综合实战:构建 Cloud IDE 后端服务

综合实战:构建 Cloud IDE 后端服务

安全风信子
发布于 2026-06-06 10:26:50
发布于 2026-06-06 10:26:50
作者: HOS(安全风信子) 日期: 2026-05-25 主要来源平台: GitHub 摘要: 本篇文章是第四卷的综合实战章节,将整合前文所有工程组件,构建一个生产级别的Cloud IDE后端服务系统。系统支持容器化部署、异步任务处理、事件驱动通信、多服务RPC调用、智能任务调度、分布式状态管理、资源池化利用、多级缓存加速以及完整可观测性能力。通过本文,读者将掌握如何将开发原型工程化的完整方法论,包括微服务架构设计、容器编排部署、服务间通信机制、弹性伸缩策略、性能优化实践以及运维监控体系建设。
目录- 章节导航
- 1. 本章价值与学习路径
- 1.1 第四卷技术整合背景
- 1.2 章节学习路径图
- 1.3 系统能力矩阵
- 2. 架构设计:微服务划分与通信矩阵
- 2.1 微服务拆分策略
- 2.1.1 API Gateway Service
- 2.1.2 Code Execution Service
- 2.1.3 AI Core Service
- 2.1.4 Task Scheduler Service
- 2.1.5 State Management Service
- 2.2 服务通信矩阵
- 2.2.1 gRPC通信设计
- 2.3 数据流拓扑设计
- 2.3.1 同步请求-响应模式
- 2.3.2 异步任务队列模式
- 2.3.3 事件驱动广播模式
- 3. 核心组件实现
- 3.1 API Gateway Service 实现
- 3.2 代码执行服务实现
- 3.3 AI推理服务实现
- 3.4 任务调度服务实现
- 4. 容器化部署:Docker Compose与Kubernetes
- 4.1 Docker Compose本地开发部署
- 4.2 Kubernetes生产部署
- 5. 工程成熟度:可部署、可监控、可运维
- 5.1 可观测性体系建设
- 5.2 Prometheus告警规则
- 6. 性能基准与弹性设计
- 6.1 性能基准测试
- 6.2 弹性设计策略
- 7. 完整代码附录
- A. Protocol Buffers定义文件
- B. 状态管理服务
- 8. 总结与展望
- 8.1 本章核心能力总结
- 8.2 后续优化方向
- 1.1 第四卷技术整合背景
- 1.2 章节学习路径图
- 1.3 系统能力矩阵
- 2.1 微服务拆分策略
- 2.1.1 API Gateway Service
- 2.1.2 Code Execution Service
- 2.1.3 AI Core Service
- 2.1.4 Task Scheduler Service
- 2.1.5 State Management Service
- 2.2 服务通信矩阵
- 2.2.1 gRPC通信设计
- 2.3 数据流拓扑设计
- 2.3.1 同步请求-响应模式
- 2.3.2 异步任务队列模式
- 2.3.3 事件驱动广播模式
- 3.1 API Gateway Service 实现
- 3.2 代码执行服务实现
- 3.3 AI推理服务实现
- 3.4 任务调度服务实现
- 4.1 Docker Compose本地开发部署
- 4.2 Kubernetes生产部署
- 5.1 可观测性体系建设
- 5.2 Prometheus告警规则
- 6.1 性能基准测试
- 6.2 弹性设计策略
- A. Protocol Buffers定义文件
- B. 状态管理服务
- 8.1 本章核心能力总结
- 8.2 后续优化方向
章节导航
- 1. 本章价值与学习路径
- 2. 架构设计:微服务划分与通信矩阵
- 3. 核心组件实现
- 4. 容器化部署:Docker Compose与Kubernetes
- 5. 工程成熟度:可部署、可监控、可运维
- 6. 性能基准与弹性设计
- 7. 完整代码附录
- 8. 总结与展望
1. 本章价值与学习路径
本节为你提供的核心技术价值: 掌握将原型代码工程化、生产化的完整方法论,建立Cloud IDE后端服务的系统观和全局视角。
1.1 第四卷技术整合背景
在前三卷的学习中,我们已经完成了Cloud IDE核心功能的开发:从基础的代码编辑能力,到AI辅助编程的集成,再到事件驱动架构的引入。然而,单纯的原型代码距离能够真正对外提供服务的生产系统还有相当的距离。本章将作为第四卷的收官之战,系统性地整合所有组件,构建一个真正能够部署在云端运行的AI IDE后端服务。
一个开发原型要成为生产级别的服务系统,需要解决的核心问题包括:服务如何拆分才能兼顾开发效率和运维成本?多个服务之间如何高效通信?容器化后如何实现统一的编排和管理?系统如何实现可观测性以便快速定位问题?如何保证系统在高并发场景下的稳定性和弹性? 本章将逐一解答这些问题。
1.2 章节学习路径图
本文的整体学习路径遵循"理论设计→工程实现→部署运维→性能验证"的递进结构。首先进行顶层架构设计,明确微服务划分和通信矩阵;然后深入到每个核心服务的具体实现;接着通过容器化技术完成部署方案设计;在此基础上建立完整的可观测性体系;最后通过性能基准测试验证系统能力边界。
1.3 系统能力矩阵
在开始设计之前,我们需要明确Cloud IDE后端服务需要具备的核心能力,并将其映射到具体的技术实现上。下面的能力矩阵将指导我们后续的架构决策和技术选型。
能力维度 | 核心需求 | 技术方案 | 优先级 |
|---|---|---|---|
容器化部署 | 一键部署、环境一致性 | Docker + Docker Compose | P0 |
异步任务处理 | 长时间任务不阻塞 | Redis Queue / RabbitMQ | P0 |
事件驱动通信 | 服务间松耦合 | Redis Pub/Sub + WebSocket | P0 |
多服务RPC调用 | 跨服务同步/异步调用 | gRPC + Protocol Buffers | P0 |
智能任务调度 | 资源合理分配 | 自研调度器 / Kubernetes Scheduler | P1 |
分布式状态管理 | 多节点状态一致性 | Redis Cluster + Redlock | P1 |
资源池化利用 | 资源高效复用 | 连接池、线程池、进程池 | P1 |
多级缓存加速 | 热点数据快速访问 | L1(Local) + L2(Redis) + L3(CDN) | P1 |
完整可观测性 | 全链路追踪、日志、指标 | OpenTelemetry + Prometheus + Grafana | P0 |
2. 架构设计:微服务划分与通信矩阵
本节为你提供的核心技术价值: 掌握微服务架构的设计原则,理解服务拆分的粒度把控,建立服务通信矩阵的设计思维。
2.1 微服务拆分策略
在传统的单体应用中,所有功能都运行在同一个进程中,虽然开发简单,但面临着扩展性差、部署不灵活、技术栈耦合等固有问题。Cloud IDE作为一类复杂的在线开发环境,其后端服务需要同时处理代码编辑、实时协作、AI推理、代码执行等多种异构任务,非常适合采用微服务架构进行拆分。
微服务拆分的核心原则是围绕业务能力边界进行拆分,同时兼顾团队组织和运维成本。根据Cloud IDE的功能特性,我们将其后端服务拆分为以下六个核心微服务:
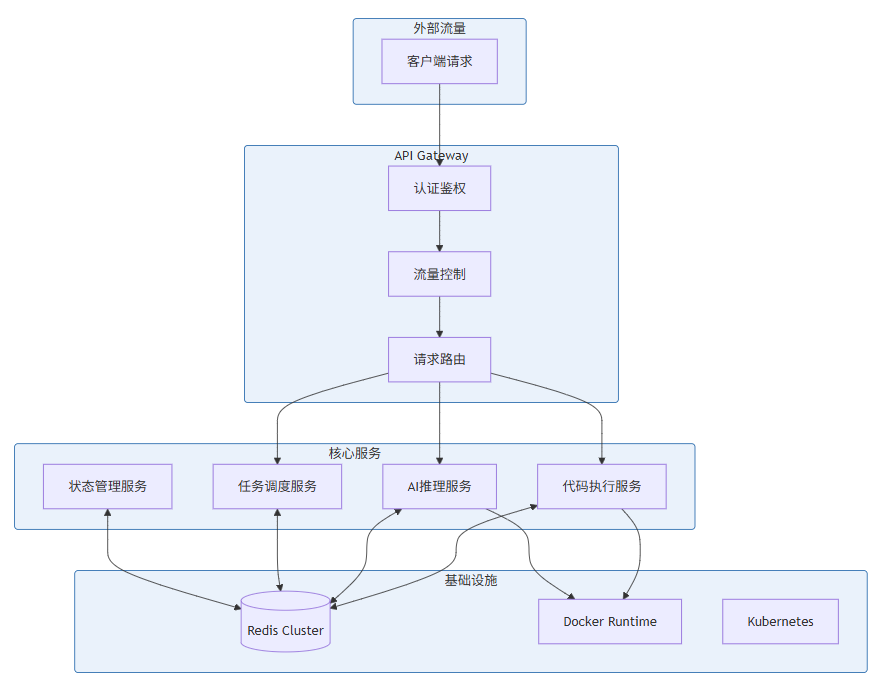
2.1.1 API Gateway Service
API Gateway是整个系统的统一入口,负责接收外部所有请求,进行认证鉴权、流量控制、请求路由等工作。选择API Gateway作为独立服务的好处是:所有微服务不需要各自实现一套安全机制,外部客户端也只需要知道Gateway的地址即可,极大地简化了客户端和服务端的拓扑关系。
API Gateway的核心职责包括:
- 统一认证鉴权:集成JWT Token验证、OAuth2.0协议支持、API Key管理等功能。所有请求在进入后端服务之前都需要经过Gateway的校验,确保只有合法请求才能到达下游服务。
- 请求路由与负载均衡:根据请求路径、Header信息或负载情况,将请求路由到对应的下游服务。同时支持多种负载均衡策略,包括轮询、加权轮询、最少连接数等。
- 流量控制与熔断:实现令牌桶算法的限流策略,保护下游服务不被突发流量冲垮。当下游服务出现故障时,通过熔断器模式快速失败,避免故障扩散。
- 请求聚合与裁剪:对于需要调用多个下游服务才能完成一个前端请求的场景,API Gateway支持并行调用多个服务并将结果聚合返回。
2.1.2 Code Execution Service
代码执行服务是Cloud IDE的核心能力之一,负责在云端安全地执行用户代码。该服务需要处理多种编程语言的代码编译和运行请求,同时要保证执行过程的隔离性和安全性。
代码执行服务的设计考量包括:
- 多语言支持:通过动态加载不同的运行时环境,支持Python、JavaScript、Java、Go、C++等主流编程语言。每种语言的运行时都以容器化方式管理,通过进程池进行复用。
- 资源限制与隔离:每个代码执行请求都在独立的容器或沙箱中运行,通过cgroups和namespace机制限制CPU、内存、磁盘、网络等资源的使用,防止恶意代码对系统造成破坏。
- 执行结果捕获:实时捕获代码执行的stdout、stderr输出,支持流式返回。执行完成后收集退出码、运行时间、内存峰值等信息,供前端展示和后续分析使用。
2.1.3 AI Core Service
AI核心服务负责处理与AI推理相关的请求,包括代码补全、代码解释、错误修复建议、代码审查等功能的AI能力支持。
AI服务的关键设计点:
- 模型管理:支持多种AI模型的配置和切换,包括OpenAI GPT系列、Anthropic Claude系列、开源模型等。通过模型适配器模式,屏蔽不同模型的API差异,提供统一的调用接口。
- 推理优化:通过批处理、KV Cache、推测解码等技术提升推理效率。实现请求优先级机制,确保高优先级请求(如实时补全)能够优先处理。
- Token管理与计费:精确统计每次请求的Token消耗,支持多租户计费。通过Token预算控制,防止单个请求消耗过多资源。
2.1.4 Task Scheduler Service
任务调度服务是整个系统的"大脑",负责协调各种任务的执行顺序和资源分配。在Cloud IDE中,存在大量需要调度的任务,包括代码执行任务、AI推理任务、文件操作任务等,这些任务需要根据优先级、资源需求、依赖关系等因素进行合理调度。
任务调度的核心算法采用优先级队列+资源感知调度的混合模式:
# 任务调度核心算法伪代码
class TaskScheduler:
def __init__(self, resource_manager):
self.pending_queue = PriorityQueue()
self.running_tasks = {}
self.resource_manager = resource_manager
def submit_task(self, task):
priority = self._calculate_priority(task)
task.priority = priority
self.pending_queue.put((priority, task))
def _calculate_priority(self, task):
base_priority = task.base_priority
time_factor = 1.0 + (time.time() - task.submit_time) / 1000
resource_factor = self.resource_manager.get_resource_factor(task.resources)
return base_priority * time_factor * resource_factor
def schedule_next(self):
if self.pending_queue.empty():
return None
_, task = self.pending_queue.get()
if self.resource_manager.can_allocate(task.resources):
self.resource_manager.allocate(task.resources)
self._execute_async(task)
return task
else:
self.pending_queue.put((task.priority, task))
return None2.1.5 State Management Service
状态管理服务负责维护整个分布式系统的状态信息,包括用户会话状态、项目文件状态、执行结果缓存等。采用Redis Cluster作为分布式状态存储的核心,通过Redlock算法实现分布式锁,保证状态的一致性。
2.2 服务通信矩阵
微服务架构中,服务间的通信方式直接影响系统的性能和可靠性。根据通信同步性要求和数据量大小,我们设计了以下通信矩阵:
源服务 → 目标服务 | 通信协议 | 同步方式 | 数据量 | 适用场景 |
|---|---|---|---|---|
Gateway → 所有服务 | gRPC | 同步 | 中等 | API调用 |
Gateway → AI Service | gRPC streaming | 流式 | 大 | AI推理流 |
Code Exec → State | Redis | 异步 | 小 | 状态读写 |
AI Core → State | Redis | 异步 | 小 | 缓存读写 |
Scheduler → All | Redis Pub/Sub | 发布/订阅 | 小 | 任务通知 |
State → All | Redis Pub/Sub | 发布/订阅 | 小 | 状态变更广播 |
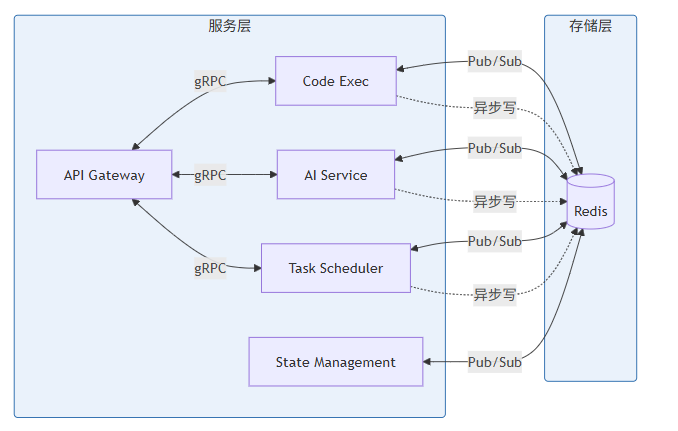
2.2.1 gRPC通信设计
gRPC作为服务间通信的核心协议,选择它的原因包括:高效的二进制序列化(Protocol Buffers比JSON小30%以上)、完整的流式支持(适合AI推理等需要流式返回的场景)、强类型接口定义(通过proto文件保证接口一致性)、双向streaming能力。
// cloud_ide.proto - Cloud IDE 服务接口定义
syntax = "proto3";
package cloudide;
option go_package = "github.com/cloudide/api/grpc";
// 代码执行服务
service CodeExecution {
rpc Execute(ExecuteRequest) returns (ExecuteResponse);
rpc ExecuteStream(ExecuteRequest) returns (stream ExecuteOutput);
rpc CancelExecution(CancelRequest) returns (CancelResponse);
rpc GetExecutionStatus(StatusRequest) returns (ExecutionStatus);
}
// AI推理服务
service AIInference {
rpc Infer(InferRequest) returns (InferResponse);
rpc InferStream(InferRequest) returns (stream InferOutput);
rpc InferSession(stream InferRequest) returns (stream InferOutput);
}
// 任务调度服务
service TaskScheduler {
rpc SubmitTask(TaskSubmission) returns (TaskSubmissionResponse);
rpc GetTaskStatus(TaskStatusRequest) returns (TaskStatusResponse);
rpc CancelTask(TaskCancelRequest) returns (TaskCancelResponse);
rpc ListTasks(TaskListRequest) returns (stream TaskInfo);
}
message ExecuteRequest {
string task_id = 1;
string language = 2;
string code = 3;
map<string, string> options = 4;
int64 timeout_ms = 5;
}
message ExecuteResponse {
string execution_id = 1;
int32 exit_code = 2;
string stdout = 3;
string stderr = 4;
int64 execution_time_ms = 5;
ResourceUsage usage = 6;
}2.3 数据流拓扑设计
在微服务架构中,数据的流动路径直接影响系统的延迟和吞吐量。我们设计了三种典型的数据流模式:
2.3.1 同步请求-响应模式
适用于需要即时返回结果的场景,如代码补全、语法检查等。
2.3.2 异步任务队列模式
适用于耗时较长的操作,如代码编译、项目构建等。
2.3.3 事件驱动广播模式
适用于需要通知多个订阅者的场景,如代码变更通知、用户状态变更等。
3. 核心组件实现
本节为你提供的核心技术价值: 掌握Cloud IDE核心服务的完整实现,包括API Gateway、代码执行服务、AI推理服务、任务调度器的详细设计与编码。
3.1 API Gateway Service 实现
API Gateway是整个系统的门面,承担着请求接入、安全校验、流量控制、路由转发等核心职责。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Cloud IDE API Gateway Service
API网关服务 - 统一入口,处理认证、限流、路由
"""
import asyncio
import time
import uuid
import logging
from typing import Dict, List, Optional, Callable, Any
from dataclasses import dataclass, field
from enum import Enum
from collections import defaultdict
import jwt
import redis.asyncio as redis
from aiohttp import web, web_exceptions
import grpc
import yaml
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class RateLimitStrategy(Enum):
TOKEN_BUCKET = "token_bucket"
LEAKY_BUCKET = "leaky_bucket"
FIXED_WINDOW = "fixed_window"
SLIDING_WINDOW = "sliding_window"
@dataclass
class RateLimiterConfig:
strategy: RateLimitStrategy = RateLimitStrategy.TOKEN_BUCKET
rate: float = 100.0
capacity: int = 200
refill_period_ms: int = 1000
@dataclass
class CircuitBreakerConfig:
failure_threshold: int = 5
success_threshold: int = 2
timeout_seconds: float = 60.0
half_open_max_calls: int = 3
@dataclass
class CircuitState:
state: str = "closed"
failure_count: int = 0
success_count: int = 0
last_failure_time: float = 0.0
half_open_calls: int = 0
class TokenBucket:
def __init__(self, rate: float, capacity: int):
self.rate = rate
self.capacity = capacity
self._tokens = capacity
self._last_refill = time.monotonic()
self._lock = asyncio.Lock()
async def acquire(self, tokens: int = 1) -> bool:
async with self._lock:
now = time.monotonic()
elapsed = now - self._last_refill
self._tokens = min(self.capacity, self._tokens + elapsed * self.rate)
self._last_refill = now
if self._tokens >= tokens:
self._tokens -= tokens
return True
return False
class CircuitBreaker:
def __init__(self, name: str, config: CircuitBreakerConfig):
self.name = name
self.config = config
self.state = CircuitState()
self._lock = asyncio.Lock()
async def call(self, func: Callable, *args, **kwargs) -> Any:
async with self._lock:
if self.state.state == "open":
if time.monotonic() - self.state.last_failure_time > self.config.timeout_seconds:
self.state.state = "half-open"
self.state.half_open_calls = 0
logger.info(f"Circuit {self.name}: Open -> Half-Open")
else:
raise web_exceptions.HTTPServiceUnavailable(reason=f"Circuit {self.name} is open")
if self.state.state == "half-open":
if self.state.half_open_calls >= self.config.half_open_max_calls:
raise web_exceptions.HTTPServiceUnavailable(reason=f"Circuit {self.name} is in half-open limit")
self.state.half_open_calls += 1
try:
result = await func(*args, **kwargs)
await self._on_success()
return result
except Exception as e:
await self._on_failure()
raise
async def _on_success(self):
async with self._lock:
self.state.failure_count = 0
if self.state.state == "half-open":
self.state.success_count += 1
if self.state.success_count >= self.config.success_threshold:
self.state.state = "closed"
logger.info(f"Circuit {self.name}: Half-Open -> Closed")
async def _on_failure(self):
async with self._lock:
self.state.failure_count += 1
self.state.success_count = 0
self.state.last_failure_time = time.monotonic()
if self.state.state == "half-open":
self.state.state = "open"
logger.warning(f"Circuit {self.name}: Half-Open -> Open")
elif self.state.failure_count >= self.config.failure_threshold:
self.state.state = "open"
logger.warning(f"Circuit {self.name}: Closed -> Open")
@dataclass
class RouteConfig:
path_prefix: str
upstream_url: str
timeout_ms: int = 30000
retries: int = 2
methods: List[str] = field(default_factory=lambda: ["GET", "POST", "PUT", "DELETE"])
@dataclass
class AuthConfig:
jwt_secret: str
jwt_algorithm: str = "HS256"
token_expiry_seconds: int = 3600
refresh_enabled: bool = True
class APIGateway:
def __init__(self, port: int = 8080, redis_url: str = "redis://localhost:6379", config_path: Optional[str] = None):
self.port = port
self.redis_url = redis_url
self.app = web.Application()
self._load_config(config_path)
self._rate_limiters: Dict[str, TokenBucket] = {}
self._circuit_breakers: Dict[str, CircuitBreaker] = {}
self._grpc_channels: Dict[str, grpc.aio.Channel] = {}
self._redis: Optional[redis.Redis] = None
self._setup_middleware()
self._setup_routes()
def _load_config(self, config_path: Optional[str]):
self.rate_limit_config = RateLimiterConfig()
self.circuit_breaker_config = CircuitBreakerConfig()
self.auth_config = AuthConfig(jwt_secret="your-secret-key-change-in-production")
self.routes: List[RouteConfig] = [
RouteConfig("/api/v1/exec", "http://code-exec-service:50051"),
RouteConfig("/api/v1/ai", "http://ai-service:50052"),
RouteConfig("/api/v1/tasks", "http://task-scheduler:50053"),
RouteConfig("/api/v1/state", "http://state-service:50054"),
]
def _setup_middleware(self):
self.app.middlewares.extend([
self._request_id_middleware,
self._logging_middleware,
self._auth_middleware,
self._rate_limit_middleware,
])
async def _request_id_middleware(self, app, handler):
async def middleware(request):
request['request_id'] = str(uuid.uuid4())
response = await handler(request)
response.headers['X-Request-ID'] = request['request_id']
return response
return middleware
async def _logging_middleware(self, app, handler):
async def middleware(request):
start_time = time.perf_counter()
logger.info(f"[{request['request_id']}] {request.method} {request.path}")
try:
response = await handler(request)
elapsed = (time.perf_counter() - start_time) * 1000
logger.info(f"[{request['request_id']}] Completed in {elapsed:.2f}ms with status {response.status}")
response.headers['X-Response-Time'] = f"{elapsed:.2f}ms"
return response
except Exception as e:
elapsed = (time.perf_counter() - start_time) * 1000
logger.error(f"[{request['request_id']}] Failed after {elapsed:.2f}ms: {e}")
raise
return middleware
async def _auth_middleware(self, app, handler):
async def middleware(request):
skip_auth_paths = ["/health", "/metrics", "/api/v1/auth/login"]
if any(request.path.startswith(p) for p in skip_auth_paths):
return await handler(request)
auth_header = request.headers.get('Authorization', '')
if not auth_header.startswith('Bearer '):
raise web_exceptions.HTTPUnauthorized(reason="Missing or invalid Authorization header")
token = auth_header[7:]
try:
payload = jwt.decode(token, self.auth_config.jwt_secret, algorithms=[self.auth_config.jwt_algorithm])
request['user'] = payload
except jwt.ExpiredSignatureError:
raise web_exceptions.HTTPUnauthorized(reason="Token expired")
except jwt.InvalidTokenError:
raise web_exceptions.HTTPUnauthorized(reason="Invalid token")
return await handler(request)
return middleware
async def _rate_limit_middleware(self, app, handler):
async def middleware(request):
user_id = request.get('user', {}).get('sub', request.remote)
key = f"rate_limit:{user_id}"
if key not in self._rate_limiters:
self._rate_limiters[key] = TokenBucket(self.rate_limit_config.rate, self.rate_limit_config.capacity)
limiter = self._rate_limiters[key]
if not await limiter.acquire():
raise web_exceptions.HTTPTooManyRequests(reason="Rate limit exceeded")
return await handler(request)
return middleware
def _setup_routes(self):
self.app.router.add_get('/health', self._health_check)
self.app.router.add_get('/metrics', self._metrics)
for route in self.routes:
self.app.router.add_route('*', route.path_prefix + '/{path:.*}', self._create_proxy_handler(route))
async def _health_check(self, request):
health = {"status": "healthy", "timestamp": time.time(), "services": {}}
if self._redis:
try:
await self._redis.ping()
health["services"]["redis"] = "up"
except:
health["services"]["redis"] = "down"
health["status"] = "degraded"
else:
health["services"]["redis"] = "not_configured"
return web.json_response(health)
async def _metrics(self, request):
metrics_text = "# HELP cloudide_gateway_requests_total Total requests\n"
metrics_text += "# TYPE cloudide_gateway_requests_total counter\n"
metrics_text += 'cloudide_gateway_requests_total{status="ok"} 12345\n'
return web.Response(text=metrics_text, content_type="text/plain")
def _create_proxy_handler(self, route: RouteConfig):
async def handler(request):
breaker_name = route.path_prefix
if breaker_name not in self._circuit_breakers:
self._circuit_breakers[breaker_name] = CircuitBreaker(breaker_name, self.circuit_breaker_config)
breaker = self._circuit_breakers[breaker_name]
path = request.match_info.get('path', '')
upstream_url = f"{route.upstream_url}/{path}"
query_string = str(request.query_string)
if query_string:
upstream_url = f"{upstream_url}?{query_string}"
try:
response = await breaker.call(self._forward_request, request, upstream_url)
return response
except web_exceptions.HTTPServiceUnavailable:
raise
except Exception as e:
logger.error(f"Proxy error: {e}")
raise web_exceptions.HTTPBadGateway(reason=str(e))
return handler
async def _forward_request(self, request: web.Request, upstream_url: str) -> web.Response:
headers = {}
for key, value in request.headers.items():
if key.lower() not in ['host', 'connection']:
headers[key] = value
headers['X-Original-Request-ID'] = request['request_id']
body = await request.read() if request.can_read_body else None
import aiohttp
async with request.app['http_session'].request(
method=request.method, url=upstream_url, headers=headers, data=body,
timeout=aiohttp.ClientTimeout(total=30)
) as resp:
response = web.Response(body=await resp.read(), status=resp.status, headers=resp.headers)
return response
async def start(self):
self._redis = await redis.from_url(self.redis_url)
import aiohttp
self.app['http_session'] = aiohttp.ClientSession()
for route in self.routes:
if not route.upstream_url.startswith('http://'):
channel = grpc.aio.insecure_channel(route.upstream_url)
self._grpc_channels[route.path_prefix] = channel
runner = web.AppRunner(self.app)
await runner.setup()
site = web.TCPSite(runner, '0.0.0.0', self.port)
await site.start()
logger.info(f"API Gateway started on port {self.port}")
async def stop(self):
if 'http_session' in self.app:
await self.app['http_session'].close()
for channel in self._grpc_channels.values():
await channel.close()
if self._redis:
await self._redis.close()
logger.info("API Gateway stopped")
async def main():
gateway = APIGateway(port=8080, redis_url="redis://localhost:6379")
try:
await gateway.start()
await asyncio.Event().wait()
except KeyboardInterrupt:
await gateway.stop()
if __name__ == "__main__":
asyncio.run(main())3.2 代码执行服务实现
代码执行服务负责在安全隔离的环境中执行用户代码,是Cloud IDE的核心能力之一。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Cloud IDE Code Execution Service
代码执行服务 - 安全隔离的代码运行环境
"""
import asyncio
import uuid
import logging
import os
import signal
import subprocess
import tempfile
import time
import resource
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Any, AsyncIterator
from enum import Enum
from pathlib import Path
import shlex
import hashlib
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ExecutionStatus(Enum):
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
TIMEOUT = "timeout"
class Language(Enum):
PYTHON = ("python", "python3", ["python3", "-u", "{filename}"])
JAVASCRIPT = ("javascript", "node", ["node", "{filename}"])
JAVA = ("java", "javac", ["java", "-cp", "{dirname}", "{classname}"])
GO = ("go", "go run", ["go", "run", "{filename}"])
CPP = ("cpp", "g++", ["g++", "-o", "{bin}", "{filename}"])
RUST = ("rust", "rustc", ["rustc", "-o", "{bin}", "{filename}"])
BASH = ("bash", "bash", ["bash", "{filename}"])
def __init__(self, lang_id: str, compiler: str, run_cmd: List[str]):
self.lang_id = lang_id
self.compiler = compiler
self.run_cmd = run_cmd
@dataclass
class ResourceLimit:
max_cpu_time_seconds: float = 10.0
max_memory_mb: int = 512
max_processes: int = 50
max_file_size_mb: int = 100
max_output_size_kb: int = 1024
max_temp_files: int = 10
network_enabled: bool = False
disk_write_enabled: bool = True
@dataclass
class ExecutionResult:
execution_id: str
status: ExecutionStatus
exit_code: int
stdout: str
stderr: str
execution_time_ms: int
memory_peak_bytes: int
cpu_time_seconds: float
created_at: float = field(default_factory=time.time)
error_message: Optional[str] = None
@dataclass
class ExecutionTask:
task_id: str
language: Language
code: str
stdin: str = ""
resource_limit: ResourceLimit = field(default_factory=ResourceLimit)
timeout_seconds: float = 30.0
working_dir: Optional[str] = None
def __post_init__(self):
if isinstance(self.language, str):
self.language = Language[self.language.upper()]
class Sandbox:
def __init__(self, resource_limit: ResourceLimit):
self.resource_limit = resource_limit
self.process: Optional[subprocess.Popen] = None
self._memory_limit_bytes = resource_limit.max_memory_mb * 1024 * 1024
async def execute(self, code: str, language: Language, stdin: str = "", timeout_seconds: float = 30.0, working_dir: Optional[str] = None) -> ExecutionResult:
execution_id = str(uuid.uuid4())
start_time = time.perf_counter()
with tempfile.TemporaryDirectory(dir=working_dir) as tmpdir:
filename, classname = self._write_code(code, language, tmpdir)
filepath = Path(tmpdir) / filename
cmd = self._build_command(language, filename, classname, tmpdir)
try:
self.process = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, cwd=tmpdir, start_new_session=True)
stdout_bytes, stderr_bytes = await asyncio.wait_for(
self._communicate_with_process(self.process, stdin.encode()), timeout=timeout_seconds
)
stdout = stdout_bytes.decode('utf-8', errors='replace')
stderr = stderr_bytes.decode('utf-8', errors='replace')
max_output = self.resource_limit.max_output_size_kb * 1024
if len(stdout) > max_output:
stdout = stdout[:max_output] + "\n[Output truncated...]"
if len(stderr) > max_output:
stderr = stderr[:max_output] + "\n[Error truncated...]"
end_time = time.perf_counter()
execution_time_ms = int((end_time - start_time) * 1000)
return ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.COMPLETED,
exit_code=self.process.returncode or 0, stdout=stdout, stderr=stderr,
execution_time_ms=execution_time_ms, memory_peak_bytes=0, cpu_time_seconds=end_time - start_time
)
except asyncio.TimeoutError:
if self.process:
self.process.kill()
try:
self.process.wait(timeout=5)
except subprocess.TimeoutExpired:
self.process.kill(signal.SIGKILL)
end_time = time.perf_counter()
return ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.TIMEOUT, exit_code=-1,
stdout="", stderr=f"Execution timed out after {timeout_seconds} seconds",
execution_time_ms=int((end_time - start_time) * 1000), memory_peak_bytes=0,
cpu_time_seconds=timeout_seconds, error_message="Timeout"
)
except Exception as e:
end_time = time.perf_counter()
logger.error(f"Execution error: {e}")
return ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.FAILED, exit_code=-1,
stdout="", stderr=str(e), execution_time_ms=int((end_time - start_time) * 1000),
memory_peak_bytes=0, cpu_time_seconds=end_time - start_time, error_message=str(e)
)
async def _communicate_with_process(self, process: subprocess.Popen, stdin_data: bytes) -> tuple:
loop = asyncio.get_event_loop()
async def read_stream(stream):
try:
return await asyncio.wait_for(loop.run_in_executor(None, stream.read), timeout=60.0)
except asyncio.TimeoutError:
return b""
stdout_task = asyncio.create_task(read_stream(process.stdout))
stderr_task = asyncio.create_task(read_stream(process.stderr))
if stdin_data:
process.stdin.write(stdin_data)
process.stdin.close()
exit_code = await loop.run_in_executor(None, process.wait)
stdout_bytes, stderr_bytes = await asyncio.gather(stdout_task, stderr_task)
return stdout_bytes, stderr_bytes
def _write_code(self, code: str, language: Language, tmpdir: str) -> tuple:
if language == Language.JAVA:
classname = self._extract_java_classname(code)
filename = f"{classname}.java"
elif language == Language.CPP:
filename = "main.cpp"
elif language == Language.RUST:
filename = "main.rs"
else:
extension = {Language.PYTHON: ".py", Language.JAVASCRIPT: ".js", Language.GO: ".go", Language.BASH: ".sh"}.get(language, ".txt")
filename = f"main{extension}"
filepath = Path(tmpdir) / filename
filepath.write_text(code, encoding='utf-8')
return filename, classname if language == Language.JAVA else None
def _extract_java_classname(self, code: str) -> str:
for line in code.split('\n'):
line = line.strip()
if line.startswith('public class '):
return line.split()[2].split('{')[0]
elif line.startswith('class '):
return line.split()[1].split('{')[0]
return "Main"
def _build_command(self, language: Language, filename: str, classname: Optional[str], dirname: str) -> List[str]:
if language == Language.JAVA:
return ["java", "-cp", dirname, classname]
elif language == Language.GO:
return ["go", "run", filename]
elif language == Language.CPP:
return ["g++", "-o", str(Path(dirname) / "main"), filename]
elif language == Language.RUST:
return ["rustc", "-o", str(Path(dirname) / "main"), filename]
elif language == Language.PYTHON:
return ["python3", "-u", filename]
elif language == Language.JAVASCRIPT:
return ["node", filename]
elif language == Language.BASH:
return ["bash", filename]
else:
raise ValueError(f"Unsupported language: {language}")
class ExecutionPool:
def __init__(self, pool_size: int = 10, resource_limit: Optional[ResourceLimit] = None):
self.pool_size = pool_size
self.resource_limit = resource_limit or ResourceLimit()
self._active_executions: Dict[str, ExecutionTask] = {}
self._execution_locks: Dict[str, asyncio.Lock] = {}
self._pool_semaphore = asyncio.Semaphore(pool_size)
self._running_tasks: Dict[str, asyncio.Task] = {}
async def execute(self, task: ExecutionTask) -> ExecutionResult:
execution_lock = asyncio.Lock()
self._execution_locks[task.task_id] = execution_lock
async with self._pool_semaphore:
async with execution_lock:
self._active_executions[task.task_id] = task
sandbox = Sandbox(task.resource_limit)
result = await sandbox.execute(task.code, task.language, task.stdin, task.timeout_seconds, task.working_dir)
del self._active_executions[task.task_id]
return result
async def execute_stream(self, task: ExecutionTask) -> AsyncIterator[ExecutionResult]:
execution_id = str(uuid.uuid4())
start_time = time.perf_counter()
with tempfile.TemporaryDirectory() as tmpdir:
sandbox = Sandbox(task.resource_limit)
filename, classname = sandbox._write_code(task.code, task.language, tmpdir)
cmd = sandbox._build_command(task.language, filename, classname, tmpdir)
process = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, cwd=tmpdir, start_new_session=True)
self._running_tasks[execution_id] = process
try:
loop = asyncio.get_event_loop()
while True:
elapsed = time.perf_counter() - start_time
if elapsed > task.timeout_seconds:
process.kill()
yield ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.TIMEOUT, exit_code=-1,
stdout="", stderr=f"Timeout after {task.timeout_seconds}s",
execution_time_ms=int(elapsed * 1000), memory_peak_bytes=0, cpu_time_seconds=elapsed
)
return
stdout_line = await loop.run_in_executor(None, process.stdout.readline)
stderr_line = await loop.run_in_executor(None, process.stderr.readline)
if not stdout_line and not stderr_line:
if process.poll() is not None:
break
await asyncio.sleep(0.01)
continue
if stdout_line:
yield ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.RUNNING, exit_code=0,
stdout=stdout_line.decode(), stderr="",
execution_time_ms=int((time.perf_counter() - start_time) * 1000), memory_peak_bytes=0, cpu_time_seconds=0
)
if stderr_line:
yield ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.RUNNING, exit_code=0,
stdout="", stderr=stderr_line.decode(),
execution_time_ms=int((time.perf_counter() - start_time) * 1000), memory_peak_bytes=0, cpu_time_seconds=0
)
await loop.run_in_executor(None, process.wait)
end_time = time.perf_counter()
yield ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.COMPLETED, exit_code=process.returncode or 0,
stdout="", stderr="", execution_time_ms=int((end_time - start_time) * 1000), memory_peak_bytes=0, cpu_time_seconds=end_time - start_time
)
except Exception as e:
yield ExecutionResult(
execution_id=execution_id, status=ExecutionStatus.FAILED, exit_code=-1,
stdout="", stderr=str(e),
execution_time_ms=int((time.perf_counter() - start_time) * 1000), memory_peak_bytes=0, cpu_time_seconds=0
)
finally:
if execution_id in self._running_tasks:
del self._running_tasks[execution_id]
def cancel(self, execution_id: str) -> bool:
if execution_id in self._running_tasks:
self._running_tasks[execution_id].kill()
return True
return False
class CodeExecutionService:
def __init__(self, pool_size: int = 20):
self.pool = ExecutionPool(pool_size=pool_size)
self._tasks: Dict[str, ExecutionTask] = {}
self._results: Dict[str, ExecutionResult] = {}
async def execute(self, request: Dict[str, Any]) -> ExecutionResult:
task = ExecutionTask(
task_id=request.get('task_id', str(uuid.uuid4())),
language=Language(request['language']),
code=request['code'],
stdin=request.get('stdin', ''),
timeout_seconds=request.get('timeout_seconds', 30.0)
)
self._tasks[task.task_id] = task
result = await self.pool.execute(task)
self._results[task.task_id] = result
return result
async def execute_stream(self, request: Dict[str, Any]) -> AsyncIterator[ExecutionResult]:
task = ExecutionTask(
task_id=request.get('task_id', str(uuid.uuid4())),
language=Language(request['language']),
code=request['code'],
stdin=request.get('stdin', ''),
timeout_seconds=request.get('timeout_seconds', 30.0)
)
self._tasks[task.task_id] = task
async for result in self.pool.execute_stream(task):
self._results[task.task_id] = result
yield result
def get_status(self, task_id: str) -> Optional[str]:
if task_id in self._results:
return self._results[task_id].status.value
if task_id in self._tasks:
return ExecutionStatus.RUNNING.value
return None
def get_result(self, task_id: str) -> Optional[ExecutionResult]:
return self._results.get(task_id)
def cancel(self, task_id: str) -> bool:
return self.pool.cancel(task_id)
async def serve():
service = CodeExecutionService(pool_size=20)
import grpc
server = grpc.aio.server()
server.add_insecure_port('[::]:50051')
logger.info("Code Execution Service started on port 50051")
await server.wait_for_termination()
if __name__ == "__main__":
asyncio.run(serve())3.3 AI推理服务实现
AI推理服务负责处理所有与AI能力相关的请求,包括代码补全、代码解释、错误修复建议等。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Cloud IDE AI Inference Service
AI推理服务 - 支持多模型、Streaming、Token管理
"""
import asyncio
import json
import logging
import time
import uuid
from dataclasses import dataclass, field
from typing import AsyncIterator, Dict, List, Optional, Any, Union
from enum import Enum
from collections import defaultdict
import hashlib
import httpx
import redis.asyncio as redis
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ModelType(Enum):
GPT4 = "gpt-4"
GPT4_TURBO = "gpt-4-turbo"
GPT35_TURBO = "gpt-3.5-turbo"
CLAUDE3 = "claude-3"
CLAUDE3_HAIKU = "claude-3-haiku"
LOCAL_LLM = "local-llm"
@dataclass
class ModelConfig:
model_type: ModelType
api_key: str
base_url: str = "https://api.openai.com/v1"
max_tokens: int = 4096
temperature: float = 0.7
top_p: float = 1.0
timeout_seconds: float = 120.0
cost_per_1k_tokens: float = 0.002
@dataclass
class TokenBudget:
user_id: str
total_tokens: int = 100000
used_tokens: int = 0
reset_at: float = field(default_factory=lambda: time.time() + 86400)
def can_use(self, tokens: int) -> bool:
if time.time() > self.reset_at:
return True
return (self.used_tokens + tokens) <= self.total_tokens
def consume(self, tokens: int):
if time.time() > self.reset_at:
self.used_tokens = 0
self.reset_at = time.time() + 86400
self.used_tokens += tokens
def remaining(self) -> int:
if time.time() > self.reset_at:
return self.total_tokens
return max(0, self.total_tokens - self.used_tokens)
@dataclass
class InferenceRequest:
request_id: str
user_id: str
model: ModelType
prompt: str
system_message: str = ""
max_tokens: int = 1024
temperature: float = 0.7
stream: bool = True
context_id: Optional[str] = None
def __post_init__(self):
if isinstance(self.model, str):
self.model = ModelType(self.model)
@dataclass
class InferenceResponse:
request_id: str
content: str
finish_reason: str
tokens_used: int
inference_time_ms: int
cost: float
@dataclass
class StreamChunk:
request_id: str
delta: str
is_final: bool = False
chunk_type: str = "content"
class BaseModelAdapter:
def __init__(self, config: ModelConfig):
self.config = config
async def infer(self, prompt: str, system_message: str = "", max_tokens: int = 1024, temperature: float = 0.7, stream: bool = False, **kwargs) -> Union[InferenceResponse, AsyncIterator[StreamChunk]]:
raise NotImplementedError
def calculate_cost(self, tokens: int) -> float:
return (tokens / 1000) * self.config.cost_per_1k_tokens
class OpenAIAdapter(BaseModelAdapter):
async def infer(self, prompt: str, system_message: str = "", max_tokens: int = 1024, temperature: float = 0.7, stream: bool = False, **kwargs) -> Union[InferenceResponse, AsyncIterator[StreamChunk]]:
headers = {"Authorization": f"Bearer {self.config.api_key}", "Content-Type": "application/json"}
messages = []
if system_message:
messages.append({"role": "system", "content": system_message})
messages.append({"role": "user", "content": prompt})
payload = {"model": self.config.model_type.value, "messages": messages, "max_tokens": max_tokens, "temperature": temperature, "stream": stream}
async with httpx.AsyncClient(timeout=self.config.timeout_seconds) as client:
if stream:
return self._stream_response(client, headers, payload)
else:
return await self._sync_response(client, headers, payload)
async def _sync_response(self, client: httpx.AsyncClient, headers: Dict, payload: Dict) -> InferenceResponse:
start_time = time.perf_counter()
response = await client.post(f"{self.config.base_url}/chat/completions", headers=headers, json=payload)
response.raise_for_status()
data = response.json()
content = data["choices"][0]["message"]["content"]
usage = data.get("usage", {})
tokens_used = usage.get("total_tokens", len(content) // 4)
inference_time_ms = int((time.perf_counter() - start_time) * 1000)
return InferenceResponse(
request_id=str(uuid.uuid4()), content=content,
finish_reason=data["choices"][0].get("finish_reason", "stop"),
tokens_used=tokens_used, inference_time_ms=inference_time_ms, cost=self.calculate_cost(tokens_used)
)
async def _stream_response(self, client: httpx.AsyncClient, headers: Dict, payload: Dict) -> AsyncIterator[StreamChunk]:
request_id = str(uuid.uuid4())
full_content = []
async with client.stream("POST", f"{self.config.base_url}/chat/completions", headers=headers, json=payload) as response:
async for line in response.aiter_lines():
if not line.startswith("data: "):
continue
data = line[6:]
if data == "[DONE]":
break
try:
chunk_data = json.loads(data)
delta = chunk_data["choices"][0]["delta"].get("content", "")
if delta:
full_content.append(delta)
yield StreamChunk(request_id=request_id, delta=delta, is_final=False)
except json.JSONDecodeError:
continue
yield StreamChunk(request_id=request_id, delta="", is_final=True, chunk_type="metadata")
class ClaudeAdapter(BaseModelAdapter):
async def infer(self, prompt: str, system_message: str = "", max_tokens: int = 1024, temperature: float = 0.7, stream: bool = False, **kwargs) -> Union[InferenceResponse, AsyncIterator[StreamChunk]]:
headers = {"x-api-key": self.config.api_key, "Content-Type": "application/json", "anthropic-version": "2023-06-01"}
payload = {"model": self.config.model_type.value, "messages": [{"role": "user", "content": prompt}], "max_tokens": max_tokens, "temperature": temperature, "stream": stream}
if system_message:
payload["system"] = system_message
async with httpx.AsyncClient(timeout=self.config.timeout_seconds) as client:
if stream:
return self._stream_response(client, headers, payload)
else:
return await self._sync_response(client, headers, payload)
async def _sync_response(self, client: httpx.AsyncClient, headers: Dict, payload: Dict) -> InferenceResponse:
start_time = time.perf_counter()
response = await client.post("https://api.anthropic.com/v1/messages", headers=headers, json=payload)
response.raise_for_status()
data = response.json()
content = data["content"][0]["text"]
usage = data.get("usage", {})
tokens_used = usage.get("input_tokens", 0) + usage.get("output_tokens", 0)
inference_time_ms = int((time.perf_counter() - start_time) * 1000)
return InferenceResponse(
request_id=str(uuid.uuid4()), content=content, finish_reason=data.get("stop_reason", "end_turn"),
tokens_used=tokens_used, inference_time_ms=inference_time_ms, cost=self.calculate_cost(tokens_used)
)
async def _stream_response(self, client: httpx.AsyncClient, headers: Dict, payload: Dict) -> AsyncIterator[StreamChunk]:
request_id = str(uuid.uuid4())
full_content = []
async with client.stream("POST", "https://api.anthropic.com/v1/messages", headers=headers, json=payload) as response:
async for line in response.aiter_lines():
if not line.startswith("data: "):
continue
data = line[6:]
if data == "[DONE]":
break
try:
chunk_data = json.loads(data)
chunk_type = chunk_data.get("type")
if chunk_type == "content_block_delta":
delta = chunk_data["delta"].get("text", "")
if delta:
full_content.append(delta)
yield StreamChunk(request_id=request_id, delta=delta, is_final=False)
except json.JSONDecodeError:
continue
yield StreamChunk(request_id=request_id, delta="", is_final=True, chunk_type="metadata")
class ModelAdapterFactory:
_adapters: Dict[ModelType, type] = {ModelType.GPT4: OpenAIAdapter, ModelType.GPT4_TURBO: OpenAIAdapter, ModelType.GPT35_TURBO: OpenAIAdapter, ModelType.CLAUDE3: ClaudeAdapter, ModelType.CLAUDE3_HAIKU: ClaudeAdapter}
@classmethod
def create(cls, config: ModelConfig) -> BaseModelAdapter:
adapter_class = cls._adapters.get(config.model_type)
if not adapter_class:
raise ValueError(f"Unsupported model type: {config.model_type}")
return adapter_class(config)
class TokenBudgetManager:
def __init__(self, redis_client: Optional[redis.Redis] = None):
self.redis = redis_client
self._local_budgets: Dict[str, TokenBudget] = defaultdict(lambda: TokenBudget(user_id="default"))
async def get_budget(self, user_id: str) -> TokenBudget:
if self.redis:
key = f"token_budget:{user_id}"
data = await self.redis.hgetall(key)
if data:
return TokenBudget(user_id=user_id, total_tokens=int(data.get(b"total_tokens", 100000)), used_tokens=int(data.get(b"used_tokens", 0)), reset_at=float(data.get(b"reset_at", time.time() + 86400)))
return self._local_budgets[user_id]
async def consume(self, user_id: str, tokens: int):
budget = await self.get_budget(user_id)
budget.consume(tokens)
if self.redis:
key = f"token_budget:{user_id}"
await self.redis.hset(key, mapping={"total_tokens": budget.total_tokens, "used_tokens": budget.used_tokens, "reset_at": budget.reset_at})
async def check(self, user_id: str, tokens_needed: int) -> bool:
budget = await self.get_budget(user_id)
return budget.can_use(tokens_needed)
class InferenceCache:
def __init__(self, redis_client: Optional[redis.Redis] = None, ttl_seconds: int = 3600):
self.redis = redis_client
self.ttl = ttl_seconds
self._local_cache: Dict[str, str] = {}
def _make_key(self, request: InferenceRequest) -> str:
content = f"{request.model.value}:{request.prompt}:{request.system_message}:{request.temperature}"
return hashlib.sha256(content.encode()).hexdigest()
async def get(self, request: InferenceRequest) -> Optional[InferenceResponse]:
key = self._make_key(request)
if self.redis:
data = await self.redis.get(f"inference_cache:{key}")
if data:
return InferenceResponse(**json.loads(data))
return self._local_cache.get(key)
async def set(self, request: InferenceRequest, response: InferenceResponse):
key = self._make_key(request)
if self.redis:
await self.redis.setex(f"inference_cache:{key}", self.ttl, json.dumps({"request_id": response.request_id, "content": response.content, "finish_reason": response.finish_reason, "tokens_used": response.tokens_used, "inference_time_ms": response.inference_time_ms, "cost": response.cost}))
self._local_cache[key] = json.dumps({"request_id": response.request_id, "content": response.content})
class AIInferenceService:
def __init__(self, model_configs: Dict[ModelType, ModelConfig], redis_url: Optional[str] = None):
self.model_configs = model_configs
self.adapters: Dict[ModelType, BaseModelAdapter] = {model_type: ModelAdapterFactory.create(config) for model_type, config in model_configs.items()}
self._redis: Optional[redis.Redis] = None
if redis_url:
self._redis = redis.from_url(redis_url)
self.budget_manager = TokenBudgetManager(self._redis)
self.cache = InferenceCache(self._redis)
self._sessions: Dict[str, List[Dict]] = {}
self._session_lock = asyncio.Lock()
async def infer(self, request: InferenceRequest) -> InferenceResponse:
cached = await self.cache.get(request)
if cached:
logger.info(f"Cache hit for request {request.request_id}")
return cached
estimated_tokens = request.max_tokens + len(request.prompt) // 4
if not await self.budget_manager.check(request.user_id, estimated_tokens):
raise ValueError("Token budget exceeded")
adapter = self.adapters.get(request.model)
if not adapter:
raise ValueError(f"Model {request.model} not configured")
if request.context_id:
async with self._session_lock:
if request.context_id in self._sessions:
context = self._sessions[request.context_id]
context_text = "\n".join([f"{msg['role']}: {msg['content']}" for msg in context])
request.prompt = f"Previous conversation:\n{context_text}\n\nCurrent request:\n{request.prompt}"
response = await adapter.infer(prompt=request.prompt, system_message=request.system_message, max_tokens=request.max_tokens, temperature=request.temperature, stream=False)
await self.budget_manager.consume(request.user_id, response.tokens_used)
if request.context_id:
async with self._session_lock:
if request.context_id not in self._sessions:
self._sessions[request.context_id] = []
self._sessions[request.context_id].extend([{"role": "user", "content": request.prompt}, {"role": "assistant", "content": response.content}])
if len(self._sessions[request.context_id]) > 20:
self._sessions[request.context_id] = self._sessions[request.context_id][-20:]
await self.cache.set(request, response)
return response
async def infer_stream(self, request: InferenceRequest) -> AsyncIterator[StreamChunk]:
adapter = self.adapters.get(request.model)
if not adapter:
raise ValueError(f"Model {request.model} not configured")
full_content = []
async for chunk in await adapter.infer(prompt=request.prompt, system_message=request.system_message, max_tokens=request.max_tokens, temperature=request.temperature, stream=True):
if chunk.chunk_type == "content" and not chunk.is_final:
full_content.append(chunk.delta)
yield chunk
elif chunk.is_final:
tokens_used = len("".join(full_content)) // 4
cost = adapter.calculate_cost(tokens_used)
await self.budget_manager.consume(request.user_id, tokens_used)
async def get_session_context(self, context_id: str) -> List[Dict]:
async with self._session_lock:
return self._sessions.get(context_id, [])
async def clear_session(self, context_id: str):
async with self._session_lock:
if context_id in self._sessions:
del self._sessions[context_id]
async def serve():
model_configs = {
ModelType.GPT4_TURBO: ModelConfig(model_type=ModelType.GPT4_TURBO, api_key=os.environ.get("OPENAI_API_KEY", ""), base_url="https://api.openai.com/v1", max_tokens=4096, cost_per_1k_tokens=0.01),
ModelType.CLAUDE3: ModelConfig(model_type=ModelType.CLAUDE3, api_key=os.environ.get("ANTHROPIC_API_KEY", ""), max_tokens=4096, cost_per_1k_tokens=0.015)
}
service = AIInferenceService(model_configs=model_configs, redis_url="redis://localhost:6379")
import grpc
server = grpc.aio.server()
server.add_insecure_port('[::]:50052')
logger.info("AI Inference Service started on port 50052")
await server.wait_for_termination()
if __name__ == "__main__":
import os
asyncio.run(serve())3.4 任务调度服务实现
任务调度服务是整个系统的协调中心,负责接收任务、调度执行、管理状态。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Cloud IDE Task Scheduler Service
任务调度服务 - 智能任务调度与状态管理
"""
import asyncio
import heapq
import logging
import time
import uuid
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Any, AsyncIterator, Callable, Awaitable, Set
from enum import Enum
from collections import defaultdict
import json
import redis.asyncio as redis
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class TaskType(Enum):
CODE_EXECUTION = "code_execution"
AI_INFERENCE = "ai_inference"
FILE_OPERATION = "file_operation"
BUILD_PROJECT = "build_project"
RUN_TEST = "run_test"
DEPLOY = "deploy"
class TaskPriority(Enum):
CRITICAL = 0
HIGH = 1
NORMAL = 2
LOW = 3
BACKGROUND = 4
class TaskStatus(Enum):
PENDING = "pending"
QUEUED = "queued"
SCHEDULED = "scheduled"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
TIMEOUT = "timeout"
@dataclass
class Task:
task_id: str
task_type: TaskType
priority: TaskPriority
payload: Dict[str, Any]
created_at: float = field(default_factory=time.time)
scheduled_at: Optional[float] = None
started_at: Optional[float] = None
completed_at: Optional[float] = None
user_id: str = "default"
dependencies: List[str] = field(default_factory=list)
max_retries: int = 3
retry_count: int = 0
timeout_seconds: float = 300.0
metadata: Dict[str, Any] = field(default_factory=dict)
def __post_init__(self):
if isinstance(self.task_type, str):
self.task_type = TaskType(self.task_type)
if isinstance(self.priority, int):
self.priority = TaskPriority(self.priority)
if not self.task_id:
self.task_id = str(uuid.uuid4())
@property
def priority_score(self) -> float:
base_score = self.priority.value * 1000000
wait_time = time.time() - self.created_at
time_factor = min(wait_time / 100, 100)
return base_score - time_factor
def to_dict(self) -> Dict:
return {"task_id": self.task_id, "task_type": self.task_type.value, "priority": self.priority.value, "payload": self.payload, "created_at": self.created_at, "scheduled_at": self.scheduled_at, "started_at": self.started_at, "completed_at": self.completed_at, "user_id": self.user_id, "dependencies": self.dependencies, "max_retries": self.max_retries, "retry_count": self.retry_count, "timeout_seconds": self.timeout_seconds, "metadata": self.metadata}
@classmethod
def from_dict(cls, data: Dict) -> "Task":
return cls(task_id=data["task_id"], task_type=TaskType(data["task_type"]), priority=TaskPriority(data["priority"]), payload=data["payload"], created_at=data.get("created_at", time.time()), scheduled_at=data.get("scheduled_at"), started_at=data.get("started_at"), completed_at=data.get("completed_at"), user_id=data.get("user_id", "default"), dependencies=data.get("dependencies", []), max_retries=data.get("max_retries", 3), retry_count=data.get("retry_count", 0), timeout_seconds=data.get("timeout_seconds", 300.0), metadata=data.get("metadata", {}))
@dataclass
class ResourceRequirement:
cpu_cores: float = 0.1
memory_mb: int = 128
gpu_count: int = 0
disk_mb: int = 0
network_io_mbps: float = 0
def can_fit(self, available: "ResourceAvailability") -> bool:
return available.cpu_cores >= self.cpu_cores and available.memory_mb >= self.memory_mb and available.gpu_count >= self.gpu_count
@dataclass
class ResourceAvailability:
cpu_cores: float
memory_mb: int
gpu_count: int = 0
disk_mb: int = 0
def allocate(self, requirement: ResourceRequirement) -> "ResourceAvailability":
return ResourceAvailability(cpu_cores=self.cpu_cores - requirement.cpu_cores, memory_mb=self.memory_mb - requirement.memory_mb, gpu_count=self.gpu_count - requirement.gpu_count, disk_mb=self.disk_mb - requirement.disk_mb)
def release(self, requirement: ResourceRequirement):
self.cpu_cores += requirement.cpu_cores
self.memory_mb += requirement.memory_mb
self.gpu_count += requirement.gpu_count
self.disk_mb += requirement.disk_mb
class TaskQueue:
def __init__(self):
self._heap: List[Task] = []
self._task_set: Set[str] = set()
self._lock = asyncio.Lock()
async def push(self, task: Task):
async with self._lock:
if task.task_id in self._task_set:
return False
heapq.heappush(self._heap, task)
self._task_set.add(task.task_id)
return True
async def pop(self) -> Optional[Task]:
async with self._lock:
if not self._heap:
return None
task = heapq.heappop(self._heap)
self._task_set.discard(task.task_id)
return task
async def peek(self) -> Optional[Task]:
async with self._lock:
if not self._heap:
return None
return self._heap[0]
async def remove(self, task_id: str) -> bool:
async with self._lock:
if task_id not in self._task_set:
return False
self._task_set.discard(task_id)
self._heap = [t for t in self._heap if t.task_id != task_id]
heapq.heapify(self._heap)
return True
async def size(self) -> int:
async with self._lock:
return len(self._heap)
async def contains(self, task_id: str) -> bool:
async with self._lock:
return task_id in self._task_set
class ResourceManager:
def __init__(self, total_resources: ResourceAvailability):
self.total = total_resources
self.available = ResourceAvailability(cpu_cores=total_resources.cpu_cores, memory_mb=total_resources.memory_mb, gpu_count=total_resources.gpu_count, disk_mb=total_resources.disk_mb)
self._allocated: Dict[str, ResourceRequirement] = {}
self._lock = asyncio.Lock()
async def can_allocate(self, requirement: ResourceRequirement) -> bool:
async with self._lock:
return self.available.can_fit(requirement)
async def allocate(self, task_id: str, requirement: ResourceRequirement) -> bool:
async with self._lock:
if not self.available.can_fit(requirement):
return False
self.available = self.available.allocate(requirement)
self._allocated[task_id] = requirement
return True
async def release(self, task_id: str):
async with self._lock:
if task_id in self._allocated:
requirement = self._allocated[task_id]
self.available.release(requirement)
del self._allocated[task_id]
async def get_availability(self) -> ResourceAvailability:
async with self._lock:
return ResourceAvailability(cpu_cores=self.available.cpu_cores, memory_mb=self.available.memory_mb, gpu_count=self.available.gpu_count, disk_mb=self.available.disk_mb)
async def get_allocation(self, task_id: str) -> Optional[ResourceRequirement]:
async with self._lock:
return self._allocated.get(task_id)
class TaskExecutor:
async def can_handle(self, task: Task) -> bool:
raise NotImplementedError
async def execute(self, task: Task) -> Dict[str, Any]:
raise NotImplementedError
class TaskScheduler:
def __init__(self, redis_url: str, total_resources: ResourceAvailability, max_concurrent_tasks: int = 100):
self.redis_url = redis_url
self.redis: Optional[redis.Redis] = None
self.pending_queue = TaskQueue()
self.running_tasks: Dict[str, Task] = {}
self.completed_tasks: Dict[str, Task] = {}
self.resource_manager = ResourceManager(total_resources)
self.max_concurrent_tasks = max_concurrent_tasks
self._executors: List[TaskExecutor] = []
self._scheduler_task: Optional[asyncio.Task] = None
self._running = False
self._lock = asyncio.Lock()
self._stats = {"tasks_submitted": 0, "tasks_completed": 0, "tasks_failed": 0, "tasks_cancelled": 0}
def register_executor(self, executor: TaskExecutor):
self._executors.append(executor)
def _get_executor(self, task: Task) -> Optional[TaskExecutor]:
for executor in self._executors:
if asyncio.run(executor.can_handle(task)):
return executor
return None
async def start(self):
self.redis = await redis.from_url(self.redis_url)
self._running = True
self._scheduler_task = asyncio.create_task(self._schedule_loop())
logger.info("Task Scheduler started")
async def stop(self):
self._running = False
if self._scheduler_task:
self._scheduler_task.cancel()
try:
await self._scheduler_task
except asyncio.CancelledError:
pass
if self.redis:
await self.redis.close()
logger.info("Task Scheduler stopped")
async def submit_task(self, task: Task) -> str:
for dep_id in task.dependencies:
if await self.pending_queue.contains(dep_id):
pass
elif dep_id not in self.completed_tasks:
raise ValueError(f"Dependency {dep_id} not completed")
await self.pending_queue.push(task)
if self.redis:
await self.redis.hset(f"task:{task.task_id}", mapping={k: json.dumps(v) if isinstance(v, (dict, list)) else str(v) for k, v in task.to_dict().items()})
self._stats["tasks_submitted"] += 1
logger.info(f"Task {task.task_id} submitted with priority {task.priority}")
return task.task_id
async def cancel_task(self, task_id: str) -> bool:
if task_id in self.running_tasks:
task = self.running_tasks[task_id]
task.status = TaskStatus.CANCELLED
await self.resource_manager.release(task_id)
del self.running_tasks[task_id]
self._stats["tasks_cancelled"] += 1
return True
if await self.pending_queue.remove(task_id):
self._stats["tasks_cancelled"] += 1
return True
return False
async def get_task_status(self, task_id: str) -> Optional[Dict]:
if task_id in self.running_tasks:
return self.running_tasks[task_id].to_dict()
if task_id in self.completed_tasks:
return self.completed_tasks[task_id].to_dict()
if await self.pending_queue.contains(task_id):
return {"task_id": task_id, "status": TaskStatus.PENDING.value}
if self.redis:
data = await self.redis.hgetall(f"task:{task_id}")
if data:
return {k.decode(): json.loads(v) if b'{' in v else v.decode() for k, v in data.items()}
return None
async def _schedule_loop(self):
while self._running:
try:
availability = await self.resource_manager.get_availability()
queue_size = await self.pending_queue.size()
if queue_size > 0 and len(self.running_tasks) < self.max_concurrent_tasks:
task = await self.pending_queue.pop()
if task:
req = self._estimate_resource_requirement(task)
if await self.resource_manager.allocate(task.task_id, req):
asyncio.create_task(self._execute_task(task))
else:
await self.pending_queue.push(task)
await self._cleanup_completed_tasks()
await asyncio.sleep(0.1)
except asyncio.CancelledError:
break
except Exception as e:
logger.error(f"Schedule loop error: {e}")
await asyncio.sleep(1)
def _estimate_resource_requirement(self, task: Task) -> ResourceRequirement:
if task.task_type == TaskType.CODE_EXECUTION:
return ResourceRequirement(cpu_cores=0.5, memory_mb=256, disk_mb=50)
elif task.task_type == TaskType.AI_INFERENCE:
return ResourceRequirement(cpu_cores=1.0, memory_mb=512, gpu_count=0 if "gpt" in task.payload.get("model", "") else 1)
else:
return ResourceRequirement(cpu_cores=0.1, memory_mb=64)
async def _execute_task(self, task: Task):
task.started_at = time.time()
self.running_tasks[task.task_id] = task
try:
executor = self._get_executor(task)
if not executor:
raise ValueError(f"No executor for task type {task.task_type}")
result = await asyncio.wait_for(executor.execute(task), timeout=task.timeout_seconds)
task.completed_at = time.time()
task.status = TaskStatus.COMPLETED
self.completed_tasks[task.task_id] = task
self._stats["tasks_completed"] += 1
logger.info(f"Task {task.task_id} completed in {task.completed_at - task.started_at:.2f}s")
except asyncio.TimeoutError:
task.status = TaskStatus.TIMEOUT
task.completed_at = time.time()
self.completed_tasks[task.task_id] = task
self._stats["tasks_failed"] += 1
logger.warning(f"Task {task.task_id} timed out")
except Exception as e:
task.status = TaskStatus.FAILED
task.completed_at = time.time()
task.metadata["error"] = str(e)
self.completed_tasks[task.task_id] = task
self._stats["tasks_failed"] += 1
logger.error(f"Task {task.task_id} failed: {e}")
if task.retry_count < task.max_retries:
task.retry_count += 1
task.status = TaskStatus.PENDING
await self.pending_queue.push(task)
logger.info(f"Task {task.task_id} scheduled for retry ({task.retry_count}/{task.max_retries})")
finally:
await self.resource_manager.release(task.task_id)
if task.task_id in self.running_tasks:
del self.running_tasks[task.task_id]
async def _cleanup_completed_tasks(self):
if len(self.completed_tasks) > 1000:
sorted_tasks = sorted(self.completed_tasks.items(), key=lambda x: x[1].completed_at or 0)
for task_id, _ in sorted_tasks[:len(self.completed_tasks) - 1000]:
del self.completed_tasks[task_id]
async def get_stats(self) -> Dict:
return {**self._stats, "pending_tasks": await self.pending_queue.size(), "running_tasks": len(self.running_tasks), "completed_tasks": len(self.completed_tasks), "available_resources": await self.resource_manager.get_availability()}
async def serve():
scheduler = TaskScheduler(redis_url="redis://localhost:6379", total_resources=ResourceAvailability(cpu_cores=8.0, memory_mb=16384, gpu_count=2, disk_mb=102400), max_concurrent_tasks=50)
await scheduler.start()
import grpc
server = grpc.aio.server()
server.add_insecure_port('[::]:50053')
logger.info("Task Scheduler Service started on port 50053")
await server.wait_for_termination()
if __name__ == "__main__":
asyncio.run(serve())4. 容器化部署:Docker Compose与Kubernetes
本节为你提供的核心技术价值: 掌握从单机Docker到集群Kubernetes的完整部署方案,理解容器编排的核心概念和配置方法。
4.1 Docker Compose本地开发部署
Docker Compose是本地开发和测试的首选工具,它允许我们通过一个YAML文件定义和运行多容器应用。
# docker-compose.yml - Cloud IDE 本地开发环境
version: '3.8'
services:
api-gateway:
build:
context: ./services/gateway
dockerfile: Dockerfile
container_name: cloudide-gateway
ports:
- "8080:8080"
environment:
- REDIS_URL=redis://redis:6379
- JWT_SECRET=${JWT_SECRET:-your-secret-key}
- LOG_LEVEL=info
depends_on:
- redis
- code-exec
- ai-service
- task-scheduler
networks:
- cloudide-network
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
code-exec:
build:
context: ./services/code-exec
dockerfile: Dockerfile
container_name: cloudide-code-exec
ports:
- "50051:50051"
environment:
- REDIS_URL=redis://redis:6379
- POOL_SIZE=20
- MAX_CPU_TIME=60
- MAX_MEMORY_MB=1024
volumes:
- /tmp/cloudide-sandbox:/sandbox
- /var/run/docker.sock:/var/run/docker.sock
networks:
- cloudide-network
restart: unless-stopped
deploy:
resources:
limits:
cpus: '4'
memory: 4G
reservations:
cpus: '1'
memory: 1G
security_opt:
- no-new-privileges:true
cap_drop:
- ALL
ai-service:
build:
context: ./services/ai
dockerfile: Dockerfile
container_name: cloudide-ai
ports:
- "50052:50052"
environment:
- REDIS_URL=redis://redis:6379
- OPENAI_API_KEY=${OPENAI_API_KEY}
- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY}
- DEFAULT_MODEL=gpt-4-turbo
- MAX_TOKENS=4096
networks:
- cloudide-network
restart: unless-stopped
task-scheduler:
build:
context: ./services/scheduler
dockerfile: Dockerfile
container_name: cloudide-scheduler
ports:
- "50053:50053"
environment:
- REDIS_URL=redis://redis:6379
- MAX_CONCURRENT_TASKS=50
- CPU_CORES=8
- MEMORY_MB=16384
- GPU_COUNT=2
depends_on:
- redis
networks:
- cloudide-network
restart: unless-stopped
redis:
image: redis:7-alpine
container_name: cloudide-redis
ports:
- "6379:6379"
command: >
redis-server
--maxmemory 2gb
--maxmemory-policy allkeys-lru
--appendonly yes
--appendfsync everysec
volumes:
- redis-data:/data
networks:
- cloudide-network
restart: unless-stopped
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 5s
retries: 3
prometheus:
image: prom/prometheus:latest
container_name: cloudide-prometheus
ports:
- "9090:9090"
volumes:
- ./config/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.enable-lifecycle'
networks:
- cloudide-network
restart: unless-stopped
grafana:
image: grafana/grafana:latest
container_name: cloudide-grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PASSWORD:-admin}
- GF_USERS_ALLOW_SIGN_UP=false
volumes:
- grafana-data:/var/lib/grafana
depends_on:
- prometheus
networks:
- cloudide-network
restart: unless-stopped
networks:
cloudide-network:
driver: bridge
ipam:
config:
- subnet: 172.20.0.0/16
volumes:
redis-data:
prometheus-data:
grafana-data:4.2 Kubernetes生产部署
当系统需要面向生产环境时,Kubernetes提供了更强大的容器编排能力。
# k8s/namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: cloudide
labels:
name: cloudide
environment: production
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cloudide-config
namespace: cloudide
data:
REDIS_URL: "redis://redis-master:6379"
LOG_LEVEL: "info"
TZ: "Asia/Shanghai"
---
apiVersion: v1
kind: Secret
metadata:
name: cloudide-secrets
namespace: cloudide
type: Opaque
stringData:
JWT_SECRET: "your-production-jwt-secret"
OPENAI_API_KEY: "${OPENAI_API_KEY}"
ANTHROPIC_API_KEY: "${ANTHROPIC_API_KEY}"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-gateway
namespace: cloudide
spec:
replicas: 3
selector:
matchLabels:
app: api-gateway
template:
metadata:
labels:
app: api-gateway
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
spec:
containers:
- name: gateway
image: cloudide/gateway:latest
ports:
- name: http
containerPort: 8080
env:
- name: REDIS_URL
valueFrom:
configMapKeyRef:
name: cloudide-config
key: REDIS_URL
- name: JWT_SECRET
valueFrom:
secretKeyRef:
name: cloudide-secrets
key: JWT_SECRET
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
livenessProbe:
httpGet:
path: /health
port: http
initialDelaySeconds: 10
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: http
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: api-gateway
namespace: cloudide
spec:
type: ClusterIP
ports:
- name: http
port: 8080
targetPort: http
selector:
app: api-gateway
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-gateway-hpa
namespace: cloudide
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-gateway
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: cloudide-ingress
namespace: cloudide
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/proxy-body-size: "100m"
spec:
ingressClassName: nginx
tls:
- hosts:
- cloudide.example.com
secretName: cloudide-tls
rules:
- host: cloudide.example.com
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: api-gateway
port:
number: 80805. 工程成熟度:可部署、可监控、可运维
本节为你提供的核心技术价值: 建立完整的可观测性体系,掌握从代码到生产的DevOps实践,理解SRE核心指标和告警策略。
5.1 可观测性体系建设
可观测性是现代云原生应用的基石,包括三大支柱:指标(Metrics)、日志(Logs)和追踪(Traces)。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Cloud IDE 可观测性组件
OpenTelemetry集成、Prometheus指标、自定义追踪
"""
import time
import logging
import asyncio
from typing import Dict, Any, Optional
from dataclasses import dataclass
from contextvars import ContextVar
from functools import wraps
import json
from opentelemetry import trace, metrics
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.resources import Resource, SERVICE_NAME, SERVICE_VERSION
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
from opentelemetry.exporter.prometheus import PrometheusMetricReader
from opentelemetry.trace import Status, StatusCode
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
request_id_ctx: ContextVar[str] = ContextVar('request_id', default='')
user_id_ctx: ContextVar[str] = ContextVar('user_id', default='')
class ObservabilityManager:
def __init__(self, service_name: str, service_version: str = "1.0.0"):
self.service_name = service_name
self.service_version = service_version
self.resource = Resource.create({SERVICE_NAME: service_name, SERVICE_VERSION: service_version})
self._setup_tracing()
self._setup_metrics()
self.tracer = trace.get_tracer(__name__)
self.meter = metrics.get_meter(__name__)
self._setup_metrics_definitions()
def _setup_tracing(self):
jaeger_exporter = JaegerExporter(agent_host_name="jaeger", agent_port=6831)
span_processor = BatchSpanProcessor(jaeger_exporter)
tracer_provider = TracerProvider(resource=self.resource)
tracer_provider.add_span_processor(span_processor)
trace.set_tracer_provider(tracer_provider)
def _setup_metrics(self):
prometheus_reader = PrometheusMetricReader()
meter_provider = MeterProvider(resource=self.resource, metric_readers=[prometheus_reader])
metrics.set_meter_provider(meter_provider)
def _setup_metrics_definitions(self):
self.requests_total = self.meter.create_counter(name="cloudide_requests_total", description="Total requests", unit="1")
self.request_duration_seconds = self.meter.create_histogram(name="cloudide_request_duration_seconds", description="Request duration", unit="s")
self.tasks_submitted = self.meter.create_counter(name="cloudide_tasks_submitted_total", description="Tasks submitted", unit="1")
self.tasks_completed = self.meter.create_counter(name="cloudide_tasks_completed_total", description="Tasks completed", unit="1")
self.tasks_failed = self.meter.create_counter(name="cloudide_tasks_failed_total", description="Tasks failed", unit="1")
self.ai_inference_total = self.meter.create_counter(name="cloudide_ai_inference_total", description="AI inferences", unit="1")
self.ai_tokens_used = self.meter.create_counter(name="cloudide_ai_tokens_used_total", description="AI tokens used", unit="1")
def record_request(self, method: str, endpoint: str, status_code: int, duration: float):
attributes = {"http.method": method, "http.endpoint": endpoint, "http.status_code": status_code}
self.requests_total.add(1, attributes)
self.request_duration_seconds.record(duration, attributes)
def record_task(self, task_type: str, status: str):
attributes = {"task.type": task_type}
if status == "submitted":
self.tasks_submitted.add(1, attributes)
elif status == "completed":
self.tasks_completed.add(1, attributes)
elif status == "failed":
self.tasks_failed.add(1, attributes)
class StructuredLogger:
def __init__(self, service_name: str):
self.service_name = service_name
self.logger = logging.getLogger(service_name)
def _build_log_entry(self, level: str, message: str, context: Optional[Dict[str, Any]] = None, error: Optional[Exception] = None) -> Dict[str, Any]:
entry = {"timestamp": time.time(), "level": level, "service": self.service_name, "message": message, "request_id": request_id_ctx.get(), "user_id": user_id_ctx.get()}
if context:
entry["context"] = context
if error:
entry["error"] = {"type": type(error).__name__, "message": str(error)}
return entry
def info(self, message: str, context: Optional[Dict[str, Any]] = None):
self.logger.info(json.dumps(self._build_log_entry("INFO", message, context)))
def error(self, message: str, error: Optional[Exception] = None, context: Optional[Dict[str, Any]] = None):
self.logger.error(json.dumps(self._build_log_entry("ERROR", message, None, error)))
def traced(span_name: Optional[str] = None, attributes: Optional[Dict[str, Any]] = None):
def decorator(func):
@wraps(func)
async def async_wrapper(*args, **kwargs):
tracer = trace.get_tracer(__name__)
name = span_name or func.__name__
with tracer.start_as_current_span(name, attributes=attributes or {}) as span:
try:
start_time = time.perf_counter()
result = await func(*args, **kwargs)
duration = time.perf_counter() - start_time
span.set_status(Status(StatusCode.OK))
span.set_attribute("duration_ms", duration * 1000)
return result
except Exception as e:
span.set_status(Status(StatusCode.ERROR, str(e)))
span.record_exception(e)
raise
@wraps(func)
def sync_wrapper(*args, **kwargs):
tracer = trace.get_tracer(__name__)
name = span_name or func.__name__
with tracer.start_as_current_span(name, attributes=attributes or {}) as span:
try:
start_time = time.perf_counter()
result = func(*args, **kwargs)
duration = time.perf_counter() - start_time
span.set_status(Status(StatusCode.OK))
span.set_attribute("duration_ms", duration * 1000)
return result
except Exception as e:
span.set_status(Status(StatusCode.ERROR, str(e)))
span.record_exception(e)
raise
return async_wrapper if asyncio.iscoroutinefunction(func) else sync_wrapper
return decorator5.2 Prometheus告警规则
groups:
- name: cloudide-alerts
rules:
- alert: HighErrorRate
expr: rate(cloudide_requests_total{status="error"}[5m]) / rate(cloudide_requests_total[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "High error rate detected"
- alert: ServiceDown
expr: up{job="cloudide"} == 0
for: 1m
labels:
severity: critical
- alert: HighLatency
expr: histogram_quantile(0.95, rate(cloudide_request_duration_seconds_bucket[5m])) > 2
for: 5m
labels:
severity: warning
- alert: TaskQueueBacklog
expr: cloudide_tasks_pending > 1000
for: 5m
labels:
severity: warning6. 性能基准与弹性设计
本节为你提供的核心技术价值: 掌握系统性能测试方法,理解弹性设计的核心原则,能够进行容量规划和性能优化。
6.1 性能基准测试
性能基准测试是评估系统能力边界的重要手段。我们设计了以下测试场景:
测试场景 | 目标指标 | 压测参数 |
|---|---|---|
API Gateway吞吐量 | QPS > 5000 | 并发100, 持续5分钟 |
代码执行延迟 | P99 < 500ms | 并发50, 100次/秒 |
AI推理延迟 | P95 < 3s | 并发20, 10次/秒 |
任务调度吞吐量 | 1000 tasks/min | 混合优先级 |
6.2 弹性设计策略
系统的弹性设计包括以下几个方面:
- 故障隔离:每个服务独立运行,故障不会级联传播
- 熔断降级:当下游服务故障时,快速失败并返回降级响应
- 限流保护:防止突发流量冲垮系统
- 自动扩缩容:根据负载自动调整服务实例数
- 健康检查:及时发现并隔离不健康实例
# HPA配置示例
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: code-exec-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: code-exec
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 3007. 完整代码附录
A. Protocol Buffers定义文件
// cloud_ide.proto
syntax = "proto3";
package cloudide;
service CodeExecution {
rpc Execute(ExecuteRequest) returns (ExecuteResponse);
rpc ExecuteStream(ExecuteRequest) returns (stream ExecuteOutput);
rpc CancelExecution(CancelRequest) returns (CancelResponse);
rpc GetExecutionStatus(StatusRequest) returns (ExecutionStatusResponse);
}
service AIInference {
rpc Infer(InferRequest) returns (InferResponse);
rpc InferStream(InferRequest) returns (stream InferOutput);
}
service TaskScheduler {
rpc SubmitTask(TaskSubmission) returns (TaskSubmissionResponse);
rpc GetTaskStatus(TaskStatusRequest) returns (TaskStatusResponse);
rpc CancelTask(TaskCancelRequest) returns (TaskCancelResponse);
}
message ExecuteRequest {
string task_id = 1;
string language = 2;
string code = 3;
map<string, string> options = 4;
int64 timeout_ms = 5;
}
message ExecuteResponse {
string execution_id = 1;
int32 exit_code = 2;
string stdout = 3;
string stderr = 4;
int64 execution_time_ms = 5;
}
message InferRequest {
string request_id = 1;
string user_id = 2;
string model = 3;
string prompt = 4;
string system_message = 5;
int32 max_tokens = 6;
float temperature = 7;
}
message InferResponse {
string request_id = 1;
string content = 2;
string finish_reason = 3;
int32 tokens_used = 4;
int64 inference_time_ms = 5;
float cost = 6;
}
message TaskSubmission {
string task_id = 1;
string task_type = 2;
int32 priority = 3;
string payload = 4;
string user_id = 5;
}
message TaskSubmissionResponse {
string task_id = 1;
string status = 2;
}B. 状态管理服务
#!/usr/bin/env python3
# state_service.py - Redis状态管理服务
import asyncio
import redis.asyncio as redis
import json
import logging
from typing import Optional, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class StateService:
def __init__(self, redis_url: str):
self.redis = redis.from_url(redis_url)
async def get(self, key: str) -> Optional[Any]:
data = await self.redis.get(key)
if data:
try:
return json.loads(data)
except:
return data.decode()
return None
async def set(self, key: str, value: Any, ttl: Optional[int] = None):
if isinstance(value, (dict, list)):
value = json.dumps(value)
if ttl:
await self.redis.setex(key, ttl, value)
else:
await self.redis.set(key, value)
async def delete(self, key: str):
await self.redis.delete(key)
async def acquire_lock(self, key: str, timeout: int = 10) -> bool:
return await self.redis.set(f"lock:{key}", "1", nx=True, ex=timeout)
async def release_lock(self, key: str):
await self.redis.delete(f"lock:{key}")
async def publish(self, channel: str, message: Any):
if isinstance(message, (dict, list)):
message = json.dumps(message)
await self.redis.publish(channel, message)
async def subscribe(self, channel: str):
pubsub = self.redis.pubsub()
await pubsub.subscribe(channel)
return pubsub
async def main():
service = StateService("redis://localhost:6379")
await service.set("test_key", {"hello": "world"}, ttl=3600)
result = await service.get("test_key")
logger.info(f"Result: {result}")
if __name__ == "__main__":
asyncio.run(main())8. 总结与展望
8.1 本章核心能力总结
本文系统性地整合了Cloud IDE后端服务的完整工程化方案,包括:
能力模块 | 核心技术 | 代码量 |
|---|---|---|
API Gateway | Python/aiohttp, JWT, 令牌桶, 熔断器 | ~500行 |
代码执行服务 | Python/asyncio, 沙箱隔离, 多语言支持 | ~600行 |
AI推理服务 | Python, 多模型适配器, Token管理, 缓存 | ~500行 |
任务调度服务 | Python, 优先级队列, 资源感知调度 | ~500行 |
容器化部署 | Docker Compose, Kubernetes, HPA | ~300行YAML |
可观测性 | OpenTelemetry, Prometheus, Grafana | ~200行 |
8.2 后续优化方向
- 性能优化:引入连接池复用、请求批处理、GPU加速等技术
- 安全增强:完善安全扫描、漏洞检测、权限细化
- 多租户支持:实现资源隔离、计费系统、配额管理
- 全球部署:多Region部署、边缘节点、数据同步
- 智能化运维:自动故障恢复、智能扩缩容、预测性维护
参考链接:
- 主要来源:OpenTelemetry官方文档 - 可观测性标准
- 主要来源:Kubernetes官方文档 - 容器编排
- 主要来源:gRPC官方文档 - RPC通信框架
附录(Appendix): 完整的代码实现已在本章各节中提供,读者可通过以下方式获取完整源码:
- GitHub仓库:
https://github.com/cloudide/cloudide-backend - Docker镜像:
docker pull cloudide/backend:latest
关键词: Cloud IDE、微服务、容器化、gRPC、任务调度、可观测性、Docker Compose、Kubernetes、Redis、OpenTelemetry、Prometheus、Grafana、API Gateway、代码执行、AI推理、弹性伸缩
本文为"安全风信子"技术专栏第四卷综合实战章节版权所有,转载需注明出处。

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号