threadsafe(self._loop.stop)
def submit(self, coro_func: Callable, *args, priority: int = 2,
cpu_cores: float = 1.0, memory_mb: int = 256,
timeout: Optional[float] = None, **kwargs) -> str:
task_id = str(uuid.uuid4())
self._queue.add(task_id, (coro_func, args, kwargs), priority)
self._task_statuses[task_id] = TaskStatus.PENDING
self._metrics.inc_counter("tasks_submitted")
return task_id
def _dispatch_loop(self) -> None:
while self._running:
with self._lock:
if len(self._running_tasks) >= self._max_concurrent:
time.sleep(0.01)
continue
result = self._queue.pop()
if not result:
time.sleep(0.01)
continue
task_id, (coro_func, args, kwargs), _ = result
quota = ResourceQuota(cpu_cores=1.0, memory_mb=256)
if not self._resource_pool.acquire(task_id, quota):
self._queue.add(task_id, (coro_func, args, kwargs), priority=2)
time.sleep(0.1)
continue
asyncio_coro = self._execute_task(task_id, coro_func, args, kwargs)
future = asyncio.run_coroutine_threadsafe(asyncio_coro, self._loop)
with self._lock:
self._running_tasks[task_id] = future
self._task_statuses[task_id] = TaskStatus.RUNNING
async def _execute_task(self, task_id: str, coro_func: Callable,
args: tuple, kwargs: dict) -> None:
try:
if self._default_timeout:
result = await asyncio.wait_for(
coro_func(*args, **kwargs),
timeout=self._default_timeout
)
else:
result = await coro_func(*args, **kwargs)
self._task_results[task_id] = result
self._task_statuses[task_id] = TaskStatus.COMPLETED
self._metrics.inc_counter("tasks_completed")
except Exception as e:
self._task_errors[task_id] = str(e)
self._task_statuses[task_id] = TaskStatus.FAILED
self._metrics.inc_counter("tasks_failed")
finally:
self._resource_pool.release(task_id)
with self._lock:
self._running_tasks.pop(task_id, None)
def get_task_result(self, task_id: str) -> Tuple[Any, Optional[str], TaskStatus]:
status = self._task_statuses.get(task_id, TaskStatus.PENDING)
result = self._task_results.get(task_id)
error = self._task_errors.get(task_id)
return result, error, status
def get_metrics(self) -> Dict[str, Any]:
return self._metrics.get_metrics()
# ==================== 使用示例 ====================
async def example_task(name: str, duration: float) -> str:
"""示例任务"""
await asyncio.sleep(duration)
return f"Task {name} completed after {duration}s"
if __name__ == "__main__":
scheduler = CoroutineScheduler(max_concurrent=10)
scheduler.start()
# 提交任务
task_id = scheduler.submit(
example_task,
"test_task",
1.0,
priority=TaskPriority.NORMAL.value
)
# 等待结果
time.sleep(2)
result, error, status = scheduler.get_task_result(task_id)
print(f"Result: {result}, Error: {error}, Status: {status}")
scheduler.stop()关键词: 任务调度、优先级队列、资源池、协程调度、超时控制、失败重试、监控告警、MLFQ、指数退避、SLA、Job、Task、Step、AI IDE、并发控制

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号