Claude Code 的工具延迟加载机制

Claude Code 的工具延迟加载机制

CandyTong
发布于 2026-06-08 13:09:57
发布于 2026-06-08 13:09:57
AI Agent 的工具调用依赖模型理解每个工具的参数 schema。传统做法是在 system prompt 中列出所有工具的完整定义——名称、描述、参数类型、参数说明。当工具数量在 10-20 个以内时,这没有问题。
但当工具数量增长到 50+,schema 的 token 成本就不可忽视了。Claude Code 的内置工具(如 Bash、Read、Edit)每个 schema 约 70-150 token,MCP 工具的 schema 通常更复杂。一个典型的 MCP 场景:用户配置了 Slack、GitHub、Jira、Notion、Linear 五个服务器,每个提供 10-15 个工具,总计 50-75 个。全部内联发送会消耗大量 token——在 200K 上下文窗口中占比可观。
更关键的是,大多数工具在一次对话中不会被用到。用户可能只用了 Slack 的发送消息功能,但 GitHub、Jira、Notion、Linear 的所有工具 schema 都白白占据了上下文空间。
Claude Code 通过 defer_loading(延迟加载)机制解决了这个问题。先看 Claude Code 是怎么把工具传给大模型的,再看延迟加载如何在这个流程中发挥作用。
工具如何传给大模型
每次调用 Claude API 时,工具列表作为 tools 参数传入 anthropic.beta.messages.create()。这个参数是一个数组,每个元素包含工具的名称、描述和参数 schema:
const result = await anthropic.beta.messages.create({
model: options.model,
messages: messagesForAPI,
system,
tools: allTools, // 工具列表在这里传入
tool_choice: options.toolChoice,
max_tokens: maxOutputTokens,
stream: true,
});每个工具对象在传入 API 前,会经过转换,取出名称、描述和输入 schema,组装成 API 需要的格式。最终 allTools 中每个元素的结构类似:
{
"name": "Bash",
"description": "Executes a given bash command and returns its output.",
"input_schema": {
"type": "object",
"properties": {
"command": { "type": "string", "description": "The command to execute" }
},
"required": ["command"]
}
}这就是工具传入大模型的基本流程。
defer_loading 的核心机制
延迟判定:谁被延迟,谁不被延迟
工具组装时,每个工具都会经过一个判定函数:
function isDeferredTool(tool: Tool): boolean {
// alwaysLoad 优先——MCP 工具可以通过 _meta 设置此标志
if (tool.alwaysLoad === true) return false;
// MCP 工具默认延迟
if (tool.isMcp === true) return true;
// ToolSearch 自身不能被延迟——模型需要它来加载其他工具
if (tool.name === TOOL_SEARCH_TOOL_NAME) return false;
// 内置工具通过 shouldDefer 显式标记
return tool.shouldDefer === true;
}判定规则:
- • MCP 工具默认被延迟——这是延迟加载存在的主要原因
- •
alwaysLoad: true的 MCP 工具跳过延迟——适用于高频使用的工具 - •
ToolSearchTool自身永远不延迟——它是模型发现其他工具的唯一入口 - • 内置工具默认不延迟——
shouldDefer字段默认为false,除非工具显式标记
defer_loading 如何生效
判定结果通过 willDefer() 函数传入 toolToAPISchema(),后者在工具的 API schema 上加上 defer_loading: true 标记:
const toolSchemas = await Promise.all(
filteredTools.map(tool =>
toolToAPISchema(tool, {
deferLoading: willDefer(tool),
}),
),
);toolToAPISchema() 的核心逻辑:
function toolToAPISchema(tool, options) {
const schema = {
name: base.name,
description: base.description,
input_schema: base.input_schema,
};
if (options.deferLoading) {
schema.defer_loading = true;
}
return schema;
}带 defer_loading: true 的工具在 API 侧的行为不同:模型只能看到工具的名称和描述,看不到完整的参数 schema。这正是延迟加载的核心——通过一个 API 字段,控制工具 schema 的可见性。
延迟后的工具在 prompt 中长什么样
被延迟的工具不会从工具池中移除,但发送给 API 时只携带名称,不携带完整的 inputSchema。
模型在 system prompt 中看到的是一个 <available-deferred-tools> 区域,每个工具只有一行:
<available-deferred-tools>
mcp__slack__send_message — send a message to a Slack channel or user
mcp__slack__list_channels — list available Slack channels
mcp__github__create_issue — create a new GitHub issue
mcp__jira__search_issues — search for Jira issues using JQL
</available-deferred-tools>模型知道这些工具存在,也知道它们大概做什么,但不知道它们需要什么参数。这意味着模型无法直接调用它们——它必须先获取完整的 schema。
ToolSearchTool:按需加载的桥梁
ToolSearchTool 是整个延迟加载机制的关键枢纽。它是唯一一个始终加载的工具,负责在模型需要时加载其他工具的完整 schema。
它支持两种查询方式:
- 1. 精确查询:
"select:Read,Edit,Grep"—— 按名称直接获取 - 2. 关键词搜索:
"notebook jupyter"—— 匹配工具描述,返回最相关的工具
搜索结果以 tool_reference 块的形式返回。每个匹配的工具包含完整的 JSONSchema 定义:
{
"type": "tool_reference",
"tool": {
"name": "mcp__slack__send_message",
"description": "send a message to a Slack channel or user",
"input_schema": {
"type": "object",
"properties": {
"channel": { "type": "string", "description": "Channel ID or name" },
"text": { "type": "string", "description": "Message text" }
},
"required": ["channel", "text"]
}
}
}API 层会自动将 tool_reference 展开为完整的工具定义。展开后,工具就像从未被延迟过一样可以正常调用。
完整流程
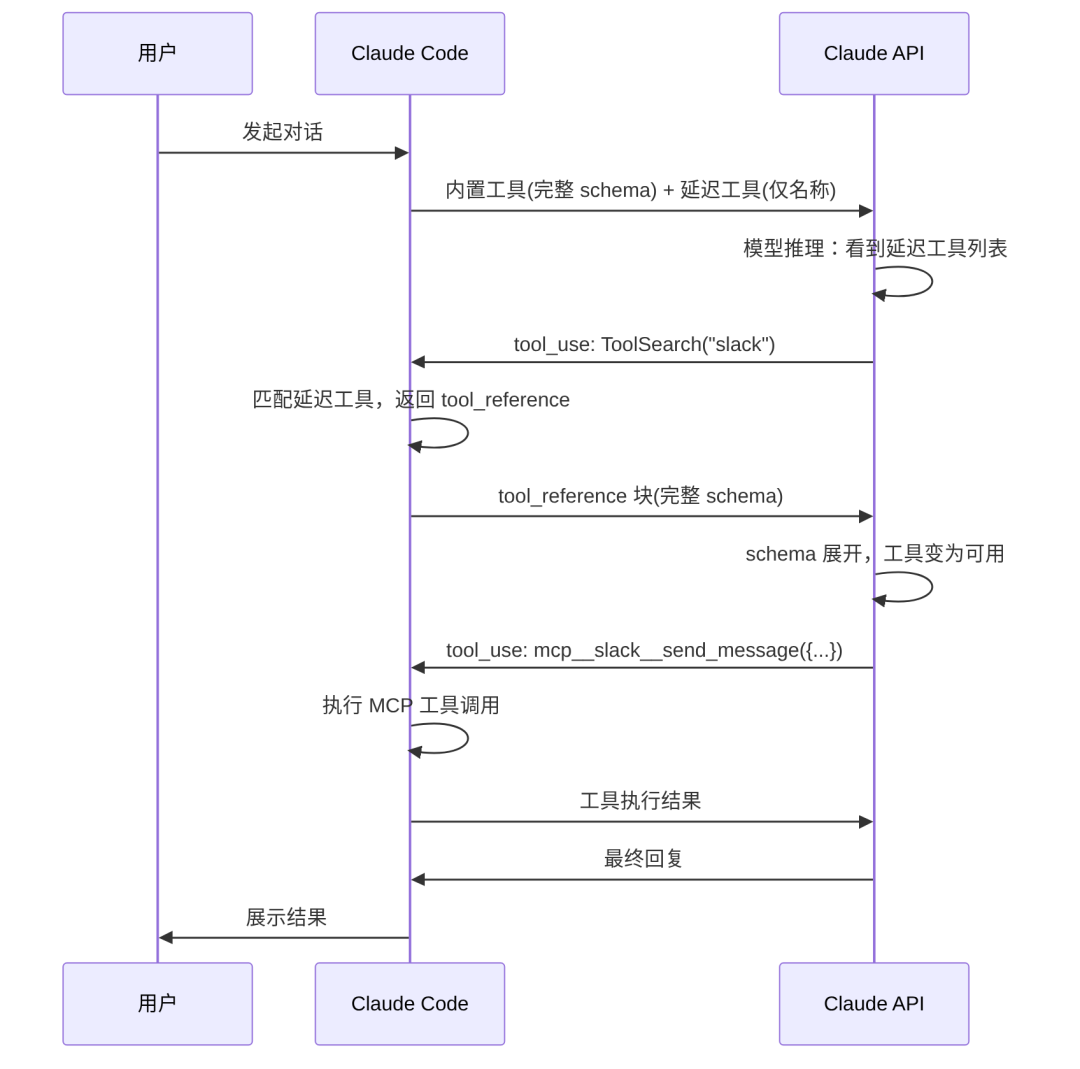
slack
模型缓存:defer_loading 的隐性问题
defer_loading 解决了上下文窗口膨胀的问题,但它还意外地解决了另一个更隐蔽的问题。
模型的 prompt cache 以 system prompt 的前缀匹配为基础。如果工具列表在两次请求之间发生变化——比如 MCP 服务器重连后工具数量变了——prompt 就会变化,缓存就会失效。缓存失效意味着更多的 token 需要重新计算,API 调用成本和延迟都会大量上升。
针对这个问题,claude 模型 API 支持传入 defer_loading 的工具:它们不参与 KV Cache 的 key 计算。API 侧会将 defer_loading 的工具从 prompt 中剥离,因此它们不影响实际的缓存 key。即使 MCP 工具集合在会话中不断变化,已有的缓存依然有效。
为什么要将工具 Schema 传给模型 API 接口,而不是通过 Prompt 让模型生成工具调用?
这里有一个容易混淆的点:Schema 是给 API 用的,不是给模型看的。
如果只是让模型"知道有哪些工具、怎么调用",prompt 确实够了,但 Schema 的作用不止于此:
- • API 层的结构化输出:Claude API 的
tools参数会改变模型的输出格式。传入工具后,模型返回的不是自由文本,而是结构化的tool_use块——包含工具名和 JSON 格式的输入参数。这是 API 级别的能力,不是 prompt 能模拟的。 - • 输入校验:API 侧会根据 Schema 校验模型的输入——类型是否正确、必填字段是否缺失、是否符合 enum 约束。校验失败时 API 会自动修正或拒绝,而不是把错误参数传给工具执行层。
- • 可靠性保证:没有 Schema,模型可能幻觉出不存在的参数、用错类型、生成格式错误的 JSON。有了 Schema,这些错误在 API 层就被拦截了。
所以 Schema 和 Prompt 解决的是不同层面的问题:Prompt 告诉模型"有什么、做什么",Schema 告诉 API"怎么验证、怎么格式化"。
如果模型不支持呢
defer_loading 需要模型侧配合——它是一个 API 级别的特性,不是所有模型都能处理。Claude Code 在构建 API 请求前会检查当前模型是否支持:
const toolSearchEnabled = isToolSearchEnabled(options.model, ...)不支持的模型无法使用 defer_loading,所有工具 schema 只能内联发送。支持的模型还需要在请求头中附加 beta 标志。
这就引出了一个实际问题:延迟行为应该一刀切吗?Claude Code 提供了三种 ToolSearchMode 策略:
tst-auto 是一个自适应策略:MCP 工具较少时内联发送(省去 ToolSearch 的额外 round trip),数量增长到一定程度自动切换到延迟模式。standard 则是完全不延迟——当模型 不支持 defer_loading 时,这是唯一的选项。
如果模型没有 defer_loading API,要怎么实现工具延迟加载?
可以,思路是用一个通用的代理工具做中转。
注册一个 CallTool,它的 Schema 只有两个字段:tool_name 和 args。所有动态工具都不直接注册到 API,而是通过 CallTool 间接调用。模型先通过 ToolSearch 获取目标工具的完整参数定义,然后把参数填进 CallTool 的 args 字段,由 CallTool 转发给实际工具执行。
模型 → ToolSearch("slack send_message") → 获取参数 Schema
模型 → CallTool({ tool_name: "slack_send_message", args: { channel: "#general", text: "hello" } })
→ 内部路由到实际工具执行这个方案虽然可行,但有一个明显的弊端:失去了 API 层的 Schema 强校验。CallTool 的 args 是一个通用的 JSON 对象,API 无法校验里面的结构是否符合目标工具的定义。模型生成的参数是否正确,完全依赖模型自身的能力 —— 类型错误、缺少必填字段、幻觉出不存在的参数,都不会在 API 层被拦截。
相比之下,defer_loading 的方案让 API 在工具被调用时拥有完整的 Schema 定义,校验是自动的,当然其问题就在于延迟加载工具需要重复计算缓存了,各有利弊。
MCP 工具:延迟加载的主要受益者
MCP 工具是 defer_loading 存在的核心原因。MCP 工具与内置工具有一个根本区别:数量不可预测。
内置工具是 Claude Code 开发团队控制的,数量稳定在 40 个左右,schema 经过优化,token 占用可控,且部分为异步加载。
MCP 工具则来自外部服务器——用户可以配置任意数量的 MCP 服务器,每个服务器可以提供任意数量的工具。
return result.tools.map((tool): Tool => ({
...MCPTool, // 骨架模板
name: `mcp__${serverName}__${tool.name}`, // 命名空间隔离
isMcp: true, // 标记为 MCP → 默认延迟
alwaysLoad: tool._meta?.['anthropic/alwaysLoad'] === true,
inputJSONSchema: tool.inputSchema, // 直接使用 JSON Schema
async call(args, context, ...) {
const connectedClient = await ensureConnectedClient(client)
return await callMCPTool(connectedClient, tool.name, args)
},
}))isMcp: true 标记让这些工具在 isDeferredTool() 判定中默认返回 true
总结
Claude Code 的 defer_loading 机制解决了工具数量增长时的上下文窗口膨胀问题:
- 1. MCP 工具默认被延迟 —— 只发送名称到 API,不发送完整 schema
- 2. 模型通过 ToolSearchTool 按需发现工具 —— 精确查询或关键词搜索
- 3. 搜索结果返回
tool_reference块 —— API 自动展开为完整工具定义 - 4. 展开后的工具可以正常调用 —— 对模型来说没有区别
- 5. defer_loading 的工具不参与 KV Cache 计算 —— 工具变化不会导致缓存失效
这套机制让 Claude Code 能够支持几乎无限数量的 MCP 工具,同时保持上下文窗口的高效利用。
如果你觉得这篇文章有帮助,欢迎点赞收藏关注。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号