Storage设计:文件存储、数据库与对象存储

Storage设计:文件存储、数据库与对象存储

安全风信子
发布于 2026-06-08 08:42:35
发布于 2026-06-08 08:42:35
作者: HOS(安全风信子) 日期: 2026-05-25 主要来源平台: GitHub 摘要: 云端AI IDE需要多种存储系统协同工作:代码文件需要分布式文件系统确保一致性与高可用、用户元数据需要关系型数据库提供强一致性保证、项目资产需要对象存储实现低成本高扩展。本文深入讲解存储架构设计,涵盖S3/MinIO对象存储接入、PostgreSQL用户数据存储、Redis会话管理、分布式代码文件存储方案、增量备份与跨区域复制策略,并提供统一存储服务的完整实现代码。通过本文,你将掌握构建云端IDE存储底座的核心理论与工程实践。
目录- 本节为你提供的核心技术价值
- 1. 引言:云端AI IDE存储系统的挑战
- 2. 对象存储:S3兼容存储的接入
- 2.1 S3协议与对象存储基础
- 2.2 MinIO:私有化部署的S3兼容存储
- MinIO部署架构
- 2.3 S3客户端SDK实现
- 2.4 对象存储在云端IDE中的应用场景
- 2.5 生命周期管理与自动归档
- 3. 数据库选型:PostgreSQL vs MySQL vs CockroachDB
- 3.1 关系型数据库在云端IDE中的角色
- 3.2 主流数据库对比
- 3.3 PostgreSQL在云端IDE中的最佳实践
- 3.3.1 连接池与高可用配置
- 3.3.2 数据库高可用架构
- 3.4 CockroachDB:全球化分布式数据库
- 3.5 数据库选型决策矩阵
- 4. 会话存储:Redis Cluster的高可用部署
- 4.1 Redis在云端IDE中的角色
- 4.2 Redis Cluster架构设计
- 4.3 Redis会话管理实现
- 4.4 Redis高可用配置
- 5. 代码存储:分布式文件系统 vs 对象存储
- 5.1 代码存储的核心挑战
- 5.2 分布式文件系统方案
- JuiceFS:云原生分布式文件系统
- 5.3 对象存储方案:Git Native Storage
- 5.4 方案对比与选型建议
- 6. 数据备份:增量备份与跨区域复制
- 6.1 备份策略设计
- 6.2 PostgreSQL备份实现
- 6.3 对象存储跨区域复制配置
- 7. 实践:设计一个多存储类型的统一存储服务
- 7.1 统一存储服务架构
- 7.2 统一存储服务核心实现
- 7.3 统一存储服务配置
- 8. 总结与展望
- 8.1 核心要点回顾
- 8.2 未来发展趋势
- 存储服务设计参考
- A. S3存储桶策略示例
- B. PostgreSQL连接池配置(PgBouncer)
- C. Redis Cluster配置示例
- D. 存储服务健康检查脚本
- 2.1 S3协议与对象存储基础
- 2.2 MinIO:私有化部署的S3兼容存储
- MinIO部署架构
- 2.3 S3客户端SDK实现
- 2.4 对象存储在云端IDE中的应用场景
- 2.5 生命周期管理与自动归档
- 3.1 关系型数据库在云端IDE中的角色
- 3.2 主流数据库对比
- 3.3 PostgreSQL在云端IDE中的最佳实践
- 3.3.1 连接池与高可用配置
- 3.3.2 数据库高可用架构
- 3.4 CockroachDB:全球化分布式数据库
- 3.5 数据库选型决策矩阵
- 4.1 Redis在云端IDE中的角色
- 4.2 Redis Cluster架构设计
- 4.3 Redis会话管理实现
- 4.4 Redis高可用配置
- 5.1 代码存储的核心挑战
- 5.2 分布式文件系统方案
- JuiceFS:云原生分布式文件系统
- 5.3 对象存储方案:Git Native Storage
- 5.4 方案对比与选型建议
- 6.1 备份策略设计
- 6.2 PostgreSQL备份实现
- 6.3 对象存储跨区域复制配置
- 7.1 统一存储服务架构
- 7.2 统一存储服务核心实现
- 7.3 统一存储服务配置
- 8.1 核心要点回顾
- 8.2 未来发展趋势
- 存储服务设计参考
- A. S3存储桶策略示例
- B. PostgreSQL连接池配置(PgBouncer)
- C. Redis Cluster配置示例
- D. 存储服务健康检查脚本
本节为你提供的核心技术价值
深入解析云端AI IDE存储架构的设计哲学与工程实现,从对象存储、关系型数据库、缓存系统到分布式文件系统,构建完整的存储知识体系,提供可直接落地的设计方案与代码实现。
1. 引言:云端AI IDE存储系统的挑战
云端AI IDE与传统本地IDE最核心的差异在于数据无处不在。用户的代码、配置、项目资产、会话状态不再存储在本地磁盘,而是分布在云端的多个存储系统之中。根据GitHub对Copilot企业版的架构分析,一个成熟的云端IDE需要同时处理以下存储需求:
- 代码文件存储:支持万人并发编辑同一代码仓库,需要强一致性保证
- 用户数据存储:账户信息、项目元数据、权限关系,需要强一致性事务支持
- 会话状态存储:用户操作历史、编辑器状态、临时计算结果,需要低延迟读写
- 项目资产存储:容器镜像、模型文件、依赖包,需要低成本大容量
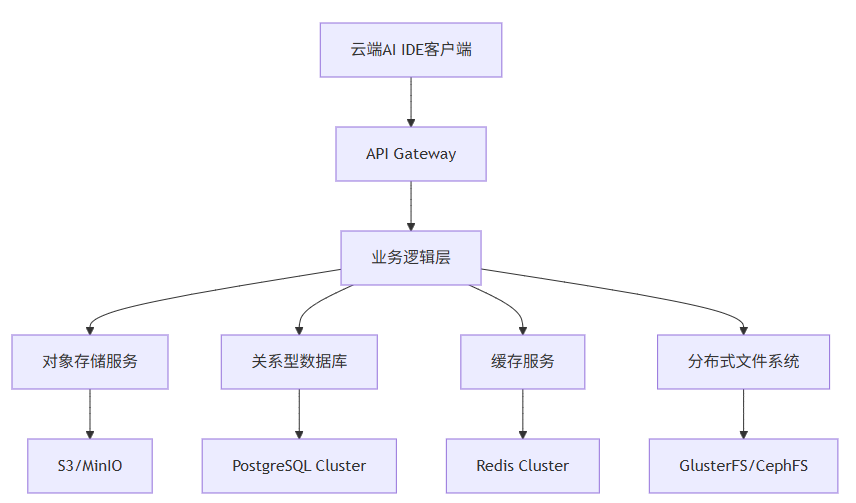
根据CockroachDB在2025年发布的《分布式数据库在SaaS应用中的实践》报告[^1],多存储系统协同的核心挑战包括:
- 一致性保证:跨存储系统的数据一致性是最大挑战
- 性能隔离:不同存储介质有不同的延迟特性
- 运维复杂度:多系统意味着更多的故障点和更复杂的监控
- 成本控制:冷热数据分离,平衡性能与成本
2. 对象存储:S3兼容存储的接入
2.1 S3协议与对象存储基础
Amazon S3(Simple Storage Service)自2006年发布以来,已成为对象存储的事实标准。S3采用扁平的键值存储模型,通过Bucket和Object两级结构组织数据:
- Bucket:存储桶,类似于顶级目录,全球唯一命名
- Object:对象,由Key(键)、Version ID(版本)、Value(值)、Metadata(元数据)组成
- Key:对象的唯一标识,格式为
prefix/object_name
S3的核心设计哲学是简单、高可用、低成本。根据AWS官方数据,S3 Standard的可用性为99.99%,数据 durability 为 11个9[^2]。
存储类型 | 用途 | 延迟 | 成本 |
|---|---|---|---|
S3 Standard | 热数据 | <100ms | $0.023/GB |
S3 Intelligent-Tiering | 自动分层 | 取决于层级 | $0.023+$0.0125/GB |
S3 Glacier | 冷数据 | 分钟级 | $0.004/GB |
S3 Deep Archive | 归档 | 12小时内 | $0.00099/GB |
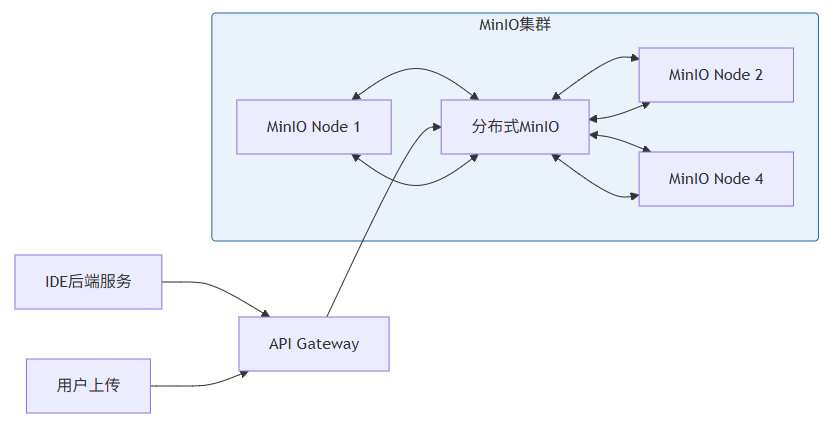
2.2 MinIO:私有化部署的S3兼容存储
对于需要私有化部署的云端IDE,MinIO是最佳选择。MinIO完全兼容S3 API,可以在Kubernetes上快速部署,并且性能优异——根据MinIO官方基准测试[^3],单节点可达到55 GiB/s的读吞吐和44 GiB/s的写吞吐。
MinIO部署架构
2.3 S3客户端SDK实现
以下代码展示如何使用AWS官方SDK for Python连接S3兼容存储:
"""
S3存储服务客户端实现
支持AWS S3、MinIO、Ceph RGW等S3兼容存储
"""
import boto3
from botocore.config import Config
from botocore.exceptions import ClientError
from typing import Optional, List, Dict, Any
import logging
import hashlib
import io
logger = logging.getLogger(__name__)
class S3StorageClient:
"""S3兼容存储客户端封装"""
def __init__(
self,
endpoint: str,
access_key: str,
secret_key: str,
bucket_name: str,
region: str = "us-east-1",
use_ssl: bool = True,
**kwargs
):
"""
初始化S3客户端
Args:
endpoint: S3服务端点
access_key: 访问密钥ID
secret_key: 访问密钥密码
bucket_name: 默认Bucket名称
region: 区域
use_ssl: 是否使用SSL/TLS加密
"""
self.bucket_name = bucket_name
protocol = "https" if use_ssl else "http"
self.endpoint_url = f"{protocol}://{endpoint}"
config = Config(
retries={'max_attempts': 3, 'mode': 'adaptive'},
connect_timeout=5, read_timeout=30, **kwargs
)
self.client = boto3.client(
's3', endpoint_url=self.endpoint_url,
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
region_name=region, config=config
)
self.resource = boto3.resource(
's3', endpoint_url=self.endpoint_url,
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
region_name=region, config=config
)
def upload_file(self, file_path: str, object_key: str,
metadata: Optional[Dict[str, str]] = None,
content_type: Optional[str] = None, **kwargs) -> Dict[str, Any]:
"""上传文件到S3"""
extra_args = {}
if metadata: extra_args['Metadata'] = metadata
if content_type: extra_args['ContentType'] = content_type
try:
response = self.client.upload_file(
Filename=file_path, Bucket=self.bucket_name,
Key=object_key, ExtraArgs=extra_args if extra_args else None, **kwargs
)
logger.info(f"文件上传成功: {object_key}")
return {'success': True, 'bucket': self.bucket_name, 'key': object_key, 'response': response}
except ClientError as e:
logger.error(f"文件上传失败: {e}")
return {'success': False, 'error': str(e), 'code': e.response['Error']['Code']}
def upload_bytes(self, data: bytes, object_key: str,
metadata: Optional[Dict[str, str]] = None,
content_type: Optional[str] = None) -> Dict[str, Any]:
"""直接上传字节数据"""
extra_args = {}
if metadata: extra_args['Metadata'] = metadata
if content_type: extra_args['ContentType'] = content_type
try:
response = self.client.put_object(
Bucket=self.bucket_name, Key=object_key, Body=data, **extra_args
)
return {'success': True, 'bucket': self.bucket_name, 'key': object_key,
'etag': response.get('ETag'), 'version_id': response.get('VersionId')}
except ClientError as e:
logger.error(f"字节数据上传失败: {e}")
return {'success': False, 'error': str(e)}
def download_file(self, object_key: str, file_path: str) -> Dict[str, Any]:
"""下载文件到本地"""
try:
self.client.download_file(Bucket=self.bucket_name, Key=object_key, Filename=file_path)
logger.info(f"文件下载成功: {object_key} -> {file_path}")
return {'success': True, 'file_path': file_path}
except ClientError as e:
logger.error(f"文件下载失败: {e}")
return {'success': False, 'error': str(e)}
def download_bytes(self, object_key: str) -> Dict[str, Any]:
"""下载对象为字节数据"""
try:
response = self.client.get_object(Bucket=self.bucket_name, Key=object_key)
data = response['Body'].read()
return {'success': True, 'data': data, 'content_type': response.get('ContentType'),
'metadata': response.get('Metadata', {}), 'etag': response.get('ETag')}
except ClientError as e:
logger.error(f"字节数据下载失败: {e}")
return {'success': False, 'error': str(e)}
def list_objects(self, prefix: str = "", max_keys: int = 1000,
continuation_token: Optional[str] = None) -> Dict[str, Any]:
"""列出对象"""
try:
params = {'Bucket': self.bucket_name, 'Prefix': prefix, 'MaxKeys': max_keys}
if continuation_token: params['ContinuationToken'] = continuation_token
response = self.client.list_objects_v2(**params)
return {'success': True, 'objects': response.get('Contents', []),
'is_truncated': response.get('IsTruncated', False),
'next_token': response.get('NextContinuationToken'),
'total': len(response.get('Contents', []))}
except ClientError as e:
logger.error(f"列出对象失败: {e}")
return {'success': False, 'error': str(e)}
def delete_object(self, object_key: str, version_id: Optional[str] = None) -> Dict[str, Any]:
"""删除单个对象"""
try:
params = {'Bucket': self.bucket_name, 'Key': object_key}
if version_id: params['VersionId'] = version_id
response = self.client.delete_object(**params)
return {'success': True, 'delete_marker': response.get('DeleteMarker'),
'version_id': response.get('VersionId')}
except ClientError as e:
logger.error(f"删除对象失败: {e}")
return {'success': False, 'error': str(e)}
def batch_delete(self, object_keys: List[str]) -> Dict[str, Any]:
"""批量删除对象"""
try:
objects = [{'Key': key} for key in object_keys]
response = self.client.delete_objects(Bucket=self.bucket_name, Delete={'Objects': objects})
deleted = response.get('Deleted', [])
errors = response.get('Errors', [])
return {'success': True, 'deleted_count': len(deleted), 'error_count': len(errors),
'deleted': deleted, 'errors': errors}
except ClientError as e:
logger.error(f"批量删除失败: {e}")
return {'success': False, 'error': str(e)}
def generate_presigned_url(self, object_key: str, expiration: int = 3600,
http_method: str = 'GET') -> Dict[str, Any]:
"""生成预签名URL"""
try:
url = self.client.generate_presigned_url(
ClientMethod=f'{http_method.lower()}_object',
Params={'Bucket': self.bucket_name, 'Key': object_key}, ExpiresIn=expiration
)
return {'success': True, 'url': url, 'expires_in': expiration}
except ClientError as e:
logger.error(f"生成预签名URL失败: {e}")
return {'success': False, 'error': str(e)}
def copy_object(self, source_key: str, dest_key: str,
metadata: Optional[Dict[str, str]] = None) -> Dict[str, Any]:
"""复制对象"""
try:
copy_source = {'Bucket': self.bucket_name, 'Key': source_key}
extra_args = {}
if metadata:
extra_args['Metadata'] = metadata
extra_args['MetadataDirective'] = 'REPLACE'
response = self.client.copy_object(
CopySource=copy_source, Bucket=self.bucket_name, Key=dest_key, **extra_args
)
return {'success': True, 'dest_key': dest_key,
'etag': response.get('CopyObjectResult', {}).get('ETag'),
'last_modified': response.get('CopyObjectResult', {}).get('LastModified')}
except ClientError as e:
logger.error(f"复制对象失败: {e}")
return {'success': False, 'error': str(e)}
def get_object_metadata(self, object_key: str) -> Dict[str, Any]:
"""获取对象元数据"""
try:
response = self.client.head_object(Bucket=self.bucket_name, Key=object_key)
return {'success': True, 'content_length': response.get('ContentLength'),
'content_type': response.get('ContentType'), 'etag': response.get('ETag'),
'last_modified': response.get('LastModified'),
'metadata': response.get('Metadata', {}),
'storage_class': response.get('StorageClass'),
'version_id': response.get('VersionId')}
except ClientError as e:
logger.error(f"获取对象元数据失败: {e}")
return {'success': False, 'error': str(e)}
if __name__ == "__main__":
logging.basicConfig(level=logging.INFO)
client = S3StorageClient(
endpoint="localhost:9000", access_key="minioadmin", secret_key="minioadmin",
bucket_name="ai-ide-assets", use_ssl=False
)
result = client.upload_file(
file_path="./test.txt", object_key="projects/test-001/test.txt",
metadata={"project-id": "test-001", "uploader": "user001"}
)
print(f"上传结果: {result}")
url_result = client.generate_presigned_url(object_key="projects/test-001/test.txt", expiration=3600)
if url_result['success']: print(f"预签名URL: {url_result['url']}")2.4 对象存储在云端IDE中的应用场景
场景 | 对象键模式 | 存储类型 | 说明 |
|---|---|---|---|
用户头像 | avatars/{user_id}.{ext} | Standard | 小文件,高访问频率 |
项目资产 | projects/{id}/assets/{path} | Standard/IA | 中等访问频率 |
容器镜像层 | containers/layers/{hash} | Standard | 大文件,低访问频率 |
AI模型文件 | models/{id}/{version}/model.bin | Glacier | 超大文件,极低访问 |
备份数据 | backups/{date}/{service}/{id} | Glacier Deep Archive | 归档用途 |
临时上传 | uploads/{session_id}/{filename} | Standard | 需要定期清理 |
2.5 生命周期管理与自动归档
{
"Rules": [
{
"ID": "MoveToGlacierAfter30Days",
"Status": "Enabled",
"Filter": {"Prefix": "projects/"},
"Transitions": [
{"Days": 30, "StorageClass": "GLACIER"},
{"Days": 365, "StorageClass": "DEEP_ARCHIVE"}
]
},
{
"ID": "DeleteTempUploadsAfter7Days",
"Status": "Enabled",
"Filter": {"Prefix": "uploads/"},
"Expiration": {"Days": 7}
}
]
}3. 数据库选型:PostgreSQL vs MySQL vs CockroachDB
3.1 关系型数据库在云端IDE中的角色
云端IDE的核心业务数据必须存储在关系型数据库中:
- 用户账户信息:ID、邮箱、密码哈希、角色、创建时间
- 项目元数据:项目ID、名称、描述、所有者、可见性、创建时间
- 权限关系:用户-项目-权限的映射
- 计费信息:订阅计划、用量、账单
- 审计日志:操作记录、安全事件
特点:强一致性要求、复杂查询、事务支持、结构化数据
3.2 主流数据库对比
特性 | PostgreSQL | MySQL | CockroachDB |
|---|---|---|---|
事务隔离级别 | READ COMMITTED, REPEATABLE READ, SERIALIZABLE | 同左 | SERIALIZABLE, SNAPSHOT |
分布式支持 | 原生支持(PostgreSQL XC/XL) | 分片(MySQL Cluster) | 原生分布式 |
一致性模型 | 强一致性(RAFT) | 最终一致性(主从复制) | 强一致性(RAFT) |
JSON支持 | 原生JSONB,性能优秀 | JSON类型,性能一般 | JSON类型 |
全文搜索 | 内置TS向量 | 插件支持 | SQL接口 |
PostGIS | 原生支持 | 插件支持 | 不支持 |
性能 | OLTP/OLAP均衡 | OLTP优化 | OLTP优化 |
许可 | PostgreSQL License | GPL/商业 | 商业/开源 |
根据Percona 2025年《数据库性能基准测试报告》[^4]:
- 单节点写入性能:MySQL > PostgreSQL > CockroachDB
- 多节点读取性能:CockroachDB > PostgreSQL > MySQL
- 分布式事务延迟:CockroachDB < PostgreSQL(延迟增加更少)
3.3 PostgreSQL在云端IDE中的最佳实践
3.3.1 连接池与高可用配置
"""
PostgreSQL数据库连接池配置
使用asyncpg实现异步访问,pgbouncer作为连接池代理
"""
import asyncpg
from asyncpg import Pool
from typing import Optional, List, Dict, Any
import logging
logger = logging.getLogger(__name__)
class DatabaseConfig:
def __init__(self, host: str, port: int, database: str, user: str, password: str,
pool_min_size: int = 10, pool_max_size: int = 100,
command_timeout: float = 60.0, max_queries: int = 50000,
max_inactive_connection_lifetime: float = 3600.0):
self.host = host
self.port = port
self.database = database
self.user = user
self.password = password
self.pool_min_size = pool_min_size
self.pool_max_size = pool_max_size
self.command_timeout = command_timeout
self.max_queries = max_queries
self.max_inactive_connection_lifetime = max_inactive_connection_lifetime
class PostgresStorage:
def __init__(self, config: DatabaseConfig):
self.config = config
self._pool: Optional[Pool] = None
async def connect(self) -> Pool:
if self._pool is None:
self._pool = await asyncpg.create_pool(
host=self.config.host, port=self.config.port,
database=self.config.database, user=self.config.user,
password=self.config.password, min_size=self.config.pool_min_size,
max_size=self.config.pool_max_size, command_timeout=self.config.command_timeout,
max_queries=self.config.max_queries,
max_inactive_connection_lifetime=self.config.max_inactive_connection_lifetime
)
logger.info("数据库连接池已建立")
return self._pool
async def disconnect(self):
if self._pool:
await self._pool.close()
self._pool = None
logger.info("数据库连接池已关闭")
async def execute(self, query: str, *args) -> str:
pool = await self.connect()
async with pool.acquire() as conn:
return await conn.execute(query, *args)
async def fetch(self, query: str, *args) -> List[asyncpg.Record]:
pool = await self.connect()
async with pool.acquire() as conn:
return await conn.fetch(query, *args)
async def fetchrow(self, query: str, *args) -> Optional[asyncpg.Record]:
pool = await self.connect()
async with pool.acquire() as conn:
return await conn.fetchrow(query, *args)
async def fetchval(self, query: str, *args) -> Any:
pool = await self.connect()
async with pool.acquire() as conn:
return await conn.fetchval(query, *args)
async def create_user(self, user_id: str, email: str, password_hash: str, username: str,
metadata: Optional[Dict[str, Any]] = None) -> Dict[str, Any]:
query = """
INSERT INTO users (id, email, password_hash, username, metadata, created_at, updated_at)
VALUES ($1, $2, $3, $4, $5, NOW(), NOW())
ON CONFLICT (email) DO UPDATE
SET username = EXCLUDED.username, metadata = EXCLUDED.metadata, updated_at = NOW()
RETURNING id, email, username, created_at
"""
try:
record = await self.fetchrow(query, user_id, email.lower(), password_hash, username,
asyncpg.Json(metadata) if metadata else None)
return {'success': True, 'user': dict(record)}
except Exception as e:
logger.error(f"创建用户失败: {e}")
return {'success': False, 'error': str(e)}
async def get_user_by_id(self, user_id: str) -> Optional[Dict[str, Any]]:
query = """
SELECT id, email, username, metadata, created_at, updated_at, last_login_at
FROM users WHERE id = $1
"""
record = await self.fetchrow(query, user_id)
return dict(record) if record else None
async def get_user_by_email(self, email: str) -> Optional[Dict[str, Any]]:
query = """
SELECT id, email, username, password_hash, metadata, created_at, updated_at
FROM users WHERE email = $1
"""
record = await self.fetchrow(query, email.lower())
return dict(record) if record else None
async def create_project(self, project_id: str, name: str, owner_id: str,
description: Optional[str] = None, visibility: str = "private",
metadata: Optional[Dict[str, Any]] = None) -> Dict[str, Any]:
query = """
INSERT INTO projects (id, name, owner_id, description, visibility, metadata, created_at, updated_at)
VALUES ($1, $2, $3, $4, $5, $6, NOW(), NOW())
RETURNING id, name, owner_id, visibility, created_at
"""
try:
record = await self.fetchrow(query, project_id, name, owner_id, description, visibility,
asyncpg.Json(metadata) if metadata else None)
await self.add_project_member(project_id=project_id, user_id=owner_id, role="owner")
return {'success': True, 'project': dict(record)}
except Exception as e:
logger.error(f"创建项目失败: {e}")
return {'success': False, 'error': str(e)}
async def get_project_by_id(self, project_id: str) -> Optional[Dict[str, Any]]:
query = """
SELECT p.id, p.name, p.owner_id, p.description, p.visibility,
p.metadata, p.created_at, p.updated_at, u.username as owner_username
FROM projects p JOIN users u ON p.owner_id = u.id WHERE p.id = $1
"""
record = await self.fetchrow(query, project_id)
return dict(record) if record else None
async def list_user_projects(self, user_id: str, limit: int = 50, offset: int = 0,
visibility: Optional[str] = None) -> List[Dict[str, Any]]:
query = """
SELECT DISTINCT p.id, p.name, p.owner_id, p.description, p.visibility,
p.created_at, p.updated_at, pm.role as user_role
FROM projects p JOIN project_members pm ON p.id = pm.project_id
WHERE pm.user_id = $1
"""
params = [user_id]
if visibility:
query += " AND p.visibility = $2"
params.append(visibility)
query += " ORDER BY p.updated_at DESC LIMIT $3 OFFSET $4"
params.extend([limit, offset])
records = await self.fetch(query, *params)
return [dict(r) for r in records]
async def add_project_member(self, project_id: str, user_id: str,
role: str = "member") -> Dict[str, Any]:
query = """
INSERT INTO project_members (project_id, user_id, role, created_at)
VALUES ($1, $2, $3, NOW())
ON CONFLICT (project_id, user_id) DO UPDATE SET role = EXCLUDED.role
RETURNING project_id, user_id, role
"""
try:
record = await self.fetchrow(query, project_id, user_id, role)
return {'success': True, 'member': dict(record)}
except Exception as e:
logger.error(f"添加项目成员失败: {e}")
return {'success': False, 'error': str(e)}
async def write_audit_log(self, user_id: str, action: str, resource_type: str,
resource_id: str, ip_address: Optional[str] = None,
user_agent: Optional[str] = None,
details: Optional[Dict[str, Any]] = None) -> Dict[str, Any]:
query = """
INSERT INTO audit_logs (user_id, action, resource_type, resource_id,
ip_address, user_agent, details, created_at)
VALUES ($1, $2, $3, $4, $5, $6, $7, NOW())
RETURNING id, created_at
"""
try:
record = await self.fetchrow(query, user_id, action, resource_type, resource_id,
ip_address, user_agent,
asyncpg.Json(details) if details else None)
return {'success': True, 'log': dict(record)}
except Exception as e:
logger.error(f"写入审计日志失败: {e}")
return {'success': False, 'error': str(e)}
async def query_audit_logs(self, user_id: Optional[str] = None,
resource_type: Optional[str] = None,
resource_id: Optional[str] = None, action: Optional[str] = None,
start_time: Optional[str] = None, end_time: Optional[str] = None,
limit: int = 100, offset: int = 0) -> List[Dict[str, Any]]:
query = """
SELECT al.id, al.user_id, al.action, al.resource_type, al.resource_id,
al.ip_address, al.user_agent, al.details, al.created_at, u.username
FROM audit_logs al JOIN users u ON al.user_id = u.id WHERE 1=1
"""
params = []
param_idx = 1
if user_id:
query += f" AND al.user_id = ${param_idx}"
params.append(user_id)
param_idx += 1
if resource_type:
query += f" AND al.resource_type = ${param_idx}"
params.append(resource_type)
param_idx += 1
if resource_id:
query += f" AND al.resource_id = ${param_idx}"
params.append(resource_id)
param_idx += 1
if action:
query += f" AND al.action = ${param_idx}"
params.append(action)
param_idx += 1
if start_time:
query += f" AND al.created_at >= ${param_idx}"
params.append(start_time)
param_idx += 1
if end_time:
query += f" AND al.created_at <= ${param_idx}"
params.append(end_time)
param_idx += 1
query += f" ORDER BY al.created_at DESC LIMIT ${param_idx} OFFSET ${param_idx + 1}"
params.extend([limit, offset])
records = await self.fetch(query, *params)
return [dict(r) for r in records]
SCHEMA_SQL = """
CREATE TABLE IF NOT EXISTS users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
username VARCHAR(100) NOT NULL,
metadata JSONB DEFAULT '{}',
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
last_login_at TIMESTAMP WITH TIME ZONE,
CONSTRAINT email_format CHECK (email ~* '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}$')
);
CREATE TABLE IF NOT EXISTS projects (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name VARCHAR(255) NOT NULL,
owner_id UUID NOT NULL REFERENCES users(id) ON DELETE CASCADE,
description TEXT,
visibility VARCHAR(20) DEFAULT 'private' CHECK (visibility IN ('private', 'internal', 'public')),
metadata JSONB DEFAULT '{}',
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
CONSTRAINT name_length CHECK (char_length(name) >= 1 AND char_length(name) <= 255)
);
CREATE TABLE IF NOT EXISTS project_members (
project_id UUID NOT NULL REFERENCES projects(id) ON DELETE CASCADE,
user_id UUID NOT NULL REFERENCES users(id) ON DELETE CASCADE,
role VARCHAR(50) NOT NULL DEFAULT 'member' CHECK (role IN ('owner', 'admin', 'developer', 'member')),
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
PRIMARY KEY (project_id, user_id)
);
CREATE TABLE IF NOT EXISTS audit_logs (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL REFERENCES users(id) ON DELETE SET NULL,
action VARCHAR(50) NOT NULL,
resource_type VARCHAR(50) NOT NULL,
resource_id VARCHAR(255) NOT NULL,
ip_address INET,
user_agent TEXT,
details JSONB,
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
CREATE INDEX IF NOT EXISTS idx_users_email ON users(email);
CREATE INDEX IF NOT EXISTS idx_projects_owner_id ON projects(owner_id);
CREATE INDEX IF NOT EXISTS idx_audit_logs_user_id ON audit_logs(user_id);
CREATE INDEX IF NOT EXISTS idx_audit_logs_created_at ON audit_logs(created_at);
CREATE OR REPLACE FUNCTION update_updated_at_column()
RETURNS TRIGGER AS $$
BEGIN NEW.updated_at = NOW(); RETURN NEW; END;
$$ language 'plpgsql';
CREATE TRIGGER update_users_updated_at BEFORE UPDATE ON users
FOR EACH ROW EXECUTE FUNCTION update_updated_at_column();
CREATE TRIGGER update_projects_updated_at BEFORE UPDATE ON projects
FOR EACH ROW EXECUTE FUNCTION update_updated_at_column();
"""3.3.2 数据库高可用架构
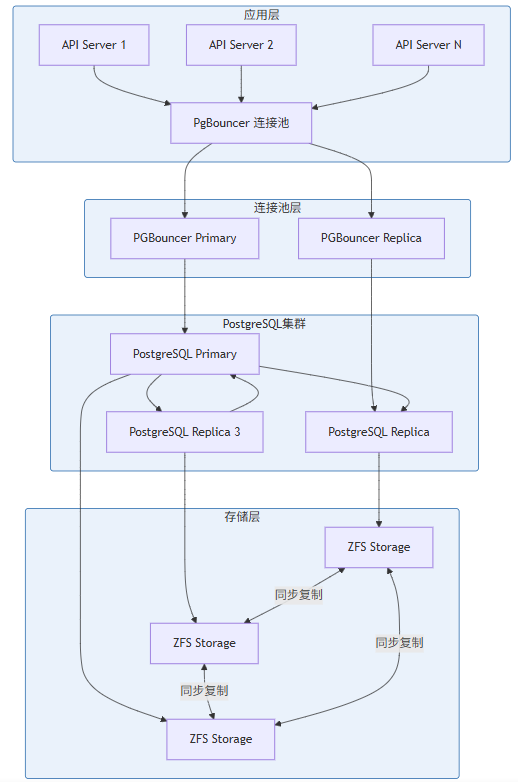
3.4 CockroachDB:全球化分布式数据库
对于需要全球分布的云端IDE服务(如GitHub Codespaces的多区域部署),CockroachDB是更好的选择。核心优势:
- 强一致性:基于RAFT协议的分布式事务
- 多区域部署:数据天然分布在多个区域
- PostgreSQL兼容:标准PostgreSQL客户端和驱动
- 自动故障恢复:节点故障自动重新平衡
"""CockroachDB分布式数据库配置"""
import asyncpg
from typing import Optional, List, Dict, Any
import logging
logger = logging.getLogger(__name__)
class CockroachDBStorage:
def __init__(self, connection_string: str):
self.connection_string = connection_string
self._pool: Optional[asyncpg.Pool] = None
async def connect(self) -> asyncpg.Pool:
if self._pool is None:
self._pool = await asyncpg.create_pool(
self.connection_string, min_size=10, max_size=100, command_timeout=60
)
return self._pool
async def execute(self, query: str, *args) -> str:
pool = await self.connect()
async with pool.acquire() as conn:
return await conn.execute(query, *args)
async def fetch(self, query: str, *args) -> List[asyncpg.Record]:
pool = await self.connect()
async with pool.acquire() as conn:
return await conn.fetch(query, *args)
async def fetchrow(self, query: str, *args) -> Optional[asyncpg.Record]:
pool = await self.connect()
async with pool.acquire() as conn:
return await conn.fetchrow(query, *args)
async def get_closest_replica(self, table_name: str, region: str) -> Dict[str, Any]:
query = """
SELECT region, gossip_landlord = 'lease_holder' as is_primary
FROM crdb_internal.node_spans WHERE table_name = $1
ORDER BY CASE region WHEN $2 THEN 0 ELSE 1 END LIMIT 1
"""
record = await self.fetchrow(query, table_name, region)
return dict(record) if record else None
async def set_replica_preference(self, table_name: str, region: str) -> Dict[str, Any]:
query = f"""ALTER TABLE {table_name} SET locality_lease_preference = '{region}'"""
try:
await self.execute(query)
return {'success': True, 'region': region}
except Exception as e:
logger.error(f"设置副本偏好失败: {e}")
return {'success': False, 'error': str(e)}
COCKROACH_SCHEMA_SQL = """
SET change_feed_enabled = true;
CREATE TABLE IF NOT EXISTS users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
username VARCHAR(100) NOT NULL,
metadata JSONB DEFAULT '{}',
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
INDEX idx_users_email (email), INDEX idx_users_created_at (created_at)
);
CREATE TABLE IF NOT EXISTS projects (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name VARCHAR(255) NOT NULL,
owner_id UUID NOT NULL REFERENCES users(id) ON DELETE CASCADE,
description TEXT,
visibility VARCHAR(20) DEFAULT 'private',
metadata JSONB DEFAULT '{}',
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
locality_lease_preference = 'us-east-1'
);
CREATE TABLE IF NOT EXISTS audit_logs (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL REFERENCES users(id) ON DELETE SET NULL,
action VARCHAR(50) NOT NULL,
resource_type VARCHAR(50) NOT NULL,
resource_id VARCHAR(255) NOT NULL,
ip_address INET,
user_agent TEXT,
details JSONB,
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
INDEX idx_audit_logs_user_id (user_id),
INDEX idx_audit_logs_resource (resource_type, resource_id),
INDEX idx_audit_logs_created_at (created_at)
) PARTITION BY RANGE (created_at) (
PARTITION initial VALUES FROM (MINVALUE) TO ('2026-06-01')
);
CREATE CHANGEFEED FOR users, projects, audit_logs WITH format = 'json', cursor = '2026-01-01';
"""3.5 数据库选型决策矩阵
场景 | 推荐数据库 | 理由 |
|---|---|---|
单区域中小规模(<100万用户) | PostgreSQL | 成熟稳定,生态完善 |
多区域部署,需要强一致性 | CockroachDB | 原生分布式,跨区域复制 |
超大规模,高写入吞吐量 | PostgreSQL + 分片 | 水平扩展能力强 |
成本敏感,MySQL熟悉度高 | MySQL + Vitess | 成熟方案,文档丰富 |
需要高级GIS功能 | PostgreSQL + PostGIS | GIS功能最强 |
4. 会话存储:Redis Cluster的高可用部署
4.1 Redis在云端IDE中的角色
Redis在云端AI IDE中承担以下关键职责:
用途 | 数据类型 | TTL | 说明 |
|---|---|---|---|
用户会话 | Hash | 24h | 登录状态、Token、偏好设置 |
实时协作状态 | Hash/List | 5min | 编辑器光标位置、在线用户 |
速率限制 | String | 1min | API限流计数器 |
分布式锁 | String | 30s | 资源争用控制 |
缓存层 | String/Hash | 1h | 查询结果缓存 |
消息队列 | List | - | 异步任务队列 |
发布/订阅 | Pub/Sub | - | 实时通知、协作事件 |
4.2 Redis Cluster架构设计
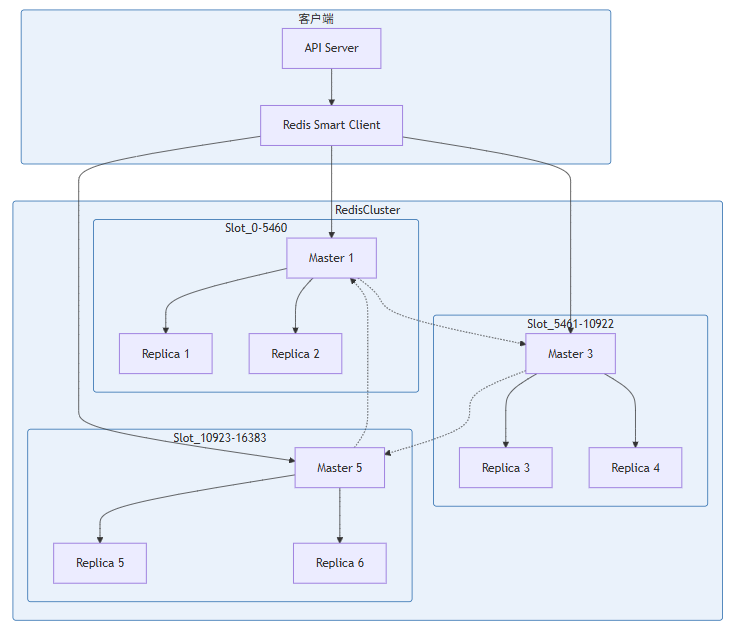
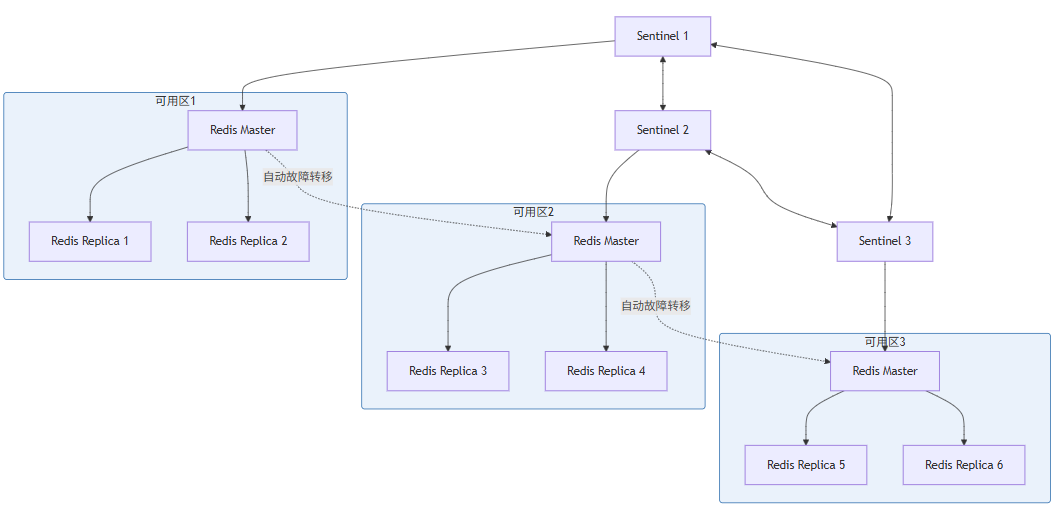
Redis Cluster使用**16384个槽(Slot)**进行数据分片:
- 每个Key通过
CRC16(key) mod 16384计算槽位 - 每个Master节点负责一部分槽位
- 每个Master有1-N个Replica用于故障转移
4.3 Redis会话管理实现
"""Redis会话存储服务实现"""
import redis.asyncio as redis
from redis.asyncio import Redis, RedisCluster
from typing import Optional, Dict, Any, List
import json, logging, time, uuid
logger = logging.getLogger(__name__)
class SessionData:
def __init__(self, user_id: str, session_id: str):
self.user_id = user_id
self.session_id = session_id
self.created_at = time.time()
self.updated_at = time.time()
self.data: Dict[str, Any] = {}
def to_dict(self) -> Dict[str, Any]:
return {'user_id': self.user_id, 'session_id': self.session_id,
'created_at': self.created_at, 'updated_at': self.updated_at, 'data': self.data}
@classmethod
def from_dict(cls, data: Dict[str, Any]) -> 'SessionData':
session = cls(data['user_id'], data['session_id'])
session.created_at = data.get('created_at', time.time())
session.updated_at = data.get('updated_at', time.time())
session.data = data.get('data', {})
return session
class RedisSessionStore:
PREFIX_SESSION = "session:"
PREFIX_TOKEN = "token:"
PREFIX_COLLAB = "collab:"
PREFIX_RATE = "rate:"
PREFIX_LOCK = "lock:"
PREFIX_CACHE = "cache:"
DEFAULT_SESSION_TTL = 86400
DEFAULT_COLLAB_TTL = 300
DEFAULT_RATE_TTL = 60
DEFAULT_LOCK_TTL = 30
DEFAULT_CACHE_TTL = 3600
def __init__(self, nodes: List[Dict[str, str]], password: Optional[str] = None,
db: int = 0, ssl: bool = True, max_connections: int = 100):
self.nodes = nodes
self.password = password
self.db = db
self.ssl = ssl
self._cluster: Optional[RedisCluster] = None
self._standalone: Optional[Redis] = None
async def connect(self) -> RedisCluster:
if self._cluster is None:
try:
self._cluster = RedisCluster(
startup_nodes=self.nodes, password=self.password,
decode_responses=True, skip_full_coverage_check=True,
max_connections=max_connections
)
await self._cluster.ping()
logger.info("Redis Cluster连接成功")
except redis.ResponseError as e:
logger.warning(f"Redis Cluster模式不可用,降级到Standalone模式: {e}")
self._cluster = None
self._standalone = await self._connect_standalone()
return self._cluster or self._standalone
async def _connect_standalone(self) -> Redis:
if self._standalone is None:
node = self.nodes[0]
self._standalone = redis.Redis(
host=node['host'], port=int(node['port']), password=self.password,
db=self.db, ssl=self.ssl, decode_responses=True
)
await self._standalone.ping()
logger.info(f"Redis Standalone连接成功: {node['host']}:{node['port']}")
return self._standalone
async def disconnect(self):
if self._cluster:
await self._cluster.close()
self._cluster = None
if self._standalone:
await self._standalone.close()
self._standalone = None
logger.info("Redis连接已关闭")
@property
def client(self) -> Redis:
return self._cluster or self._standalone
async def create_session(self, user_id: str,
metadata: Optional[Dict[str, Any]] = None) -> SessionData:
session_id = str(uuid.uuid4())
session = SessionData(user_id, session_id)
if metadata:
session.data.update(metadata)
key = f"{self.PREFIX_SESSION}{session_id}"
await self.client.hset(key, mapping={
'user_id': user_id, 'session_id': session_id,
'created_at': str(session.created_at), 'updated_at': str(session.updated_at),
'data': json.dumps(session.data)
})
await self.client.expire(key, self.DEFAULT_SESSION_TTL)
logger.info(f"创建会话: {session_id} (user: {user_id})")
return session
async def get_session(self, session_id: str) -> Optional[SessionData]:
key = f"{self.PREFIX_SESSION}{session_id}"
data = await self.client.hgetall(key)
if not data:
return None
session = SessionData(data['user_id'], data['session_id'])
session.created_at = float(data.get('created_at', 0))
session.updated_at = float(data.get('updated_at', 0))
session.data = json.loads(data.get('data', '{}'))
return session
async def update_session(self, session_id: str, data: Dict[str, Any],
extend_ttl: bool = True) -> bool:
key = f"{self.PREFIX_SESSION}{session_id}"
existing = await self.client.hget(key, 'data')
existing_data = json.loads(existing) if existing else {}
existing_data.update(data)
await self.client.hset(key, mapping={
'updated_at': str(time.time()), 'data': json.dumps(existing_data)
})
if extend_ttl:
await self.client.expire(key, self.DEFAULT_SESSION_TTL)
return True
async def delete_session(self, session_id: str) -> bool:
key = f"{self.PREFIX_SESSION}{session_id}"
result = await self.client.delete(key)
logger.info(f"删除会话: {session_id}, 结果: {result}")
return result > 0
async def store_token(self, token: str, user_id: str, ttl: int = 86400) -> bool:
key = f"{self.PREFIX_TOKEN}{token}"
await self.client.set(key, user_id, ex=ttl)
return True
async def get_token(self, token: str) -> Optional[str]:
key = f"{self.PREFIX_TOKEN}{token}"
return await self.client.get(key)
async def revoke_token(self, token: str) -> bool:
key = f"{self.PREFIX_TOKEN}{token}"
result = await self.client.delete(key)
return result > 0
async def set_collab_state(self, project_id: str, user_id: str,
state: Dict[str, Any], ttl: int = DEFAULT_COLLAB_TTL) -> bool:
key = f"{self.PREFIX_COLLAB}{project_id}:{user_id}"
await self.client.hset(key, mapping={
'user_id': user_id, 'state': json.dumps(state), 'updated_at': str(time.time())
})
await self.client.expire(key, ttl)
set_key = f"{self.PREFIX_COLLAB}{project_id}:online_users"
await self.client.sadd(set_key, user_id)
await self.client.expire(set_key, ttl)
return True
async def get_collab_state(self, project_id: str, user_id: str) -> Optional[Dict[str, Any]]:
key = f"{self.PREFIX_COLLAB}{project_id}:{user_id}"
data = await self.client.hgetall(key)
if not data:
return None
return {'user_id': data.get('user_id'), 'state': json.loads(data.get('state', '{}')),
'updated_at': float(data.get('updated_at', 0))}
async def get_project_online_users(self, project_id: str) -> List[str]:
set_key = f"{self.PREFIX_COLLAB}{project_id}:online_users"
return list(await self.client.smembers(set_key))
async def check_rate_limit(self, key: str, max_requests: int,
window_seconds: int) -> Dict[str, Any]:
rate_key = f"{self.PREFIX_RATE}{key}"
now = time.time()
window_start = now - window_seconds
pipe = self.client.pipeline()
pipe.zremrangebyscore(rate_key, 0, window_start)
pipe.zcard(rate_key)
pipe.zadd(rate_key, {f"{now}:{uuid.uuid4()}": now})
pipe.expire(rate_key, window_seconds)
results = await pipe.execute()
current_count = results[1]
allowed = current_count < max_requests
remaining = max(0, max_requests - current_count - 1)
return {'allowed': allowed, 'remaining': remaining, 'reset_at': now + window_seconds, 'total': current_count}
async def acquire_lock(self, resource: str, owner: str, ttl: int = DEFAULT_LOCK_TTL) -> bool:
key = f"{self.PREFIX_LOCK}{resource}"
result = await self.client.set(key, owner, nx=True, ex=ttl)
if result:
logger.debug(f"获取锁成功: {resource} (owner: {owner})")
return result is not None
async def release_lock(self, resource: str, owner: str) -> bool:
key = f"{self.PREFIX_LOCK}{resource}"
script = """
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else return 0 end
"""
result = await self.client.eval(script, 1, key, owner)
logger.debug(f"释放锁: {resource}, 结果: {result}")
return result == 1
async def set_cache(self, key: str, value: Any, ttl: int = DEFAULT_CACHE_TTL) -> bool:
cache_key = f"{self.PREFIX_CACHE}{key}"
await self.client.set(cache_key, json.dumps(value), ex=ttl)
return True
async def get_cache(self, key: str) -> Optional[Any]:
cache_key = f"{self.PREFIX_CACHE}{key}"
data = await self.client.get(cache_key)
return json.loads(data) if data else None
async def delete_cache(self, key: str) -> bool:
cache_key = f"{self.PREFIX_CACHE}{key}"
result = await self.client.delete(cache_key)
return result > 04.4 Redis高可用配置
5. 代码存储:分布式文件系统 vs 对象存储
5.1 代码存储的核心挑战
代码存储是云端IDE最核心的基础设施之一:
特性 | 代码存储特点 | 普通文件存储特点 |
|---|---|---|
文件数量 | 超大量小文件(Git仓库可能有数十万个文件) | 相对较少的较大文件 |
读取模式 | 频繁读取相同文件(同一文件的访问热点) | 顺序或随机访问 |
写入模式 | 增量写入(每次提交只修改少量文件) | 全量或随机写入 |
一致性要求 | 强一致性(代码合并必须一致) | 最终一致性可接受 |
元数据开销 | 极高(文件系统inode压力大) | 中等 |
根据Facebook 2022年《Git at Scale》论文[^5],大型代码仓库面临的核心问题:
.git目录膨胀:历史越长的仓库,.git目录越大- 检出(Checkout)慢:工作目录文件众多,检出耗时
- 克隆(Clone)慢:完整下载历史,流量大
- 索引(Index)操作慢:Git内部索引文件庞大
5.2 分布式文件系统方案
JuiceFS:云原生分布式文件系统
JuiceFS[^6]采用数据与元数据分离的架构:
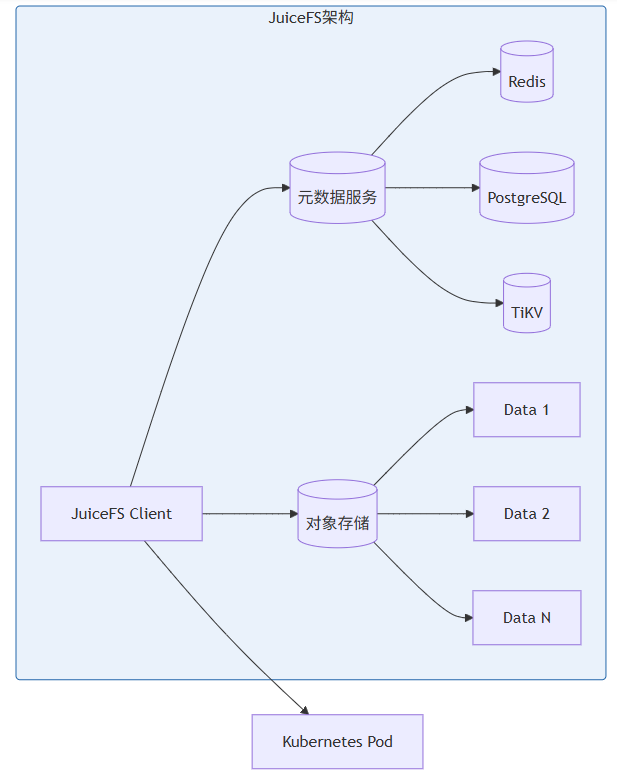
核心优势:
- POSIX兼容:无需修改代码
- 云原生:原生支持Kubernetes、CSI Driver
- 数据分离:元数据与数据分离,便于独立扩展
- 多后端:支持S3、MinIO、本地磁盘等
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: juicefs-sc
provisioner: csi.juicefs.com
parameters:
bucket: https://myminio:9000/juicefs
metaurl: redis://redis:6379/0
storage: s3
cache-size: 102400
cache-dir: /var/lib/juicefs/cache
access-key: ${AWS_ACCESS_KEY_ID}
secret-key: ${AWS_SECRET_ACCESS_KEY}
compress: lz4
reclaimPolicy: Retain
allowVolumeExpansion: true"""JuiceFS代码存储服务实现"""
import subprocess
import os, logging
from typing import Optional, Dict, Any, List
from pathlib import Path
import asyncio, aiofiles
logger = logging.getLogger(__name__)
class JuiceFSStorage:
def __init__(self, mount_point: str, bucket: str, metaurl: str,
access_key: Optional[str] = None, secret_key: Optional[str] = None,
cache_dir: str = "/var/lib/juicefs/cache", cache_size: int = 102400, compress: str = "lz4"):
self.mount_point = Path(mount_point)
self.bucket = bucket
self.metaurl = metaurl
self.access_key = access_key
self.secret_key = secret_key
self.cache_dir = cache_dir
self.cache_size = cache_size
self.compress = compress
async def mount(self, background: bool = True) -> bool:
cmd = ["juicefs", "mount", self.metaurl, str(self.mount_point),
"-d" if background else "", "--bucket", self.bucket,
"--cache-size", str(self.cache_size), "--cache-dir", self.cache_dir,
"--compress", self.compress]
if self.access_key and self.secret_key:
cmd.extend(["--access-key", self.access_key, "--secret-key", self.secret_key])
cmd = [c for c in cmd if c]
try:
result = subprocess.run(cmd, capture_output=True, text=True, timeout=30)
if result.returncode == 0:
logger.info(f"JuiceFS已挂载到 {self.mount_point}")
return True
else:
logger.error(f"JuiceFS挂载失败: {result.stderr}")
return False
except subprocess.TimeoutExpired:
logger.error("JuiceFS挂载超时")
return False
except FileNotFoundError:
logger.error("JuiceFS命令未找到")
return False
async def unmount(self) -> bool:
try:
result = subprocess.run(["juicefs", "umount", str(self.mount_point)],
capture_output=True, text=True, timeout=30)
if result.returncode == 0:
logger.info(f"JuiceFS已从 {self.mount_point} 卸载")
return True
else:
logger.error(f"JuiceFS卸载失败: {result.stderr}")
return False
except Exception as e:
logger.error(f"JuiceFS卸载异常: {e}")
return False
def get_repo_path(self, repo_id: str, owner: str) -> Path:
return self.mount_point / "repos" / owner / repo_id
async def create_repo(self, repo_id: str, owner: str, name: str,
description: str = "", is_private: bool = True) -> Dict[str, Any]:
repo_path = self.get_repo_path(repo_id, owner)
try:
repo_path.mkdir(parents=True, exist_ok=True)
result = subprocess.run(["git", "init"], cwd=repo_path, capture_output=True, text=True)
if result.returncode != 0:
return {'success': False, 'error': result.stderr}
readme_path = repo_path / "README.md"
async with aiofiles.open(readme_path, 'w') as f:
await f.write(f"# {name}\n\n{description}\n")
subprocess.run(["git", "add", "."], cwd=repo_path)
subprocess.run(["git", "commit", "-m", "Initial commit"], cwd=repo_path, capture_output=True)
import json
metadata = {'name': name, 'owner': owner, 'private': is_private, 'created_at': asyncio.get_event_loop().time()}
meta_path = repo_path / ".repo_metadata"
async with aiofiles.open(meta_path, 'w') as f:
await f.write(json.dumps(metadata))
return {'success': True, 'path': str(repo_path), 'repo_id': repo_id}
except Exception as e:
logger.error(f"创建仓库失败: {e}")
return {'success': False, 'error': str(e)}
async def get_repo_stats(self, repo_path: Path) -> Dict[str, Any]:
try:
file_count_result = subprocess.run(["git", "ls-files"], cwd=repo_path, capture_output=True, text=True)
file_count = len(file_count_result.stdout.strip().split('\n')) if file_count_result.stdout.strip() else 0
commit_count_result = subprocess.run(["git", "rev-list", "--count", "HEAD"], cwd=repo_path, capture_output=True, text=True)
commit_count = int(commit_count_result.stdout.strip())
size_result = subprocess.run(["du", "-sb", str(repo_path)], capture_output=True, text=True)
total_size = int(size_result.stdout.split()[0])
branch_result = subprocess.run(["git", "branch", "-a"], cwd=repo_path, capture_output=True, text=True)
branches = branch_result.stdout.strip().split('\n') if branch_result.stdout.strip() else []
return {'file_count': file_count, 'commit_count': commit_count, 'total_size_bytes': total_size,
'branches': [b.strip() for b in branches if b.strip()]}
except Exception as e:
logger.error(f"获取仓库统计失败: {e}")
return {}5.3 对象存储方案:Git Native Storage
对于超大规模代码仓库,Git Native Storage[^7]将Git仓库以对象形式存储在S3中:
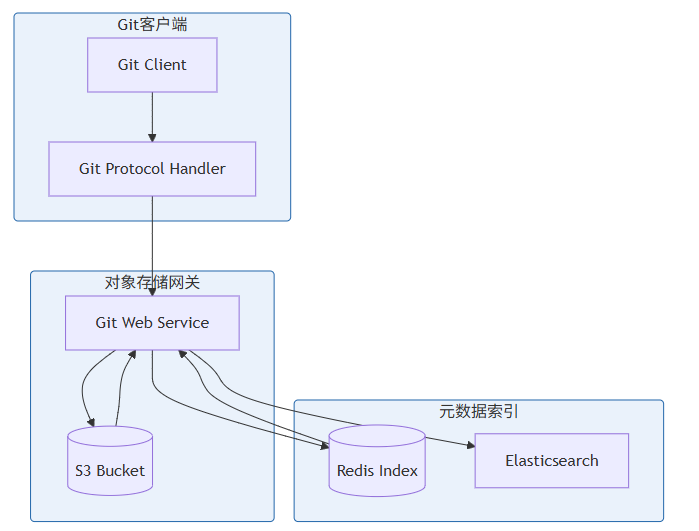
核心原理:
- Pack文件存储在S3:Git的pack文件直接作为对象存储
- Loose Object缓存:小对象先缓存,达到阈值后打包上传
- 前缀压缩:相同前缀的pack文件共享数据块
- 元数据索引:文件名、大小、SHA等存储在Redis/ES
5.4 方案对比与选型建议
特性 | JuiceFS | Git Native Storage | CephFS |
|---|---|---|---|
部署复杂度 | 中 | 中 | 高 |
POSIX兼容性 | 完全兼容 | 不兼容 | 完全兼容 |
海量小文件 | 优秀 | 优秀 | 一般 |
吞吐量 | 高 | 极高 | 高 |
成本 | 中(需要Redis) | 低 | 高 |
适用规模 | 中大型 | 大型超大型 | 超大型 |
选型建议:
- 小型团队(<100人):直接使用本地SSD + JuiceFS
- 中型团队(100-1000人):JuiceFS + 云对象存储
- 大型团队(>1000人):Git Native Storage + 对象存储
- 超大型(>10000人):自研Git Native Storage + 分片对象存储
6. 数据备份:增量备份与跨区域复制
6.1 备份策略设计
云端IDE的数据备份需要考虑三个维度:
- RPO(Recovery Point Objective):可接受的数据丢失量
- RTO(Recovery Time Objective):可接受的恢复时间
- 成本:存储和带宽成本
数据类型 | RPO | RTO | 备份策略 |
|---|---|---|---|
用户数据(数据库) | 5分钟 | 30分钟 | 连续归档(WAL)+ 每小时快照 |
代码仓库 | 1小时 | 1小时 | 每日全量 + 每小时增量 |
对象存储 | 24小时 | 12小时 | 跨区域复制 |
会话数据 | N/A | N/A | 不备份(TTL自动过期) |
6.2 PostgreSQL备份实现
"""PostgreSQL备份服务实现"""
import asyncpg
import subprocess
import asyncio
import logging
from datetime import datetime, timedelta
from typing import Optional, Dict, Any, List
from pathlib import Path
import boto3
from botocore.config import Config
import hashlib
import json
logger = logging.getLogger(__name__)
class PostgresBackupService:
def __init__(self, db_config: Dict[str, Any], backup_config: Dict[str, Any]):
self.db_config = db_config
self.backup_config = backup_config
self.backup_dir = Path(backup_config['backup_dir'])
self._s3_client = None
@property
def s3_client(self):
if self._s3_client is None:
config = Config(retries={'max_attempts': 3}, connect_timeout=10, read_timeout=30)
self._s3_client = boto3.client(
's3', endpoint_url=self.backup_config.get('s3_endpoint'),
aws_access_key_id=self.backup_config.get('aws_access_key_id'),
aws_secret_access_key=self.backup_config.get('aws_secret_access_key'), config=config
)
return self._s3_client
async def create_basebackup(self) -> Dict[str, Any]:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
backup_name = f"basebackup_{timestamp}"
backup_path = self.backup_dir / backup_name
backup_path.mkdir(parents=True, exist_ok=True)
try:
cmd = ["pg_basebackup", "-h", self.db_config['host'], "-p", str(self.db_config['port']),
"-U", self.db_config['user'], "-D", str(backup_path), "-Ft", "-z", "-P", "-X", "stream"]
result = subprocess.run(cmd, capture_output=True, text=True,
env={**subprocess.os.environ, "PGPASSWORD": self.db_config['password']})
if result.returncode != 0:
return {'success': False, 'error': result.stderr, 'backup_path': str(backup_path)}
checksum = await self._calculate_checksum(backup_path)
metadata = {
'backup_type': 'basebackup', 'timestamp': timestamp, 'backup_path': str(backup_path),
'checksum': checksum, 'pg_version': await self._get_pg_version(),
'created_at': datetime.now().isoformat(), 'size_bytes': await self._get_directory_size(backup_path)
}
metadata_path = backup_path / "backup_metadata.json"
with open(metadata_path, 'w') as f:
json.dump(metadata, f, indent=2)
logger.info(f"基础备份创建成功: {backup_name}")
return {'success': True, 'backup_name': backup_name, 'backup_path': str(backup_path), 'metadata': metadata}
except Exception as e:
logger.error(f"基础备份创建失败: {e}")
return {'success': False, 'error': str(e)}
async def create_incremental_backup(self) -> Dict[str, Any]:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
backup_name = f"incremental_{timestamp}"
backup_path = self.backup_dir / backup_name
backup_path.mkdir(parents=True, exist_ok=True)
try:
wal_dir = Path(self.db_config.get('wal_dir', '/var/lib/postgresql/data/pg_wal'))
if not wal_dir.exists():
return {'success': False, 'error': f"WAL目录不存在: {wal_dir}"}
last_backup_time = await self._get_last_backup_time()
wal_files = []
for wal_file in wal_dir.glob("*.wal"):
file_mtime = datetime.fromtimestamp(wal_file.stat().st_mtime)
if file_mtime > last_backup_time:
dest_file = backup_path / wal_file.name
dest_file.write_bytes(wal_file.read_bytes())
wal_files.append(wal_file.name)
if not wal_files:
logger.info("没有新的WAL文件需要备份")
backup_path.rmdir()
return {'success': True, 'backup_name': backup_name, 'wal_files_count': 0}
metadata = {
'backup_type': 'incremental', 'timestamp': timestamp, 'backup_path': str(backup_path),
'wal_files_count': len(wal_files), 'wal_files': wal_files,
'since': last_backup_time.isoformat(), 'created_at': datetime.now().isoformat()
}
metadata_path = backup_path.parent / f"{backup_name}_metadata.json"
with open(metadata_path, 'w') as f:
json.dump(metadata, f, indent=2)
logger.info(f"增量备份创建成功: {backup_name}, WAL文件数: {len(wal_files)}")
return {'success': True, 'backup_name': backup_name, 'backup_path': str(backup_path),
'wal_files_count': len(wal_files), 'metadata': metadata}
except Exception as e:
logger.error(f"增量备份创建失败: {e}")
return {'success': False, 'error': str(e)}
async def list_backups(self) -> List[Dict[str, Any]]:
backups = []
if not self.backup_dir.exists():
return backups
for item in self.backup_dir.iterdir():
if item.is_dir():
metadata_file = item / "backup_metadata.json"
if metadata_file.exists():
with open(metadata_file) as f:
backups.append(json.load(f))
else:
meta_file = self.backup_dir / f"{item.name}_metadata.json"
if meta_file.exists():
with open(meta_file) as f:
backups.append(json.load(f))
return sorted(backups, key=lambda x: x.get('created_at', ''), reverse=True)
async def delete_backup(self, backup_name: str) -> Dict[str, Any]:
backup_path = self.backup_dir / backup_name
if not backup_path.exists():
return {'success': False, 'error': f"备份不存在: {backup_name}"}
try:
import shutil
shutil.rmtree(backup_path)
metadata_file = self.backup_dir / f"{backup_name}_metadata.json"
if metadata_file.exists():
metadata_file.unlink()
logger.info(f"备份已删除: {backup_name}")
return {'success': True, 'backup_name': backup_name}
except Exception as e:
logger.error(f"删除备份失败: {e}")
return {'success': False, 'error': str(e)}
async def cleanup_old_backups(self, retention_days: Optional[int] = None) -> Dict[str, Any]:
retention = retention_days or self.backup_config.get('retention_days', 30)
cutoff_date = datetime.now() - timedelta(days=retention)
backups = await self.list_backups()
deleted = []
errors = []
for backup in backups:
created_at = datetime.fromisoformat(backup.get('created_at', ''))
if created_at < cutoff_date:
result = await self.delete_backup(backup.get('timestamp', backup.get('backup_name', '')))
if result['success']:
deleted.append(backup.get('backup_name'))
else:
errors.append({'backup': backup.get('backup_name'), 'error': result.get('error')})
return {'deleted_count': len(deleted), 'deleted': deleted, 'errors': errors,
'retention_days': retention, 'cutoff_date': cutoff_date.isoformat()}
async def replicate_to_s3(self, backup_name: str, target_region: Optional[str] = None) -> Dict[str, Any]:
backup_path = self.backup_dir / backup_name
if not backup_path.exists():
return {'success': False, 'error': f"备份不存在: {backup_name}"}
bucket = self.backup_config.get('s3_bucket')
if not bucket:
return {'success': False, 'error': "S3 bucket未配置"}
try:
import tarfile
archive_name = f"{backup_name}.tar.gz"
archive_path = self.backup_dir / archive_name
with tarfile.open(archive_path, 'w:gz') as tar:
tar.add(backup_path, arcname=backup_path.name)
s3_key = f"backups/{datetime.now().strftime('%Y/%m/%d')}/{backup_name}.tar.gz"
extra_args = {'StorageClass': 'STANDARD_IA',
'Metadata': {'backup-type': 'postgres', 'backup-name': backup_name,
'created-at': datetime.now().isoformat()}}
self.s3_client.upload_file(str(archive_path), bucket, s3_key, ExtraArgs=extra_args)
presigned_url = self.s3_client.generate_presigned_url(
'get_object', Params={'Bucket': bucket, 'Key': s3_key}, ExpiresIn=3600 * 24 * 7
)
archive_path.unlink()
logger.info(f"备份已复制到S3: {s3_key}")
return {'success': True, 's3_key': s3_key, 'bucket': bucket, 'presigned_url': presigned_url}
except Exception as e:
logger.error(f"复制到S3失败: {e}")
return {'success': False, 'error': str(e)}
async def replicate_cross_region(self, backup_name: str, dest_bucket: str, dest_region: str) -> Dict[str, Any]:
try:
src_bucket = self.backup_config.get('s3_bucket')
src_key = f"backups/{datetime.now().strftime('%Y/%m/%d')}/{backup_name}.tar.gz"
copy_source = {'Bucket': src_bucket, 'Key': src_key}
dest_key = f"cross-region/{dest_region}/{backup_name}.tar.gz"
self.s3_client.copy(CopySource=copy_source, Bucket=dest_bucket, Key=dest_key,
ExtraArgs={'StorageClass': 'GLACIER',
'Metadata': {'source-region': self.backup_config.get('region', 'us-east-1'),
'dest-region': dest_region}})
logger.info(f"跨区域复制完成: {src_bucket} -> {dest_bucket} ({dest_region})")
return {'success': True, 'src_bucket': src_bucket, 'dest_bucket': dest_bucket, 'dest_region': dest_region}
except Exception as e:
logger.error(f"跨区域复制失败: {e}")
return {'success': False, 'error': str(e)}
async def _get_pg_version(self) -> str:
try:
conn = await asyncpg.connect(**self.db_config)
version = await conn.fetchval("SELECT version()")
await conn.close()
return version
except Exception:
return "unknown"
async def _get_last_backup_time(self) -> datetime:
backups = await self.list_backups()
if backups:
last_backup = backups[0]
return datetime.fromisoformat(last_backup.get('created_at'))
return datetime.now() - timedelta(days=1)
async def _calculate_checksum(self, path: Path) -> str:
hasher = hashlib.sha256()
for item in path.rglob("*"):
if item.is_file():
hasher.update(item.read_bytes())
return hasher.hexdigest()
async def _get_directory_size(self, path: Path) -> int:
total = 0
for item in path.rglob("*"):
if item.is_file():
total += item.stat().st_size
return total6.3 对象存储跨区域复制配置
{
"Role": "arn:aws:iam::123456789012:role/s3-replication-role",
"Rules": [
{
"ID": "ReplicateToDRRegion",
"Status": "Enabled",
"Priority": 1,
"Filter": {"Prefix": "projects/"},
"Destination": {
"Bucket": "arn:aws:s3:::ai-ide-backups-dr",
"StorageClass": "STANDARD_IA",
"EncryptionConfiguration": {"ReplicaKmsKeyID": "arn:aws:kms:us-west-2:123456789012:key/xxx"},
"AccessControlTranslation": {"Owner": "Destination"}
},
"SourceSelectionCriteria": {"SseKmsEncryptedObjects": {"Status": "Enabled"}},
"DeleteMarkerReplication": {"Status": "Enabled"}
},
{
"ID": "ReplicateGlacierToDeepArchive",
"Status": "Enabled",
"Priority": 2,
"Filter": {"Prefix": "backups/"},
"Destination": {"Bucket": "arn:aws:s3:::ai-ide-backups-archive", "StorageClass": "DEEP_ARCHIVE"}
}
],
"ExistingObjectReplication": {"Status": "Disabled"}
}7. 实践:设计一个多存储类型的统一存储服务
7.1 统一存储服务架构
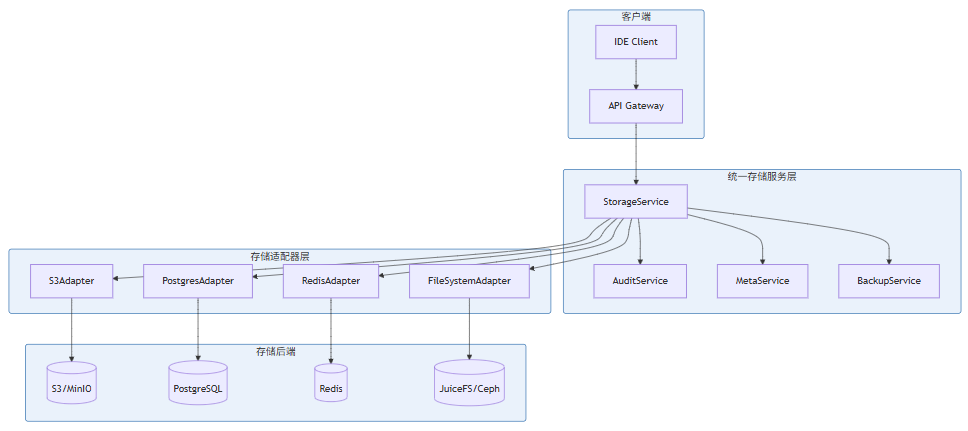
7.2 统一存储服务核心实现
"""统一存储服务 - Unified Storage Service"""
import asyncio
import logging
from typing import Optional, Dict, Any, List
from dataclasses import dataclass, field
from enum import Enum
from datetime import datetime
import uuid
import json
logger = logging.getLogger(__name__)
class StorageType(Enum):
OBJECT = "object"
DATABASE = "database"
CACHE = "cache"
FILESYSTEM = "filesystem"
@dataclass
class StorageConfig:
s3_endpoint: str = "localhost:9000"
s3_access_key: str = ""
s3_secret_key: str = ""
s3_bucket: str = "ai-ide-storage"
s3_region: str = "us-east-1"
s3_use_ssl: bool = False
pg_host: str = "localhost"
pg_port: int = 5432
pg_database: str = "ai_ide"
pg_user: str = "postgres"
pg_password: str = ""
pg_pool_min: int = 10
pg_pool_max: int = 100
redis_nodes: List[Dict[str, str]] = field(default_factory=lambda: [{"host": "localhost", "port": "6379"}])
redis_password: Optional[str] = None
redis_db: int = 0
fs_type: str = "juicefs"
fs_mount_point: str = "/mnt/juicefs"
fs_bucket: str = ""
fs_metaurl: str = ""
@dataclass
class StorageResult:
success: bool
storage_type: StorageType
operation: str
data: Any = None
error: Optional[str] = None
metadata: Dict[str, Any] = field(default_factory=dict)
def to_dict(self) -> Dict[str, Any]:
return {'success': self.success, 'storage_type': self.storage_type.value,
'operation': self.operation, 'data': self.data, 'error': self.error, 'metadata': self.metadata}
class UnifiedStorageService:
def __init__(self, config: StorageConfig):
self.config = config
self._s3_client = None
self._pg_storage = None
self._redis_store = None
self._fs_storage = None
self._connections: Dict[StorageType, bool] = {}
async def initialize(self) -> Dict[StorageType, bool]:
from .adapters.s3_adapter import S3StorageClient
from .adapters.postgres_adapter import PostgresStorage, DatabaseConfig
from .adapters.redis_adapter import RedisSessionStore
from .adapters.filesystem_adapter import JuiceFSStorage
results = {}
# S3
try:
self._s3_client = S3StorageClient(
endpoint=self.config.s3_endpoint, access_key=self.config.s3_access_key,
secret_key=self.config.s3_secret_key, bucket_name=self.config.s3_bucket,
region=self.config.s3_region, use_ssl=self.config.s3_use_ssl
)
await self._s3_client.list_objects(prefix="", max_keys=1)
self._connections[StorageType.OBJECT] = True
results[StorageType.OBJECT] = True
logger.info("S3存储连接成功")
except Exception as e:
logger.error(f"S3存储连接失败: {e}")
self._connections[StorageType.OBJECT] = False
results[StorageType.OBJECT] = False
# PostgreSQL
try:
pg_config = DatabaseConfig(
host=self.config.pg_host, port=self.config.pg_port,
database=self.config.pg_database, user=self.config.pg_user,
password=self.config.pg_password, pool_min_size=self.config.pg_pool_min,
pool_max_size=self.config.pg_pool_max
)
self._pg_storage = PostgresStorage(pg_config)
await self._pg_storage.connect()
self._connections[StorageType.DATABASE] = True
results[StorageType.DATABASE] = True
logger.info("PostgreSQL存储连接成功")
except Exception as e:
logger.error(f"PostgreSQL存储连接失败: {e}")
self._connections[StorageType.DATABASE] = False
results[StorageType.DATABASE] = False
# Redis
try:
self._redis_store = RedisSessionStore(
nodes=self.config.redis_nodes, password=self.config.redis_password, db=self.config.redis_db
)
await self._redis_store.connect()
self._connections[StorageType.CACHE] = True
results[StorageType.CACHE] = True
logger.info("Redis存储连接成功")
except Exception as e:
logger.error(f"Redis存储连接失败: {e}")
self._connections[StorageType.CACHE] = False
results[StorageType.CACHE] = False
# 文件系统
try:
if self.config.fs_type == "juicefs":
self._fs_storage = JuiceFSStorage(
mount_point=self.config.fs_mount_point, bucket=self.config.fs_bucket,
metaurl=self.config.fs_metaurl, access_key=self.config.s3_access_key,
secret_key=self.config.s3_secret_key
)
self._connections[StorageType.FILESYSTEM] = True
results[StorageType.FILESYSTEM] = True
logger.info("JuiceFS存储连接成功")
else:
self._connections[StorageType.FILESYSTEM] = False
results[StorageType.FILESYSTEM] = False
except Exception as e:
logger.error(f"文件系统存储连接失败: {e}")
self._connections[StorageType.FILESYSTEM] = False
results[StorageType.FILESYSTEM] = False
return results
async def close(self):
if self._pg_storage:
await self._pg_storage.disconnect()
if self._redis_store:
await self._redis_store.disconnect()
if self._fs_storage:
await self._fs_storage.unmount()
self._connections = {}
logger.info("所有存储连接已关闭")
def is_connected(self, storage_type: StorageType) -> bool:
return self._connections.get(storage_type, False)
async def create_user(self, email: str, password_hash: str, username: str,
metadata: Optional[Dict[str, Any]] = None) -> StorageResult:
if not self.is_connected(StorageType.DATABASE):
return StorageResult(success=False, storage_type=StorageType.DATABASE, operation="create_user",
error="数据库未连接")
user_id = str(uuid.uuid4())
result = await self._pg_storage.create_user(
user_id=user_id, email=email, password_hash=password_hash, username=username, metadata=metadata
)
if result['success']:
await self._pg_storage.write_audit_log(
user_id=user_id, action="CREATE", resource_type="user", resource_id=user_id,
details={"email": email, "username": username}
)
return StorageResult(success=result['success'], storage_type=StorageType.DATABASE, operation="create_user",
data=result.get('user'), error=result.get('error'))
async def get_user(self, user_id: str) -> StorageResult:
if not self.is_connected(StorageType.DATABASE):
return StorageResult(success=False, storage_type=StorageType.DATABASE, operation="get_user",
error="数据库未连接")
user = await self._pg_storage.get_user_by_id(user_id)
return StorageResult(success=user is not None, storage_type=StorageType.DATABASE, operation="get_user", data=user)
async def authenticate_user(self, email: str, password_hash: str) -> StorageResult:
if not self.is_connected(StorageType.DATABASE) or not self.is_connected(StorageType.CACHE):
return StorageResult(success=False, storage_type=StorageType.DATABASE, operation="authenticate",
error="存储服务未完全连接")
user = await self._pg_storage.get_user_by_email(email)
if not user or user['password_hash'] != password_hash:
return StorageResult(success=False, storage_type=StorageType.DATABASE, operation="authenticate",
error="邮箱或密码错误")
session = await self._redis_store.create_session(
user_id=user['id'], metadata={"email": email, "username": user['username']}
)
token = f"tok_{uuid.uuid4().hex}"
await self._redis_store.store_token(token, user['id'], ttl=86400)
await self._pg_storage.execute("UPDATE users SET last_login_at = NOW() WHERE id = $1", user['id'])
await self._pg_storage.write_audit_log(
user_id=user['id'], action="LOGIN", resource_type="session", resource_id=session.session_id
)
return StorageResult(success=True, storage_type=StorageType.DATABASE, operation="authenticate",
data={"user": {"id": user['id'], "email": user['email'], "username": user['username']},
"session_id": session.session_id, "token": token})
async def create_project(self, name: str, owner_id: str, description: str = "",
visibility: str = "private") -> StorageResult:
if not self.is_connected(StorageType.DATABASE):
return StorageResult(success=False, storage_type=StorageType.DATABASE, operation="create_project",
error="数据库未连接")
project_id = str(uuid.uuid4())
result = await self._pg_storage.create_project(
project_id=project_id, name=name, owner_id=owner_id, description=description, visibility=visibility
)
if not result['success']:
return StorageResult(success=False, storage_type=StorageType.DATABASE, operation="create_project",
error=result.get('error'))
if self.is_connected(StorageType.FILESYSTEM) and self._fs_storage:
await self._fs_storage.create_repo(
repo_id=project_id, owner=owner_id, name=name, description=description,
is_private=(visibility == "private")
)
if self.is_connected(StorageType.OBJECT) and self._s3_client:
marker_key = f"projects/{project_id}/.project_marker"
await self._s3_client.upload_bytes(
data=json.dumps({"project_id": project_id, "name": name, "created_at": datetime.now().isoformat()}).encode(),
object_key=marker_key, content_type="application/json"
)
await self._pg_storage.write_audit_log(
user_id=owner_id, action="CREATE", resource_type="project", resource_id=project_id,
details={"name": name, "visibility": visibility}
)
return StorageResult(success=True, storage_type=StorageType.DATABASE, operation="create_project",
data={"project": result['project'], "project_id": project_id,
"repo_path": f"/repos/{owner_id}/{project_id}" if self._fs_storage else None})
async def get_project(self, project_id: str) -> StorageResult:
project = await self._pg_storage.get_project_by_id(project_id)
return StorageResult(success=project is not None, storage_type=StorageType.DATABASE, operation="get_project", data=project)
async def update_collab_state(self, project_id: str, user_id: str, state: Dict[str, Any]) -> StorageResult:
if not self._redis_store:
return StorageResult(success=False, storage_type=StorageType.CACHE, operation="update_collab_state",
error="Redis未连接")
success = await self._redis_store.set_collab_state(project_id=project_id, user_id=user_id, state=state)
return StorageResult(success=success, storage_type=StorageType.CACHE, operation="update_collab_state",
data={"project_id": project_id, "user_id": user_id})
async def get_online_users(self, project_id: str) -> StorageResult:
if not self._redis_store:
return StorageResult(success=False, storage_type=StorageType.CACHE, operation="get_online_users",
error="Redis未连接")
users = await self._redis_store.get_project_online_users(project_id)
return StorageResult(success=True, storage_type=StorageType.CACHE, operation="get_online_users",
data={"users": users, "count": len(users)})
async def health_check(self) -> Dict[str, Any]:
status = {"overall": "healthy", "timestamp": datetime.now().isoformat(), "storages": {}}
try:
if self._s3_client:
await self._s3_client.list_objects(prefix="", max_keys=1)
status["storages"]["object"] = {"status": "healthy"}
else:
status["storages"]["object"] = {"status": "not_initialized"}
except Exception as e:
status["storages"]["object"] = {"status": "unhealthy", "error": str(e)}
status["overall"] = "degraded"
try:
if self._pg_storage:
await self._pg_storage.fetchval("SELECT 1")
status["storages"]["database"] = {"status": "healthy"}
else:
status["storages"]["database"] = {"status": "not_initialized"}
except Exception as e:
status["storages"]["database"] = {"status": "unhealthy", "error": str(e)}
status["overall"] = "degraded"
try:
if self._redis_store:
await self._redis_store.client.ping()
status["storages"]["cache"] = {"status": "healthy"}
else:
status["storages"]["cache"] = {"status": "not_initialized"}
except Exception as e:
status["storages"]["cache"] = {"status": "unhealthy", "error": str(e)}
status["overall"] = "degraded"
try:
if self._fs_storage:
status["storages"]["filesystem"] = {"status": "healthy"}
else:
status["storages"]["filesystem"] = {"status": "not_initialized"}
except Exception as e:
status["storages"]["filesystem"] = {"status": "unhealthy", "error": str(e)}
status["overall"] = "degraded"
return status
async def main():
from dataclasses import dataclass, field
@dataclass
class StorageConfigExample:
s3_endpoint: str = "localhost:9000"
s3_access_key: str = "minioadmin"
s3_secret_key: str = "minioadmin"
s3_bucket: str = "ai-ide-storage"
s3_region: str = "us-east-1"
s3_use_ssl: bool = False
pg_host: str = "localhost"
pg_port: int = 5432
pg_database: str = "ai_ide"
pg_user: str = "postgres"
pg_password: str = "postgres"
pg_pool_min: int = 10
pg_pool_max: int = 100
redis_nodes: List[Dict[str, str]] = field(default_factory=lambda: [{"host": "localhost", "port": "6379"}])
redis_password: Optional[str] = None
redis_db: int = 0
fs_type: str = "juicefs"
fs_mount_point: str = "/mnt/juicefs"
fs_bucket: str = "s3://minio/juicefs"
fs_metaurl: str = "redis://localhost:6379/0"
config = StorageConfigExample()
storage = UnifiedStorageService(config)
try:
await storage.initialize()
user_result = await storage.create_user(
email="user@example.com", password_hash="hashed_password", username="testuser",
metadata={"plan": "pro"}
)
if user_result.success:
user_id = user_result.data['id']
project_result = await storage.create_project(
name="my-awesome-project", owner_id=user_id, description="A test project", visibility="private"
)
if project_result.success:
await storage.update_collab_state(
project_id=project_result.data['project_id'], user_id=user_id,
state={"cursor_position": {"line": 42, "column": 15}}
)
online = await storage.get_online_users(project_result.data['project_id'])
print(f"在线用户: {online.data['users']}")
health = await storage.health_check()
print(f"健康状态: {health['overall']}")
finally:
await storage.close()
if __name__ == "__main__":
asyncio.run(main())7.3 统一存储服务配置
storage:
object_storage:
enabled: true
provider: minio
endpoint: ${S3_ENDPOINT:localhost:9000}
access_key: ${S3_ACCESS_KEY:minioadmin}
secret_key: ${S3_SECRET_KEY:minioadmin}
bucket: ai-ide-storage
region: us-east-1
use_ssl: false
storage_classes:
hot: STANDARD
warm: STANDARD_IA
cold: GLACIER
archive: DEEP_ARCHIVE
database:
enabled: true
host: ${PG_HOST:localhost}
port: ${PG_PORT:5432}
database: ai_ide
username: ${PG_USER:postgres}
password: ${PG_PASSWORD:}
pool:
min_size: 10
max_size: 100
ssl:
enabled: false
mode: require
cache:
enabled: true
cluster_mode: true
nodes:
- host: ${REDIS_NODE1:localhost}
port: ${REDIS_PORT:6379}
password: ${REDIS_PASSWORD:}
db: 0
ssl: false
ttl:
session: 86400
collab_state: 300
rate_limit: 60
cache: 3600
filesystem:
enabled: true
type: juicefs
mount_point: /mnt/juicefs
juicefs:
bucket: ${JUICEFS_BUCKET:s3://minio/juicefs}
metaurl: ${JUICEFS_METAURL:redis://localhost:6379/0}
cache_size: 102400
compress: lz4
backup:
enabled: true
target: s3
interval: 3600
backup:
enabled: true
retention_days: 30
schedule:
full_backup: "0 2 * * *"
incremental_backup: "0 */4 * * *"
targets:
- type: s3
bucket: ai-ide-backups
region: us-west-2
- type: s3
bucket: ai-ide-backups-dr
region: ap-east-1
storage_class: GLACIER
monitoring:
metrics_enabled: true
export_interval: 60
alert_thresholds:
storage_usage_percent: 85
connection_pool_usage_percent: 80
latency_p99_ms: 5008. 总结与展望
8.1 核心要点回顾
本文深入探讨了云端AI IDE存储系统的设计与实现:
- 对象存储(S3/MinIO):S3兼容存储完整接入方案,文件上传下载、生命周期管理、预签名URL。MinIO完全兼容S3 API,适合私有化部署。
- 关系型数据库选型:PostgreSQL、MySQL、CockroachDB对比。PostgreSQL适合大多数场景;CockroachDB适合全球分布强一致性需求。
- 会话存储(Redis):完整Redis Cluster会话管理方案,用户会话、Token管理、实时协作状态、速率限制、分布式锁等,支持自动降级到Standalone模式。
- 代码存储:分布式文件系统(JuiceFS)与对象存储(Git Native Storage)对比,根据团队规模给出选型建议。
- 数据备份:PostgreSQL全量备份、增量备份、WAL归档实现,跨区域复制配置,确保数据安全和业务连续性。
- 统一存储服务:整合所有存储类型,提供统一API接口,简化应用开发。
8.2 未来发展趋势
- 边缘存储融合:存储系统将进一步向边缘延伸,实现更低延迟的数据访问。
- 智能化分层存储:基于AI的访问模式预测,自动将数据在不同存储层之间迁移。
- 统一元数据管理:打破数据孤岛,建立统一的元数据索引。
- 更强的一致性保证:CRDTs等技术在分布式系统中的更广泛应用。
- 安全存储一体化:存储加密、访问控制、审计追踪更深层次融合。
参考链接:
- 主要来源:AWS S3 Documentation - AWS官方S3存储文档
- 主要来源:PostgreSQL Documentation - PostgreSQL官方文档
- 主要来源:Redis Documentation - Redis官方文档
- 主要来源:JuiceFS Documentation - JuiceFS官方中文文档
- 主要来源:CockroachDB Documentation - CockroachDB官方文档
附录(Appendix):
存储服务设计参考
A. S3存储桶策略示例
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::ai-ide-public/*"
},
{
"Sid": "RestrictedWriteObject",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::ai-ide-assets/private/*",
"Condition": {
"StringNotEquals": {"s3:x-amz-server-side-encryption": "AES256"}
}
}
]
}B. PostgreSQL连接池配置(PgBouncer)
[databases]
ai_ide = host=localhost port=5432 dbname=ai_ide
[pgbouncer]
listen_addr = 0.0.0.0
listen_port = 6432
auth_type = md5
pool_mode = transaction
max_client_conn = 1000
default_pool_size = 50
min_pool_size = 10
reserve_pool_size = 10
reserve_pool_timeout = 5
max_db_connections = 200C. Redis Cluster配置示例
bind 0.0.0.0
port 6379
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
appendonly yes
requirepass your_redis_password
masterauth your_redis_passwordD. 存储服务健康检查脚本
#!/bin/bash
echo "=== 存储服务健康检查 ==="
echo "检查 S3..."
mc ls myminio/ai-ide-storage > /dev/null 2>&1 && echo "✓ S3 正常" || echo "✗ S3 异常"
echo "检查 PostgreSQL..."
pg_isready -h localhost -p 5432 > /dev/null 2>&1 && echo "✓ PostgreSQL 正常" || echo "✗ PostgreSQL 异常"
echo "检查 Redis..."
redis-cli -h localhost -p 6379 ping > /dev/null 2>&1 && echo "✓ Redis 正常" || echo "✗ Redis 异常"
echo "检查 JuiceFS..."
mount | grep -q "/mnt/juicefs" && echo "✓ JuiceFS 已挂载" || echo "✗ JuiceFS 未挂载"
echo "=== 检查完成 ==="关键词: 云端IDE、存储架构、S3对象存储、PostgreSQL数据库、Redis缓存、分布式文件系统、JuiceFS、数据备份、跨区域复制、MinIO、CockroachDB、高可用存储

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号