消息队列:异步任务与系统解耦


作者: HOS(安全风信子) 日期: 2026-05-25 主要来源平台: GitHub 摘要: 消息队列是AI IDE工程系统的神经网络,负责连接前端与后端、同步与异步任务、多服务之间的通信。本文系统讲解消息队列的核心设计:队列模型( FIFO、Priority、Dead Letter)、消息格式(JSON、Protobuf、Avro)、投递语义(At Most Once、At Least Once、Exactly Once)、消费者组与负载均衡、顺序保证与分区策略。最后通过Redis Streams实现一个完整的轻量级任务队列作为实践案例,对比RabbitMQ、Kafka、Redis Streams的适用场景,为构建弹性的AI IDE后端提供可落地的技术方案。
目录- 1 引言:消息队列在AI IDE系统中的角色
- 2 队列模型:FIFO、Priority、Dead Letter
- 2.1 FIFO队列:先入先出的基本模型
- 2.2 Priority队列:优先级驱动的任务调度
- 2.3 Dead Letter队列:故障消息的最终归宿
- 3 消息格式:JSON、Protocol Buffers、Apache Avro
- 3.1 JSON:可读性与灵活性的平衡
- 3.2 Protocol Buffers:高性能与版本管理
- 3.3 Apache Avro:动态Schema与数据压缩
- 3.4 消息格式选型决策树
- 4 投递语义:At Most Once、At Least Once、Exactly Once
- 4.1 At Most Once:追求性能的代价
- 4.2 At Least Once:可靠性与重复处理的权衡
- 4.3 Exactly Once:理论与实践的鸿沟
- 5 消费者组:负载均衡与分区策略
- 5.1 消费者组模型
- 5.2 负载均衡策略
- 5.2.1 轮询分配(Round Robin)
- 5.2.2 最小消费者优先(Least Backlog First)
- 5.3 分区策略:消息路由的核心
- 5.3.1 按键哈希分区
- 5.4 分区数与消费者数的关系
- 6 顺序保证:分区有序与全局有序的权衡
- 6.1 顺序保证的三个层次
- 6.2 分区有序的实现
- 6.3 全局有序的代价
- 6.4 顺序保证的工程实践
- 7 实践:使用Redis Streams实现轻量级任务队列
- 7.1 Redis Streams架构
- 7.2 完整实现代码
- 7.3 监控与管理
- 8 消息队列对比选型:RabbitMQ、Kafka、Redis Streams
- 8.1 核心特性对比
- 8.2 适用场景分析
- 8.3 AI IDE场景选型建议
- 9 工程实践:构建弹性的AI IDE后端
- 9.1 架构设计原则
- 9.2 完整架构示例
- 9.3 关键实现代码
- 10 总结与展望
- 10.1 核心要点总结
- 10.2 技术选型决策树
- 10.3 未来发展趋势
- 10.4 最佳实践清单
- 参考链接
- A. Redis Streams完整命令参考
- B. 性能基准测试脚本
- C. 常见问题排查指南
- 2.1 FIFO队列:先入先出的基本模型
- 2.2 Priority队列:优先级驱动的任务调度
- 2.3 Dead Letter队列:故障消息的最终归宿
- 3.1 JSON:可读性与灵活性的平衡
- 3.2 Protocol Buffers:高性能与版本管理
- 3.3 Apache Avro:动态Schema与数据压缩
- 3.4 消息格式选型决策树
- 4.1 At Most Once:追求性能的代价
- 4.2 At Least Once:可靠性与重复处理的权衡
- 4.3 Exactly Once:理论与实践的鸿沟
- 5.1 消费者组模型
- 5.2 负载均衡策略
- 5.2.1 轮询分配(Round Robin)
- 5.2.2 最小消费者优先(Least Backlog First)
- 5.3 分区策略:消息路由的核心
- 5.3.1 按键哈希分区
- 5.4 分区数与消费者数的关系
- 6.1 顺序保证的三个层次
- 6.2 分区有序的实现
- 6.3 全局有序的代价
- 6.4 顺序保证的工程实践
- 7.1 Redis Streams架构
- 7.2 完整实现代码
- 7.3 监控与管理
- 8.1 核心特性对比
- 8.2 适用场景分析
- 8.3 AI IDE场景选型建议
- 9.1 架构设计原则
- 9.2 完整架构示例
- 9.3 关键实现代码
- 10.1 核心要点总结
- 10.2 技术选型决策树
- 10.3 未来发展趋势
- 10.4 最佳实践清单
1 引言:消息队列在AI IDE系统中的角色
本节为你提供的核心价值:理解消息队列作为AI IDE系统神经网络的定位,明确其在异步解耦、流量削峰、事件驱动架构中的不可替代性。
在传统的单体架构中,模块之间的调用是同步的、紧耦合的。当用户在前端触发一个复杂的AI任务(如代码分析、语义搜索、大规模重构)时,后端服务必须等待该任务完成后才能响应用户。这种模式在AI IDE场景下面临严峻挑战:
- AI任务耗时不确定:一次完整的代码库分析可能耗时数秒到数分钟不等
- 资源竞争激烈:多个并发任务同时占用计算资源,导致响应延迟
- 服务耦合严重:前端服务必须了解后端任务的执行细节
消息队列的出现彻底改变了这一局面。通过引入异步通信层,前端只需将任务描述发送到队列,无需等待执行完成;后端服务从队列中获取任务,按自身节奏处理。这种模式带来了三大核心价值:
- 时间解耦:发送者和接收者无需同时在线
- 空间解耦:发送者和接收者无需知道彼此的存在
- 速率解耦:生产速度和消费速度可以不同
在AI IDE工程系统中,消息队列承担着以下关键职责:
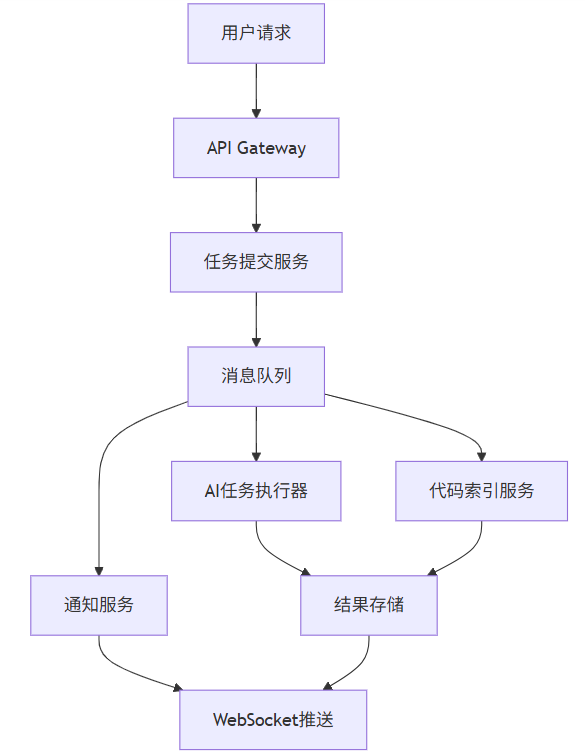
上图展示了AI IDE系统中消息队列的核心地位。从用户发起请求到最终获取结果,所有关键路径都围绕消息队列展开。API Gateway接收请求后,立即将任务投入队列并返回任务ID给前端;后台的多个消费者(AI任务执行器、代码索引服务、通知服务)并行从队列获取任务,实现了真正的异步处理。
在接下来的章节中,我们将从队列模型、消息格式、投递语义、消费者组、顺序保证五个维度深入剖析消息队列的设计要点,最后通过Redis Streams实现一个完整的轻量级任务队列。
2 队列模型:FIFO、Priority、Dead Letter
本节为你提供的核心价值:掌握三种核心队列模型的适用场景,理解死信队列在故障处理和消息追溯中的关键作用。
2.1 FIFO队列:先入先出的基本模型
FIFO(First In, First Out)是消息队列最基础的模型,确保消息按照提交顺序被处理。在AI IDE场景中,FIFO适用于:
- 任务调度:用户提交的任务按顺序执行,避免资源竞争
- 日志收集:审计日志必须严格按时间顺序记录
- 事务消息:需要保证操作顺序的场景
FIFO队列的实现原理相对简单:队列头部是最早进入的消息,每次消费都从头部取走。下图展示了FIFO队列的基本操作:
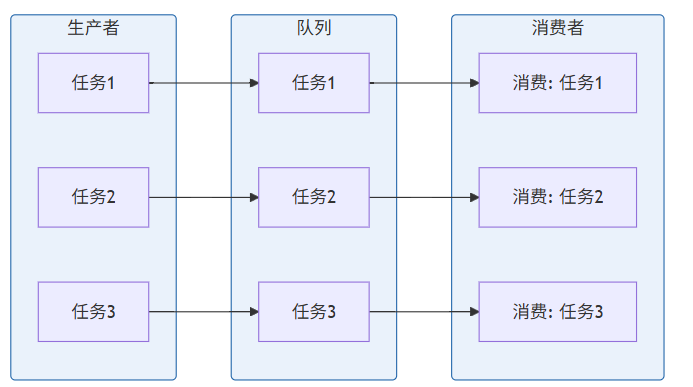
关键结论:FIFO队列保证了消息的顺序性,但无法保证消息的及时性。如果队首任务耗时较长,后续任务将被阻塞。
2.2 Priority队列:优先级驱动的任务调度
在AI IDE系统中,不是所有任务都同等重要。用户的即时编辑操作需要毫秒级响应,而后台代码分析任务可以接受较长的延迟。Priority队列解决了这一问题。
Priority队列允许消息带有优先级属性,高优先级的消息总是被优先消费。典型的实现方式有两种:
- 多队列模式:每个优先级对应一个队列,消费者优先从高优先级队列获取
- 堆结构模式:使用最小堆/最大堆维护优先级顺序
import heapq
from dataclasses import dataclass, field
from typing import Any, Optional
import time
import uuid
@dataclass(order=True)
class PriorityMessage:
"""优先队列消息封装"""
priority: int = field(compare=True) # 优先级,数值越小越先被消费
timestamp: float = field(compare=True) # 时间戳用于同优先级FIFO
message_id: str = field(compare=False, default_factory=lambda: str(uuid.uuid4()))
payload: Any = field(compare=False, default=None)
retry_count: int = field(compare=False, default=0)
max_retries: int = field(compare=False, default=3)
class PriorityQueue:
"""基于堆结构的优先级队列实现"""
def __init__(self):
self._heap = []
self._entry_finder = {} # message_id -> entry mapping for O(1)查找
self._removed = set() # 标记已删除的消息
def add(self, message_id: str, payload: Any, priority: int = 5) -> None:
"""
添加消息到优先级队列
Args:
message_id: 消息唯一标识
payload: 消息内容
priority: 优先级 (0-10, 0为最高优先级)
"""
if message_id in self._entry_finder:
self.remove(message_id)
entry = [priority, time.time(), message_id, payload, 0, 3]
self._entry_finder[message_id] = entry
heapq.heappush(self._heap, entry)
def remove(self, message_id: str) -> bool:
"""标记消息为已删除"""
if message_id in self._entry_finder:
self._removed.add(message_id)
del self._entry_finder[message_id]
return True
return False
def pop(self) -> Optional[tuple]:
"""
弹出最高优先级的消息
Returns:
(message_id, payload) or None if queue is empty
"""
while self._heap:
entry = heapq.heappop(self._heap)
if entry[2] not in self._removed:
del self._entry_finder[entry[2]]
return entry[2], entry[3] # message_id, payload
return None
def peek(self) -> Optional[tuple]:
"""查看最高优先级消息但不弹出"""
while self._heap:
entry = self._heap[0]
if entry[2] in self._removed:
heapq.heappop(self._heap)
continue
return entry[2], entry[3]
return None
def __len__(self) -> int:
return len(self._entry_finder)
def is_empty(self) -> bool:
return len(self) == 0
# 使用示例:AI IDE任务调度器
def demo_priority_queue():
"""演示在AI IDE场景下的优先级调度"""
queue = PriorityQueue()
# 模拟不同类型的任务
tasks = [
("task_001", {"type": "completion", "code": "func "}, 0), # 代码补全 - 最高优先级
("task_002", {"type": "analysis", "file": "main.py"}, 7), # 代码分析 - 低优先级
("task_003", {"type": "completion", "code": "class "}, 0), # 代码补全 - 最高优先级
("task_004", {"type": "indexing", "path": "/project"}, 9), # 索引构建 - 最低优先级
("task_005", {"type": "completion", "code": "import "}, 0), # 代码补全 - 最高优先级
]
# 添加所有任务
for task_id, payload, priority in tasks:
queue.add(task_id, payload, priority)
print(f"添加任务: {task_id}, 类型: {payload['type']}, 优先级: {priority}")
print(f"\n队列中共有 {len(queue)} 个任务")
print("\n按优先级顺序消费:")
while not queue.is_empty():
task_id, payload = queue.pop()
print(f"消费 -> {task_id}: {payload}")
if __name__ == "__main__":
demo_priority_queue()上述代码实现了一个基于最小堆的优先级队列。在AI IDE场景中,我们可以将用户交互操作(代码补全、语法高亮)设为最高优先级,后台分析任务设为低优先级。核心结论:优先级队列解决了任务紧急程度不同的问题,但引入了新的复杂度——需要合理设计优先级策略,否则可能导致低优先级任务长期饥饿。
2.3 Dead Letter队列:故障消息的最终归宿
在生产环境中,部分消息由于各种原因无法被正常消费:消息格式错误、消费者服务宕机、超时未响应等。如果这些"死信"消息停留在原队列中,会造成以下问题:
- 阻塞正常消息:死信占据队列位置,影响正常消息消费
- 丢失故障信息:无法追溯消息处理失败的原因
- 系统状态不一致:发送方不知道消息是否被处理
Dead Letter Queue(DLQ)专门用于收集处理失败的消息,其工作流程如下:
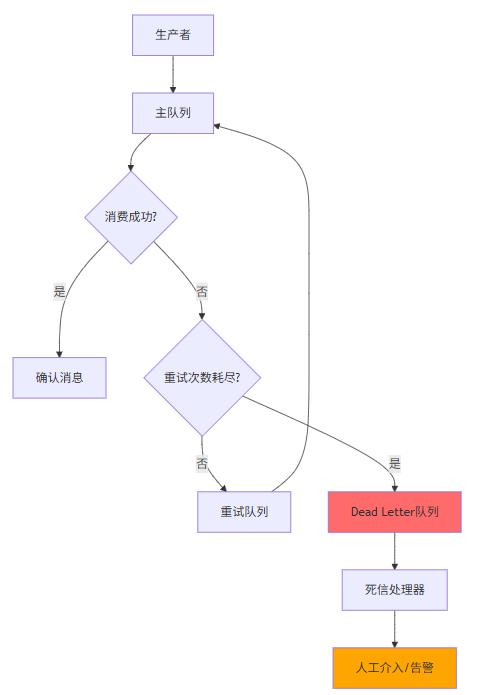
死信的产生场景:
场景 | 触发条件 | 处理策略 |
|---|---|---|
消息格式错误 | JSON解析失败、Schema不匹配 | 记录原始消息,人工修复 |
处理超时 | 消费者在设定时间内未确认 | 重试或投入DLQ |
消费者异常 | 消费者抛出不可恢复异常 | 记录堆栈,投入DLQ |
资源不足 | 内存不足、连接池耗尽 | 降级处理,最终投入DLQ |
消息过期 | TTL过期或消息已过期 | 直接投入DLQ |
关键结论:Dead Letter队列是消息队列系统可靠性的最后一道防线。合理的DLQ设计可以实现消息的可追溯性,同时为系统故障提供告警和人工介入的机会。
3 消息格式:JSON、Protocol Buffers、Apache Avro
本节为你提供的核心价值:根据场景选择合适的序列化格式,理解不同格式在性能、兼容性、可读性之间的权衡。
消息格式直接影响消息队列的传输效率、存储成本和系统兼容性。AI IDE系统需要处理大量结构化的任务描述和代码片段,消息格式的选择尤为关键。
3.1 JSON:可读性与灵活性的平衡
JSON(JavaScript Object Notation)是目前最广泛使用的数据交换格式。其核心优势在于:
- 人类可读:调试和日志分析非常方便
- 无模式依赖:无需预定义Schema即可解析
- 生态系统完善:几乎所有语言都原生支持
{
"message_id": "msg_8f7a6b5c4e3d2c1a",
"type": "task.submitted",
"timestamp": "2026-05-25T10:30:00.123Z",
"payload": {
"task_type": "code_analysis",
"priority": 5,
"params": {
"file_path": "/workspace/project/src/main.py",
"options": {
"deep_analysis": true,
"max_iterations": 100
}
},
"metadata": {
"user_id": "user_123",
"session_id": "session_abc",
"request_id": "req_xyz789"
}
}
}适用场景:
- 快速原型开发和调试
- 跨团队、跨语言的微服务通信
- 消息体较小、对可读性要求高的场景
不适用场景:
- 高吞吐量场景(JSON解析开销较大)
- 大文件传输(如完整的代码库内容)
- 需要严格类型校验的场景
3.2 Protocol Buffers:高性能与版本管理
Protocol Buffers(Protobuf)是Google推出的二进制序列化协议,相比JSON有显著的性能优势:
指标 | JSON | Protobuf | 提升幅度 |
|---|---|---|---|
序列化体积 | 100% | 30-50% | 2-3x smaller |
序列化速度 | 基准 | 5-10x faster | 5-10x |
反序列化速度 | 基准 | 3-5x faster | 3-5x |
// task.proto - AI IDE任务消息格式定义
syntax = "proto3";
package aide;
option java_package = "com.aide.messaging";
option java_multiple_files = true;
// 任务优先级枚举
enum TaskPriority {
PRIORITY_UNSPECIFIED = 0;
PRIORITY_CRITICAL = 1; // 代码补全等交互任务
PRIORITY_HIGH = 2; // 实时分析
PRIORITY_NORMAL = 3; // 标准任务
PRIORITY_LOW = 4; // 后台分析
PRIORITY_BATCH = 5; // 批量处理
}
// 任务类型枚举
enum TaskType {
TYPE_UNSPECIFIED = 0;
TYPE_CODE_COMPLETION = 1;
TYPE_CODE_ANALYSIS = 2;
TYPE_semantic_SEARCH = 3;
TYPE_REFACTORING = 4;
TYPE_INDEXING = 5;
TYPE_NOTIFICATION = 6;
}
// 任务消息
message TaskMessage {
string message_id = 1;
int64 timestamp = 2;
TaskType task_type = 3;
TaskPriority priority = 4;
TaskPayload payload = 5;
TaskMetadata metadata = 6;
}
// 任务载荷
message TaskPayload {
string file_path = 1;
string content = 2;
map<string, string> options = 3;
int32 max_retries = 4;
}
// 任务元数据
message TaskMetadata {
string user_id = 1;
string session_id = 2;
string request_id = 3;
map<string, string> tags = 4;
}
// 任务提交请求
message TaskSubmitRequest {
TaskType task_type = 1;
TaskPriority priority = 2;
TaskPayload payload = 3;
map<string, string> options = 4;
}
// 任务状态更新
message TaskStatusUpdate {
string message_id = 1;
TaskStatus status = 2;
int64 updated_at = 3;
string error_message = 4;
}
// 任务状态枚举
enum TaskStatus {
STATUS_UNSPECIFIED = 0;
STATUS_PENDING = 1;
STATUS_PROCESSING = 2;
STATUS_COMPLETED = 3;
STATUS_FAILED = 4;
STATUS_CANCELLED = 5;
}# Python中使用protobuf实现消息序列化/反序列化
from aide.messaging import task_pb2
import json
import time
class TaskMessageSerializer:
"""任务消息的Protobuf序列化器"""
@staticmethod
def serialize(task_message: task_pb2.TaskMessage) -> bytes:
"""将TaskMessage序列化为字节数组"""
return task_message.SerializeToString()
@staticmethod
def deserialize(data: bytes) -> task_pb2.TaskMessage:
"""从字节数组反序列化为TaskMessage"""
message = task_pb2.TaskMessage()
message.ParseFromString(data)
return message
@staticmethod
def from_dict(data: dict) -> task_pb2.TaskMessage:
"""从字典创建TaskMessage"""
message = task_pb2.TaskMessage()
message.message_id = data.get('message_id', '')
message.timestamp = data.get('timestamp', int(time.time() * 1000))
message.task_type = data.get('task_type', task_pb2.TYPE_UNSPECIFIED)
message.priority = data.get('priority', task_pb2.PRIORITY_NORMAL)
# 填充payload
if 'payload' in data:
payload = message.payload
payload.file_path = data['payload'].get('file_path', '')
payload.content = data['payload'].get('content', '')
for k, v in data['payload'].get('options', {}).items():
payload.options[k] = v
# 填充metadata
if 'metadata' in data:
metadata = message.metadata
metadata.user_id = data['metadata'].get('user_id', '')
metadata.session_id = data['metadata'].get('session_id', '')
metadata.request_id = data['metadata'].get('request_id', '')
for k, v in data['metadata'].get('tags', {}).items():
metadata.tags[k] = v
return message
@staticmethod
def to_dict(message: task_pb2.TaskMessage) -> dict:
"""将TaskMessage转换为字典(用于日志/调试)"""
return {
'message_id': message.message_id,
'timestamp': message.timestamp,
'task_type': task_pb2.TaskType.Name(message.task_type),
'priority': task_pb2.TaskPriority.Name(message.priority),
'payload': {
'file_path': message.payload.file_path,
'content': message.payload.content[:100] + '...' if len(message.payload.content) > 100 else message.payload.content,
'options': dict(message.payload.options),
},
'metadata': {
'user_id': message.metadata.user_id,
'session_id': message.metadata.session_id,
'request_id': message.metadata.request_id,
'tags': dict(message.metadata.tags),
}
}
# 使用示例
def demo_protobuf_serialization():
"""演示Protobuf序列化"""
# 创建任务消息
original = task_pb2.TaskMessage()
original.message_id = "msg_8f7a6b5c"
original.timestamp = int(time.time() * 1000)
original.task_type = task_pb2.TYPE_CODE_ANALYSIS
original.priority = task_pb2.PRIORITY_HIGH
original.payload.file_path = "/workspace/project/main.py"
original.payload.content = "def main():\n print('Hello, World!')"
original.payload.options["deep_analysis"] = "true"
original.metadata.user_id = "user_123"
original.metadata.session_id = "session_abc"
# 序列化
serializer = TaskMessageSerializer()
serialized = serializer.serialize(original)
print(f"Protobuf序列化后字节数: {len(serialized)}")
# 反序列化
deserialized = serializer.deserialize(serialized)
print(f"反序列化成功: {deserialized.message_id}")
print(f"任务类型: {task_pb2.TaskType.Name(deserialized.task_type)}")
# 转换为字典(调试用)
as_dict = serializer.to_dict(deserialized)
print(f"转换为字典: {json.dumps(as_dict, indent=2)}")
# 与JSON对比
json_bytes = json.dumps(as_dict).encode('utf-8')
print(f"\nJSON序列化后字节数: {len(json_bytes)}")
print(f"Protobuf节省空间: {(1 - len(serialized) / len(json_bytes)) * 100:.1f}%")
if __name__ == "__main__":
demo_protobuf_serialization()核心结论:Protobuf在AI IDE这种高吞吐量场景中具有明显优势。其二进制格式减少了网络传输和存储开销,强类型定义避免了运行时类型错误。
3.3 Apache Avro:动态Schema与数据压缩
Apache Avro是Apache顶级项目,专为大数据场景设计。与Protobuf的主要区别在于:
- Schema内嵌于数据:数据自描述,无需预加载Schema文件
- 动态Schema:可以在运行时改变数据结构
- 更紧凑的二进制格式:去除字段标签,只保留位置信息
Avro的典型应用场景是大规模日志采集和实时流处理。在AI IDE场景中,如果需要处理海量的代码变更事件流,Avro是一个值得考虑的选择。
3.4 消息格式选型决策树
渲染错误: Mermaid 渲染失败: Parse error on line 2: ...消息格式] --> B{对可读性要求高?] B -->|是| C[JSO -----------------------^ Expecting 'DIAMOND_STOP', 'TAGEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'SQE'
4 投递语义:At Most Once、At Least Once、Exactly Once
本节为你提供的核心价值:理解三种投递语义的本质区别,根据业务需求选择合适的语义,避免数据丢失或重复处理。
投递语义是消息队列最核心的概念之一。它描述了消息从生产者到消费者的过程中,消息传递的可靠性保证。
4.1 At Most Once:追求性能的代价
语义定义:消息最多被投递一次,可能丢失,但不会重复。
实现原理:生产者在发送消息后,不等待消费者的确认,直接标记消息发送完成。如果消费者未能及时处理,消息将被丢弃。
生产者: 发送消息 ──────────────────────────> 队列 ──────────────────────────> 消费者
│ │
└─ 不等待确认 ────────────────────────────────────────────────────────┘代码实现:
import asyncio
from typing import Callable, Any, Optional
import time
import uuid
class AtMostOncePublisher:
"""
At Most Once 投递语义实现
特点:
- Fire-and-forget 模式
- 不等待消费者确认
- 消息可能丢失,但不重复
"""
def __init__(self, queue_backend):
self.queue = queue_backend
self.published_count = 0
self.dropped_count = 0
async def publish(self, topic: str, message: dict) -> str:
"""
发布消息,不等待确认
Args:
topic: 主题名称
message: 消息内容
Returns:
message_id: 消息ID,用于追踪
"""
message_id = f"msg_{uuid.uuid4().hex[:12]}"
# 添加元数据
enriched_message = {
"message_id": message_id,
"timestamp": time.time(),
"payload": message,
"delivery_mode": "at_most_once"
}
try:
# 直接发送到队列,不等待确认
await self.queue.push(topic, enriched_message)
self.published_count += 1
print(f"[AtMostOnce] 发送消息 {message_id} 到 {topic}")
except Exception as e:
self.dropped_count += 1
print(f"[AtMostOnce] 消息发送失败 {message_id}: {e}")
raise
return message_id
class AtMostOnceConsumer:
"""
At Most Once 消费语义实现
特点:
- 消费后立即确认,不等待处理完成
- 如果处理失败,消息已确认,无法重试
"""
def __init__(self, queue_backend):
self.queue = queue_backend
self.processed_count = 0
self.failed_count = 0
async def consume(self, topic: str, handler: Callable[[dict], Any]) -> None:
"""
消费消息,处理后立即确认
Args:
topic: 主题名称
handler: 消息处理函数
"""
while True:
try:
# 获取消息(非阻塞)
message = await self.queue.pop(topic)
if message is None:
await asyncio.sleep(0.01) # 避免CPU空转
continue
message_id = message.get("message_id")
try:
# 处理消息
await handler(message["payload"])
self.processed_count += 1
print(f"[AtMostOnce] 处理成功 {message_id}")
except Exception as e:
# 处理失败,但不重试(因为消息已被消费)
self.failed_count += 1
print(f"[AtMostOnce] 处理失败 {message_id}: {e}")
finally:
# 立即确认消息已被消费
await self.queue.ack(topic, message_id)
except Exception as e:
print(f"[AtMostOnce] 消费异常: {e}")
await asyncio.sleep(1)
async def demo_at_most_once():
"""演示At Most Once投递语义"""
# 模拟队列后端
class MockQueue:
def __init__(self):
self.data = {}
async def push(self, topic, message):
if topic not in self.data:
self.data[topic] = []
self.data[topic].append(message)
async def pop(self, topic):
if topic in self.data and self.data[topic]:
return self.data[topic].pop(0)
return None
async def ack(self, topic, message_id):
pass # At Most Once不需要确认
mock = MockQueue()
publisher = AtMostOncePublisher(mock)
# 发布消息
for i in range(5):
await publisher.publish("ai.tasks", {
"task_id": f"task_{i}",
"action": "code_completion"
})
print(f"\n统计: 发送 {publisher.published_count}, 丢弃 {publisher.dropped_count}")
if __name__ == "__main__":
asyncio.run(demo_at_most_once())适用场景:
- 实时性要求高、可容忍少量丢失的场景
- 监控指标采集
- 日志收集(丢失几条无关紧要)
- 视频/音频流处理
不适用场景:
- 支付、订单等关键业务
- 数据同步任务
- 任何不能丢失的消息
4.2 At Least Once:可靠性与重复处理的权衡
语义定义:消息至少被投递一次,不会丢失,但可能重复。
实现原理:生产者发送消息后,等待消费者确认。如果消费者未在规定时间内确认,生产者将重新发送。消费者需要实现幂等逻辑来处理重复消息。
生产者: 发送消息 ──────────────────────────> 队列 ──────────────────────────> 消费者
│ │
│<─────────────── 确认超时,重新发送 ────────────────────────────────┤代码实现:
import asyncio
from typing import Callable, Any, Optional, Dict
import time
import uuid
import hashlib
class AtLeastOncePublisher:
"""
At Least Once 投递语义实现
特点:
- 等待消费者确认
- 确认超时则重发
- 消息不丢失,但可能重复
"""
def __init__(self, queue_backend, max_retries: int = 3, timeout: float = 5.0):
self.queue = queue_backend
self.max_retries = max_retries
self.timeout = timeout
self.pending_messages: Dict[str, asyncio.Future] = {}
async def publish(self, topic: str, message: dict) -> str:
"""
发布消息并等待确认
Args:
topic: 主题名称
message: 消息内容
Returns:
message_id: 消息ID
"""
message_id = f"msg_{uuid.uuid4().hex[:12]}"
enriched_message = {
"message_id": message_id,
"timestamp": time.time(),
"payload": message,
"delivery_mode": "at_least_once",
"retry_count": 0
}
# 创建未来用于接收确认
confirm_future = asyncio.Future()
self.pending_messages[message_id] = confirm_future
try:
# 发送到队列
await self.queue.push(topic, enriched_message)
print(f"[AtLeastOnce] 发送消息 {message_id} 到 {topic}")
# 等待确认
try:
confirmed = await asyncio.wait_for(
confirm_future,
timeout=self.timeout
)
if confirmed:
print(f"[AtLeastOnce] 消息 {message_id} 已确认")
except asyncio.TimeoutError:
print(f"[AtLeastOnce] 消息 {message_id} 确认超时,准备重试")
# 这里可以触发重试逻辑
raise
finally:
self.pending_messages.pop(message_id, None)
return message_id
def on_confirm(self, message_id: str, success: bool) -> None:
"""收到确认通知"""
if message_id in self.pending_messages:
future = self.pending_messages[message_id]
if not future.done():
future.set_result(success)
class AtLeastOnceConsumer:
"""
At Least Once 消费语义实现
特点:
- 消息处理完成后才确认
- 支持重试
- 需要实现幂等逻辑
"""
def __init__(self, queue_backend, idempotency_store: Optional[Dict] = None):
self.queue = queue_backend
self.processed_ids: set = idempotency_store or set() # 幂等性存储
self.processed_count = 0
self.duplicate_count = 0
def _generate_dedup_key(self, message: dict) -> str:
"""生成去重键"""
content = f"{message.get('message_id')}:{message.get('timestamp')}"
return hashlib.sha256(content.encode()).hexdigest()[:16]
async def consume(self, topic: str, handler: Callable[[dict], Any]) -> None:
"""
消费消息,处理完成后确认
Args:
topic: 主题名称
handler: 消息处理函数(必须是幂等的)
"""
while True:
try:
message = await self.queue.pop(topic)
if message is None:
await asyncio.sleep(0.01)
continue
message_id = message.get("message_id")
dedup_key = self._generate_dedup_key(message)
# 幂等性检查
if dedup_key in self.processed_ids:
self.duplicate_count += 1
print(f"[AtLeastOnce] 检测到重复消息 {message_id},跳过处理")
await self.queue.ack(topic, message_id)
continue
# 处理消息
try:
await handler(message["payload"])
self.processed_count += 1
# 标记为已处理
self.processed_ids.add(dedup_key)
print(f"[AtLeastOnce] 处理成功 {message_id}")
except Exception as e:
print(f"[AtLeastOnce] 处理失败 {message_id}: {e}")
# 可以选择重试或投入DLQ
raise
finally:
# 处理完成后确认
await self.queue.ack(topic, message_id)
except Exception as e:
print(f"[AtLeastOnce] 消费异常: {e}")
await asyncio.sleep(1)
async def demo_at_least_once():
"""演示At Least Once投递语义"""
# 模拟队列后端
class MockQueue:
def __init__(self):
self.data = {}
self.acks = {} # message_id -> True 表示已确认
async def push(self, topic, message):
if topic not in self.data:
self.data[topic] = []
self.data[topic].append(message)
async def pop(self, topic):
if topic in self.data and self.data[topic]:
return self.data[topic].pop(0)
return None
async def ack(self, topic, message_id):
self.acks[message_id] = True
print(f"[Queue] 消息 {message_id} 已确认")
mock = MockQueue()
publisher = AtLeastOncePublisher(mock)
# 发布消息
for i in range(3):
try:
await publisher.publish("ai.tasks", {
"task_id": f"task_{i}",
"action": "code_analysis",
"data": f"content_{i}"
})
except Exception as e:
print(f"发布失败: {e}")
print(f"\n处理统计: 成功 {publisher.published_count}")
if __name__ == "__main__":
asyncio.run(demo_at_least_once())适用场景:
- 绝大多数业务场景
- 订单处理、任务调度
- 数据同步和事件驱动架构
关键结论:At Least Once是实际应用中最常用的投递语义。其核心挑战在于消费者必须实现幂等逻辑,否则重复消息会导致数据不一致。
4.3 Exactly Once:理论与实践的鸿沟
语义定义:消息恰好被处理一次,不丢失,不重复。
实现难度:Exactly Once是理论上最难实现的语义。在分布式系统中,同时满足"不丢失"和"不重复"需要分布式事务支持,开销极大。
业界实现方案:
方案 | 原理 | 开销 | 适用场景 |
|---|---|---|---|
两阶段提交 | 预提交+确认 | 极高 | 银行转账 |
Saga模式 | 补偿事务 | 高 | 分布式事务 |
幂等消费者 + At Least Once | 重试+去重 | 中 | 大多数业务 |
Kafka的Exactly Once语义:Kafka通过以下机制实现了Exactly Once:
- 幂等生产者:每个生产者有一个唯一ID,消息带有序列号,broker去重
- 事务性消费:消费和提交在同一事务中
class ExactlyOnceKafkaConsumer:
"""
Kafka Exactly Once 消费实现
关键机制:
1. 消费者先处理消息,不提交offset
2. 处理成功后,在同一事务中提交offset和业务数据
3. 事务失败则回滚,不提交offset,消息会被重新消费
"""
def __init__(self, kafka_config: dict, transaction_config: dict):
self.config = kafka_config
self.transaction_config = transaction_config
self.consumer = None
self.producer = None
def _init_clients(self):
"""初始化Kafka客户端"""
from kafka import KafkaConsumer, KafkaProducer
self.consumer = KafkaConsumer(
bootstrap_servers=self.config['bootstrap_servers'],
group_id=self.config['group_id'],
enable_auto_commit=False, # 关闭自动提交
isolation_level='read_committed' # 只读取已提交的事务
)
self.producer = KafkaProducer(
bootstrap_servers=self.config['bootstrap_servers'],
acks='all', # 等待所有副本确认
enable_idempotence=True # 启用幂等性
)
async def consume_with_exactly_once(
self,
topic: str,
handler: Callable[[dict], None]
) -> None:
"""
Exactly Once 消费
Args:
topic: 主题
handler: 消息处理函数(必须幂等)
"""
self._init_clients()
while True:
records = self.consumer.poll(timeout_ms=1000)
for tp, messages in records.items():
for message in messages:
try:
# 开启事务
with self.transaction_config['transaction_manager']() as tx:
# 处理业务数据
await handler(message.value)
# 提交offset和业务数据
tx.commit()
print(f"Exactly Once 处理成功: {message.offset}")
except Exception as e:
print(f"处理失败,offset将回滚: {e}")
# 事务回滚,offset不会提交,下次重新消费
raise核心结论:Exactly Once的开销最高,不应作为默认选择。只有在支付、金融等对数据一致性要求极高的场景才需要考虑。对于AI IDE系统中的大多数任务,At Least Once + 幂等消费者是更实际的方案。
5 消费者组:负载均衡与分区策略
本节为你提供的核心价值:掌握消费者组的原理,理解分区数与消费者数的关系,设计高效的负载均衡策略。
5.1 消费者组模型
消费者组(Consumer Group)是消息队列实现负载均衡的核心机制。同一消费者组内的消费者实例分担主题的消息,不同消费者组独立消费,互不影响。
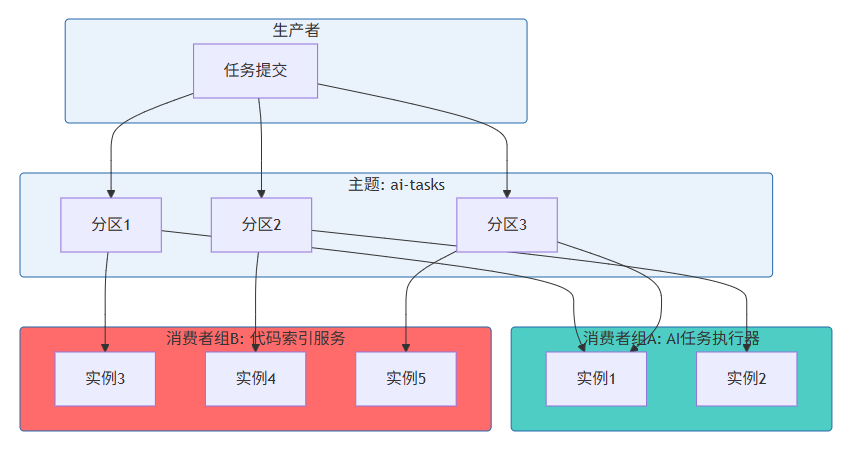
5.2 负载均衡策略
5.2.1 轮询分配(Round Robin)
最简单的分配策略,将消息轮流分配给消费者。
分区序列: [0, 1, 2, 3, 4, 5, 6, 7]
消费者: [C1, C2, C3]
分配结果:
C1 -> [0, 3, 6]
C2 -> [1, 4, 7]
C3 -> [2, 5]优点:实现简单,负载大致均匀 缺点:不考虑消费者处理能力的差异
5.2.2 最小消费者优先(Least Backlog First)
新消息分配给当前积压最少(处理最快)的消费者。
class LeastBacklogLoadBalancer:
"""
最小积压优先负载均衡器
核心思想:将新消息分配给当前处理任务最少的消费者
适用于消费者处理能力差异较大的场景
"""
def __init__(self):
self.consumer_backlog: Dict[str, int] = {} # consumer_id -> pending_tasks
self.consumer_capacity: Dict[str, int] = {} # consumer_id -> max_capacity
def register_consumer(self, consumer_id: str, max_capacity: int = 10) -> None:
"""注册消费者"""
self.consumer_backlog[consumer_id] = 0
self.consumer_capacity[consumer_id] = max_capacity
def unregister_consumer(self, consumer_id: str) -> None:
"""注销消费者"""
self.consumer_backlog.pop(consumer_id, None)
self.consumer_capacity.pop(consumer_id, None)
def assign_partition(self, partition_id: str) -> str:
"""
为分区分配消费者
使用加权最小积压算法:
1. 计算每个消费者的负载率 (backlog / capacity)
2. 选择负载率最低的消费者
"""
if not self.consumer_backlog:
raise ValueError("没有可用的消费者")
min_load_ratio = float('inf')
selected_consumer = None
for consumer_id in self.consumer_backlog:
backlog = self.consumer_backlog[consumer_id]
capacity = self.consumer_capacity[consumer_id]
load_ratio = backlog / capacity if capacity > 0 else float('inf')
if load_ratio < min_load_ratio:
min_load_ratio = load_ratio
selected_consumer = consumer_id
# 增加选中消费者的积压
self.consumer_backlog[selected_consumer] += 1
print(f"分区 {partition_id} -> 消费者 {selected_consumer} "
f"(负载率: {min_load_ratio:.2f}, 积压: {self.consumer_backlog[selected_consumer]})")
return selected_consumer
def on_task_complete(self, consumer_id: str) -> None:
"""任务完成时调用,减少消费者的积压"""
if consumer_id in self.consumer_backlog and self.consumer_backlog[consumer_id] > 0:
self.consumer_backlog[consumer_id] -= 1
def get_load_distribution(self) -> Dict[str, float]:
"""获取当前负载分布"""
result = {}
for consumer_id, backlog in self.consumer_backlog.items():
capacity = self.consumer_capacity[consumer_id]
result[consumer_id] = {
'backlog': backlog,
'capacity': capacity,
'load_ratio': backlog / capacity if capacity > 0 else 0
}
return result
def demo_load_balancer():
"""演示负载均衡器"""
balancer = LeastBacklogLoadBalancer()
# 注册消费者(不同容量)
balancer.register_consumer("worker_1", max_capacity=5) # 小型worker
balancer.register_consumer("worker_2", max_capacity=10) # 中型worker
balancer.register_consumer("worker_3", max_capacity=20) # 大型worker
print("模拟分配12个分区:\n")
for i in range(12):
balancer.assign_partition(f"partition_{i}")
print("\n\n最终负载分布:")
distribution = balancer.get_load_distribution()
for consumer, stats in distribution.items():
print(f" {consumer}: 积压 {stats['backlog']}/{stats['capacity']}, "
f"负载率 {stats['load_ratio']*100:.1f}%")
if __name__ == "__main__":
demo_load_balancer()运行结果:
模拟分配12个分区:
分区 partition_0 -> 消费者 worker_1 (负载率: 0.00, 积压: 1)
分区 partition_1 -> 消费者 worker_2 (负载率: 0.00, 积压: 1)
分区 partition_2 -> 消费者 worker_3 (负载率: 0.00, 积压: 1)
分区 partition_3 -> 消费者 worker_1 (负载率: 0.20, 积压: 2)
...5.3 分区策略:消息路由的核心
分区(Partition)是Kafka等消息队列实现并行处理和负载均衡的基础单位。消息的分区策略决定了它将被哪个消费者处理。
5.3.1 按键哈希分区
class KeyBasedPartitioner:
"""
基于键的哈希分区器
相同键的消息总是被发送到相同的分区
适用于需要保证顺序的场景
"""
def __init__(self, num_partitions: int):
self.num_partitions = num_partitions
def partition(self, key: str, total_partitions: int = None) -> int:
"""
计算消息应该发送到的分区号
Args:
key: 消息键(通常为user_id或task_id)
total_partitions: 总分区数
Returns:
分区号 (0 ~ num_partitions-1)
"""
if total_partitions is None:
total_partitions = self.num_partitions
if not key:
# 无键消息,随机分配
import random
return random.randint(0, total_partitions - 1)
# 哈希后取模
partition = hash(key) % total_partitions
return partition
def get_partition_for_user(self, user_id: str) -> int:
"""获取用户任务应发送到的分区"""
return self.partition(user_id)
class ConsistentHashPartitioner:
"""
一致性哈希分区器
优势:
1. 节点动态加入/离开时,影响范围最小
2. 更好地支持节点容量差异
"""
def __init__(self, virtual_nodes: int = 100):
self.virtual_nodes = virtual_nodes
self.ring = {} # hash -> node_id
self.sorted_keys = []
def add_node(self, node_id: str, capacity: int = 1) -> None:
"""
添加节点到哈希环
Args:
node_id: 节点标识
capacity: 节点容量(虚拟节点数)
"""
for i in range(capacity * self.virtual_nodes):
key = self._hash(f"{node_id}_vn_{i}")
self.ring[key] = node_id
self.sorted_keys = sorted(self.ring.keys())
def remove_node(self, node_id: str) -> None:
"""从哈希环移除节点"""
keys_to_remove = [k for k, v in self.ring.items() if v == node_id]
for key in keys_to_remove:
del self.ring[key]
self.sorted_keys = sorted(self.ring.keys())
def _hash(self, key: str) -> int:
"""计算哈希值(使用MD5获得更好的分布)"""
import hashlib
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def get_node(self, message_key: str) -> str:
"""
获取消息应发送到的节点
Args:
message_key: 消息键
Returns:
节点ID
"""
if not self.ring:
raise ValueError("哈希环为空")
hash_value = self._hash(message_key)
# 二分查找第一个大于等于hash_value的位置
pos = 0
for i, key in enumerate(self.sorted_keys):
if key >= hash_value:
pos = i
break
else:
pos = 0 # 环回起点
return self.ring[self.sorted_keys[pos]]
def demo_partitioning():
"""演示分区策略"""
print("=== 按键哈希分区 ===")
partitioner = KeyBasedPartitioner(num_partitions=6)
users = ["user_a", "user_b", "user_c", "user_a", "user_b"]
for user in users:
part = partitioner.partition(user)
print(f"用户 {user} -> 分区 {part}")
print("\n注意:相同用户始终分配到相同分区")
print("这保证了同一用户的任务按顺序处理")
print("\n\n=== 一致性哈希分区 ===")
ch = ConsistentHashPartitioner(virtual_nodes=50)
# 添加节点(模拟不同容量的服务器)
ch.add_node("server_1", capacity=1) # 小型
ch.add_node("server_2", capacity=2) # 中型
ch.add_node("server_3", capacity=3) # 大型
# 测试分布
test_keys = [f"user_{i}" for i in range(20)]
distribution = {}
for key in test_keys:
node = ch.get_node(key)
distribution[node] = distribution.get(node, 0) + 1
print("\n20个用户的分布:")
for node, count in distribution.items():
print(f" {node}: {count} 个用户")
if __name__ == "__main__":
demo_partitioning()5.4 分区数与消费者数的关系
这是设计消息队列系统时最常见的问题之一。
核心规则:
关系 | 结论 |
|---|---|
分区数 = 消费者数 | 最佳情况,每个消费者处理一个分区 |
分区数 > 消费者数 | 消费者并行处理,部分分区空闲 |
分区数 < 消费者数 | 部分消费者无事可做(浪费) |
动态调整的挑战:
- 分区数无法减少:Kafka分区数只能增加,不能减少
- 消费者重平衡代价高:触发Rebalance时,所有消费者暂停
- 增加分区需要迁移数据:分区扩容涉及数据迁移
实践建议:
class PartitionManager:
"""
分区动态管理器
策略:
1. 预估未来容量,设置略高的分区数
2. 监控消费者处理延迟,动态调整
3. 避免频繁Rebalance
"""
def __init__(self, topic: str, base_partitions: int = 6):
self.topic = topic
self.partitions = base_partitions
self.target_consumer_count = 0
self.alert_threshold = 1000 # 消息积压告警阈值
def calculate_optimal_partitions(
self,
throughput_per_consumer: int,
target_throughput: int
) -> int:
"""
计算最优分区数
Args:
throughput_per_consumer: 每个消费者的处理能力(消息/秒)
target_throughput: 目标吞吐量(消息/秒)
Returns:
最优分区数
"""
optimal = target_throughput / throughput_per_consumer
# 向上取整,并预留20%余量
return int(optimal * 1.2)
def should_scale(self, current_backlog: int, consumer_count: int) -> tuple:
"""
判断是否需要扩缩容
Returns:
(should_scale, scale_direction, reason)
"""
avg_backlog_per_consumer = current_backlog / max(consumer_count, 1)
if avg_backlog_per_consumer > self.alert_threshold * 0.8:
return (True, "expand", f"平均积压 {avg_backlog_per_consumer} 过高")
elif avg_backlog_per_consumer < self.alert_threshold * 0.2 and consumer_count > 3:
return (True, "shrink", f"平均积压 {avg_backlog_per_consumer} 过低")
return (False, None, "无需调整")
def get_rebalance_strategy(self) -> str:
"""
获取重平衡策略建议
Returns:
策略描述
"""
if self.partitions < self.target_consumer_count:
return ("当前分区数不足以支持所有消费者,"
"建议增加分区数或减少消费者实例")
elif self.partitions > self.target_consumer_count * 2:
return ("分区数过多,建议减少分区以降低资源消耗")
else:
return ("分区数与消费者数比例合理")
def demo_partition_design():
"""演示分区设计"""
manager = PartitionManager("ai-tasks", base_partitions=12)
# 场景:AI IDE系统
# 每个AI任务执行器每秒处理10个任务
# 预期峰值:每秒500个任务
# 平时:每秒100个任务
print("=== AI IDE 任务队列分区设计 ===\n")
# 峰值计算
peak_optimal = manager.calculate_optimal_partitions(10, 500)
print(f"目标峰值吞吐量: 500 消息/秒")
print(f"单个消费者能力: 10 消息/秒")
print(f"建议分区数: {peak_optimal}")
# 平时计算
normal_optimal = manager.calculate_optimal_partitions(10, 100)
print(f"\n平时吞吐量: 100 消息/秒")
print(f"建议分区数: {normal_optimal}")
# 扩缩容判断
print("\n=== 扩缩容判断 ===")
# 高负载场景
should, direction, reason = manager.should_scale(5000, 6)
print(f"积压5000,6个消费者: {direction if should else '不调整'} - {reason}")
# 低负载场景
should, direction, reason = manager.should_scale(200, 6)
print(f"积压200,6个消费者: {direction if should else '不调整'} - {reason}")
if __name__ == "__main__":
demo_partition_design()核心结论:分区数的设计需要综合考虑峰值吞吐量、消费者处理能力、扩缩容频率。建议初期设置略高的分区数,预留扩容空间。
6 顺序保证:分区有序与全局有序的权衡
本节为你提供的核心价值:理解顺序保证的代价,掌握在分区有序和全局有序之间的权衡策略。
6.1 顺序保证的三个层次
层次 | 定义 | 实现成本 | 适用场景 |
|---|---|---|---|
单消息有序 | 单个消息内部字段有序 | 低 | 字段级别的顺序处理 |
分区内有序 | 同一分区内消息有序 | 中 | 同一用户/同一实体的操作 |
全局有序 | 所有分区消息有序 | 极高 | 极少数关键业务 |
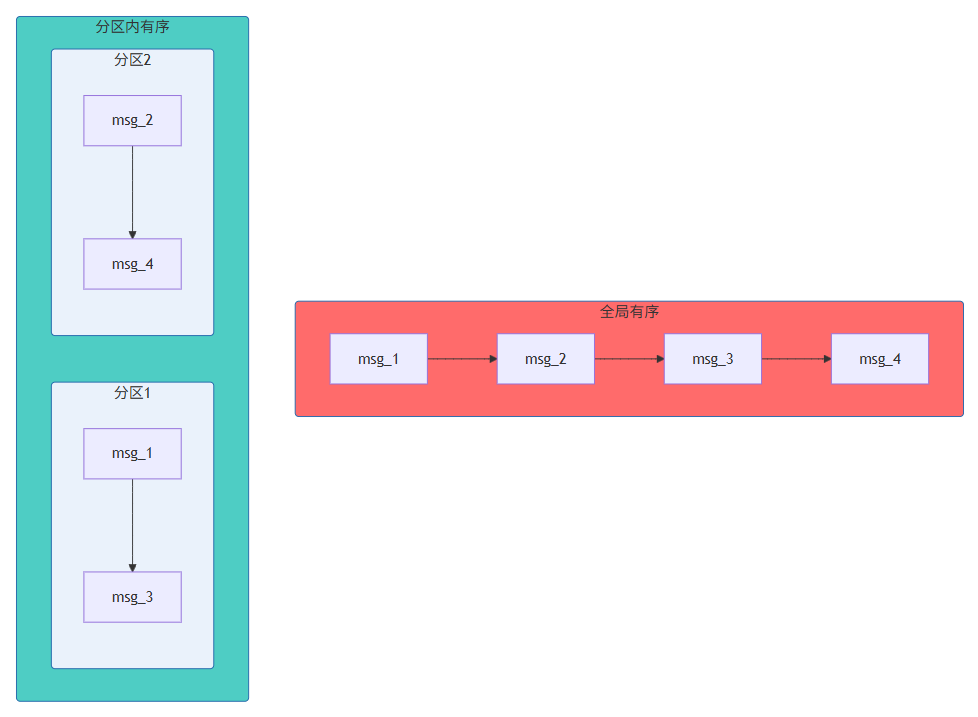
6.2 分区有序的实现
在Kafka等消息队列中,分区内有序是默认保证的。只要消息使用相同的键发送到相同的分区,它们将按发送顺序被消费。
class OrderedTaskProcessor:
"""
有序任务处理器
核心思想:
1. 将需要保证顺序的消息发送到相同的分区
2. 消费者按分区顺序处理消息
"""
def __init__(self, partitioner: KeyBasedPartitioner, num_workers: int = 4):
self.partitioner = partitioner
self.num_workers = num_workers
# 每个worker维护自己的消息缓冲
self.buffers: Dict[int, asyncio.Queue] = {
i: asyncio.Queue() for i in range(num_workers)
}
self.processing: Dict[int, bool] = {i: False for i in range(num_workers)}
def get_partition_for_entity(self, entity_id: str) -> int:
"""获取实体应分配的分区"""
return self.partitioner.partition(entity_id)
async def submit_task(self, entity_id: str, task: dict) -> None:
"""
提交任务,保证同一entity的任务有序处理
Args:
entity_id: 实体ID(如用户ID、项目ID)
task: 任务内容
"""
partition = self.get_partition_for_entity(entity_id)
worker_id = partition % self.num_workers
await self.buffers[worker_id].put({
'entity_id': entity_id,
'task': task,
'partition': partition
})
print(f"任务已提交: entity={entity_id}, worker={worker_id}, partition={partition}")
async def process_ordered(self, worker_id: int, handler: Callable) -> None:
"""
有序处理任务
同一worker内,同一entity的任务按顺序处理
不同entity的任务可以并行处理
"""
entity_locks: Dict[str, asyncio.Lock] = {}
buffer = self.buffers[worker_id]
while True:
try:
item = await buffer.get()
entity_id = item['entity_id']
task = item['task']
# 获取或创建实体的锁
if entity_id not in entity_locks:
entity_locks[entity_id] = asyncio.Lock()
async with entity_locks[entity_id]:
# 按顺序处理该实体的任务
await handler(task, entity_id)
buffer.task_done()
except Exception as e:
print(f"处理异常: {e}")
await asyncio.sleep(1)
def demo_ordered_processing():
"""演示有序任务处理"""
partitioner = KeyBasedPartitioner(num_partitions=10)
processor = OrderedTaskProcessor(partitioner, num_workers=2)
async def handler(task, entity_id):
print(f" 处理任务: {task['action']} for {entity_id}")
await asyncio.sleep(0.1) # 模拟处理
async def main():
# 提交同一用户的多个任务
user_id = "user_123"
for i in range(5):
await processor.submit_task(user_id, {
'action': f'task_{i}',
'seq': i
})
# 启动worker处理
await asyncio.gather(
processor.process_ordered(0, handler),
processor.process_ordered(1, handler),
)
asyncio.run(main())6.3 全局有序的代价
如果业务真的需要全局有序,代价是巨大的:
- 单分区瓶颈:所有消息发往同一分区,丧失并行处理能力
- 吞吐量骤降:订单量级从10万/秒可能降至几千/秒
- 故障风险集中:单分区单消费者,无容错能力
案例分析:银行转账
class GlobalOrderEnforcer:
"""
全局有序强制器
警告:这是性能杀手,仅用于确实需要全局有序的场景
"""
def __init__(self):
self.global_lock = asyncio.Lock()
self.processing_queue = asyncio.Queue()
self.worker_task = None
async def start(self, handler: Callable):
"""启动全局有序处理器"""
self.worker_task = asyncio.create_task(self._process_loop(handler))
async def stop(self):
"""停止处理器"""
if self.worker_task:
self.worker_task.cancel()
await asyncio.gather(self.worker_task, return_exceptions=True)
async def submit(self, message: dict):
"""提交消息(全局串行处理)"""
await self.processing_queue.put(message)
async def _process_loop(self, handler: Callable):
"""单线程处理循环"""
while True:
message = await self.processing_queue.get()
async with self.global_lock:
try:
await handler(message)
except Exception as e:
print(f"处理异常: {e}")
self.processing_queue.task_done()
async def get_throughput_estimate(self, avg_process_time: float) -> float:
"""
估算全局有序模式下的吞吐量
Args:
avg_process_time: 平均处理时间(秒)
Returns:
每秒可处理的消息数
"""
return 1.0 / avg_process_time
def demo_global_order_cost():
"""演示全局有序的性能代价"""
enforcer = GlobalOrderEnforcer()
print("=== 全局有序的性能代价 ===\n")
# 不同处理时间的吞吐量
process_times = [0.001, 0.01, 0.1, 1.0] # 秒
for pt in process_times:
throughput = await enforcer.get_throughput_estimate(pt)
print(f"平均处理时间 {pt*1000:.0f}ms -> 最大吞吐量 {throughput:.0f} 消息/秒")
print("\n对比:")
print(f" 分区有序(10分区,每分区100ms处理): {10 * 10:.0f} 消息/秒")
print(f" 全局有序(单线程,100ms处理): 10 消息/秒")
print(f"\n结论:全局有序的吞吐量是分区有序的 1/N (N=分区数)")
if __name__ == "__main__":
asyncio.run(demo_global_order_cost())6.4 顺序保证的工程实践
核心原则:
- 能不分顺序就不分顺序:大多数场景下,分区内有序已经足够
- 用业务键保证相关消息同区:将需要保证顺序的消息发往同一分区
- 必要时引入外部协调:对于确实需要全局有序的场景,使用分布式锁或序列号
AI IDE场景的顺序保证策略:
任务类型 | 顺序要求 | 实现方案 |
|---|---|---|
代码补全 | 同一文件的补全请求有序 | 按文件路径哈希分区 |
代码分析 | 同一文件的分析有序 | 按文件路径哈希分区 |
项目索引 | 无顺序要求 | 按需分区 |
用户会话 | 同一用户的操作有序 | 按用户ID哈希分区 |
构建任务 | 同一项目的构建有序 | 按项目ID哈希分区 |
7 实践:使用Redis Streams实现轻量级任务队列
本节为你提供的核心价值:通过完整的代码实现,掌握使用Redis Streams构建生产级任务队列的工程方法。
Redis Streams是Redis 5.0引入的数据结构,专门为消息队列场景设计。它结合了Redis的高性能和Streams的持久化、消费者组特性,是AI IDE系统构建轻量级任务队列的理想选择。
7.1 Redis Streams架构
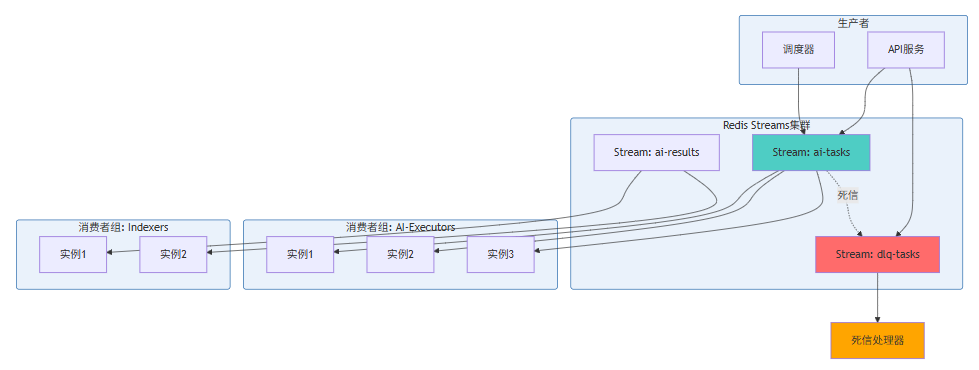
7.2 完整实现代码
import redis
import json
import time
import uuid
import asyncio
from typing import Optional, Callable, List, Dict, Any
from dataclasses import dataclass, field, asdict
from enum import Enum
import threading
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class TaskStatus(Enum):
"""任务状态枚举"""
PENDING = "pending"
PROCESSING = "processing"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
class TaskPriority(Enum):
"""任务优先级枚举"""
CRITICAL = 0 # 最高优先级
HIGH = 1
NORMAL = 2
LOW = 3
BATCH = 4 # 最低优先级
@dataclass
class TaskMessage:
"""任务消息结构"""
task_id: str = field(default_factory=lambda: f"task_{uuid.uuid4().hex[:12]}")
task_type: str = ""
priority: int = TaskPriority.NORMAL.value
payload: dict = field(default_factory=dict)
metadata: dict = field(default_factory=dict)
created_at: float = field(default_factory=time.time)
timeout: int = 300 # 默认超时时间(秒)
max_retries: int = 3
retry_count: int = 0
def to_stream_entry(self) -> dict:
"""转换为Redis Stream格式"""
return {
"task_id": self.task_id,
"task_type": self.task_type,
"priority": str(self.priority),
"payload": json.dumps(self.payload),
"metadata": json.dumps(self.metadata),
"created_at": str(self.created_at),
"timeout": str(self.timeout),
"max_retries": str(self.max_retries),
"retry_count": str(self.retry_count),
"status": TaskStatus.PENDING.value
}
@classmethod
def from_stream_entry(cls, entry: dict) -> 'TaskMessage':
"""从Redis Stream条目创建TaskMessage"""
return cls(
task_id=entry[b"task_id"].decode(),
task_type=entry[b"task_type"].decode(),
priority=int(entry[b"priority"].decode()),
payload=json.loads(entry[b"payload"].decode()),
metadata=json.loads(entry[b"metadata"].decode()),
created_at=float(entry[b"created_at"].decode()),
timeout=int(entry[b"timeout"].decode()),
max_retries=int(entry[b"max_retries"].decode()),
retry_count=int(entry[b"retry_count"].decode())
)
class RedisStreamsTaskQueue:
"""
基于Redis Streams的轻量级任务队列
特性:
1. 支持消费者组,实现负载均衡
2. 支持优先级任务
3. 支持死信队列和自动重试
4. 支持消息确认和幂等处理
5. 支持待处理任务监控
"""
STREAM_KEY = "stream:ai-tasks"
CONSUMER_GROUP = "group:ai-executors"
DLQ_KEY = "stream:dlq-tasks"
PROCESSING_STREAM = "stream:processing"
def __init__(self, redis_url: str = "redis://localhost:6379/0"):
self.redis = redis.from_url(redis_url, decode_responses=False)
self._ensure_consumer_group()
self._ensure_streams()
def _ensure_consumer_group(self) -> None:
"""确保消费者组存在"""
try:
self.redis.xgroup_create(
self.STREAM_KEY,
self.CONSUMER_GROUP,
id="0",
mkstream=True
)
logger.info(f"创建消费者组: {self.CONSUMER_GROUP}")
except redis.ResponseError as e:
if "BUSYGROUP" not in str(e):
raise
logger.debug(f"消费者组已存在: {self.CONSUMER_GROUP}")
def _ensure_streams(self) -> None:
"""确保必要的Stream存在"""
# 处理中的任务Stream(用于追踪)
try:
self.redis.xgroup_create(
self.PROCESSING_STREAM,
self.CONSUMER_GROUP,
id="0",
mkstream=True
)
except redis.ResponseError:
pass
# 死信队列
try:
self.redis.xgroup_create(
self.DLQ_KEY,
"dlq-processors",
id="0",
mkstream=True
)
except redis.ResponseError:
pass
def enqueue(self, task: TaskMessage) -> str:
"""
将任务加入队列
Args:
task: 任务消息
Returns:
task_id: 任务ID
"""
# 写入主队列
task_id = self.redis.xadd(
self.STREAM_KEY,
task.to_stream_entry(),
maxlen=100000 # 限制Stream长度
)
logger.info(f"任务已入队: {task_id.decode()}")
return task_id.decode()
def enqueue_batch(self, tasks: List[TaskMessage]) -> List[str]:
"""
批量添加任务
Args:
tasks: 任务列表
Returns:
task_ids: 任务ID列表
"""
pipe = self.redis.pipeline()
for task in tasks:
pipe.xadd(self.STREAM_KEY, task.to_stream_entry(), maxlen=100000)
return [tid.decode() for tid in pipe.execute()]
def dequeue(self, consumer_id: str, count: int = 1, block_ms: int = 5000) -> List[TaskMessage]:
"""
从队列取任务(阻塞)
Args:
consumer_id: 消费者ID
count: 每次获取的消息数
block_ms: 阻塞等待时间(毫秒)
Returns:
tasks: 任务列表
"""
# 使用XREADGROUP读取消费者组消息
results = self.redis.xreadgroup(
groupname=self.CONSUMER_GROUP,
consumername=consumer_id,
streams={self.STREAM_KEY: ">"}, # ">表示只读取新消息
count=count,
block=block_ms
)
if not results:
return []
tasks = []
for stream_name, messages in results:
for msg_id, msg_data in messages:
try:
task = TaskMessage.from_stream_entry(msg_data)
task.msg_id = msg_id # 存储Stream消息ID
tasks.append(task)
except Exception as e:
logger.error(f"解析任务失败: {e}")
return tasks
def acknowledge(self, task: TaskMessage) -> bool:
"""
确认任务已完成
Args:
task: 已完成的任务
Returns:
success: 是否成功
"""
msg_id = getattr(task, 'msg_id', None)
if not msg_id:
logger.error("任务缺少msg_id")
return False
try:
# 从pending列表中删除
self.redis.xack(self.STREAM_KEY, self.CONSUMER_GROUP, msg_id)
# 从处理中Stream中删除
self.redis.xdel(self.PROCESSING_STREAM, msg_id)
logger.info(f"任务已确认: {task.task_id}")
return True
except Exception as e:
logger.error(f"确认任务失败: {e}")
return False
def requeue_with_retry(self, task: TaskMessage) -> bool:
"""
重新加入队列(带重试计数)
Args:
task: 失败的任务
Returns:
success: 是否成功重试
"""
task.retry_count += 1
if task.retry_count >= task.max_retries:
# 超过最大重试次数,移入死信队列
return self.move_to_dlq(task, reason="max_retries_exceeded")
# 重新入队
try:
# 清除 PEL(Pending Entries List)中的记录
msg_id = getattr(task, 'msg_id', None)
if msg_id:
self.redis.xack(self.STREAM_KEY, self.CONSUMER_GROUP, msg_id)
# 创建新的任务消息(保留原始task_id)
new_task = TaskMessage(
task_id=task.task_id, # 保持原始ID用于幂等
task_type=task.task_type,
priority=task.priority,
payload=task.payload,
metadata={**task.metadata, "retry_of": task.task_id},
created_at=time.time(),
timeout=task.timeout,
max_retries=task.max_retries,
retry_count=task.retry_count
)
self.enqueue(new_task)
logger.info(f"任务已重试 ({task.retry_count}/{task.max_retries}): {task.task_id}")
return True
except Exception as e:
logger.error(f"重试任务失败: {e}")
return False
def move_to_dlq(self, task: TaskMessage, reason: str = "") -> bool:
"""
将任务移入死信队列
Args:
task: 失败的任务
reason: 失败原因
Returns:
success: 是否成功
"""
try:
dlq_entry = task.to_stream_entry()
dlq_entry["dlq_reason"] = reason
dlq_entry["dlq_at"] = str(time.time())
self.redis.xadd(self.DLQ_KEY, dlq_entry)
# 确认原任务
msg_id = getattr(task, 'msg_id', None)
if msg_id:
self.redis.xack(self.STREAM_KEY, self.CONSUMER_GROUP, msg_id)
logger.warning(f"任务已移入DLQ: {task.task_id}, 原因: {reason}")
return True
except Exception as e:
logger.error(f"移动到DLQ失败: {e}")
return False
def get_pending_tasks(self, consumer_id: Optional[str] = None) -> Dict:
"""
获取待处理任务统计
Args:
consumer_id: 可选,指定消费者
Returns:
stats: 统计信息
"""
# 获取消费者组的Pending信息
try:
info = self.redis.xpending(self.STREAM_KEY, self.CONSUMER_GROUP)
return {
"pending_count": info[b"pending"],
"first_id": info[b"first"].decode() if info[b"first"] else None,
"last_id": info[b"last"].decode() if info[b"last"] else None,
"consumers": [
{
"name": c[b"name"].decode(),
"pending": c[b"pending"]
}
for c in info.get(b"consumers", [])
]
}
except Exception as e:
logger.error(f"获取pending信息失败: {e}")
return {}
def get_queue_length(self) -> int:
"""获取队列长度"""
try:
return self.redis.xlen(self.STREAM_KEY)
except Exception as e:
logger.error(f"获取队列长度失败: {e}")
return 0
def get_dlq_length(self) -> int:
"""获取死信队列长度"""
try:
return self.redis.xlen(self.DLQ_KEY)
except Exception:
return 0
def repair_pending(self, idle_threshold_ms: int = 3600000) -> int:
"""
修复Pending列表中的卡住任务
将超过阈值的pending任务重新投递给其他消费者
Args:
idle_threshold_ms: 空闲阈值(毫秒),默认1小时
Returns:
repaired_count: 修复的任务数
"""
repaired = 0
try:
# 获取所有pending任务
info = self.redis.xpending(self.STREAM_KEY, self.CONSUMER_GROUP)
for consumer in info.get(b"consumers", []):
consumer_name = consumer[b"name"].decode()
consumer_pending = consumer[b"pending"]
if consumer_pending > 0:
# 获取该消费者超时的任务
tasks = self.redis.xpending_range(
self.STREAM_KEY,
self.CONSUMER_GROUP,
consumer_name,
min="-",
max="+",
count=100
)
now = time.time() * 1000
for task in tasks:
msg_id, consumer_name, idle_time, delivery_count = task
if idle_time >= idle_threshold_ms:
# 将任务claim过来
self.redis.xclaim(
self.STREAM_KEY,
self.CONSUMER_GROUP,
"repair-consumer", # 修复用的消费者名
idle_time + 1000, # 最小idle时间
[msg_id]
)
repaired += 1
logger.info(f"修复卡住任务: {msg_id.decode()}, idle: {idle_time}ms")
except Exception as e:
logger.error(f"修复pending任务失败: {e}")
return repaired
class TaskConsumer:
"""
任务消费者
封装了消费者的常见逻辑:
1. 消息获取和处理循环
2. 异常处理和重试
3. 心跳和健康检查
"""
def __init__(
self,
queue: RedisStreamsTaskQueue,
consumer_id: str,
handler: Callable[[TaskMessage], Any]
):
self.queue = queue
self.consumer_id = consumer_id
self.handler = handler
self.running = False
self.processed_count = 0
self.failed_count = 0
async def process_loop(self) -> None:
"""主处理循环"""
self.running = True
logger.info(f"消费者启动: {self.consumer_id}")
while self.running:
try:
# 获取任务(非阻塞)
tasks = self.queue.dequeue(
self.consumer_id,
count=1,
block_ms=5000
)
for task in tasks:
await self._process_task(task)
except Exception as e:
logger.error(f"处理循环异常: {e}")
await asyncio.sleep(1)
async def _process_task(self, task: TaskMessage) -> None:
"""处理单个任务"""
start_time = time.time()
try:
logger.info(f"处理任务: {task.task_id}, 类型: {task.task_type}")
# 调用业务处理器
result = await self._safe_handler(task)
# 处理成功,确认任务
self.queue.acknowledge(task)
self.processed_count += 1
elapsed = (time.time() - start_time) * 1000
logger.info(f"任务完成: {task.task_id}, 耗时: {elapsed:.0f}ms")
except Exception as e:
logger.error(f"任务处理失败: {task.task_id}, 错误: {e}")
self.failed_count += 1
# 尝试重试
if not self.queue.requeue_with_retry(task):
# 重试失败,移入死信队列
self.queue.move_to_dlq(task, reason=str(e))
async def _safe_handler(self, task: TaskMessage) -> Any:
"""安全调用处理器(支持异步)"""
result = self.handler(task)
if asyncio.iscoroutine(result):
return await result
return result
def stop(self) -> None:
"""停止消费者"""
self.running = False
logger.info(f"消费者停止: {self.consumer_id}, "
f"处理: {self.processed_count}, 失败: {self.failed_count}")
# ============ 示例业务处理器 ============
async def code_analysis_handler(task: TaskMessage) -> dict:
"""
代码分析任务处理器示例
Args:
task: 任务消息
Returns:
分析结果
"""
payload = task.payload
# 模拟代码分析过程
await asyncio.sleep(0.5) # 实际会调用AI模型
file_path = payload.get("file_path", "")
options = payload.get("options", {})
# 返回分析结果
return {
"status": "success",
"file_path": file_path,
"issues_found": 3,
"suggestions": [
"考虑使用类型注解提高代码可读性",
"检测到潜在的空指针异常",
"建议提取重复代码到公共函数"
]
}
async def code_completion_handler(task: TaskMessage) -> dict:
"""
代码补全任务处理器示例
Args:
task: 任务消息
Returns:
补全结果
"""
payload = task.payload
# 模拟补全延迟
await asyncio.sleep(0.1)
context = payload.get("context", "")
return {
"status": "success",
"completions": [
{"text": "def main():", "confidence": 0.95},
{"text": "class Handler:", "confidence": 0.85},
]
}
# ============ 使用示例 ============
async def demo_task_queue():
"""演示完整的使用流程"""
# 初始化队列
queue = RedisStreamsTaskQueue("redis://localhost:6379/0")
# 创建任务
tasks = [
TaskMessage(
task_type="code_analysis",
priority=TaskPriority.HIGH.value,
payload={
"file_path": "/workspace/project/main.py",
"options": {"deep_analysis": True}
},
metadata={"user_id": "user_123"}
),
TaskMessage(
task_type="code_completion",
priority=TaskPriority.CRITICAL.value,
payload={
"context": "def ",
"position": {"line": 10, "column": 4}
},
metadata={"user_id": "user_456", "session_id": "sess_abc"}
),
TaskMessage(
task_type="code_analysis",
priority=TaskPriority.LOW.value,
payload={
"file_path": "/workspace/project/utils.py",
"options": {"deep_analysis": False}
},
metadata={"user_id": "user_789"}
)
]
# 入队
print("=== 入队操作 ===")
task_ids = queue.enqueue_batch(tasks)
for tid in task_ids:
print(f" 入队: {tid}")
# 模拟消费者
print("\n=== 模拟消费 ===")
consumer_id = "worker_001"
# 获取任务
received_tasks = queue.dequeue(consumer_id, count=2)
print(f" 获取到 {len(received_tasks)} 个任务")
for task in received_tasks:
print(f" 处理: {task.task_id}, 类型: {task.task_type}")
# 模拟处理
if task.task_type == "code_analysis":
result = await code_analysis_handler(task)
else:
result = await code_completion_handler(task)
print(f" 结果: {result['status']}")
# 确认任务
queue.acknowledge(task)
# 检查队列状态
print("\n=== 队列状态 ===")
print(f" 队列长度: {queue.get_queue_length()}")
print(f" 死信队列: {queue.get_dlq_length()}")
pending = queue.get_pending_tasks()
print(f" 待处理任务: {pending.get('pending_count', 0)}")
# 消费者统计
if pending.get('consumers'):
print(" 消费者状态:")
for c in pending['consumers']:
print(f" {c['name']}: {c['pending']} 个待处理")
def demo_priority_queue_usage():
"""演示优先级队列的使用"""
queue = RedisStreamsTaskQueue("redis://localhost:6379/0")
# 混合优先级的任务
tasks = [
# 高优先级
TaskMessage(
task_type="code_completion",
priority=TaskPriority.CRITICAL.value,
payload={"context": "import "}
),
# 低优先级
TaskMessage(
task_type="code_analysis",
priority=TaskPriority.LOW.value,
payload={"file_path": "/large/project"}
),
# 普通优先级
TaskMessage(
task_type="code_analysis",
priority=TaskPriority.NORMAL.value,
payload={"file_path": "/small/project"}
),
]
# 入队
print("=== 优先级演示 ===")
for task in tasks:
priority_name = TaskPriority(task.priority).name
task_id = queue.enqueue(task)
print(f"入队: {task_id}, 优先级: {priority_name}")
# 注意:Redis Streams本身不原生支持优先级
# 需要配合ZSET或多个队列实现优先级
print("\n提示:Redis Streams不原生支持优先级,需要应用层实现")
if __name__ == "__main__":
print("=" * 60)
print("Redis Streams 轻量级任务队列演示")
print("=" * 60)
# 同步方式演示
try:
demo_priority_queue_usage()
except Exception as e:
print(f"演示出错: {e}")
# 异步方式演示
try:
asyncio.run(demo_task_queue())
except Exception as e:
print(f"异步演示出错: {e}")7.3 监控与管理
class QueueMonitor:
"""
队列监控器
监控指标:
1. 队列长度和增长趋势
2. 消费者状态和积压
3. 任务处理延迟
4. 死信队列告警
"""
def __init__(self, queue: RedisStreamsTaskQueue):
self.queue = queue
self.history: List[Dict] = []
self.max_history = 1000
def collect_metrics(self) -> Dict:
"""收集当前指标"""
metrics = {
"timestamp": time.time(),
"queue_length": self.queue.get_queue_length(),
"dlq_length": self.queue.get_dlq_length(),
"pending": self.queue.get_pending_tasks()
}
# 计算处理速率(如果有历史数据)
if len(self.history) >= 2:
last = self.history[-1]
interval = metrics["timestamp"] - last["timestamp"]
if interval > 0:
queue_delta = metrics["queue_length"] - last["queue_length"]
metrics["produce_rate"] = queue_delta / interval
# 保存历史
self.history.append(metrics)
if len(self.history) > self.max_history:
self.history.pop(0)
return metrics
def get_health_status(self) -> Dict:
"""获取健康状态"""
metrics = self.collect_metrics()
alerts = []
status = "healthy"
# 队列长度告警
if metrics["queue_length"] > 10000:
alerts.append("队列积压严重")
status = "warning"
elif metrics["queue_length"] > 50000:
alerts.append("队列严重积压,需要扩容")
status = "critical"
# 死信队列告警
if metrics["dlq_length"] > 100:
alerts.append("死信队列异常增长")
status = "warning"
# 消费者健康检查
pending = metrics.get("pending", {})
consumers = pending.get("consumers", [])
if consumers:
total_pending = sum(c["pending"] for c in consumers)
inactive_consumers = [c for c in consumers if c["pending"] == 0]
if len(inactive_consumers) == len(consumers) and len(consumers) > 0:
alerts.append("所有消费者处于空闲状态")
status = "warning"
return {
"status": status,
"alerts": alerts,
"metrics": metrics
}
def print_dashboard(self) -> None:
"""打印监控面板"""
health = self.get_health_status()
metrics = health["metrics"]
print("\n" + "=" * 50)
print("队列监控面板")
print("=" * 50)
print(f"状态: {health['status'].upper()}")
print(f"队列长度: {metrics['queue_length']}")
print(f"死信队列: {metrics['dlq_length']}")
pending = metrics.get("pending", {})
print(f"待处理任务: {pending.get('pending_count', 0)}")
print("\n消费者状态:")
for c in pending.get("consumers", []):
print(f" {c['name']}: {c['pending']} 个待处理")
if health["alerts"]:
print("\n告警:")
for alert in health["alerts"]:
print(f" [!] {alert}")
print("=" * 50)
def demo_monitoring():
"""演示监控功能"""
queue = RedisStreamsTaskQueue("redis://localhost:6379/0")
monitor = QueueMonitor(queue)
# 收集指标
for _ in range(5):
monitor.collect_metrics()
time.sleep(0.1)
# 打印面板
monitor.print_dashboard()
if __name__ == "__main__":
demo_monitoring()8 消息队列对比选型:RabbitMQ、Kafka、Redis Streams
本节为你提供的核心价值:对比三大主流消息队列的优劣势,根据AI IDE场景需求给出选型建议。
8.1 核心特性对比
特性 | RabbitMQ | Apache Kafka | Redis Streams |
|---|---|---|---|
定位 | 传统企业消息队列 | 分布式流平台 | Redis数据结构 |
吞吐量 | ~10万/秒 | ~100万/秒 | ~50万/秒 |
消息持久化 | 支持 | 支持 | 支持(RDB+AOF) |
消费者组 | 支持 | 支持(原生) | 支持 |
消息顺序 | 队列内有序 | 分区有序 | 分区有序 |
TTL支持 | 队列级别 | 消息级别 | 消息级别 |
死信队列 | 原生支持 | 需手动实现 | 需手动实现 |
事务支持 | 部分 | 完整 | Lua脚本实现 |
多租户 | 支持 | 通过SASL | 通过DB隔离 |
监控 | 完整 | 完整 | 需自行开发 |
集群 | Federation/Shovel | 原生分布式 | Redis Cluster |
学习曲线 | 中等 | 陡峭 | 低 |
运维复杂度 | 中等 | 高 | 低 |
8.2 适用场景分析
渲染错误: Mermaid 渲染失败: Parse error on line 2: ...A[开始选型] --> B{吞吐量要求?] B -->|<10万/秒| -----------------------^ Expecting 'DIAMOND_STOP', 'TAGEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'SQE'
8.3 AI IDE场景选型建议
基于AI IDE系统的特点(任务类型多样、实时性要求高、需长期运行),推荐以下选型策略:
场景 | 推荐方案 | 原因 |
|---|---|---|
AI任务执行 | Redis Streams | 轻量、实时性好、易集成 |
代码索引构建 | Apache Kafka | 高吞吐、支持事件回溯 |
实时通知推送 | Redis Streams | 低延迟、简单可靠 |
跨服务事件总线 | RabbitMQ | 丰富的路由功能 |
日志采集 | Apache Kafka | 高吞吐、长期存储 |
混合架构示例:
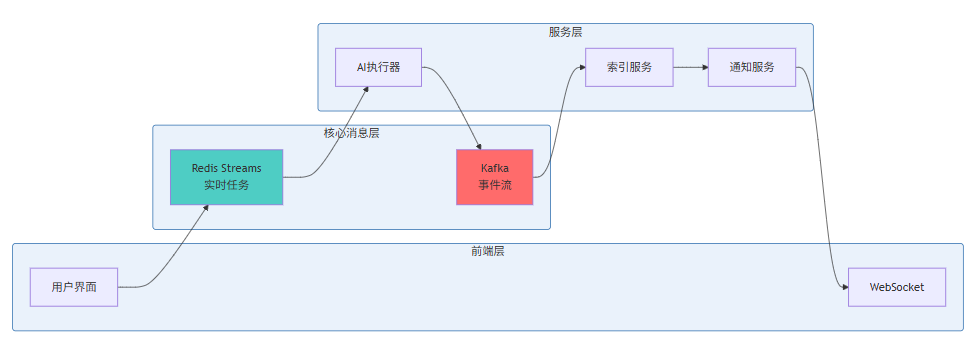
9 工程实践:构建弹性的AI IDE后端
本节为你提供的核心价值:掌握使用消息队列构建高可用、高弹性AI IDE后端的工程方法。
9.1 架构设计原则
- 异步优先:所有非即时操作必须异步化
- 服务隔离:不同类型的任务使用不同的队列
- 优雅降级:部分服务不可用时,系统仍能核心功能
- 可观测性:完善的监控和告警机制
9.2 完整架构示例
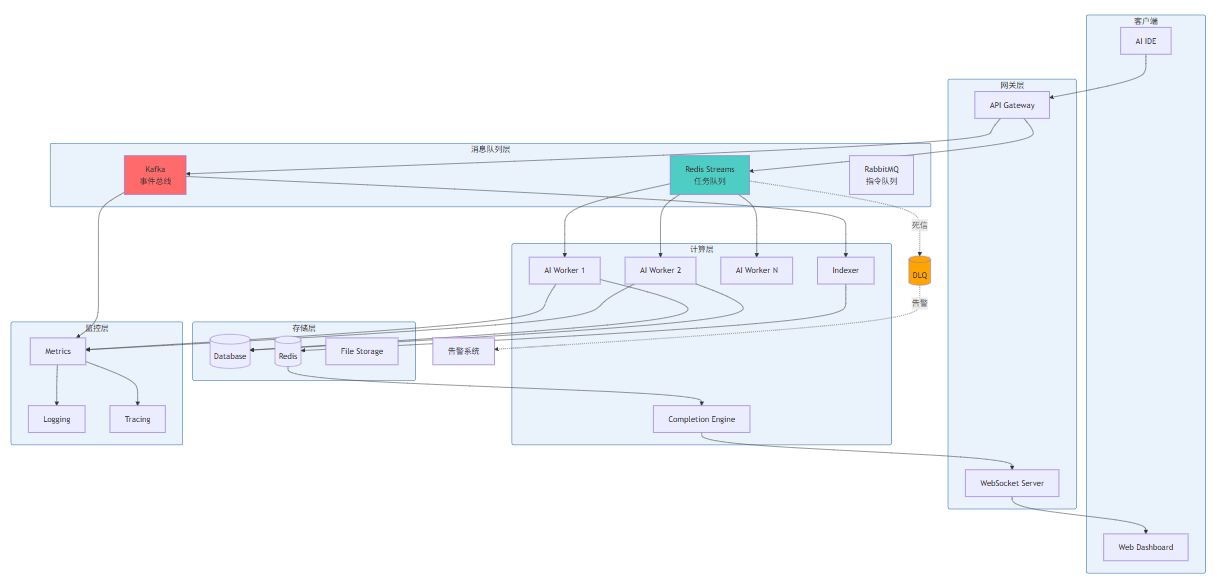
9.3 关键实现代码
# AI IDE 后端核心服务实现
import asyncio
from typing import Dict, List, Optional
from dataclasses import dataclass
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class TaskResult:
"""任务结果"""
task_id: str
status: str
result: Optional[dict] = None
error: Optional[str] = None
execution_time: float = 0
class AIIDETaskOrchestrator:
"""
AI IDE 任务编排器
职责:
1. 接收任务请求,发送到合适的队列
2. 追踪任务状态
3. 聚合结果返回给客户端
"""
def __init__(self, task_queue, result_store):
self.task_queue = task_queue
self.result_store = result_store
self.pending_tasks: Dict[str, asyncio.Future] = {}
async def submit_task(
self,
task_type: str,
payload: dict,
priority: int = 2,
metadata: dict = None
) -> str:
"""
提交任务
Args:
task_type: 任务类型
payload: 任务参数
priority: 优先级
metadata: 元数据
Returns:
task_id: 任务ID
"""
from task_queue import TaskMessage, TaskPriority
task = TaskMessage(
task_type=task_type,
priority=priority,
payload=payload,
metadata=metadata or {}
)
# 创建Future用于异步等待结果
result_future = asyncio.Future()
self.pending_tasks[task.task_id] = result_future
# 发送任务
self.task_queue.enqueue(task)
logger.info(f"任务已提交: {task.task_id}, 类型: {task_type}")
return task.task_id
async def wait_for_result(self, task_id: str, timeout: float = 300) -> TaskResult:
"""
等待任务结果
Args:
task_id: 任务ID
timeout: 超时时间(秒)
Returns:
TaskResult: 任务结果
"""
if task_id not in self.pending_tasks:
return TaskResult(
task_id=task_id,
status="not_found",
error="任务不存在或已超时"
)
future = self.pending_tasks[task_id]
try:
result = await asyncio.wait_for(future, timeout=timeout)
return result
except asyncio.TimeoutError:
return TaskResult(
task_id=task_id,
status="timeout",
error=f"任务超时({timeout}秒)"
)
finally:
self.pending_tasks.pop(task_id, None)
def on_task_complete(self, task_id: str, result: dict) -> None:
"""任务完成回调"""
if task_id in self.pending_tasks:
future = self.pending_tasks[task_id]
if not future.done():
future.set_result(TaskResult(
task_id=task_id,
status="completed",
result=result
))
def on_task_failed(self, task_id: str, error: str) -> None:
"""任务失败回调"""
if task_id in self.pending_tasks:
future = self.pending_tasks[task_id]
if not future.done():
future.set_result(TaskResult(
task_id=task_id,
status="failed",
error=error
))
class GracefulDegradationManager:
"""
优雅降级管理器
当某些服务不可用时,系统能够优雅降级,
保证核心功能不受影响。
"""
def __init__(self):
self.service_status: Dict[str, bool] = {
"ai_completion": True,
"code_analysis": True,
"semantic_search": True,
"indexing": True
}
self.fallback_handlers: Dict[str, Callable] = {}
def register_fallback(self, service: str, handler: Callable) -> None:
"""注册降级处理器"""
self.fallback_handlers[service] = handler
def set_service_status(self, service: str, available: bool) -> None:
"""更新服务状态"""
old_status = self.service_status.get(service, False)
self.service_status[service] = available
if old_status and not available:
logger.warning(f"服务降级: {service}")
elif not old_status and available:
logger.info(f"服务恢复: {service}")
async def execute_with_fallback(
self,
service: str,
primary_handler: Callable,
*args, **kwargs
):
"""
执行带降级的服务调用
Args:
service: 服务名称
primary_handler: 主处理器
*args, **kwargs: 处理器参数
"""
if self.service_status.get(service, False):
try:
return await primary_handler(*args, **kwargs)
except Exception as e:
logger.error(f"主服务调用失败: {e}")
# 降级到备用服务
if service in self.fallback_handlers:
logger.info(f"触发降级: {service}")
return await self.fallback_handlers[service](*args, **kwargs)
raise
else:
# 服务不可用,直接使用降级
if service in self.fallback_handlers:
return await self.fallback_handlers[service](*args, **kwargs)
raise ServiceUnavailableError(f"服务不可用: {service}")
class ServiceUnavailableError(Exception):
"""服务不可用异常"""
pass
# 健康检查实现
class HealthChecker:
"""
健康检查器
定期检查各服务组件的健康状态,
用于负载均衡器和告警系统。
"""
def __init__(self, task_queue, redis_client):
self.task_queue = task_queue
self.redis = redis_client
self.last_check = {}
async def check_all(self) -> Dict:
"""执行全面健康检查"""
results = {
"timestamp": time.time(),
"components": {}
}
# 检查Redis连接
results["components"]["redis"] = await self._check_redis()
# 检查任务队列
results["components"]["task_queue"] = await self._check_task_queue()
# 检查消费者
results["components"]["consumers"] = await self._check_consumers()
# 总体状态
failed_components = [
name for name, status in results["components"].items()
if not status.get("healthy", False)
]
results["overall"] = "healthy" if not failed_components else "degraded"
results["failed_components"] = failed_components
self.last_check = results
return results
async def _check_redis(self) -> Dict:
"""检查Redis连接"""
try:
start = time.time()
self.redis.ping()
latency = (time.time() - start) * 1000
return {
"healthy": True,
"latency_ms": latency
}
except Exception as e:
return {
"healthy": False,
"error": str(e)
}
async def _check_task_queue(self) -> Dict:
"""检查任务队列"""
try:
queue_length = self.task_queue.get_queue_length()
dlq_length = self.task_queue.get_dlq_length()
healthy = queue_length < 100000 and dlq_length < 1000
return {
"healthy": healthy,
"queue_length": queue_length,
"dlq_length": dlq_length
}
except Exception as e:
return {
"healthy": False,
"error": str(e)
}
async def _check_consumers(self) -> Dict:
"""检查消费者状态"""
try:
pending = self.task_queue.get_pending_tasks()
# 检查是否有活跃消费者
consumers = pending.get("consumers", [])
has_active = any(c["pending"] > 0 for c in consumers)
return {
"healthy": True,
"consumer_count": len(consumers),
"has_active": has_active,
"consumers": consumers
}
except Exception as e:
return {
"healthy": False,
"error": str(e)
}
async def demo_elastic_backend():
"""演示弹性后端架构"""
from task_queue import RedisStreamsTaskQueue
# 初始化组件
queue = RedisStreamsTaskQueue("redis://localhost:6379/0")
result_store = {} # 简化实现
# 初始化编排器
orchestrator = AIIDETaskOrchestrator(queue, result_store)
# 初始化降级管理器
degradation = GracefulDegradationManager()
# 注册降级处理器
async def fallback_analysis(payload):
return {"status": "degraded", "message": "使用简化分析"}
degradation.register_fallback("code_analysis", fallback_analysis)
# 初始化健康检查
import redis
redis_client = redis.from_url("redis://localhost:6379/0")
health_checker = HealthChecker(queue, redis_client)
# 演示:提交任务
print("=== 任务提交演示 ===")
task_id = await orchestrator.submit_task(
task_type="code_analysis",
payload={"file_path": "/project/main.py"},
priority=1
)
print(f"任务已提交: {task_id}")
# 演示:健康检查
print("\n=== 健康检查演示 ===")
health = await health_checker.check_all()
print(f"总体状态: {health['overall']}")
print(f"失败的组件: {health.get('failed_components', [])}")
# 演示:降级触发
print("\n=== 降级演示 ===")
degradation.set_service_status("code_analysis", False)
try:
result = await degradation.execute_with_fallback(
"code_analysis",
lambda: (_ for _ in()).throw(Exception("服务故障"))
)
print(f"结果: {result}")
except ServiceUnavailableError as e:
print(f"服务完全不可用: {e}")
if __name__ == "__main__":
asyncio.run(demo_elastic_backend())10 总结与展望
本节为你提供的核心价值:回顾消息队列在AI IDE系统中的核心作用,展望未来发展趋势。
10.1 核心要点总结
- 队列模型:根据任务特性选择合适的队列模型
- FIFO满足基本顺序需求
- Priority队列处理紧急任务
- Dead Letter队列实现故障追溯
- 消息格式:根据场景选择序列化格式
- JSON用于调试和日志
- Protobuf用于高性能场景
- Avro用于大数据流处理
- 投递语义:At Least Once是实际应用的主流选择
- 配合幂等消费者实现最终一致性
- Exactly Once开销巨大,谨慎使用
- 消费者组:实现负载均衡和容错
- 合理设计分区数
- 避免频繁Rebalance
- 监控消费者状态
- 顺序保证:分区有序是性能和可靠性的平衡
- 使用业务键保证相关消息同区
- 全局有序代价巨大,谨慎使用
10.2 技术选型决策树
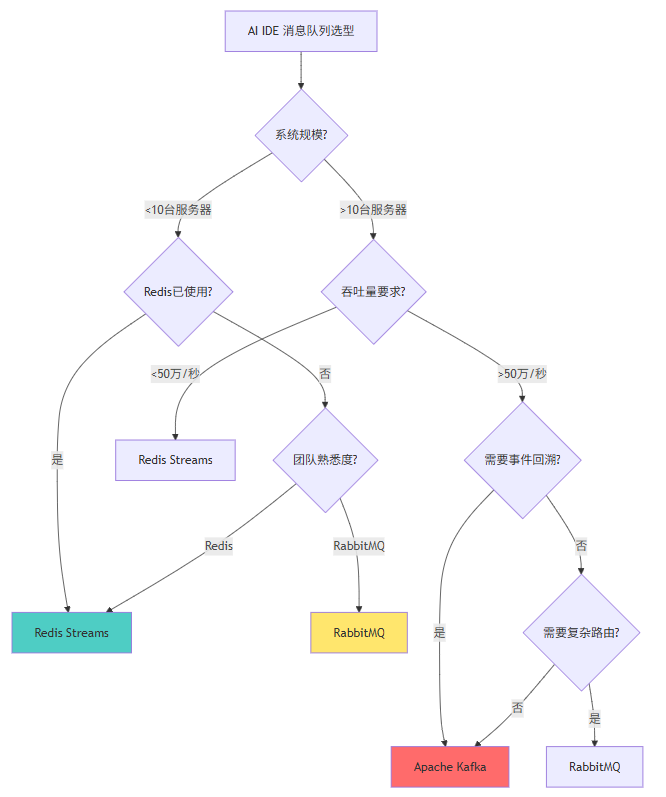
10.3 未来发展趋势
趋势 | 描述 | 对AI IDE的影响 |
|---|---|---|
边缘计算集成 | 消息队列向边缘节点延伸 | 更低延迟的本地AI推理 |
Serverless原生 | 原生支持函数式消息处理 | 弹性扩展,成本优化 |
AI原生队列 | 内置AI任务调度优化 | 更智能的任务分配 |
统一消息层 | 跨云、跨集群的统一接口 | 混合云部署更便捷 |
10.4 最佳实践清单
- 队列模型设计(优先级、死信)
- 消息格式标准化(Protobuf推荐)
- 投递语义选择(At Least Once)
- 消费者组负载均衡
- 顺序保证策略
- 监控和告警体系
- 优雅降级机制
- 健康检查实现
参考链接
- 主要来源:Redis Streams官方文档 - Redis Streams命令参考和最佳实践
- 主要来源:Apache Kafka官方文档 - Kafka架构和核心概念
- 主要来源:RabbitMQ官方文档 - RabbitMQ教程和模式
- 主要来源:Google Protocol Buffers - Protobuf语法和规范
- 主要来源:Martin Fowler - Messaging Patterns - 分布式系统消息模式
- 主要来源:Kafka Exactly Once语义 - Kafka事务和Exactly Once实现
附录(Appendix):
A. Redis Streams完整命令参考
# Redis Streams 核心命令速查
"""
XADD key [MAXLEN ~ count] field value [field value ...]
添加消息到Stream
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
读取新消息(非消费者组)
XREADGROUP GROUP name ID [COUNT count] [BLOCK milliseconds]
STREAMS key [key ...] ID [ID ...]
消费者组读取消息
XACK key group ID [ID ...]
确认消息
XPENDING key group [IDLE milliseconds] [start end count]
查看Pending消息
XCLAIM key group consumer min-idle-time ID [ID ...]
认领超时的Pending消息
XRANGE key start end [COUNT count]
按范围读取消息
XLEN key
获取Stream长度
XDEL key ID [ID ...]
删除消息
"""B. 性能基准测试脚本
# Redis Streams 性能测试
import time
import redis
import threading
from queue import Queue
def producer_test(redis_url, num_messages, num_threads):
"""生产者性能测试"""
r = redis.from_url(redis_url)
stream_key = "bench:stream"
def worker(thread_id, count):
for i in range(count):
r.xadd(stream_key, {"data": f"msg_{thread_id}_{i}"})
threads = []
messages_per_thread = num_messages // num_threads
start = time.time()
for t in range(num_threads):
t = threading.Thread(target=worker, args=(t, messages_per_thread))
threads.append(t)
t.start()
for t in threads:
t.join()
elapsed = time.time() - start
print(f"生产者: {num_messages} 消息, {num_threads} 线程")
print(f"耗时: {elapsed:.2f}s, 速率: {num_messages/elapsed:.0f}/s")
# 清理
r.delete(stream_key)
def consumer_test(redis_url, num_messages, num_consumers):
"""消费者性能测试"""
r = redis.from_url(redis_url)
stream_key = "bench:stream"
group = "bench:group"
# 准备数据
for i in range(num_messages):
r.xadd(stream_key, {"data": f"msg_{i}"})
def worker(consumer_id, results_queue):
r_local = redis.from_url(redis_url)
count = 0
while count < num_messages // num_consumers:
result = r_local.xreadgroup(
group, f"consumer_{consumer_id}",
{stream_key: ">"},
count=100,
block=1000
)
if result:
for _, messages in result:
for msg_id, _ in messages:
r_local.xack(stream_key, group, msg_id)
count += 1
results_queue.put(count)
results = Queue()
threads = []
start = time.time()
for c in range(num_consumers):
t = threading.Thread(target=worker, args=(c, results))
threads.append(t)
t.start()
for t in threads:
t.join()
elapsed = time.time() - start
total_consumed = sum(results.queue)
print(f"消费者: {total_consumed} 消息, {num_consumers} 线程")
print(f"耗时: {elapsed:.2f}s, 速率: {total_consumed/elapsed:.0f}/s")
# 清理
r.delete(stream_key)
try:
r.delete(stream_key)
except:
pass
if __name__ == "__main__":
URL = "redis://localhost:6379/0"
print("=" * 50)
print("Redis Streams 性能基准测试")
print("=" * 50)
print("\n--- 生产者测试 ---")
producer_test(URL, num_messages=100000, num_threads=4)
print("\n--- 消费者测试 ---")
consumer_test(URL, num_messages=100000, num_consumers=4)C. 常见问题排查指南
问题 | 可能原因 | 解决方案 |
|---|---|---|
消息积压严重 | 消费者处理慢或数量不足 | 增加消费者实例、优化处理逻辑 |
消费者频繁Rebalance | 消费者处理时间过长 | 增加max.poll.interval.ms |
消息重复消费 | At Least Once未正确实现幂等 | 使用唯一键去重 |
死信队列增长 | 消息格式错误或处理逻辑bug | 检查DLQ消息,分析根因 |
内存持续增长 | Stream未设置MAXLEN | 设置MAXLEN或TTL |
消息丢失 | 未确认消息或持久化未生效 | 检查XACK调用和持久化配置 |
关键词: 消息队列、异步解耦、Redis Streams、Kafka、RabbitMQ、投递语义、消费者组、负载均衡、死信队列、消息顺序、AI IDE工程系统

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号