用自定义 MCP 接入企业日志系统——从命令行到一键定位问题


“你将学到
- 设计一个企业级日志 MCP 的工具分层(Discovery 层 + Query 层),让 AI 不再蒙头乱查
- 用 FastMCP 把 Loki 或 Elasticsearch 的查询接口封装成 MCP 工具(完整 Python 代码)
- 选对传输协议:内网 stdio 还是 HTTP,安全性和复杂度如何取舍
- 在 MCP 中处理私有认证(Bearer token / API key / Basic auth)且不暴露明文凭证
一、AI 跟你一起对着日志干瞪眼
我见过太多这样的场景。
生产告警在半夜响了,on-call 工程师打开 Claude Code,把报错日志粘进去,问:"这是什么原因?"AI 给了一个看起来很有道理的分析,但这个分析基于的是那几十行日志片段——而真正的根因,藏在上游服务三分钟前的一条 ERROR,藏在某个 pod 的完整调用链里,藏在你没有粘贴进去的地方。
AI 的分析不是错的,只是不完整。因为它只能看到你告诉它的那部分。
这就是问题的本质:AI 看日志,不是 AI 没能力分析日志,而是 AI 根本没有主动查日志的渠道。你在手动做信息中间人的工作——从 Kibana 或 Grafana 复制日志,粘到 Claude,看 Claude 分析,再去系统里找更多上下文,再粘,循环。
这一讲要解决的,就是这个信息中间人问题。把企业日志系统包装成 MCP,让 Claude Code 能直接调用查询接口,从"看你粘贴的片段"升级到"自己去查、自己判断要看什么"。
这个痛点的根源清楚了。我们先搞懂,为什么这件事不简单,然后再一步步把它做出来。
二、为什么不能直接用官方 MCP,要自己写
这个问题值得先回答,因为很多人第一反应是"去找现成的"。
Grafana 官方确实有 mcp-grafana 仓库,Elastic 也有 mcp-server-elasticsearch(当前 v0.4.6)。如果你的日志系统是标准的公有云 Loki 或者 Elastic Cloud,这些官方实现装上去就能用。
但企业内网的日志系统通常有三个官方 MCP 处理不了的问题:
第一,工具粒度太粗。 官方 Loki MCP 只暴露一个 loki_query 工具,要求 AI 直接输入 LogQL 查询语句。问题是:如果 AI 不知道你的系统里有哪些 label(app、env、namespace……),它只能靠猜。猜出来的 LogQL 十有八九查不到东西,而且你不知道是没日志还是 label 写错了。正确的做法是先 Discovery(探索有什么),再 Query(有目的地查)——这需要多个分层工具。
第二,认证方式不匹配。 企业内网的日志系统认证千变万化:有用 LDAP 打通单点登录的,有每个团队发 API key 的,有走内部 OAuth 的,还有用 Cookie 维持会话的。官方 MCP 支持的认证方式往往是针对公有云设计的,对内网私有部署支持有限。
第三,查询权限不可控。 把一个能全量查询生产日志的 MCP 工具直接暴露给 AI,等于把你们的 DBA 账号直接给了 AI 用。你需要在 MCP 层做最小权限控制:只允许查特定时间范围、特定服务、特定字段,禁止写入、禁止删除索引。
这三个问题加在一起,解释了为什么企业场景下,自定义 MCP 比用官方实现更合适。
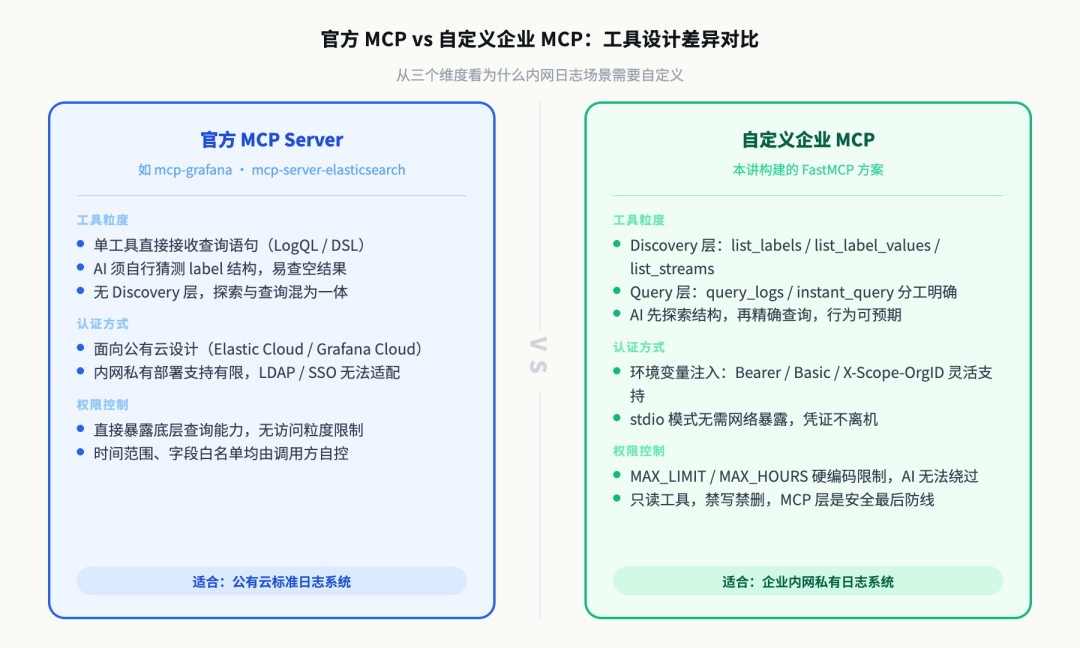
官方 vs 自定义 MCP 工具设计
这三个问题搞清楚之后,我们来设计解决方案。
三、企业日志 MCP 的架构设计
在动手写代码之前,先把架构想清楚。一个能在生产环境用的日志 MCP,需要回答三个设计问题。
工具要怎么分层
我在这个项目里采用了两层设计:Discovery 层和 Query 层。
Discovery 层的工具负责"告诉 AI 这个日志系统里有什么"——有哪些 label、哪些 label 的可能值、哪些服务正在产生日志。这层工具是无害的,调用它们不会产生大量数据传输,不会有性能影响。
Query 层的工具负责"真正去查日志"——按时间范围查日志流、在特定时间点执行表达式。这层工具有潜在的性能影响,需要做查询限制(比如返回条数上限、时间范围上限)。
这个分层设计让 AI 的查询行为更接近有经验的工程师:先探索,再精确查询,而不是上来就发一个"全量扫描"把服务器打挂。
Loki 的工具设计:
层级 | 工具名 | 功能 | 对应 Loki API |
|---|---|---|---|
Discovery | list_labels | 列出所有可用 label | /loki/api/v1/labels |
Discovery | list_label_values | 列出某个 label 的所有值 | /loki/api/v1/label/{name}/values |
Discovery | list_streams | 列出活跃的日志流 | /loki/api/v1/series |
Query | query_logs | 按时间范围查日志 | /loki/api/v1/query_range |
Query | instant_query | 在特定时间点执行 LogQL | /loki/api/v1/query |
传输协议选哪个
MCP 支持两种传输协议:stdio(标准输入输出)和 Streamable HTTP。
对企业内网部署,stdio 是首选。原因很实际:
- stdio 模式下,MCP server 是 Claude Code 的子进程,认证凭证通过环境变量传入,不需要网络暴露
- 不需要搭 HTTP 服务器,没有端口占用,没有额外的网络攻击面
- Claude Code 的
claude_desktop_config.json或settings.json直接配置 env,凭证管理清晰
什么时候用 Streamable HTTP?当你需要多个工程师共享同一个 MCP server 实例,或者 MCP server 需要部署在独立机器上(比如有网络隔离的堡垒机)时。这种情况下才需要上 OAuth 2.1,复杂度高得多,第 33 讲会专门讲数据库 MCP 的 HTTP 部署方案。
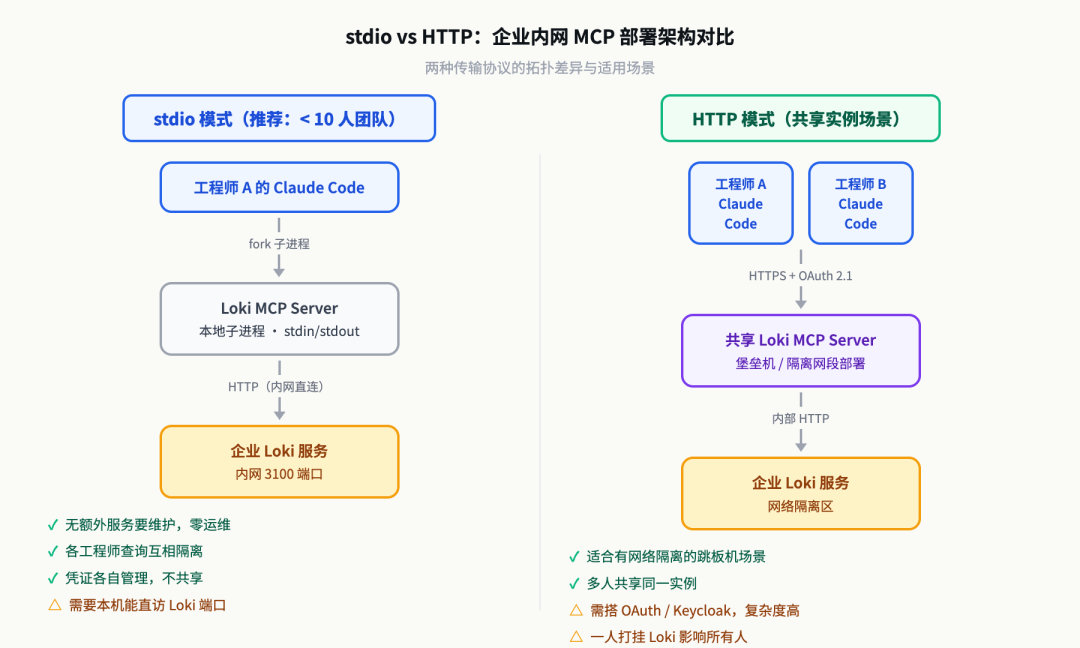
stdio vs HTTP 传输协议部署架构
认证方案
内网 Loki 常见认证:
- Basic auth(用户名 + 密码):最常见,通过
Authorization: Basic <base64>头传递 - Bearer token:通过
Authorization: Bearer <token>头传递 - 多租户(Grafana Loki):额外需要
X-Scope-OrgID头
内网 Elasticsearch 常见认证:
- API key:通过
Authorization: ApiKey <key>头传递 - Basic auth:同 Loki
- 不少企业部署了内部 Elastic 时直接关掉了 security(不推荐,但确实存在)
这些认证信息全部通过环境变量注入 stdio 进程,不硬编码在代码里,不提交到 git。
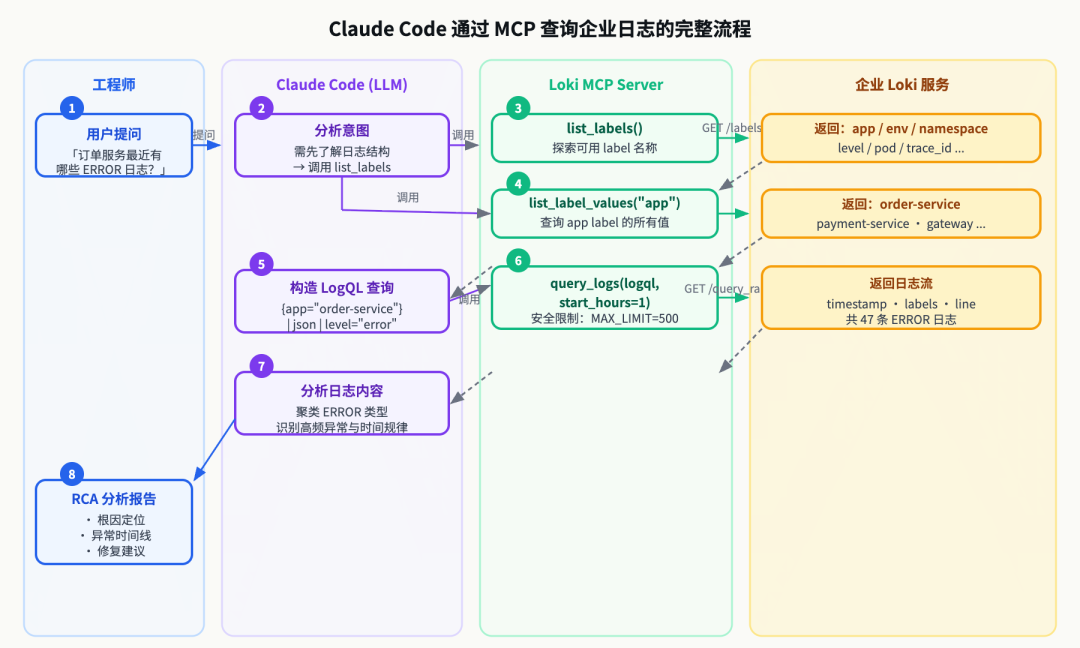
Claude Code 通过 MCP 查询日志完整流程
架构说清楚了,我们开始写代码。在这里大家需要学会用 AI 自己创建 MCP 给自己使用。
你完全可以结合码哥之前分享的使用 /superpower 来头脑风暴,把上文提出的 MCP 架构和实现方式告诉 Claude Code,并且在提示语中提示可以使用 /mcp-builder 创建最终的 skill。
四、实战:把 Loki 查询包装成 MCP(完整代码)
4.1 环境准备
Python >= 3.10
mcp[cli] == 1.27.2(2026-05-29 发布,截至本讲写作时的最新版)
httpx == 0.28.x(异步 HTTP 客户端)
安装依赖:
pip install "mcp[cli]" httpx
“💡 版本提醒:MCP Python SDK 迭代快,如果你在几个月后读到这篇,先用
pip show mcp确认版本,@mcp.tool()这个装饰器 API 在 1.x 大版本内是稳定的。
4.2 第一步:创建 MCP server 骨架
其实大家在创建 MCP 的时候可以结合 superpower 做头脑风暴,并且提示使用 mcp-builder skill 看来创建 MCP。而不是全部手写代码实现。
新建文件 loki_mcp/server.py:
# loki_mcp/server.py
import os
import base64
from datetime import datetime, timedelta, timezone
import httpx
from mcp.server.fastmcp import FastMCP
# --- 初始化 FastMCP server ---
mcp = FastMCP("loki-log-server")
# --- 从环境变量读取认证配置 ---
LOKI_URL = os.environ.get("LOKI_URL", "http://localhost:3100")
LOKI_USERNAME = os.environ.get("LOKI_USERNAME", "")
LOKI_PASSWORD = os.environ.get("LOKI_PASSWORD", "")
LOKI_BEARER_TOKEN = os.environ.get("LOKI_BEARER_TOKEN", "")
LOKI_ORG_ID = os.environ.get("LOKI_ORG_ID", "") # Grafana 多租户头
# --- 查询安全限制 ---
MAX_LIMIT = int(os.environ.get("LOKI_MAX_LIMIT", "1000")) # 单次最多返回条数
MAX_HOURS = int(os.environ.get("LOKI_MAX_HOURS", "24")) # 最多回溯小时数
def _build_headers() -> dict[str, str]:
"""根据环境变量构建认证 headers,优先级:Bearer > Basic > 无认证"""
headers = {"Content-Type": "application/json"}
if LOKI_BEARER_TOKEN:
headers["Authorization"] = f"Bearer {LOKI_BEARER_TOKEN}"
elif LOKI_USERNAME and LOKI_PASSWORD:
credentials = base64.b64encode(
f"{LOKI_USERNAME}:{LOKI_PASSWORD}".encode()
).decode()
headers["Authorization"] = f"Basic {credentials}"
if LOKI_ORG_ID:
headers["X-Scope-OrgID"] = LOKI_ORG_ID
return headers
def _validate_time_range(start_hours: float, end_hours: float) -> tuple[str, str]:
"""
把"N 小时前"转成 Loki 需要的 nanosecond 时间戳字符串。
同时做安全校验:时间范围不超过 MAX_HOURS。
"""
if start_hours < 0or end_hours < 0:
raise ValueError("时间范围不能是负数")
if start_hours > MAX_HOURS:
raise ValueError(f"最多只能查 {MAX_HOURS} 小时内的日志,当前请求 {start_hours} 小时")
now = datetime.now(timezone.utc)
start_dt = now - timedelta(hours=start_hours)
end_dt = now - timedelta(hours=end_hours)
# Loki API 使用 nanosecond 时间戳
start_ns = str(int(start_dt.timestamp() * 1e9))
end_ns = str(int(end_dt.timestamp() * 1e9))
return start_ns, end_ns
4.3 第二步:实现 Discovery 层工具
继续在 server.py 中添加 Discovery 层工具:
@mcp.tool()
asyncdef list_labels() -> dict:
"""
列出 Loki 中所有可用的 label 名称。
在构造查询之前,先用这个工具了解当前日志系统的结构。
返回示例:{"labels": ["app", "env", "namespace", "pod", "level"]}
"""
asyncwith httpx.AsyncClient(timeout=10.0) as client:
resp = await client.get(
f"{LOKI_URL}/loki/api/v1/labels",
headers=_build_headers(),
verify=False# 内网自签名证书常见,生产环境替换为 CA 路径
)
resp.raise_for_status()
data = resp.json()
return {"labels": data.get("data", [])}
@mcp.tool()
asyncdef list_label_values(label_name: str) -> dict:
"""
列出指定 label 的所有可能值。
例如:list_label_values("app") 返回 ["order-service", "payment-service", "gateway"]
Args:
label_name: label 名称,必须是 list_labels 返回的 label 之一
"""
ifnot label_name ornot label_name.replace("-", "").replace("_", "").isalnum():
raise ValueError(f"无效的 label 名称: {label_name!r}")
asyncwith httpx.AsyncClient(timeout=10.0) as client:
resp = await client.get(
f"{LOKI_URL}/loki/api/v1/label/{label_name}/values",
headers=_build_headers(),
verify=False
)
resp.raise_for_status()
data = resp.json()
return {
"label": label_name,
"values": data.get("data", [])
}
@mcp.tool()
asyncdef list_streams(
match: str = "",
start_hours: float = 1.0
) -> dict:
"""
列出当前活跃的日志流(流 = 一组 label 的组合)。
Args:
match: LogQL stream selector,例如 '{app="order-service"}',
空字符串返回所有流(数量可能很大,建议加过滤)
start_hours: 往前看多少小时,默认 1 小时
"""
start_ns, end_ns = _validate_time_range(start_hours, 0)
params: dict = {"start": start_ns, "end": end_ns, "limit": "100"}
if match:
params["match[]"] = match
asyncwith httpx.AsyncClient(timeout=15.0) as client:
resp = await client.get(
f"{LOKI_URL}/loki/api/v1/series",
headers=_build_headers(),
params=params,
verify=False
)
resp.raise_for_status()
data = resp.json()
return {
"streams": data.get("data", []),
"count": len(data.get("data", []))
}
4.4 第三步:实现 Query 层工具
@mcp.tool()
asyncdef query_logs(
logql: str,
start_hours: float = 1.0,
end_hours: float = 0.0,
limit: int = 100,
direction: str = "backward"
) -> dict:
"""
按时间范围查询日志流。这是最常用的查询工具。
Args:
logql: LogQL 查询语句,例如:
'{app="order-service"} |= "ERROR"'
'{namespace="production", level="error"} | json | duration > 1s'
start_hours: 查询起点(N 小时前),默认 1 小时前
end_hours: 查询终点(N 小时前),默认 0(即现在)
limit: 最多返回条数,默认 100,最大 {MAX_LIMIT}
direction: 排序方向,"backward"(最新的在前)或 "forward"
"""
if direction notin ("backward", "forward"):
raise ValueError("direction 必须是 'backward' 或 'forward'")
limit = min(limit, MAX_LIMIT)
start_ns, end_ns = _validate_time_range(start_hours, end_hours)
params = {
"query": logql,
"start": start_ns,
"end": end_ns,
"limit": str(limit),
"direction": direction
}
asyncwith httpx.AsyncClient(timeout=30.0) as client:
resp = await client.get(
f"{LOKI_URL}/loki/api/v1/query_range",
headers=_build_headers(),
params=params,
verify=False
)
resp.raise_for_status()
data = resp.json()
# 把 Loki 返回的格式整理成更易读的结构
result_streams = data.get("data", {}).get("result", [])
logs = []
for stream in result_streams:
labels = stream.get("stream", {})
for ts_ns, log_line in stream.get("values", []):
# 把 nanosecond 时间戳转成可读时间
ts_sec = int(ts_ns) / 1e9
readable_ts = datetime.fromtimestamp(
ts_sec, tz=timezone.utc
).strftime("%Y-%m-%d %H:%M:%S.%f UTC")
logs.append({
"timestamp": readable_ts,
"labels": labels,
"line": log_line
})
return {
"query": logql,
"total": len(logs),
"logs": logs
}
@mcp.tool()
asyncdef instant_query(logql: str, time_hours_ago: float = 0.0) -> dict:
"""
在某个特定时间点执行 LogQL 表达式(通常用于 metric 类查询)。
Args:
logql: LogQL metric 表达式,例如:
'count_over_time({app="order-service"}[5m])'
'rate({app="payment-service", level="error"}[1m])'
time_hours_ago: 在多少小时前的时间点执行,0 表示当前时间
"""
if time_hours_ago > MAX_HOURS:
raise ValueError(f"时间点不能超过 {MAX_HOURS} 小时前")
now = datetime.now(timezone.utc)
query_time = now - timedelta(hours=time_hours_ago)
query_time_ns = str(int(query_time.timestamp() * 1e9))
asyncwith httpx.AsyncClient(timeout=15.0) as client:
resp = await client.get(
f"{LOKI_URL}/loki/api/v1/query",
headers=_build_headers(),
params={"query": logql, "time": query_time_ns},
verify=False
)
resp.raise_for_status()
data = resp.json()
return {
"query": logql,
"result_type": data.get("data", {}).get("resultType"),
"result": data.get("data", {}).get("result", [])
}
# --- 入口 ---
if __name__ == "__main__":
# stdio 模式,Claude Code 会把这个进程作为子进程启动
mcp.run(transport="stdio")
4.5 配置 Claude Code 加载这个 MCP
编辑 Claude Code 的配置文件(~/.claude.json 或项目目录的 .claude/settings.json):
{
"mcpServers": {
"loki-logs": {
"command": "python",
"args": ["-m", "loki_mcp.server"],
"env": {
"LOKI_URL": "http://your-loki-server:3100",
"LOKI_BEARER_TOKEN": "your-token-here",
"LOKI_ORG_ID": "your-org-id",
"LOKI_MAX_LIMIT": "500",
"LOKI_MAX_HOURS": "48"
}
}
}
}
“💡 凭证安全:
env字段里的 token 虽然是明文,但这个配置文件只在本地机器上,不提交到 git。比把 token 写死在代码里安全得多。如果公司有统一的 secret manager(Vault、AWS Secrets Manager 等),可以改成调用 CLI 读取的方式。
4.6 验证:让 Claude Code 做一次日志排查
配置好之后,在 Claude Code 里可以这样用:
/mcp # 查看 MCP 工具列表,确认 loki-logs 加载成功
然后就可以直接提问:
最近一小时订单服务有哪些 ERROR 日志?帮我分析一下根因。
Claude Code 会自动调用 list_labels → list_label_values("app") → query_logs 这个链路,不需要你手动拼 LogQL,也不需要你去 Grafana 粘贴日志片段。
demo 跑通了,但生产环境还有几个坑要绕过。
五、进阶案例:三个让你重写 MCP 的生产教训
教训一:AI 不知道你的 LogQL 语法,它会猜
我们内部接好 Loki MCP 的第二天,一个工程师让 Claude Code 查了一个服务的日志,AI 生成的 LogQL 是:
{app="payment-service", error="true"}
这个查询在 Loki 里返回空结果。问题是:我们的日志里没有 error 这个 label,错误信息在日志行的 JSON 内容里,不是 label。正确写法应该是:
{app="payment-service"} | json | level = "error"
AI 不是不会 LogQL,而是它不知道你的日志结构。
解决方案:在 MCP 工具的 docstring 里加一段当前系统的日志结构说明,以及 2-3 个真实的查询示例。这是最低成本的做法。更系统化的做法是增加一个 get_schema 工具,返回当前系统常用的 label 组合和日志格式说明,供 AI 在生成查询前先读取。
@mcp.tool()
asyncdef get_log_schema() -> dict:
"""
返回当前日志系统的结构说明和常用查询示例。
在构造复杂查询之前,先调用这个工具了解日志格式。
"""
return {
"label_structure": {
"app": "服务名,如 order-service, payment-service, gateway",
"env": "环境,值为 production 或 staging",
"namespace": "K8s namespace",
"level": "注意:level 不是 label,需要通过 json 解析:| json | level = \"error\""
},
"common_queries": [
'{app="order-service"} | json | level = "error"',
'{app="payment-service", env="production"} |= "timeout" | json',
'count_over_time({app="order-service"} | json | level = "error" [5m])'
],
"gotchas": [
"日志内容是 JSON 格式,level/trace_id 等字段需要先 | json 再用",
"时间戳在 Loki 里精度到纳秒,API 返回的是纳秒字符串"
]
}
教训二:不限制返回量,AI 会把服务器打挂
我们有条服务在出问题时每秒产生几百条日志。一次 AI 查了"最近 24 小时的所有 ERROR 日志",没有加任何过滤,结果 Loki 开始扫描几十 GB 的数据,查询超时、Loki 内存飙升,影响了同时在看日志的其他工程师。
这就是为什么要在代码里硬编码 MAX_LIMIT 和 MAX_HOURS,并且通过环境变量让管理员可以调整,但 AI 本身不能改变这两个限制——工具的参数不暴露这两个值。
另一个建议是:给 query_logs 加一个预检步骤,先用 count_over_time 评估查询量,超过阈值就提示 AI 缩小范围再查:
# 在 query_logs 执行前,先做量级评估(伪代码)
count_query = f'count_over_time(({logql})[{time_range}])'
count_result = await _loki_instant_query(count_query)
if count_result > WARN_THRESHOLD:
return {
"warning": f"该查询预计返回 {count_result} 条日志,建议缩小时间范围或增加过滤条件",
"suggestion": "缩小时间范围到 1 小时内,或增加 level='error' 过滤"
}
教训三:stdio 在内网部署时的一个反直觉好处
我们最开始按"标准做法"想把 MCP server 部署成一个 HTTP 服务,然后让团队里所有工程师共享。结果遇到了:
- 需要管理 OAuth,搭一套 Keycloak 比想象中麻烦
- MCP server 部署在内网某台机器上,需要开防火墙端口
- 每个工程师的 Claude Code 连同一个 MCP server,有一个人把 Loki 打挂了,所有人都受影响
最后我们改回了 stdio 模式,每个工程师本地起自己的 MCP 进程。收益是:
- 零运维负担,没有额外服务要维护
- 每个工程师的查询互相隔离,一个人出问题不影响他人
- 认证 token 管理各自负责,不需要团队共享凭证
stdio 的使用限制:你的机器需要能直接访问 Loki/ES 的 HTTP 接口。如果有网络隔离(只有特定跳板机能访问日志系统),就需要走 HTTP 模式 + 部署在跳板机上。
三条教训总结:工具粒度 → 查询限制 → 部署模式,这三件事想清楚了,一个能在生产环境长期跑的日志 MCP 才算搭好了。
六、小结
今天这一讲我们做了一件事:把企业日志系统包装成 MCP,让 Claude Code 从"等你粘贴日志"升级到"主动去查日志"。
如果你只能记住三件事,记住这三件:
- 工具分层比工具数量更重要——Discovery 层(探索结构)和 Query 层(精确查询)分开,让 AI 的查询行为可预期、可控制。
- 内网 stdio 优于 HTTP——少于 10 人的团队用 stdio 模式,零运维、各自隔离、认证简单;只有需要共享 MCP server 时才上 HTTP + OAuth。
- MCP 层是安全的最后防线——查询上限、时间范围限制、label 白名单都在 MCP 代码里硬编码,AI 看到的工具参数里不暴露这些限制的调整权限。
这一讲的 Loki MCP 代码,在第 32 讲会作为 RCA 自动化 Skill 的核心组件再次登场——那一讲我们把查日志 + 分析根因 + 更新 runbook 这整个流程串成一个 Skill,你会看到今天打的这个地基有多重要。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号