让 Claude 成为化学家:从结构到谱图,再从谱图反推结构

让 Claude 成为化学家:从结构到谱图,再从谱图反推结构

MindDance
发布于 2026-06-08 13:45:53
发布于 2026-06-08 13:45:53
昨日,Anthropic 发布了一篇研究推文。他们正在和一批顶尖的合成化学家、计算化学家与分析化学家合作,目标是把 Claude 训练成一个能真正帮上忙的化学助手。这次公开的,是这项长期工作的第一篇白皮书——由 Anthropic 的化学家 David Kamber 主笔,主题是化学家每天都要面对的一种分析数据:核磁共振谱图。结论相当克制,却很有意思:一个没有经过任何化学专门微调的通用大模型,在这项专业任务上,平均水平已经追平、某些维度甚至反超了化学家桌面上用了几十年的专业软件。
一、看不见的分子,与化学家的多重语言
化学研究有一个容易被外行忽略的前提:分子太小了,小到再好的显微镜也看不见。一个化学家做完一步反应,瓶子里到底生成了什么,他其实没法直接看。他只能用各种能量去探这个分子——可见光、射电波、磁场——再根据分子吸收、发射或偏转这些能量的方式,反推出它的结构。
更麻烦的是,同一个分子,在化学家的工作流里会以完全不同的面貌出现。白板上的手绘结构式、仪器打印出来的谱图、查数据库时输入的字符串、专利和论文里那套严谨的命名法……每一种表示方式背后是同一套化学,但每一种都需要一套不同的读法。
文章里举了一个很妙的例子:当一个化学家看到咖啡因的结构草图,他能一眼认出它和腺苷(adenosine,也就是身体里负责让人犯困的那个信号分子)长得很像,从而推测出咖啡因之所以提神,是因为它占住了腺苷该去的受体。但同样这张草图,却没法帮他把咖啡因和其他几个长得几乎一模一样的分子区分开来。不同的任务,需要不同的表示方式。
为什么把分子认对这么重要?因为化学几乎是一切的底层——我们吃的食物和药、抹的护肤品、用的油漆和塑料,都建立在分子之上。而分子对结构的微小差别极其敏感。同样数目的原子,把几根化学键重新连一下,葡萄糖就变成了果糖:分子式一模一样,在体内却走完全不同的代谢通路。再极端一点,把一个分子翻转成它的镜像,一种镇静剂就可能变成致畸剂——这正是当年沙利度胺(反应停)悲剧的根源,一种治疗孕吐的药物,最终和全球一万多名儿童的严重出生缺陷联系在了一起。
而这件事的规模大到让人绝望。全球最大的化学物质登记机构 CAS,已经收录了超过 2.9 亿种公开披露的物质,并且每天还在以大约 1.5 万种的速度增长。在不同表示方式之间来回翻译——从一张图里把结构抠出来、把仪器读数和你设想的产物对上、用正确的记号去查数据库——既耗时,又根本不可能靠人力跟上这个增速。
二、为什么是现在
让我们直说:AI 能帮化学家这件事,并不是一个新想法。
机器学习被寄予厚望已经很多年了,尤其是在逆合成分析(即从一个目标分子倒推,规划出该用哪些更简单的原料、按什么步骤把它合成出来)、反应预测和性质估算这些方向上。但这些工具需要的数据一直很难拿到:阴性结果(也就是失败的实验)几乎没人记录、格式五花八门、还大量锁在付费期刊和那些非结构化的补充材料里。逆合成就是个典型例子——能用的 AI 工具其实早就有了,但普及程度很不均衡,一个普通高校实验室或小课题组里的化学家,往往根本不用它。
那为什么是现在?因为前沿模型变得不一样了。
今天的模型是多模态的,而且能进行显式的推理。它可以直接从一篇论文的插图、甚至一张手绘草图里读出化学结构,而不必依赖一个事先整理好的分子数据库;它可以读懂方法部分和补充材料里那种真实发表出来、乱糟糟的实验细节;最关键的是,它能把推理过程一步步摊开给你看,这意味着化学家可以审查它的输出,而不是面对一个黑箱。
这些都没有消灭化学界念叨了多年的数据难题。但它改变了一件事:在数据不足的前提下,哪些问题变得可解了。 Anthropic 给自己定的说法相当克制——Claude 正开始在那些与化学家判断力互补的日常工作上,也就是翻译、回忆与整合,提供有意义的帮助,而他们打算把这种帮助继续往前推。
三、第一道考题:核磁共振谱
作为整个计划的第一篇白皮书,他们选了核磁共振(NMR)谱图作为切入点。这个选择很合理:NMR 是化学家做结构确认时最常用、也最耗时间的手段之一。
简单解释一下这件事在干嘛。化学反应几乎从不会干干净净只生成一个产物,而确认你拿到的东西就是你想要的,往往要吃掉化学家大半的表征时间。NMR 的做法,是把样品放进强磁场、再用射电波去激发它:分子里每一个化学环境不同的氢原子或碳原子,都会在略微不同的位置上给出一个信号峰。最后你得到的,是一排峰——本质上是这个分子的指纹。而所谓读谱,就是要把谱图上每一个峰,手工对应到结构里的某一个原子。这是合成化学里最磨人的步骤之一。
实验的设计本身就值得说道。研究者拿三个 Claude 模型(Opus 4.7、Opus 4.6、Sonnet 4.6),去对阵化学家桌面上几乎人手一份的两款专业软件:ChemDraw 和 MestReNova。测试用了 20 个化合物,而这 20 个化合物有一个关键来源——它们全部取自 ChemRxiv 上、在这些模型训练数据截止之后才发表的预印本。
这一点很重要,值得专门点出来。把测试材料限定在模型训练截止日期之后,等于堵死了一种最常见的质疑:模型不是真的会算,只是早就把答案背下来了。这些分子是全新的,模型在训练时不可能见过它们的谱图,所以它的表现只能来自推理,而不是记忆。同时,研究者还特意在生成任何预测之前,就把化合物选定、锁死,以避免选择偏差。这是很扎实的实验卫生。
这 20 个化合物分成四个结构家族、每个家族 5 个,每一族都被刻意挑来代表一类不同的 NMR 难题。第一族是含有缓慢交换 NH 质子的氯哒嗪,这类质子的位置出了名地难预测;第二族是马来酰亚胺与炔酰胺,考验的是一类特殊的羰基,以及炔酰胺里那对罕见的 α、β 碳;第三族是带有非对映异位 CH₂ 的螺环酮;第四族是 α-硅基甲磺酰胺,其中紧邻硅原子的那个碳会被强烈屏蔽。换句话说,这不是一份挑软柿子捏的考卷。
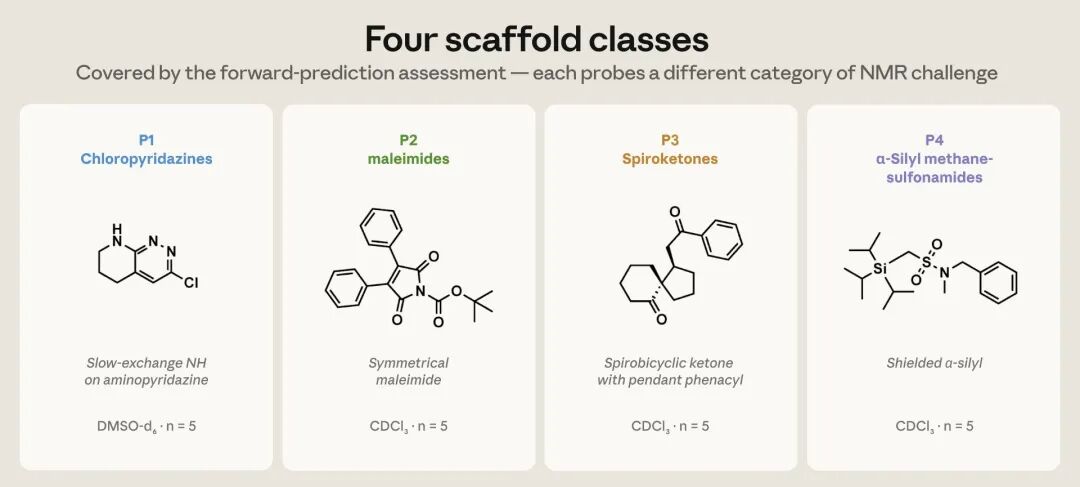
图1 正向预测评测覆盖的四类结构骨架,每一类对应一种不同的 NMR 难题——氯哒嗪(P1)、马来酰亚胺与炔酰胺(P2)、螺环酮(P3)、α-硅基甲磺酰胺(P4),每类 5 个、共 20 个化合物。(图片来源:Anthropic)
图1 正向预测评测覆盖的四类结构骨架,每一类对应一种不同的 NMR 难题——氯哒嗪(P1)、马来酰亚胺与炔酰胺(P2)、螺环酮(P3)、α-硅基甲磺酰胺(P4),每类 5 个、共 20 个化合物。(图片来源:Anthropic)
测试分成方向相反的两道大题:正向预测(从结构推谱图)和逆向预测(从谱图推结构)。后者要难得多,也恰恰是现有软件留给化学家自己去啃的那一块。
四、正向预测:和专业软件正面硬碰
正向预测是这两件事里比较常规的那个:你画出预想的结构,让工具预测它应该长出什么样的谱图,再拿去和实测的对比。ChemDraw 和 MestReNova 干的就是这个。
考虑到大模型每次输出都会有些波动,每个 Claude 模型对每个化合物都被问了三遍取平均;而两款软件是确定性的,每次答案都一样,所以只跑一遍。然后研究者把每一个预测峰和它对应的实测峰配对,量出两者相差多少 ppm(化学位移的单位)。化学家眼里算对的窗口是:氢谱 ±0.20 ppm,碳谱 ±1.0 ppm。
结果是这样的。在氢谱上,Opus 4.7 是所有工具里最准的,平均误差只有 ±0.079 ppm——还不到那个容差窗口的一半——落在窗口内的峰的比例也最高。在碳谱上,Opus 4.7(±1.37 ppm)和 MestReNova(±1.48 ppm)基本打平。Opus 4.6 不出意料地处在中游,Sonnet 4.6 最弱。
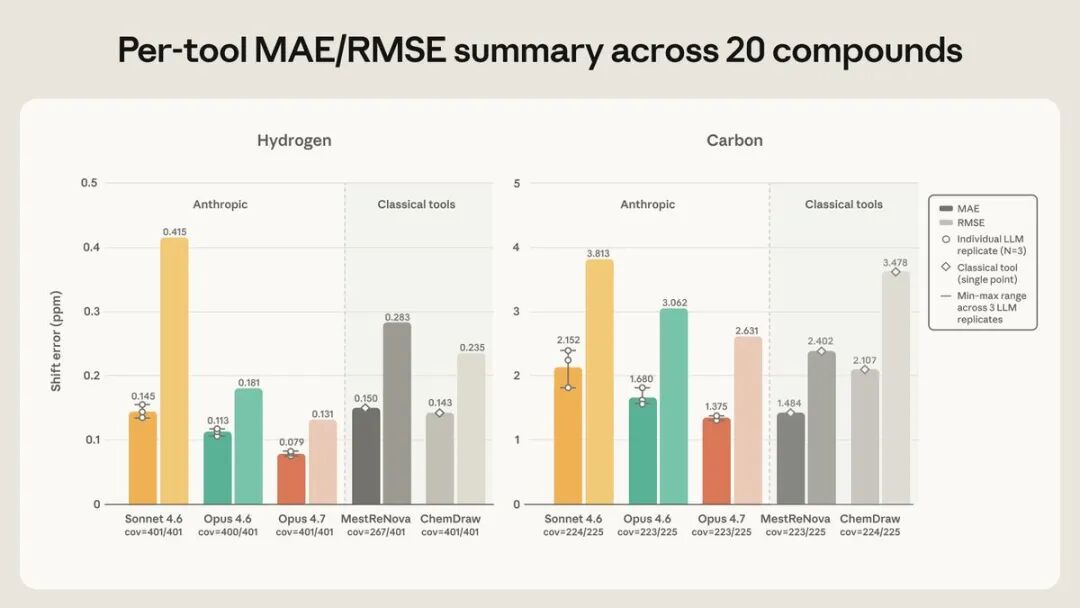
图2 20 个化合物上各工具的氢谱(左)与碳谱(右)位移误差,深色为平均绝对误差 MAE、浅色为均方根误差 RMSE,下方标注峰覆盖率。Claude 取三次重复的均值并标出最小到最大范围,传统软件为单次确定性预测。(图片来源:Anthropic)
图2 20 个化合物上各工具的氢谱(左)与碳谱(右)位移误差,深色为平均绝对误差 MAE、浅色为均方根误差 RMSE,下方标注峰覆盖率。Claude 取三次重复的均值并标出最小到最大范围,传统软件为单次确定性预测。(图片来源:Anthropic)
模型之间的差距,在一个出了名难缠的氢质子上体现得最清楚:氯哒嗪家族里那个 NH 质子,它真实的位置落在 6.8 到 7.9 ppm 这个很窄的区间里。Opus 4.7 把它放得略低,但稳定地略低;Opus 4.6 的几次猜测散落在好几个 ppm 上;而 Sonnet 4.6 干脆把它扔到了 10 到 13 ppm,离它实际出现的地方差了十万八千里。这个细节很说明问题——同一个体系,能力的差异不在平均分上,而在它会不会在最难的地方彻底跑偏。
更有意思的是峰形和峰距。一个氢的信号会裂分成什么形状(单峰、双峰、三峰……),以及裂开的小峰彼此间隔多远,这些里面同样藏着化学家要读的结构信息。在裂分模式上,Opus 4.7 和实测对上的次数比任何其他工具都多。而在描述小峰间距的耦合常数(J 值)上,三个 Claude 模型大约有 80% 的预测能精确到半个赫兹以内——而 ChemDraw 和 MestReNova 这个比例只有 26% 到 35%。这里的差距不是细微领先,而是数量级上的碾压。Opus 4.7 同时也是三次重复里最稳的,它自己几次之间的平均误差波动,比它领先第二名的幅度还要小。
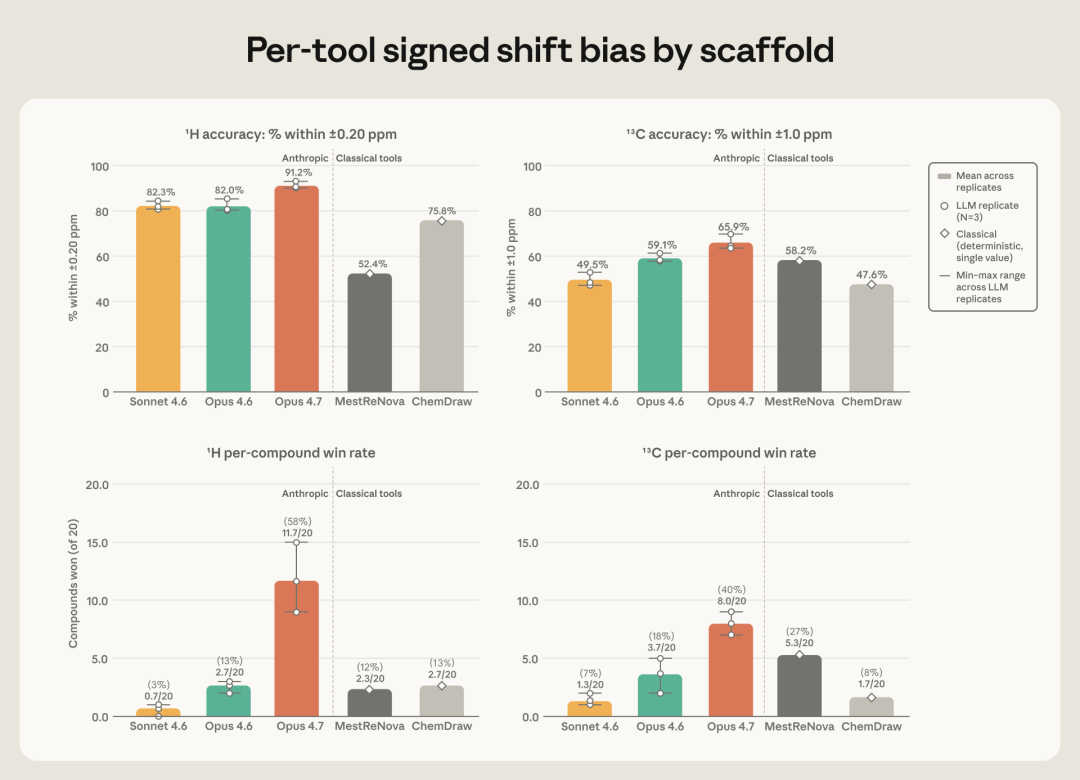
图3 上排为落在容差窗口内的原子比例(氢谱 ±0.20 ppm、碳谱 ±1.0 ppm);下排为逐化合物胜出率,即在 20 个化合物中,每个工具拿到最低单化合物 MAE 的次数。(图片来源:Anthropic)
图3 上排为落在容差窗口内的原子比例(氢谱 ±0.20 ppm、碳谱 ±1.0 ppm);下排为逐化合物胜出率,即在 20 个化合物中,每个工具拿到最低单化合物 MAE 的次数。(图片来源:Anthropic)
当然,专业软件也有它的主场。ChemDraw 最大的长处是覆盖面——它在氢和碳两边都维持着最广的峰覆盖率,哪怕它的耦合常数算得不准。换句话说,它什么都给你预测,只是不一定都准;而 Claude 是预测得更准,但偶尔会漏掉一些原子。这是一个很真实的权衡,而不是一边倒。
五、逆向推断:去做软件做不到的事
如果说正向预测是 Claude 去和专业软件比谁更准,那逆向推断就是 Claude 去做这一整类软件压根做不到的事——这才是这篇白皮书里真正让人坐直身子的部分。
逆向推断,也叫结构解析:给你一张谱图,反过来确定背后是什么结构。这需要专家级的推理——要判断分子里有哪些片段、它们又是怎么连起来的。ChemDraw 完全没有这个能力;MestReNova 能帮你把峰归属到一个已知结构上,但它没法从一张峰列表凭空生成候选结构。这一步,传统上一直是留给化学家本人的。
研究者给了 Opus 4.7 共 15 道结构解析题,每题做三遍,要求它给出最多三个排了序的候选结构。每道题提供的,是这个化合物的精确分子式(来自高分辨质谱 HRMS)以及它的氢谱和碳谱。这 15 道题按难度分成两档:8 道较简单的(单环或两片段的分子),只给分子式和谱图;7 道更密集的(稠环、螺环之类),额外多给一个提示——那个投进反应里的起始原料的结构。
值得说明的是,那一点点额外提示之外,研究者刻意不给任何其他反应背景:没有试剂、没有条件、没有机理、也没告诉它产物属于哪一类。这其实模拟了化学家真实会遇到的两种处境——确认一个来路不明的反应的产物,和确认一个你知道投了什么料的反应的产物。
结果相当亮眼。那 8 道较简单的题,Opus 4.7 仅凭分子式和谱图,每一次尝试都把正确结构还原了出来。在 7 道更难的题上,借助起始原料这个提示,它对其中 4 道在三次尝试里全部答对,剩下几道也在三次里答对了两次。
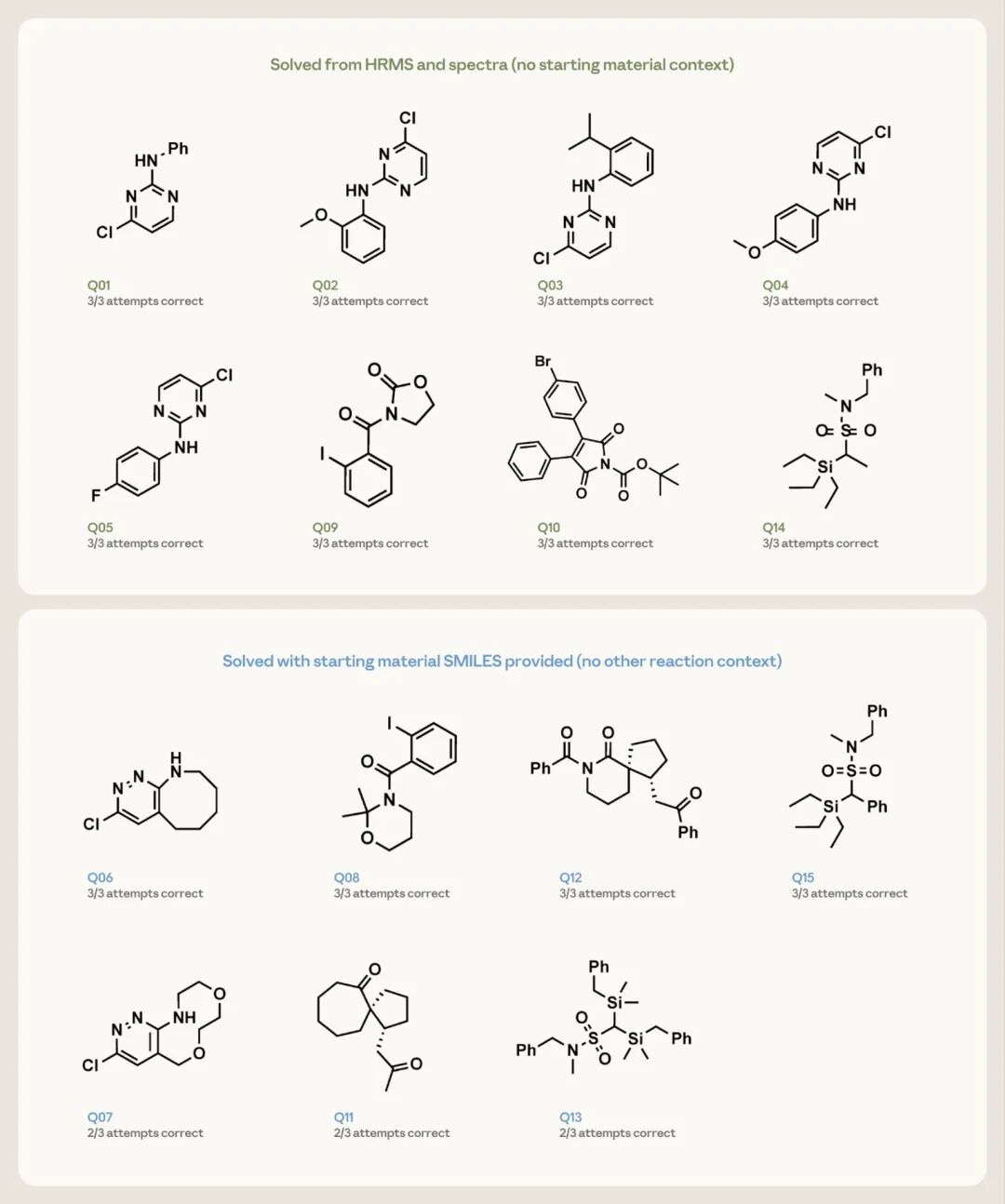
图4 15 道逆向结构解析题的结果,每格标注该题三次尝试中答对的次数。绿色边框表示只给谱图和高分辨质谱、不给起始原料;蓝色边框表示额外提供了起始原料的结构(但不含任何其他反应信息)。(图片来源:Anthropic)
图4 15 道逆向结构解析题的结果,每格标注该题三次尝试中答对的次数。绿色边框表示只给谱图和高分辨质谱、不给起始原料;蓝色边框表示额外提供了起始原料的结构(但不含任何其他反应信息)。(图片来源:Anthropic)
为什么这件事重要?因为专门的结构解析软件其实已经存在了几十年,但它通常需要二维核磁(一种有两个坐标轴、输出是等高线图而非一排峰的谱图)、需要专门的训练、还需要付费授权。而 Claude 用的,就是化学家会直接粘进对话框里的那些东西——一张常规高分辨质谱和一份一维峰列表,不需要任何额外的搭建。它把自动结构解析从原本要靠二维实验或人工硬解的领域,往前推进到了只用手头现成的一维数据就能搞定的程度。
六、一份诚实的边界清单
这篇白皮书让我比较欣赏的一点,是它对自己的局限交代得相当坦白,没有把一个初步结果包装成一场革命。
最直接的一条:这次评测规模很小——正向任务 20 个化合物、四个骨架,逆向任务 15 个。而且每一类骨架只贡献了一种失败模式,所以这些数字排名应该被当成有指示意义、而不是精确结论来读。
第二,在最密集的那几道逆向题上,如果不给起始原料,模型可能会在推理里反复绕圈、迟迟不肯锁定一个最终结构——这正是那 7 道难题为什么要附上起始原料、而不是只给谱图的原因。这是个很诚实的承认:在最难的情况下,模型还需要一根拐杖。
第三,有些化学骨架根本没测到。比如前面那种缓慢交换的 NH 芳杂环,这次只通过氯哒嗪取了样,像羟基吡啶、氨基噻唑这些相关体系都没覆盖。第四,二维实验(COSY、HSQC、HMBC)和立体化学从设计上就被排除在外了,因为一维核磁本身就定不了构型——也正因如此,复杂的天然产物没有参与评测。第五,溶剂只覆盖了三种,甲醇、苯、丙酮这几种常用氘代溶剂都没评估到。
还有一个挺有意思的共性瑕疵被特意点了出来:所有工具——包括两款软件和 Claude——都会把羰基碳预测得偏低一点。这意味着如果你想用两个工具是否一致来给羰基碳做交叉验证,是抓不出这个错的,因为它们会一起错。这种对系统性偏差的觉察,恰恰是认真做评测才会注意到的东西。
研究者也说了理想中该怎么做:评测应该铺开到几百个化合物、覆盖 20 到 30 类骨架、每类至少 15 个,这样才能把同一类内部的波动和工具之间的真实差异分开来;还应该补上那些没测的 NH 芳杂环、那些没测的溶剂,并做出动用二维实验的版本。
七、路线图,以及这件事真正的分量
NMR 只是开头。文章列出了接下来要重点攻克的几个瓶颈,都是最拖慢化学家的环节。一是读取和渲染化学结构,也就是把图、专利、幻灯片或草图里的结构转成机器可读的形式,并在结构表示和文献里那套系统命名之间自由换算。二是反应与合成推理,包括提出、评估、批判一条合成路线,预判结果,想清楚选择性、条件和可能的副产物。三是机理,用化学家真正在用的语言——电子箭头、中间体、过渡态——去解释和检验反应机理。四是化学文献理解,去读懂文献里那种同一个分子可能被画出来、被命名、被缩写、或被一个代号指代的真实写法,并从方法部分、补充材料和专利里把真正重要的化学抽出来。
值得注意的是,这几件事并不在同一条成熟度曲线上。光谱分析已经成熟到可以拿来做基准测试了,而像逆合成规划这样的方向,还停留在被界定范围的阶段。Anthropic 的说法是,随着对这些瓶颈理解得更清楚,他们会持续公布当前模型在哪些地方表现出色、又在哪些地方仍然不够——最终目标是让一线化学家清楚地知道,Claude 在哪里能帮他们省时间,又在哪里还得靠自己的专业判断。
读完整篇,我觉得有几点比这些数字更值得琢磨。
第一,最反直觉的事实是没有专门微调。Opus 4.7 是一个通用模型,它没有为化学单独做过精调,却能在一项高度专业的任务上追平甚至局部反超用了几十年的专用软件。这和过去那种为每个垂直领域训练一个专门 AI 的范式很不一样——它暗示通用推理能力本身,正在跨过越来越多原本被认为需要专门工具的门槛。
第二,正向和逆向这两道题,分量其实不对等。在正向预测上,Claude 是在和已有软件比谁更准,这是一种追平;但在逆向解析上,Claude 做的是这一整类正向预测软件在原理上就做不了的事,这是一种新增的能力。前者让人佩服,后者才真正改变了化学家能向一个模型提出什么样的请求——确认一个已知反应的产物、排除一个区域异构体、给一次峰归属做一次快速核验、或者判断哪些化合物值得再去做二维实验,这些原本要么得靠专业软件、要么得靠专家脑子的活,现在用纯文本对话就能处理了。
第三,也别忘了那个被忽视的普通用户。文章特意提到,逆合成这类工具明明早就有了,可大多数小实验室的化学家从来不用。门槛——授权、专门训练、专用软件的搭建——本身就是一种障碍。而 Claude 把这些能力变成了把数据粘进对话框这么低的使用成本,这件事对那些一直被专业工具挡在门外的人,可能比追平精度更有意义。
最后是它的姿态。这是一篇由化学家主笔、把局限一条条摊开、反复强调补充而非替代化学家判断的研究。它没有喊口号,它在做基准、认偏差、划边界。对于一个本质上还很难被验证的领域,这种克制和诚实,本身就是可信度的一部分。
顺带一提,Anthropic 也在把它的 AI for Science 计划更明确地扩展到化学研究,并公开征集那些 Claude 有可能帮上忙、尤其涉及这类多模态推理的课题。换句话说,这篇白皮书与其说是一个终点,不如说是一份邀请函。
参考文献
Anthropic 研究博客《Making Claude a chemist》及配套白皮书,作者 David Kamber。
本文为基于该原文的中文深度解读,具体数据与结论以原文为准。
https://www.anthropic.com/research/making-claude-a-chemist

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号