340GB 索引压到 13GB、成本降到 1/15:Vector Lakebase 架构拆解
原创
340GB 索引压到 13GB、成本降到 1/15:Vector Lakebase 架构拆解
原创
运维有术
发布于 2026-06-07 09:44:12
发布于 2026-06-07 09:44:12
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 131 篇,Milvus 最佳实战「2026」系列第 9 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

信息图封面:Vector Lakebase 核心要点
一个做自动驾驶的客户,数据湖里存了 10 亿条 768 维向量(摄像头帧、驾驶场景、天气、位置等元数据),每天只需要在线查询大约 20 分钟。但为了这 20 分钟,他得跑一组 Long-running 集群,每月烧掉将近 $7,000。
这不是个例。AI 数据架构有个挺普遍的结构性矛盾:在线检索和离线分析,活在两个完全不同的世界里。向量数据库负责低延迟查询,但数据进不去也出不来;数据湖擅长批量分析,但连一个像样的向量索引都没有。
Zilliz 的 Vector Lakebase 就是冲着这个矛盾来的。它不是简单的 向量数据库 + 数据湖 拼接,而是一套统一的、湖原生的 AI 数据基础架构,试图让在线服务和离线发现围绕同一份数据跑起来。
截至 2026 年 6 月,Vector Lakebase 仍处于 Public Preview 阶段(官方未公布 GA 日期)。这篇文章基于 Zilliz 官方博客、CTO 栾小凡和 VP Product 郭人通的公开文章,以及 Milvus 社区公开资料整理,拆解它的技术思路。
说明:本文内容基于 Zilliz 官方博客、CTO/VP Product 公开文章和 Milvus 社区公开资料分析整理而成,尚未在生产环境中完成全场景验证。文中的性能数据和成本对比仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 从向量数据库到 Vector Lakebase:一条怎样的演进路径?
要理解 Vector Lakebase,得先看 Zilliz CTO 栾小凡画的一条历史类比线:
移动互联网时代,数据基础设施经历了三代演进 - MongoDB 解决半结构化数据存储,Snowflake/Redshift 解决分析需求,Lakehouse(Databricks/Iceberg/Hudi)把 OLTP 和 OLAP 统一到同一架构下。
AI 时代正在经历类似的演进。向量数据库(如 Milvus、Pinecone)解决的是 AI 的语义检索问题,相当于当年的 MongoDB。但 AI 系统正在从静态助手演变为持续运行的 Agent,企业需要的不仅是检索,还有聚类、去重、重嵌入、离线评估、模型微调数据准备等发现能力。
Vector Lakebase 想做的,就是 AI 时代的 Lakehouse - 把在线服务(Serving) 和离线发现(Discovery) 统一起来。
这里有个关键认知:向量数据库不会消失。正如 OLTP 数据库在 Lakehouse 时代没有被替代,而是成为架构栈中的一层,向量数据库在 Vector Lakebase 中会成为内部的服务引擎(serving engine)。Milvus 3.0 beta 已经包含了新的 Loon 存储引擎,就是这条路线在开源侧的落地。
向量搜索架构三代演进
图:从向量数据库到 Vector Lakebase 的架构演进
2. CS/CD 飞轮:不只是检索,而是持续改进数据
Vector Lakebase 的核心理念叫 CS/CD(Continuous Serving / Continuous Discovery),这个缩写是有意借用了 CI/CD 的概念。
Serving 层做的是我们熟悉的事:高吞吐写入、低延迟检索,支撑在线 RAG、推荐、个性化、AI 记忆、实时 Agent。这部分是向量数据库的老本行。
Discovery 层做的事情就不一样了:聚类、去重、重嵌入、离线评估、质量分析、模型微调准备、Agent 轨迹分析。这些操作在传统向量数据库里基本做不到,或者得把数据导出来到 Spark/Ray 里跑。
关键在于,两者形成了一个飞轮:Serving 产生反馈和新数据 → Discovery 分析和改进数据 → 改进后的数据回流到 Serving。这个循环如果跑不起来,AI 系统就永远是个查询工具而不是持续改进的系统。
说实话,这个理念本身不算新鲜 - 数据飞轮的概念很多公司都在讲。但 Vector Lakebase 的意思是:如果你得在向量数据库和数据湖之间来回搬数据,这个飞轮根本转不起来。所以核心问题回到了架构层面。
3. 一份数据,三种计算:架构拆解
Vector Lakebase 的架构可以简化为三个层次:
存储层:基于 Loon 存储引擎和 Vortex 开放格式的统一湖存储。所有数据(向量、标量、文本、JSON、地理空间)存在一张湖表里,底层是 S3 对象存储。
索引层:索引不再是某个引擎的内部资产,而是湖级资产(lake-level asset)。向量索引、倒排索引、JSON 索引都可以独立构建、版本化、跨不同计算模式复用。
计算层:三种计算模式按需激活:
计算模式 | 用途 | 特点 |
|---|---|---|
Long-running | 在线 RAG、Agent 服务 | 常驻内存,个位数 ms 延迟 |
On-Demand | 低频查询、开发调试 | 按分钟计费,空闲零成本 |
Offline Batch | 聚类、去重、批量嵌入 | 共享 GPU 池,离线运行 |
这种设计的直接好处是资源跟着数据走,而不是跟着租户走。传统架构里,100 万个租户就需要 100 万组计算资源。Vector Lakebase 的控制平面通过共享 Coordinator、Catalog 替代 etcd、WAL 直写 S3(官方数据:750 MB/s,5.8 倍于 Kafka),把控制平面的复杂度从 O(N) 降到 O(1)。官方给出的数据是:100 万租户中通常只有 1% 同时活跃,意味着 99% 的数据零计算成本。
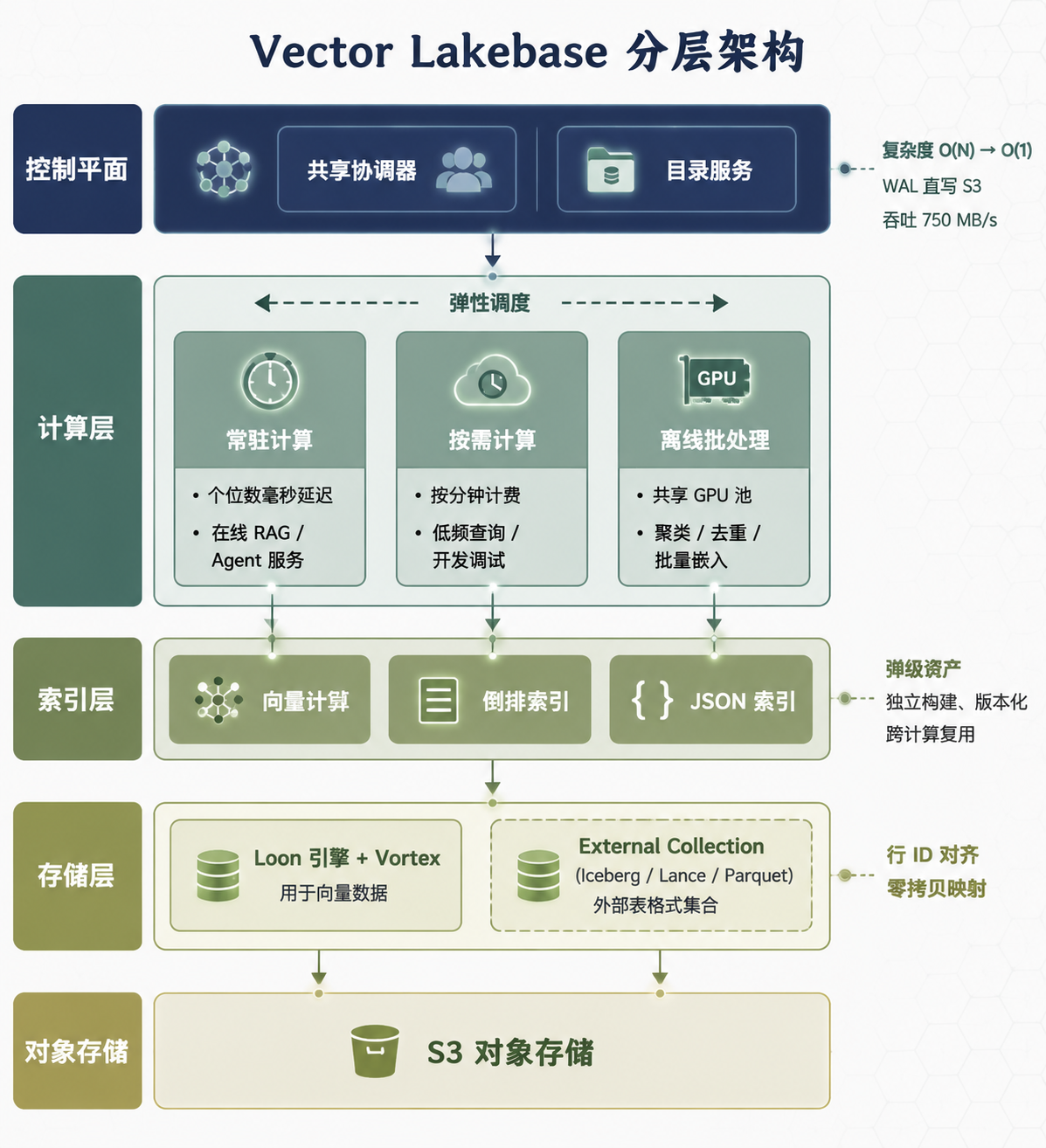
Vector Lakebase 五层架构图
图 1:Vector Lakebase 分层架构:控制平面 → 计算层(三种模式) → 索引层 → 存储层 → S3
4. Loon 存储引擎:混合格式 + 行 ID 对齐
Loon 是 Milvus 和 Vector Lakebase 的新存储引擎,Principal Engineer Ted Xu 在官方博客里详细讲了设计思路。它面对的是三个绕不开的问题:
问题一:长列导致写放大
AI 数据的列比传统分析表大得多。TPC-H lineitem 行约 150 字节,但 768 维 fp16 向量行就有 1.5 KB+,3072 维 fp32 向量(如 text-embedding-3-large)光向量就约 12 KB。如果要给 1 亿行数据加一个 1024 维 fp32 嵌入列,光原始向量数据就有约 400 GB。用传统方式重写整行?太慢了。
问题二:同一数据需要扫描和点查
分析负载需要宽的、压缩的扫描(Parquet 擅长),ANN 结果需要窄的、行级查找(Parquet 不擅长)。混合搜索一次查询可能同时需要两种模式。
问题三:数据集不只存在于一个引擎
AI 数据管道横跨 Spark、Ray、GPU 服务、LLM 推理管道。私有存储格式意味着真相的多份拷贝。
Loon 的三个设计决策
混合文件格式:标量字段用 Parquet(扫描/过滤/生态兼容),密集向量和稀疏向量用 Vortex(低延迟随机访问),原始对象(视频/PDF/图片)留在对象存储,数据库只存引用。
行 ID 对齐:每个物理 ColumnGroupFile 记录路径和行 ID 范围(start_index / end_index),不同 ColumnGroup 可以覆盖同一行 ID 空间,即使在不同文件和不同格式中。这意味着添加新的 embedding_v2 不需要重写原有的 caption、元数据或 embedding_v1。
Manifest 版本化:用 Apache Avro 编码的 Manifest 包含 ColumnGroups / DeltaLogs / Stats / Indexes 四个板块,支持乐观并发提交。外部引擎(Spark/Ray)可以生成新的 ColumnGroup 并提交 Manifest。这个思路和 Iceberg/Delta Lake 类似,但对象模型更广泛。
官方给出的基准测试数据(8 vCPU,本地文件系统,4 万行 128 维向量):
操作 | Vortex | Parquet | 差异 |
|---|---|---|---|
Take(K=1000 随机行) | 5.8 ms | 144 ms | 25 倍更快 |
全向量列扫描 | 21 ms | 142 ms | 6.76 倍更快 |
文件大小(~21 MB 原始) | 6.62 MB | 7.16 MB | 还小 7% |
有意思的是 Vortex 在压缩比上也没吃亏 - 反而比 Parquet 小 7%,点查还快 25 倍。原因是它不强制行组结构,布局完全可配置,支持 Delta → RLE → BitPacking 嵌套编码,压缩数据上就能直接做点查。
5. 两项关键优化:Vortex 读取和 RaBitQ 量化
Vortex:135 倍减少 S3 读取
Parquet 的 64 MB row group 在 S3 场景下是个大问题。如果你只需要读一条 3 KB 的记录,得先把 64 MB 的 row group 整个拉下来 - 大约 20000 倍的 I/O 浪费。
Vortex 的做法是把每次 S3 读取量从 Parquet 的 9.44 MB 压到 0.07 MB,减少 135 倍下载流量,而且没有 IOPS 惩罚。官方基准测试(3M 行 128 维向量,S3 存储,256 并发)的关键数据:
指标 | Parquet | Lance | Vortex |
|---|---|---|---|
点查吞吐(reads/s) | 162 | 464 | 620 |
每次 S3 读取量(MB) | 9.44 | 0.006 | 0.07 |
全扫描吞吐(MB/s) | 638 | 730 | 1,548 |
全扫描吞吐是 Parquet 的 2.4 倍。Vortex 是 Linux Foundation 托管的开放格式,不是 Zilliz 的私有格式 - 这一点对避免厂商锁定很关键。
RaBitQ:340 GB 压到 13 GB,冷启动 5 秒
RaBitQ 来自 SIGMOD 2024 论文(Gao & Long),核心是 1+3 bit 嵌套量化 - 类似俄罗斯套娃的结构。1-bit 层提供可证明的误差边界,用于粗过滤;3-bit 层后台下载,用于精排,召回率可达 95% 以上。
在 Zilliz 的实际应用中:340 GB 的 HNSW 索引经 1-bit 压缩后仅 13 GB,冷启动时间从 4 分钟以上降到 5-10 秒。再配合 IVF 聚类剪枝,每个查询只扫描约 3% 的数据,最终每次查询只需约 400 MB。
RaBitQ 不是只有 Zilliz 在用。faiss v1.11.0 已经集成了 RaBitQ;Elastic/Lucene 正在实验它作为更高量化级别的方案(GitHub issue #13650);阿里云 RDS PostgreSQL 中的 pgvector 也引入了 RaBitQ 量化。Elastic 团队的实验还发现:在相同压缩比下,RaBitQ 的召回率等于或优于 Product Quantization,量化速度快 20-30 倍。
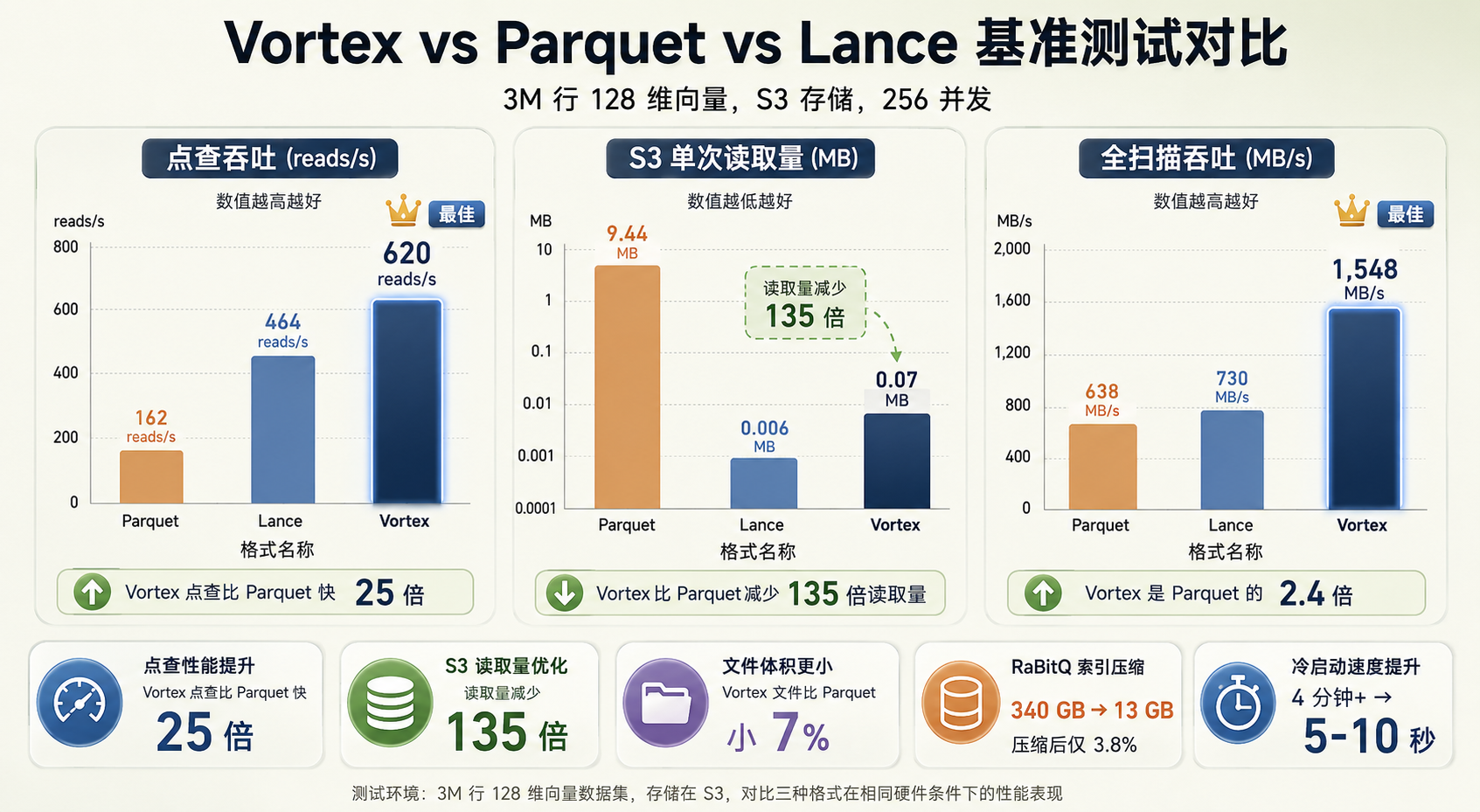
Vortex vs Parquet vs Lance 基准测试对比
图 2:Vortex vs Parquet vs Lance 基准测试对比——点查吞吐、S3 读取量、全扫描吞吐
6. 分层服务与成本优化
Vector Lakebase 提供三种服务层级:
层级 | QPS | 延迟 | 适用场景 |
|---|---|---|---|
性能优先层 | 1000+ | 个位数 ms | 生产 RAG、实时 Agent |
容量优化层 | 100-500 | <100 ms | 中等负载在线服务 |
分层存储层 | 10-50 | ~100 ms | 冷数据、归档查询 |
三个层级共享同一份数据,区别在于缓存命中率和计算资源配比。分层存储层官方给出的缓存命中率 >95%,这意味着大部分请求不会穿透到 S3。
但更值得关注的是 On-Demand Search。这是为大规模、低频查询场景设计的计算模式,按分钟计费,空闲时零成本。
回到开头那个自动驾驶客户的例子:10 亿条 768 维向量,每天只需约 20 分钟在线查询。
- Long-running 模式:约 $7,000/月
- On-Demand 模式:约 $500/月
省了 93%。
另一个对比数据更有说服力:同样是 10 亿向量 768 维、月累计 10 小时活跃计算的场景,Serverless 模式要 $4,937/月,On-Demand 只要 $318/月 - 大约是 Serverless 的 1/15。差距的核心在于 Serverless 按数据量和空闲计算收费,On-Demand 只按实际计算时间收费。
你的场景是低频查询还是高频常驻?这个选择对成本影响巨大。
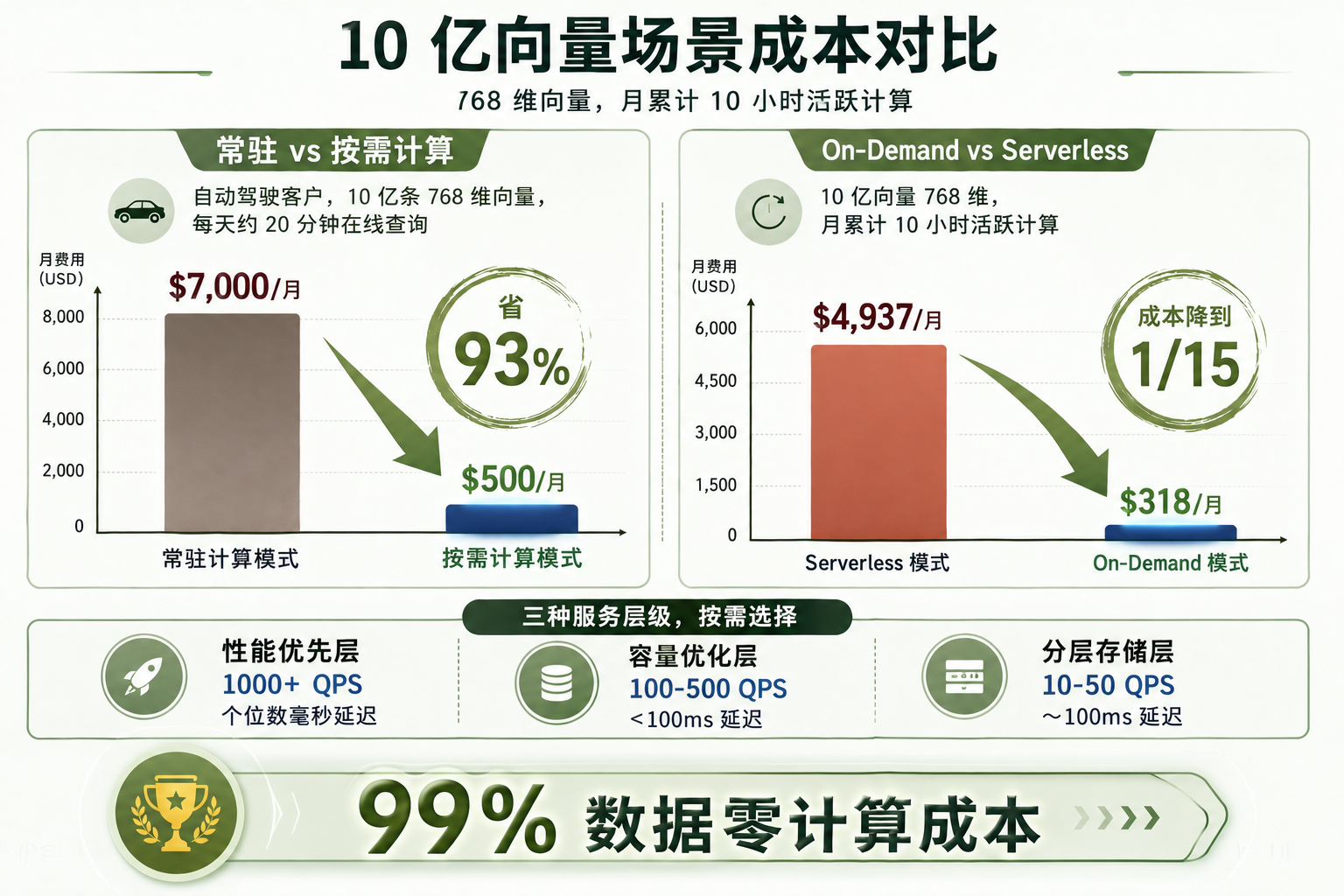
10 亿向量场景成本对比
图 3:10 亿向量场景成本对比——Long-running $7,000 → On-Demand $500(省 93%)、Serverless $4,937 → On-Demand $318(1/15)
7. External Collection:不搬数据,直接搜
External Collection 解决的是一个很实际的问题:很多公司的数据已经存在 Iceberg/Lance/Parquet 格式的数据湖里,搬不搬?
传统做法是把数据 ETL 到向量数据库里。问题是:数据冗余、同步延迟、还需要维护两套系统。
Vector Collection 的做法是零拷贝逻辑映射。它在外部数据之上构建独立的索引层(向量索引、倒排索引、JSON 索引),原始数据留在客户现有平台。支持增量同步。
官方的原则是 One Data. One Index. - 数据不搬家,索引跟着数据走。支持的湖表格式包括 Lance 和 Iceberg,开放数据格式包括 Parquet 和 Vortex。
不过,当前资料中未发现 External Collection 的具体性能数据和增量同步延迟数据,因此不做推断。如果同步延迟对你的场景很敏感,建议直接向 Zilliz 确认。
8. Full-Spectrum Search:不只是向量检索
Vector Lakebase 把自己定位为全谱检索(Full-Spectrum Search)平台,不仅限于向量相似度搜索。它支持:
- 向量检索(稠密 + 稀疏向量)
- 全文搜索(BM25 索引,支持短语查询、前缀匹配、模糊匹配、多种分词器)
- JSON 查询(JSON shredding 索引)
- 地理空间搜索
- 多向量搜索
- 多路径检索和重排序
重排序器支持 Cohere、Voyage AI、Boost、Decay、RRF、Weighted 等方案。宽表建模让每个 application-level entity 映射为单行,支持稠密/稀疏向量、文本、JSON、地理空间数据混合存储。
默认召回率在 95%-98% 之间,可调优至 90%-99%+。Schema evolution 支持 1 亿行数据回填在个位数分钟内完成(由平台侧共享计算资源处理)。Global Cluster 提供 99.99% uptime SLA。
这些指标看着漂亮,但要泼一盆冷水:这些都来自官方数据,Vector Lakebase 目前仍处于 Public Preview,还没有生产环境的大规模验证案例。
9. 和现有架构比,差异在哪?
Zilliz 官方把向量搜索架构分为三代:
维度 | 向量数据库 (Gen 1) | 向量湖 (Gen 2) | Vector Lakebase (Gen 3) |
|---|---|---|---|
数据源 | 自有存储 | 湖存储 | 湖存储(统一) |
在线服务 | 毫秒级 | 不支持或延迟高 | 毫秒级 |
离线发现 | 不支持 | 有限 | 原生支持 |
批量分析 | 不支持 | 支持 | 原生支持 |
索引 | 引擎内部 | 无或弱 | 湖级资产 |
数据拷贝 | 需要导入 | 无需 | 零拷贝 |
一个制药客户的实际数据能说明问题:分子相似性搜索中,Spark 暴力扫描比 IVF 索引检索慢约 1000 倍。还有一组去重性能数据:10 亿向量的近重复检测,用 ANN 逐条搜索需要 70 小时,用 Offline Batch Job 只需 10 小时。
那 Vector Lakebase 和 Databricks Lakebase 是什么关系?Zilliz 官方明确说是互补而非竞争:
维度 | Databricks Lakebase | Vector Lakebase |
|---|---|---|
目标用户 | 后端工程师、数据工程师 | ML 工程师、AI 平台团队 |
主要数据 | 行数据、账户、事务 | 嵌入、文档、多模态数据 |
存储模型 | Postgres + Delta Lake(分离) | 单一湖表,统一 |
批量嵌入/去重 | 不在范围内 | 一等公民操作 |
上下文工程 | 不在范围内 | 核心能力 |
Databricks Lakebase 解决的是结构化数据的 OLTP/OLAP 统一,Vector Lakebase 解决的是非结构化数据的在线服务/离线发现统一。两者面对的是不同的问题域。
不过有一个信息缺口:当前资料中没有 Vector Lakebase 与其他向量数据库(Pinecone、Weaviate、Qdrant)的直接性能对比数据,也没有 Vortex 格式的独立第三方基准测试。如果这些数据对你的选型很关键,建议关注后续社区评测。

向量搜索架构三代演进对比
图 4:向量搜索架构三代演进——Gen 1 向量数据库 → Gen 2 向量湖 → Gen 3 Vector Lakebase
10. 什么场景该考虑 Vector Lakebase?
根据官方给出的使用场景和案例,以下几类团队可能值得关注:
适合的场景:
- 数据规模达到十亿级,既有在线检索又有离线分析需求(如自动驾驶、基础模型训练、制药)
- 当前在向量数据库和数据湖之间做 ETL,数据同步成为瓶颈
- 低频查询场景下成本敏感(On-Demand 模式的成本优势明显)
- 需要对向量数据做聚类、去重、重嵌入等批量操作
- 数据已经存在 Iceberg/Lance 格式的湖里,不想搬迁
可能还不适合的场景:
- 数据规模在千万级以下,纯在线检索 - 这种场景用 Milvus 或其他向量数据库就够了
- 需要 OLTP 事务能力 - 这是 Databricks Lakebase 的领域
- 对生产稳定性要求极高 - Vector Lakebase 目前还在 Public Preview
还有几个当前无法确认的点(官方资料中未给出):具体定价细节和计费模型、Loon 在 Milvus 3.0 开源版中的功能范围与 Zilliz Cloud 商业版的差异、External Collection 的增量同步延迟。
总结
Vector Lakebase 的核心思路很清晰:一份数据,一个索引,多种计算模式。它不试图替代向量数据库,而是把向量数据库变成更大架构栈里的一层服务引擎。
技术栈上有三个亮点值得持续关注:Loon 的混合文件格式和行 ID 对齐解决了存算分离后的写放大问题;Vortex 开放格式把 S3 点查的 I/O 放大压了两个数量级;RaBitQ 量化让冷启动从分钟级降到秒级。
但话说回来,这些数据目前都来自 Zilliz 官方。Vector Lakebase 要证明自己,还得靠生产环境的验证和第三方基准测试。External Collection 的实际性能、增量同步的可靠性、大规模多租户下的稳定性——这些都需要时间来回答。
Milvus 作为全球 42k+ GitHub Stars 的开源向量数据库,Zilliz Cloud 已服务 10,000+ 组织,这个社区基础是 Vector Lakebase 的底气。但湖原生 AI 数据平台这个赛道才刚刚开始,Databricks、Snowflake 都不会袖手旁观。
我赌这个方向是对的 - AI 数据架构的下一站,大概率就是湖原生。但谁是最终的赢家,现在下结论还太早。
你的 AI 数据架构现在是什么形态?有没有遇到过数据在向量数据库和数据湖之间来回搬的痛点?评论区聊聊。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
相关资源
Zilliz 官网:https://zilliz.com/
Vector Lakebase 介绍:https://zilliz.com/blog/what-is-a-vector-lakebase
为什么推出 Vector Lakebase(CTO 栾小凡):https://zilliz.com/blog/why-we-built-vector-lakebase
Loon 存储引擎详解:https://zilliz.com/blog/why-we-built-loon-a-storage-engine-for-ai-data-that-never-stops-changing
Milvus 开源项目:https://github.com/milvus-io/milvus
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号