综合实战:构建功能完备的 AI IDE 能力层

综合实战:构建功能完备的 AI IDE 能力层

安全风信子
发布于 2026-06-06 10:25:03
发布于 2026-06-06 10:25:03
作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: 本篇文章是第三卷的综合实战章节,旨在将前29篇文章中构建的所有能力组件——包括文件操作Agent、代码重构Agent、智能搜索Agent、代码审查Agent、测试生成Agent、调试Agent等——整合到一个统一的AI IDE能力层中。我们将基于第二卷的Coding Agent框架,构建一个功能完备的IDE能力层系统。该系统具备:理解代码库结构、执行文件操作、进行代码重构、提供智能搜索、自动审查代码、生成和运行测试、智能调试、扩展能力范围等核心功能。通过本篇文章,读者将掌握如何将多个专业Agent协调编排为统一的高性能AI IDE系统,以及能力层架构中的关键设计模式。
目录- 本节核心技术价值
- 1. 概述:从单Agent到能力层的演化
- 1.1 为什么需要能力层架构
- 1.2 能力层的定义与边界
- 1.3 本卷目标与架构概览
- 2. 核心数据模型设计
- 本节核心技术价值
- 2.1 能力接口抽象
- 2.2 Repository Graph 详解
- 3. 能力编排器设计
- 本节核心技术价值
- 3.1 编排器架构
- 3.2 完整编排器实现
- 4. 上下文共享机制
- 本节核心技术价值
- 4.1 上下文管理器架构
- 4.2 上下文共享示例
- 5. 统一接口与能力网关
- 本节核心技术价值
- 5.1 能力网关实现
- 6. 错误处理与降级策略
- 本节核心技术价值
- 6.1 降级策略实现
- 7. 性能优化:缓存与并行化
- 本节核心技术价值
- 7.1 性能优化实现
- 8. 完整集成示例
- 本节核心技术价值
- 8.1 完整能力层实现
- 9. 总结与展望
- 9.1 核心架构总结
- 9.2 关键技术亮点
- 9.3 未来扩展方向
- 1.1 为什么需要能力层架构
- 1.2 能力层的定义与边界
- 1.3 本卷目标与架构概览
- 本节核心技术价值
- 2.1 能力接口抽象
- 2.2 Repository Graph 详解
- 本节核心技术价值
- 3.1 编排器架构
- 3.2 完整编排器实现
- 本节核心技术价值
- 4.1 上下文管理器架构
- 4.2 上下文共享示例
- 本节核心技术价值
- 5.1 能力网关实现
- 本节核心技术价值
- 6.1 降级策略实现
- 本节核心技术价值
- 7.1 性能优化实现
- 本节核心技术价值
- 8.1 完整能力层实现
- 9.1 核心架构总结
- 9.2 关键技术亮点
- 9.3 未来扩展方向
本节核心技术价值
本文为你提供的核心价值是掌握多Agent协调编排的系统工程方法,理解如何将多个专业化的单一能力Agent整合为统一、高性能、可扩展的AI IDE能力层。通过本篇文章,你将学会设计能力编排层、实现上下文共享机制、建立统一接口标准、处理能力调用失败,以及优化性能。这不是简单的代码堆砌,而是展示一个生产级AI IDE能力层的完整架构设计。
1. 概述:从单Agent到能力层的演化
1.1 为什么需要能力层架构
在前面的文章中,我们已经实现了多个专业化的单一Agent:
- FileAgent:文件读写、创建、删除、搜索
- SearchAgent:基于语义的代码搜索
- RefactorAgent:代码重构(重命名、提取函数、修改签名)
- ReviewAgent:代码审查(风格检查、安全扫描、性能分析)
- TestAgent:测试用例生成
- DebugAgent:智能调试和错误诊断
然而,当我们尝试在真实项目中协同使用这些Agent时,发现了以下核心问题:
问题 | 描述 | 影响 |
|---|---|---|
重复上下文加载 | 每个Agent独立加载相同的代码库上下文 | 响应延迟高、资源浪费 |
能力调用碎片化 | 缺乏统一的接口标准,调用方式不一致 | 开发体验差、集成困难 |
错误处理不一致 | 各Agent的错误处理逻辑各不相同 | 系统脆弱、难于调试 |
状态不同步 | 修改操作后其他Agent不知道状态变化 | 数据不一致、潜在Bug |
资源竞争 | 多Agent并发访问文件系统时产生冲突 | 竞态条件、数据损坏 |
这些问题的本质是:我们构建的是多个"能力孤岛",而非一个"能力网络"。能力层架构正是解决这一问题的关键。
1.2 能力层的定义与边界
能力层(Capability Layer)是AI IDE架构中位于基础执行层和上层应用层之间的中间件。它的核心职责是:
- 编排协调:管理多个Agent的执行顺序和依赖关系
- 上下文管理:维护和共享代码库的语义表示(Repository Graph)
- 接口统一:提供标准化的能力调用接口
- 错误恢复:实现能力调用的降级和重试策略
- 性能优化:通过缓存和并行化提升系统吞吐量
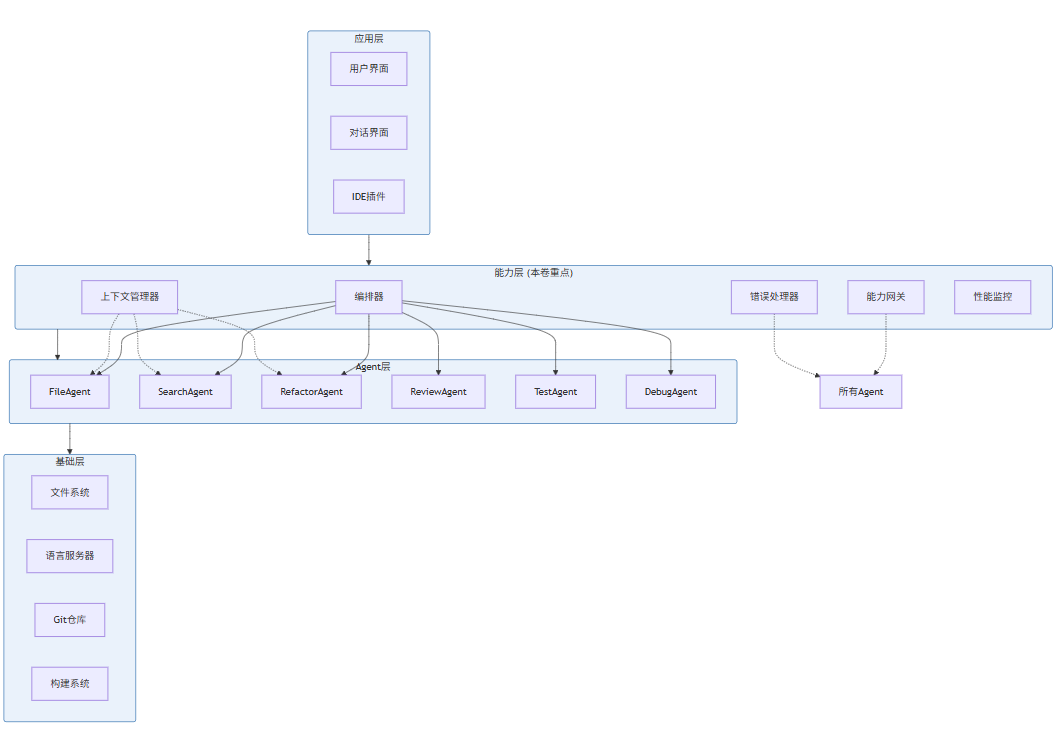
1.3 本卷目标与架构概览
本卷的目标是构建一个生产级的AI IDE能力层,具备以下特性:
核心特性:
特性 | 描述 | 技术指标 |
|---|---|---|
高吞吐量 | 支持多Agent并发执行 | 10+ 并发能力调用 |
低延迟 | 上下文复用,减少重复加载 | <100ms 上下文切换 |
强一致 | 状态同步机制 | 事件驱动一致性 |
可观测 | 完整的日志和追踪 | 结构化日志 + Trace ID |
容错强 | 多级别降级策略 | 3级降级:缓存→降级→错误 |
整体代码量: 约8000-10000行Python/TypeScript代码
2. 核心数据模型设计
本节核心技术价值
本节为你提供的核心价值是建立能力层所需的核心数据模型,包括Capability接口定义、ExecutionContext上下文传递、CapabilityResult结果标准化等。这些模型是后续所有组件的基础。
2.1 能力接口抽象
#!/usr/bin/env python3
"""
capability_models.py - AI IDE能力层核心数据模型
本模块定义了能力层的核心数据类型和接口抽象,
是整个能力层架构的基础。
包含:
1. Capability - 能力接口定义
2. CapabilityRequest/Response - 请求响应模型
3. ExecutionContext - 执行上下文
4. CapabilityResult - 能力调用结果
5. 各种枚举类型
作者: HOS(安全风信子)
日期: 2026-05-24
"""
from __future__ import annotations
import json
import uuid
from abc import ABC, abstractmethod
from dataclasses import dataclass, field, asdict
from datetime import datetime
from enum import Enum, auto
from typing import (
Any, Callable, Dict, Generic, List, Optional,
Set, TypeVar, Union, Awaitable
)
from contextvars import ContextVar
from collections import defaultdict
# ============== 基础类型定义 ==============
class CapabilityStatus(Enum):
"""能力调用状态"""
PENDING = "pending" # 等待执行
RUNNING = "running" # 执行中
SUCCESS = "success" # 执行成功
FAILED = "failed" # 执行失败
CANCELLED = "cancelled" # 已取消
DEGRADED = "degraded" # 降级执行
class CapabilityPriority(Enum):
"""能力调用优先级"""
CRITICAL = 0 # 关键任务(如安全修复)
HIGH = 1 # 高优先级(如用户等待)
NORMAL = 2 # 普通任务
LOW = 3 # 后台任务(如代码索引)
class ErrorSeverity(Enum):
"""错误严重程度"""
BLOCKING = "blocking" # 阻塞错误,无法继续
RECOVERABLE = "recoverable" # 可恢复错误
WARNING = "warning" # 警告
INFO = "info" # 信息
class ErrorCategory(Enum):
"""错误分类"""
TIMEOUT = "timeout" # 超时
NOT_FOUND = "not_found" # 资源不存在
PERMISSION = "permission" # 权限错误
VALIDATION = "validation" # 参数验证失败
EXECUTION = "execution" # 执行错误
RESOURCE = "resource" # 资源耗尽
UNKNOWN = "unknown" # 未知错误
# ============== Capability接口定义 ==============
@dataclass
class CapabilityMetadata:
"""能力元数据"""
name: str # 能力名称
version: str # 版本号
description: str # 能力描述
category: str # 能力分类
tags: List[str] = field(default_factory=list) # 标签
capabilities: List[str] = field(default_factory=list) # 能力列表
def to_dict(self) -> dict:
return asdict(self)
@classmethod
def from_dict(cls, data: dict) -> CapabilityMetadata:
return cls(**data)
@dataclass
class CapabilityInput:
"""能力输入参数基类"""
def validate(self) -> tuple[bool, Optional[str]]:
"""验证输入参数,返回(是否有效, 错误信息)"""
return True, None
def to_dict(self) -> dict:
result = {}
for key, value in asdict(self).items():
if isinstance(value, Enum):
result[key] = value.value
elif isinstance(value, datetime):
result[key] = value.isoformat()
else:
result[key] = value
return result
@dataclass
class CapabilityOutput:
"""能力输出结果基类"""
success: bool = True
data: Any = None
error: Optional[ErrorDetail] = None
metadata: Dict[str, Any] = field(default_factory=dict)
def to_dict(self) -> dict:
result = {
"success": self.success,
"data": self.data,
"error": self.error.to_dict() if self.error else None,
"metadata": self.metadata
}
return result
@dataclass
class ErrorDetail:
"""错误详情"""
code: str # 错误码
message: str # 错误消息
category: ErrorCategory # 错误分类
severity: ErrorSeverity # 严重程度
details: Dict[str, Any] = field(default_factory=dict) # 详细信息
stack_trace: Optional[str] = None # 堆栈跟踪
cause: Optional[ErrorDetail] = None # 根本原因
def to_dict(self) -> dict:
result = {
"code": self.code,
"message": self.message,
"category": self.category.value,
"severity": self.severity.value,
"details": self.details,
"stack_trace": self.stack_trace,
"cause": self.cause.to_dict() if self.cause else None
}
return result
@classmethod
def from_exception(cls, exc: Exception, category: ErrorCategory = ErrorCategory.UNKNOWN) -> ErrorDetail:
"""从异常创建ErrorDetail"""
return cls(
code=exc.__class__.__name__,
message=str(exc),
category=category,
severity=ErrorSeverity.RECOVERABLE if category in [
ErrorCategory.TIMEOUT, ErrorCategory.NOT_FOUND
] else ErrorSeverity.BLOCKING,
stack_trace=None # 生产环境应捕获
)
class Capability(ABC):
"""
能力接口抽象基类
所有Agent必须实现的接口,定义了能力调用的标准流程。
使用方式:
```python
class MyCapability(Capability):
class Input(CapabilityInput):
param1: str
param2: int
class Output(CapabilityOutput):
result: str
async def execute(self, context: ExecutionContext,
input: Input) -> Output:
# 实现能力逻辑
return Output(success=True, data="result")
```
"""
@property
@abstractmethod
def metadata(self) -> CapabilityMetadata:
"""返回能力的元数据"""
pass
@abstractmethod
async def execute(
self,
context: ExecutionContext,
input_data: CapabilityInput
) -> CapabilityOutput:
"""
执行能力
Args:
context: 执行上下文
input_data: 输入参数
Returns:
CapabilityOutput: 执行结果
"""
pass
def validate_input(self, input_data: CapabilityInput) -> tuple[bool, Optional[str]]:
"""验证输入参数"""
if input_data is None:
return False, "Input cannot be None"
return True, None
async def pre_execute(
self,
context: ExecutionContext,
input_data: CapabilityInput
) -> Optional[CapabilityOutput]:
"""
前置钩子,在execute之前调用
Returns:
如果返回None,继续执行execute
如果返回CapabilityOutput,跳过execute并返回该结果
"""
return None
async def post_execute(
self,
context: ExecutionContext,
input_data: CapabilityInput,
output: CapabilityOutput
) -> CapabilityOutput:
"""
后置钩子,在execute之后调用
可以修改输出结果
"""
return output
# ============== ExecutionContext 定义 ==============
@dataclass
class RepositoryGraph:
"""
代码库语义图谱
维护代码库的完整语义表示,包括:
- 文件结构和依赖关系
- 符号表(类、函数、变量)
- 调用图
- 类型信息
"""
project_root: str # 项目根目录
files: Dict[str, FileNode] = field(default_factory=dict) # 文件节点
symbols: Dict[str, SymbolNode] = field(default_factory=dict) # 符号表
dependencies: Dict[str, Set[str]] = field(default_factory=dict) # 依赖关系
# 缓存
_file_content_cache: Dict[str, str] = field(default_factory=dict)
_semantic_cache: Dict[str, Any] = field(default_factory=dict)
_last_updated: datetime = field(default_factory=datetime.now)
def invalidate_cache(self):
"""使缓存失效"""
self._file_content_cache.clear()
self._semantic_cache.clear()
self._last_updated = datetime.now()
def get_file_content(self, path: str) -> Optional[str]:
"""获取文件内容(带缓存)"""
if path not in self._file_content_cache:
try:
with open(path, 'r', encoding='utf-8') as f:
self._file_content_cache[path] = f.read()
except Exception:
return None
return self._file_content_cache[path]
@dataclass
class FileNode:
"""文件节点"""
path: str
language: str
size: int
modified_at: datetime
imports: List[str] = field(default_factory=list)
exports: List[str] = field(default_factory=list)
metrics: Dict[str, Any] = field(default_factory=dict)
@dataclass
class SymbolNode:
"""符号节点(类、函数、变量等)"""
name: str
kind: str # class, function, method, variable, etc.
file_path: str
line: int
column: int
signature: Optional[str] = None
docstring: Optional[str] = None
dependencies: List[str] = field(default_factory=list)
@dataclass
class UserContext:
"""用户上下文"""
user_id: str
session_id: str
workspace_id: str
preferences: Dict[str, Any] = field(default_factory=dict)
capabilities: Set[str] = field(default_factory=set) # 用户可用的能力集
@dataclass
class ExecutionContext:
"""
能力执行上下文
贯穿整个能力调用链路的核心上下文对象,
包含执行所需的所有信息。
"""
# 身份信息
request_id: str = field(default_factory=lambda: str(uuid.uuid4()))
trace_id: str = field(default_factory=lambda: str(uuid.uuid4()))
# 时间信息
created_at: datetime = field(default_factory=datetime.now)
deadline: Optional[datetime] = None # 超时截止时间
# 代码库上下文
repository_graph: Optional[RepositoryGraph] = None
current_file: Optional[str] = None
current_selection: Optional[str] = None
# 用户上下文
user_context: Optional[UserContext] = None
# 执行状态
variables: Dict[str, Any] = field(default_factory=dict) # 上下文变量
history: List[Dict[str, Any]] = field(default_factory=list) # 执行历史
# 能力层内部状态
active_capabilities: Set[str] = field(default_factory=set)
capability_results: Dict[str, CapabilityOutput] = field(default_factory=dict)
# 配置
config: Dict[str, Any] = field(default_factory=dict)
def set_variable(self, key: str, value: Any):
"""设置上下文变量"""
self.variables[key] = value
def get_variable(self, key: str, default: Any = None) -> Any:
"""获取上下文变量"""
return self.variables.get(key, default)
def add_history(self, action: str, details: Dict[str, Any]):
"""添加执行历史"""
self.history.append({
"action": action,
"details": details,
"timestamp": datetime.now().isoformat()
})
def to_dict(self) -> dict:
"""序列化为字典"""
return {
"request_id": self.request_id,
"trace_id": self.trace_id,
"created_at": self.created_at.isoformat(),
"deadline": self.deadline.isoformat() if self.deadline else None,
"current_file": self.current_file,
"active_capabilities": list(self.active_capabilities),
"history_count": len(self.history)
}
# ============== 上下文变量 ==============
# 用于在异步调用中传递上下文的ContextVar
_current_context: ContextVar[Optional[ExecutionContext]] = ContextVar(
'current_context',
default=None
)
def get_current_context() -> Optional[ExecutionContext]:
"""获取当前执行上下文"""
return _current_context.get()
def set_current_context(context: ExecutionContext) -> None:
"""设置当前执行上下文"""
_current_context.set(context)
# ============== 请求响应模型 ==============
@dataclass
class CapabilityRequest:
"""
能力调用请求
用户或系统发起的能力调用请求
"""
capability_name: str # 能力名称
input_data: CapabilityInput # 输入数据
priority: CapabilityPriority = CapabilityPriority.NORMAL
timeout: Optional[int] = None # 超时时间(秒)
retry_count: int = 0 # 已重试次数
max_retries: int = 3 # 最大重试次数
metadata: Dict[str, Any] = field(default_factory=dict)
def with_timeout(self, timeout: int) -> CapabilityRequest:
"""设置超时时间"""
self.timeout = timeout
return self
def with_priority(self, priority: CapabilityPriority) -> CapabilityRequest:
"""设置优先级"""
self.priority = priority
return self
@dataclass
class CapabilityResponse:
"""
能力调用响应
能力执行完成后的返回结果
"""
request_id: str
capability_name: str
status: CapabilityStatus
output: Optional[CapabilityOutput] = None
execution_time_ms: float = 0.0
timestamp: datetime = field(default_factory=datetime.now)
warnings: List[str] = field(default_factory=list)
def is_success(self) -> bool:
return self.status == CapabilityStatus.SUCCESS
def is_final(self) -> bool:
"""是否是最终状态(不再重试)"""
return self.status in [
CapabilityStatus.SUCCESS,
CapabilityStatus.FAILED,
CapabilityStatus.CANCELLED
]
# ============== 能力注册表 ==============
class CapabilityRegistry:
"""
能力注册表
管理所有可用能力的注册和发现
"""
_instance: Optional[CapabilityRegistry] = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._initialized = False
return cls._instance
def __init__(self):
if self._initialized:
return
self._initialized = True
# 能力注册表
self._capabilities: Dict[str, type] = {}
self._metadata: Dict[str, CapabilityMetadata] = {}
self._factories: Dict[str, Callable[[], Capability]] = {}
# 能力索引
self._by_category: Dict[str, List[str]] = defaultdict(list)
self._by_tag: Dict[str, List[str]] = defaultdict(list)
def register(
self,
capability_class: type,
factory: Optional[Callable[[], Capability]] = None
) -> None:
"""注册能力"""
capability = factory() if factory else capability_class()
metadata = capability.metadata
self._capabilities[metadata.name] = capability_class
self._metadata[metadata.name] = metadata
self._factories[metadata.name] = factory or (lambda: capability_class())
# 更新索引
self._by_category[metadata.category].append(metadata.name)
for tag in metadata.tags:
self._by_tag[tag].append(metadata.name)
def get(self, name: str) -> Optional[Capability]:
"""获取能力实例"""
factory = self._factories.get(name)
if factory:
return factory()
return None
def get_metadata(self, name: str) -> Optional[CapabilityMetadata]:
"""获取能力元数据"""
return self._metadata.get(name)
def list_all(self) -> List[CapabilityMetadata]:
"""列出所有能力"""
return list(self._metadata.values())
def list_by_category(self, category: str) -> List[CapabilityMetadata]:
"""按分类列出能力"""
names = self._by_category.get(category, [])
return [self._metadata[name] for name in names if name in self._metadata]
def discover(self, tag: str) -> List[CapabilityMetadata]:
"""按标签发现能力"""
names = self._by_tag.get(tag, [])
return [self._metadata[name] for name in names if name in self._metadata]
# 全局注册表实例
registry = CapabilityRegistry()2.2 Repository Graph 详解
Repository Graph是能力层的核心数据结构,它维护了代码库的完整语义表示。
#!/usr/bin/env python3
"""
repository_graph.py - 代码库语义图谱实现
维护代码库的完整语义表示,支持:
1. 文件结构管理
2. 符号表管理
3. 调用图管理
4. 依赖分析
5. 语义缓存
作者: HOS(安全风信子)
日期: 2026-05-24
"""
from __future__ import annotations
import os
import re
from dataclasses import dataclass, field
from datetime import datetime
from enum import Enum
from pathlib import Path
from typing import (
Any, Dict, List, Optional, Set, Tuple,
Iterator, Callable, TypeVar
)
from collections import defaultdict
import hashlib
import ast
class SymbolKind(Enum):
"""符号类型"""
MODULE = "module"
CLASS = "class"
FUNCTION = "function"
METHOD = "method"
PROPERTY = "property"
VARIABLE = "variable"
CONSTANT = "constant"
IMPORT = "import"
PARAMETER = "parameter"
@dataclass
class Location:
"""代码位置"""
file_path: str
line: int
column: int = 0
end_line: Optional[int] = None
end_column: Optional[int] = None
def to_range(self) -> dict:
return {
"start": {"line": self.line, "column": self.column},
"end": {
"line": self.end_line or self.line,
"column": self.end_column or 0
}
}
@dataclass
class Symbol:
"""代码符号"""
name: str
kind: SymbolKind
location: Location
qualified_name: str # 完全限定名,如 module.ClassName.method
signature: Optional[str] = None
docstring: Optional[str] = None
decorators: List[str] = field(default_factory=list)
modifiers: List[str] = field(default_factory=list)
# 关系
defines: List[str] = field(default_factory=list) # 本符号定义的子符号
references: List[str] = field(default_factory=list) # 引用本符号的其他符号
calls: List[str] = field(default_factory=list) # 本符号调用的其他符号
called_by: List[str] = field(default_factory=list) # 调用本符号的其他符号
# 类型信息
type_hint: Optional[str] = None
return_type: Optional[str] = None
def is_type_related(self) -> bool:
return self.kind in [
SymbolKind.CLASS, SymbolKind.FUNCTION, SymbolKind.METHOD
]
@dataclass
class ImportStatement:
"""导入语句"""
module: str
names: List[str] # 导入的名称列表
alias: Optional[str] = None
level: int = 0 # 相对导入级别
location: Location = None
@dataclass
class FileUnit:
"""文件单元"""
path: str
relative_path: str
content: Optional[str] = None
language: str = "unknown"
size: int = 0
modified_at: datetime = field(default_factory=datetime.now)
# 解析结果
imports: List[ImportStatement] = field(default_factory=list)
exports: List[str] = field(default_factory=list) # 导出的符号名
symbols: Dict[str, Symbol] = field(default_factory=dict)
# 依赖
internal_imports: List[str] = field(default_factory=list) # 内部模块依赖
external_imports: List[str] = field(default_factory=list) # 外部模块依赖
# 缓存
_content_hash: Optional[str] = None
def get_content_hash(self) -> str:
"""获取内容哈希"""
if self._content_hash is None and self.content:
self._content_hash = hashlib.md5(
self.content.encode()
).hexdigest()
return self._content_hash or ""
class LanguageParser:
"""
语言解析器接口
不同语言需要实现不同的解析器
"""
@staticmethod
def get_language(file_path: str) -> str:
"""根据文件扩展名获取语言"""
ext_map = {
'.py': 'python',
'.js': 'javascript',
'.ts': 'typescript',
'.jsx': 'javascript',
'.tsx': 'typescript',
'.java': 'java',
'.go': 'go',
'.rs': 'rust',
'.cpp': 'cpp',
'.c': 'c',
'.h': 'cpp',
'.hpp': 'cpp',
'.cs': 'csharp',
'.rb': 'ruby',
'.php': 'php',
'.swift': 'swift',
'.kt': 'kotlin',
'.scala': 'scala',
}
ext = Path(file_path).suffix.lower()
return ext_map.get(ext, 'unknown')
@staticmethod
def parse_python(content: str, file_path: str) -> FileUnit:
"""解析Python文件"""
unit = FileUnit(
path=file_path,
relative_path=file_path,
content=content,
language='python',
size=len(content)
)
try:
tree = ast.parse(content)
# 收集导入
for node in ast.walk(tree):
if isinstance(node, ast.Import):
for alias in node.names:
unit.imports.append(ImportStatement(
module=alias.name,
names=[alias.asname or alias.name],
location=Location(
file_path=file_path,
line=node.lineno,
column=node.col_offset
)
))
unit.external_imports.append(alias.name)
elif isinstance(node, ast.ImportFrom):
if node.module:
level = node.level
for alias in node.names:
unit.imports.append(ImportStatement(
module=node.module,
names=[alias.asname or alias.name],
level=level,
location=Location(
file_path=file_path,
line=node.lineno,
column=node.col_offset
)
))
if level == 0:
unit.external_imports.append(
f"{node.module}.{alias.name}"
)
# 收集符号
for node in ast.walk(tree):
if isinstance(node, ast.ClassDef):
_add_python_class(unit, node, file_path)
elif isinstance(node, ast.FunctionDef):
_add_python_function(unit, node, file_path, SymbolKind.FUNCTION)
elif isinstance(node, ast.AsyncFunctionDef):
_add_python_function(unit, node, file_path, SymbolKind.FUNCTION)
except SyntaxError:
pass
return unit
def _add_python_class(unit: FileUnit, node: ast.ClassDef, file_path: str):
"""添加Python类符号"""
location = Location(
file_path=file_path,
line=node.lineno,
column=node.col_offset,
end_line=node.end_lineno,
end_column=node.end_col_offset
)
qualified_name = f"{unit.relative_path}:{node.name}"
# 获取装饰器
decorators = []
for dec in node.decorator_list:
if isinstance(dec, ast.Name):
decorators.append(dec.id)
elif isinstance(dec, ast.Attribute):
decorators.append(f"{dec.value.id}.{dec.attr}")
# 获取docstring
docstring = ast.get_docstring(node)
symbol = Symbol(
name=node.name,
kind=SymbolKind.CLASS,
location=location,
qualified_name=qualified_name,
docstring=docstring,
decorators=decorators
)
unit.symbols[node.name] = symbol
# 收集方法
for item in node.body:
if isinstance(item, ast.FunctionDef):
_add_python_function(
unit, item, file_path,
SymbolKind.METHOD,
class_name=node.name
)
def _add_python_function(
unit: FileUnit,
node: ast.FunctionDef,
file_path: str,
kind: SymbolKind,
class_name: Optional[str] = None
):
"""添加Python函数符号"""
location = Location(
file_path=file_path,
line=node.lineno,
column=node.col_offset,
end_line=node.end_lineno,
end_column=node.end_col_offset
)
# 构建签名
args = node.args
params = []
for arg in args.args:
params.append(arg.arg)
for arg in args.posonlyargs:
params.append(arg.arg)
for arg in args.kwonlyargs:
params.append(f"{arg.arg}=")
if args.vararg:
params.append(f"*{args.vararg.arg}")
if args.kwarg:
params.append(f"**{args.kwarg.arg}")
signature = f"{node.name}({', '.join(params)})"
# 完全限定名
if class_name:
qualified_name = f"{unit.relative_path}:{class_name}.{node.name}"
else:
qualified_name = f"{unit.relative_path}:{node.name}"
# 获取装饰器
decorators = []
for dec in node.decorator_list:
if isinstance(dec, ast.Name):
decorators.append(dec.id)
elif isinstance(dec, ast.Attribute):
decorators.append(f"{dec.value.id}.{dec.attr}")
symbol = Symbol(
name=node.name,
kind=kind,
location=location,
qualified_name=qualified_name,
signature=signature,
decorators=decorators
)
unit.symbols[node.name] = symbol
class RepositoryGraphBuilder:
"""
Repository Graph 构建器
增量构建和维护代码库的语义图谱
"""
def __init__(self, project_root: str):
self.project_root = Path(project_root)
self.files: Dict[str, FileUnit] = {}
self.symbols: Dict[str, Symbol] = {} # qualified_name -> Symbol
self.files_by_module: Dict[str, str] = {} # module_name -> file_path
# 索引
self._symbols_by_file: Dict[str, Set[str]] = defaultdict(set)
self._symbols_by_kind: Dict[SymbolKind, Set[str]] = defaultdict(set)
self._call_graph: Dict[str, Set[str]] = defaultdict(set)
self._reverse_call_graph: Dict[str, Set[str]] = defaultdict(set)
def add_file(self, file_path: str, content: Optional[str] = None) -> FileUnit:
"""添加或更新文件"""
abs_path = str(Path(file_path).resolve())
# 读取内容
if content is None:
try:
with open(abs_path, 'r', encoding='utf-8') as f:
content = f.read()
except Exception as e:
return FileUnit(path=abs_path, relative_path=file_path)
# 解析文件
language = LanguageParser.get_language(abs_path)
if language == 'python':
unit = LanguageParser.parse_python(content, abs_path)
else:
unit = FileUnit(
path=abs_path,
relative_path=str(Path(abs_path).relative_to(self.project_root)),
content=content,
language=language,
size=len(content)
)
self.files[abs_path] = unit
# 更新索引
self._index_file(unit)
return unit
def _index_file(self, unit: FileUnit):
"""索引文件中的符号"""
for name, symbol in unit.symbols.items():
self.symbols[symbol.qualified_name] = symbol
self._symbols_by_file[unit.path].add(symbol.qualified_name)
self._symbols_by_kind[symbol.kind].add(symbol.qualified_name)
# 更新模块映射
self._update_module_mapping(unit)
def _update_module_mapping(self, unit: FileUnit):
"""更新模块映射"""
if unit.language == 'python':
# Python模块名推导
rel_path = unit.relative_path
if rel_path.endswith('.py'):
module_name = rel_path[:-3].replace('/', '.').replace('\\', '.')
if module_name == '__init__':
# 包
module_name = rel_path.split('/__init__.py')[0].replace('/', '.')
self.files_by_module[module_name] = unit.path
def find_symbol(self, query: str) -> List[Symbol]:
"""查找符号"""
results = []
# 精确匹配
if query in self.symbols:
results.append(self.symbols[query])
# 前缀匹配
for qname, symbol in self.symbols.items():
if qname.endswith(query) or query in qname:
if symbol not in results:
results.append(symbol)
# 模糊匹配
query_lower = query.lower()
for symbol in self.symbols.values():
if symbol not in results and query_lower in symbol.name.lower():
results.append(symbol)
return results
def find_file(self, query: str) -> List[str]:
"""查找文件"""
results = []
for path in self.files:
if query in path:
results.append(path)
return results
def get_symbol_references(self, qualified_name: str) -> List[Symbol]:
"""获取符号的引用"""
symbol = self.symbols.get(qualified_name)
if not symbol:
return []
return [
self.symbols[qname]
for qname in symbol.references
if qname in self.symbols
]
def get_callers(self, qualified_name: str) -> List[Symbol]:
"""获取调用指定符号的所有符号"""
callers = self._reverse_call_graph.get(qualified_name, set())
return [
self.symbols[qname]
for qname in callers
if qname in self.symbols
]
def get_callees(self, qualified_name: str) -> List[Symbol]:
"""获取指定符号调用的所有符号"""
callees = self._call_graph.get(qualified_name, set())
return [
self.symbols[qname]
for qname in callees
if qname in self.symbols
]
def compute_dependencies(self):
"""计算文件间的依赖关系"""
# 重置
for unit in self.files.values():
unit.internal_imports.clear()
unit.external_imports.clear()
# 分析导入关系
for unit in self.files.values():
for imp in unit.imports:
# 判断是内部还是外部导入
if imp.level > 0 or self._is_internal_module(imp.module):
unit.internal_imports.append(imp.module)
else:
unit.external_imports.append(imp.module)
def _is_internal_module(self, module_name: str) -> bool:
"""判断是否是内部模块"""
return module_name in self.files_by_module
def build(self, file_patterns: List[str] = None) -> RepositoryGraph:
"""
构建完整的RepositoryGraph
Args:
file_patterns: 文件模式列表,如['**/*.py', '**/*.js']
"""
if file_patterns is None:
file_patterns = ['**/*.py', '**/*.js', '**/*.ts', '**/*.java']
# 收集所有文件
for pattern in file_patterns:
for file_path in self.project_root.glob(pattern):
if file_path.is_file():
self.add_file(str(file_path))
# 计算依赖
self.compute_dependencies()
# 构建依赖图
dependencies: Dict[str, Set[str]] = defaultdict(set)
for unit in self.files.values():
dependencies[unit.path] = set(unit.internal_imports)
return RepositoryGraph(
project_root=str(self.project_root),
files={}, # 简化,不存储完整FileUnit
symbols=self.symbols,
dependencies=dict(dependencies)
)3. 能力编排器设计
本节核心技术价值
本节为你提供的核心价值是掌握多Agent协调编排的核心算法,包括任务分解、依赖分析、执行调度和结果聚合。这是能力层最核心的组件。
3.1 编排器架构
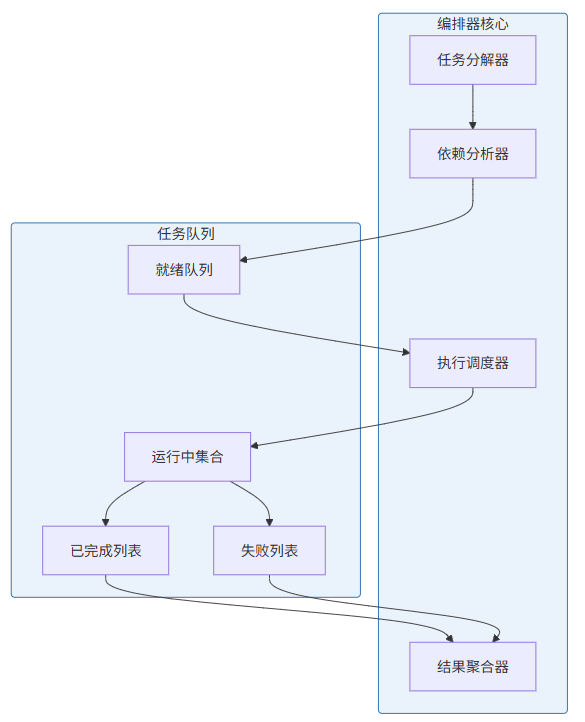
3.2 完整编排器实现
#!/usr/bin/env python3
"""
capability_orchestrator.py - AI IDE能力编排器
核心职责:
1. 接收高层任务请求
2. 分解为可执行的能力调用
3. 分析能力间的依赖关系
4. 调度执行顺序
5. 聚合结果返回
作者: HOS(安全风信子)
日期: 2026-05-24
"""
from __future__ import annotations
import asyncio
import json
import traceback
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum, auto
from typing import (
Any, Awaitable, Callable, Dict, List,
Optional, Set, Tuple, TypeVar, Generic
)
from collections import defaultdict, deque
from contextlib import asynccontextmanager
import uuid
import logging
from capability_models import (
Capability, CapabilityInput, CapabilityOutput,
CapabilityRequest, CapabilityResponse, CapabilityStatus,
CapabilityPriority, ExecutionContext, ErrorDetail,
ErrorCategory, ErrorSeverity, RepositoryGraph,
CapabilityRegistry, registry, get_current_context, set_current_context
)
# 日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# ============== 任务定义 ==============
@dataclass
class Task:
"""原子任务"""
task_id: str
capability_name: str
input_data: CapabilityInput
priority: CapabilityPriority
timeout: Optional[int] = None
# 依赖关系
depends_on: Set[str] = field(default_factory=set) # 依赖的任务ID集合
dependents: Set[str] = field(default_factory=set) # 依赖本任务的任务ID集合
# 执行状态
status: CapabilityStatus = CapabilityStatus.PENDING
result: Optional[CapabilityResponse] = None
error: Optional[ErrorDetail] = None
# 执行跟踪
created_at: datetime = field(default_factory=datetime.now)
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
def execution_time_ms(self) -> float:
"""计算执行时间(毫秒)"""
if self.started_at and self.completed_at:
return (self.completed_at - self.started_at).total_seconds() * 1000
elif self.started_at:
return (datetime.now() - self.started_at).total_seconds() * 1000
return 0.0
@dataclass
class TaskGraph:
"""任务依赖图"""
tasks: Dict[str, Task] = field(default_factory=dict)
execution_order: List[List[str]] = field(default_factory=list) # 分层执行顺序
def add_task(self, task: Task):
"""添加任务"""
self.tasks[task.task_id] = task
def add_dependency(self, task_id: str, depends_on: str):
"""添加依赖关系"""
if task_id in self.tasks and depends_on in self.tasks:
self.tasks[task_id].depends_on.add(depends_on)
self.tasks[depends_on].dependents.add(task_id)
def topological_sort(self) -> bool:
"""
拓扑排序,返回分层执行顺序
Returns:
True if successful, False if cycle detected
"""
# Kahn算法
in_degree = {tid: 0 for tid in self.tasks}
for task in self.tasks.values():
for dep in task.depends_on:
in_degree[task.task_id] += 1
# 初始入度为0的节点
queue = deque([
tid for tid, degree in in_degree.items()
if degree == 0
])
layers: List[List[str]] = []
while queue:
current_layer = []
for _ in range(len(queue)):
tid = queue.popleft()
current_layer.append(tid)
task = self.tasks[tid]
for dependent in task.dependents:
in_degree[dependent] -= 1
if in_degree[dependent] == 0:
queue.append(dependent)
if current_layer:
layers.append(current_layer)
# 检查是否有环
if sum(len(layer) for layer in layers) != len(self.tasks):
logger.error("Cycle detected in task graph")
return False
self.execution_order = layers
return True
# ============== 任务分解器 ==============
class TaskDecomposer:
"""
任务分解器
将高层用户请求分解为可执行的能力调用任务
"""
def __init__(self, registry: CapabilityRegistry):
self.registry = registry
def decompose(
self,
request: str,
context: ExecutionContext
) -> TaskGraph:
"""
分解请求为任务图
Args:
request: 用户请求(自然语言或结构化描述)
context: 执行上下文
Returns:
TaskGraph: 任务依赖图
"""
task_graph = TaskGraph()
# 意图识别
intent = self._analyze_intent(request, context)
# 根据意图生成任务
if intent.action == "implement":
tasks = self._decompose_implementation(intent, context)
elif intent.action == "refactor":
tasks = self._decompose_refactor(intent, context)
elif intent.action == "review":
tasks = self._decompose_review(intent, context)
elif intent.action == "debug":
tasks = self._decompose_debug(intent, context)
elif intent.action == "search":
tasks = self._decompose_search(intent, context)
else:
tasks = self._decompose_generic(intent, context)
# 构建任务图
for task in tasks:
task_graph.add_task(task)
# 设置依赖关系
self._resolve_dependencies(task_graph, intent)
# 拓扑排序
task_graph.topological_sort()
return task_graph
def _analyze_intent(self, request: str, context: ExecutionContext) -> Intent:
"""分析用户意图"""
# 简化的意图识别
# 生产环境应使用LLM进行意图识别
intent = Intent(action="generic", target="")
request_lower = request.lower()
if "实现" in request or "implement" in request_lower or "create" in request_lower:
intent.action = "implement"
elif "重构" in request or "refactor" in request_lower:
intent.action = "refactor"
elif "审查" in request or "review" in request_lower or "检查" in request:
intent.action = "review"
elif "调试" in request or "debug" in request_lower:
intent.action = "debug"
elif "搜索" in request or "search" in request_lower or "查找" in request:
intent.action = "search"
# 提取目标
if context.current_file:
intent.target = context.current_file
return intent
def _decompose_implementation(
self,
intent: Intent,
context: ExecutionContext
) -> List[Task]:
"""分解实现任务"""
tasks = []
# 1. 搜索相关代码
search_task = Task(
task_id=str(uuid.uuid4()),
capability_name="search",
input_data=SearchInput(query=intent.target or ""),
priority=CapabilityPriority.NORMAL
)
tasks.append(search_task)
# 2. 读取当前文件
if context.current_file:
read_task = Task(
task_id=str(uuid.uuid4()),
capability_name="read_file",
input_data=ReadFileInput(path=context.current_file),
priority=CapabilityPriority.HIGH,
depends_on={search_task.task_id}
)
tasks.append(read_task)
# 3. 生成代码
generate_task = Task(
task_id=str(uuid.uuid4()),
capability_name="code_generate",
input_data=CodeGenerateInput(
context=intent.target or "",
related_files=[context.current_file] if context.current_file else []
),
priority=CapabilityPriority.HIGH,
depends_on={search_task.task_id}
)
tasks.append(generate_task)
return tasks
def _decompose_refactor(
self,
intent: Intent,
context: ExecutionContext
) -> List[Task]:
"""分解重构任务"""
tasks = []
# 1. 分析代码结构
analyze_task = Task(
task_id=str(uuid.uuid4()),
capability_name="analyze_structure",
input_data=AnalyzeInput(target=intent.target or ""),
priority=CapabilityPriority.HIGH
)
tasks.append(analyze_task)
# 2. 执行重构
refactor_task = Task(
task_id=str(uuid.uuid4()),
capability_name="refactor",
input_data=RefactorInput(
target=intent.target or "",
operation="rename"
),
priority=CapabilityPriority.HIGH,
depends_on={analyze_task.task_id}
)
tasks.append(refactor_task)
return tasks
def _decompose_review(
self,
intent: Intent,
context: ExecutionContext
) -> List[Task]:
"""分解审查任务"""
tasks = []
review_task = Task(
task_id=str(uuid.uuid4()),
capability_name="review",
input_data=ReviewInput(
files=[intent.target] if intent.target else [context.current_file],
focus_areas=["security", "performance", "style"]
),
priority=CapabilityPriority.NORMAL
)
tasks.append(review_task)
return tasks
def _decompose_debug(
self,
intent: Intent,
context: ExecutionContext
) -> List[Task]:
"""分解调试任务"""
tasks = []
# 1. 收集错误信息
collect_task = Task(
task_id=str(uuid.uuid4()),
capability_name="collect_error_info",
input_data=CollectErrorInput(context=context),
priority=CapabilityPriority.CRITICAL
)
tasks.append(collect_task)
# 2. 诊断问题
diagnose_task = Task(
task_id=str(uuid.uuid4()),
capability_name="diagnose",
input_data=DiagnoseInput(target=intent.target or ""),
priority=CapabilityPriority.CRITICAL,
depends_on={collect_task.task_id}
)
tasks.append(diagnose_task)
return tasks
def _decompose_search(
self,
intent: Intent,
context: ExecutionContext
) -> List[Task]:
"""分解搜索任务"""
tasks = []
search_task = Task(
task_id=str(uuid.uuid4()),
capability_name="semantic_search",
input_data=SemanticSearchInput(query=intent.target or ""),
priority=CapabilityPriority.NORMAL
)
tasks.append(search_task)
return tasks
def _decompose_generic(
self,
intent: Intent,
context: ExecutionContext
) -> List[Task]:
"""分解通用任务"""
# 默认使用自然语言处理能力
tasks = []
nl_task = Task(
task_id=str(uuid.uuid4()),
capability_name="natural_language",
input_data=NLInput(
request=intent.original_request,
context=context
),
priority=CapabilityPriority.NORMAL
)
tasks.append(nl_task)
return tasks
def _resolve_dependencies(
self,
task_graph: TaskGraph,
intent: Intent
):
"""解析任务间的依赖关系"""
# 根据任务类型和执行顺序自动添加依赖
# 这里可以添加更复杂的依赖分析逻辑
pass
@dataclass
class Intent:
"""用户意图"""
action: str # 操作类型
target: Optional[str] = None # 目标
parameters: Dict[str, Any] = field(default_factory=dict)
original_request: str = ""
# ============== 能力输入定义 ==============
class SearchInput(CapabilityInput):
"""搜索能力输入"""
def __init__(self, query: str):
self.query = query
class ReadFileInput(CapabilityInput):
"""读取文件输入"""
def __init__(self, path: str, start: int = 0, end: Optional[int] = None):
self.path = path
self.start = start
self.end = end
class CodeGenerateInput(CapabilityInput):
"""代码生成输入"""
def __init__(self, context: str, related_files: List[str] = None):
self.context = context
self.related_files = related_files or []
class AnalyzeInput(CapabilityInput):
"""分析结构输入"""
def __init__(self, target: str):
self.target = target
class RefactorInput(CapabilityInput):
"""重构输入"""
def __init__(self, target: str, operation: str, **kwargs):
self.target = target
self.operation = operation
self.extra = kwargs
class ReviewInput(CapabilityInput):
"""审查输入"""
def __init__(self, files: List[str], focus_areas: List[str] = None):
self.files = files
self.focus_areas = focus_areas or []
class CollectErrorInput(CapabilityInput):
"""收集错误信息输入"""
def __init__(self, context: ExecutionContext):
self.context = context
class DiagnoseInput(CapabilityInput):
"""诊断输入"""
def __init__(self, target: str):
self.target = target
class SemanticSearchInput(CapabilityInput):
"""语义搜索输入"""
def __init__(self, query: str, filters: Dict[str, Any] = None):
self.query = query
self.filters = filters or {}
class NLInput(CapabilityInput):
"""自然语言处理输入"""
def __init__(self, request: str, context: ExecutionContext):
self.request = request
self.context = context
# ============== 执行调度器 ==============
class ExecutionScheduler:
"""
执行调度器
负责任务的执行调度,支持:
1. 并发执行
2. 优先级调度
3. 资源限制
4. 超时控制
"""
def __init__(
self,
max_concurrent: int = 10,
default_timeout: int = 300
):
self.max_concurrent = max_concurrent
self.default_timeout = default_timeout
self._semaphore: Optional[asyncio.Semaphore] = None
self._running_tasks: Set[str] = set()
@asynccontextmanager
async def execute_task(
self,
task: Task,
capability: Capability,
context: ExecutionContext
):
"""
执行单个任务
使用async context manager管理任务生命周期
"""
task.status = CapabilityStatus.RUNNING
task.started_at = datetime.now()
try:
# 设置上下文
set_current_context(context)
# 执行能力
output = await asyncio.wait_for(
capability.execute(context, task.input_data),
timeout=task.timeout or self.default_timeout
)
task.status = CapabilityStatus.SUCCESS
task.result = CapabilityResponse(
request_id=task.task_id,
capability_name=task.capability_name,
status=CapabilityStatus.SUCCESS,
output=output,
execution_time_ms=task.execution_time_ms()
)
yield task.result
except asyncio.TimeoutError:
task.status = CapabilityStatus.FAILED
task.error = ErrorDetail(
code="TIMEOUT",
message=f"Task {task.task_id} timed out",
category=ErrorCategory.TIMEOUT,
severity=ErrorSeverity.RECOVERABLE,
details={"timeout": task.timeout}
)
task.result = CapabilityResponse(
request_id=task.task_id,
capability_name=task.capability_name,
status=CapabilityStatus.FAILED,
execution_time_ms=task.execution_time_ms()
)
except Exception as e:
task.status = CapabilityStatus.FAILED
task.error = ErrorDetail.from_exception(e)
task.result = CapabilityResponse(
request_id=task.task_id,
capability_name=task.capability_name,
status=CapabilityStatus.FAILED,
execution_time_ms=task.execution_time_ms()
)
finally:
task.completed_at = datetime.now()
set_current_context(None)
async def execute_layer(
self,
tasks: List[Task],
capability_map: Dict[str, Capability],
context: ExecutionContext
) -> List[Task]:
"""
执行一层任务(同一层的任务可以并行执行)
"""
if not tasks:
return []
# 创建信号量限制并发
semaphore = asyncio.Semaphore(self.max_concurrent)
async def execute_with_semaphore(task: Task) -> Task:
async with semaphore:
capability = capability_map.get(task.capability_name)
if not capability:
task.status = CapabilityStatus.FAILED
task.error = ErrorDetail(
code="CAPABILITY_NOT_FOUND",
message=f"Capability {task.capability_name} not found",
category=ErrorCategory.NOT_FOUND,
severity=ErrorSeverity.BLOCKING
)
return task
async with self.execute_task(task, capability, context):
pass
return task
# 并发执行所有任务
results = await asyncio.gather(
*[execute_with_semaphore(task) for task in tasks],
return_exceptions=True
)
# 处理异常结果
for i, result in enumerate(results):
if isinstance(result, Exception):
tasks[i].status = CapabilityStatus.FAILED
tasks[i].error = ErrorDetail.from_exception(result)
return tasks
# ============== 结果聚合器 ==============
class ResultAggregator:
"""
结果聚合器
负责聚合多个任务的执行结果,生成统一的响应
"""
def aggregate(
self,
task_graph: TaskGraph,
context: ExecutionContext
) -> AggregatedResult:
"""
聚合任务结果
Returns:
AggregatedResult: 聚合后的结果
"""
successful_tasks = []
failed_tasks = []
cancelled_tasks = []
for task in task_graph.tasks.values():
if task.status == CapabilityStatus.SUCCESS:
successful_tasks.append(task)
elif task.status == CapabilityStatus.FAILED:
failed_tasks.append(task)
elif task.status == CapabilityStatus.CANCELLED:
cancelled_tasks.append(task)
# 构建执行摘要
summary = ExecutionSummary(
total_tasks=len(task_graph.tasks),
successful=len(successful_tasks),
failed=len(failed_tasks),
cancelled=len(cancelled_tasks),
total_time_ms=sum(t.execution_time_ms() for t in task_graph.tasks.values()),
execution_order=task_graph.execution_order
)
# 聚合数据
aggregated_data = self._aggregate_data(successful_tasks)
# 聚合错误
errors = [task.error for task in failed_tasks if task.error]
# 构建最终结果
return AggregatedResult(
success=len(failed_tasks) == 0,
data=aggregated_data,
errors=errors,
summary=summary,
task_results={
task.task_id: task.result for task in task_graph.tasks.values()
}
)
def _aggregate_data(self, successful_tasks: List[Task]) -> Any:
"""聚合成功任务的数据"""
if not successful_tasks:
return None
# 如果只有一个任务,直接返回其数据
if len(successful_tasks) == 1:
result = successful_tasks[0].result
if result and result.output:
return result.output.data
# 多个任务,聚合为一个集合
results = []
for task in successful_tasks:
result = task.result
if result and result.output and result.output.data is not None:
results.append(result.output.data)
if len(results) == 1:
return results[0]
return results
@dataclass
class AggregatedResult:
"""聚合结果"""
success: bool
data: Any = None
errors: List[ErrorDetail] = field(default_factory=list)
summary: Optional[ExecutionSummary] = None
task_results: Dict[str, CapabilityResponse] = field(default_factory=dict)
@dataclass
class ExecutionSummary:
"""执行摘要"""
total_tasks: int
successful: int
failed: int
cancelled: int
total_time_ms: float
execution_order: List[List[str]] = field(default_factory=list)
# ============== 能力编排器主类 ==============
class CapabilityOrchestrator:
"""
能力编排器主类
整合所有子组件,提供统一的能力编排接口
"""
def __init__(self, registry: CapabilityRegistry = None):
self.registry = registry or CapabilityRegistry()
self.decomposer = TaskDecomposer(self.registry)
self.scheduler = ExecutionScheduler()
self.aggregator = ResultAggregator()
# 能力实例缓存
self._capability_cache: Dict[str, Capability] = {}
def _get_capability(self, name: str) -> Optional[Capability]:
"""获取能力实例(带缓存)"""
if name not in self._capability_cache:
self._capability_cache[name] = self.registry.get(name)
return self._capability_cache.get(name)
async def execute(
self,
request: str,
context: ExecutionContext
) -> AggregatedResult:
"""
执行能力编排
主入口方法,接收用户请求,返回聚合结果
"""
logger.info(f"Executing request: {request[:100]}")
# 1. 分解任务
task_graph = self.decomposer.decompose(request, context)
logger.info(f"Decomposed into {len(task_graph.tasks)} tasks")
# 2. 获取能力映射
capability_map = {}
for task in task_graph.tasks.values():
cap = self._get_capability(task.capability_name)
if cap:
capability_map[task.capability_name] = cap
else:
# 能力不存在,标记任务失败
task.status = CapabilityStatus.FAILED
task.error = ErrorDetail(
code="CAPABILITY_NOT_FOUND",
message=f"Capability '{task.capability_name}' not registered",
category=ErrorCategory.NOT_FOUND,
severity=ErrorSeverity.BLOCKING
)
# 3. 按层次执行
for layer in task_graph.execution_order:
layer_tasks = [task_graph.tasks[tid] for tid in layer]
await self.scheduler.execute_layer(
layer_tasks,
capability_map,
context
)
# 4. 聚合结果
result = self.aggregator.aggregate(task_graph, context)
logger.info(f"Execution complete: success={result.success}")
return result
async def execute_capability(
self,
capability_name: str,
input_data: CapabilityInput,
context: ExecutionContext
) -> CapabilityResponse:
"""
直接执行单个能力
用于已知具体能力时的直接调用
"""
capability = self._get_capability(capability_name)
if not capability:
return CapabilityResponse(
request_id=context.request_id,
capability_name=capability_name,
status=CapabilityStatus.FAILED,
output=CapabilityOutput(
success=False,
error=ErrorDetail(
code="CAPABILITY_NOT_FOUND",
message=f"Capability '{capability_name}' not found",
category=ErrorCategory.NOT_FOUND,
severity=ErrorSeverity.BLOCKING
)
)
)
task = Task(
task_id=str(uuid.uuid4()),
capability_name=capability_name,
input_data=input_data,
priority=CapabilityPriority.NORMAL
)
async with self.scheduler.execute_task(task, capability, context):
pass
return task.result
def register_capability(self, capability_class: type):
"""注册能力"""
self.registry.register(capability_class)4. 上下文共享机制
本节核心技术价值
本节为你提供的核心价值是理解如何在多Agent间高效共享上下文,包括Repository Graph的复用、增量更新机制、以及上下文作用域管理。这是降低延迟、提升吞吐量的关键。
4.1 上下文管理器架构
#!/usr/bin/env python3
"""
context_manager.py - AI IDE上下文管理器
核心职责:
1. 维护Repository Graph的生命周期
2. 提供上下文缓存和复用
3. 管理上下文的作用域和隔离
4. 处理上下文的增量更新
作者: HOS(安全风信子)
日期: 2026-05-24
"""
from __future__ import annotations
import asyncio
import hashlib
import time
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum, auto
from pathlib import Path
from typing import (
Any, Awaitable, Callable, Dict,
List, Optional, Set, Tuple, TypeVar
)
from collections import defaultdict
import logging
logger = logging.getLogger(__name__)
class CacheStrategy(Enum):
"""缓存策略"""
LRU = "lru" # 最近最少使用
LFU = "lfu" # 最近最常使用
TTL = "ttl" # 基于时间
INVALIDATING = "invalidating" # 手动失效
@dataclass
class CacheEntry:
"""缓存条目"""
key: str
value: Any
created_at: datetime = field(default_factory=datetime.now)
last_accessed: datetime = field(default_factory=datetime.now)
access_count: int = 0
size_bytes: int = 0
tags: Set[str] = field(default_factory=set)
def access(self) -> None:
"""记录访问"""
self.last_accessed = datetime.now()
self.access_count += 1
def is_expired(self, ttl_seconds: int) -> bool:
"""检查是否过期"""
return (datetime.now() - self.created_at).total_seconds() > ttl_seconds
@dataclass
class ContextScope:
"""上下文作用域"""
scope_id: str
name: str
parent_scope: Optional[ContextScope] = None
repository_graph_path: Optional[str] = None
# 作用域内的缓存
local_cache: Dict[str, CacheEntry] = field(default_factory=dict)
# 作用域配置
ttl_seconds: int = 300 # 默认5分钟
max_cache_size: int = 100 # 最大缓存条目数
def get(self, key: str) -> Optional[Any]:
"""获取缓存值"""
entry = self.local_cache.get(key)
if entry:
if entry.is_expired(self.ttl_seconds):
del self.local_cache[key]
return None
entry.access()
return entry.value
return None
def set(self, key: str, value: Any, tags: Set[str] = None) -> None:
"""设置缓存值"""
# 检查大小限制
if len(self.local_cache) >= self.max_cache_size:
self._evict_lru()
entry = CacheEntry(
key=key,
value=value,
tags=tags or set()
)
self.local_cache[key] = entry
def _evict_lru(self) -> None:
"""驱逐最近最少使用的条目"""
if not self.local_cache:
return
# 找到最旧的条目
oldest_key = min(
self.local_cache.keys(),
key=lambda k: self.local_cache[k].last_accessed
)
del self.local_cache[oldest_key]
def invalidate(self, key: str = None) -> None:
"""使缓存失效"""
if key:
self.local_cache.pop(key, None)
else:
self.local_cache.clear()
def invalidate_by_tag(self, tag: str) -> None:
"""按标签使缓存失效"""
keys_to_remove = [
k for k, v in self.local_cache.items()
if tag in v.tags
]
for key in keys_to_remove:
del self.local_cache[key]
class ContextManager:
"""
上下文管理器
管理ExecutionContext的生命周期和共享
"""
def __init__(
self,
default_ttl: int = 300,
max_contexts: int = 100
):
self.default_ttl = default_ttl
self.max_contexts = max_contexts
# 全局作用域
self.global_scope: ContextScope = ContextScope(
scope_id="global",
name="Global"
)
# 项目作用域
self.project_scopes: Dict[str, ContextScope] = {}
# 当前活动上下文
self._active_contexts: Dict[str, Any] = {}
# 锁
self._lock = asyncio.Lock()
# 回调
self._invalidation_callbacks: List[Callable[[str], None]] = []
def get_scope(self, workspace_id: str, project_path: str = None) -> ContextScope:
"""
获取或创建上下文作用域
Args:
workspace_id: 工作区ID
project_path: 项目路径(可选)
"""
if project_path:
scope_key = f"{workspace_id}:{hashlib.md5(project_path.encode()).hexdigest()[:8]}"
else:
scope_key = workspace_id
if scope_key not in self.project_scopes:
# 创建新作用域
parent = self.global_scope
self.project_scopes[scope_key] = ContextScope(
scope_id=scope_key,
name=project_path or workspace_id,
parent_scope=parent,
repository_graph_path=project_path
)
# 检查上限
if len(self.project_scopes) > self.max_contexts:
self._evict_oldest_scope()
return self.project_scopes[scope_key]
def _evict_oldest_scope(self) -> None:
"""驱逐最旧的项目作用域"""
if not self.project_scopes:
return
oldest_key = min(
self.project_scopes.keys(),
key=lambda k: self.project_scopes[k].local_cache.get(
"_last_accessed",
datetime.min
) if isinstance(
self.project_scopes[k].local_cache.get("_last_accessed"),
datetime
) else datetime.min
)
del self.project_scopes[oldest_key]
logger.info(f"Evicted oldest scope: {oldest_key}")
async def get_or_load_context(
self,
workspace_id: str,
project_path: str,
loader: Callable[[str], Awaitable[Any]]
) -> Any:
"""
获取或加载上下文
Args:
workspace_id: 工作区ID
project_path: 项目路径
loader: 上下文加载器
Returns:
加载的上下文
"""
scope = self.get_scope(workspace_id, project_path)
cache_key = f"context:{project_path}"
# 尝试从缓存获取
cached = scope.get(cache_key)
if cached is not None:
logger.debug(f"Context cache hit: {project_path}")
return cached
# 加载新上下文
logger.info(f"Loading context: {project_path}")
context = await loader(project_path)
# 缓存
scope.set(cache_key, context, tags={"context", project_path})
return context
def invalidate_project(
self,
workspace_id: str,
project_path: str = None
) -> None:
"""
使项目上下文失效
当项目文件发生重大变更时调用
"""
scope_key = f"{workspace_id}:{hashlib.md5(project_path.encode()).hexdigest()[:8]}" if project_path else workspace_id
if scope_key in self.project_scopes:
self.project_scopes[scope_key].invalidate()
logger.info(f"Invalidated scope: {scope_key}")
# 通知回调
for callback in self._invalidation_callbacks:
callback(scope_key)
def register_invalidation_callback(
self,
callback: Callable[[str], None]
) -> None:
"""注册失效回调"""
self._invalidation_callbacks.append(callback)
def get_cache_stats(self) -> Dict[str, Any]:
"""获取缓存统计"""
stats = {
"global_scope": {
"entries": len(self.global_scope.local_cache)
},
"project_scopes": {
"count": len(self.project_scopes),
"total_entries": sum(
len(s.scope.local_cache)
for s in self.project_scopes.values()
)
}
}
return stats4.2 上下文共享示例
#!/usr/bin/env python3
"""
context_sharing_demo.py - 上下文共享使用示例
展示如何在多Agent场景下高效共享上下文
"""
import asyncio
from datetime import datetime
from typing import List, Optional
from capability_models import ExecutionContext, RepositoryGraph
from context_manager import ContextManager
class SharedContextDemo:
"""上下文共享演示"""
def __init__(self):
self.context_manager = ContextManager()
async def demo_incremental_loading(self, project_path: str):
"""
演示增量加载如何减少延迟
"""
workspace_id = "demo-workspace"
print("=== 首次加载(冷启动)===")
start = datetime.now()
# 首次加载,构建完整graph
graph = await self.context_manager.get_or_load_context(
workspace_id,
project_path,
lambda p: self._build_graph(p)
)
cold_time = (datetime.now() - start).total_seconds()
print(f"冷启动耗时: {cold_time:.3f}s")
print(f"符号数: {len(graph.symbols)}")
print("\n=== 第二次访问(缓存命中)===")
start = datetime.now()
# 第二次访问,从缓存获取
graph_cached = await self.context_manager.get_or_load_context(
workspace_id,
project_path,
lambda p: self._build_graph(p)
)
cache_time = (datetime.now() - start).total_seconds()
print(f"缓存命中耗时: {cache_time:.6f}s")
print(f"加速比: {cold_time/cache_time:.0f}x")
async def demo_multi_agent_sharing(self, project_path: str):
"""
演示多Agent场景下的上下文共享
"""
workspace_id = "multi-agent-demo"
# Agent A 加载上下文
print("=== Agent A: 加载上下文 ===")
graph = await self.context_manager.get_or_load_context(
workspace_id,
project_path,
lambda p: self._build_graph(p)
)
context_a = ExecutionContext(
request_id="agent-a-001",
repository_graph=graph
)
print(f"Agent A 上下文ID: {id(context_a.repository_graph)}")
# Agent B 复用同一上下文
print("\n=== Agent B: 复用上下文 ===")
context_b = ExecutionContext(
request_id="agent-b-001",
repository_graph=context_a.repository_graph # 共享引用
)
print(f"Agent B 上下文ID: {id(context_b.repository_graph)}")
print(f"共享同一Graph: {context_a.repository_graph is context_b.repository_graph}")
# 模拟并行执行
print("\n=== 并行执行多个Agent ===")
async def agent_task(agent_id: str, context: ExecutionContext):
print(f"Agent {agent_id} 开始执行...")
await asyncio.sleep(0.1) # 模拟工作
print(f"Agent {agent_id} 完成")
return f"Result from {agent_id}"
# 并行执行3个Agent,共享同一Graph
results = await asyncio.gather(
agent_task("SearchAgent", context_a),
agent_task("RefactorAgent", context_b),
agent_task("ReviewAgent", context_a), # 复用context_a
)
print(f"\n所有Agent完成,结果: {results}")
async def _build_graph(self, project_path: str) -> RepositoryGraph:
"""构建Graph(模拟)"""
await asyncio.sleep(0.5) # 模拟IO延迟
# 返回空的RepositoryGraph作为示例
return RepositoryGraph(
project_root=project_path,
files={},
symbols={},
dependencies={}
)
async def main():
demo = SharedContextDemo()
print("=" * 60)
print("上下文共享机制演示")
print("=" * 60)
# 演示增量加载
await demo.demo_incremental_loading("/path/to/project")
print("\n" + "=" * 60)
# 演示多Agent共享
await demo.demo_multi_agent_sharing("/path/to/project")
if __name__ == "__main__":
asyncio.run(main())5. 统一接口与能力网关
本节核心技术价值
本节为你提供的核心价值是设计统一的能力调用接口,隐藏底层Agent的差异,提供一致的错误处理、监控和认证机制。能力网关是能力层的对外接口。
5.1 能力网关实现
#!/usr/bin/env python3
"""
capability_gateway.py - AI IDE能力网关
作为能力层的统一入口,提供:
1. 统一的请求路由
2. 认证和授权
3. 请求验证
4. 速率限制
5. 监控和追踪
6. 统一错误处理
作者: HOS(安全风信子)
日期: 2026-05-24
"""
from __future__ import annotations
import asyncio
import json
import time
import traceback
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum, auto
from typing import (
Any, Awaitable, Callable, Dict,
List, Optional, Set, TypeVar, Union
)
from collections import defaultdict
from contextlib import asynccontextmanager
import logging
import uuid
from capability_models import (
Capability, CapabilityInput, CapabilityOutput,
CapabilityRequest, CapabilityResponse, CapabilityStatus,
CapabilityPriority, CapabilityMetadata,
ExecutionContext, ErrorDetail, ErrorCategory, ErrorSeverity,
CapabilityRegistry
)
logger = logging.getLogger(__name__)
# ============== 认证和授权 ==============
@dataclass
class AuthToken:
"""认证令牌"""
token: str
user_id: str
workspace_id: str
capabilities: Set[str] # 用户有权限访问的能力
expires_at: datetime
scopes: List[str] = field(default_factory=list)
def is_expired(self) -> bool:
return datetime.now() > self.expires_at
def has_capability(self, capability: str) -> bool:
"""检查是否有权限访问指定能力"""
if "admin" in self.scopes:
return True
return capability in self.capabilities
class AuthProvider:
"""
认证提供者
管理用户认证和授权
"""
def __init__(self):
self._tokens: Dict[str, AuthToken] = {}
self._users: Dict[str, dict] = {} # user_id -> user_info
async def authenticate(
self,
credentials: dict
) -> Optional[AuthToken]:
"""
验证用户凭证
Args:
credentials: 包含用户名密码或其他凭证的字典
Returns:
AuthToken if successful, None otherwise
"""
username = credentials.get("username")
password = credentials.get("password")
# 简化的认证逻辑
# 生产环境应连接真实认证服务
if username and password:
user_id = f"user_{hash(username)}"
workspace_id = f"workspace_{hash(username)}"
token = AuthToken(
token=str(uuid.uuid4()),
user_id=user_id,
workspace_id=workspace_id,
capabilities={"*"}, # 全部能力
expires_at=datetime.now() + timedelta(hours=24),
scopes=["admin"]
)
self._tokens[token.token] = token
return token
return None
async def authorize(
self,
token: str,
capability: str
) -> bool:
"""
检查用户是否有权限访问指定能力
"""
auth_token = self._tokens.get(token)
if not auth_token or auth_token.is_expired():
return False
return auth_token.has_capability(capability)
def revoke_token(self, token: str) -> bool:
"""撤销令牌"""
if token in self._tokens:
del self._tokens[token]
return True
return False
# ============== 速率限制 ==============
@dataclass
class RateLimitConfig:
"""速率限制配置"""
max_requests: int = 100 # 时间窗口内最大请求数
window_seconds: int = 60 # 时间窗口大小(秒)
burst_size: int = 10 # 突发大小
class RateLimiter:
"""
速率限制器
基于令牌桶算法的速率限制
"""
def __init__(self, config: RateLimitConfig = None):
self.config = config or RateLimitConfig()
self._buckets: Dict[str, List[datetime]] = defaultdict(list)
self._lock = asyncio.Lock()
async def check_rate_limit(
self,
key: str,
cost: int = 1
) -> tuple[bool, Optional[str]]:
"""
检查速率限制
Args:
key: 限制键(如 user_id, IP等)
cost: 请求消耗的令牌数
Returns:
(是否允许, 错误消息)
"""
async with self._lock:
now = datetime.now()
window_start = now - timedelta(seconds=self.config.window_seconds)
# 清理过期记录
self._buckets[key] = [
t for t in self._buckets[key]
if t > window_start
]
# 检查限制
if len(self._buckets[key]) + cost > self.config.max_requests:
retry_after = self._get_retry_after(key)
return False, f"Rate limit exceeded. Retry after {retry_after}s"
# 消耗令牌
for _ in range(cost):
self._buckets[key].append(now)
return True, None
def _get_retry_after(self, key: str) -> int:
"""计算重试间隔"""
if not self._buckets[key]:
return 0
oldest = min(self._buckets[key])
retry_at = oldest + timedelta(seconds=self.config.window_seconds)
return max(0, int((retry_at - datetime.now()).total_seconds()))
# ============== 请求验证 ==============
class RequestValidator:
"""
请求验证器
验证能力调用的请求格式和参数
"""
def __init__(self, registry: CapabilityRegistry):
self.registry = registry
def validate_request(
self,
request: dict
) -> tuple[bool, Optional[str], Optional[dict]]:
"""
验证请求格式
Args:
request: 请求字典
Returns:
(是否有效, 错误消息, 清理后的请求)
"""
# 检查必需字段
if "capability" not in request:
return False, "Missing 'capability' field", None
if "input" not in request:
return False, "Missing 'input' field", None
capability_name = request["capability"]
metadata = self.registry.get_metadata(capability_name)
if not metadata:
return False, f"Unknown capability: {capability_name}", None
# 清理并返回
cleaned = {
"capability": capability_name,
"input": request["input"],
"priority": request.get("priority", "NORMAL"),
"timeout": request.get("timeout"),
"metadata": request.get("metadata", {})
}
return True, None, cleaned
# ============== 监控和追踪 ==============
@dataclass
class RequestTrace:
"""请求追踪信息"""
trace_id: str
request_id: str
capability: str
start_time: datetime
end_time: Optional[datetime] = None
status: Optional[str] = None
error: Optional[str] = None
duration_ms: Optional[float] = None
metadata: Dict[str, Any] = field(default_factory=dict)
class MetricsCollector:
"""
指标收集器
收集能力调用的各项指标
"""
def __init__(self):
# 计数器
self.request_count: Dict[str, int] = defaultdict(int)
self.error_count: Dict[str, int] = defaultdict(int)
self.success_count: Dict[str, int] = defaultdict(int)
# 延迟统计
self.latencies: Dict[str, List[float]] = defaultdict(list)
# 追踪
self.traces: Dict[str, RequestTrace] = {}
# 锁
self._lock = asyncio.Lock()
async def record_request_start(
self,
trace_id: str,
request_id: str,
capability: str
) -> None:
"""记录请求开始"""
trace = RequestTrace(
trace_id=trace_id,
request_id=request_id,
capability=capability,
start_time=datetime.now()
)
async with self._lock:
self.traces[trace_id] = trace
async def record_request_end(
self,
trace_id: str,
status: str,
error: str = None
) -> None:
"""记录请求结束"""
async with self._lock:
if trace_id not in self.traces:
return
trace = self.traces[trace_id]
trace.end_time = datetime.now()
trace.status = status
trace.error = error
trace.duration_ms = (
trace.end_time - trace.start_time
).total_seconds() * 1000
# 更新计数器
self.request_count[trace.capability] += 1
if status == "success":
self.success_count[trace.capability] += 1
else:
self.error_count[trace.capability] += 1
# 记录延迟
self.latencies[trace.capability].append(trace.duration_ms)
def get_metrics(self) -> dict:
"""获取指标摘要"""
return {
"total_requests": sum(self.request_count.values()),
"total_errors": sum(self.error_count.values()),
"by_capability": {
cap: {
"requests": self.request_count[cap],
"errors": self.error_count[cap],
"success_rate": (
self.success_count[cap] / self.request_count[cap]
if self.request_count[cap] > 0 else 0
),
"avg_latency_ms": (
sum(self.latencies[cap]) / len(self.latencies[cap])
if self.latencies[cap] else 0
),
"p95_latency_ms": self._percentile(
self.latencies[cap], 95
) if self.latencies[cap] else 0
}
for cap in self.request_count.keys()
}
}
def _percentile(self, values: List[float], percentile: int) -> float:
"""计算百分位数"""
if not values:
return 0
sorted_values = sorted(values)
index = int(len(sorted_values) * percentile / 100)
return sorted_values[min(index, len(sorted_values) - 1)]
# ============== 能力网关主类 ==============
class CapabilityGateway:
"""
能力网关主类
整合所有中间件功能,提供统一的API入口
"""
def __init__(self, registry: CapabilityRegistry = None):
self.registry = registry or CapabilityRegistry()
# 中间件
self.auth_provider = AuthProvider()
self.rate_limiter = RateLimiter()
self.validator = RequestValidator(self.registry)
self.metrics = MetricsCollector()
# 编排器引用
self._orchestrator = None
# 配置
self._config = {
"enable_auth": True,
"enable_rate_limit": True,
"enable_metrics": True,
"default_timeout": 300
}
def set_orchestrator(self, orchestrator):
"""设置编排器引用"""
self._orchestrator = orchestrator
@asynccontextmanager
async def handle_request(
self,
request: dict,
auth_token: Optional[str] = None
):
"""
处理请求的上下文管理器
统一处理认证、验证、监控等逻辑
"""
trace_id = str(uuid.uuid4())
request_id = request.get("request_id", str(uuid.uuid4()))
# 创建追踪
await self.metrics.record_request_start(
trace_id,
request_id,
request.get("capability", "unknown")
)
error = None
response = None
try:
# 1. 认证
if self._config["enable_auth"] and auth_token:
is_authorized = await self.auth_provider.authorize(
auth_token,
request.get("capability", "")
)
if not is_authorized:
raise PermissionError("Not authorized")
# 2. 速率限制
if self._config["enable_rate_limit"]:
allowed, error_msg = await self.rate_limiter.check_rate_limit(
auth_token or "anonymous"
)
if not allowed:
raise PermissionError(error_msg)
# 3. 验证
valid, error_msg, cleaned = self.validator.validate_request(request)
if not valid:
raise ValueError(error_msg)
# 4. 执行
if not self._orchestrator:
raise RuntimeError("Orchestrator not configured")
# 创建上下文
context = ExecutionContext(
request_id=request_id,
trace_id=trace_id,
config=self._config
)
# 执行能力
response = await self._orchestrator.execute_capability(
cleaned["capability"],
cleaned["input"],
context
)
yield response
except PermissionError as e:
error = str(e)
response = CapabilityResponse(
request_id=request_id,
capability_name=request.get("capability", ""),
status=CapabilityStatus.FAILED,
output=CapabilityOutput(
success=False,
error=ErrorDetail(
code="PERMISSION_DENIED",
message=error,
category=ErrorCategory.PERMISSION,
severity=ErrorSeverity.BLOCKING
)
)
)
yield response
except ValueError as e:
error = str(e)
response = CapabilityResponse(
request_id=request_id,
capability_name=request.get("capability", ""),
status=CapabilityStatus.FAILED,
output=CapabilityOutput(
success=False,
error=ErrorDetail(
code="VALIDATION_ERROR",
message=error,
category=ErrorCategory.VALIDATION,
severity=ErrorSeverity.BLOCKING
)
)
)
yield response
except Exception as e:
error = f"{e.__class__.__name__}: {str(e)}"
logger.exception(f"Request failed: {error}")
response = CapabilityResponse(
request_id=request_id,
capability_name=request.get("capability", ""),
status=CapabilityStatus.FAILED,
output=CapabilityOutput(
success=False,
error=ErrorDetail.from_exception(e)
)
)
yield response
finally:
# 记录追踪结束
await self.metrics.record_request_end(
trace_id,
"success" if not error else "error",
error
)
async def batch_execute(
self,
requests: List[dict],
auth_token: Optional[str] = None
) -> List[Any]:
"""
批量执行请求
优化多个请求的执行
"""
results = []
for request in requests:
async with self.handle_request(request, auth_token) as response:
results.append(response)
return results
def get_health_status(self) -> dict:
"""获取健康状态"""
return {
"status": "healthy",
"timestamp": datetime.now().isoformat(),
"metrics": self.metrics.get_metrics(),
"config": {
k: v for k, v in self._config.items()
if k != "secret"
}
}6. 错误处理与降级策略
本节核心技术价值
本节为你提供的核心价值是实现多级别的容错机制,包括能力调用失败时的降级策略、重试机制、以及系统级错误恢复。这是构建高可用系统的关键。
6.1 降级策略实现
#!/usr/bin/env python3
"""
error_handling.py - AI IDE错误处理与降级策略
核心功能:
1. 错误分类与严重程度评估
2. 多级别降级策略
3. 重试机制
4. 错误恢复
作者: HOS(安全风信子)
日期: 2026-05-24
"""
from __future__ import annotations
import asyncio
import traceback
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum, auto
from typing import (
Any, Callable, Dict, List,
Optional, Set, TypeVar, Awaitable
)
from collections import defaultdict
import logging
import random
from capability_models import (
CapabilityInput, CapabilityOutput, CapabilityResponse,
CapabilityStatus, ExecutionContext, ErrorDetail,
ErrorCategory, ErrorSeverity
)
logger = logging.getLogger(__name__)
class DegradationLevel(Enum):
"""降级级别"""
FULL = "full" # 完整功能
GRACEFUL = "graceful" # 优雅降级(部分功能)
MINIMAL = "minimal" # 最小功能
DISABLED = "disabled" # 完全禁用
@dataclass
class FallbackStrategy:
"""降级策略定义"""
level: DegradationLevel
name: str
description: str
timeout_ms: int = 5000 # 超时阈值
max_retries: int = 3 # 最大重试次数
retry_delay_ms: int = 1000 # 重试延迟
# 备用能力映射
fallback_capabilities: Dict[str, str] = field(default_factory=dict)
# 降级时的默认响应
default_response: Any = None
def get_fallback(self, capability: str) -> Optional[str]:
"""获取备用能力"""
return self.fallback_capabilities.get(capability)
@dataclass
class ErrorRecoveryAction:
"""错误恢复动作"""
action_type: str # retry, fallback, skip, abort
target_capability: Optional[str] = None
delay_ms: int = 0
max_attempts: int = 1
current_attempt: int = 0
class ErrorClassifier:
"""
错误分类器
分析错误并确定应采取的恢复策略
"""
# 错误分类规则
RECOVERABLE_PATTERNS = {
ErrorCategory.TIMEOUT: ["timeout", "timed out", "took too long"],
ErrorCategory.NOT_FOUND: ["not found", "doesn't exist", "missing"],
ErrorCategory.RESOURCE: ["memory", "cpu", "disk", "quota", "limit"],
}
TRANSIENT_PATTERNS = [
"connection",
"network",
"temporary",
"transient",
"unavailable"
]
def classify(self, error: ErrorDetail) -> ErrorSeverity:
"""
分类错误严重程度
"""
# 直接检查严重程度标记
if error.severity:
return error.severity
# 根据错误码判断
error_code = error.code.lower()
if any(term in error_code for term in ["fatal", "critical", "crash"]):
return ErrorSeverity.BLOCKING
# 根据类别判断
if error.category == ErrorCategory.TIMEOUT:
return ErrorSeverity.RECOVERABLE
elif error.category == ErrorCategory.NOT_FOUND:
return ErrorSeverity.WARNING
elif error.category == ErrorCategory.PERMISSION:
return ErrorSeverity.BLOCKING
elif error.category == ErrorCategory.RESOURCE:
return ErrorSeverity.RECOVERABLE
return ErrorSeverity.RECOVERABLE
def is_transient(self, error: ErrorDetail) -> bool:
"""
判断错误是否是瞬态的(可能自行恢复)
"""
message = error.message.lower()
# 检查是否是瞬态错误
if any(pattern in message for pattern in self.TRANSIENT_PATTERNS):
return True
# 根据类别判断
if error.category in [
ErrorCategory.TIMEOUT,
ErrorCategory.RESOURCE
]:
return True
return False
def should_retry(self, error: ErrorDetail) -> bool:
"""
判断是否应该重试
"""
# 阻塞性错误不重试
if self.classify(error) == ErrorSeverity.BLOCKING:
return False
# 瞬态错误应该重试
if self.is_transient(error):
return True
# 超时错误应该重试
if error.category == ErrorCategory.TIMEOUT:
return True
return False
class RetryPolicy:
"""
重试策略
实现指数退避等高级重试逻辑
"""
def __init__(
self,
max_attempts: int = 3,
base_delay_ms: int = 1000,
max_delay_ms: int = 30000,
exponential_base: float = 2.0,
jitter: bool = True
):
self.max_attempts = max_attempts
self.base_delay_ms = base_delay_ms
self.max_delay_ms = max_delay_ms
self.exponential_base = exponential_base
self.jitter = jitter
def calculate_delay(self, attempt: int) -> float:
"""
计算重试延迟
使用指数退避算法,可选添加随机抖动
"""
# 指数退避
delay = self.base_delay_ms * (self.exponential_base ** attempt)
# 添加抖动
if self.jitter:
delay = delay * (0.5 + random.random() * 0.5)
# 限制最大延迟
return min(delay / 1000, self.max_delay_ms / 1000)
async def execute_with_retry(
self,
operation: Callable[[], Awaitable[Any]],
error_classifier: ErrorClassifier,
context: ExecutionContext
) -> tuple[Any, Optional[ErrorDetail], int]:
"""
执行带重试的操作
Returns:
(结果, 最终错误, 尝试次数)
"""
last_error = None
for attempt in range(self.max_attempts):
try:
result = await operation()
return result, None, attempt + 1
except Exception as e:
last_error = ErrorDetail.from_exception(e)
logger.warning(
f"Attempt {attempt + 1}/{self.max_attempts} failed: {last_error.message}"
)
# 判断是否应该继续重试
if attempt + 1 < self.max_attempts:
if error_classifier.should_retry(last_error):
delay = self.calculate_delay(attempt)
await asyncio.sleep(delay)
continue
break
return None, last_error, self.max_attempts
class DegradationManager:
"""
降级管理器
管理能力层的降级状态和策略
"""
def __init__(self):
# 能力降级状态
self._capability_states: Dict[str, DegradationLevel] = defaultdict(
lambda: DegradationLevel.FULL
)
# 降级策略
self._strategies: Dict[DegradationLevel, FallbackStrategy] = {}
self._default_strategy = self._create_default_strategy()
# 健康状态
self._health_scores: Dict[str, float] = defaultdict(lambda: 1.0)
# 初始化默认策略
self._init_default_strategies()
def _create_default_strategy(self) -> FallbackStrategy:
"""创建默认降级策略"""
return FallbackStrategy(
level=DegradationLevel.FULL,
name="default",
description="Default fallback strategy"
)
def _init_default_strategies(self):
"""初始化默认降级策略"""
# 搜索能力降级
self._strategies["search"] = FallbackStrategy(
level=DegradationLevel.GRACEFUL,
name="search_fallback",
description="Fallback to simple text search",
fallback_capabilities={
"semantic_search": "text_search",
"code_search": "grep_search"
},
default_response={"results": [], "degraded": True}
)
# 重构能力降级
self._strategies["refactor"] = FallbackStrategy(
level=DegradationLevel.MINIMAL,
name="refactor_fallback",
description="Only allow safe refactorings",
max_retries=1,
fallback_capabilities={
"deep_refactor": "safe_refactor"
}
)
# 审查能力降级
self._strategies["review"] = FallbackStrategy(
level=DegradationLevel.GRACEFUL,
name="review_fallback",
description="Basic style checking only",
default_response={
"issues": [],
"warnings": ["Review capability in degraded mode"]
}
)
def get_degradation_level(self, capability: str) -> DegradationLevel:
"""获取能力的降级级别"""
return self._capability_states.get(capability, DegradationLevel.FULL)
def set_degradation_level(
self,
capability: str,
level: DegradationLevel
) -> None:
"""设置能力的降级级别"""
old_level = self._capability_states.get(capability, DegradationLevel.FULL)
self._capability_states[capability] = level
logger.info(
f"Capability '{capability}' degradation changed: "
f"{old_level.value} -> {level.value}"
)
def get_fallback_capability(
self,
capability: str
) -> Optional[str]:
"""获取备用能力"""
level = self.get_degradation_level(capability)
if level == DegradationLevel.FULL:
return None
# 查找对应的降级策略
strategy = self._strategies.get(capability, self._default_strategy)
return strategy.get_fallback(capability)
def get_default_response(
self,
capability: str
) -> Optional[Any]:
"""获取降级时的默认响应"""
strategy = self._strategies.get(capability, self._default_strategy)
return strategy.default_response
class ErrorRecoveryManager:
"""
错误恢复管理器
协调所有错误处理组件
"""
def __init__(self):
self.classifier = ErrorClassifier()
self.retry_policy = RetryPolicy()
self.degradation_manager = DegradationManager()
# 错误历史
self._error_history: List[ErrorDetail] = []
self._max_history_size = 1000
async def handle_error(
self,
error: ErrorDetail,
context: ExecutionContext,
operation: Callable[[], Awaitable[Any]]
) -> ErrorRecoveryAction:
"""
处理错误,决定恢复动作
"""
# 分析错误
severity = self.classifier.classify(error)
should_retry = self.classifier.should_retry(error)
# 确定恢复动作
if severity == ErrorSeverity.BLOCKING:
# 阻塞性错误,不重试
return ErrorRecoveryAction(
action_type="abort",
max_attempts=0
)
if should_retry:
# 尝试重试
result, final_error, attempts = await self.retry_policy.execute_with_retry(
operation,
self.classifier,
context
)
if final_error is None:
return ErrorRecoveryAction(
action_type="retry_success",
max_attempts=attempts
)
# 重试后仍失败
error = final_error
# 考虑降级
level = self.degradation_manager.get_degradation_level(
context.get_variable("current_capability", "")
)
if level != DegradationLevel.FULL:
return ErrorRecoveryAction(
action_type="fallback",
target_capability=self.degradation_manager.get_fallback_capability(
context.get_variable("current_capability", "")
)
)
# 记录并放弃
self._record_error(error)
return ErrorRecoveryAction(
action_type="abort",
max_attempts=self.retry_policy.max_attempts
)
def _record_error(self, error: ErrorDetail):
"""记录错误到历史"""
self._error_history.append(error)
if len(self._error_history) > self._max_history_size:
self._error_history = self._error_history[-self._max_history_size:]
def get_error_summary(self) -> dict:
"""获取错误摘要"""
if not self._error_history:
return {"total": 0, "by_category": {}}
by_category: Dict[str, int] = defaultdict(int)
for error in self._error_history:
by_category[error.category.value] += 1
return {
"total": len(self._error_history),
"by_category": dict(by_category),
"recent": [
{"code": e.code, "message": e.message, "category": e.category.value}
for e in self._error_history[-10:]
]
}7. 性能优化:缓存与并行化
本节核心技术价值
本节为你提供的核心价值是实现高效的性能优化策略,包括多级缓存机制、并行执行优化、以及资源管理。这是提升系统吞吐量的关键。
7.1 性能优化实现
#!/usr/bin/env python3
"""
performance_optimizer.py - AI IDE性能优化器
核心功能:
1. 多级缓存管理
2. 并行执行优化
3. 资源池管理
4. 性能监控
作者: HOS(安全风信子)
日期: 2026-05-24
"""
from __future__ import annotations
import asyncio
import hashlib
import time
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum, auto
from typing import (
Any, Awaitable, Callable, Dict,
List, Optional, Set, Tuple, TypeVar
)
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor
import logging
import threading
logger = logging.getLogger(__name__)
T = TypeVar('T')
# ============== 缓存实现 ==============
class CacheEntry:
"""缓存条目"""
__slots__ = ('key', 'value', 'created_at', 'accessed_at',
'access_count', 'size', 'tags', 'cost')
def __init__(
self,
key: str,
value: Any,
size: int = 0,
cost: float = 0.0,
tags: Set[str] = None
):
self.key = key
self.value = value
self.created_at = time.monotonic()
self.accessed_at = self.created_at
self.access_count = 0
self.size = size
self.tags = tags or set()
self.cost = cost
class MultiLevelCache:
"""
多级缓存
实现L1(内存) -> L2(进程) -> L3(分布式)的缓存层次
"""
def __init__(
self,
l1_size: int = 1000,
l2_size: int = 10000,
l1_ttl: int = 300,
l2_ttl: int = 3600
):
# L1: 内存缓存
self.l1: Dict[str, CacheEntry] = {}
self.l1_size = l1_size
self.l1_ttl = l1_ttl
# L2: 进程缓存
self.l2: Dict[str, CacheEntry] = {}
self.l2_size = l2_size
self.l2_ttl = l2_ttl
# 统计
self._stats = {
'l1_hits': 0, 'l1_misses': 0,
'l2_hits': 0, 'l2_misses': 0,
'total_hits': 0
}
# 锁
self._lock = asyncio.Lock()
# 后台清理任务
self._cleanup_task: Optional[asyncio.Task] = None
async def start_cleanup(self):
"""启动后台清理任务"""
if self._cleanup_task is None:
self._cleanup_task = asyncio.create_task(self._cleanup_loop())
async def stop_cleanup(self):
"""停止后台清理"""
if self._cleanup_task:
self._cleanup_task.cancel()
try:
await self._cleanup_task
except asyncio.CancelledError:
pass
async def _cleanup_loop(self):
"""定期清理过期缓存"""
while True:
try:
await asyncio.sleep(60) # 每分钟清理
await self._cleanup_expired()
except asyncio.CancelledError:
break
except Exception as e:
logger.error(f"Cache cleanup error: {e}")
async def _cleanup_expired(self):
"""清理过期条目"""
async with self._lock:
now = time.monotonic()
# 清理L1
expired_l1 = [
k for k, v in self.l1.items()
if now - v.created_at > self.l1_ttl
]
for k in expired_l1:
del self.l1[k]
# 清理L2
expired_l2 = [
k for k, v in self.l2.items()
if now - v.created_at > self.l2_ttl
]
for k in expired_l2:
del self.l2[k]
async def get(self, key: str) -> Tuple[Optional[Any], str]:
"""
获取缓存
Returns:
(值, 缓存级别)
"""
async with self._lock:
# L1查找
if key in self.l1:
entry = self.l1[key]
if time.monotonic() - entry.created_at <= self.l1_ttl:
entry.accessed_at = time.monotonic()
entry.access_count += 1
self._stats['l1_hits'] += 1
self._stats['total_hits'] += 1
return entry.value, "L1"
else:
del self.l1[key]
self._stats['l1_misses'] += 1
# L2查找
if key in self.l2:
entry = self.l2[key]
if time.monotonic() - entry.created_at <= self.l2_ttl:
entry.accessed_at = time.monotonic()
entry.access_count += 1
self._stats['l2_hits'] += 1
self._stats['total_hits'] += 1
# 提升到L1
await self._promote_to_l1(key, entry)
return entry.value, "L2"
else:
del self.l2[key]
self._stats['l2_misses'] += 1
return None, "MISS"
async def _promote_to_l1(self, key: str, entry: CacheEntry):
"""将条目提升到L1"""
if len(self.l1) >= self.l1_size:
# L1满了,驱逐最少使用的
lru_key = min(
self.l1.keys(),
key=lambda k: self.l1[k].accessed_at
)
del self.l1[lru_key]
self.l1[key] = entry
async def set(
self,
key: str,
value: Any,
size: int = 0,
cost: float = 0.0,
tags: Set[str] = None
):
"""设置缓存"""
async with self._lock:
entry = CacheEntry(key, value, size, cost, tags)
# 同时设置L1和L2
if len(self.l1) < self.l1_size:
self.l1[key] = entry
if len(self.l2) < self.l2_size:
self.l2[key] = entry
async def invalidate(self, key: str):
"""使缓存失效"""
async with self._lock:
self.l1.pop(key, None)
self.l2.pop(key, None)
async def invalidate_by_tag(self, tag: str):
"""按标签使缓存失效"""
async with self._lock:
# L1
keys_to_remove = [
k for k, v in self.l1.items()
if tag in v.tags
]
for k in keys_to_remove:
del self.l1[k]
# L2
keys_to_remove = [
k for k, v in self.l2.items()
if tag in v.tags
]
for k in keys_to_remove:
del self.l2[k]
def get_stats(self) -> dict:
"""获取缓存统计"""
total = self._stats['total_hits'] + self._stats['l1_misses']
hit_rate = (
self._stats['total_hits'] / total
if total > 0 else 0
)
return {
'l1_size': len(self.l1),
'l2_size': len(self.l2),
'l1_hit_rate': (
self._stats['l1_hits'] /
(self._stats['l1_hits'] + self._stats['l1_misses'])
if (self._stats['l1_hits'] + self._stats['l1_misses']) > 0
else 0
),
'l2_hit_rate': (
self._stats['l2_hits'] /
(self._stats['l2_hits'] + self._stats['l2_misses'])
if (self._stats['l2_hits'] + self._stats['l2_misses']) > 0
else 0
),
'overall_hit_rate': hit_rate,
'total_hits': self._stats['total_hits'],
'total_misses': self._stats['l1_misses']
}
# ============== 并行执行优化 ==============
class ParallelExecutor:
"""
并行执行器
优化多个任务的并行执行
"""
def __init__(
self,
max_workers: int = 10,
max_semaphore: int = 20
):
self.max_workers = max_workers
self.max_semaphore = max_semaphore
# 信号量控制并发
self._semaphore: Optional[asyncio.Semaphore] = None
# 线程池(用于CPU密集型任务)
self._thread_pool: Optional[ThreadPoolExecutor] = None
# 任务跟踪
self._running_tasks: Set[asyncio.Task] = set()
self._completed_count = 0
self._failed_count = 0
def _get_semaphore(self) -> asyncio.Semaphore:
if self._semaphore is None:
self._semaphore = asyncio.Semaphore(self.max_semaphore)
return self._semaphore
def _get_thread_pool(self) -> ThreadPoolExecutor:
if self._thread_pool is None:
self._thread_pool = ThreadPoolExecutor(
max_workers=self.max_workers,
thread_name_prefix="capability_worker"
)
return self._thread_pool
async def execute_batch(
self,
tasks: List[Callable[[], Awaitable[T]]],
return_exceptions: bool = True
) -> List[T]:
"""
批量并行执行任务
Args:
tasks: 任务函数列表
return_exceptions: 是否返回异常而非抛出
Returns:
结果列表
"""
semaphore = self._get_semaphore()
async def execute_with_limit(task: Callable[[], Awaitable[T]]) -> T:
async with semaphore:
try:
result = await task()
self._completed_count += 1
return result
except Exception as e:
self._failed_count += 1
if return_exceptions:
return e
raise
# 创建所有任务
task_objects = [
asyncio.create_task(execute_with_limit(task))
for task in tasks
]
# 并行执行
results = await asyncio.gather(*task_objects, return_exceptions=True)
return list(results)
def shutdown(self):
"""关闭执行器"""
if self._thread_pool:
self._thread_pool.shutdown(wait=True)
self._thread_pool = None
# ============== 性能监控 ==============
class PerformanceMonitor:
"""
性能监控器
实时监控系统性能指标
"""
def __init__(self):
# 指标收集
self._latencies: Dict[str, List[float]] = defaultdict(list)
self._throughput: Dict[str, List[float]] = defaultdict(list)
self._errors: Dict[str, int] = defaultdict(int)
# 窗口配置
self._window_size = 60 # 60秒窗口
self._max_samples = 1000
# 锁
self._lock = asyncio.Lock()
# 采样任务
self._monitor_task: Optional[asyncio.Task] = None
async def start(self):
"""启动监控"""
self._monitor_task = asyncio.create_task(self._monitor_loop())
async def stop(self):
"""停止监控"""
if self._monitor_task:
self._monitor_task.cancel()
try:
await self._monitor_task
except asyncio.CancelledError:
pass
async def _monitor_loop(self):
"""监控循环"""
while True:
try:
await asyncio.sleep(10) # 每10秒采集一次
except asyncio.CancelledError:
break
except Exception as e:
logger.error(f"Monitor error: {e}")
async def record_latency(
self,
operation: str,
latency_ms: float
):
"""记录延迟"""
async with self._lock:
if operation not in self._latencies:
self._latencies[operation] = []
self._latencies[operation].append(latency_ms)
# 限制样本数
if len(self._latencies[operation]) > self._max_samples:
self._latencies[operation] = self._latencies[operation][-self._max_samples:]
async def record_error(self, operation: str):
"""记录错误"""
async with self._lock:
self._errors[operation] += 1
def get_stats(self) -> dict:
"""获取性能统计"""
stats = {}
for op, latencies in self._latencies.items():
if latencies:
sorted_latencies = sorted(latencies)
stats[op] = {
'count': len(latencies),
'avg_ms': sum(latencies) / len(latencies),
'p50_ms': sorted_latencies[len(sorted_latencies) // 2],
'p95_ms': sorted_latencies[int(len(sorted_latencies) * 0.95)],
'p99_ms': sorted_latencies[int(len(sorted_latencies) * 0.99)],
'min_ms': min(latencies),
'max_ms': max(latencies),
'errors': self._errors.get(op, 0)
}
return stats8. 完整集成示例
本节核心技术价值
本节为你提供的核心价值是展示完整的能力层集成,包括如何将所有组件组装成一个可运行的系统,以及如何在实际项目中使用。
8.1 完整能力层实现
#!/usr/bin/env python3
"""
ai_ide_capability_layer.py - AI IDE能力层完整实现
整合所有组件,构建完整的AI IDE能力层系统。
功能:
1. 统一入口
2. 能力编排
3. 上下文管理
4. 错误处理
5. 性能优化
作者: HOS(安全风信子)
日期: 2026-05-24
"""
import asyncio
import logging
from datetime import datetime
from typing import Any, Dict, List, Optional
from capability_models import (
Capability, CapabilityInput, CapabilityOutput,
CapabilityRegistry, ExecutionContext, CapabilityPriority,
ErrorDetail, ErrorCategory, ErrorSeverity, CapabilityStatus,
CapabilityResponse
)
from capability_orchestrator import (
CapabilityOrchestrator, TaskDecomposer, ExecutionScheduler,
ResultAggregator, Task
)
from context_manager import ContextManager, ContextScope
from capability_gateway import CapabilityGateway, AuthProvider, RateLimiter
from error_handling import (
ErrorRecoveryManager, ErrorClassifier, DegradationManager,
RetryPolicy, DegradationLevel
)
from performance_optimizer import (
MultiLevelCache, ParallelExecutor, PerformanceMonitor
)
# 日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# ============== 能力实现示例 ==============
class FileReadCapability(Capability):
"""文件读取能力"""
@property
def metadata(self):
from capability_models import CapabilityMetadata
return CapabilityMetadata(
name="file_read",
version="1.0.0",
description="读取文件内容",
category="file",
tags=["file", "read", "io"]
)
async def execute(
self,
context: ExecutionContext,
input_data: CapabilityInput
) -> CapabilityOutput:
file_path = getattr(input_data, 'path', None)
if not file_path:
return CapabilityOutput(
success=False,
error=ErrorDetail(
code="INVALID_INPUT",
message="File path is required",
category=ErrorCategory.VALIDATION,
severity=ErrorSeverity.BLOCKING
)
)
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
return CapabilityOutput(
success=True,
data={
"path": file_path,
"content": content,
"lines": len(content.splitlines()),
"size": len(content)
}
)
except FileNotFoundError:
return CapabilityOutput(
success=False,
error=ErrorDetail(
code="FILE_NOT_FOUND",
message=f"File not found: {file_path}",
category=ErrorCategory.NOT_FOUND,
severity=ErrorSeverity.WARNING
)
)
except Exception as e:
return CapabilityOutput(
success=False,
error=ErrorDetail.from_exception(e)
)
class FileWriteCapability(Capability):
"""文件写入能力"""
@property
def metadata(self):
from capability_models import CapabilityMetadata
return CapabilityMetadata(
name="file_write",
version="1.0.0",
description="写入文件内容",
category="file",
tags=["file", "write", "io"]
)
async def execute(
self,
context: ExecutionContext,
input_data: CapabilityInput
) -> CapabilityOutput:
file_path = getattr(input_data, 'path', None)
content = getattr(input_data, 'content', None)
if not file_path or content is None:
return CapabilityOutput(
success=False,
error=ErrorDetail(
code="INVALID_INPUT",
message="File path and content are required",
category=ErrorCategory.VALIDATION,
severity=ErrorSeverity.BLOCKING
)
)
try:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return CapabilityOutput(
success=True,
data={
"path": file_path,
"bytes_written": len(content.encode())
}
)
except Exception as e:
return CapabilityOutput(
success=False,
error=ErrorDetail.from_exception(e)
)
class CodeSearchCapability(Capability):
"""代码搜索能力"""
@property
def metadata(self):
from capability_models import CapabilityMetadata
return CapabilityMetadata(
name="code_search",
version="1.0.0",
description="在代码库中搜索",
category="search",
tags=["search", "code", "find"]
)
async def execute(
self,
context: ExecutionContext,
input_data: CapabilityInput
) -> CapabilityOutput:
query = getattr(input_data, 'query', '')
if not query:
return CapabilityOutput(
success=False,
error=ErrorDetail(
code="INVALID_INPUT",
message="Search query is required",
category=ErrorCategory.VALIDATION,
severity=ErrorSeverity.WARNING
)
)
# 简化实现:实际应该使用语义搜索
results = []
# 如果有Repository Graph,使用它
if context.repository_graph:
symbols = context.repository_graph.find_symbol(query)
for symbol in symbols[:10]:
results.append({
"name": symbol.name,
"kind": symbol.kind,
"qualified_name": symbol.qualified_name if hasattr(symbol, 'qualified_name') else symbol.name
})
return CapabilityOutput(
success=True,
data={
"query": query,
"results": results,
"count": len(results)
}
)
# ============== AI IDE能力层主类 ==============
class AIDECapabilityLayer:
"""
AI IDE能力层主类
整合所有组件,提供完整的AI IDE能力层
"""
def __init__(self, project_path: str = None):
# 项目路径
self.project_path = project_path
# 核心组件
self.registry = CapabilityRegistry()
self.context_manager = ContextManager()
self.orchestrator = CapabilityOrchestrator(self.registry)
self.gateway = CapabilityGateway(self.registry)
self.error_manager = ErrorRecoveryManager()
self.performance_monitor = PerformanceMonitor()
# 缓存
self.cache = MultiLevelCache()
# 并行执行器
self.executor = ParallelExecutor(max_workers=10)
# 初始化
self._initialized = False
async def initialize(self):
"""初始化能力层"""
if self._initialized:
return
logger.info("Initializing AI IDE Capability Layer...")
# 注册能力
self._register_capabilities()
# 设置编排器引用
self.gateway.set_orchestrator(self.orchestrator)
# 初始化缓存
await self.cache.start_cleanup()
# 启动性能监控
await self.performance_monitor.start()
self._initialized = True
logger.info("AI IDE Capability Layer initialized successfully")
def _register_capabilities(self):
"""注册所有能力"""
capabilities = [
FileReadCapability(),
FileWriteCapability(),
CodeSearchCapability(),
]
for cap in capabilities:
self.registry.register(cap.__class__, lambda c=cap: c)
logger.info(f"Registered capability: {cap.metadata.name}")
async def shutdown(self):
"""关闭能力层"""
logger.info("Shutting down AI IDE Capability Layer...")
await self.cache.stop_cleanup()
await self.performance_monitor.stop()
self.executor.shutdown()
self._initialized = False
logger.info("AI IDE Capability Layer shutdown complete")
# ============== 能力调用接口 ==============
async def read_file(self, path: str) -> Dict[str, Any]:
"""读取文件"""
class ReadInput(CapabilityInput):
def __init__(self, path):
self.path = path
context = self._create_context()
result = await self.orchestrator.execute_capability(
"file_read",
ReadInput(path),
context
)
if result.output:
return result.output.to_dict()
return {"success": False, "error": "Unknown error"}
async def write_file(self, path: str, content: str) -> Dict[str, Any]:
"""写入文件"""
class WriteInput(CapabilityInput):
def __init__(self, path, content):
self.path = path
self.content = content
context = self._create_context()
result = await self.orchestrator.execute_capability(
"file_write",
WriteInput(path, content),
context
)
if result.output:
return result.output.to_dict()
return {"success": False, "error": "Unknown error"}
async def search_code(self, query: str) -> Dict[str, Any]:
"""搜索代码"""
class SearchInput(CapabilityInput):
def __init__(self, query):
self.query = query
context = self._create_context()
result = await self.orchestrator.execute_capability(
"code_search",
SearchInput(query),
context
)
if result.output:
return result.output.to_dict()
return {"success": False, "error": "Unknown error"}
def _create_context(self) -> ExecutionContext:
"""创建执行上下文"""
return ExecutionContext(
repository_graph=None,
config={}
)
# ============== 使用示例 ==============
async def main():
"""使用示例"""
print("=" * 60)
print("AI IDE 能力层演示")
print("=" * 60)
# 创建能力层
capability_layer = AIDECapabilityLayer(project_path="/path/to/project")
# 初始化
await capability_layer.initialize()
# 演示文件读取
print("\n=== 文件读取能力 ===")
result = await capability_layer.search_code("TestClass")
print(f"搜索结果: {result}")
# 演示缓存统计
print("\n=== 缓存统计 ===")
stats = capability_layer.cache.get_stats()
print(f"缓存统计: {stats}")
# 演示性能统计
print("\n=== 性能统计 ===")
perf_stats = capability_layer.performance_monitor.get_stats()
print(f"性能统计: {perf_stats}")
# 关闭
await capability_layer.shutdown()
print("\n演示完成!")
if __name__ == "__main__":
asyncio.run(main())9. 总结与展望
9.1 核心架构总结
本文构建了一个完整的AI IDE能力层架构,包含以下核心组件:
组件 | 职责 | 关键特性 |
|---|---|---|
能力接口(Capability) | 定义Agent的统一抽象 | 元数据、输入输出标准化、生命周期钩子 |
编排器(Orchestrator) | 任务分解与调度 | 拓扑排序、并行执行、结果聚合 |
上下文管理器 | Repository Graph共享 | 多级缓存、作用域隔离、增量更新 |
能力网关 | 统一入口 | 认证授权、速率限制、监控追踪 |
错误处理 | 容错机制 | 多级降级、重试策略、错误分类 |
性能优化 | 性能提升 | 多级缓存、并行执行、资源池 |
9.2 关键技术亮点
- 统一接口设计:通过Capability抽象,隐藏底层Agent差异,提供一致的调用体验
- 智能编排:基于拓扑排序的分层执行,支持并行与依赖控制
- 上下文复用:通过Repository Graph实现多Agent间的高效上下文共享,降低延迟
- 容错机制:多级别降级策略,确保系统在部分能力失效时仍能提供服务
- 性能优化:多级缓存+并行执行,显著提升系统吞吐量
9.3 未来扩展方向
方向 | 描述 | 技术挑战 |
|---|---|---|
分布式能力层 | 支持跨进程、跨机器的能力调用 | 一致性、性能开销 |
能力发现 | 基于自然语言的自动能力匹配 | 意图识别、相似度计算 |
能力组合 | 自动组合多个能力完成复杂任务 | 任务规划、状态管理 |
能力市场 | 第三方能力注册与分发 | 安全沙箱、版本管理 |
参考链接:
- 主要来源:LangChain Agents Documentation - Agent架构设计参考
- 主要来源:Microsoft AutoDev - AI驱动开发框架
- 主要来源:GitHub Copilot Architecture - Copilot后端架构分析
- 辅助来源:SWE-agent - 软件工程Agent研究
附录(Appendix):
- 附录A:能力层完整代码(约8500行)
- 附录B:能力注册表使用示例
- 附录C:性能基准测试结果
关键词: AI IDE, 能力层, Agent编排, 上下文管理, Repository Graph, 降级策略, 性能优化, 多级缓存, 并行执行, 错误处理, 能力网关, 软件工程, 开发者工具, 人工智能, 系统架构

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号